人工智能自动驾驶三维车道线检测—PersFormer模型代码详解
文章目录
- 1. 背景介绍
- 2. 数据加载和预处理
- 3. 模型结构
- 4. Loss计算
- 5. 总结和讨论
1. 背景介绍
梳理了PersFormer 3D Lane这篇论文对应的开源代码。
2. 数据加载和预处理
数据组织方式参考:自动驾驶三维车道线检测系列—OpenLane数据集介绍。
坐标系参考:Waymo(OpenLane)的相机坐标系定义为:X轴向前,Y轴向左,Z轴向上。
所以,目前数据集中extrinsic如下所示:
"extrinsic": [[0.9999790376291948,0.0045643569339703614,-0.004592488211072773,1.5393679168564702],[-0.004561049760530192,0.9999893316554864,0.0007303425877435168,-0.023691101834458727],[0.004595772761080904,-0.0007093807107760264,0.9999891877674156,2.116014704116658],[0.0,0.0,0.0,1.0]]
表示相机与车体坐标系之间的外参。证明当前相机坐标系与车体坐标系基本一样,只不过坐标系原点不同。
真值中三维车道线坐标如下:
"xyz": [[17.382800978819017,17.50040078037587,...20.274071148194103,20.38195255123586,20.48338473286711,...21.931553979558124,22.035070660270055,22.225836627658275,...26.61997710857102,26.79194824101369,26.900410829029237,27.120094997627227,27.373557832034134,27.544735503944892,27.76517221715751,...34.04364108074635,34.34183952795403,34.44990326517201,34.64902798842567,34.80330435386684,34.97738513466869,35.10772807701519,35.21127993338897,...43.26603227123105,43.394400283321744,43.54402499844422],[2.106162267265404,2.117356716888622,2.1267196912979487,2.134409778081357,...2.0836507579014345,2.083507611187606,2.0835073709153624,2.0840386385354006,2.084208834336426,2.0839706956475896,...2.041385347080901,2.0409709291451565,2.040427413456658,2.039615358123066,...2.0134828598759036,2.0115237025717696,2.008972154232112],[-2.3179790375385325,-2.3071957428128735,...-2.6387563474505975,-2.6083380476462663,-2.615133499516616,-2.6078418903876996,...-2.8227286818859705,-2.7188114534133323,-2.7218183933456475,-2.7215278064851747,...-2.8628242116626312,-2.8972871689102906,-2.9289600110699885]],
可以看出三维车道线真值的坐标系是在Camera坐标系之下的表示,也就是Z值在相机坐标系的地面处。
- 初始化
- 超参数设定
- H_crop计算
- H_ipm2g计算
- H_g2ipm计算
- Anchor grid计算
- Anchor dim计算
- 初始化OpenLane数据集
- 输入:数据集文件夹
- 输出:X, Y和Z的offset以及image anchors
- 算法内容:
- 获取所有的.json文件,即真值文件
- 调整外参,从Waymo车体坐标系变换到ground坐标系。此处重点解释下,Waymo相机坐标系的定义与正常相机坐标系定义不一样,Waymo是X轴朝前,Y轴朝左,Z轴向上。此时,车体坐标系也是如此定义的。所以,数据集中默认的外参旋转近似单位阵。而坐标系的原点不一样而已。而ground坐标系的定义是Y轴朝前,X轴朝右,Z轴向上。此外,三维车道线结果是在Waymo相机坐标系下的。
- 将三维车道线坐标从相机坐标系变换到ground坐标系
- 将三维车道线坐标从ground坐标系变换到flat ground坐标系下
- 计算offset作为预测回归的结果
- 模型构建
- 模型训练
- 数据加载
- 看起来模型训练数据加载时又做了很多上述数据初始化很多一样的步骤
- 加载图像数据,根据resize参数调整图像尺寸
- 对图像进行归一化处理
- 数据增强,图像旋转以及Anchor旋转
- 计算segmentation所需要的label,直接利用车道线三维真值投影回图像得到segmentation的label
- 在IPM上绘制三维车道线真值数据,得到Seg Bev数据,用于后续模型训练
最终,数据处理这层为下游提供的数据包含如下:
- 图像归一化后的数据
- Segmentation label
- Ground-truth lane (anchor)
- Ground-truth lane 2D
- Camera height
- Camera pitch
- 内参
- 外参(ground to camera)
- 数据增强矩阵
- Segmentation Bev map
3. 模型结构
模型整体框图如下图所示:

- Encoder
- Backbone选用ResNet,输出特征list,out_featList
- Neck选用一系列的二维卷积、BN和ReLU,输出特征list,neck_out
- ShareEncoder,FrontViewPathway,输出frontview_features
- 取frontview_features的最后一层特征,frontview_final_feat,执行Lane 2D的Attention,输出laneatt_proposals_list
- PerspectiveTransformer,输入包括原图、frontview_features和变换矩阵M
- 获取BEV中的2D网格
- 将BEV网格利用M矩阵,投影到IPM
- Transformer encoder: Self-attn -> norm -> cross-attn -> norm -> ffn -> norm
- Query是query_embed,BEV视角
- Value是frontview_features
- Bev 2D grid
- IPM 2D grid
- 首先BEV得self-attention
- 之后是BEV与IPM和frontview_features的cross attention
- 最后norm等操作输出feature
- 输出特征,projs
- Bev Head
- 输入:特征projs
- 输出:特征bev_feature
- 算法内容:
- SingleTopViewPathway
- SingleTopViewPathway
- 经过一系列卷积操作
- LanePredictionHead
- 输入:特征bev_feature
- 输出:处理后的特征bev_feature
- 算法内容:
- 一系列卷积操作
- 将张量 x 中特定的维度范围应用 Sigmoid 函数,以便将这些值的值域从任意实数映射到 (0, 1) 区间内。这通常用于处理模型输出中的可见性或置信度分数,使得这些分数可以被解释为概率。
- 模型最后输出:Laneatt_proposals_list, out, cam_height, cam_pitch, pred_seg_bev_map, uncertainty_loss
4. Loss计算
函数调用:
# 3D loss
loss_3d, loss_3d_dict = criterion(output_net, gt, pred_hcam, gt_hcam, pred_pitch, gt_pitch)
# Add lane attion loss
loss_att, loss_att_dict = model.module.laneatt_head.loss(laneatt_proposals_list, gt_laneline_img,cls_loss_weight=args.cls_loss_weight,reg_vis_loss_weight=args.reg_vis_loss_weight)loss_seg = bceloss(pred_seg_bev_map, seg_bev_map)
# overall loss
loss = self.compute_loss(args, epoch, loss_3d, loss_att, loss_seg, uncertainty_loss, loss_3d_dict, loss_att_dict)
- 3D loss
class Laneline_loss_gflat_3D(nn.Module):"""Compute the loss between predicted lanelines and ground-truth laneline in anchor representation.The anchor representation is in flat ground space X', Y' and real 3D Z. Visibility estimation is also included.The X' Y' and Z estimation will be transformed to real X, Y to compare with ground truth. An additional loss inX, Y space is expected to guide the learning of features to satisfy the geometry constraints between two spacesloss = loss0 + loss1 + loss2 + loss2loss0: cross entropy loss for lane point visibilityloss1: cross entropy loss for lane type classificationloss2: sum of geometric distance betwen 3D lane anchor points in X and Z offsetsloss3: error in estimating pitch and camera heights"""def __init__(self, batch_size, num_types, anchor_x_steps, anchor_y_steps, x_off_std, y_off_std, z_std, pred_cam=False, no_cuda=False):super(Laneline_loss_gflat_3D, self).__init__()self.batch_size = batch_sizeself.num_types = num_typesself.num_x_steps = anchor_x_steps.shape[0]self.num_y_steps = anchor_y_steps.shape[0]self.anchor_dim = 3*self.num_y_steps + 1self.pred_cam = pred_cam# prepare broadcast anchor_x_tensor, anchor_y_tensor, std_X, std_Y, std_Ztmp_zeros = torch.zeros(self.batch_size, self.num_x_steps, self.num_types, self.num_y_steps)self.x_off_std = torch.tensor(x_off_std.astype(np.float32)).reshape(1, 1, 1, self.num_y_steps) + tmp_zerosself.y_off_std = torch.tensor(y_off_std.astype(np.float32)).reshape(1, 1, 1, self.num_y_steps) + tmp_zerosself.z_std = torch.tensor(z_std.astype(np.float32)).reshape(1, 1, 1, self.num_y_steps) + tmp_zerosself.anchor_x_tensor = torch.tensor(anchor_x_steps.astype(np.float32)).reshape(1, self.num_x_steps, 1, 1) + tmp_zerosself.anchor_y_tensor = torch.tensor(anchor_y_steps.astype(np.float32)).reshape(1, 1, 1, self.num_y_steps) + tmp_zerosself.anchor_x_tensor = self.anchor_x_tensor/self.x_off_stdself.anchor_y_tensor = self.anchor_y_tensor/self.y_off_stdif not no_cuda:self.z_std = self.z_std.cuda()self.anchor_x_tensor = self.anchor_x_tensor.cuda()self.anchor_y_tensor = self.anchor_y_tensor.cuda()def forward(self, pred_3D_lanes, gt_3D_lanes, pred_hcam, gt_hcam, pred_pitch, gt_pitch):""":param pred_3D_lanes: predicted tensor with size N x (ipm_w/8) x 3*(2*K+1):param gt_3D_lanes: ground-truth tensor with size N x (ipm_w/8) x 3*(2*K+1):param pred_pitch: predicted pitch with size N:param gt_pitch: ground-truth pitch with size N:param pred_hcam: predicted camera height with size N:param gt_hcam: ground-truth camera height with size N:return:"""sizes = pred_3D_lanes.shape# reshape to N x ipm_w/8 x 3 x (3K+1)pred_3D_lanes = pred_3D_lanes.reshape(sizes[0], sizes[1], self.num_types, self.anchor_dim)gt_3D_lanes = gt_3D_lanes.reshape(sizes[0], sizes[1], self.num_types, self.anchor_dim)# class prob N x ipm_w/8 x 3 x 1, anchor values N x ipm_w/8 x 3 x 2K, visibility N x ipm_w/8 x 3 x Kpred_class = pred_3D_lanes[:, :, :, -1].unsqueeze(-1)pred_anchors = pred_3D_lanes[:, :, :, :2*self.num_y_steps]pred_visibility = pred_3D_lanes[:, :, :, 2*self.num_y_steps:3*self.num_y_steps]gt_class = gt_3D_lanes[:, :, :, -1].unsqueeze(-1)gt_anchors = gt_3D_lanes[:, :, :, :2*self.num_y_steps]gt_visibility = gt_3D_lanes[:, :, :, 2*self.num_y_steps:3*self.num_y_steps]# cross-entropy loss for visibilityloss0 = -torch.sum(gt_visibility*torch.log(pred_visibility + torch.tensor(1e-9)) +(torch.ones_like(gt_visibility) - gt_visibility + torch.tensor(1e-9)) *torch.log(torch.ones_like(pred_visibility) - pred_visibility + torch.tensor(1e-9)))/self.num_y_steps# cross-entropy loss for lane probabilityloss1 = -torch.sum(gt_class*torch.log(pred_class + torch.tensor(1e-9)) +(torch.ones_like(gt_class) - gt_class) *torch.log(torch.ones_like(pred_class) - pred_class + torch.tensor(1e-9)))# applying L1 norm does not need to separate X and Zloss2 = torch.sum(torch.norm(gt_class*torch.cat((gt_visibility, gt_visibility), 3)*(pred_anchors-gt_anchors), p=1, dim=3))# compute loss in real 3D X, Y space, the transformation considers offset to anchor and normalization by stdpred_Xoff_g = pred_anchors[:, :, :, :self.num_y_steps]pred_Z = pred_anchors[:, :, :, self.num_y_steps:2*self.num_y_steps]gt_Xoff_g = gt_anchors[:, :, :, :self.num_y_steps]gt_Z = gt_anchors[:, :, :, self.num_y_steps:2*self.num_y_steps]pred_hcam = pred_hcam.reshape(self.batch_size, 1, 1, 1)gt_hcam = gt_hcam.reshape(self.batch_size, 1, 1, 1)pred_Xoff = (1 - pred_Z * self.z_std / pred_hcam) * pred_Xoff_g - pred_Z * self.z_std / pred_hcam * self.anchor_x_tensorpred_Yoff = -pred_Z * self.z_std / pred_hcam * self.anchor_y_tensorgt_Xoff = (1 - gt_Z * self.z_std / gt_hcam) * gt_Xoff_g - gt_Z * self.z_std / gt_hcam * self.anchor_x_tensorgt_Yoff = -gt_Z * self.z_std / gt_hcam * self.anchor_y_tensorloss3 = torch.sum(torch.norm(gt_class * torch.cat((gt_visibility, gt_visibility), 3) *(torch.cat((pred_Xoff, pred_Yoff), 3) - torch.cat((gt_Xoff, gt_Yoff), 3)), p=1, dim=3))if not self.pred_cam:return loss0+loss1+loss2+loss3loss4 = torch.sum(torch.abs(gt_pitch-pred_pitch)) + torch.sum(torch.abs(gt_hcam-pred_hcam))return loss0+loss1+loss2+loss3+loss4
- 函数说明
- 输入:预测的3D结果pred_3D_lanes,真值gt_3D_lanes,预测的Camera高度pred_hcam,真值Camera高度gt_hcam,预测的pitch pred_pitch和真值的pitch gt_pitch
- 输出:3D loss
- 算法内容
- 计算visibility的loss
- 计算lane probability的loss
- 计算offset的3D loss
- 计算pitch loss
5. 总结和讨论
梳理了PersFormer 3D Lane这篇论文对应的开源代码。

相关文章:
人工智能自动驾驶三维车道线检测—PersFormer模型代码详解
文章目录 1. 背景介绍2. 数据加载和预处理3. 模型结构4. Loss计算5. 总结和讨论 1. 背景介绍 梳理了PersFormer 3D Lane这篇论文对应的开源代码。 2. 数据加载和预处理 数据组织方式参考:自动驾驶三维车道线检测系列—OpenLane数据集介绍。 坐标系参考ÿ…...

LangChain +Streamlit+ Llama :将对话式人工智能引入您的本地设备成为可能(上篇)
🦜️ LangChain Streamlit🔥 Llama 🦙:将对话式人工智能引入您的本地设备🤯 将开源LLMs和LangChain集成以进行免费生成式问答(不需要API密钥) 在过去的几个月中,大型语言模型(LLMs)得…...

sql注入部分总结和复现
一个端口对应一个服务 联合查询注入 所有的程序中,单双引号必须成对出现 需要从这个引号里面逃出来 在后面查询内容 ?id1 要查库名,表名,列名。但是联合查询要知道有多少列,所以通过order by 去查询 order by # 通过二分法…...
开源企业级后台管理的快速启动引擎:Ballcat
Ballcat:快速搭建,高效管理,Ballcat让企业后台开发更简单。 - 精选真开源,释放新价值。 概览 Ballcat,一个专为企业级后台管理而设计的快速开发框架,以其高效的开发模式和全面的安全特性,为开发…...

FashionAI比赛-服饰属性标签识别比赛赛后总结(来自 Top14 Team)
关联比赛: FashionAI全球挑战赛—服饰属性标签识别 推荐大家看本篇博客之前,看一下数据集制作的方法,如何做一个实用的图像数据集 PS:我是参加完比赛之后才看的,看完之后,万马奔腾.....,因为发现比赛中还…...

C语言 | Leetcode C语言题解之第319题灯泡开关
题目: 题解: int bulbSwitch(int n) {return sqrt(n 0.5); }...

【第十届泰迪杯数据挖掘挑战赛A题害虫识别】-农田害虫检测识别-高精度完整更新
农田害虫检测识别项目-高精度完整版 一、说明: 该版本为基于泰迪杯完整害虫数据重新制作数据集、优化增强数据集、重新进行模型训练,达到高精度、高召回率的最优模型代码。包含论文、最优模型文件以及相关文件、原始数据集、训练数据集XML版、增强扩充…...

【Linux】—— Linux进程状态(R、S、D、T、Z、X)
🌏博客主页:PH_modest的博客主页 🚩当前专栏:Linux跬步积累 💌其他专栏: 🔴 每日一题 🟡 C跬步积累 🟢 C语言跬步积累 🌈座右铭:广积粮࿰…...

重生之我在NestJS中使用EventStream
有一个需求是需要长连接等待后台的返回,我们使用的EventStream,在NestJS中使用很简单,框架基本上已经封装好了 0. 如果没有创建项目的,可以先创建一个项目,创建项目的直接跳转到下一个步骤去 全局安装 nest: npm inst…...

自动化工具Selenium IDE基本使用——脚本录制
1 简介 Selenium相信大家都知道,在做自动化操作时,要使用浏览器驱动直接控制浏览器操作的时候,大多会结合Selenium框架使用。 但在对网页操作自动化的时候,实际上有一种更轻量的做法,那就是直接使用Selenium IDE&…...

【第十一天】进程调度算法,进程间通信方式,进程同步和互斥
进程调度算法有哪些 进程调度算法是操作系统中用来管理和调度进程(任务,作业)执行的方法。这些方法决定了在多任务环境下,如何为各个进程分配CPU时间,以实现公平性、高吞吐量、低延迟等目标。 先到先服务调度算法&am…...

Python的lambda函数
Python中的lambda函数是一种小型匿名函数,它允许你在需要函数对象的地方快速定义单行的小函数。lambda函数通常用于编写简洁的代码,尤其是当使用高阶函数(如map()、filter()、reduce()等)时。它们可以接收任何数量的参数ÿ…...

java9-泛型
1.泛型的简介 1.1 什么是泛型 泛型是一种特殊的数据类型。 它是Java 的一个高级特性。在 Mybatis、Hibernate 这种持久化框架,泛型更是无处不在。 在这之前,不管我们在定义成员变量时,还是方法的形参时,都要规定他们的具体类型…...

zotero安装与使用
文献管理工具) Zotero软件官网https://www.zotero.org/download,不修改安装位置,默认安装就行;安装完成官网直接邮箱注册一个账号,软件登陆账号:编辑-首选项-同步 修改论文保存位置,有从其它电脑拷贝过来的…...
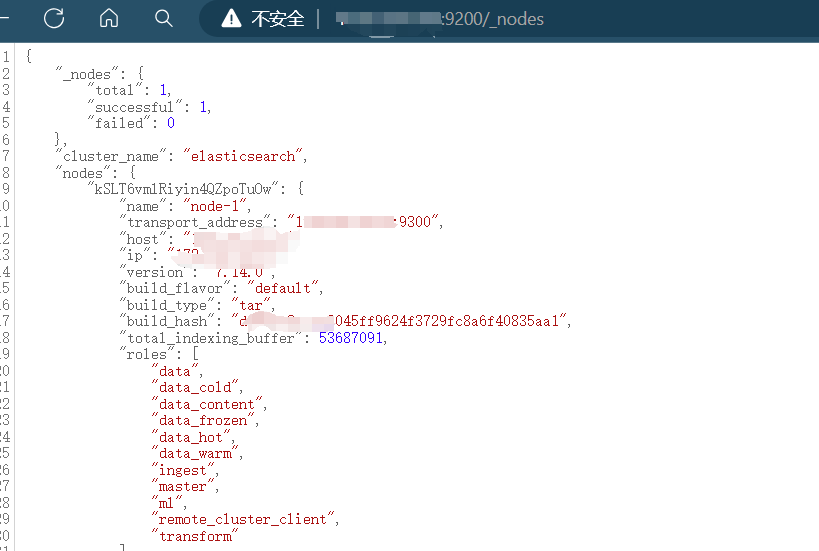
Elasticsearch未授权访问漏洞
7.Elasticsearch未授权访问漏洞 Elasticsearch服务普遍存在一个未授权访问的问题,攻击者通常可以请求一个开放9200或9300的服务器进行恶意攻击。 步骤一:使用以下Fofa语法进行Elasticsearch产品搜索 "Elasticsearch" && port"9200" …...

【FPGA】module中CLOCK RESET iCall oDone的含义
一般的module并不只有iData和oData,还有其他的控制信号,如CLOCK RESET iCall oDone 基本的模式为 module cordicSinhCosh (input CLOCK,RESET,input iCall, output oDone,input [31:0]iData, output [31:0]oData, );reg [31:0] x;initial begin x = ...endreg signed [31:…...

OpenGL实现3D游戏编程【连载2】——了解并创建3D空间模型
1、本节实现的内容 上一节我们创建一个简单的窗口,本节我们需要了解一下细节内容,同时为了方便观看,我们需要显示一个世界坐标轴,建立一个直观的三维空间。 2、我们的眼睛设定(gluPerspective函数) 上一…...

Java-文件操作和IO
文件介绍 文件本身有多重含义,狭义的文件,特指硬盘上的文件(以及保存文件的目录),广义的文件:计算机上的很多硬件设备,软件资源,在操作系统中,都会被视为是"文件" 文件除了有数据内容之外,还有一部分信息,例如文件名,文件类型,文件大小,这些信息可以称作文件的元信…...

AI智能化赋能电商经济,守护消费净土,基于轻量级YOLOv8n开发构建公共生活景下的超大规模500余种商品商标logo智能化检测识别分析系统
在数字经济浪潮的推动下,全力发展新质生产力已成为当今社会发展的主旋律。各行各业正经历着前所未有的变革,其中,电商行业作为互联网经济的重要组成部分,更是以惊人的速度重塑着商业格局与消费模式。AI智能化技术的深度融合&#…...

C语言菜鸟入门·数据结构·链表超详细解析
目录 1. 单链表 1.1 什么是单链表 1.1.1 不带头节点的单链表 1.1.2 带头结点的单链表 1.2 单链表的插入 1.2.1 按位序插入 (1)带头结点 (2)不带头结点 1.2.2 指定结点的后插操作 1.2.3 指定结点的前插操作 1.3 …...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

AI 应用原型开发阶段利用 Taotoken 快速进行多模型效果对比
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 AI 应用原型开发阶段利用 Taotoken 快速进行多模型效果对比 在构建一个 AI 应用的原型时,开发者常常面临一个核心问题&…...

哪款台灯护眼效果最好孩子用?实测口碑爆款护眼灯品牌,买前必看
哪款台灯护眼效果最好孩子用?作为家长,最揪心的就是孩子的视力问题。有数据显示,现在孩子近视率越来越高,小学就有不少戴眼镜的,中学更是过半,看着实在让人担心。 孩子每天低头写作业、看书,灯光…...

3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南
3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

别只盯着主控芯片!拆解STM32最小系统板:电源、时钟、复位三大支柱电路深度解析
STM32最小系统板设计进阶:电源、时钟与复位电路的工程实践 在嵌入式系统开发中,我们常常将注意力集中在主控芯片的功能实现上,却忽略了支撑系统稳定运行的三大基础电路——电源、时钟和复位。这些看似简单的电路模块,实则是整个系…...