【JVM】垃圾回收机制、算法和垃圾回收器
什么是垃圾回收机制
为了让程序员更加专注于代码的实现,而不用过多的考虑内存释放的问题,所以在Java语言中,有了自动的垃圾回收机制,也是我们常常提及的GC(Garbage Collection)
有了这个垃圾回收机制之后,程序员只需要考虑内存的申请即可,内存的释放由系统自动识别完成。在垃圾回收的时候,不同的对象引用类型,GC会采用不同的回收时机,换句话说自动垃圾回收算法就会变得非常重要,如果因为算法的不合理,导致内存资源一直没有释放,同样也可能导致内存资源一直没有被释放,同样也可能会导致内存溢出
对象什么时候可以被垃圾回收

简单用一句话来说:人如果一个或者多个对象没有任何的引用指向它,那么这个对象现在就是垃圾,如果定位成垃圾,那么就有可能被垃圾回收器回收
如果要定位什么是垃圾,有两种方式来确定,第一个是引用计数法,第二个是可达性分析算法
引用计数法
一个对象被引用一次,在当前对象头上递增一次引用次数 ,如果这个对象的引用次数为0,代表这个对象可以被回收
String demo = new String("123");
String demo = null;
当对象间出现了循环引用的话,则引用计数法就会失效,如下图:

虽然a和b都为null,但是由于a和b存在循环引用,这样a和b永远都不会被回收
引用计数法的优点:
- 实时性较高,无需等到内存不够的时候,才开始回收,运行时根据对象的计数器是否为0,就可以直接回收
- 在垃圾回收过程中,应用无需挂起。如果申请内存时,内存不足,则立刻报OOM错误
- 区域性,更新对象的计数器时,只是影响到该对象,不会扫描全部对象
缺点:
- 每次对象被引用时,都需要去更新计数器,有一点时间开销
- 浪费 CPU 资源,即使内存够用,仍然在运行时进行计数器的统计
- 无法解决循环引用问题,会引发内存泄露 (最大的缺点)
可达性分析算法
现在的虚拟机采用的都是通过可达性分析算法来确定哪些内容是垃圾
首先会存在一个根节点(GC Roots),引出它下面指向的下一个节点,在以下一个节点开始为开始找到它下面的节点,依次往下类推,直到所有节点全部遍历完毕。这个思想类似于算法中的并查集

如上图,X和Y就是GC Roots无法到达的节点,那么X和Y就可以被认为是垃圾
根对象是那些肯定不能当作垃圾回收的对象,就可以当作根对象。一般有四种类型可以选做根对象:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(即一般说的Native方法)引用的对象(不常用)



JVM垃圾回收算法有哪些
刚刚已经讲解完了如何定义垃圾,那么定义完成之后的垃圾有一系列的处理算法
标记清除算法
标记清除算法,是将垃圾回收分为两个阶段,分别是标记和清除
- 根据可达性分析算法得出了垃圾进行标记
- 对这些标记为可回收的内容进行垃圾回收

标记清除算法有一定的劣势:
- 效率比较低,标记和清除两个动作都是需要遍历所有的对象,并且GC的时候,需要停止应用程序,对于交互性要求比较高的应用而言这个不是很推荐
- (重要)通过标记清除算法清理出来的内存,碎片化比较严重,因为被回收的对象可能存在于内存的各个角落,所以清理出来的内存不是很连贯
复制算法
复制算法的核心就是,将原来的内存空间一分为二,每次都是用其中的一块内存。在垃圾回收的时候,将正在使用的对象复制到另一个内存空间中,然后将该内存空间清空,交换两个内存的角色,完成垃圾的
如果内存中的垃圾对象较多,需要复制的对象就较少,这种情况下适合使用该 方式并且效率比较高,反之,则不适合

复制算法的执行流程:
- 将内存区域分成两个部分,每次只是操作其中的一个
- 当进行垃圾回收的时候,将正在使用的内存区域中的存活对象移动到未使用的内存区域。当移动完成之后,对这一部分内存进行一次性清除
优点:
- 在垃圾对象多的情况下,效率较高
- 清理后,内存无碎片
缺点:
- 分配的2块内存空间,在同一个时刻,只能使用一半,内存使用率较低
标记整理算法
标记整理算法是在标记清除算法的基础上,做了优化和改进的算法。和标记清除算法一样,也是从根节点开始,对对象的引用进行标记,在清理阶段,并不是简单的直接清理可回收对象,而是将存活对象都向内存的另一端移动,让然后清理边界以外的垃圾,从而解决了碎片化的问题

标记整理算法的执行流程:
- 标记垃圾
- 需要清楚的向右走,不需要清楚的向左走
- 清除边界以外的垃圾
优缺点:
- 解决了标记清除算法的碎片化的问题
- 标记压缩算法多了一步,对象移动内存位置的步骤,其效率也有有一定的影响
- 复制算法标记完就复制,但标记整理算法得等把所有存活对象 都标记完毕,再进行整理
分代收集算法
在Java8时,堆被分成两份新生代和老年代(1:2),在Java7的时候,还存在一个永久代,Java8将其移动到本地内存的元空间中

对于新生代,内部被分为三个区域:Eden区,两个大小完全相同的survivor区S0(from)和S1(to)(8:1:1)
分代收集算法执行流程:
- 新建的对象都会先分配代eden区,当eden区内存不足的时候,会标记eden区和from区(现阶段还没有)的存活对象

- 将存活下来的对象采用复制算法复制到to中,复制完毕之后,eden和from内存得以释放

- 经过一段时间之后,eden区的内存又不足了,标记eden区和to区存活的对象,将存货的对象复制到from区

- 当幸存区对象熬过几次回收(最多15次),晋升到老年代(幸存区内存不足 或大对象会导致提前晋升)

MinorGC 、 Mixed GC 、 FullGC 的区别是什么
- MinorGC【young GC】发生在新生代的垃圾回收,暂停时间短(STW:暂停所有应用程序线程,等待垃圾回收的完成)
- Mixed GC 新生代 + 老年代部分区域的垃圾回收,G1 收集器特有
- FullGC 新生代 + 老年代完整垃圾回收,暂停时间长(STW),应尽力避免
JVM垃圾回收器有哪些
在JVM中,实现了多种垃圾收集器,包括:
- 串行垃圾收集器
- 并行垃圾收集器
- CMS(并发)垃圾收集器
- G1垃圾收集器
串行垃圾收集器
Serial和Serial Old串行垃圾收集器,是指使用单线程进行垃圾回收,堆内存较小,适合个人电脑
- Serial作用于新生代,曹勇复制算法
- Serial Old作用于年轻代,采用标记-整理算法
垃圾回收时,只有一个线程在工作,并且Java应用中所有线程都要暂停(STW),等待垃圾回收的完成

并行垃圾收集器
Parallel New和Parallel Old是一个并行垃圾回收器,JDK8默认使用此垃圾回收器
- Parallel New作用于新生代,采用复制算法
- Parallel Old作用于老年代,采用标记-整理算法
垃圾回收时,多个线程在工作,并且java应用中的所有线程都要暂停(STW), 等待垃圾回收的完成

CMS (并发)垃圾收集器
CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,该回收器是针对老年代垃圾回收的,是一款以获取最短回收停顿时间为目标的收集器,停顿时间短,用户体验就好。其最大特点是在进行垃圾回收时,应用仍然能正常运行

G1垃圾收集器
应用于新生代和老年代,在JDK9之后默认人使用的G1垃圾收集器。其中划分了很多个区域,每个区域都可以充当eden,survivor,old,humongous,其中humongous专门为大对象准备的。采用的复制算法,并且注重于响应时间和吞吐量。运行时主要是分为三个阶段:新生代回收、并发标记、混合收集。如果出现并发失败(即回收速度赶不上创建新对象的速度),就会触发Full GC

下面来详细的讲解一下年轻代垃圾回收:
- 初始的时候,所有的区域都处于空闲状态

- 创建了一些对象,挑出一些空闲区域作为eden区存储这些对象

- 当eden区需要垃圾回收时,挑出一个空闲区域作为survivor,用复制算法复制存活对象,需要暂停用户线程


- 随着时间流逝,eden区的内存又有不足,将eden区以及之前幸存区中存活的对象,采用复制算法,复制到新的幸存区,其中比较老的对象晋升至老年代



下面来说一下下一个阶段年轻代垃圾回收 + 并发标记:
- 当老年代占用内存超过一定的阈值(默认是45%)后,触发并发标记,这个时候无需暂停用户线程

- 并发标记之后,会有重新标记阶段解决漏标问题,此时需要暂停用户线程
- 这些都完成后就知道了老年代有哪些存活对象,随后进入混合收集阶段。此时不会对所有老年代区域进行回收,而是根据暂停时间目标优先回收价值高 (存活对象少)的区域(这也是 Gabage First 名称的由来)

混合垃圾回收的执行流程:
复制完成,内存得到释放。进入到下一轮的新生代回收、并发标记、混合收集
其中H叫做大对象,如果对象非常大,就会开辟一块连续的空间存储巨型对象
强引用、软引用、弱引用、虚引用的区别
强引用:只有所有 GC Roots 对象都不通过【强引用】引用该对象,该对象才能 被垃圾回收
User user = new User()
软引用:仅有软引用引用该对象时,在垃圾回收后,内存仍不足时会再次出发垃圾回收
User user = new User();
SoftReference softReference = new SoftReference(user); 
弱引用:仅有弱引用引用该对象时,在垃圾回收时,无论内存是否充足,都会回收弱引用对象
User user = new User();
WeakReference weakReference = new WeakReference(user);
虚引用:必须配合引用队列使用,被引用对象回收时,会将虚引用入队,由Reference Handler线程调用虚引用相关方法释放直接内存
User user = new User();
ReferenceQueue referenceQueue = new ReferenceQueue();
PhantomReference phantomReference = new PhantomReference(user,queue);
相关文章:
【JVM】垃圾回收机制、算法和垃圾回收器
什么是垃圾回收机制 为了让程序员更加专注于代码的实现,而不用过多的考虑内存释放的问题,所以在Java语言中,有了自动的垃圾回收机制,也是我们常常提及的GC(Garbage Collection) 有了这个垃圾回收机制之后,程序员只需…...

大数据资源平台建设可行性研究方案(58页PPT)
方案介绍: 在当今信息化高速发展的时代,大数据已成为推动各行各业创新与转型的关键力量。为了充分利用大数据的潜在价值,构建一个高效、安全、可扩展的大数据资源平台显得尤为重要。通过本方案的实施企业可以显著提升数据处理能力、优化资源配置、促进业…...

PHP教育培训小程序系统源码
🚀【学习新纪元】解锁教育培训小程序的无限可能✨ 📚 引言:教育培训新风尚,小程序来引领! Hey小伙伴们,是不是还在为找不到合适的学习资源而烦恼?或是厌倦了传统教育模式的单调?今…...

吴恩达机器学习笔记
1.机器学习定义: 机器学习就是让机器从大量的数据集中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好 2.监督学习: 从给定的训练数据集中学习出一个函数(模型参数)…...

React和Vue3 的 Diff 算法有什么区别
React 和 Vue 3 的 Diff 算法都有相似的目标,即在组件状态或属性变化时高效地更新 DOM,但它们在实现细节上有所不同。以下是 React 和 Vue 3 的 Diff 算法的主要区别: React 的 Diff 算法 1. 同层比较 React 使用的是同层比较策略…...
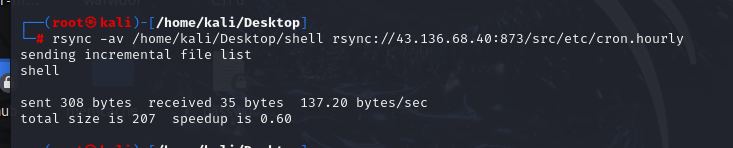
【vulhub靶场之rsync关】
一、使用nmap模块查看该ip地址有没有Rsync未授权访问漏洞 nmap -p 873 --script rsync-list-modules 加IP地址 查看到是有漏洞的模块的 二、使用rsync命令连接并读取文件 查看src目录里面的信息。 三、对系统中的敏感文件进行下载——/etc/passwd 执行命令: rsy…...
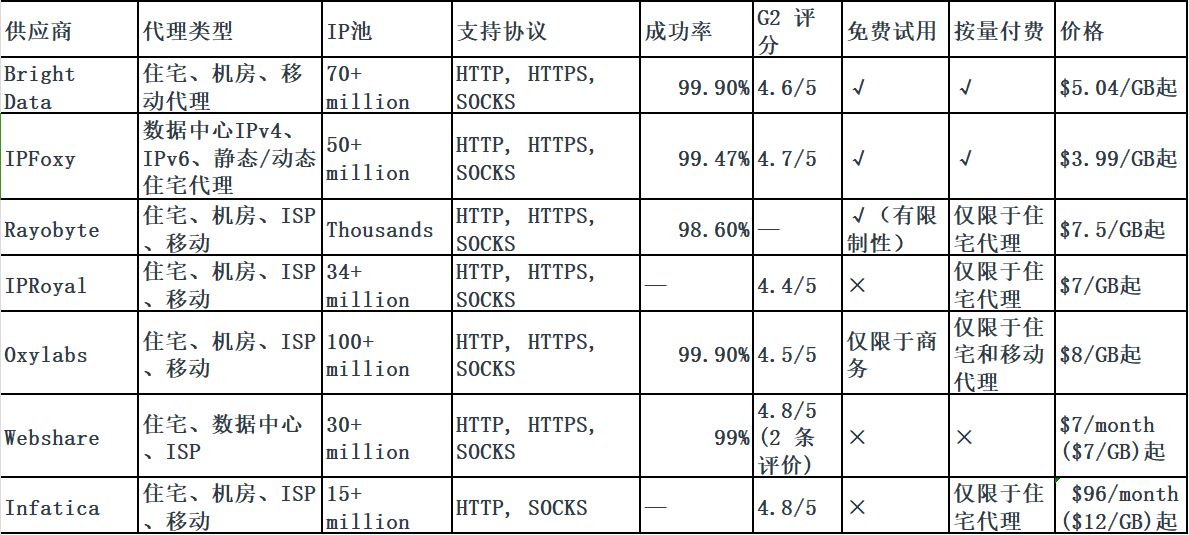
全球7大高质量海外代理IP对比大全
随着国内市场逐渐饱和,越来越多朋友私信我说打算开拓海外市场这片蓝海了!海外代理IP作为解决这些需求的有效工具,帮助跨境企业或团队进行社媒管理、电商运营、市场调研、抓取数据、广告验证等等业务。但是,市场上提供的代理IP服务…...

对于原型链的理解
1.同一个构造函数的多个实例之间 无法共享属性(创建多个实例的时候会造成资源浪费) function Cat(name, color) {this.name name;this.color color;this.meow function () {console.log(miao);}; }var cat1 new Cat(LH, White); var cat2 new Cat(…...

Web开发:Vue中的事件小结
一、全选按钮checkbox <template><div id"checkboxs"><label><input id"selectAll" type"checkbox" v-model"selectAllChecked" change"selectAllItems">全部</label><label v-for"…...

基于Springboot的运行时动态可调的定时任务
配置类 import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;Configuration public class TaskSchedulerConfig {Bean(destroyMe…...

linux perf
perf是Linux性能分析工具的集合,它提供了丰富的命令来收集和分析程序运行时的性能数据。perf能够报告CPU使用率、缓存命中率、分支预测成功率等多种硬件级别的事件,同时也支持软件级别的事件,如页面错误、任务切换等。perf是理解程序性能瓶颈…...

Linux--网络层IP
IP协议 IP协议,全称Internet Protocol(互联网协议),是TCP/IP协议族中的核心协议之一,用于在互联网络上进行数据的传输。IP协议的主要功能是确保数据从一个网络节点(如计算机、服务器、路由器等)…...

浅谈vite之import.meta
一. 解析 开发者使用一个模块时,有时需要知道模板本身的一些信息(比如模块的路径)。现在有一个提案,为 import 命令添加了一个元属性 import.meta,返回当前模块的元信息。 import.meta只能在模块内部使用,如…...

【Pytorch实用教程】Pytorch中nn.Sequential的用法
nn.Sequential 是 PyTorch 中用于构建神经网络的一种容器类,它可以按顺序封装多个子模块(层),并依次将输入数据传递给这些子模块。这样可以简化模型的定义,使得代码更加简洁和易读。 文章目录 基本用法方法一:直接传递子模块方法二:使用 `OrderedDict`动态构建模型优点注…...
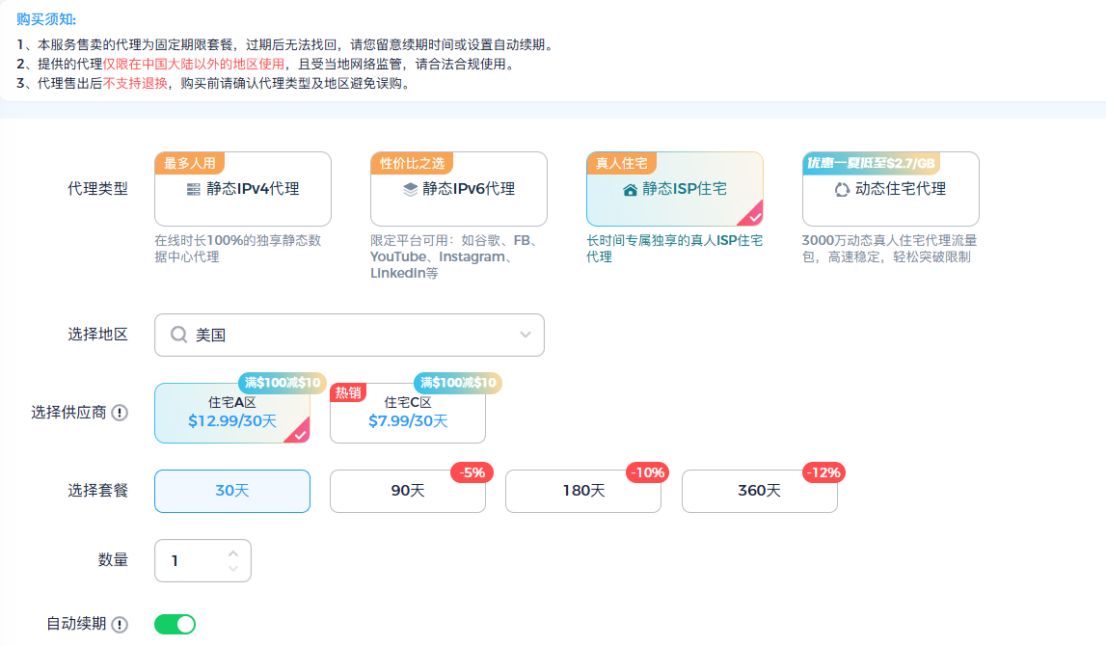
Shopify被封?Shopify店铺开店到防封全面指南
Shopify,作为独立电商建站领域的佼佼者,其SaaS模式简化了建站流程,无需编程背景即可创建线上店铺,吸引了众多商家的目光。本文将详细讲解Shopify店铺从注册、运营到防封的每一个关键环节,为商家提供一站式指导…...
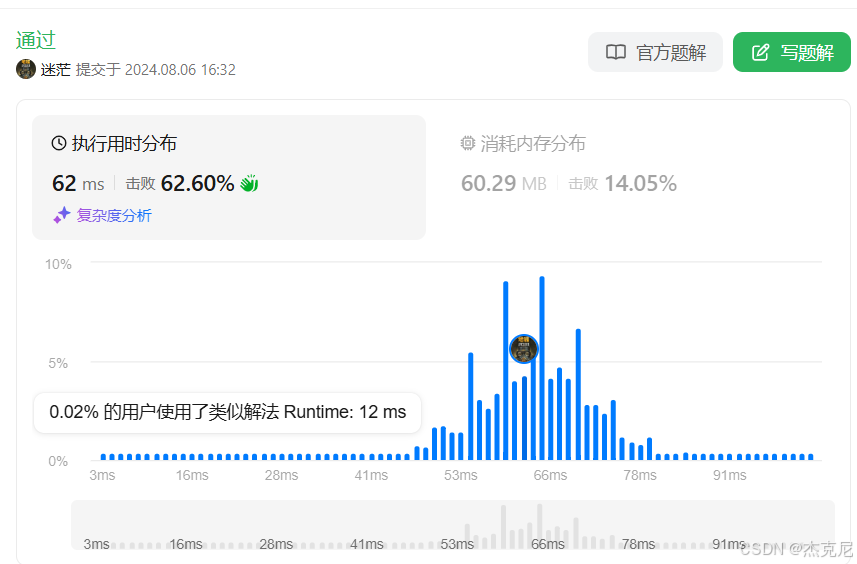
11. 盛最多水的容器
一题目: 二:代码: class Solution { public:int maxArea(vector<int>& height) {int l0;int rheight.size()-1;int ans0;while(l<r){int a(r-l)*min(height[l],height[r]);ansmax(ans,a);if(height[l]<height[r]) l;else r-…...

react如何父子组件传参
在React中,父子组件之间的传参主要通过props(属性)来实现。子组件通过props接收来自父组件的数据,而父组件则可以通过在子组件标签上设置属性(即props)来传递数据。下面是一个简单的例子来说明这个过程。 …...

【C++】二维数组 数组名
二维数组名用途 1、查看所占内存空间 2、查看二维数组首地址 针对第一种用途,还可以计算数组有多少行、多少列、多少元素 针对第二种用途,数组元素、行数、列数都是连续的,且相差地址是有规律的 下面是一个实例 #include<iostream&g…...

【蘑菇书EasyRL】强化学习,笔记整理
【蘑菇书EasyRL】强化学习,笔记整理 1.笔记整理1.1 学习和决策代码框架 2. 遇到的buggym 环境,新版本python无法使用env_specs envs.registry.all() 报错 蘑菇书的教程地址: https://datawhalechina.github.io/easy-rl/#/chapter1/chapter1?…...

尚硅谷谷粒商城项目笔记——三、安装docker【电脑CPU:AMD】
三、安装docker 注意: 因为电脑是AMD芯片,自己知识储备不够,无法保证和课程中用到的环境一样,所以环境都是自己根据适应硬件软件环境重新配置的,这里的虚拟机使用的是VMware。 首先关闭防火墙和安全策略 systemctl…...

Python 批量导出数据库数据至 Excel 文件页
简介 langchain专门用于构建LLM大语言模型,其中提供了大量的prompt模板,和组件,通过chain(链)的方式将流程连接起来,操作简单,开发便捷。 环境配置 安装langchain框架 pip install langchain langchain-community 其中…...

精华贴分享|【实操分享】花了2000块,用AI把A股前600家公司的基本面全筛了一遍
本文来源于量化小论坛策略分享会板块精华帖,作者为皮蛋瘦肉粥,发布于2026年3月20日。以下为精华帖正文:2019年,幻方科技的梁文锋在金牛奖颁奖典礼上说了一段话:"现在量化赚的是技术面流派原来赚的钱,未…...

DOL-CHS-MODS整合包:2024一站式解决方案,3大优势助你轻松体验Degrees of Lewdity
DOL-CHS-MODS整合包:2024一站式解决方案,3大优势助你轻松体验Degrees of Lewdity 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS DOL-CHS-MODS整合包作为Degrees of Lewdity游…...

Java全栈开发工程师面试实录:从基础到高阶的深度技术探讨
Java全栈开发工程师面试实录:从基础到高阶的深度技术探讨 一、开场介绍 面试官(李工):你好,我是李工,目前在一家互联网大厂负责后端架构设计。今天来聊聊你的技术背景和项目经验。 应聘者(张伟&…...

STM32 UART 通信详解
通用异步收发传输器(UART)是STM32微控制器中最基础、最常用的串行通信接口之一。它通过简单的两根信号线(TX和RX)实现全双工异步数据交换,广泛应用于与PC调试、传感器模块、蓝牙/Wi-Fi模块等的通信。一、UART协议基础1…...

Matlab新手也能搞定的MFAC仿真:从侯忠生教授书上的例题4.1代码跑通说起
Matlab新手也能搞定的MFAC仿真:从侯忠生教授书上的例题4.1代码跑通说起 第一次接触无模型自适应控制(MFAC)时,很多人会被各种理论推导吓退。但作为工程师,我们更关心的是如何让代码跑起来,看到实际效果。本…...

力扣第98题:颜色分类
第一部分:问题描述 给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地 对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sort 函数的情况下解决这个问题。…...

Linux设备驱动 -- RTC驱动移植DS1339
查看原理图RTC芯片采用的是DS1339芯片,这是达拉斯半导体公司的一款RTC芯片,使用I2C接口。 芯片接在RK3568的I2C5。 Linux内核支持DS1339 检索linux内核是否支持DS1339芯片驱动。 通过搜索可知到,Linux系统内核中已有达拉斯DS1339的驱动&#…...

Flutter 性能优化:构建流畅的应用体验
Flutter 性能优化:构建流畅的应用体验掌握 Flutter 性能优化的高级技巧,创建流畅、响应迅速的应用。一、性能优化概述 作为一名追求像素级还原的 UI 匠人,我对 Flutter 性能优化有着深入的研究。性能优化是现代应用开发的重要组成部分&#x…...

第02章-操作系统的发展与挑战
第2章 操作系统的发展与挑战 本章目标:从更宏观的视角审视操作系统的发展脉络,深入探讨移动操作系统和嵌入式操作系统的演进,分析现代操作系统面临的核心挑战与新兴技术趋势。 2.1 移动操作系统的演进 第1章我们回顾了操作系统的整体发展历程,本章聚焦于与开源鸿蒙关系最密…...