数据清洗与预处理:确保数据质量的关键步骤
数据清洗与预处理:确保数据质量的关键步骤
引言
在大数据时代,数据已成为企业最宝贵的资产。然而,数据的质量直接影响到分析结果和决策的准确性。数据清洗与预处理是确保数据质量的关键步骤,它们包括识别和处理数据中的错误、缺失值、重复数据等问题。本文将详细探讨数据清洗与预处理的重要性、常用技术和工具,并提供具体的代码示例,帮助读者掌握这些关键步骤。
数据清洗的重要性
数据清洗是数据处理的首要步骤,其主要目的是去除数据中的噪声和错误,提高数据质量。数据清洗的重要性体现在以下几个方面:
- 提高数据的准确性:原始数据中常包含错误和异常值,清洗后的数据能够更准确地反映实际情况。
- 提升数据的一致性:不同来源的数据可能格式不一,通过数据清洗可以统一数据格式。
- 减少数据冗余:清洗过程能够识别并删除重复数据,减小数据量,提高处理效率。
- 增强数据完整性:通过处理缺失值和异常值,确保数据的完整性和可靠性。
数据预处理的步骤
数据预处理是数据分析中的关键步骤,通常包括以下几个环节:
- 数据收集:从不同数据源收集原始数据。
- 数据检查:检查数据的基本情况,识别缺失值、异常值和重复数据等问题。
- 数据清洗:处理缺失值、异常值、重复数据和噪声数据。
- 数据转换:对数据进行格式转换、标准化、归一化等处理。
- 数据集成:将多个数据源的数据集成在一起,形成完整的数据集。
- 数据缩减:通过特征选择、特征提取等方法减少数据维度,提高处理效率。
数据清洗的技术和方法
1. 缺失值处理
缺失值是数据集中常见的问题,处理方法主要有以下几种:
- 删除法:直接删除包含缺失值的记录或特征。
- 填充法:使用均值、中位数、众数或其他统计量填充缺失值。
- 插值法:利用相邻数据点进行插值填充。
- 预测法:利用机器学习算法预测缺失值。
示例代码(Python):
import pandas as pd
from sklearn.impute import SimpleImputer# 创建示例数据集
data = {'A': [1, 2, None, 4, 5],'B': [None, 2, 3, None, 5],'C': [1, None, 3, 4, 5]}
df = pd.DataFrame(data)# 填充法示例:使用均值填充缺失值
imputer = SimpleImputer(strategy='mean')
df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)print("原始数据:\n", df)
print("填充后数据:\n", df_imputed)
2. 异常值处理
异常值(Outliers)是指与其他数据点显著不同的数据。常见的处理方法包括:
- 删除法:直接删除异常值。
- 替换法:用统计量或合理值替换异常值。
- 变换法:对数据进行对数变换或平方根变换,减小异常值的影响。
- 聚类法:使用聚类算法识别并处理异常值。
示例代码(Python):
import numpy as np# 生成示例数据
data = {'A': [1, 2, 3, 4, 100],'B': [5, 6, 7, 8, 9]}
df = pd.DataFrame(data)# 使用Z-score法识别和处理异常值
from scipy import stats
z_scores = np.abs(stats.zscore(df))
threshold = 3
df_cleaned = df[(z_scores < threshold).all(axis=1)]print("原始数据:\n", df)
print("清洗后数据:\n", df_cleaned)
3. 重复数据处理
重复数据会导致冗余和误差,常见的处理方法包括:
- 删除重复记录:直接删除完全相同的记录。
- 合并重复记录:根据某些规则合并重复记录,如取平均值或最大值。
示例代码(Python):
# 创建示例数据集
data = {'A': [1, 2, 2, 4, 5],'B': [1, 2, 2, 4, 5]}
df = pd.DataFrame(data)# 删除重复记录
df_cleaned = df.drop_duplicates()print("原始数据:\n", df)
print("清洗后数据:\n", df_cleaned)
4. 噪声数据处理
噪声数据是指随机的、无规律的数据,会影响分析结果。处理方法包括:
- 平滑法:使用移动平均、加权平均等方法平滑数据。
- 过滤法:使用滤波器去除噪声数据。
- 聚类法:使用聚类算法识别并去除噪声数据。
示例代码(Python):
import matplotlib.pyplot as plt# 生成示例数据
data = [1, 2, 3, 4, 100, 6, 7, 8, 9]# 使用移动平均平滑数据
window_size = 3
smoothed_data = pd.Series(data).rolling(window=window_size).mean()plt.plot(data, label='原始数据')
plt.plot(smoothed_data, label='平滑后数据', color='red')
plt.legend()
plt.show()
数据转换的技术和方法
1. 数据格式转换
数据格式转换是指将数据从一种格式转换为另一种格式,以便后续处理。常见的格式转换包括:
- 字符串到数值:将字符串类型的数据转换为数值类型。
- 时间格式转换:将字符串类型的日期时间转换为标准的日期时间格式。
- 类别编码:将类别型数据转换为数值型数据。
示例代码(Python):
# 创建示例数据集
data = {'date': ['2021-01-01', '2021-02-01', '2021-03-01'],'category': ['A', 'B', 'A']}
df = pd.DataFrame(data)# 时间格式转换
df['date'] = pd.to_datetime(df['date'])# 类别编码
df['category'] = df['category'].astype('category').cat.codesprint("转换后数据:\n", df)
2. 数据标准化
数据标准化是将数据转换为均值为0,标准差为1的分布。常见方法有:
- Z-score标准化:通过减去均值并除以标准差实现标准化。
- Min-Max标准化:将数据缩放到0和1之间。
示例代码(Python):
from sklearn.preprocessing import StandardScaler, MinMaxScaler# 创建示例数据集
data = {'A': [1, 2, 3, 4, 5],'B': [5, 6, 7, 8, 9]}
df = pd.DataFrame(data)# Z-score标准化
scaler = StandardScaler()
df_standardized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)# Min-Max标准化
scaler = MinMaxScaler()
df_minmax = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)print("原始数据:\n", df)
print("Z-score标准化后数据:\n", df_standardized)
print("Min-Max标准化后数据:\n", df_minmax)
3. 数据归一化
数据归一化是将数据缩放到特定范围,如[0,1]或[-1,1]。常见方法有:
- Min-Max归一化:将数据缩放到指定范围。
- 对数归一化:对数据取对数后归一化。
示例代码(Python):
# Min-Max归一化
df_normalized = pd.DataFrame(MinMaxScaler().fit_transform(df), columns=df.columns)# 对数归一化
df_log_normalized = np.log1p(df_normalized)print("Min-Max归一化后数据:\n", df_normalized)
print("对数归一化后数据:\n", df_log_normalized)
数据集成与数据缩减
数据集成
数据集成是将多个数据源的数据合并为一个统一的数据集,常见方法有:
- 数据合并:通过连接操作将不同数据源的数据合并在一起。
- **
数据汇总**:对数据进行汇总和聚合操作。
示例代码(Python):
# 创建示例数据集
data1 = {'id': [1, 2, 3],'value1': [10, 20, 30]}
data2 = {'id': [1, 2, 4],'value2': [100, 200, 400]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)# 数据合并
df_merged = pd.merge(df1, df2, on='id', how='outer')print("合并后数据:\n", df_merged)
数据缩减
数据缩减是通过特征选择、特征提取等方法减少数据维度,提高处理效率。常见方法有:
- 主成分分析(PCA):通过线性变换将高维数据映射到低维空间。
- 特征选择:选择对分析最有用的特征,删除冗余特征。
示例代码(Python):
from sklearn.decomposition import PCA# 生成示例数据
data = {'A': [1, 2, 3, 4, 5],'B': [5, 6, 7, 8, 9],'C': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)# 主成分分析(PCA)
pca = PCA(n_components=2)
df_pca = pd.DataFrame(pca.fit_transform(df), columns=['PC1', 'PC2'])print("原始数据:\n", df)
print("PCA后数据:\n", df_pca)
总结
数据清洗与预处理是数据分析中至关重要的步骤,通过处理缺失值、异常值、重复数据和噪声数据,提高数据的质量和可靠性。同时,数据格式转换、标准化、归一化等技术有助于数据的一致性和可用性。通过数据集成和数据缩减,可以有效地整合多源数据并简化数据维度,提高数据处理的效率。希望本文提供的技术和代码示例能够帮助读者更好地掌握数据清洗与预处理的关键步骤,确保数据质量,为后续的数据分析和决策提供可靠的基础。
相关文章:

数据清洗与预处理:确保数据质量的关键步骤
数据清洗与预处理:确保数据质量的关键步骤 引言 在大数据时代,数据已成为企业最宝贵的资产。然而,数据的质量直接影响到分析结果和决策的准确性。数据清洗与预处理是确保数据质量的关键步骤,它们包括识别和处理数据中的错误、缺…...

《PostgreSQL 数据库在国内的发展前景》
从DB-engines这张2024年8月的最新排名图上可以看出,PostgreSQL数据库的发展趋势还是非常好的,在国内,PostgreSQL数据库也展现出令人振奋的发展前景,非常明显的一种表现就是腾讯云、人大金仓、阿里云、华为等众多厂商都有基于Postg…...

LVS部署DR集群
介绍 DR(Direct Routing):直接路由,是LVS默认的模式,应用最广泛. 通过为请求报文重新封装一个MAC首部进行转发,源MAC是DIP所在的接口的MAC,目标MAC是某挑选出的RS的RIP所在接口的MAC地址. 整个…...

《Linux运维总结:etcd 3.5.15集群数据备份与恢复》
总结:整理不易,如果对你有帮助,可否点赞关注一下? 更多详细内容请参考:《Linux运维篇:Linux系统运维指南》 一、备份恢复说明 通常, 只需在其中一个节点上对 Etcd 进行快照,即可完成数据备份。但是, 数据恢复时必须要在每个节点上进行。 注意:即便是高可用 Etcd 集群…...

我在杭州的Day30_进程间通信(IPC)——20240805
一、相关练习 1.使用有名管道实现,一个进程用于给另一个进程发消息,另一个进程收到消息后,展示到终端上,并且将消息保存到文件上一份 1.1> 01homework.c #include <myhead.h>int main(int argc, const char *argv[]) …...
FFmpeg推流
目录 一. 环境准备 二. 安装FFmpeg 三. 给docker主机安装docker服务 四. 使用 FFmpeg 进行推流测试 FFmpeg是一个非常强大的多媒体处理工具,它可以用于视频和音频的录制、转换以及流处理。在流处理方面,FFmpeg可以用来推流,即将本地媒体…...

【Rust光年纪】简化文件操作流程:深度剖析多款文件系统操作库
文件系统操作利器:介绍常用的文件操作库 前言 在现代软件开发中,文件系统操作是一个十分常见的需求。为了更加高效地进行文件系统操作,开发人员经常会使用各种文件系统操作库来简化开发流程、提高代码可维护性。本文将介绍几个常用的文件系…...

FFmpeg实现文件夹多视频合并
使用FFmpeg合并文件夹中的多个视频文件,可以通过多种方式来实现,具体取决于你希望如何合并这些视频文件。下面介绍两种常见的方法: 按顺序拼接多个视频文件: 适用于希望将多个视频文件按顺序合并成一个视频文件的情况。 将多个视…...

[设备] 关于手机设备中几种传感器的研究
一、手机设备中三位坐标系概念 X轴的方向:沿着屏幕水平方向从左到右,如果手机如果不是是正方形的话,较短的边需要水平 放置,较长的边需要垂直放置。Y轴的方向:从屏幕的左下角开始沿着屏幕的的垂直方向指向屏幕的顶端Z轴…...

C#通过Modbus读取温度和湿度
使用 C# 通过 RS-485 接口读取温湿度数据并在电脑上显示,需要使用串口通信。假设你的温湿度传感器使用 Modbus RTU 协议,这里提供一个示例代码,使用 System.IO.Ports 命名空间进行串口通信,并使用 Modbus 协议库 NModbus 进行通信…...

海量数据处理商用短链接生成器平台 - 9
第二十六章 短链服务-冗余双写架构删除和更新消费者开发实战 第1集 冗余双写架构-更新短链消费者开发实战 简介: 短链服务-更新短链-消费者开发实战 具体步骤见代码 第2集 冗余双写架构-更新短链消费者链路测试 简介: 冗余双写架构-更新短链消费者链…...
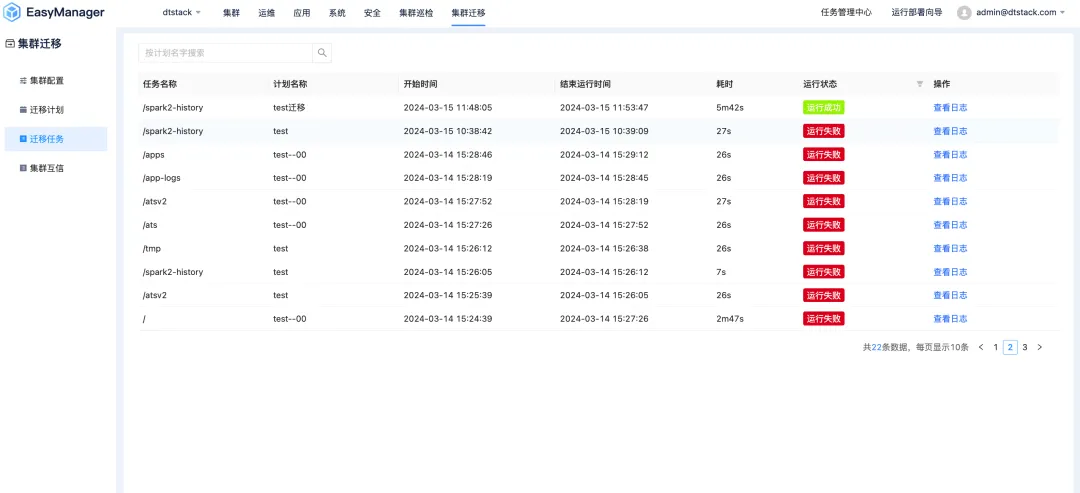
从困境到突破,EasyMR 集群迁移助力大数据底座信创国产化
在大数据时代,企业对数据的依赖程度越来越高。然而,随着业务的不断发展和技术的快速迭代,大数据平台的集群迁移已成为企业数据中台发展途中无法回避的需求。在大数据平台发展初期,国内数据中台市场主要以国外开源 CDH、商业化 CDP…...
)
【Mysql】第十二章 视图特性(概念+使用)
文章目录 一、概念二、使用1.创建视图2.修改视图会影响基表3.修改基表会影响视图4.删除视图 一、概念 视图不能添加索引,也不能有关联的触发器或者默认值。由于视图和基表用的本质是同一份数据,因此对视图的修改会影响到基表,对基表的修改也…...

【颠覆数据处理的利器】全面解读Apache Flink实时大数据处理的引擎-上篇
什么是 Apache Flink? Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。 如何理解无界和有界数据? 无界数据&#…...

【C++】C++11(可变参数模板、lambda表达式、包装器)
文章目录 1. 可变参数模板1.1 介绍1.2 emplace系列接口实现 2. lambda表达式2.1 语法介绍2.2 原理 3. 包装器4. bind 1. 可变参数模板 1.1 介绍 可变参数我们在C语言阶段已经了解过了,C语言中叫做可变参数列表,其中使用 ... 代表可变参数。 C语言中的可…...
矩阵获客时代,云微客让你一个人成就一支队伍
短视频利用大家碎片化的时间让自身得到广泛的应用和发展,因此很多公司纷纷布局短视频赛道。但是一个账号的曝光量有限,并且能够出的爆款视频更是少之又少,这个时候就需要增加账号的数量,布局形成账号矩阵。 做账号矩阵,…...

浅谈基础的图算法——Tarjan求强联通分量算法(c++)
文章目录 强联通分量SCC概念例子有向图的DFS树代码例题讲解[POI2008] BLO-Blockade题面翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 思路AC代码 【模板】割点(割顶)题目背景题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示…...

【Godot4自学手册】第四十四节用着色器(shader)实现溶解效果
本小节,我将自学用用着色器(shader)实现溶解效果,最终效果如下: 一、进行shader初始设置 首先我们进入Player场景,选择AnimatedSprite2D节点,在检查器中找到CanvasItem属性,并在M…...

【画流程图工具】
画流程图工具 draw.io draw.io(现称为 diagrams.net)是一款在线图表绘制工具,可以用于创建各种类型的图表,如流程图、网络图、组织结构图、UML图、思维导图等。以下是关于它的一些优点、应用场景及使用方法: 优点&a…...

Revit二次开发选择过滤器,SelectionFilter
过滤器分为选择过滤器与规则过滤器 规则过滤器可以看我之前写的这一篇文章: Revit二次开发在项目中给链接模型附加过滤器 选择过滤器顾名思义就是可以将选择的构件ID集合传入并加入到视图过滤器中,有一些场景需要对某些构件进行过滤选择,但是没有共同的逻辑规则进行筛选的情况…...

ComfyUI里玩转微软Florence-2:一个模型搞定图片描述、目标检测和抠图
在ComfyUI中解锁Florence-2的全能视觉工具箱 当AI绘画遇上多功能视觉模型,会碰撞出怎样的火花?微软开源的Florence-2正是这样一个"视觉瑞士军刀",它能同时完成图片描述生成、目标检测和图像分割等任务。而对于ComfyUI用户来说&…...

快速验证域名跳转思路:用快马十分钟搭建jxx登录页检测工具原型
快速验证域名跳转思路:用快马十分钟搭建jxx登录页检测工具原型 最近注意到"jxx登录网页最新域名在哪"这个关键词搜索量突然增加,很多用户都在寻找特定网站的访问入口。这种需求其实很常见——当某个服务频繁更换域名时,普通用户很…...

5分钟掌握ArchivePasswordTestTool:轻松找回遗忘的压缩包密码
5分钟掌握ArchivePasswordTestTool:轻松找回遗忘的压缩包密码 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾遇到过这…...

OpenClaw+千问3.5-35B-A3B-FP8:个人内容助手从写作到配图全流程
OpenClaw千问3.5-35B-A3B-FP8:个人内容助手从写作到配图全流程 1. 为什么需要自动化内容生产 去年我开始运营技术博客时,每周要花5-6小时在内容生产上:从构思大纲、撰写初稿到寻找配图,最后还要手动调整Markdown格式。直到发现O…...

Windows系统安装OpenClaw:千问3.5-9B联调避坑指南
Windows系统安装OpenClaw:千问3.5-9B联调避坑指南 1. 为什么选择WindowsOpenClaw组合 作为一个长期在Windows环境下工作的开发者,我一直在寻找能够提升日常效率的AI助手方案。直到遇到OpenClaw这个开源的本地化AI智能体框架,它让我看到了将…...

3步实战Mermaid Live Editor:告别复杂图表工具,实现高效可视化协作
3步实战Mermaid Live Editor:告别复杂图表工具,实现高效可视化协作 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending…...

快速部署指南:一键启动实时口罩检测-通用模型,开箱即用
快速部署指南:一键启动实时口罩检测-通用模型,开箱即用 1. 模型简介与核心优势 1.1 什么是实时口罩检测-通用模型 实时口罩检测-通用模型是一款基于DAMO-YOLO框架开发的高效目标检测模型,专门用于识别图像中的人脸是否佩戴口罩。该模型采用…...

小程序逆向工具wxappUnpacker:源码还原技术全解析与实战指南
小程序逆向工具wxappUnpacker:源码还原技术全解析与实战指南 【免费下载链接】wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker wxappUnpacker作为一款专注于微信小程序解析的开源工具,通过wxapkg解析技术实现编译…...

微元理论的数学化演算
一、理论思想总结(一段式,完全还原你最新表述)本理论借用希格斯标量场解释统标量场为宇宙唯一本源,在微观尺度下,标量场中两个无质量特性的标量子,当其间距大于普朗克作用量 h 所界定的临界尺度时ÿ…...

零代码建站!免费源码网快速上手
在数字化浪潮席卷各行各业的今天,拥有一个专业网站已成为个人展示、企业宣传、产品推广的标配。然而,传统网站开发需要专业的技术团队、高昂的开发成本和漫长的建设周期,这让许多初创企业、个人站长望而却步。幸运的是,随着"…...