Elasticsearch VS Typesense! Elasticsearch未来会被其它搜索引擎取代吗?
近期网上流行一批新的搜索引擎,动不动就大言不惭,要跟龙头老大Elasticsearch比,想把Elasticsearch击败。
1. Typesense 太猖狂了,对Elasticsearch极为不敬
如近期炒作很猖狂的Typesense开源搜索引擎,一出来就急着挑战Elasticsearch,我们来看看它的嚣张之处到底在哪?
Typesense 50毫秒完成3200万条数据搜索,这款搜索引擎让ElasticSearch慌了
这算得上开源搜索界的一记重拳!这回可把ElasticSearch打得措手不及了。最近放出了一段视频,展示了一款名为Typesense的开源搜索引擎的恐怖威力:我可以在不到50毫秒的时间内搜索3200万条记录。这个速度简直疯了!。。。。。。。
 看到这里,不少开发者都惊呆了:
看到这里,不少开发者都惊呆了:
"这速度也太离谱了吧?我们的搜索怎么就这么慢呢?"
但是我想说的是:Typesense 就这?
2. Typesense 就这??
Typesense 就这点性能就敢拿出来大言不惭,敢于挑战ES?也太嚣张了吧!!
3. 来看看Elasticsearch吧
ES要用好,确实是一门难能的技术。学习ES,从初学到深入,再到产品级的亿级数据量搜索调优实战,学习曲线是比较陡!!
3.1 什么是Lucene
很多ES爱好者们可能不太清楚这个玩意,其实ES的前身就是Lucene,ES就是基于Lucene(单机版)做出来的集群搜索!
Lucene 其实学习起来不难,只需要理解每个字段有三个配置属性,即index(是否创建索引,选择是后,还需要选择索引类型),tokenizer(是否分词,选择是后还需要选择分词器类型),store(是否存储,若该值是否,index=true,表示不存在,但需要创建索引,用来搜索)即可。其它属性一般都是基于这三个的扩展,抓住主要的,再去做扩展学习就比较轻松!
其它不多说,本人也是ES的爱好者,从2012年接触lucene开始,通过一个具体项目实战,就对lucene有了比较深的了解,lucene当时用的4.0版本(经过了数年的进化,现在都已经9.0版本了),当时就有上亿的IO跟踪记录用的lucene存放,对某些字段创建了索引,硬盘都是普通的机械盘,内存只分配了2G,搜索速度那叫一个快,都是毫秒级返回!几毫秒到几十毫秒,很少超过100毫秒的!
3.2 来看看ES吧
ES的数据量如果不是很大,一般都没什么性能调整,几百万,千把万甚至几千万,就无需做什么调优,基本上保证内存适当大些,查询都是毫秒级,直接完败Typesense 。
只有上了亿级流量数据量了,才有必要考虑对ES做一些性能调优!
如下图,是ES集群搜索,单个节点的流程示意图,从此图得知,ES 的搜索引擎严重依赖于底层的 Filesystem Cache,如果给 Filesystem Cache 更多的内存,尽量让内存可以容纳所有的 IDX Segment File 索引数据文件,那么你在搜索的时候基本都会走内存且性能会非常高。
 **性能差距究竟可以有多大?**我们之前很多的测试和压测,如果走磁盘一般肯定上秒,搜索性能绝对是秒级别的,1 秒、5 秒、10 秒。但如果走 Filesystem Cache,则是走纯内存的,那么一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等。
**性能差距究竟可以有多大?**我们之前很多的测试和压测,如果走磁盘一般肯定上秒,搜索性能绝对是秒级别的,1 秒、5 秒、10 秒。但如果走 Filesystem Cache,则是走纯内存的,那么一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等。
3.3 ES亿级数据调优实战
真实场景
某个公司 ES 节点有 3 台机器,每台机器看起来内存很多(64G),总内存就是 64 * 3 = 192G。
每台机器给 ES JVM Heap 是 32G,那么剩下来留给 Filesystem Cache 的就是每台机器才 32G,总共集群里给 Filesystem Cache 的就是 32 * 3 = 96G 内存。
而此时,整个磁盘上索引数据文件,在 3 台机器上一共占用了 1T 的磁盘容量,ES 数据量是 1T,那么每台机器的数据量是 300G。这样性能好吗?
场景分析
Filesystem Cache 的内存才 100G,十分之一的数据可以放内存,其它的都在磁盘,然后你执行搜索操作,大部分操作都是走磁盘,性能肯定差。
优化方案
根据我们自己的生产环境实践经验,最佳的情况下,是仅仅在 ES 中就存少量的数据,就是你要用来搜索的那些索引,如果内存留给 Filesystem Cache 的是 100G,那么你就将索引数据控制在 100G 以内即可。这样,你的数据几乎全部走内存来搜索,性能非常之高,一般可以在1秒以内。
比如,你现在有一行数据:id,name,age … 30 个字段。但是你现在搜索,只需要根据 id,name,age 三个字段来搜索。如果你傻乎乎往 ES 里写入一行数据所有的字段,就会导致 90% 的数据无法用来搜索。
结果硬是占据了 ES 机器上的 Filesystem Cache 的空间,单条数据的数据量越大,就会导致 Filesystem Cahce 能缓存的数据就越少。
其实,仅仅写入 ES 中要用来检索的少数几个字段就可以了,比如写入 es id,name,age 三个字段。
然后你将其他的字段数据存在 MySQL/HBase 里,我们一般是建议用 ES + HBase 这个架构。
HBase 的特点是适用于海量数据的在线存储,就是对 HBase 可以写入海量数据,但是不要做复杂的搜索,做很简单的一些根据 id 或者范围进行查询的操作就可以了。
从 ES 中根据 name 和 age 去搜索,拿到的结果可能就 20 个 doc id,然后根据 doc id 到 HBase 里去查询每个 doc id 对应的完整的数据,查出来后再返回给前端。
**写入 ES 的数据最好小于等于,或者是略微大于 ES 的 Filesystem Cache 的内存容量。**你从 ES 检索可能只花费 20ms,然后再根据 ES 返回的 id 去 HBase 里查询,查 20 条数据,可能只耗费 30ms。
可能你原来那么玩儿,1T 数据都放 ES,会每次查询都是 5~10s,现在可能性能就会很高,每次查询就是 50ms。
4. Elasticsearch 的未来及其对搜索引擎行业的影响
Elasticsearch 是一个开源搜索引擎和分析平台,近年来越来越受欢迎。凭借其近乎实时地索引和搜索大量数据的能力,Elasticsearch 已成为许多企业和组织的首选解决方案。随着技术的不断发展,Elasticsearch 的未来一片光明,它对搜索引擎行业的影响预计将是巨大的。
推动 Elasticsearch 未来发展的关键趋势之一是大数据的持续增长。随着越来越多的数据生成,组织正在寻找实时处理和分析数据的方法。Elasticsearch 提供了一种解决方案,使组织能够快速搜索、分析和可视化大量数据。这将继续推动 Elasticsearch 的采用,并可能导致开发新的用例。
塑造 Elasticsearch 未来的另一个趋势是云的增长。随着云计算的日益普及,组织正在寻找将其数据和应用程序迁移到云的方法。Elasticsearch 提供了一种可以轻松部署在云中的云原生解决方案,使其成为许多组织的有吸引力的选择。
人工智能 (AI) 和机器学习 (ML) 也有望在 Elasticsearch 的未来中发挥重要作用。凭借索引和搜索大量数据的能力,Elasticsearch 为构建 AI 和 ML 应用程序提供了一个宝贵的平台。例如,Elasticsearch 可用于构建推荐系统、预测模型等。
Elasticsearch 的未来也可能受到边缘计算增长的影响。随着设备和传感器数量的增加,组织正在寻找在靠近源头的边缘处理数据的方法。Elasticsearch 为此提供了解决方案,使组织能够在边缘索引和搜索数据,从而减少延迟并提高性能。
Elasticsearch 现在在做什么?
Elasticsearch 在数据库领域以多种有趣的方式颠覆了传统数据库。由于 Elasticsearch 并非旨在成为应用程序的主要数据库(如 MySQL 或 MongoDB),因此它具有更大的扩展灵活性,这是典型数据库产品无法做到的。Elastic 似乎正在采用“广泛”增长模式来扩大其用户群并创新 Elastic 堆栈。他们创建了Elasticsearch 有价值的其他用例,并开始蚕食其他数据库技术的市场份额。他们扫荡了 MongoDB、MySQL 和其他解决方案未能关注的所有边缘领域。
5. Elasticsearch 与 Typesense:有什么区别?
Elasticsearch 和 Typesense 都是非常流行的搜索和数据检索解决方案。让我们来探讨一下它们之间的主要区别。
5.1 可扩展性
Elasticsearch 的设计具有高度可扩展性,可通过向集群添加更多节点来实现水平扩展。它可以处理大量数据,并在需要时扩展到数千台服务器。另一方面,Typesense 构建为轻量级,并针对低资源消耗进行了优化。它是小型部署或资源效率优先考虑时的理想选择。
5.2 查询
Elasticsearch 提供强大而灵活的查询 DSL(领域特定语言),允许进行复杂的查询和聚合。它还高效地支持全文搜索、过滤和排序。另一方面,Typesense 提供了简化的查询语法,使其更易于使用和理解。它针对简单的搜索用例进行了优化,可能无法提供与 Elasticsearch 相同级别的灵活性。
5.3 无模式与基于模式
Elasticsearch 无模式,这意味着它可以处理同一索引内不同结构的文档。这种灵活性在处理非结构化数据时非常有用。相比之下,Typesense 采用基于模式的方法,其中文档必须遵循预定义的模式。这可确保数据一致性和更高效的索引,但在处理动态或不断发展的数据结构时可能会受到限制。
5.4 索引速度
Elasticsearch 针对快速索引数据进行了优化。它可以处理高写入负载,并且可以近乎实时地索引数据。这使得它适合需要频繁更新索引的用例。Typesense 虽然也具有良好的索引性能,但在高写入场景中可能不如 Elasticsearch 快。
5.5 内置功能
Elasticsearch 具有各种内置功能,如地理位置搜索、语言分析器和对父子关系的支持。它还拥有强大的插件和集成生态系统。另一方面,Typesense 专注于提供轻量级且易于使用的搜索引擎,内置功能较少。它可能需要额外的定制或与外部库集成才能实现某些功能。
5.6 社区和采用
Elasticsearch 存在时间较长,拥有较大的社区和用户群。它已被企业广泛采用,并且拥有更成熟的生态系统。Typesense 作为市场上的新玩家,社区可能较小,可用资源也较少。
5.7 学习曲线
ElasticSearch是比较著名的搜索引擎,您可能知道它是一种非常强大的工具,但它也很复杂,学习难度很高,曲线陡峭。例如,在内部部署 ElasticSearch 时,您将面临高昂的生产操作开销,需要处理超过 3000 个配置参数。
Typesense用 C++ 编写,是 ElasticSearch 的一个更易于使用的替代品。社区将其描述为一个开源、快速、容错且易于使用的搜索引擎。
6. 总结
综上所述,Elasticsearch 的未来前景光明,预计其对搜索引擎行业的影响将是巨大的。凭借实时索引和搜索大量数据的能力,Elasticsearch 完全有能力在大数据、云计算、人工智能和边缘计算的持续增长中发挥关键作用。现在采用 Elasticsearch 的公司将能够充分利用这些趋势,并可能在未来几年获得巨大的收益。
总而言之,Elasticsearch 提供可扩展性、强大的查询功能、无模式结构、快速索引、更广泛的内置功能和更大的社区。
另一方面,Typesense 专注于轻量级、资源高效、易于使用、基于模式并针对简单搜索用例进行量身定制。
相关文章:
Elasticsearch VS Typesense! Elasticsearch未来会被其它搜索引擎取代吗?
近期网上流行一批新的搜索引擎,动不动就大言不惭,要跟龙头老大Elasticsearch比,想把Elasticsearch击败。 1. Typesense 太猖狂了,对Elasticsearch极为不敬 如近期炒作很猖狂的Typesense开源搜索引擎,一出来就急着挑战…...

usb摄像头 按钮 静止按钮
usb摄像头 按钮 静止按钮 来分析一个UVC的摄像头的枚举信息 UVC学习:UVC中断端点介绍 https://www.eet-china.com/mp/a269529.html 输入命令lsusb -d 0c45:62f1 -v https://www.miaokee.com/705548.html >Video Class-Specific VS Video Input Header Descrip…...

SAP MM学习笔记 - 豆知识03 - 安全在库和最小安全在库,扩张物料的保管场所的几种方法,定义生产订单的默认入库保管场所,受注票中设定禁止贩卖某个物料
上一章讲了一些MM模块的豆知识。 - MR21 修改物料原价 - MM02 修改基本数量单位/评价Class - MMAM 修改物料类型/评价Class SAP MM学习笔记 - 豆知识02 - MR21 修改物料原价,MM02 修改基本数量单位/评价Class,MMAM 修改物料类型/评价Class-CSDN博客 …...

激光导航AGV叉车那么多,究竟该怎么选?一篇文章讲明白~
AGV叉车 随着经济的快速发展,大部分企业的物料搬运开始脱离人工劳作,取而代之的是以叉车为主的机械化搬运。AGV叉车是工业搬运车辆,是指对成件托盘货物进行装卸、堆垛和短距离运输作业的各种轮式搬运车辆,主要应用于货场、工厂车间…...

redis面试(七)初识lua加锁脚本
redisson redisson如何来进行redis分布式锁实现的源码,基于redis实现各种各样的分布式锁的原理 https://redisson.org/ 这是官网 https://github.com/redisson/redisson/wiki/Table-of-Content 这是官方文档 开始 demo 建一个普通的工程在pom.xml里引入依赖 <…...

企元数智百年营销史的精粹:借鉴历史创造未来商机
随着时代的发展和科技的进步,传统营销方式正在经历前所未有的颠覆和改变。在这个数字化时代,企业需要不断创新,同时借鉴百年营销史的精粹,汲取历史经验,创造未来商机。而"企元数智"作为现代营销的代表&#…...

Java @SpringBootTest注解用法
SpringBootTest 是 Spring Framework 中的一个注解,用于指示 Spring Boot 应用程序的测试类。当你在测试类上使用 SpringBootTest 注解时,Spring Boot 会启动一个 Spring 应用程序上下文,并且加载应用程序的 application.properties 或 appli…...

构建智能招聘平台:人才招聘系统源码开发指南
本篇文章,小编将详细探讨如何基于人才招聘系统源码开发一个智能招聘平台,为企业的人才战略提供支持。 一、智能招聘平台的核心功能 智能招聘平台的核心在于提高招聘效率和匹配度,这需要集成多个关键功能模块: 1.职位发布与管理…...

Docker + Nacos + Spring Cloud Gateway 实现简单的动态路由配置修改和动态路由发现
1.环境准备 1.1 拉取Nacos Docker镜像 从Docker Hub拉取Nacos镜像: docker pull nacos/nacos-server:v2.4.01.2 生成密钥 你可以使用命令行工具生成一个不少于32位的密钥。以下是使用 OpenSSL 生成 32 字节密钥的示例: openssl rand -base64 321.3 …...
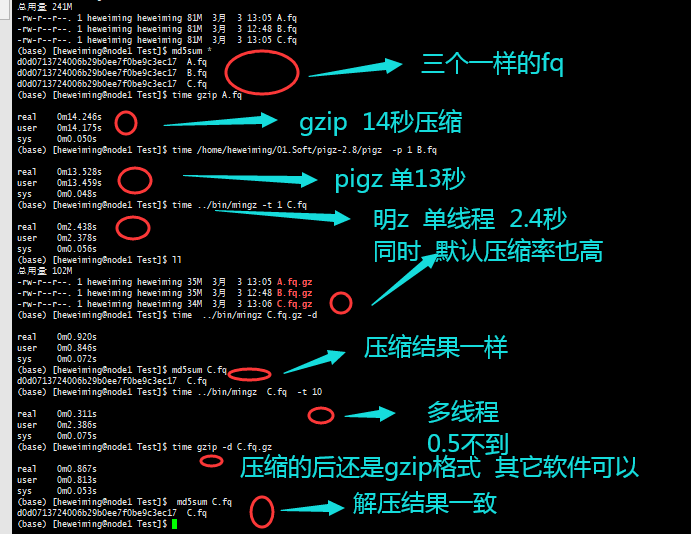
Linux中多线程压缩软件 | Mingz
原文链接:Linux中多线程压缩软件 本期教程 软件网址: https://github.com/hewm2008/MingZ安装: git clone https://github.com/hewm2008/MingZ.git cd MingZ make cd bin ./mingz -h使用源码安装: 若是你的git无法使用安装&am…...

【JavaEE精炼宝库】网络原理基础——UDP详解
文章目录 一、应用层二、传输层2.1 端口号:2.2 UDP 协议:2.2.1 UDP 协议端格式:2.2.2 UDP 存在的问题: 2.3 UDP 特点:2.4 基于 UDP 的应用层协议: 一、应用层 我们 Java 程序员在日常开发中,最…...

【回眸】周中WLB-个人
生活 计划 苏州or杭州or舟山 负负得正 烟火 鲜芋仙 办上海银行的银行卡 申请表材料准备好 个人博客提现签约变现 个人提升 yas补直播笔记(听、口)1~3课 *2倍 dy学堂 —— 3课时输出博客 个人笔记本搭建环境 副业探索 收集信息差 目前已…...

基于Spring boot + Vue的灾难救援系统
作者的B站地址:程序员云翼的个人空间-程序员云翼个人主页-哔哩哔哩视频 csdn地址:程序员云翼-CSDN博客 1.项目技术栈: 前后端分离的项目 后端:Springboot MybatisPlus 前端:Vue ElementUI 数据库: …...

C#进阶:轻量级ORM框架Dapper详解
C#进阶:轻量级ORM框架Dapper详解 在C#开发中,ORM(对象关系映射)框架是处理数据库交互的重要工具。Dapper作为一个轻量级的ORM框架,专为.NET平台设计,因其高性能和易用性而备受开发者青睐。本文将详细介绍D…...

【python015】常见成熟AI-图像识别场景算法清单(已更新)
1.欢迎点赞、关注、批评、指正,互三走起来,小手动起来! 【python015】常见成熟AI-图像识别场景算法清单及代码【python015】常见成熟AI-图像识别场景算法清单及代码【python015】常见成熟AI-图像识别场景算法清单及代码 文章目录 1.背景介绍2…...
删除有序数组中的重复项(LeetCode)
题目 给你一个 升序排列 的数组 ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 中唯一元素的个数。 考虑 的唯一元素的数量为 ,你需要做以下事情确…...

【算法 03】雇佣问题
“雇用问题”及其算法优化 在日常生活和工作中,我们经常会遇到需要从多个选项中做出选择的情况,而“雇用问题”正是这样一个典型的例子。在这个问题中,我们不仅要考虑如何高效地找到最佳候选人,还要关注整个过程中的成本。今天&a…...

vue3+axios请求导出excel文件
在Vue 3中使用axios请求导出Excel文件,可以发送一个GET或POST请求,并设置响应类型为blob或arraybuffer,然后使用new Blob()构造函数创建一个二进制文件,最后使用URL.createObjectURL()生成一个可以下载的链接。 先看代码 import…...

LLM与NLP
大语言模型与自然语言处理的关系:整体与组成的关系如 自然语言理解的编码器式(encoder-only)的架构是语境相关的词表示BERT; 自然语言转换的编码器-解码器式的(encoder-decoder)的架构是词频-逆文档词频T…...

js 判断是否为回文串
需求:忽略英文大小写和空格差异,判断是否为回文字符串(例如"我爱你 你爱我","abc bA") 思路:利用翻转字符串比较,利用循环双指针,利用递归或者双循环…...

Qt播放MP4视频时,如何优雅地处理播放列表和播放模式?一个实战案例分享
Qt播放MP4视频时如何优雅处理播放列表与播放模式 在开发多媒体应用时,播放列表管理和播放模式切换往往是比基础播放功能更具挑战性的部分。本文将深入探讨如何在Qt框架下构建一个健壮的MP4播放器,重点解决播放列表的智能管理和多种播放模式的优雅实现。…...

高效整合B站缓存:智能合并技术让离线观看体验升级
高效整合B站缓存:智能合并技术让离线观看体验升级 【免费下载链接】BilibiliCacheVideoMerge 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCacheVideoMerge 问题溯源:当缓存视频遭遇"数字拆分"困境 解码用户痛点࿱…...

通义实验室正式开源 Mobile-Agent v3.5 及新一代多平台 GUI Agent 基座模型 GUI-Owl-1.5
做过自动化的人都知道,最让人抓狂的不是功能实现不了,而是流程跑到一半突然卡住——界面变了、元素找不到、验证码弹出来……GUI Agent 在实验室里跑得再顺,一到真实环境就各种翻车。通义实验室这次发布的 Mobile-Agent v3.5,瞄准…...

快速上手Qwen3-ASR-0.6B:无需代码基础,Gradio界面点点鼠标就能用
快速上手Qwen3-ASR-0.6B:无需代码基础,Gradio界面点点鼠标就能用 1. 零门槛语音识别体验 语音识别技术正在改变我们与设备交互的方式,但对于非技术人员来说,部署和使用专业模型往往存在门槛。Qwen3-ASR-0.6B通过预置的Gradio界面…...

实时手机检测-通用开源模型教程:如何贡献PR至ModelScope社区
实时手机检测-通用开源模型教程:如何贡献PR至ModelScope社区 1. 项目简介与核心价值 实时手机检测-通用是一个基于DAMO-YOLO框架的高性能目标检测模型,专门用于快速准确地识别图像中的手机设备。这个模型在精度和速度方面都超越了传统的YOLO系列方法&a…...

Windows Android子系统全栈指南:从技术原理到实战应用
Windows Android子系统全栈指南:从技术原理到实战应用 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 价值定位:打破系统边界的跨平台…...

HC32F460串口DMA发送中断接收避坑指南:静电干扰、丢字节问题与中断配置详解
HC32F460串口通信实战:DMA发送与中断接收的深度优化指南 在华大HC32F460系列MCU的实际应用中,串口通信作为最基础也最关键的通信接口之一,其稳定性和效率直接影响整个系统的可靠性。不同于STM32等传统MCU的固定中断映射机制,HC32F…...

FPGA图像处理避坑指南:实现CLAHE时,你的直方图统计与插值模块可能踩的这些雷
FPGA图像处理避坑指南:CLAHE实现中的直方图统计与插值模块陷阱解析 第一次在FPGA上实现CLAHE算法时,我盯着屏幕上那些奇怪的边界伪影和忽明忽暗的色块,整整三天没想明白问题出在哪。直到把示波器接到开发板上,才发现直方图统计模块…...

从零学NLP:自然语言处理完整学习路线
从零学NLP:自然语言处理完整学习路线 标签:#自然语言处理、#人工智能、#大模型、#大模型实战、#transformer、#机器学习、#深度学习 自然语言处理行业价值、核心应用场景 2026年,自然语言处理(NLP)已是AI最普适的技术&…...

零门槛掌握《经济研究》LaTeX模板:从排版小白到学术专家的蜕变指南
零门槛掌握《经济研究》LaTeX模板:从排版小白到学术专家的蜕变指南 【免费下载链接】Chinese-ERJ 《经济研究》杂志 LaTeX 论文模板 - LaTeX Template for Economic Research Journal 项目地址: https://gitcode.com/gh_mirrors/ch/Chinese-ERJ 在学术写作的…...