YoloV10 论文翻译(Real-Time End-to-End Object Detection)
摘要
近年来,YOLO因其在计算成本与检测性能之间实现了有效平衡,已成为实时目标检测领域的主流范式。研究人员对YOLO的架构设计、优化目标、数据增强策略等方面进行了探索,并取得了显著进展。然而,YOLO对非极大值抑制(NMS)后处理的依赖阻碍了其端到端的部署,并对推理延迟产生了不利影响。此外,YOLO中各组件的设计缺乏全面和深入的审查,导致计算冗余明显,并限制了模型的性能。这使得YOLO的效率不尽如人意,且存在相当大的性能提升潜力。在本文中,我们的目标是从后处理和模型架构两个方面进一步推进YOLO的性能-效率边界。为此,我们首先提出了用于YOLO无NMS训练的一致性双重分配策略,该策略同时带来了竞争性的性能和较低的推理延迟。此外,我们引入了面向YOLO的整体效率-准确率驱动的模型设计策略。我们从效率和准确性的角度对YOLO的各种组件进行了全面优化,大大降低了计算开销并提升了性能。我们的努力成果是一种新一代的用于实时端到端目标检测的YOLO系列,称为YOLOv10。大量实验表明,YOLOv10在各种模型规模下均实现了最先进的性能和效率。例如,我们的YOLOv10-S在COCO数据集上与RT-DETR-R18具有相似的平均精度(AP),但速度提高了1.8倍,同时参数数量和浮点运算次数(FLOPs)减少了2.8倍。与YOLOv9-C相比,YOLOv10-B在相同性能下延迟降低了46%,参数减少了25%。代码地址:https://github.com/THU-MIG/yolov10。

1 引言
实时目标检测一直是计算机视觉领域的研究焦点,旨在以低延迟准确地预测图像中物体的类别和位置。它在各种实际应用中得到了广泛应用,包括自动驾驶[3]、机器人导航[11]和物体跟踪[66]等。近年来,研究人员致力于开发基于卷积神经网络(CNN)的目标检测器以实现实时检测[18, 22, 43, 44, 45, 51, 12]。其中,YOLO系列因其在性能和效率之间的出色平衡而备受欢迎[2, 19, 27, 19, 20, 59, 54, 64, 7, 65, 16, 27]。YOLO的检测流程包括两部分:模型前向传播和非极大值抑制(NMS)后处理。然而,这两部分都存在不足,导致精度-延迟边界不理想。具体来说,YOLO在训练时通常采用一对多的标签分配策略,即一个真实物体对应多个正样本。尽管这种方法能够带来优越的性能,但在推理时却需要NMS来选择最佳正预测。这减慢了推理速度,并使性能对NMS的超参数敏感,从而阻碍了YOLO实现最优的端到端部署[71]。一种解决这一问题的方法是采用最近引入的端到端DETR架构[4, 74, 67, 28, 34, 40, 61]。例如,RT-DETR[71]提出了一种高效的混合编码器和不确定性最小化查询选择,使DETR能够应用于实时应用。然而,DETR部署的固有复杂性阻碍了其在精度和速度之间达到最优平衡的能力。另一种方法是探索基于CNN检测器的端到端检测,这通常利用一对一分配策略来抑制冗余预测[5, 49, 60, 73, 16]。然而,这些方法通常会增加额外的推理开销或无法达到最优性能。
此外,YOLO的模型架构设计仍然是一个根本性挑战,对精度和速度有重要影响[45, 16, 65, 7]。为了实现更高效和有效的模型架构,研究人员探索了不同的设计策略。为了增强特征提取能力,为骨干网络提出了各种基本计算单元,包括DarkNet[43, 44, 45]、CSPNet[2]、EfficientRep[27]和ELAN[56, 58]等。对于颈部网络,探索了PAN[35]、BiC[27]、GD[54]和RepGFPN[65]等来增强多尺度特征融合。此外,还研究了模型缩放策略[56, 55]和重参数化[10, 27]技术。尽管这些努力取得了显著进展,但从效率和精度角度对YOLO中各种组件进行全面检查的工作仍然缺乏。因此,YOLO中仍存在相当的计算冗余,导致参数利用率低下且效率不理想。此外,由此导致的模型能力受限也导致性能不佳,留下了大量提升精度的空间。
在本文中,我们旨在解决这些问题并进一步提升YOLO的精度-速度边界。我们的目标贯穿整个检测流程,包括后处理和模型架构。为此,我们首先通过提出一种用于无NMS YOLO的一致双重分配策略来解决后处理中的冗余预测问题,该策略结合了双重标签分配和一致匹配度量。它允许模型在训练期间享受丰富且协调的监督,同时在推理期间消除对NMS的需求,从而实现具有高效性的竞争性能。其次,我们提出了针对模型架构的全局效率-精度驱动模型设计策略,通过对YOLO中各种组件进行全面检查来实现这一目标。为了提高效率,我们提出了轻量级分类头、空间-通道解耦下采样和秩引导块设计,以减少明显的计算冗余并实现更高效的架构。为了提高精度,我们探索了大核卷积并提出了有效的部分自注意力模块,以增强模型能力,在低成本下挖掘性能提升的潜力。
基于这些方法,我们成功开发了一个具有不同模型规模的新一代实时端到端检测器系列,即YOLOv10-N/S/M/B/L/X。在标准目标检测基准测试集(如COCO[33])上进行的大量实验表明,我们的YOLOv10在各种模型规模下均能在计算-精度权衡方面显著优于先前最先进的模型。如图1所示,在相似性能下,我们的YOLOv10-S/X分别比RT-DETR-R18/R101快1.8倍/1.3倍。与YOLOv9-C相比,YOLOv10-B在相同性能下延迟降低了46%。此外,YOLOv10展现出高效的参数利用率。我们的YOLOv10-L/X在参数数量分别比YOLOv8-L/X少1.8倍和2.3倍的情况下,性能分别高出0.3 AP和0.5 AP。YOLOv10-M与YOLOv9-M/YOLO-MS具有相似的AP,但参数分别减少了23%/31%。我们希望我们的工作能够激发该领域的进一步研究和进步。

2 相关工作
实时目标检测器。实时目标检测旨在以低延迟对物体进行分类和定位,这对于实际应用至关重要。过去几年中,研究人员在开发高效检测器方面付出了大量努力[18, 51, 43, 32, 72, 69, 30, 29, 39]。特别是YOLO系列[43, 44, 45, 2, 19, 27, 56, 20, 59]脱颖而出,成为主流。YOLOv1、YOLOv2和YOLOv3确定了典型的检测架构,包括三个部分:骨干网络、颈部网络和头部网络[43, 44, 45]。YOLOv4[2]和YOLOv5[19]引入了CSPNet[57]设计来替换DarkNet[42],并结合了数据增强策略、增强的PAN和更多样化的模型规模等。YOLOv6[27]为颈部网络和骨干网络分别提出了BiC和SimCSPSPPF,并采用锚点辅助训练和自蒸馏策略。YOLOv7[56]引入了E-ELAN以实现丰富的梯度流路径,并探索了几种可训练的免费午餐方法。YOLOv8[20]提出了C2f构建块以进行有效特征提取和融合。Gold-YOLO[54]提供了先进的GD机制以增强多尺度特征融合能力。YOLOv9[59]提出了GELAN以改进架构,并提出了PGI以增强训练过程。
端到端目标检测器。端到端目标检测作为一种从传统流程中的范式转变而出现,提供了简化的架构[48]。DETR[4]引入了Transformer架构,并采用匈牙利损失实现一对一匹配预测,从而消除了手工设计的组件和后处理。自那以后,各种DETR变体被提出来增强其性能和效率[40, 61, 50, 28, 34]。Deformable-DETR[74]利用多尺度可变形注意力模块来加速收敛速度。DINO[67]将对比去噪、混合查询选择和前瞻两次方案集成到DETR中。RT-DETR[71]进一步设计了高效的混合编码器,并提出了不确定性最小化查询选择以提高准确性和延迟。实现端到端目标检测的另一条路线是基于CNN的检测器。可学习NMS[23]和关系网络[25]提出了另一种网络来移除检测器中的重复预测。OneNet[49]和DeFCN[60]提出了一对一匹配策略,以使用全卷积网络实现端到端目标检测。FCOS[73]引入了一个正样本选择器来选择最佳样本进行预测。
3 方法论
3.1 无NMS训练的一致双重分配
在训练过程中,YOLO系列[20, 59, 27, 64]通常利用TAL[14]为每个实例分配多个正样本。采用一对多分配可以产生丰富的监督信号,促进优化并实现优越的性能。然而,这导致YOLO依赖于NMS后处理,从而降低了部署时的推理效率。虽然之前的工作[49, 60, 73, 5]探索了一对一匹配来抑制冗余预测,但它们通常会增加额外的推理开销或产生次优性能。
在本文中,我们提出了一种针对YOLO的无NMS训练策略,该策略采用双重标签分配和一致匹配度量,同时实现高效能和竞争性能。
双重标签分配。与一对多分配不同,一对一匹配只为每个真实框分配一个预测,从而避免了NMS后处理。然而,这会导致较弱的监督,从而降低准确性和收敛速度[75]。幸运的是,这一缺陷可以通过一对多分配来弥补[5]。为了实现这一点,我们为YOLO引入了双重标签分配,以结合两种策略的最佳优势。具体来说,如图2(a)所示,我们为YOLO添加了另一个一对一头部。它保留了相同的结构,并采用了与原始一对多分支相同的优化目标,但利用一对一匹配来获得标签分配。在训练期间,两个头部与模型一起联合优化,使骨干网络和颈部网络能够享受一对多分配提供的丰富监督。在推理期间,我们丢弃一对多头部,并利用一对一头部进行预测。这使得YOLO能够实现端到端部署,而不会带来任何额外的推理成本。此外,在一对一匹配中,我们采用选择得分最高的预测作为匹配结果,这与匈牙利匹配[4]具有相同的性能,但额外训练时间更少。
一致匹配度量。在分配过程中,一对一和一对多方法都利用一个度量来定量评估预测和实例之间的一致性水平。为了实现两个分支的预测感知匹配,我们采用了一个统一的匹配度量,即:
m(α, β) = s · pα · IoU(ˆb, b)β, (1)
其中p是分类得分,b^和b分别表示预测框和真实框,s表示空间先验,指示预测锚点是否在实例内[20, 59, 27, 64]。α和β是两个重要的超参数,用于平衡语义预测任务和位置回归任务的影响。我们将一对多和一对一的度量分别表示为和。这些度量影响两个头部的标签分配和监督信息。
在双重标签分配中,一对多分支提供的监督信号比一对一分支丰富得多。直观地说,如果我们能够协调一对一头部和一对多头部之间的监督,我们可以将一对一头部优化到一对多头部优化的方向。因此,一对一头部可以在推理期间提供更高质量的样本,从而获得更好的性能。为此,我们首先分析两个头部之间的监督差距。由于训练过程中的随机性,我们从两个头部以相同值初始化并产生相同预测的情况开始检查,即一对一头部和一对多头部为每个预测-实例对生成相同的p和IoU。我们注意到,两个分支的回归目标不冲突,因为匹配的预测共享相同的目标,而未匹配的预测则被忽略。因此,监督差距在于不同的分类目标。给定一个实例,我们将其与预测的最大交并比(IoU)表示为 u ∗ u^* u∗,将一对多和一对一匹配的最大分数分别表示为 m o 2 m ∗ m^*_{o2m} mo2m∗和 m o 2 o ∗ m^*_{o2o} mo2o∗。假设一对多分支产生了正样本集 Ω \Omega Ω,且一对一分支根据度量 m o 2 o , i = m o 2 o ∗ m_{o2o,i}=m^*_{o2o} mo2o,i=mo2o∗选择了第 i i i个预测,我们可以推导出分类目标 t o 2 m , j = u ∗ ⋅ m o 2 m , j m o 2 m ∗ t_{o2m,j}=u^* \cdot \frac{m_{o2m,j}}{m^*_{o2m}} to2m,j=u∗⋅mo2m∗mo2m,j(对于 j ∈ Ω j \in \Omega j∈Ω)和 t o 2 o , i = u ∗ ⋅ m o 2 o , i m o 2 o ∗ = u ∗ t_{o2o,i}=u^* \cdot \frac{m_{o2o,i}}{m^*_{o2o}}=u^* to2o,i=u∗⋅mo2o∗mo2o,i=u∗,这里采用的是与任务对齐的损失函数,如[20, 59, 27, 64, 14]中所使用的。因此,两个分支之间的监督差距可以通过不同分类目标之间的1-Wasserstein距离[41]来推导得出,即:

这个差距随着一对多头部中第i个样本的分类目标 t o 2 m , i t_{o2m,i} to2m,i的增加而减小,即当第i个样本在一对多匹配结果中的排名越靠前时,差距越小。当 t o 2 m , i = u ∗ t_{o2m,i}=u^* to2m,i=u∗时,差距达到最小,这意味着第i个样本是一对多匹配结果中的最佳正样本,如图2(a)所示。
为了实现这一点,我们提出了一致匹配度量,即设置 α o 2 o = r ⋅ α o 2 m \alpha_{o2o}=r \cdot \alpha_{o2m} αo2o=r⋅αo2m和 β o 2 o = r ⋅ β o 2 m \beta_{o2o}=r \cdot \beta_{o2m} βo2o=r⋅βo2m,这意味着一对一匹配度量 m o 2 o m_{o2o} mo2o与一对多匹配度量 m o 2 m m_{o2m} mo2m成正比(系数为r)。因此,对于一对多头部而言的最佳正样本也是一对一头部的最佳正样本。这样,两个头部就可以在训练和推理过程中保持一致的优化方向,实现和谐优化。为了简化,我们默认取 r = 1 r=1 r=1,即 α o 2 o = α o 2 m \alpha_{o2o}=\alpha_{o2m} αo2o=αo2m和 β o 2 o = β o 2 m \beta_{o2o}=\beta_{o2m} βo2o=βo2m。
为了验证这种一致匹配度量带来的监督对齐改进,我们在训练后统计了一对一匹配对在一对多结果前1名、前5名和前10名中的数量。如图2(b)所示,在使用一致匹配度量后,监督对齐得到了改善。
关于数学证明的更全面理解,请参考附录部分。
3.2 整体效率-精度驱动的模型设计
除了后处理之外,YOLO的模型架构也对效率-精度的权衡提出了巨大挑战[45, 7, 27]。尽管以前的工作探索了各种设计策略,但对YOLO中各种组件的综合检查仍然缺乏。因此,YOLO的模型架构存在不可忽视的计算冗余和受限的能力,这阻碍了其实现高效能和性能的潜力。在这里,我们旨在从效率和精度两个角度对YOLO进行整体模型设计。
效率驱动的模型设计。YOLO的组件包括茎干(stem)、下采样层、具有基本构建块的阶段和头部。由于茎干的计算成本很低,因此我们针对其他三个部分进行效率驱动的模型设计。
(1)轻量级分类头。YOLO中的分类和回归头通常具有相同的架构。然而,它们在计算开销上存在显著差异。例如,在YOLOv8-S中,分类头的浮点运算次数(FLOPs)和参数数量(5.95G/1.51M)分别是回归头(2.34G/0.64M)的2.5倍和2.4倍。但是,通过分析分类错误和回归错误对性能的影响(见表6),我们发现回归头对YOLO的性能更为重要。因此,我们可以在不严重影响性能的情况下减少分类头的开销。因此,我们简单地采用了一个轻量级架构作为分类头,该架构由两个具有3×3内核大小的深度可分离卷积[24, 8]后跟一个1×1卷积组成。
(2)空间-通道解耦下采样。YOLO通常利用步长为2的常规3×3标准卷积来实现空间下采样(从H×W到H/2×W/2)和通道变换(从C到2C)同时进行。这引入了不可忽视的计算成O(9/2HWC^2).
和参数数量O(18C2)。相反,我们提出将空间降维和通道增加操作解耦,以实现更高效的下采样。具体来说,我们首先利用点卷积来调制通道维度,然后利用深度卷积进行空间下采样。这将计算成本降低到 O ( 2 H W C 2 + 9 / 2 H W C ) O(2HWC^2 + 9/2HWC) O(2HWC2+9/2HWC)并将参数数量减少到 O ( 2 C 2 + 18 C ) O(2C^2 + 18C) O(2C2+18C)同时,它在下采样过程中最大限度地保留了信息,从而在降低延迟的同时保持了竞争性能。
(3)基于秩的指导块设计。YOLO通常对所有阶段使用相同的基本构建块[27, 59],例如YOLOv8中的瓶颈块[20]。为了彻底检查YOLO的这种同质设计,我们利用内在秩[31, 15]来分析每个阶段的冗余性。具体来说,我们计算每个阶段中最后一个基本块的最后一个卷积的数值秩,即计算大于阈值的奇异值数量。图3(a)展示了YOLOv8的结果,表明深层阶段和大模型更容易表现出更多的冗余性。这一观察结果表明,对所有阶段简单地应用相同的基本块设计对于实现最佳容量-效率权衡来说并不是最优的。为了解决这个问题,我们提出了一种基于秩的指导块设计方案,旨在通过紧凑的架构设计来降低冗余阶段的复杂性。

我们首先提出了一种紧凑的倒置块(CIB)结构,如图3(b)所示,它采用廉价的深度卷积进行空间混合和成本效益高的点卷积进行通道混合。它可以作为高效的基本构建块,例如嵌入在ELAN结构中[58, 20](如图3(b)所示)。然后,我们提倡一种基于秩的指导块分配策略,以在保持竞争性能的同时实现最佳效率。具体来说,给定一个模型,我们根据其内在秩按升序对其所有阶段进行排序。我们进一步检查用CIB替换领先阶段中的基本块后的性能变化。如果与给定模型相比没有性能下降,则继续进行下一阶段的替换,否则停止该过程。因此,我们可以实现跨阶段和模型尺度的自适应紧凑块设计,从而在不影响性能的情况下提高效率。由于页面限制,我们在附录中提供了算法的详细信息。
精度驱动的模型设计。我们进一步探索了大核卷积和自注意力机制以进行精度驱动的设计,旨在以最小的成本提高性能。
(1)*大核卷积。*采用大核深度卷积是扩大感受野和增强模型能力的一种有效方法[9, 38, 37]。然而,简单地在所有阶段中利用它们可能会在用于检测小物体的浅层特征中引入干扰,同时还会在高分辨率阶段引入显著的I/O开销和延迟[7]。因此,我们提出在深层阶段中的CIB内利用大核深度卷积。具体来说,我们将CIB中第二个3×3深度卷积的核大小增加到7×7,遵循[37]。此外,我们采用结构重参数化技术[10, 9, 53]来引入另一个3×3深度卷积分支,以缓解优化问题而不增加推理开销。此外,随着模型尺寸的增加,其感受野自然会扩大,使用大核卷积的好处会减少。因此,我们仅对小模型尺寸采用大核卷积。
(2)部分自注意力(PSA)。自注意力机制[52]因其显著的全局建模能力而被广泛应用于各种视觉任务中[36, 13, 70]。然而,它表现出较高的计算复杂性和内存占用。为了解决这个问题,鉴于普遍存在的注意力头冗余性[63],我们提出了一种高效的部分自注意力(PSA)模块设计,如图3©所示。具体来说,在1×1卷积之后,我们将特征在通道上均匀划分为两部分。我们仅将其中一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。然后,将两部分进行拼接并通过1×1卷积进行融合。此外,我们遵循[21]将MHSA中查询和键的维度分配给值维度的一半,并将LayerNorm[1]替换为BatchNorm[26]以实现快速推理。此外,PSA仅放置在具有最低分辨率的第4阶段之后,以避免自注意力二次计算复杂度的过多开销。通过这种方式,可以以较低的计算成本将全局表示学习能力整合到YOLO中,从而很好地增强了模型的能力并提高了性能。
4 实验
4.1 实现细节
我们选择YOLOv8[20]作为我们的基线模型,因为它在延迟和准确性之间具有出色的平衡,并且提供了各种模型尺寸的版本。我们采用一致双重分配策略进行无NMS训练,并基于该策略进行了整体效率-精度驱动的模型设计,从而推出了YOLOv10模型。YOLOv10具有与YOLOv8相同的变体,即N/S/M/L/X。此外,我们通过简单地增加YOLOv10-M的宽度缩放因子来推导出一个新变体YOLOv10-B。我们在COCO[33]数据集上验证了所提出的检测器,并遵循相同的从头开始训练设置[20, 59, 56]。此外,我们遵循[71]在T4 GPU上使用TensorRT FP16测试了所有模型的延迟。
4.2 与最先进技术的比较
如表1所示,YOLOv10在各种模型尺寸上均实现了最先进的性能和端到端延迟。我们首先将YOLOv10与基线模型YOLOv8进行比较。在N/S/M/L/X五个变体上,YOLOv10的AP分别提高了1.2%/1.4%/0.5%/0.3%/0.5%,参数减少了28%/36%/41%/44%/57%,计算量减少了23%/24%/25%/27%/38%,延迟降低了70%/65%/50%/41%/37%。与其他YOLO系列模型相比,YOLOv10在精度和计算成本之间也展现出了优越的权衡。具体来说,对于轻量级和小型模型,YOLOv10-N/S在参数减少51%/61%和计算量减少41%/52%的情况下,分别比YOLOv6-3.0-N/S高出1.5 AP和2.0 AP。对于中型模型,与YOLOv9-C/YOLO-MS相比,YOLOv10-B/M在相同或更好的性能下实现了46%/62%的延迟降低。对于大型模型,与Gold-YOLO-L相比,YOLOv10-L的参数减少了68%,延迟降低了32%,同时AP显著提高了1.4%。此外,与RT-DETR相比,YOLOv10在性能和延迟方面均取得了显著改进。值得注意的是,在相似性能下,YOLOv10-S/X的推理速度分别比RT-DETR-R18/R101快1.8倍和1.3倍。这些结果充分证明了YOLOv10作为实时端到端检测器的优越性。

我们还将YOLOv10与使用原始一对多训练方法的其他YOLO进行了比较。在这种情况下,我们遵循[56, 20, 54],考虑了模型的性能和前向传播过程的延迟(Latencyf)。如表1所示,YOLOv10在不同模型尺寸上也表现出了最先进的性能和效率,这表明了我们架构设计的有效性。
4.3 模型分析
消融研究。我们在表2中基于YOLOv10-S和YOLOv10-M展示了消融结果。可以观察到,我们采用一致双重分配的无NMS训练显著降低了YOLOv10-S的端到端延迟4.63毫秒,同时保持了44.3% AP的竞争性性能。此外,我们的效率驱动模型设计导致YOLOv10-M的参数减少了1180万,浮点运算次数(FLOPs)减少了208亿次,延迟显著降低了0.65毫秒,充分展示了其有效性。进一步地,我们的精度驱动模型设计分别为YOLOv10-S和YOLOv10-M带来了1.8 AP和0.7 AP的显著提升,而延迟开销分别仅为0.18毫秒和0.17毫秒,这很好地证明了其优越性。
无NMS训练分析。
-
双重标签分配。我们为无NMS的YOLO提出了双重标签分配,这可以在训练期间获得一对多(o2m)分支的丰富监督,同时在推理期间利用一对一(o2o)分支实现高效率。我们基于YOLOv8-S(即表2中的#1)验证了其优势。具体来说,我们分别为仅使用o2m分支和仅使用o2o分支的训练引入了基线。如表3所示,我们的双重标签分配实现了最佳的AP-延迟权衡。
-
一致匹配度量。我们引入了一致匹配度量,以使一对一头部与一对多头部更加和谐。我们基于YOLOv8-S(即表2中的#1)在不同αo2o和βo2o下验证了其优势。如表4所示,所提出的一致匹配度量(即αo2o=r·αo2m和βo2o=r·βo2m)可以实现最佳性能,其中一对多头部中的αo2m=0.5且βo2m=6.0[20]。这种改进可以归因于监督差距(公式(2))的减少,这提供了两个分支之间更好的监督对齐。此外,所提出的一致匹配度量消除了对超参数调优的依赖,这在实际场景中非常有用。
效率驱动模型设计分析。我们进行了实验,以逐步将效率驱动的设计元素整合到YOLOv10-S/M中。我们的基线是没有效率-精度驱动模型设计的YOLOv10-S/M模型(即表2中的#2/#6)。如表5所示,每个设计组件(包括轻量级分类头、空间-通道解耦下采样和基于秩的指导块设计)都有助于减少参数数量、浮点运算次数和延迟。重要的是,这些改进是在保持竞争性能的同时实现的。

-
轻量级分类头。我们分析了预测的类别和定位误差对性能的影响,基于表5中YOLOv10-S的#1和#2,类似于[6]。具体来说,我们通过一对一分配将预测与实例进行匹配。然后,我们将预测的类别分数替换为实例标签,从而在没有分类误差的情况下获得APval w/o c。类似地,我们用实例的位置替换预测的位置,从而在没有回归误差的情况下获得APval w/o r。如表6所示,APval w/o r远高于APval w/o ,表明消除回归误差可以实现更大的改进。因此,性能瓶颈更多地在于回归任务。因此,采用轻量级分类头可以在不损害性能的情况下实现更高的效率。
-
空间-通道解耦下采样。我们为了效率而解耦了下采样操作,其中首先通过点卷积(PW)增加通道维度,然后通过深度卷积(DW)降低分辨率以最大限度地保留信息。我们将其与通过DW进行空间降维后通过PW进行通道调制的基线方式进行了比较,基于表5中YOLOv10-S的#3。如表7所示,我们的下采样策略通过在下采样过程中减少信息损失而实现了0.7% AP的改进。
-
紧凑倒置块(CIB)。我们引入了CIB作为紧凑的基本构建块。我们基于表5中YOLOv10-S的#4验证了其有效性。具体来说,我们引入了倒置残差块(IRB)作为基线,其实现了次优的43.7% AP,如表8所示。然后,我们在其后附加了一个3×3深度卷积(DW),表示为“IRB-DW”,这带来了0.5% AP的改进。与“IRB-DW”相比,我们的CIB通过以极小的开销在其前附加另一个DW进一步实现了0.3% AP的改进,表明其优越性。
-
基于秩的指导块设计。我们引入了基于秩的指导块设计,以自适应地整合紧凑块设计来提高模型效率。我们基于表5中YOLOv10-S的#3验证了其优势。基于内在秩按升序排序的阶段为Stage 8-4-7-3-5-1-6-2,如图3(a)所示。如表9所示,当逐渐将每个阶段中的瓶颈块替换为高效的CIB时,我们观察到从Stage 7开始性能开始下降。在内在秩较低且冗余性较高的Stage 8和4中,我们可以采用高效的块设计而不会损害性能。这些结果表明,基于秩的指导块设计可以作为提高模型效率的有效策略。
-
精度驱动模型设计分析。我们展示了基于YOLOv10-S/M逐步集成精度驱动设计元素的结果。我们的基线是在集成了效率驱动设计之后的YOLOv10-S/M模型,即表2中的#3/#7。如表10所示,采用大核卷积和PSA模块在最小延迟增加(分别为0.03毫秒和0.15毫秒)的情况下,为YOLOv10-S带来了显著的性能提升(分别为0.4% AP和1.4% AP)。请注意,YOLOv10-M没有采用大核卷积(见表12)。
-
大核卷积。我们首先基于表10中YOLOv10-S的#2模型研究了不同核大小的影响。如表11所示,随着核大小的增加,性能有所提高,并在核大小约为7×7时趋于稳定,这表明了大感受野的好处。此外,在训练过程中移除重参数化分支会导致0.1% AP的下降,表明其对优化的有效性。此外,我们基于YOLOv10-N/S/M检查了不同模型尺度下大核卷积的好处。如表12所示,对于大型模型(如YOLOv10-M),由于其固有的广泛感受野,大核卷积并未带来改进。因此,我们仅在小模型(如YOLOv10-N/S)中采用大核卷积。
-
部分自注意力(PSA)。我们引入PSA以增强性能,同时以最小成本融入全局建模能力。我们首先基于表10中YOLOv10-S的#3模型验证了其有效性。具体来说,我们引入了变压器块(即MHSA后跟FFN)作为基线,表示为“Trans.”。如表13所示,与基线相比,PSA在延迟减少0.05毫秒的情况下带来了0.3% AP的提升。性能提升可能归因于通过减轻注意力头中的冗余性来缓解自注意力中的优化问题[62, 9]。此外,我们研究了不同NPSA的影响。如表13所示,将NPSA增加到2带来了0.2% AP的提升,但延迟增加了0.1毫秒。因此,我们默认将NPSA设置为1,以增强模型能力同时保持高效率。
5 结论
在本文中,我们针对YOLO检测流程中的后处理和模型架构进行了优化。在后处理方面,我们提出了用于无NMS训练的一致双重分配策略,以实现高效的端到端检测。在模型架构方面,我们引入了整体效率-精度驱动模型设计策略,以改善性能-效率权衡。这些改进带来了YOLOv10,这是一种新的实时端到端目标检测器。大量实验表明,与其他先进检测器相比,YOLOv10在性能和延迟方面均达到了最先进水平,充分展示了其优越性。
相关文章:
YoloV10 论文翻译(Real-Time End-to-End Object Detection)
摘要 近年来,YOLO因其在计算成本与检测性能之间实现了有效平衡,已成为实时目标检测领域的主流范式。研究人员对YOLO的架构设计、优化目标、数据增强策略等方面进行了探索,并取得了显著进展。然而,YOLO对非极大值抑制࿰…...

第R1周:RNN-心脏病预测
本文为🔗365天深度学习训练营 中的学习记录博客 原作者:K同学啊 要求: 1.本地读取并加载数据。 2.了解循环神经网络(RNN)的构建过程 3.测试集accuracy到达87% 拔高: 1.测试集accuracy到达89% 我的环境&a…...

Golang | Leetcode Golang题解之第321题拼接最大数
题目: 题解: func maxSubsequence(a []int, k int) (s []int) {for i, v : range a {for len(s) > 0 && len(s)len(a)-1-i > k && v > s[len(s)-1] {s s[:len(s)-1]}if len(s) < k {s append(s, v)}}return }func lexico…...

远程连接本地虚拟机失败问题汇总
前言 因为我的 Ubuntu 虚拟机是新装的,并且应该装的是比较纯净的版本(纯净是指很多工具都尚未安装),然后在使用远程连接工具 XShell 连接时出现了很多问题,这些都是我之前没遇到过的(因为之前主要使用云服…...
WebRTC 初探
前言 项目中有局域网投屏与文件传输的需求,所以研究了一下 webRTC,这里记录一下学习过程。 WebRTC 基本流程以及概念 下面以 1 对 1 音视频实时通话案例介绍 WebRTC 的基本流程以及概念 WebRTC 中的角色 WebRTC 终端,负责音视频采集、编解码、NAT 穿…...

Python:read,readline和readlines的区别
在Python中,read(), readline(), 和 readlines() 是文件操作中常用的三个方法,它们都用于从文件中读取数据,但各自的使用方式和适用场景有所不同。 read() 方法: read(size-1) 方法用于从文件中读取指定数量的字符。如果指定了si…...

重生之我学编程
编程小白如何成为大神?大学新生的最佳入门攻略 编程已成为当代大学生的必备技能,但面对众多编程语言和学习资源,新生们常常感到迷茫。如何选择适合自己的编程语言?如何制定有效的学习计划?如何避免常见的学习陷阱&…...
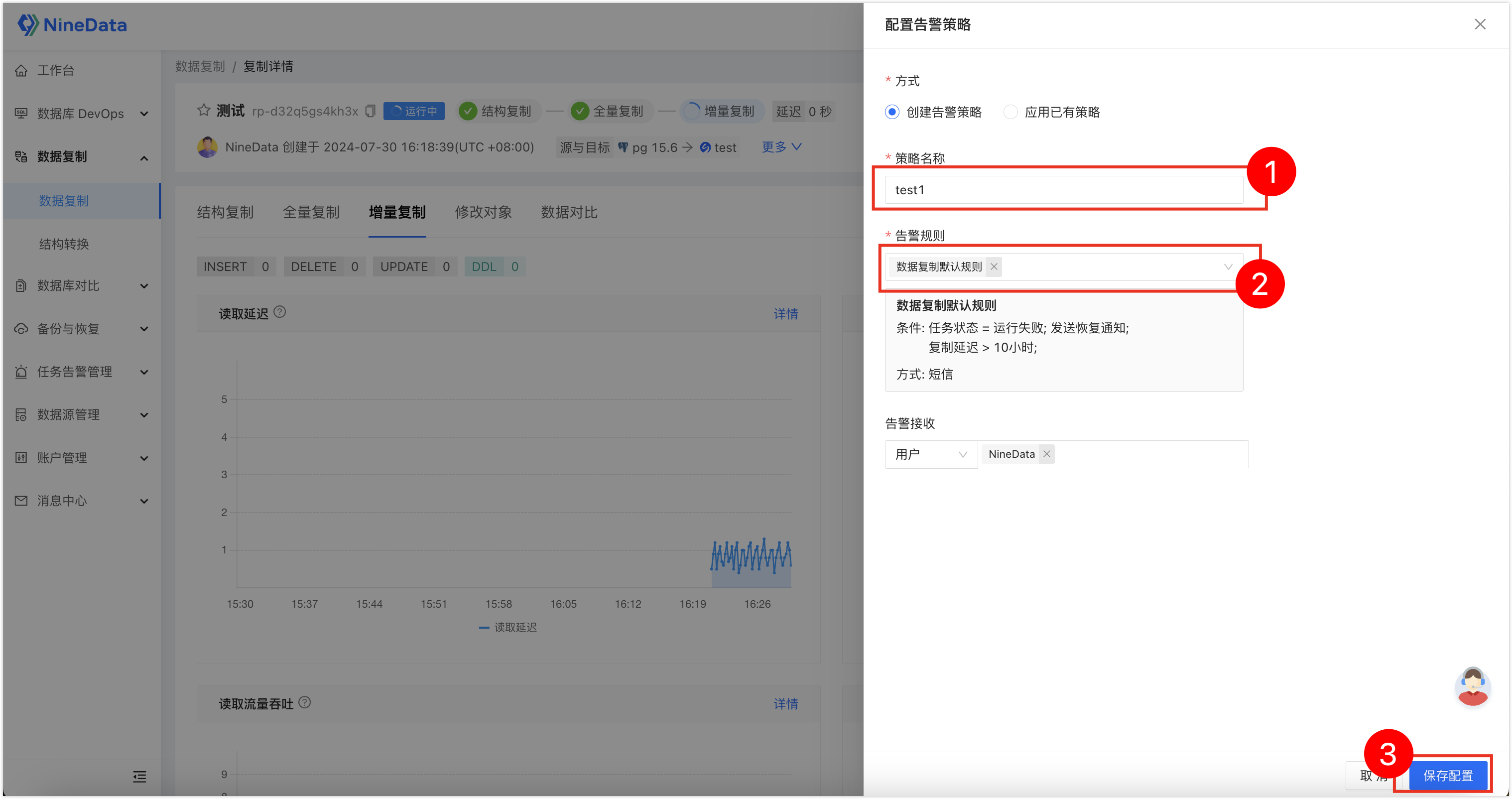
如何将PostgreSQL的数据实时迁移到SelectDB?
PostgreSQL 作为一个开源且功能强大的关系型数据库管理系统,在 OLTP 系统中得到了广泛应用。很多企业利用其卓越的性能和灵活的架构,应对高并发事务、快速响应等需求。 然而对于 OLAP 场景,PostgreSQL 可能并不是最佳选择。 为了实现庞大规…...

关于c语言的const 指针
const * type A 指向的数据是常量 如上所示,运行结果如下,通过解引用的方式,改变了data的值 const type * A 位置是常量,不能修改 运行结果如下 type const * A 指针是个常量,指向的值可以改变 如上所示,…...

万能门店小程序开发平台功能源码系统 带完整的安装代码包以及安装搭建教程
互联网技术的迅猛发展和用户对于便捷性需求的不断提高,小程序以其轻量、快捷、无需安装的特点,成为了众多商家和开发者关注的焦点。为满足广大商家对于门店线上化、智能化管理的需求,小编给大家分享一款“万能门店小程序开发平台功能源码系统…...
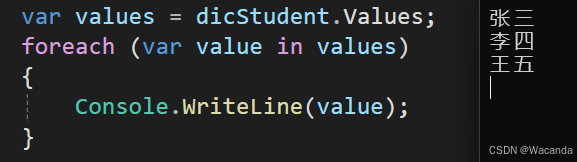
C#初级——字典Dictionary
字典 字典是C#中的一种集合,它存储键值对,并且每个键与一个值相关联。 创建字典 Dictionary<键的类型, 值的类型> 字典名字 new Dictionary<键的类型, 值的类型>(); Dictionary<int, string> dicStudent new Dictionary<int, str…...

git版本控制的底层实现
目录 前言 核心概念串讲 底层存储形式探测 本地仓库的详细解析 提交与分支的深入解析 几个问题的深入探讨 前言 Git的重要性 Git是一个开源的版本控制工具,广泛用于编程开发领域。它极大地提高了研发团队的开发协作效率。对于开发者来说,Git是一个…...

深入解析数据处理的技术与实践
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: 工💗重💗hao💗:野老杂谈 ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、应用领域等内容。 ⭐…...

python-调用c#代码
环境: win10,net framework 4,python3.9 镜像: C#-使用IronPython调用python代码_ironpython wpf-CSDN博客 https://blog.csdn.net/pxy7896/article/details/119929434 目录 hello word不接收参数接收参数 其他例子 hello word 不…...
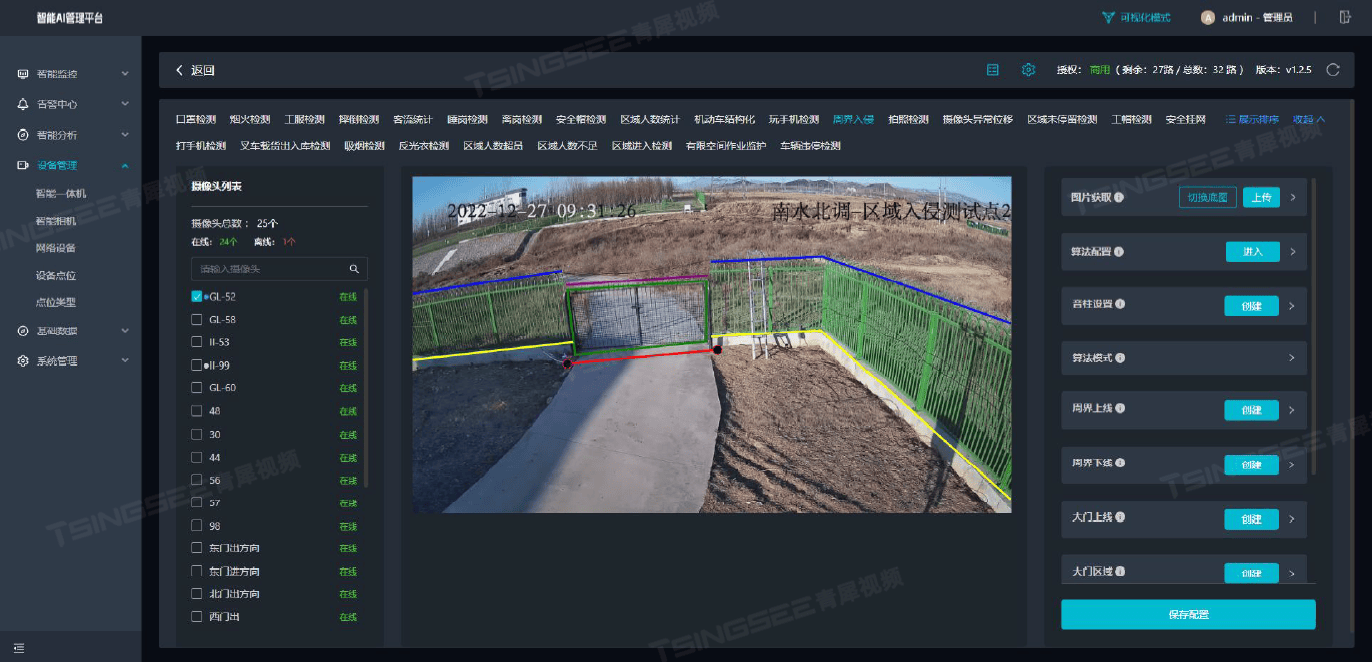
构建铁路安全防线:EasyCVR视频+AI智能分析赋能铁路上道作业高效监管
一、方案背景 随着我国铁路特别是高速铁路的快速发展,铁路运营里程不断增加,铁路沿线的安全环境对保障铁路运输的安全畅通及人民群众的生命财产安全具有至关重要的作用。铁路沿线安全环境复杂多变,涉及多种风险因素,如人员入侵、…...

openai command not found (mac)
题意:mac 系统上无法识别 openai 的命令 问题背景: Im trying to follow the fine tuning guide for Openai here. 我正在尝试遵循 OpenAI 的微调指南 I ran: 我运行以下命令 pip install --upgrade openaiWhich install without any errors.…...

鸿蒙(API 12 Beta2版)NDK开发【LLDB高性能调试器】调试和性能分析
概述 LLDB(Low Level Debugger)是新一代高性能调试器。 当前HarmonyOS中的LLDB工具是在[llvm15.0.4]基础上适配演进出来的工具,是HUAWEI DevEco Studio工具中默认的调试器,支持调试C和C应用。 工具获取 可通过HUAWEI DevEco S…...

HAL库源码移植与使用之DMA
内存到内存不支持传输计数器自动重装 结构: 与DMA具有连线的外设都可以完成搬运 DMA触发源 DMA优先级分配 由仲裁器来决定 寄存器作用: DMA.C #include "./BSP/DMA/dma.h" #include "./SYSTEM/delay/delay.h"DMA_HandleTypeDef…...

Scrapy爬虫框架介绍、创建Scrapy项目
Scrapy官网:https://scrapy.org/ 什么是Scrapy Scrapy 是一个基于 Python 的快速的高级网页抓取和网页爬取框架,用于抓取网站并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。 Scrapy核心组件 1. Scrapy Engin…...
?)
如何监测某个进程是否退出(C++)?
使用WaitForSingleObject函数,可以判断进程是否退出。 WaitForSingleObject函数的作用是:等待直到指定的对象处于信号状态(通知状态)或到达指定的等待时间(超时时间)。 函数声明如下: 1 DWOR…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...