【三维几何学习】从零开始网格上的深度学习-3:Transformer篇(Pytorch)
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
从零开始网格上的深度学习-3:Transformer篇
- 引言
- 一、概述
- 二、核心代码
- 2.1 位置编码
- 2.2 网络框架
- 三、基于Transformer的网格分类
- 3.1 分类结果
- 3.2 全部代码
引言
本文主要内容如下:
- 简述网格上的位置编码
- 参考点云上的Transformer-1:PCT:Point cloud transformer,构造网格分类网络
一、概述
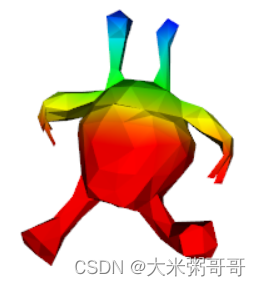
个人认为对于三角形网格来说,想要将Transformer应用到其上较为重要的一步是位置编码。三角网格在3D空间中如何编码每一个元素的位置,能尽可能保证的泛化性能? 以xyz坐标为例,最好是模型经过对齐的预处理,使朝向一致。或者保证网格水密的情况下使用谱域特征,如热核特征。或者探索其他位置编码等等… 上图为一个外星人x坐标的位置编码可视化
- 使用简化网格每一个面直接作为一个Token即可,高分辨率的网格(考虑输入特征计算、训练数据对齐等)并不适合深度学习(
个人认为) - 直接应用现有的Tranformer网络框架、自注意力模块等,
细节或参数需要微调
二、核心代码
2.1 位置编码
使用每一个网格面的中心坐标作为位置编码,计算代码在DataLoader中:
- 需要平移到坐标轴原点,并进行尺度归一化
# xyz
xyz_min = np.min(vs[:, 0:3], axis=0)
xyz_max = np.max(vs[:, 0:3], axis=0)
xyz_move = xyz_min + (xyz_max - xyz_min) / 2
vs[:, 0:3] = vs[:, 0:3] - xyz_move
# scale
scale = np.max(vs[:, 0:3])
vs[:, 0:3] = vs[:, 0:3] / scale
# 面中心坐标
xyz = []
for i in range(3):xyz.append(vs[faces[:, i]])
xyz = np.array(xyz) # 转为np
mean_xyz = xyz.sum(axis=0) / 3
2.2 网络框架
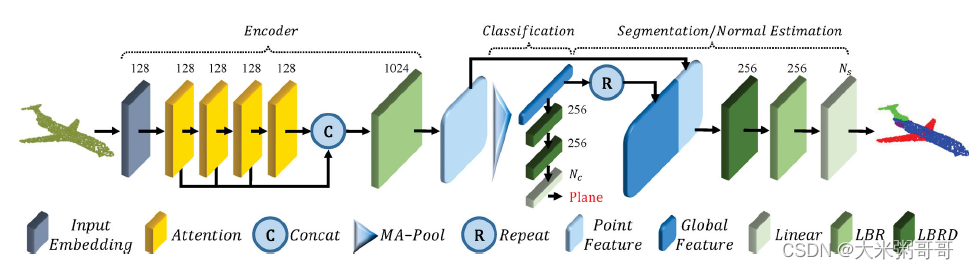
- 参考上图PCT框架,修改了部分细节,如减少了Attention模块数量等
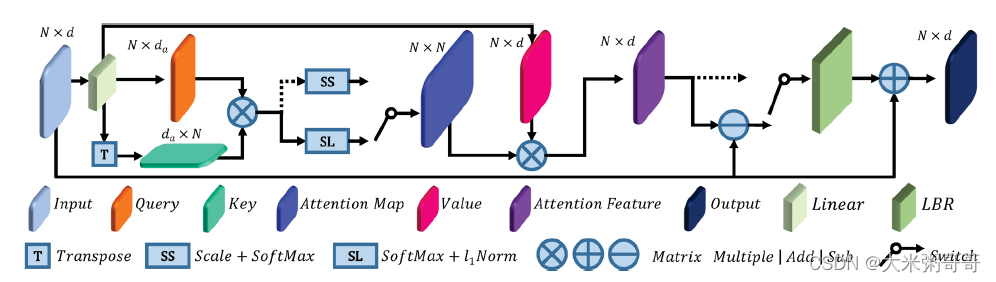
- 参考上图自注意力模块,
个人感觉图中应该有误. 从一个共享权重的Linear里出来了Q、K、VQ、K、VQ、K、V三个矩阵,但VVV的维度和Q、KQ、KQ、K不一致,少画了一个Linear?
class SA(nn.Module):def __init__(self, channels):super().__init__()self.q_conv = nn.Conv1d(channels, channels // 4, 1, bias=False)self.k_conv = nn.Conv1d(channels, channels // 4, 1, bias=False)self.q_conv.weight = self.k_conv.weightself.v_conv = nn.Conv1d(channels, channels, 1, bias=False)self.trans_conv = nn.Conv1d(channels, channels, 1)self.after_norm = nn.BatchNorm1d(channels)self.act = nn.GELU()self.softmax = nn.Softmax(dim=-1)def forward(self, x):x_q = self.q_conv(x).permute(0, 2, 1)x_k = self.k_conv(x)x_v = self.v_conv(x)energy = x_q @ x_kattention = self.softmax(energy)attention = attention / (1e-9 + attention.sum(dim=1, keepdims=True))x_r = x_v @ attentionx_r = self.act(self.after_norm(self.trans_conv(x - x_r)))x = x + x_rreturn xclass TriTransNet(nn.Module):def __init__(self, dim_in, classes_n=30):super().__init__()self.conv_fea = FaceConv(6, 128, 4)self.conv_pos = FaceConv(3, 128, 4)self.bn_fea = nn.BatchNorm1d(128)self.bn_pos = nn.BatchNorm1d(128)self.sa1 = SA(128)self.sa2 = SA(128)self.gp = nn.AdaptiveAvgPool1d(1)self.linear1 = nn.Linear(256, 128, bias=False)self.bn1 = nn.BatchNorm1d(128)self.linear2 = nn.Linear(128, classes_n)self.act = nn.GELU()def forward(self, x, mesh):x = x.permute(0, 2, 1).contiguous()# 位置编码 放到DataLoader中比较好pos = [m.xyz for m in mesh]pos = np.array(pos)pos = torch.from_numpy(pos).float().to(x.device).requires_grad_(True)batch_size, _, N = x.size()x = self.act(self.bn_fea(self.conv_fea(x, mesh).squeeze(-1)))pos = self.act(self.bn_pos(self.conv_pos(pos, mesh).squeeze(-1)))x1 = self.sa1(x + pos)x2 = self.sa2(x1 + pos)x = torch.cat((x1, x2), dim=1)x = self.gp(x)x = x.view(batch_size, -1)x = self.act(self.bn1(self.linear1(x)))x = self.linear2(x)return x
三、基于Transformer的网格分类
数据集是SHREC’11 可参考三角网格(Triangular Mesh)分类数据集 或 MeshCNN
3.1 分类结果
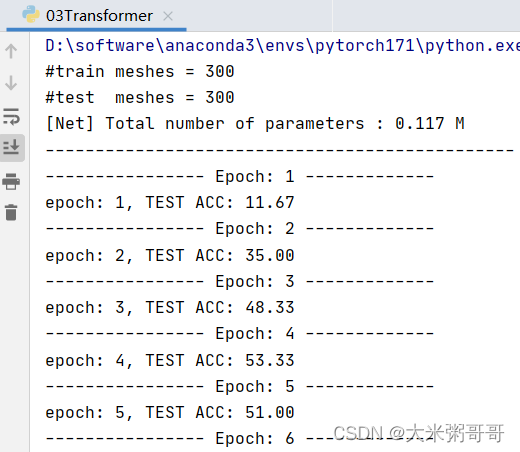
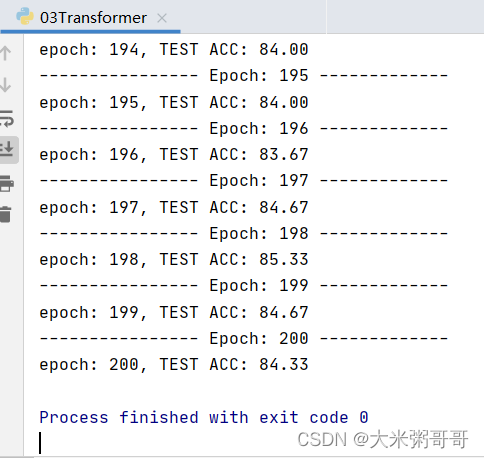
准确率太低… 可以尝试改进的点:
- 尝试不同的位置编码(
谱域特征),不同的位置嵌入方式 (sum可改为concat) 数据集较小的情况下Transformer略难收敛,加入更多CNN可加速且提升明显 (或者加入降采样)- 打印loss进行分析,是否
欠拟合,尝试增加网络参数?
基于Transformer的网络在网格分割上的表现会很好,仅用少量参数即可媲美甚至超过基于面卷积的分割结果,个人感觉得益于其近乎全局的感受野…
3.2 全部代码
DataLoader代码请参考2:从零开始网格上的深度学习-1:输入篇(Pytorch)
FaceConv代码请参考3:从零开始网格上的深度学习-2:卷积网络CNN篇
import torch
import torch.nn as nn
import numpy as np
from CNN import FaceConv
from DataLoader_shrec11 import DataLoader
from DataLoader_shrec11 import Meshclass SA(nn.Module):def __init__(self, channels):super().__init__()self.q_conv = nn.Conv1d(channels, channels // 4, 1, bias=False)self.k_conv = nn.Conv1d(channels, channels // 4, 1, bias=False)self.q_conv.weight = self.k_conv.weightself.v_conv = nn.Conv1d(channels, channels, 1, bias=False)self.trans_conv = nn.Conv1d(channels, channels, 1)self.after_norm = nn.BatchNorm1d(channels)self.act = nn.GELU()self.softmax = nn.Softmax(dim=-1)def forward(self, x):x_q = self.q_conv(x).permute(0, 2, 1)x_k = self.k_conv(x)x_v = self.v_conv(x)energy = x_q @ x_kattention = self.softmax(energy)attention = attention / (1e-9 + attention.sum(dim=1, keepdims=True))x_r = x_v @ attentionx_r = self.act(self.after_norm(self.trans_conv(x - x_r)))x = x + x_rreturn xclass TriTransNet(nn.Module):def __init__(self, dim_in, classes_n=30):super().__init__()self.conv_fea = FaceConv(6, 128, 4)self.conv_pos = FaceConv(3, 128, 4)self.bn_fea = nn.BatchNorm1d(128)self.bn_pos = nn.BatchNorm1d(128)self.sa1 = SA(128)self.sa2 = SA(128)self.gp = nn.AdaptiveAvgPool1d(1)self.linear1 = nn.Linear(256, 128, bias=False)self.bn1 = nn.BatchNorm1d(128)self.linear2 = nn.Linear(128, classes_n)self.act = nn.GELU()def forward(self, x, mesh):x = x.permute(0, 2, 1).contiguous()# 位置编码 放到DataLoader中比较好pos = [m.xyz for m in mesh]pos = np.array(pos)pos = torch.from_numpy(pos).float().to(x.device).requires_grad_(True)batch_size, _, N = x.size()x = self.act(self.bn_fea(self.conv_fea(x, mesh).squeeze(-1)))pos = self.act(self.bn_pos(self.conv_pos(pos, mesh).squeeze(-1)))x1 = self.sa1(x + pos)x2 = self.sa2(x1 + pos)x = torch.cat((x1, x2), dim=1)x = self.gp(x)x = x.view(batch_size, -1)x = self.act(self.bn1(self.linear1(x)))x = self.linear2(x)return xif __name__ == '__main__':# 输入data_train = DataLoader(phase='train') # 训练集data_test = DataLoader(phase='test') # 测试集print('#train meshes = %d' % len(data_train)) # 输出训练模型个数print('#test meshes = %d' % len(data_test)) # 输出测试模型个数# 网络net = TriTransNet(data_train.input_n, data_train.class_n) # 创建网络 以及 优化器optimizer = torch.optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999))net = net.cuda(0)loss_fun = torch.nn.CrossEntropyLoss(ignore_index=-1)num_params = 0for param in net.parameters():num_params += param.numel()print('[Net] Total number of parameters : %.3f M' % (num_params / 1e6))print('-----------------------------------------------')# 迭代训练for epoch in range(1, 201):print('---------------- Epoch: %d -------------' % epoch)for i, data in enumerate(data_train):# 前向传播net.train(True) # 训练模式optimizer.zero_grad() # 梯度清零face_features = torch.from_numpy(data['face_features']).float()face_features = face_features.to(data_train.device).requires_grad_(True)labels = torch.from_numpy(data['label']).long().to(data_train.device)out = net(face_features, data['mesh']) # 输入到网络# 反向传播loss = loss_fun(out, labels)loss.backward()optimizer.step() # 参数更新# 测试net.eval()acc = 0for i, data in enumerate(data_test):with torch.no_grad():# 前向传播face_features = torch.from_numpy(data['face_features']).float()face_features = face_features.to(data_test.device).requires_grad_(False)labels = torch.from_numpy(data['label']).long().to(data_test.device)out = net(face_features, data['mesh'])# 计算准确率pred_class = out.data.max(1)[1]correct = pred_class.eq(labels).sum().float()acc += correctacc = acc / len(data_test)print('epoch: %d, TEST ACC: %0.2f' % (epoch, acc * 100))PCT:Point cloud transformer ↩︎
从零开始网格上的深度学习-1:输入篇(Pytorch) ↩︎
从零开始网格上的深度学习-2:卷积网络CNN篇 ↩︎
相关文章:
【三维几何学习】从零开始网格上的深度学习-3:Transformer篇(Pytorch)
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 从零开始网格上的深度学习-3:Transformer篇引言一、概述二、核心代码2.1 位置编码2.2 网络框架三、基于Transformer的网格分类3.1 分类结果3.2 全部代码引言 本文主要内容如下&#…...
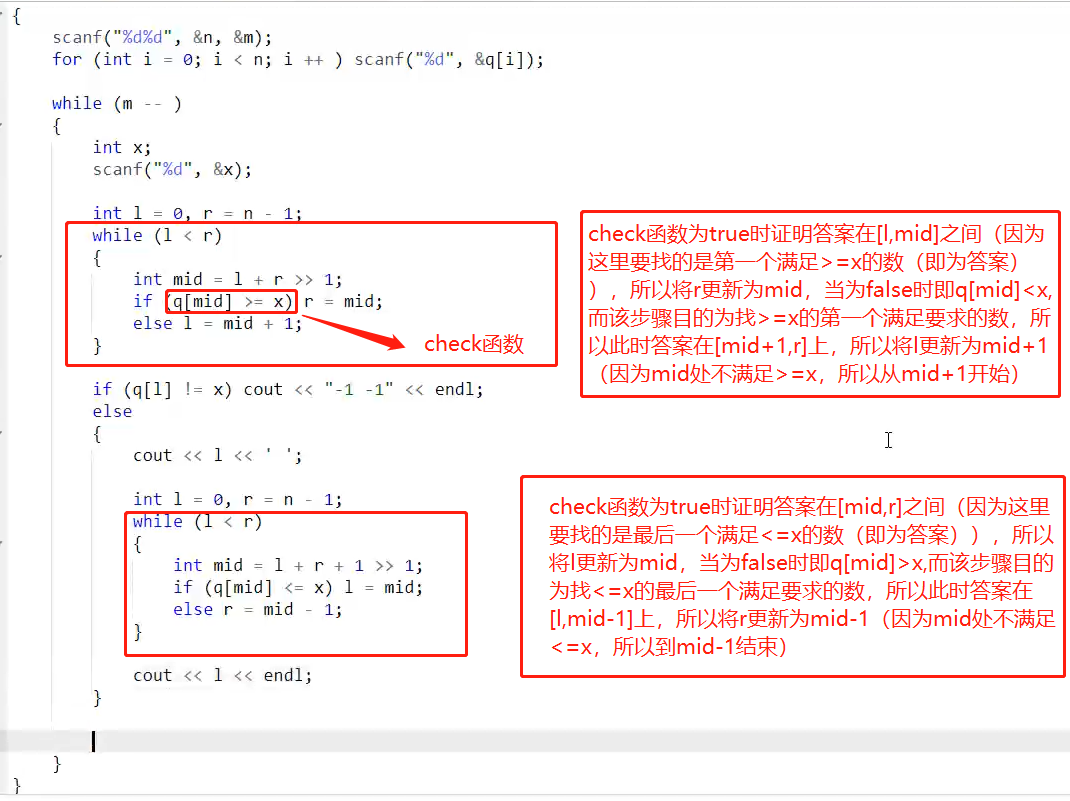
一、基础算法3:二分 模板题+算法模板(数的范围,数的三次方根)
文章目录算法模板整数二分算法模板浮点数二分算法模板模板题数的范围原题链接题目题解数的三次方根原题链接题目题解算法模板 整数二分算法模板 bool check(int x) {/* ... */} // 检查x是否满足某种性质// 区间[l, r]被划分成[l, mid]和[mid 1, r]时使用: int b…...
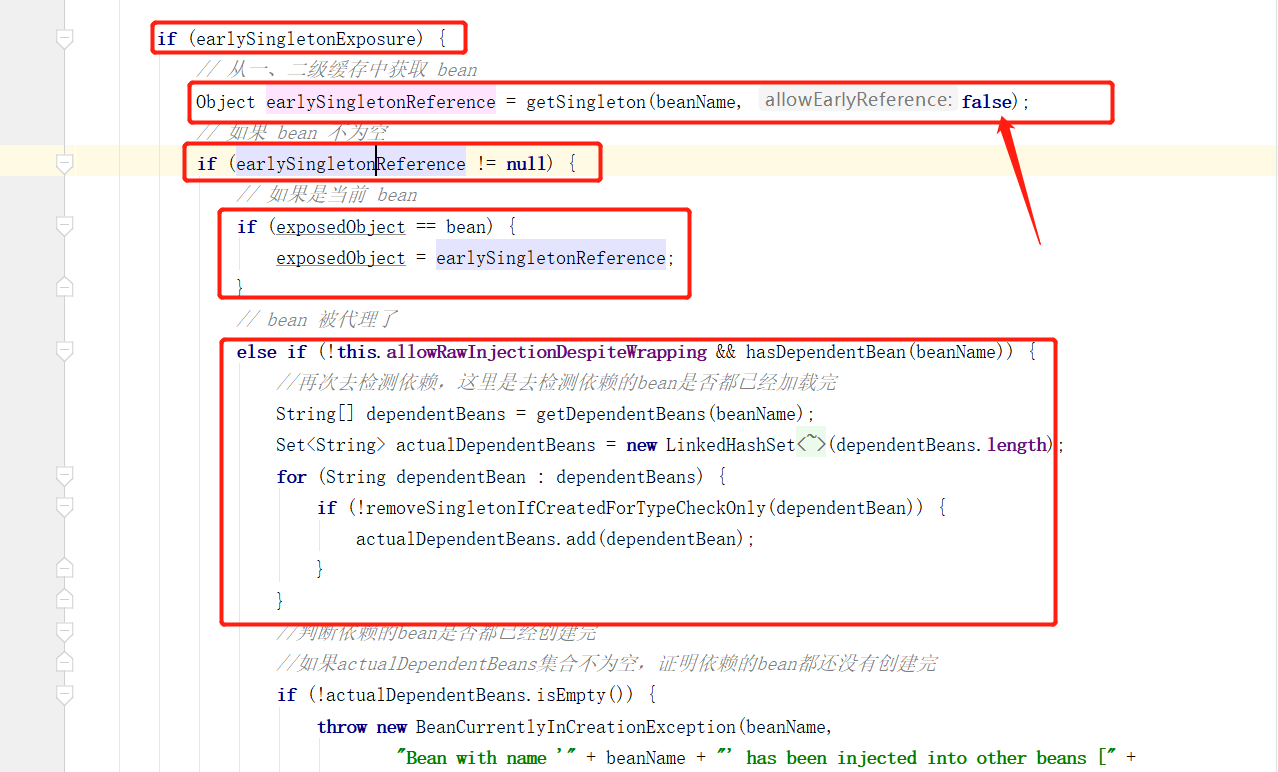
Spring 源码解析 - Bean创建过程 以及 解决循环依赖
一、Spring Bean创建过程以及循环依赖 上篇文章对 Spring Bean资源的加载注册过程进行了源码梳理和解析,我们可以得到结论,资源文件中的 bean 定义信息,被组装成了 BeanDefinition 存放进了 beanDefinitionMap 容器中,那 Bean 是…...
)
移除元素(双指针)
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的…...
76.qt qml-QianWindow开源炫酷界面框架(支持白色暗黑渐变自定义控件均以适配)
界面介绍界面支持: 透明 白色 黑色 渐变 单色 静态图 动态图侧边栏支持:抽屉、带折叠、多模式场景控件已集成: 暗黑风格 高亮风格、并附带个人自定义控件及开源demo白色场景如下所示:单色暗黑风格如下所示:用户自定义皮肤如下所示:皮肤预览如下所示:b站入口:https://www.bilibi…...

Python生日蛋糕
目录 前言 底盘 蛋糕 蜡烛 祝福 前言 Hello,小伙伴们晚上好吖!前两天博主满20岁啦(要开始奔三辽呜呜呜),这几天收到了不少小伙伴们的祝福,浪漫的小博主想送给大家一份不一样的生日蛋糕,…...

QT 如何提高 Qt Creator 的编译速度
如何提高编译速度,貌似是一个老生常谈的话题。对于Qter而言,如何提高QT Creator 的编辑速度是一直都是大家所期盼的。本文也是查阅了各路大神的方法后整理出来的,希望对各位有所帮助。 1、在*.pro文件添加预编译机制 QT官方给出的示例&…...

STM32之震动传感器、继电器介绍及实战
目录 一、震动传感器介绍及实战 二、编程代码实现 1、gpio.c---------初始化GPIO口引脚函数 2、调用中断服务函数 3、中断服务函数 4、中断服务回调函数 5、把上述的中断服务回调函数,放入main主函数里 6、结果演示 三、继电器介绍及实战 一、震动传感器介…...

RK3588平台开发系列讲解(显示篇)RK3588 平台 的DP介绍
平台内核版本安卓版本RK3588Linux 5.10Android 12文章目录 一、功能特性二、 DP 输⼊三、DP 输出四、 代码路径沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇将介绍 RK3588 平台 DP 的使⽤与调试⽅法。 一、功能特性 RK3588 的 DP ⽀持 1.4a 版本的 DP 协议,最…...

【Java】i++和++i的实现原理
文章目录 i++案例反编译分析扩展 x = x++我们接下来从字节码层面分析: 不了解字节码的可以参考这篇:【精通JVM】字节码指令全解 i++案例 package org.example;public class Main {public static void main...
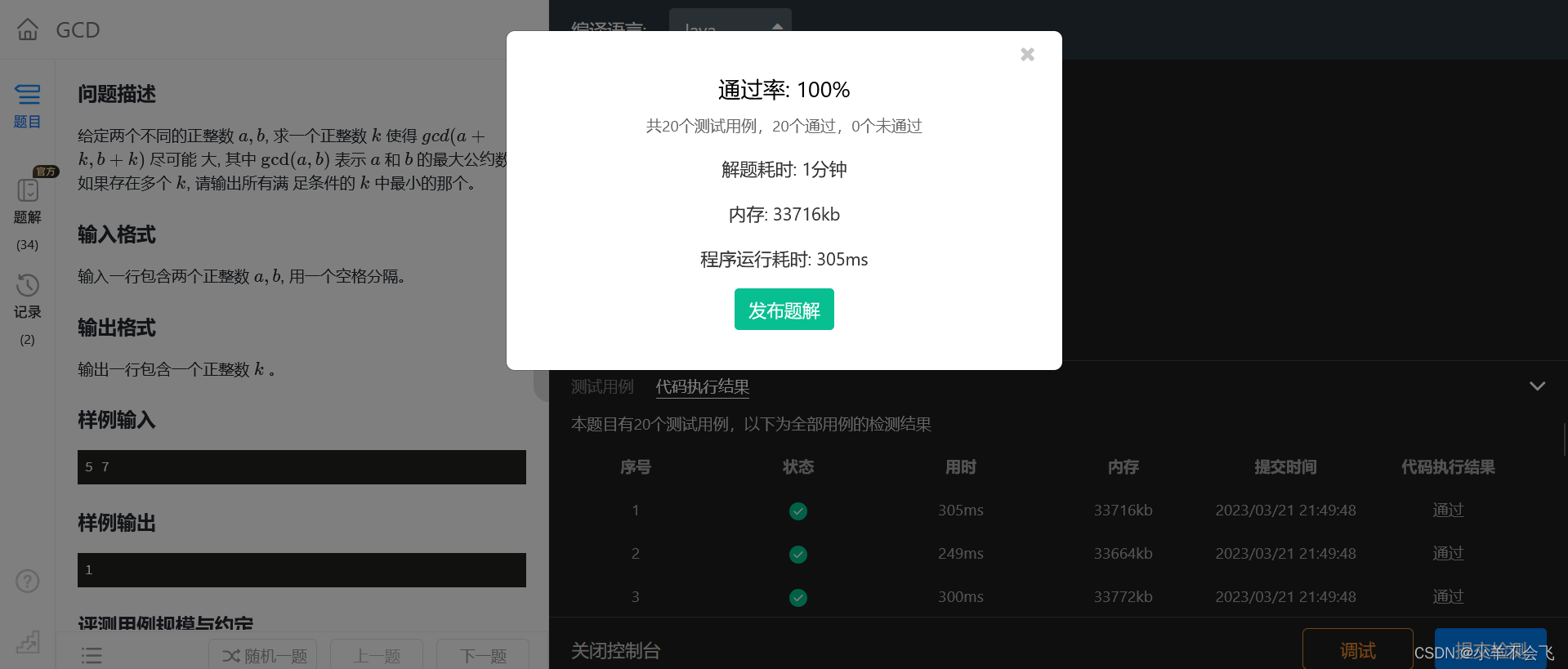
第十四届蓝桥杯三月真题刷题训练——第 18 天
目录 第 1 题:排列字母 问题描述 运行限制 代码: 第 2 题:GCD_数论 问题描述 输入格式 输出格式 样例输入 样例输出 评测用例规模与约定 运行限制 第 3 题:选数异或 第 4 题:背包与魔法 第 1 题&#x…...

软件测试拿了几个20K offer,分享一波面经
1、你的测试职业发展是什么? 测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师奔去。而且我也有初步的职业规划,前3年积累测试经验,按如何做好测试工程师的要点去要求自己,不断…...
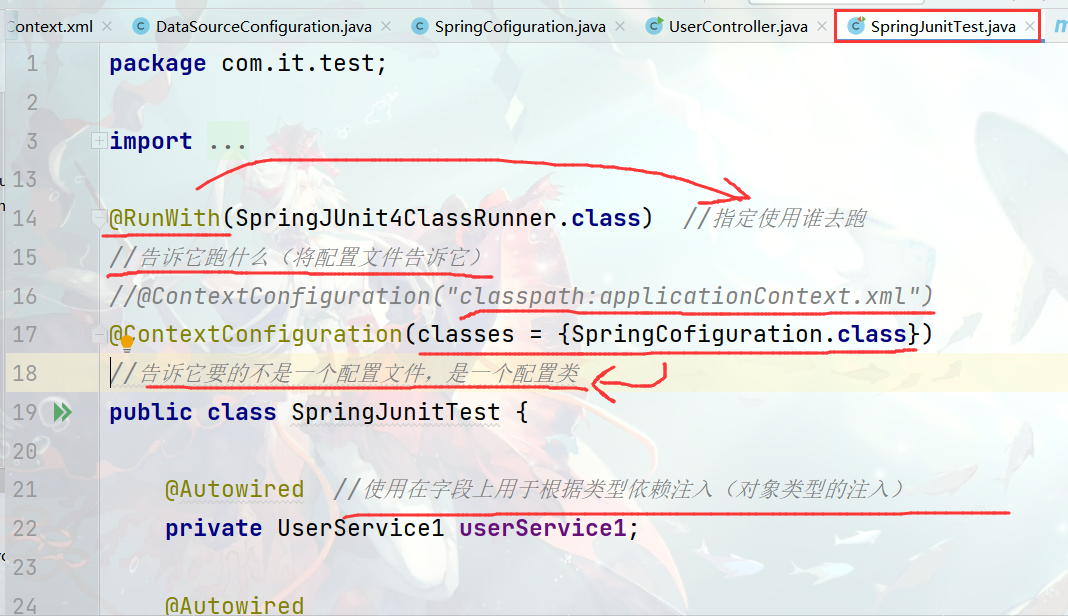
spring2
1.Spring配置数据源1.1 数据源(连接池)的作用 数据源(连接池)是提高程序性能如出现的事先实例化数据源,初始化部分连接资源使用连接资源时从数据源中获取使用完毕后将连接资源归还给数据源常见的数据源(连接池):DBCP、C3P0、BoneC…...

【Linux】网络编程套接字(中)
🎇Linux: 博客主页:一起去看日落吗分享博主的在Linux中学习到的知识和遇到的问题博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持…...
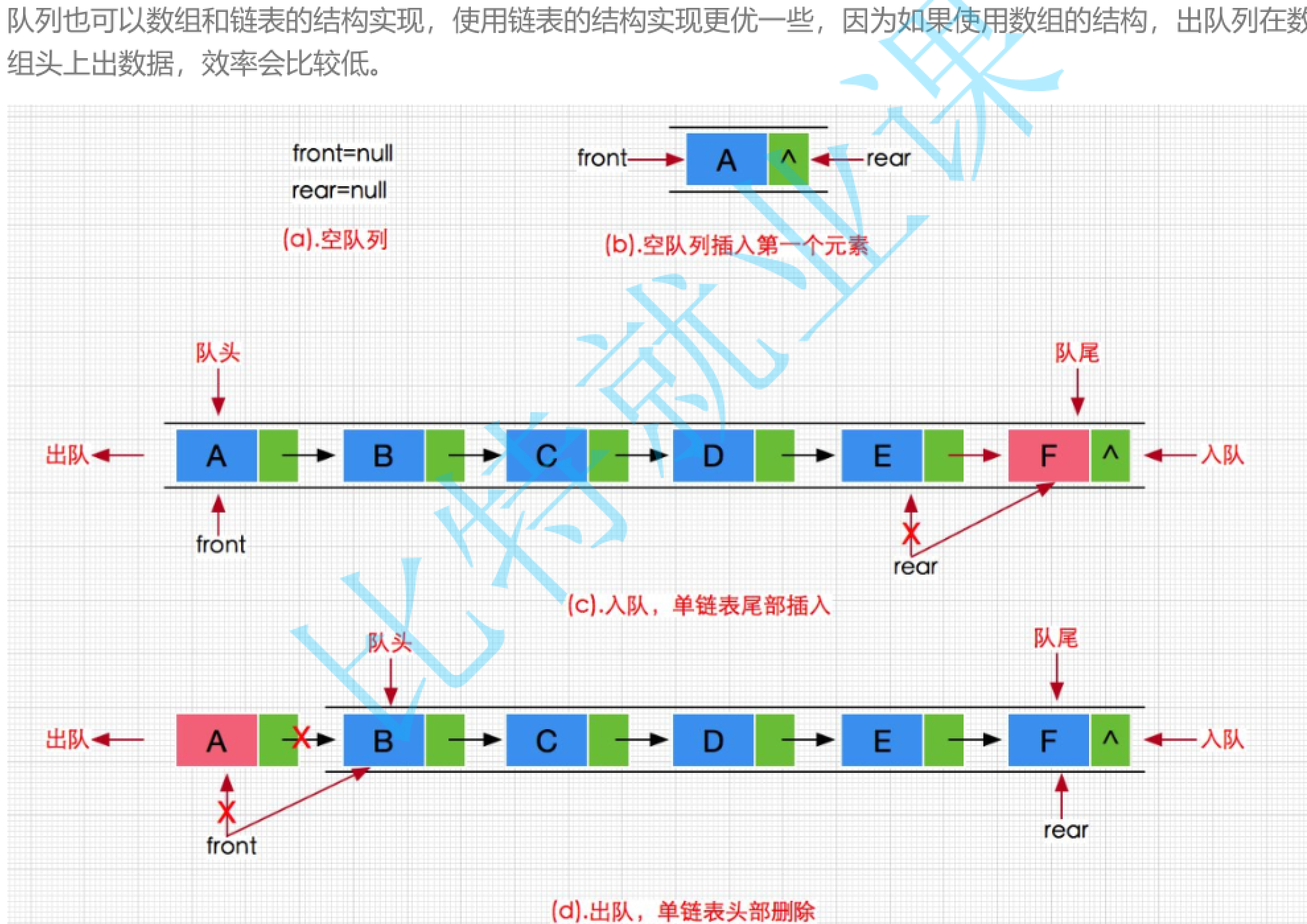
手撕数据结构—队列
队列队列的话只允许在一端插入,在另外一端删除。插入数据的那一段叫做队尾,出数据的那一段叫做队头(从尾巴插入)。因此的话队列是先进先出的。入的顺序与出的顺序的话是一样的。这个与栈是不一样的,因为栈的话就是说如…...
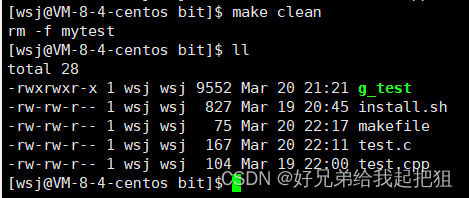
gdb调试工具和makemakefile工具
gdb调试工具和make/makefile工具 文章目录gdb调试工具和make/makefile工具一、gdb调试工具1.debug/release2.使用二、make/makefile1.什么是make/makefile2.编写一、gdb调试工具 1.debug/release 程序有两种默认的发布方式debug和release。release是无法进行调试的。Linux中g…...
【进阶数据结构】平衡搜索二叉树 —— AVL树
🌈感谢阅读East-sunrise学习分享——[进阶数据结构]AVL树 博主水平有限,如有差错,欢迎斧正🙏感谢有你 码字不易,若有收获,期待你的点赞关注💙我们一起进步🚀 🌈我们上一篇…...
action学习)
ROS使用(5)action学习
action消息的构建 首先进行功能包的创建 mkdir -p ros2_ws/src cd ros2_ws/src ros2 pkg create action_tutorials_interfaces action消息的类型 # Request --- # Result --- # Feedback 动作定义由三个消息定义组成,以---分隔。 从动作客户机向动作服务器发送…...
之HTML+CSS篇(一))
2023前端面试题集(含答案)之HTML+CSS篇(一)
在又到了金三银四的招聘季,不管你是刚入行的小白,亦或是混迹职场的老鸟,还在为面试前端工程师时不知道面试官要问什么怎么回答而苦恼吗?为了帮助你获得面试官的青睐,顺利通过面试,跳槽进入大厂,…...

设计模式2 - 观察者模式
定义: 观察者模式又叫发布订阅模式,它定义了对象之间的一对多依赖,这样一来,当一个对象改变状态时,它的所有依赖者都会收到通知并自动更新。 组成: Subject(通知者/被观察者)&#…...

电视盒子视频播放难题如何破解?TVBoxOSC带来流畅观影体验
电视盒子视频播放难题如何破解?TVBoxOSC带来流畅观影体验 【免费下载链接】TVBoxOSC TVBoxOSC - 一个基于第三方项目的代码库,用于电视盒子的控制和管理。 项目地址: https://gitcode.com/GitHub_Trending/tv/TVBoxOSC 客厅里的电视盒子本应是家庭…...

Java中使用四叶天动态代理IP构建代理池——HttpClient与Jsoup爬虫实战
本文档详细介绍如何使用四叶天动态代理IP服务,在Java中构建高效的IP代理池,并结合HttpClient和Jsoup实现高可用的网络爬虫。1. 为什么需要动态代理IP池?1.1 爬虫被封的痛点做过爬虫开发的都知道,同一个IP频繁请求目标网站…...

5分钟搞定电脑风扇噪音!FanControl超详细配置指南让你告别“飞机起飞“
5分钟搞定电脑风扇噪音!FanControl超详细配置指南让你告别"飞机起飞" 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcod…...
)
YOLOv8特征可视化实战:如何用一行代码查看模型内部特征图(附完整代码)
YOLOv8特征可视化实战:如何用一行代码查看模型内部特征图(附完整代码) 在计算机视觉领域,YOLO系列模型因其卓越的实时检测性能而广受欢迎。但对于开发者而言,仅仅使用模型进行预测往往不够——理解模型内部如何"思…...
)
从零开始理解反步控制:用李雅普诺夫函数一步步‘后退’设计控制器(附Simulink仿真模型)
非线性控制实战:用反步法构建稳定系统的可视化指南 在控制理论中,非线性系统总是以其复杂的动态特性让工程师们又爱又恨。传统的线性控制方法往往难以应对这种复杂性,而反步控制(Backstepping Control)作为一种系统化的…...

抖音下载器技术深度解析:构建高效无水印视频批量采集系统
抖音下载器技术深度解析:构建高效无水印视频批量采集系统 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

基于三菱PLC农田灌溉及MCGS组态智能灌溉系统说明双万字
基于三菱PLC农田灌溉 包含说明一万 和MCGS组态农田智能灌溉系统说明一万前阵子回豫东老家帮我叔打理那三亩秋月梨果园,那浇地给我整得怀疑人生——三伏天顶着三十七八度的太阳,扛着铁锹跑遍地头开电磁阀,中午热得头晕就算了,晚上还…...
从ThreadLocal到TransmittableThreadLocal:手把手解决线程池上下文传递难题
从ThreadLocal到TransmittableThreadLocal:线程池上下文传递的终极解决方案 在分布式系统和微服务架构盛行的今天,异步编程已成为Java开发者日常工作中不可或缺的一部分。无论是处理高并发请求、优化系统性能,还是实现复杂的业务流程…...

input-overlay多语言支持:如何为全球观众轻松定制直播输入显示
input-overlay多语言支持:如何为全球观众轻松定制直播输入显示 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay 想要让全球观众都能轻松理解你的游戏操作吗&a…...

usearch的API测试数据生成:使用Faker创建模拟数据
usearch的API测试数据生成:使用Faker创建模拟数据 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolf…...