四种推荐算法——Embedding+MLP、WideDeep、DeepFM、NeuralCF
一、Embedding+MLP模型
Embedding+MLP 主要是由 Embedding 部分和 MLP 部分这两部分组成,使用 Embedding 层是为了将类别型特征转换成 Embedding 向量,MLP 部分是通过多层神经网络拟合优化目标。——用于广告推荐。

- Feature层即输入特征层,是模型的input部分,如上图的Feature#1是向上连接到embedding层,而Feature #2是直接连到stacking层。——前者代表类别型特征经过one-hot编码后生成的特征向量——过于稀疏,不适合直接输入网络中进行学习(所以先接入embedding层转为稠密向量);而后者是数值型特征。
- Stacking 层中文名是堆叠层,也叫连接(Concatenate)层作用是把不同的 Embedding 特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量。
- MLP 层的作用是让特征向量不同维度之间做充分的交叉,让模型抓取到更多的非线性特征和组合特征的信息,使深度学习模型在表达能力上较传统机器学习模型大为增强。
- Scoring 层,它也被称为输出层,为了拟合优化目标。对于CTR 预估这类二分类问题,Scoring 层往往使用的是逻辑回归模型,输出层使用 sigmoid 函数作为激活函数,输出一个介于 0 和 1 之间的概率值;而对于图像分类等多分类问题,Scoring 层往往采用 softmax 模型,使用 softmax 函数作为激活函数,输出每个类别的概率值。

深度学习模型DeepCrossing——一个经典的Embedding+MLP模型结构——微软提出。属于Embedding+MLP模型的进阶,在 Embedding + MLP 的基础上增加了交叉层,以更好地模拟特征之间的高阶交互。
二、Wide&Deep模型——线性模型(Wide)和深度神经网络(Deep)
推荐算法面临一个和搜索排序系统一个类似的挑战——记忆性和泛化性的权衡。
记忆能力:可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。也可以简单地理解成对商品或者是特征之间成对出现的一种学习,由于用户的历史行为特征是非常强的特征,特征之间的直接线性关联,对于特征间的简单关系很有效。
泛化能力:可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。对于泛化能力来说,它的主要来源是特征之间的相关性以及传递,捕捉复杂特征组合中的隐形关系、非线性关系。利用特征之间的传递性,就可以探索一些历史数据当中很少出现的特征组合,获得很强的泛化能力。
GooglePlay提出的Wide&Deep是比较经典的一个深度学习模型,它使模型既具有想象力又具有记忆力——线性模型(Wide)使模型既具有记忆力和深度神经网络(Deep)使模型既具有泛化性。

Wide&Deep架构示意图
Wide&Deep模型的工作流程:
- 特征工程:首先对原始数据进行预处理和特征工程,生成一系列可用于模型训练的特征。
- Wide 部分:将一部分特征直接输入到线性模型中,用于捕捉直接的线性关系——通常采用的是逻辑回归或线性回归模型,仅考虑每个特征对目标变量的直接贡献,而不考虑特征之间的交互。每个特征的权重都是独立计算的,不涉及与其他特征的相互作用——可以手动设置简单的二阶特征交叉。
- Deep 部分:将另一部分特征输入到深层神经网络中,用于学习特征之间的非线性关系。(本项目中输入全部特征)
- 联合训练:Wide 和 Deep 两部分的输出会被合并起来,通常是在最后一层通过加权求和的方式进行融合。
- 输出层:最后的输出层会根据Wide和Deep部分的融合结果生成最终的预测值。
举个简单的例子:电影推荐系统——预测用户是否会喜欢一部电影。
Wide 部分
特征包括:用户的年龄、性别、电影类型、导演等。
这些特征之间可能有直接的关系,比如年轻观众可能更喜欢动作片。
使用Wide部分(例如逻辑回归)来捕捉这些直接关系。
Deep 部分
特征包括:用户的观看历史、评分历史等。
这些特征之间的关系更为复杂,例如用户观看历史中的模式可能是非线性的。
使用Deep部分(例如多层神经网络)来学习这些复杂的模式。
如何工作
输入:用户特征和电影特征作为输入。
Wide 部分:直接使用特征进行线性预测。
Deep 部分:使用神经网络学习特征间的非线性关系。
合并:Wide和Deep的预测结果在最后一层合并。
输出:预测用户是否会喜欢这部电影。
结果
预测:结合了记忆性(Wide部分)和泛化性(Deep部分),可以更准确地预测用户喜好。
优势:能够处理简单和复杂的关系,提高推荐系统的准确性。
三、DeepFM模型
DeepFM是由哈工大和华为公司联合提出的深度学习模型。DeepFM模型包含因子分解机 (FM) 和深度神经网络 (DNN)。
- FM 部分:处理了一阶特征(每个特征的独立贡献)和二阶特征交互(特征之间的相互作用)——相对于Wide&Deep中的Wide部分多出二阶特征交互的部分——可以自动捕捉所有的可能的特征二阶交互。——DeepFM用FM替换原来的Wide部分,加强了浅层网络部分特征组合的能力。
- Deep 部分:通过 MLP 处理高阶特征交互,这里的高阶交互指的是通过神经网络自动学习得到的复杂特征组合。
- 合并输出:将 FM 部分的一阶和二阶特征交互与 Deep 部分的高阶特征交互结果合并,得到最终的预测。

DeepFM架构示意图
DeepFM VS Wide&Deep
假设我们有一个推荐系统,需要预测用户是否会点击某个广告。我们的特征包括用户的年龄、性别、所在城市、广告类型等。
DeepFM 的FM部分会考虑年龄与所在城市的交互效应。例如,年龄较大的用户在某些城市可能更倾向于点击某种类型的广告。
Wide & Deep 的Wide部分仅考虑年龄、性别、所在城市等特征各自对点击率的贡献,而不考虑它们之间的交互。
- DeepFM 通过FM部分捕捉特征间二阶交互效应,更好处理复杂的数据关系。
- Wide & Deep 的Wide关注每个特征一阶效应,快速学习每个特征的重要性。
这两种模型各有优势,数据集非常稀疏且需要捕捉复杂的特征交互,那么DeepFM可能更适合;数据集包含丰富的特征,并希望通过显式特征工程来捕捉特征间的交互,那么Wide & Deep可能更适合。
四、NeuralCF(神经网络协同过滤)
NeuralCF 结合了传统矩阵分解的优点(记忆性)和深度学习的能力(泛化能力),通过MLP代替内积操作来提高推荐准确性——新加坡国立学者提出。

NeuralCF的模型结构图 (出自论文Neural Collaborative Filtering)
最经典的是输入用户和物品id,转化成One-hot编码后经过简单的Embedding后生成稠密向量,然后将用户塔和物品塔拼接一起,送进MLP层中充分交叉,获取更高阶的特征,然后输出。
双塔模型——NeuralCF 的扩展
双塔模型是在经典 NeuralCF 基础上的扩展,其中增加了更多的特征信息,并且在每个塔内进行了更充分的特征交叉。这种扩展能够使模型更好地理解用户和物品之间的复杂关系,提高推荐的准确性。
- 多特征输入:不仅限于用户ID和物品ID,还包括其他相关的特征信息。
- 特征交叉:每个塔内的 MLP 能够处理更多特征的交叉,增强模型的学习能力。
- 独立建模:用户和物品分别在独立的塔中建模,最后通过某种方式(如点积)进行交互。
交互方式(用户Embedding-物品Embedding):
- 如果数据集较小或者特征比较简单,捕捉线性相似度,使用点积可能会更有效率,同时避免过拟合的风险。
- 如果数据集较大或者特征之间存在复杂的非线性关系,使用 MLP 进行交互可以更好地捕捉这些关系,尽管这可能会增加计算复杂度。
相关文章:
四种推荐算法——Embedding+MLP、WideDeep、DeepFM、NeuralCF
一、EmbeddingMLP模型 EmbeddingMLP 主要是由 Embedding 部分和 MLP 部分这两部分组成,使用 Embedding 层是为了将类别型特征转换成 Embedding 向量,MLP 部分是通过多层神经网络拟合优化目标。——用于广告推荐。 Feature层即输入特征层,是模…...
鹏鼎控股:最新面试求职SHL逻辑测评笔试题库讲解及真题分享
鹏鼎控股(深圳)股份有限公司,成立于1999年4月29日,是一家专业从事印制电路板(PCB)设计、研发、制造与销售的企业。公司产品广泛应用于通讯、消费电子、汽车、服务器等多个领域,服务全球市场。鹏…...

【Git】git 不跟踪和gitignore区别
文章目录 不跟踪(Untracked):.gitignore 文件:总结 在 Git 中,不跟踪(untracked)和 .gitignore 文件有不同的作用和用途: 不跟踪(Untracked): 不…...
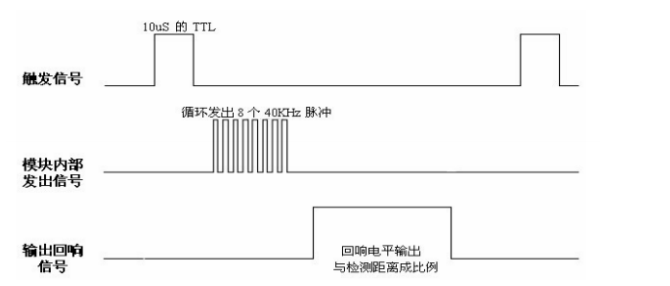
51单片机—智能垃圾桶(定时器)
一. 定时器 1. 简介 C51中的定时器和计数器是同一个硬件电路支持的,通过寄存器配置不同,就可以将他当做定时器或者计数器使用。 确切的说,定时器和计数器区别是致使他们背后的计数存储器加1的信号不同。当配置为定时器使用时,每…...
熵权法模型(评价类问题)
一. 概念 利用信息熵计算各个指标的权重,从而为多指标的评价类问题提供依据。 指标的变异程度越小,所反映的信息量也越少,所以其对应的权值也应该越低。 指标的变异程度(或称为变异性、波动性):描述了一…...

用uniapp 及socket.io做一个简单聊天app 踢人拉黑 7
在聊天群里,以及私聊时,可以点对方头象弹出踢跟拉黑,踢只是让对方退出聊天室。拉黑是记对方退出且不能再进入。 socket.io 中的踢人流程: 将用户从groupUsers 删除,表现在uniapp的界面,就是通知friends页&…...

springboot项目迁移到阿里云函数
注意:长耗时,高内存 的应用,定时任务 不适合迁移。spring-cloud的微服务项目暂不适合迁移。 一、根据模板创建项目 1.内网数据库连接配置 如果用到了rds或者阿里云上自建的mysql数据库 则配置 internetAccess: true vpcConfig:securityGrou…...

Java设计模式(桥接模式)
定义 将抽象部分与它的实现部分解耦,使得两者都能够独立变化。 角色 抽象类(Abstraction):定义抽象类,并包含一个对实现化对象的引用。 扩充抽象类(RefinedAbstraction):是抽象化角…...

【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码
【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码 目录 【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码分类效果基本描述程序设计参考资料 分类效果 基本描述 [24年最…...

【大模型】大模型指令微调的“Prompt”模板
文章目录 一、微调数据集格式二、常用的指令监督微调模板2.1 指令跟随格式(Alpaca)2.2 多轮对话格式(ShareGPT)2.3 其他形式2.4 常见模板 参考资料 一、微调数据集格式 在进行大模型微调的过程中,我们会发现“Prompt”…...

Spring的设计模式----工厂模式及对象代理
一、工厂模式 工厂模式提供了一种将对象的实例化过程封装在工厂类中的方式。通过使用工厂模式,可以将对象的创建与使用代码分离,提供一种统一的接口来创建不同类型的对象。定义一个创建对象的接口让其子类自己决定实例化哪一个工厂类,…...

【算法】浅析广度优先搜索算法
广度优先搜索算法:层层推进,全面探索 1. 引言 在计算机科学和算法设计中,广度优先搜索(Breadth-First Search,简称BFS)是一种用于遍历或搜索树或图的算法。这种算法从起点开始,优先访问所有距…...
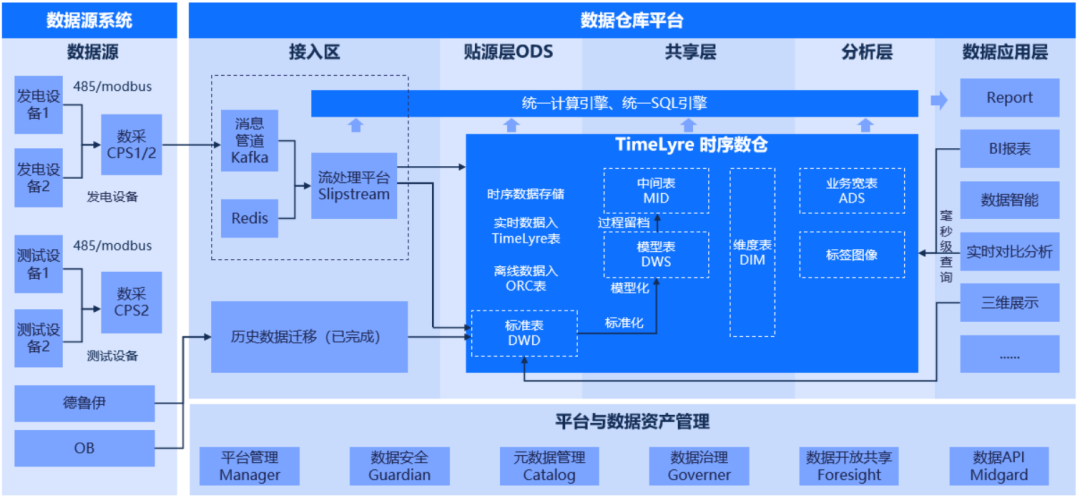
分布式时序数据库TimeLyre 9.2发布:原生多模态、高性能计算、极速时序回放分析
在当今数据驱动的世界中,多模态数据已经成为企业的重要资产。随着数据规模和多样性的不断增加,企业不仅需要高效存储和处理这些数据,更需要从中提取有价值的洞察。工业领域在处理海量设备时序数据的同时,还需要联动分析警报信息、…...

PMP考试题库每日五题+答案解析
第1题(单选题)某技术开发项目正在开展,目前项目所用成本还在预算范围内,但是已经落后项目进度计划三周。项目集经理在最近的项目状态报告中了解到这一项目信息,他要求项目经理必须在计划的交付日期之前完成可交付成果。…...

机器学习用python还是R,哪个更好?
目录 1. 语言特点 1.1 Python的语言特点 1.2 R的语言特点 2. 库支持 2.1 Python的库支持 2.2 R的库支持 3. 性能 3.1 Python的性能 3.2 R的性能 4. 社区支持 4.1 Python的社区支持 4.2 R的社区支持 5. 学习曲线 5.1 Python的学习曲线 5.2 R的学习曲线 6. 实际应…...

【数据结构】mapset详解
🍁1. Set系列集合 Set接口是一种不包含重复元素的集合。它继承自Collection接口,所以可以使用Collection所拥有的方法,Set接口的实现类主要有HashSet、LinkedHashSet、TreeSet等,它们各自以不同的方式存储元素,但都遵…...

数据结构(邓俊辉)学习笔记】词典 02—— 散列函数
文章目录 1. 冲突难免2. 何为优劣3. 整除留余4. 以禅为师5. M A D6. 平方取中7. 折叠汇总8. 伪随机数9. 多项式10. Vorldmort 1. 冲突难免 好,接下来的这一节我们就来介绍散列策略中的第一项,也是最重要的技术,散列函数的设计与定制。 在上…...

Python学习(1):使用Python的Dask库实现并行计算
目录 一、Dask介绍 二、使用说明 安装 三、测试 1、单个文件中实现功能 2、运行多个可执行文件 最近在写并行计算相关部分,用到了python的Dask库。 Dask官网:Dask | Scale the Python tools you love 一、Dask介绍 Dask是一个灵活的并行和分布式…...

数据结构 - 哈希表
文章目录 前言一、哈希思想二、哈希表概念三、哈希函数1、哈希函数设计原则2、常用的哈希函数 四、哈希冲突1、什么是哈希冲突2、解决哈希冲突闭散列开散列 五、哈希表的性能分析时间复杂度分析空间复杂度分析 前言 一、哈希思想 哈希思想(Hashing)是计…...

电商选品这几点没做好,等于放弃80%的流量!
在竞争激烈的电商领域,选品是决定店铺命运的核心环节。到底是哪些关键要点能够帮助我们在选品时抢占流量高地,稳步出单呢? 一、深入了解市场需求 选品的第一步是对市场进行深入调研。要关注当前的消费趋势、热门品类以及潜在的需求缺口。通…...

利用MT5进行文案润色:输入原始文案,AI输出优化后的多种版本
利用MT5进行文案润色:输入原始文案,AI输出优化后的多种版本 1. 为什么需要文案自动润色工具 在日常工作中,我们经常遇到这样的场景: 写了一篇产品介绍,但总觉得表达方式单一,缺乏吸引力需要为同一内容生…...

SHTC3温湿度传感器Arduino底层驱动库详解
1. 项目概述Deneyap Sıcaklık Nem ler,即 Deneyap 温湿度传感器模块(型号 M01,MPV1.0),是一款面向土耳其教育与创客生态的嵌入式环境感知单元,其核心传感元件为 Sensirion 公司出品的 SHTC3 数字温湿度传…...

开源项目 Agentic OS 实战指南:手把手教你从 ANOLISA 源码安装
首个面向 Agent 的操作系统——Agentic OS发布后,收到许多询问,是否能在本地部署?当然可以,Agentic OS 已经在 GitHub 上开源,开源项目是「ANOLISA」。 本文会详细介绍如何准备开发环境、从源码构建 ANOLISA 各组件并…...

程序行为的构成:规则、数据与延迟固化的艺术
程序行为的构成:规则、数据与延迟固化的艺术 2026-04-08 程序行为的构成:规则、数据与延迟固化的艺术 在软件系统中,程序行为并非凭空产生,而是规则作用于数据所产生的可观察效应。这一基本公式将程序的内在逻辑清晰地分为两个部分…...

2026年高性价比降AI工具:SpeedAI降AIGC率稳过审
2026年AIGC工具已经全面融入各类内容创作场景,降AI率、降AIGC率不再是学术圈的小众需求,更是论文写作、商业文案产出、自媒体内容创作、正式文稿发表等场景的核心刚需。现在市面上降AI工具种类繁多,但真正能做到效果稳定、不改动核心内容、操…...

UNet人脸融合作品集:这些换脸效果太惊艳了!
UNet人脸融合作品集:这些换脸效果太惊艳了! 1. 前言:当AI遇见人脸融合 想象一下,你有一张喜欢的风景照,但照片里的人物表情不够完美;或者你想看看自己如果长着明星的五官会是什么样子。这些在过去需要专业…...
进阶实战:从JSON Schema到企业级应用架构)
OpenAI结构化输出(Structured Outputs)进阶实战:从JSON Schema到企业级应用架构
1. 结构化输出的企业级价值与应用场景 在复杂的企业环境中,数据格式的标准化程度直接影响系统间的协作效率。想象一下财务部门需要从销售报告中提取关键指标,如果每个系统的输出格式都不一样,光是数据清洗就要耗费大量时间。这就是为什么Open…...
FastAPI 2.0流式AI响应落地全链路(从uvicorn配置到SSE/Chunked Transfer终极适配)
第一章:FastAPI 2.0流式AI响应落地全链路概览FastAPI 2.0 引入了对原生异步流式响应(StreamingResponse)的深度增强支持,结合 ASGI 3.0 规范与现代 LLM 推理服务特性,为构建低延迟、高吞吐的 AI 对话接口提供了坚实基础…...

llama-cpp-python本地部署终极指南:如何快速部署高效AI模型
llama-cpp-python本地部署终极指南:如何快速部署高效AI模型 【免费下载链接】llama-cpp-python Python bindings for llama.cpp 项目地址: https://gitcode.com/gh_mirrors/ll/llama-cpp-python 想要在本地运行大型语言模型,但担心复杂的部署过程…...

OpenClaw自动化测试:用Phi-3-mini-128k-instruct批量执行Python脚本
OpenClaw自动化测试:用Phi-3-mini-128k-instruct批量执行Python脚本 1. 为什么需要自动化测试助手 作为一个经常需要验证各种Python脚本的开发者,我发现自己陷入了重复劳动的困境。每次修改代码后,都要手动切换到终端,输入命令执…...