Python代码之特征工程基础
1. 什么是特征工程
特征工程是指从原始数据中提取、转换和创建适合于模型训练的数据特征的过程。它是机器学习和深度学习中非常重要的一步,因为好的特征工程可以显著提高模型的性能。特征工程涉及从数据中提取有意义的信息,并将其转换为模型可以理解和使用的格式。常见的特征工程步骤包括数据清洗、特征选择、特征提取和特征变换。
2. 为什么特征工程很重要
特征工程的重要性在于它直接影响模型的性能。通过合适的特征工程,可以:
- 提高模型的准确性:好的特征可以显著提高模型的预测能力,因为它们能够捕捉数据中有意义的模式和关系。
- 缩短训练时间:通过减少数据的维度和复杂性,特征工程可以加快模型的训练速度。
- 提高模型的可解释性:特征工程可以帮助识别和使用更直观和解释性强的特征,使得模型的输出更容易理解。
3. 特征工程的步骤
数据收集:收集与问题相关的数据。这可能涉及从多个来源获取数据,如数据库、文件或在线API。
import pandas as pddata = pd.read_csv('data.csv') # 从CSV文件中读取数据
数据清洗:处理缺失值、异常值和重复数据,确保数据的质量和一致性。
# 处理缺失值
data = data.dropna() # 删除包含缺失值的行
# 或
data = data.fillna(data.mean()) # 使用均值填充缺失值
特征选择:选择对模型性能有显著影响的特征,删除冗余或不相关的特征。
from sklearn.feature_selection import SelectKBest, f_classifX = data.drop('target', axis=1)
y = data['target']
selector = SelectKBest(score_func=f_classif, k=10) # 选择10个最佳特征
X_new = selector.fit_transform(X, y)
特征提取:从原始数据中提取新的特征。这可以包括从日期时间数据中提取年月日,或从文本数据中提取关键词等。
# 从日期时间数据中提取特征
data['year'] = pd.to_datetime(data['date']).dt.year
data['month'] = pd.to_datetime(data['date']).dt.month
特征变换:对特征进行转换,如标准化、归一化、编码等,以使其适合模型训练。
from sklearn.preprocessing import StandardScaler, OneHotEncoder# 数值特征标准化
scaler = StandardScaler()
data[['feature1', 'feature2']] = scaler.fit_transform(data[['feature1', 'feature2']])# 类别特征编码
encoder = OneHotEncoder()
encoded_features = encoder.fit_transform(data[['categorical_feature']]).toarray()
data = pd.concat([data, pd.DataFrame(encoded_features)], axis=1)
4. 特征工程案例
结合以上步骤,下面是一个完整的特征工程流程示例:
import pandas as pd
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.preprocessing import StandardScaler, OneHotEncoder# Sample data to simulate the process
data = pd.DataFrame({'date': ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04'],'feature1': [1.0, 2.0, 3.0, 4.0],'feature2': [10.0, 20.0, 30.0, 40.0],'categorical_feature': ['A', 'B', 'A', 'B'],'target': [0, 1, 0, 1]
})# 数据清洗
data = data.dropna()# 特征选择
X = data.drop('target', axis=1)
y = data['target']
selector = SelectKBest(score_func=f_classif, k='all') # Selecting all features to demonstrate
X_new = selector.fit_transform(X.select_dtypes(include=[float, int]), y)# 特征提取
data['year'] = pd.to_datetime(data['date']).dt.year
data['month'] = pd.to_datetime(data['date']).dt.month# 特征变换
scaler = StandardScaler()
data[['feature1', 'feature2']] = scaler.fit_transform(data[['feature1', 'feature2']])encoder = OneHotEncoder(sparse=False)
encoded_features = encoder.fit_transform(data[['categorical_feature']])
encoded_features_df = pd.DataFrame(encoded_features, columns=encoder.get_feature_names_out(['categorical_feature']))data = pd.concat([data, encoded_features_df], axis=1)# 准备最终的特征集和标签
X_final = data.drop(['target', 'date', 'categorical_feature'], axis=1)
y_final = data['target']import ace_tools as tools; tools.display_dataframe_to_user(name="Final Data after Feature Engineering", dataframe=X_final)X_final.head(), y_final.head()
运行结果
Result
( feature1 feature2 year month categorical_feature_A \0 -1.341641 -1.341641 2023 1 1.0 1 -0.447214 -0.447214 2023 1 0.0 2 0.447214 0.447214 2023 1 1.0 3 1.341641 1.341641 2023 1 0.0 categorical_feature_B 0 0.0 1 1.0 2 0.0 3 1.0 ,0 01 12 03 1Name: target, dtype: int64)Final Data after Feature Engineering

最终的特征集和标签如下:

数据经过特征工程处理后,特征包括标准化后的数值特征、提取的年份和月份、以及独热编码后的类别特征。
相关文章:
Python代码之特征工程基础
1. 什么是特征工程 特征工程是指从原始数据中提取、转换和创建适合于模型训练的数据特征的过程。它是机器学习和深度学习中非常重要的一步,因为好的特征工程可以显著提高模型的性能。特征工程涉及从数据中提取有意义的信息,并将其转换为模型可以理解和使…...

低代码平台:效率利器还是质量妥协?
目录 低代码平台:效率利器还是质量妥协? 一、引言 二、低代码平台的定义和背景 1、什么是低代码平台? 2、低代码平台的兴起 三、低代码开发的机遇 1、提高开发效率 2、降低开发成本 3、赋能业务人员 四、低代码开发的挑战 1、质量…...

大数据-Big Data
1. 简介 1.1. 主要特点 大数据(Big Data)是指规模巨大、复杂多变的数据集合,这些数据集来源于多个不同的源,包括社交媒体、移动设备、物联网、传感器等。大数据的主要特点如下: 数据量大(Volume):大数据的起始计量单位是PB(1024TB)、EB(1024PB,约100万TB)或ZB(…...
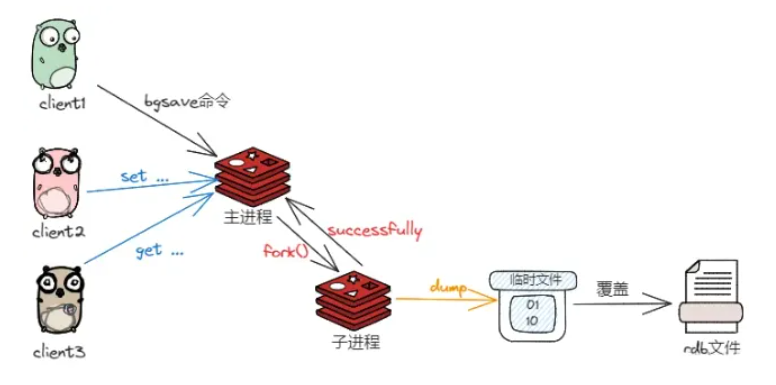
Redis的持久化的策略
Redis的持久化的策略 官方文档说明 AOF持久化策略RDB持久化的策略 AOF持久化策略 AOF持久性记录服务器接收到的每个写操作,然后,可以在服务器启动时再次重播这些操作,重建原始数据集,使用与Redis协议本身相同的格式记录命令。…...
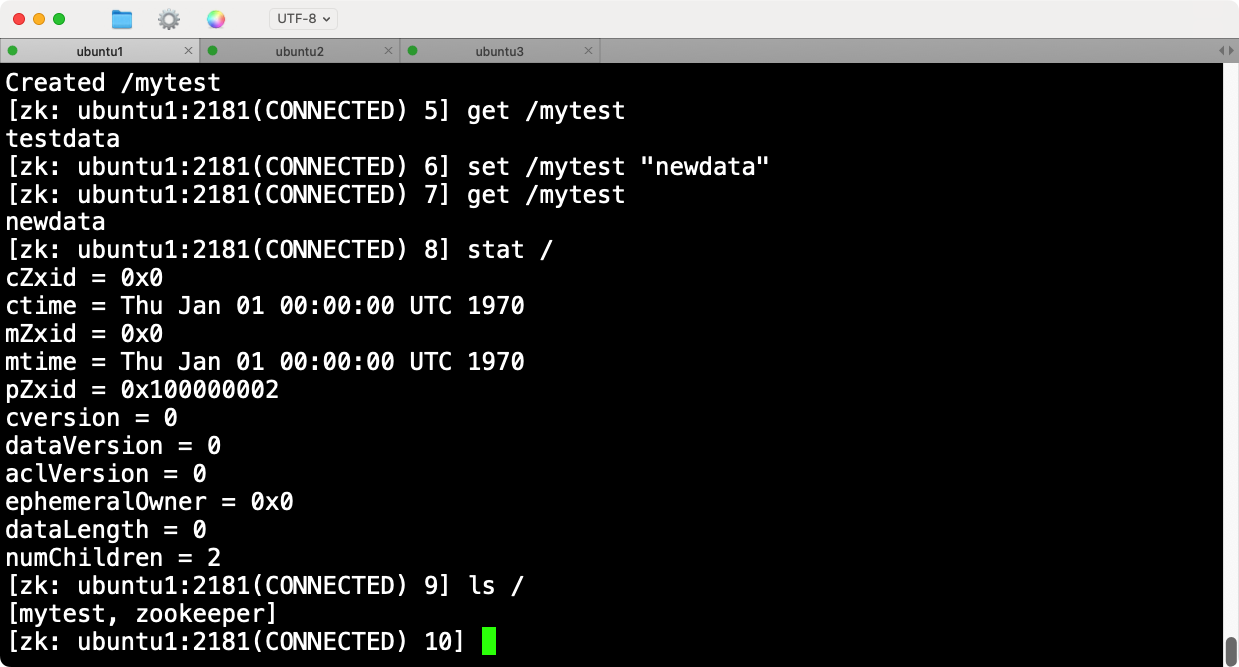
【八】Zookeeper3.7.1集成Hadoop3.3.4集群安装
文章目录 1.基本原理2.下载并解压ZooKeeper3.配置环境变量4.配置ZooKeeper5.创建数据目录并初始化myid6.启动ZooKeeper7.配置ZooKeeper集成到Hadoop8.重启Hadoop9.ZooKeeper状态检查 1.基本原理 ZooKeeper 是一个分布式协调服务,用于分布式系统中管理配置信息、命名…...

【C/C++笔记】:易错难点3 (二叉树)
选择题 🌈eg1 一棵有15个节点的完全二叉树和一棵同样有15个节点的普通二叉树,叶子节点的个数最多会差多少个()? 正确答案: C A. 3 B. 5 C. 7 D. 9 解析:普通二叉树的叶子节…...

一篇文章解决Webpack
一:什么是webpack webpack是一个用于现代JavaScript应用程序的静态模块打包工具。本质是一个软件包, 静态模块包括以下:html、css、js、图片等固定内容的文件 二:webpack工作原理 当 webpack 处理应用程序时,它会在内…...

速盾:cdn如何解析php文件中的图片?
CDN(Content Delivery Network)是一种通过分布在全球各地的服务器来加速网络内容传输的技术。CDN通过将内容缓存在离用户最近的服务器上,提供更快的访问速度和更好的用户体验。在解析PHP文件中的图片时,CDN可以起到以下几个方面的…...

如何快速实现MODBUS TCP转Profinet——泗博网关EPN-330
泗博网关EPN-330可作为PROFINET从站,支持与西门子S7-200 SMART/300/400/1200/1500全系列PLC以及具有PROFINET主站的系统无缝对接,而Modbus TCP端,可以与Modbus TCP从站设备、主站PLC、DCS系统以及组态软件等进行数据交互。 通过EPN-330&…...

什么是实时数据仓库?它有哪些不可替代之处?
【实时数据仓库】可以分开来理解: ✅【实时数据】:即能够快速处理数据,且几乎无延迟的提供最新的数据的能力。 ✅【仓库管理】:可以理解为对仓库的库存控制、对仓库的存储优化以及协调物流。 那么实时数据仓库就是:…...

《Ubuntu22.04环境下的ROS2学习笔记1》
一、在ROS2环境下创建工作空间 ROS2相比ROS1来说工作空间的创建有较大的不同,同时工作空间中的四个目录被更换为src(存放源码) , build(存放编译的中间文件) , install(存放可执行文件) , log(日志)。同时命令行也有些许变化&…...

Jupyter nbextensions安装与使用
Jupyter nbextensions的安装与使用主要包括以下几个步骤: 一、安装步骤 确保已安装Jupyter Notebook 如果尚未安装Jupyter Notebook,可以使用pip命令进行安装: pip install jupyter 安装nbextensions 使用pip命令安装nbextensions包&#x…...

java.nio.charset.MalformedInputException: Input length = 1
1、问题 项目启动报错: Exception in thread "main" org.yaml.snakeyaml.error.YAMLException: java.nio.charset.MalformedInputException: Input length 1提示原因: Caused by: java.nio.charset.MalformedInputException: Input length 1…...

yarn的安装和配置使用
文章目录 一、前言二、yarn简介三、yarn的特点四、yarn安装五、配置yarn5.1 全局配置5.2 项目配置 五、使用yarn六、yarn常用命令七、版本管理 一、前言 Yarn是facebook发布的一款取代npm的包管理工具,本文给大家介绍yarn的安装和使用,最详细教程&#…...

JVM知识总结(即时编译)
文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 即时编译 Java编译器经过解释执行,其执行速度必然会比…...

【网络】TCP协议——TCP连接相关、TCP连接状态相关、TCP数据传输与控制相关、TCP数据处理和异常、基于TCP应用层协议
文章目录 Linux网络1. TCP协议1.1 TCP连接相关1.1.1 TCP协议段格式1.1.2 确定应答(ACK)机制1.1.3 超时重传机制 1.2 TCP连接状态相关1.2.1 TIME_WAIT状态1.2.2 CLOSE_WAIT 状态 1.3 TCP数据传输与控制相关1.3.1 滑动窗口1.3.2 流量控制1.3.3 拥塞控制1.3.4 延迟应答1.3.5 捎带应…...

一起看看JavaAgent到底是干啥用的
JavaAgent 简介 定义: JDK提供的一种能力,允许开发者在运行时对已有class代码进行注入和修改。用途: 增强和修改类执行,如IntelliJ IDEA使用JavaAgent增强JVM行为实现调试功能。 JavaAgent 工作原理 premain 方法: JavaAgent的入口点,接收…...

k8s工作负载控制器--DaemonSet
文章目录 一、概述二、适用场景三、基本操作1、官网的DaemonSet资源清单2、字段解释3、编写DaemonSet资源清单4、基于yaml创建DaemonSet5、注意点5.1、必须字段5.2、DaemonSet 对象的名称5.3、.spec.selector 与 .spec.template.metadata.labels之间的关系 6、查看DaemonSet6.1…...

探索Python文档自动化的奥秘:MkDocs的神奇之旅
文章目录 **探索Python文档自动化的奥秘:MkDocs的神奇之旅**第一部分:背景为什么选择MkDocs? 第二部分:MkDocs是什么?MkDocs:文档生成的瑞士军刀 第三部分:如何安装MkDocs?一键安装&…...

树莓派边缘计算网关搭建:集成MQTT、SQLite与Flask的完整解决方案
一、项目概述 随着物联网(IoT)的快速发展,边缘计算的应用越来越广泛。边缘计算可以将数据处理和分析推向离数据源更近的地方,从而降低延迟,提高效率。本文将介绍如何利用树莓派构建一个多协议边缘计算网关,…...

Claude终端命令大全
一、终端 CLI 命令claude # 启动交互式会话claude "问题" # 直接提问并对话claude -c # 继续上一次对话claude -r 名称 …...

API测试自动化:契约测试 vs 接口测试
在微服务架构主导的现代软件开发中,API已成为系统集成的核心纽带。测试从业者面临的核心挑战是如何高效验证服务间交互的可靠性。契约测试(Contract Testing)与接口测试(API Testing)作为两种主流方法,分别…...

阿里架构师手码的Java工程师面试知识解析笔记 pdf
最近我整理了一份复习用的面试题及面试高频的考点题及技术点梳理成一份“Java 程序员高频面试解析及知识点体系笔记.pdf(实际上比预期多花了不少精力),包含集合,JVM,并发编程、Spring,MyBatis,微…...

光伏三相并网:集成MPPT与SPWM调制的高效逆变系统
光伏三相并网: 1.光伏10kwMPPT控制两级式并网逆变器(boost三相桥式逆变) 2.坐标变换锁相环dq功率控制解耦控制电流内环电压外环控制spwm调制 3.LCL滤波 仿真结果: 1.逆变输出与三项380V电网同频同相 2.直流母线电压800V稳定 3.d轴…...

如何在唐山挑选性价比高的二手房步梯房随着城市化进程的加快,越来越多的人选择购买二手房作为自己的居所。特别是在像唐山这样的城市里,由于其地理位置优越、经济发展迅速,二手房市场更是受到了不少购房者的青
随着城市化进程的加快,越来越多的人选择购买二手房作为自己的居所。特别是在像唐山这样的城市里,由于其地理位置优越、经济发展迅速,二手房市场更是受到了不少购房者的青睐。然而,在众多房源中挑选出既适合自己又具有高性价比的房…...

OpenTAP硬件集成测试优势解析
OpenTAP 之所以在硬件和系统集成测试领域表现出色,主要得益于其独特的设计理念、灵活的架构以及强大的社区生态支持。以下将从核心架构、技术优势、应用场景和具体实施案例等多个维度进行详细阐述。 一、 核心架构与设计理念 OpenTAP 基于 .NET 平台构建ÿ…...

5分钟完成开源工具FanControl本地化界面设置:效率提升指南
5分钟完成开源工具FanControl本地化界面设置:效率提升指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...
总体堵)
【OpenClaw】通过 Nanobot 源码学习架构---()总体堵
核心摘要:这篇文章能帮你 ?? 1. 彻底搞懂条件分支与循环的适用场景,告别选择困难。 ?? 2. 掌握遍历DOM集合修改属性的标准姿势与性能窍门。 ?? 3. 识别流程控制中的常见“坑”,并学会如何优雅地绕过去。 ?? 主要内容脉络 ?? 一、痛…...

GPT-6曝光4月14日发布:性能暴涨40%,200万Token,AI真正进入能干活时代
4月14日,OpenAI将发布迄今最强大的AI模型多个独立消息源已确认:OpenAI下一代旗舰模型GPT-6,代号"Spud"(土豆),预计在2026年4月14日正式发布。核心数据:相比GPT-4o性能提升超40%&#…...

用crosstool-ng 制作 Windows 上的 aarch64-linux-gnu 交叉编译器
crosstool-ng 官网链接:https://crosstool-ng.github.io/docs/ 需要注意的是,crosstool-ng不能以root身份运行,否则会提示以下错误: [ERROR] You must NOT be root to run crosstool-NG 故下面的所有操作都不要在root下进行。当…...