用PyTorch 从零开始构建 BitNet 1.58bit
我们手动实现BitNet的编写,并进行的一系列小实验证实,看看1.58bit 模型是否与全精度的大型语言模型相媲美!
什么是量化以及为什么需要它?
量化是用更少的比特数表示浮点数的过程。当两个数字使用不同的比特数进行量化时,浮点运算的计算成本几乎按照减少的比特数的比例降低(理论上)。这使我们能够提高速度并减少机器学习模型的内存消耗。但这通常会导致信息丢失,从而降低准确性,我们可以通过对量化模型进行更多的微调来一定程度上恢复这种损失。
现有的量化方法与 BitNet 1.58bit 对比
大多数量化算法都需要一个全精度的预训练模型。人们通常会应用后训练量化(PTQ)和量化感知训练(QAT)等技术,以使这些算法有效运行。
PTQ 是一种量化技术,模型在训练完成后进行量化。QAT 是对 PTQ 模型的进一步微调,即在考虑量化的情况下进一步训练模型。
而BitNet 采用了一种截然不同的方法,即从头开始训练模型时就进行量化!
BitNet 的量化算法

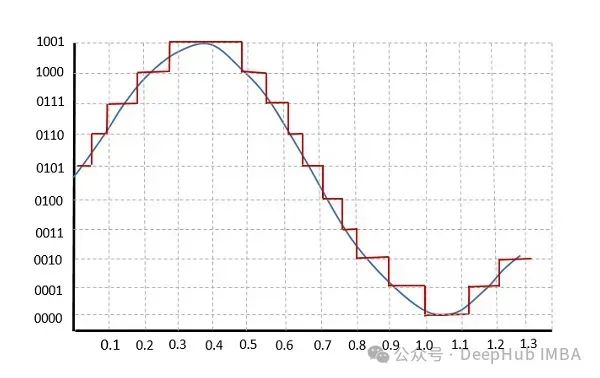
上图中,通过取绝对值的平均值的一半(假设 n=2)来计算权重裁剪阈值 γ。然后,权重矩阵 W 被相同的值除,导致新的权重矩阵在原始权重值 ≥ γ 时的值 ≥ 1,原始权重值 ≤ -γ 时的值 ≤ -1。对于 -γ 和 γ 之间的值,它们被映射到 -0.99999… 到 0.9999…
当执行 roundclip 时,
对于原始值 ≥ γ,新值为 1.0,原始值 ≤ -γ,新值为 -1.0,原始值在 -γ 和 γ 之间的新值为 0.0。
理论上,结果值可以用信息编码理论表示为 1.58 位。由于位数不能是分数,我们可以用 2 位来表示。
量化函数在Pytorch中的实现
阈值计算:
def compute_adjustment_factor(self, input_tensor: torch.Tensor):absmean_weight = torch.mean(torch.abs(input_tensor))adjustment_factor = 1e-4 + absmean_weight * 2 # 1e-4 to avoid zero divison errorreturn adjustment_factor
这里没有把绝对值减半,而是乘以了2。但是实验还是成功了!
RoundClip (1.58~= 2bit)
def compute_2bit_quantized_tensor(self, input_tensor: torch.Tensor):twobit_matrix = torch.clip(input=torch.round(input_tensor), min=-1, max=1)return twobit_matrixdef compute_1bit_quantized_tensor(self, input_tensor: torch.Tensor):return torch.sign(input_tensor)def compute_quantized_tensor(self, input_tensor: torch.Tensor):if self.quantization_mode == QuantizationMode.two_bit:return self.compute_2bit_quantized_tensor(input_tensor)else:return self.compute_1bit_quantized_tensor(input_tensor)
量化步骤
weight_adjustment_factor = self.compute_adjustment_factor(self.weight)adjusted_weight = self.weight / weight_adjustment_factorquantized_weight = self.compute_quantized_tensor(adjusted_weight)
线性层操作
F.linear(weight_adjustment_factor * x, quantized_weight, self.bias)
将调整因子与输入相乘,并将其除以量化权重
如果在将权重传递给线性层函数之前对其进行量化,则对量化矩阵的更新不会通过量化函数(因为大多数更新将在1e-4到1e-2之间,当通过量化步骤反向传播时将变为零)。因为原始的权重矩阵永远不会更新,模型永远不会学习!!
但有一个巧妙的工程技巧可以做到这一点,完整的前向传播是这样的
def forward(self, x):weight_adjustment_factor = self.compute_adjustment_factor(self.weight)adjusted_weight = self.weight / weight_adjustment_factorif self.training:quantized_weight = (adjusted_weight+ (self.compute_quantized_tensor(adjusted_weight) - adjusted_weight).detach())else:quantized_weight = self.compute_quantized_tensor(adjusted_weight)return F.linear(weight_adjustment_factor * x, quantized_weight, self.bias)
量化权重块的值无论
self.training
是否设置为
True
都是相同的。但是当
self.training
设置为
True
时,计算得到的梯度会被优雅地复制到调整后的权重中。这允许在训练过程中更新调整后的权重,同时也更新原始的权重矩阵。
这是从谷歌 DeepMind 的 VQ VAE PyTorch 实现中借鉴的简单却实用的技巧
自定义Pytorch实现的实验结果
下面的实验选择了一个小型模型和一个相对于小型模型来假设足够大的数据集。此外,为了创建目标模型的量化变体,我简单地使用以下代码块,将
nn.Linear
模块替换为这个自定义实现:
import copydef create_quantized_copy_of_model(input_model: nn.Module, quantization_mode: QuantizationMode):model_copy = copy.deepcopy(input_model)hash_table = {n: m for n, m in model_copy.named_modules()}for key in list(hash_table.keys()):if isinstance(hash_table[key], nn.Linear):new_module = BitNetLinearLayer(in_features=hash_table[key].in_features,out_features=hash_table[key].out_features,bias=hash_table[key].bias is not None,quantization_mode=quantization_mode,)name_chain = key.split(".")parent_module_attr_name = ".".join(name_chain[:-1])parent_module = hash_table[parent_module_attr_name]setattr(parent_module, name_chain[-1], new_module)for n, m in model_copy.named_modules():assert not isinstance(m, nn.Linear)return model_copy
结果如下:
4层FFN的Mnist结果 :

128维6层VIT版本训练Fashion MNIST的结果

128维8层VIT在 CIFAR100上的结果
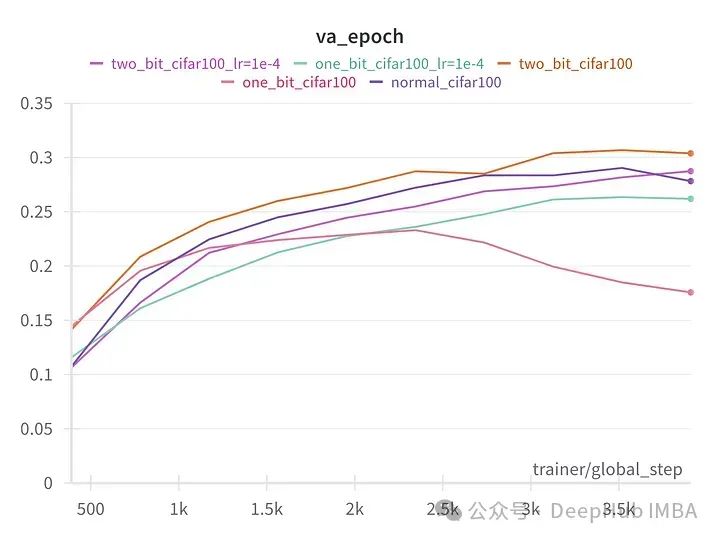
我们可以看到,除了第一个实验外,2位和1位版本的模型与全精度的常规版本的模型表现得一样好。在第一个实验中,量化模型可能发生了灾难性遗忘。
这些实验并未使用大型语言模型(LLMs)进行,但足以证明论文关于这样的系统能与全精度模型竞争的说法。
我们的实验与论文的唯一一个区别是,这个实现并没有将量化权重存储在2位矩阵中,计算仍以fp32执行的,要真正看到计算速度的提升,需要为此专门的计算内核,我们目前没有能力编写,所以实现仅验证了论文的潜在的论点。
以上实验的所有代码和模块代码都可以在github repo中找到
https://avoid.overfit.cn/post/131875e588ac4f4aa4f15d2dfa5b46db
作者:Chidhambararajan R
相关文章:
用PyTorch 从零开始构建 BitNet 1.58bit
我们手动实现BitNet的编写,并进行的一系列小实验证实,看看1.58bit 模型是否与全精度的大型语言模型相媲美! 什么是量化以及为什么需要它? 量化是用更少的比特数表示浮点数的过程。当两个数字使用不同的比特数进行量化时…...

信创安全 | 新一代内网安全方案—零信任沙盒
在当今数字化时代,访问安全和数据安全成为企业面临的重要挑战。传统的边界防御已经无法满足日益复杂的内网办公环境,层出不穷的攻击手段已经让市场单一的防御手段黔驴技穷。当企业面临越来越复杂的网络威胁和数据泄密风险时,更需要一种综合的…...
)
Redis的回收策略(淘汰策略)
volatile-lru :从已设置过期时间的数据集( server.db[i].expires )中挑选最近最少使用的数据淘汰 volatile-ttl : 从已设置过期时间的数据集( server.db[i].expires ) 中挑选将要过期的数据淘汰 volatile…...

Electron-builder 打包
项目比较简单,仅使用了 Electron 原生js 安装 electron-builder npm install electron-builder --dev配置 package.json 中的打包命令 {"script":{// ..."dev": "electron .","pack": "electron-builder"} }添…...

笔试练习day3
目录 BC149 简写单词题目解析代码 dd爱框框题目解析解析代码方法一暴力解法方法二同向双指针(滑动窗口) 除2!题目解析解法模拟贪心堆 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 🥸…...

企业想要将大模型技术应用到企业管理中需具备什么条件?
#企业 #企业管理 #大模型 企业想要将大模型技术应用到企业管理中,需要考虑以下几个关键条件: 1.明确的需求定位:企业应首先诊断自身的业务场景、数据、算法、基础设施预算以及战略等能力,明确大模型能够为企业带来的具体赋…...

go 事件机制(观察者设计模式)
背景: 公司目前有个业务,收到数据后,要分发给所有的客户端或者是业务模块,类似消息通知这样的需求,自然而然就想到了事件,观察者比较简单就自己实现以下,确保最小功能使用支持即可,其…...

RISC-V竞赛|第二届 RISC-V 软件移植及优化锦标赛报名正式开始!
目录 赛事背景 赛道方向 适配夺旗赛 优化竞速赛 比赛赛题(总奖金池8万元!) 🔥竞速赛 - OceanBase 移植与优化 比赛赛程(暂定) 赛事说明 「赛事背景」 为了推动 RISC-V 软件生态更快地发展࿰…...

【VTK】ubuntu手动编译VTK9.3 Generating qmltypes file 失败
环境 硬件:Jetson Xavier NX 套件 系统:Ubuntu 20.04 软件 :QT5.15.6 解决 0、问题 最近在Jetson Xavier NX 套件上编译VTK库,因为想要配合QQuick使用,所以cmake配置时勾选了VTK_MODULE_ENABLE_VTK_GUISupportQtQu…...

学习java的日子 Day64 学生管理系统 web2.0 web版本
MVC设计模式 概念 - 代码的分层 MVC:项目分层的思想 字母表示层理解MModle模型层业务的具体实现VView视图层展示数据CController控制器层控制业务流程(跳转) 1.细化理解层数 Controller:控制器层,用于存放Servlet&…...

【第14章】Spring Cloud之Gateway路由断言(IP黑名单)
文章目录 前言一、内置路由断言1. 案例(Weight)2. 更多断言 二、自定义路由断言1. 黑名单断言2. 全局异常处理3. 应用配置4. 单元测试 总结 前言 Spring Cloud Gateway可以让我们根据请求内容精确匹配到对应路由服务,官方已经内置了很多路由断言,我们也…...

3、pnpm yarn npm
项目里实际上就只有这些依赖 node module 里却有很多的包 原因: 比如说vue,vue内部有依赖了其余的包。工具又依赖了别的依赖 造成的问题:我可以直接去用这个包,但是这个包在package.json中却没有看到-----幽灵依赖 那如果说别…...

❄️5. Kubernetes核心资源之名称空间和Pod实战
**什么是名称空间Namespace: ** Namespace是k8s系统中的一种非常重要资源,它的主要作用是用来实现多套环境的资源隔离或者多用户的资源隔离。默认情况下,k8s集群中的所有的Pod都是可以相互访问的。但是在实际中,可能不想让两个Pod之间进行互…...

锂电池充电板电路设计
写这篇文章的目的主要是个人经验的总结,希望能给开发者们提供一种锂电池充电电路以及电源显示的电路思路。接下来从以下几个方面讲述电路。 设计这款电路的初衷是想用一块硬币大小的锂电池作为供电电源(3.5V-4.2V),降压供给3.3V电…...

工业互联网产教融合实训基地解决方案
一、引言 随着“中国制造2025”战略的深入实施与全球工业4.0浪潮的兴起,工业互联网作为新一代信息技术与制造业深度融合的产物,正引领着制造业向智能化、网络化、服务化转型。为培养适应未来工业发展需求的高素质技术技能人才,构建工业互联网…...

高效批量提取PPT幻灯片中图片的方法
处理包含大量图片的PPT(PowerPoint)幻灯片已成为许多专业人士的日常任务之一。然而,手动从每张幻灯片中逐一提取图片不仅耗时耗力,还容易出错。为了提升工作效率,减少重复劳动,探索并实现一种高效批量提取P…...
怎么在 React Native 应用中处理深度链接?
深度链接是一种技术,其中给定的 URL 或资源用于在移动设备上打开特定页面或屏幕。因此,深度链接可以引导用户到应用程序内的特定屏幕,而不仅仅是启动移动设备上的应用程序,从而提供更好的用户体验。这个特定的屏幕可能位于一系列层…...

el-table自动滚动到最底部
我的需求是这样的,因为我的表格是动态的,可以手动新增行,固定表头,而且需要一屏显示,为了方便用户就需要再新增的时候表格自动向上滚动。 差了官方文档后发现有一个属性可以支持 这个属性正是自己需要的,所…...

小白零基础学数学建模系列-引言与课程目录
目录 引言一、我们的专辑包含哪些内容?第一周:数学建模基础与工具第二周:高级数学建模技巧与应用第三周:机器学习基础与数据处理第四周:监督学习与无监督学习算法第五周:神经网络 二、学完本专辑能收获到什…...
)
Integer类型比较是 == 还是equals()
在Java编程中,判断两个Integer对象是否相等时,我们经常遇到使用和equals()方法的选择问题。这两个操作符和方法在判断对象相等性时有所不同,理解它们的区别对于编写健壮的代码至关重要。 使用判断Integer相等性 在Java中,操作符…...
:重构科学本质——公理驱动与结构化范式的确立)
贾子科学定理(Kucius Science Theorem):重构科学本质——公理驱动与结构化范式的确立
贾子科学定理(Kucius Science Theorem):重构科学本质——公理驱动与结构化范式的确立摘要: 贾子科学定理颠覆传统“可证伪性”标准,提出科学本质为“公理驱动可结构化”,构建TMM三层体系(真理层…...

SpringBoot 自动配置原理与实践
核心机制解析SpringBoot 的自动配置基于条件化装配思想,通过 Conditional 系列注解实现动态加载。spring-boot-autoconfigure 模块包含大量预定义配置类,例如 DataSourceAutoConfiguration 在检测到类路径存在 HikariCP 时自动初始化数据源。关键组件包括…...

VS2019+CMake实战:Super4PCS点云配准从源码编译到运行全流程指南
VS2019CMake实战:Super4PCS点云配准从源码编译到运行全流程指南 在三维视觉和机器人领域,点云配准一直是核心难题之一。Super4PCS算法作为4PCS的改进版本,以其在低重叠率点云上的优异表现,成为工业检测和SLAM系统中的热门选择。本…...

程序内存管理:堆与栈的核心原理与应用
1. 内存分配基础概念解析在计算机编程中,内存管理是每个程序员必须掌握的核心技能。程序运行时,操作系统会为其分配一块虚拟内存空间,这块空间被划分为几个关键区域,每个区域都有其特定的用途和管理方式。1.1 程序内存布局典型的程…...

[具身智能-228]:OpenCV的主要功能
OpenCV(Open Source Computer Vision Library)被誉为计算机视觉领域的“瑞士军刀”。它是一个基于 BSD 许可发行的开源库,提供了超过 2500 个优化算法,涵盖了从底层像素处理到高层视觉理解的完整技术链路。结合最新的技术资料&…...

BeMusic 3.1.3音乐网站源码:打造个人专属音乐平台的完美选择
在当今数字音乐时代,拥有一个属于自己的音乐网站已成为许多音乐爱好者和开发者的梦想。BeMusic 3.1.3音乐网站源码正是实现这一梦想的理想工具。作为一个功能全面的音乐分享和流媒体平台,BeMusic允许用户在几分钟内创建专业级的音乐网站,无需…...

全贴合工艺中Cover Lens Mura不良的关键影响因素与优化策略
1. 全贴合工艺中的Mura现象解析 第一次看到全贴合屏幕上出现发黄或发白的斑块时,我还以为是产品运输途中受了撞击。后来在产线蹲守三个月才发现,这些被称为"Mura"的光学缺陷,其实是贴合工艺中的隐形杀手。Mura这个词源自日语"…...

从频谱仪读数到测试报告:深入理解dBμV/m、dBm这些单位在EMC辐射发射测试中的真实含义
从频谱仪读数到测试报告:深入理解dBμV/m、dBm这些单位在EMC辐射发射测试中的真实含义 在电磁兼容(EMC)测试实验室里,工程师们每天都要面对频谱分析仪上跳动的数字——那些以dBμV/m、dBm为单位的读数,直接决定着产品能…...

3款免费MySQL客户端实测对比:DBeaver、WorkBench、HeidiSQL哪个更适合你?
三款开源MySQL客户端深度横评:从安装到高阶功能的全方位指南 当Navicat的收费模式成为团队协作或个人开发的负担时,开发者们往往需要寻找功能相当但零成本的开源替代品。本文将基于实际工程经验,对DBeaver、MySQL Workbench和HeidiSQL这三款主…...

解决Windows 11 LTSC应用商店缺失难题:从根源修复到生态重建的完整方案
解决Windows 11 LTSC应用商店缺失难题:从根源修复到生态重建的完整方案 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 在企业环境和专业工…...