数据中台建设之数据存储
目录
一、技术选型需要明确的问题
二、技术选型需要考虑的几个方面
2.1 数据规模
2.2 数据生产方式
2.3 数据应用方式
三、技术选型的场景分析
3.1 概述
3.2 在线与离线
3.2.1 在线存储
3.2.2 离线存储
3.3 OLTP与OLAP
3.3.1 OLTP
3.3.2 OLAP
3.3.3 OLTP与OLAP的关系
四、存储技术
4.1 概述
4.2 存储技术分类
4.2.1 分布式系统
4.2.2 NoSQL数据库
4.2.3 云数据库
4.2.4 数据湖
4.2.4.1 概述
4.2.4.2 数据仓库与数据湖的对比
4.2.4.3 数据编目
4.2.4.4 数据入湖
4.2.4.5 总结
一、技术选型需要明确的问题
将各类数据汇聚后,首先面临的是存储压力,不同类型的数据内容、不同的数据汇聚方式及未来可能的使用场景,都会对存储系统的选择产生影响。
常见的问题如下:
- ❑存储系统是选择关系型数据库还是大数据相关的技术(Hadoop等)?
- ❑现有存储系统与新存储系统之间是什么关系?
- ❑选择数据仓库还是数据湖?
二、技术选型需要考虑的几个方面
抛开技术指标的维度对比,选择存储系统时还需要考虑以下几个方面。
2.1 数据规模
当前的及未来的数据规模,这取决于对中台的定位及对未来的发展预期。DT时代,企业的数据生产方式越来越丰富,数据量越来越大,选择成本可控且容易扩展的存储系统是比较常见的选择。
2.2 数据生产方式
有些数据生产端没有存储系统,因此会通过实时推送的方式将生产数据按特定协议和方式进行推送,这类场景要求数据采集时的存储系统能够满足数据实时落地的需求。有些目标存储系统不具备这种高性能落地的能力,因此需要考虑在数据生产端和目标存储端中间加一个写性能较好的存储系统。
2.3 数据应用方式
数据使用场景决定了数据存储系统的选型,如离线的数据分析适合非人机交互的场景,搜索则需要能够快速检查并支持一些关键字和权重处理。这些能力也需要有特定的存储系统来支撑。
三、技术选型的场景分析
3.1 概述
针对这些复杂的场景,在大规模的数据处理下,任何一个以前认为可以忽视的小问题都有可能被无限放大,因此还像以前一样靠一种存储系统解决所有问题是不太可能的。在建设中台时,需要根据企业自身情况选择合适的存储系统组合来满足企业的数据战略和数据应用需求。
3.2 在线与离线
3.2.1 在线存储
在线存储是指存储设备和所存储的数据时刻保持在线状态,可供用户随时读取,满足计算平台对数据访问的速度要求,就像PC中常用的磁盘存储模式一样。在线存储设备一般为磁盘、磁盘阵列、云存储等。
3.2.2 离线存储
离线存储用于对在线存储的数据进行备份,以防范可能发生的数据灾难。离线存储的数据不会经常被调用,一般也远离系统应用,“离线”一词生动地描述了这种存储方式。离线存储介质上的数据的读写是顺序进行的。读取数据时,需要先把磁带卷到头,再进行定位。当需要对已写入的数据进行修改时,需要将所有数据全部改写。因此,离线存储的访问速度慢、效率低。离线存储的主要介质是硬盘、磁带、光盘等。
3.3 OLTP与OLAP
3.3.1 OLTP
OLTP(On-Line Transaction Processing,联机事务处理)是专注于面向事务的任务的一类数据处理,通常涉及在数据库中插入、更新或删除少量数据,主要处理大量用户下的大量事务。OLTP系统一般都是高可用的在线系统,以小的事务及小的查询为主,评估其系统的时候,一般看其每秒执行的事务及查询的数量。在这样的系统中,单个数据库每秒处理的事务往往有几百甚至几千个,Select语句的执行量每秒有几千甚至几万个。典型的OLTP系统有电子商务系统、银行、证券等,如美国eBay的业务数据库就是很典型的OLTP数据库。
3.3.2 OLAP
OLAP(On-Line Analytical Processing,联机分析处理)系统,有时也叫DSS(决策支持系统),就是我们说的数据仓库。它常用于报表分析场景,相对于OLTP,对准确性(如id-mapping)、事务性和实时性要求较低。1993年,E.F.Codd认为OLTP已不能满足终端用户对数据库查询分析的需要,SQL对大型数据库进行的简单查询也不能满足终端用户分析的要求。用户的决策分析需要对关系数据库进行大量计算才能得到结果,而查询的结果并不能满足决策者提出的需求。因此,他提出了多维数据库和多维分析的概念,即OLAP。
3.3.3 OLTP与OLAP的关系
OLTP和OLAP是相对传统的术语,但是在大数据时代,它们又有了新的使命。需要强调的是,OLTP和OLAP并不是竞争或者互斥的关系,相反,它们相互协作,互利共赢,OLTP用于存储和管理日常操作的数据,OLAP用于分析这些数据,如下图所示:

OLAP技术主要通过多维的方式来对数据进行分析、查询并生成报表,它不同于传统的OLTP应用。OLTP应用主要用来完成用户的事务处理,如民航订票系统和银行的储蓄系统等,通常要进行大量的更新操作,并且对响应的时间要求比较高。而OLAP应用主要对用户当前数据和历史数据进行分析,帮助市场做决策,制定营销策略,主要用来执行大量的查询操作,对实时性要求低。下表对OLTP与OLAP进行了比较:

四、存储技术
4.1 概述
为了应对数据处理的压力,过去十年间,数据处理技术领域有了很多的创新和发展。除了面向高并发、短事务的OLTP内存数据库外(Altibase、TimesTen),其他的技术创新和产品都是面向数据分析的,而且是大规模数据分析,也可以说是大数据分析。
有的采用MPP(Massive Parallel Processing,大规模并行处理)架构的数据库集群,重点面向行业大数据,如Greenplum、LibrA等;有的采用Shared Nothing架构,通过列存储、粗粒度索引等多项大数据处理技术,再结合MPP架构高效的分布式计算模式,实现对分析类应用的支撑,运行环境多为低成本的PC服务器,具有高性能和高扩展性的特点;也有的采用从Hadoop技术生态圈中衍生的相关大数据技术,如HBase等。
4.2 存储技术分类
4.2.1 分布式系统
分布式系统包含多个自主的处理单元,通过计算机网络互联来协作完成分配的任务,其分而治之的策略能够更好地处理大规模数据分析问题。分布式系统主要包含以下3类:
- ❑分布式文件系统:存储管理需要多种技术的协同工作,其中文件系统为其提供底层存储能力的支持。分布式文件系统HDFS是一个高容错性系统,被设计成适用于批量处理,能够提供高吞吐量的数据访问。
- ❑分布式键值系统:用于存储关系简单的半结构化数据。典型的分布式键值系统有Amazon Dynamo,获得广泛应用的对象存储(ObjectStorage)技术也可以视为键值系统,其存储和管理的是对象而不是数据块。
- ❑MPP系统:这里更多是指狭义上的分布式分析性数据库系统,如Greenplum、Teradata等。这类数据库具备良好的SQL兼容性,能够像操作关系型数据库一样执行任务,在集群节点规模上也能扩展到三位数,但是由于只能处理结构化数据,所以难以支持数据湖这类蕴含丰富非结构化数据的场景。
4.2.2 NoSQL数据库
关系型数据库已经无法满足Web 2.0的需求,主要表现为:
- ❑无法满足海量数据的管理需求;
- ❑无法满足数据高并发的需求;
- ❑高可扩展性和高可用性的功能太低。
NoSQL数据库的优势为:可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web 2.0应用,具有强大的横向扩展能力等。典型的NoSQL数据库包含以下几种:键值数据库、列族数据库、文档数据库和图形数据库等。
4.2.3 云数据库
云数据库是一种基于云计算技术的共享基础架构的方法,是部署和虚拟化在云计算环境中的数据库。云数据库并非全新的数据库技术,而只是以服务方式提供的数据库功能。云数据库所采用的数据模型可以是关系型数据库所使用的关系模型(微软的Azure SQL云数据库都采用了关系模型)。同一家公司也可能提供采用不同数据模型的多种云数据库服务。
4.2.4 数据湖
4.2.4.1 概述
随着企业数据的爆发式增长,以及对非结构化数据存储与分析使用的需求增大,传统数据仓库的数据中台方案遇到了瓶颈。首先,数据中台需要将所有原始数据汇聚,非结构化数据的原始数据存放在各个NAS、云盘、本地FTP等系统中,而受限于存储成本,难以将所有非结构化数据同步到数据中台;其次,数据仓库更多是结构化数据存算一体的架构,非结构化数据要进行处理再进入数据仓库,从数据处理、加工到使用的链路较长;最后,数据仓库作为OLAP的选型,ACID方面无法保证,对于要求实时、精准分析数据的场景支持并不理想。
4.2.4.2 数据仓库与数据湖的对比
数据湖除了具备数据仓库的大部分能力外,还解决了上述棘手问题。通过下表对数据仓库与数据湖的比较我们能够更好地了解数据湖的主要能力。

数据湖是一个以原始格式存储数据的存储库或系统,它按原样存储数据,而不事先对数据进行结构化处理。也就是说,数据湖既可以存储结构化数据,也可以存储非结构化数据,换句话说,可以存储企业的所有数据。
另外,搭配这一特性的还有数据的加工方式,数据仓库是写时模式,数据湖是读时模式。写时的意思是在写入数据时,就把数据结构(Scheme)定义好,系统已经知道这些数据的逻辑结构,可通过既定的程序输出计算结果;而读时模式则是数据在使用时,由使用者定义结构及分析方法,它相比读时更加灵活,可挖掘出更多的数据金矿。
4.2.4.3 数据编目
企业的数据存储系统以及业务系统逐年增加,数据存储在各个地方,存储介质多种多样,有机械硬盘、固态硬盘、内存等,数据湖可以通过数据编目的方式将这些存储系统统一管理起来,用于后续的计算。数据使用者无须关心数据的实际存储位置,只需要申请并执行计算任务即可获得结果。
数据编目可以是对原始数据的物理资源编目,也可以是基于业务需求和场景的逻辑编目。但无论采用何种编目方式,都需要保证用户和系统能够索引、定位到数据。
4.2.4.4 数据入湖
在存储计算方面,数据仓库采用的是存算一体的模式,如果要使用数据仓库,就需要单独搭建一套存储系统,将数据实际汇聚到存储系统当中。而数据湖可以做到存算分离,存储系统既可以是集中的,也可以是分散的,分散的数据在被使用时同步到加速计算引擎内,输出结果,这样就无须先将数据处理加工好再使用,因而能够更合理地利用组织内的存算资源。数据进入数据湖的方式主要有两种。
- ❑物理入湖
数据编目完成后,即将数据汇聚、同步到数据湖的存储系统中。对于经常使用、分析的数据,建议使用物理入湖的方法,这样在数据分析时,数据无须进行传输就已经在系统中存储,因而能够让数据计算任务立刻跑起来,快速获取结果。
- ❑虚拟入湖
仅完成数据编目的工作,而不进行数据汇聚、同步的工作,只有在计算时,才通过实时同步的方式将数据集中存储并计算。如果在原始存储系统中部署有计算节点,也可以先在边缘计算结果再传输到中心统一计算。对于非结构化数据这类存储开销大的或者使用频率低、难以评估使用频率的数据,都推荐使用虚拟入湖的方式“汇聚”到数据湖中。
4.2.4.5 总结
数据湖能够真正将原始数据都“汇聚”起来,消灭数据孤岛;让企业数据管理者看到数据大盘,掌握数据概况,让数据开发者无须关注物理存储即可进行指标计算、数据挖掘,快速响应业务,是数据中台现阶段在技术层面的最佳选择。
好了,本次内容就分享到这,欢迎大家关注《数据中台》专栏,后续会继续输出相关内容文章。如果有帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!
相关文章:
数据中台建设之数据存储
目录 一、技术选型需要明确的问题 二、技术选型需要考虑的几个方面 2.1 数据规模 2.2 数据生产方式 2.3 数据应用方式 三、技术选型的场景分析 3.1 概述 3.2 在线与离线 3.2.1 在线存储 3.2.2 离线存储 3.3 OLTP与OLAP 3.3.1 OLTP 3.3.2 OLAP 3.3.3 OLTP与OLAP的关…...

最常见的AI大模型总结
前言:大模型可以根据其主要的应领域和功能,可以分类为“文生文”(Text-to-Text)、“文生图”(Text-to-Image)和“文生视频”(Text-to-Video),都是基于自然语言处理&#…...

源码安装docker和docker-compose
前言 前提条件:内核要求 目前,CentOS 仅发行版本中的内核支持 Docker。 Docker 运行在 CentOS 7 上,要求系统为64位、系统内核版本为3.10 以上。 Docker 运行在 CentOS-6.5 或更高的版本的 CentOS 上,要求系统为64位、系统内核版…...
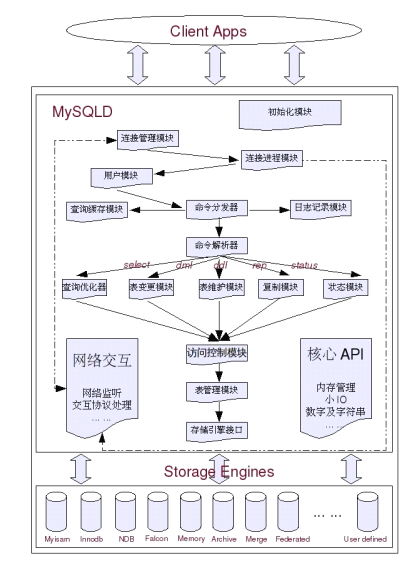
Java、PHP、Node 操作 MySQL 数据库常用方法
一、Java 操作 MySQL 数据库 1、Java 连接 MySQL 数据库 1. 使用 JDBC 驱动程序连接 使用这种方式,首先需要导入 MySQL 的 JDBC 驱动程序依赖,然后通过 Class.forName() 方法加载驱动程序类。其创建连接的过程相对直接,只需提供准确的数据库…...

nVisual分享社区正式上线啦!
nVisual分享社区正式上线啦! 访问地址:分享社区 nVisual是耐威迪基于数字孪生技术物联网技术开发的一款基础设施数字孪生软件工具,主要实现OSP室外与ISP室内基础设施的规划、记录、分析的可视化管理。 规划:nVisual可视化、智能化…...

4.5.门控循环单元GRU
门控循环单元GRU 对于一个序列,不是每个观察值都是同等重要的,可能会遇到一下几种情况: 早期观测值对预测所有未来观测值都具有非常重要的意义。 考虑极端情况,第一个观测值包含一个校验和,目的是在序列的末尾辨别…...

10种 Python数据结构,从入门到精通
今天我们将深入探讨 Python 中常用的数据结构,帮助你从基础到精通。每种数据结构都有其独特的特点和适用场景,通过实际代码示例和生活中的比喻,让你更容易理解这些概念。 学习数据结构的三个阶段 1、掌握基本用法:使用这些数据结…...

【AI】人工智能时代,程序员如何保持核心竞争力?
目录 程序员在AI时代的应对策略1. 引言2. AI在编程领域的影响2.1 AI辅助编程工具的现状2.2 AI对编程工作的影响2.3 程序员的机遇与挑战 3. 深耕细作:专注领域的深度学习3.1 专注领域的重要性3.2 深度学习的策略3.2.1 选择合适的领域3.2.2 持续学习和研究3.2.3 实践与…...
WPF学习(3)- WrapPanel控件(瀑布流布局)+DockPanel控件(停靠布局)
WrapPanel控件(瀑布流布局) WrapPanel控件表示将其子控件从左到右的顺序排列,如果第一行显示不了,则自动换至第二行,继续显示剩余的子控件。我们来看看它的结构定义: public class WrapPanel : Panel {pub…...

【python】Python中实现定时任务常见的几种方式原理分析与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

老公请喝茶,2024年老婆必送老公的养生茶,暖暖的很贴心
在这个快节奏的时代,每个人都在为生活奔波,而家的温馨与关怀,成了我们最坚实的后盾。随着2024年的已经过半,作为妻子,你是否也在寻找一份特别的礼物,来表达对老公深深的爱意与关怀?在这个充满爱…...

3d打印相关资料
模型库 拓竹makerworld爱给...

MySQL1 DDL语言
安装与配置 官网: MySQL :: Download MySQL Installer 阿里云: MySQL8 https://www.alipan.com/s/auhN4pTqpRp 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速…...

el-tree懒加载状态下实现搜索筛选(纯前端)
1.效果图 (1)初始状态 (2)筛选后 2.代码 <template><div><el-inputplaceholder"输入关键字进行过滤"v-model"filterText"input"searchValue"></el-input><el-tree…...

NLP——Transfromer 架构详解
Transformer总体架构图 输入部分:源文本嵌入层及其位置编码器、目标文本嵌入层及其位置编码器 编码器部分 由N个编码器层堆叠而成 每个编码器层由两个子层连接结构组成 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接 第二个子层连接结构包…...

大模型算法面试题(二十)
本系列收纳各种大模型面试题及答案。 1、描述Encoder和Decoder中Attention机制的不同之处 Encoder和Decoder中的Attention机制在自然语言处理(NLP)和序列到序列(Seq2Seq)模型中扮演着重要角色,它们虽然都利用了Attent…...
2024最新最全面的Selenium 3.0 + Python自动化测试框架
文档说明 Selenium是一个用于Web应用程序自动化测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。 Selenium测试的主要功能包括: 测试与浏览器的兼容性:测试应用程序是否能很好的工作在不同的浏览器和操作系统之上。…...

海运中的甩柜是怎么回事❓怎么才能避免❓
什么是甩柜? 甩柜又叫甩箱,是指集装箱船在起运离港时,船公司没有将此前计划装船的集装箱装运上船,导致部分货物滞留港口。多出现在海运旺季。 为什么会甩柜? 甩箱是集装箱物流中常见的事件,主要因为承运…...

Win11+docker+gpu+vscode+pytorch配置anomalib(2)
在上一篇文章中,我在Win11上通过Docker配置了pytorch,并顺利调用了GPU。在这篇文章中,我将继续完成anomalib的配置。 anomalib是一个非常完善的异常检测框架,我希望通过它来学习经典异常检测算法,并且测试这些算法在我自己的数据集上的效果。 步骤如下: 1. 从docker Hub上…...

AI在招聘市场趋势分析中的应用
一、引言 在数字化、智能化的时代背景下,人工智能(AI)技术正逐步渗透到各行各业,其中招聘市场也不例外。AI技术的运用不仅极大地提高了招聘的效率和精准度,还在招聘市场趋势分析方面展现出巨大的潜力。本文旨在探讨AI在…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

昇腾NPU模型服务化——从离线模型到高可用推理服务
模型训练完只是第一步。真正产生业务价值的是把模型部署成724小时在线服务——毫秒级延迟、支持动态Batching、能扛住流量洪峰,且具备高可用性。 这篇将手把手教你基于昇腾NPU构建生产级模型推理服务,涵盖框架选型、服务化架构、动态Batching优化、热加载…...

基于Meshtastic构建LoRa Mesh网络:从硬件自制到传感器集成实战
1. 项目概述:构建一个灵活且易用的LoRa Mesh网络 如果你对物联网、远程传感或者去中心化通信网络感兴趣,那么LoRa技术一定不会陌生。它以其超低功耗、超远距离和强大的抗干扰能力,成为了构建广域传感网络的理想选择。然而,传统的…...