KL 散度(python+nlp)
python demo
KL 散度(Kullback-Leibler divergence),也称为相对熵,是衡量两个概率分布之间差异的一种方式。KL 散度是非对称的,也就是说,P 相对于 Q 的 KL 散度通常不等于 Q 相对于 P 的 KL 散度。

一个简单的 Python 类来计算两个离散概率分布之间的 KL 散度:
import numpy as npclass KLDivergence:def __init__(self, eps=1e-10):self.eps = eps # 防止出现 log(0)def kl_divergence(self, p, q):"""计算两个离散概率分布 P 和 Q 之间的 KL 散度。参数:p (np.array): 分布 P 的概率值。q (np.array): 分布 Q 的概率值。返回:float: P 相对于 Q 的 KL 散度。"""p = np.asarray(p, dtype=np.float)q = np.asarray(q, dtype=np.float)# 防止分母为零q = np.clip(q, self.eps, 1 - self.eps)# 计算 KL 散度kl_div = np.sum(np.where(p != 0, p * np.log(p / q), 0))return kl_div# 示例代码
if __name__ == "__main__":kld = KLDivergence()# 定义两个概率分布p = np.array([0.1, 0.4, 0.5])q = np.array([0.2, 0.3, 0.5])# 计算 KL 散度kl_div = kld.kl_divergence(p, q)print("KL Divergence:", kl_div)

nlp demo 1
在自然语言处理(NLP)中,KL 散度可以用于多种场景,比如评估文档的主题分布一致性、语料库中的词频分布比较等。这里提供一个使用 KL 散度来比较两个文档中词频分布的例子。我们将使用 scikit-learn 库来提取文档的词频,并计算它们之间的 KL 散度。
示例说明
在这个例子中,我们将使用 TF-IDF(Term Frequency-Inverse Document Frequency)来表示文档中的词频,并计算两个文档之间的 KL 散度。TF-IDF 是一种常用的文本特征表示方法,它可以衡量一个词对文档的重要程度。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from scipy.stats import entropyclass DocumentComparator:def __init__(self):self.vectorizer = TfidfVectorizer()self.eps = 1e-10def fit_transform(self, documents):"""使用 TF-IDF 向量化器将文档转换为 TF-IDF 特征向量。参数:documents (list of str): 文档列表。返回:np.array: TF-IDF 特征矩阵。"""tfidf_matrix = self.vectorizer.fit_transform(documents)return tfidf_matrix.toarray()def calculate_kl_divergence(self, doc1_tfidf, doc2_tfidf):"""计算两个文档 TF-IDF 特征向量之间的 KL 散度。参数:doc1_tfidf (np.array): 第一个文档的 TF-IDF 特征向量。doc2_tfidf (np.array): 第二个文档的 TF-IDF 特征向量。返回:float: 两个文档之间的 KL 散度。"""# 将 TF-IDF 向量归一化为概率分布doc1_prob = doc1_tfidf / np.sum(doc1_tfidf)doc2_prob = doc2_tfidf / np.sum(doc2_tfidf)# 防止分母为零doc2_prob = np.clip(doc2_prob, self.eps, 1 - self.eps)# 计算 KL 散度kl_div = entropy(doc1_prob, doc2_prob)return kl_div# 示例代码
if __name__ == "__main__":comparator = DocumentComparator()# 定义两个文档doc1 = "Python is a widely used high-level programming language."doc2 = "Python is a popular scripting language for data science."# 将文档转换为 TF-IDF 特征向量docs = [doc1, doc2]tfidf_matrix = comparator.fit_transform(docs)# 计算两个文档之间的 KL 散度kl_div = comparator.calculate_kl_divergence(tfidf_matrix[0], tfidf_matrix[1])print("KL Divergence between documents:", kl_div)

nlp demo 2
结合 Transformer 模型(如 BERT、GPT-2、T5 或 Llama2)与 KL 散度,我们可以构建一个更复杂的系统,用于评估不同文档或句子之间的相似性。这可以通过以下几种方式实现:
- 使用预训练模型生成句子嵌入:使用 Transformer 模型来生成句子或文档级别的嵌入向量。
- 计算句子嵌入的概率分布:将句子嵌入转换为概率分布。
- 计算 KL 散度:使用 KL 散度来比较两个句子的概率分布。
这里我们使用 Hugging Face 的 Transformers 库来加载预训练的模型,并计算句子之间的 KL 散度。我们将使用 BERT 作为示例模型,但这种方法同样适用于 GPT-2、T5 或 Llama2 等其他 Transformer 模型。
import torch
from transformers import AutoTokenizer, AutoModel
from scipy.special import rel_entr
import numpy as npclass SentenceEmbeddingComparator:def __init__(self, model_name="bert-base-uncased"):"""初始化 SentenceEmbeddingComparator 类。参数:model_name (str): 预训练模型的名字,默认为 'bert-base-uncased'。"""# 设置设备为 GPU 如果可用,否则使用 CPUself.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载预训练的分词器和模型self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModel.from_pretrained(model_name).to(self.device)# 设置模型为评估模式self.model.eval()def _mean_pooling(self, model_output, attention_mask):"""对模型输出执行平均池化以获取句子级别的嵌入。参数:model_output (torch.Tensor): 模型的输出。attention_mask (torch.Tensor): 注意力掩码,指示哪些位置是填充的。返回:torch.Tensor: 句子级别的嵌入。"""# 获取最后一层的隐藏状态token_embeddings = model_output.last_hidden_state# 扩展注意力掩码以匹配嵌入的维度input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()# 计算每句话的嵌入的加权和sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)# 计算每个位置的有效掩码数量sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)# 计算平均嵌入return sum_embeddings / sum_maskdef generate_sentence_embedding(self, sentence):"""生成给定句子的嵌入。参数:sentence (str): 输入的句子。返回:np.array: 句子的嵌入向量。"""# 对输入句子进行编码并添加到设备上encoded_input = self.tokenizer(sentence, padding=True, truncation=True, max_length=128, return_tensors='pt').to(self.device)# 使用模型生成输出with torch.no_grad():model_output = self.model(**encoded_input)# 使用平均池化获取句子嵌入sentence_embedding = self._mean_pooling(model_output, encoded_input['attention_mask'])# 将嵌入从张量转换为 NumPy 数组return sentence_embedding.cpu().numpy()[0]def calculate_kl_divergence(self, emb1, emb2):"""计算两个句子嵌入之间的 KL 散度。参数:emb1 (np.array): 第一个句子的嵌入。emb2 (np.array): 第二个句子的嵌入。返回:float: 两个句子之间的 KL 散度。"""# 将嵌入向量转换为概率分布# 归一化确保概率分布的总和为 1prob1 = emb1 / np.linalg.norm(emb1, ord=1)prob2 = emb2 / np.linalg.norm(emb2, ord=1)# 计算 KL 散度kl_div = np.sum(rel_entr(prob1, prob2))return kl_div# 示例代码
if __name__ == "__main__":# 创建 SentenceEmbeddingComparator 实例comparator = SentenceEmbeddingComparator("bert-base-uncased")# 定义两个句子sentence1 = "Python is a widely used high-level programming language."sentence2 = "Python is a popular scripting language for data science."# 生成句子嵌入emb1 = comparator.generate_sentence_embedding(sentence1)emb2 = comparator.generate_sentence_embedding(sentence2)# 计算两个句子之间的 KL 散度kl_div = comparator.calculate_kl_divergence(emb1, emb2)# 输出 KL 散度print("KL Divergence between sentences:", kl_div)

相关文章:
KL 散度(python+nlp)
python demo KL 散度(Kullback-Leibler divergence),也称为相对熵,是衡量两个概率分布之间差异的一种方式。KL 散度是非对称的,也就是说,P 相对于 Q 的 KL 散度通常不等于 Q 相对于 P 的 KL 散度。 一个简…...

四种推荐算法——Embedding+MLP、WideDeep、DeepFM、NeuralCF
一、EmbeddingMLP模型 EmbeddingMLP 主要是由 Embedding 部分和 MLP 部分这两部分组成,使用 Embedding 层是为了将类别型特征转换成 Embedding 向量,MLP 部分是通过多层神经网络拟合优化目标。——用于广告推荐。 Feature层即输入特征层,是模…...
鹏鼎控股:最新面试求职SHL逻辑测评笔试题库讲解及真题分享
鹏鼎控股(深圳)股份有限公司,成立于1999年4月29日,是一家专业从事印制电路板(PCB)设计、研发、制造与销售的企业。公司产品广泛应用于通讯、消费电子、汽车、服务器等多个领域,服务全球市场。鹏…...

【Git】git 不跟踪和gitignore区别
文章目录 不跟踪(Untracked):.gitignore 文件:总结 在 Git 中,不跟踪(untracked)和 .gitignore 文件有不同的作用和用途: 不跟踪(Untracked): 不…...
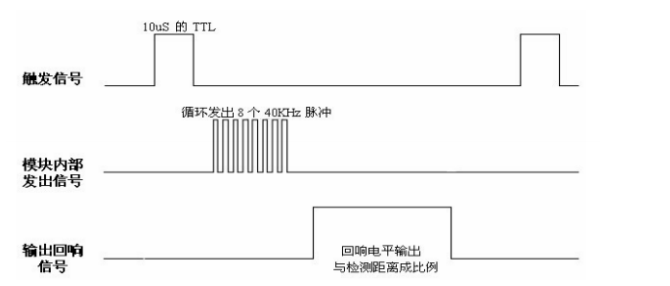
51单片机—智能垃圾桶(定时器)
一. 定时器 1. 简介 C51中的定时器和计数器是同一个硬件电路支持的,通过寄存器配置不同,就可以将他当做定时器或者计数器使用。 确切的说,定时器和计数器区别是致使他们背后的计数存储器加1的信号不同。当配置为定时器使用时,每…...
熵权法模型(评价类问题)
一. 概念 利用信息熵计算各个指标的权重,从而为多指标的评价类问题提供依据。 指标的变异程度越小,所反映的信息量也越少,所以其对应的权值也应该越低。 指标的变异程度(或称为变异性、波动性):描述了一…...

用uniapp 及socket.io做一个简单聊天app 踢人拉黑 7
在聊天群里,以及私聊时,可以点对方头象弹出踢跟拉黑,踢只是让对方退出聊天室。拉黑是记对方退出且不能再进入。 socket.io 中的踢人流程: 将用户从groupUsers 删除,表现在uniapp的界面,就是通知friends页&…...

springboot项目迁移到阿里云函数
注意:长耗时,高内存 的应用,定时任务 不适合迁移。spring-cloud的微服务项目暂不适合迁移。 一、根据模板创建项目 1.内网数据库连接配置 如果用到了rds或者阿里云上自建的mysql数据库 则配置 internetAccess: true vpcConfig:securityGrou…...

Java设计模式(桥接模式)
定义 将抽象部分与它的实现部分解耦,使得两者都能够独立变化。 角色 抽象类(Abstraction):定义抽象类,并包含一个对实现化对象的引用。 扩充抽象类(RefinedAbstraction):是抽象化角…...

【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码
【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码 目录 【独家原创】基于APO-Transformer-LSTM多特征分类预测(多输入单输出)Matlab代码分类效果基本描述程序设计参考资料 分类效果 基本描述 [24年最…...

【大模型】大模型指令微调的“Prompt”模板
文章目录 一、微调数据集格式二、常用的指令监督微调模板2.1 指令跟随格式(Alpaca)2.2 多轮对话格式(ShareGPT)2.3 其他形式2.4 常见模板 参考资料 一、微调数据集格式 在进行大模型微调的过程中,我们会发现“Prompt”…...

Spring的设计模式----工厂模式及对象代理
一、工厂模式 工厂模式提供了一种将对象的实例化过程封装在工厂类中的方式。通过使用工厂模式,可以将对象的创建与使用代码分离,提供一种统一的接口来创建不同类型的对象。定义一个创建对象的接口让其子类自己决定实例化哪一个工厂类,…...

【算法】浅析广度优先搜索算法
广度优先搜索算法:层层推进,全面探索 1. 引言 在计算机科学和算法设计中,广度优先搜索(Breadth-First Search,简称BFS)是一种用于遍历或搜索树或图的算法。这种算法从起点开始,优先访问所有距…...
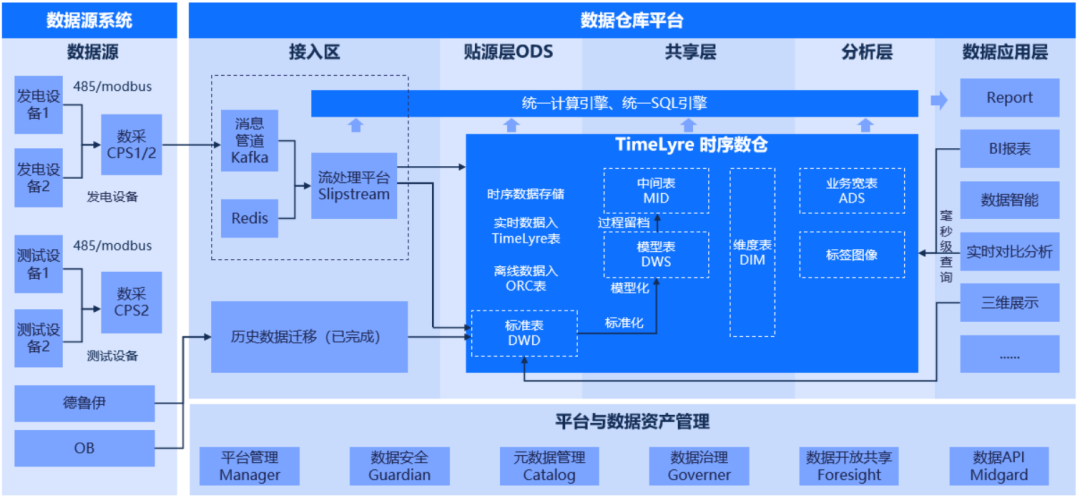
分布式时序数据库TimeLyre 9.2发布:原生多模态、高性能计算、极速时序回放分析
在当今数据驱动的世界中,多模态数据已经成为企业的重要资产。随着数据规模和多样性的不断增加,企业不仅需要高效存储和处理这些数据,更需要从中提取有价值的洞察。工业领域在处理海量设备时序数据的同时,还需要联动分析警报信息、…...

PMP考试题库每日五题+答案解析
第1题(单选题)某技术开发项目正在开展,目前项目所用成本还在预算范围内,但是已经落后项目进度计划三周。项目集经理在最近的项目状态报告中了解到这一项目信息,他要求项目经理必须在计划的交付日期之前完成可交付成果。…...

机器学习用python还是R,哪个更好?
目录 1. 语言特点 1.1 Python的语言特点 1.2 R的语言特点 2. 库支持 2.1 Python的库支持 2.2 R的库支持 3. 性能 3.1 Python的性能 3.2 R的性能 4. 社区支持 4.1 Python的社区支持 4.2 R的社区支持 5. 学习曲线 5.1 Python的学习曲线 5.2 R的学习曲线 6. 实际应…...

【数据结构】mapset详解
🍁1. Set系列集合 Set接口是一种不包含重复元素的集合。它继承自Collection接口,所以可以使用Collection所拥有的方法,Set接口的实现类主要有HashSet、LinkedHashSet、TreeSet等,它们各自以不同的方式存储元素,但都遵…...

数据结构(邓俊辉)学习笔记】词典 02—— 散列函数
文章目录 1. 冲突难免2. 何为优劣3. 整除留余4. 以禅为师5. M A D6. 平方取中7. 折叠汇总8. 伪随机数9. 多项式10. Vorldmort 1. 冲突难免 好,接下来的这一节我们就来介绍散列策略中的第一项,也是最重要的技术,散列函数的设计与定制。 在上…...

Python学习(1):使用Python的Dask库实现并行计算
目录 一、Dask介绍 二、使用说明 安装 三、测试 1、单个文件中实现功能 2、运行多个可执行文件 最近在写并行计算相关部分,用到了python的Dask库。 Dask官网:Dask | Scale the Python tools you love 一、Dask介绍 Dask是一个灵活的并行和分布式…...

数据结构 - 哈希表
文章目录 前言一、哈希思想二、哈希表概念三、哈希函数1、哈希函数设计原则2、常用的哈希函数 四、哈希冲突1、什么是哈希冲突2、解决哈希冲突闭散列开散列 五、哈希表的性能分析时间复杂度分析空间复杂度分析 前言 一、哈希思想 哈希思想(Hashing)是计…...

Qwen3.5-9B多模态能力展示:上传交通监控截图→识别违章行为→生成处罚依据
Qwen3.5-9B多模态能力展示:上传交通监控截图→识别违章行为→生成处罚依据 1. 多模态AI在交通管理中的创新应用 想象一下这样的场景:交通执法人员每天需要查看数百张监控截图,手动识别违章行为并查找相关法规条款。这不仅耗时耗力ÿ…...

韩国GaN外延片技术专家 IVWorks 宣布完成 450万美元的新一轮融资
核心技术:reGaN 与外延专长IVWorks 依托其在磊晶(Epiwafer)领域的深厚积累,正在向多个高端领域扩张:核心技术:基于选择性区域再生长(Selective Area Regrowth)技术的 reGaN。技术价值…...

【苍穹外卖】Mac前端开发环境搭建:从零到部署的完整指南
1. 为什么选择Mac搭建前端开发环境? 作为一个长期使用Mac进行前端开发的程序员,我可以很负责任地说,Mac确实是前端开发的绝佳选择。首先,Mac基于Unix系统,命令行环境对开发者极其友好,很多工具和命令与Linu…...

【JEECG Boot】 JEECG Boot——Online表单 系统性知识体系全解
文章目录JEECG Boot——Online表单一、核心基础认知1.1 官方定义与核心定位1.2 核心价值与解决的痛点1.3 与代码生成器的核心区别1.4 技术栈与运行环境依赖1.5 适用场景与能力边界二、核心架构与底层驱动原理2.1 整体四层架构体系2.2 元数据驱动的核心原理2.3 核心元数据模型与…...

Qwen3.5-2B模型Java开发集成指南:SpringBoot微服务实战案例
Qwen3.5-2B模型Java开发集成指南:SpringBoot微服务实战案例 1. 为什么企业需要AI微服务化 电商平台的商品审核团队每天要处理数万张用户上传的图片,传统人工审核方式不仅效率低下,还容易因疲劳导致误判。某头部电商引入Qwen3.5-2B模型后&am…...

河道水质在线监测系统
河道水质监测系统,以“立杆式微型站太阳能供电”为核心设计,主打“无需基建、便捷部署、精准监测”,彻底打破传统监测模式的局限。系统主要由基础支架(含立杆、地笼、ABS防腐耐蚀防护箱)、供电系统、监控主机、水质传感…...
)
双目视觉实战:如何用OpenCV和Python实现简易3D建模(附完整代码)
双目视觉实战:如何用OpenCV和Python实现简易3D建模(附完整代码) 当你第一次看到3D电影中跃然眼前的画面,或是用手机扫描物体生成三维模型时,是否好奇过这背后的技术原理?双目视觉技术正是实现这些酷炫效果的…...

WPF 进阶之路:从 MVVM 到企业级应用的架构与实战
1. MVVM 模式在企业级应用中的深度实践 很多刚接触WPF的开发者都会觉得MVVM模式很抽象,我第一次用的时候也是一头雾水。直到接手了一个电商后台管理系统项目,才真正体会到MVVM的价值。这个项目有30多个页面,如果按照传统事件驱动的方式开发&a…...

操作系统工程师成长:从兴趣到创新的四重境界
1. 操作系统工程师的成长路径:从兴趣到创新的四重境界在科技行业的金字塔尖,操作系统开发一直被视为"皇冠上的明珠"。作为一名在这个领域摸爬滚打二十余年的老兵,我见证了Linux从实验室玩具成长为数字世界基石的完整历程。每当年轻…...

SEATA分布式事务——AT模式一
简介 AI Agent 不仅仅是一个能聊天的机器人(如普通的 ChatGPT),而是一个能够感知环境、进行推理、自主决策并调用工具来完成特定任务的智能系统,更够完成更为复杂的AI场景需求。 AI Agent 功能 根据查阅的资料,agent的…...