大模型学习笔记 - InstructGPT中的微调与对齐
LLM 微调 之 InstructGPT中的微调与对齐
- LLM 微调 之 InstructGPT中的微调与对齐
- 技术概览
- InstructGPT中的微调与对齐
- 大体步骤
- 标注数据量
- 模型训练
- 1. SFT 是如何训练的
- 2. Reward Model是如何训练的
- 3. RLHF 是如何训练的
- 具体讲解RLHF 的loss 函数
- InstructGPT中的微调与对齐
- 模型效果
- 参考链接:
- 技术概览
LLM 我们不一定要预训练模型,但是一定要会微调。InstructGPT更是微调的最经典的文章。这里详细介绍InstructGPT的微调技术。
技术概览
InstructGPT中的微调与对齐
InstructGPT 里面提到LLM的微调技术, 分为2个阶段:
- 指令微调:使得模型有指令遵循的能力
- 对齐微调:对齐人类价值观

大体步骤
在GPT3/3.5的基础上,要解决的问题是 跟人类期待匹配。 最直接的方法就是人工构造一批数据(人类自己写prompt 和 期望的输出) 然后交给模型去学习,使得模型学到人类期望输出。但是这个代价太大,人类自己写prompt和答案 构造者个数据集 代价太大。
所以才有了微调和对齐模型,大体步骤如下:
- 有监督微调SFT: 我们称原始模型为V0,也就是GPT-3。人工先构造一批数据,数据量不用很大,先让模型学一学,得到模型V1(SFT) 让模型有基本指令遵循能力。
- 人类偏好对齐:(Reward model + PPO) 持续重复进行。
- 人类偏好对齐用强化学习的方式来微调模型,输入prompt 输出几个答案,人类对答案进行评价反馈(相当于环境反馈),模型根据评价的结果来继续优化,反复迭代使得最后模型输出符合人类偏好。
- 那么问题是人类如何反馈,这套机制如何建立? Reward Model 奖励模型。
- 最直接的方法肯定是 输入prompt 模型有几个输出,然后人类给每个输出打出高低分数,模型收到评价 再反向传播迭代更新。人类在根据更新后的模型,输入prompt 等新模型输出 再打分,模型再迭代。
- 但是人类不可能在模型前面等他输出一个个打分的。所以这里需要一个自动评分的模型 替代人类做 反馈。 于是就有了 reward model 这个模型输入就是prompt和模型的answer,是输出是得分。
- 为了得到这个RM模型,制作训练集,让模型对一个prompt输出多个答案,然后人类对这个答案进行打分排序。打分排序比自己写训练数据要方便多了,从而得到更多的标注数据(prompt,answer,score).
- 用这个训练集 来训练RM model,作用是对 prompt和answer pair 进行打分,评价这个pair是否搭配。
- 有了打分模型,接下来就要微调第一步得到的SFT(V1)模型。采用PPO方法
- 这里给定一些prompt,得到输出,把prompt和输出 一起给RM 模型,得到打分(外界环境的反馈),然后借助强化学习的方法,训练SFT,反复迭代最终得到V2模型也就是InstructGPT.
步骤 1 只进行一次,而步骤Reward model 和PPO算法可以持续重复进行:在当前最佳策略模型上收集更多的比较数据,用于训练新的 RM 模型,然后训练新的策略。
标注数据量
上述三个步骤分别制造和标注了多少样本呢?
- SFT 数据,第一步分类根据prompt自己写理想输出,SFT supervised fine tuning 有13k的prompt.(人工标注的占比高一些,11.3k,API 1.5k)
- RewardModel数据,第二步用来训练打分模型的数据,包含33k的prompts
- PPO数据,第三步用来训练强化学习PPO模型的数据,包含31k的prompts。
其中前2步的prompts 来自OpenAI的 API上用户使用数据和人工标注写的数据,最后一步全是从API上采样的数据。(第一步人工占比高,第二步人工占比低)。
初始种子数据集:需要标注者来编写prompts。
- plain:自己随便想一些prompts,同时尽可能保证任务多样性。(各种问题和要求)
- Few-shot: 不仅仅需要写prompts,还需要写对应的outputs(这部分是最耗人力的,也就是SFT的主要组成)
- User-based: 标注者根据openAI的waitlist里面的task 来编写一些prompts(相当于告诉标注人员,用户期待的功能,你们来写prompt 答案)
API中的数据

模型训练
这里面3个步骤 分别是如何训练的呢?
1. SFT 是如何训练的

- 训练数据: SFT是有监督的微调,训练数据是通过给定一个提示列表,人工写对应的输出得到的。大概13k左右。这里面的提示列表有来自人工自己写的也有API收集的。(这一步主要为了让模型有指令遵循的能力,人工写的比例高一些,因为API很多数据都是扩写 不使用这个任务。)
- 模型初始化:InstructGPT 是从GPT3初始化的,chatGPT是从GPT3.5初始化的。
- 训练:在Fine-tuning的过程中同样采用自回归的方式,将Prompt和对应的label answer串联在一起进行训练(下一个词预测训练目标)。
这一步finetuning时,1个epoch就已经overfit了 但是由于这个不是最终的模型,并且train epoch越多对后面两步越有帮助,所以train了16个epoch。
由于该步骤的数据量也有限,该过程获得的 SFT 模型可能会输出仍然并非用户关注的文本,并且通常会出现不一致问题。这里的问题是监督学习步骤的 可扩展性成本高 不可能让标注人员把所有的问题都写一遍。
所以需要让模型学到人类的喜爱偏好(训练出一个RM模型作为机器裁判从而代替人类当裁判) 也就是使用的策略是让人工标注者对 SFT 模型的不同输出进行排序以创建 RM 模型,而不是让人工标注者创建一个更大的精选数据集
2. Reward Model是如何训练的

- 初始化: OpenAI使用了指令微调16个epoch的6B模型作为奖励模型的初始模型。通过『移除了最后一层unembedding layer的上一阶段的SFT模型』初始化出我们的RM模型,且考虑到175B计算量大且不稳定不适合作为奖励函数,故最后用的6B版本的SFT初始化RM模型。
- 模型训练:训练方式是两两对比计crossentropy(其实就是logist 二分类损失,这里是两两组合),其中rθ 是奖励函数对指令x和回复y的打分,如下 (a>b>c) 两两组合 计算loss
l o s s ( θ ) = − 1 ( 2 k ) E ( x , y w , y l ) D [ l o g ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ] loss(\theta) = -\frac{1}{(^k_2)} E_{(x,y_w,y_l)~D}[log(\sigma(r_{\theta}(x,y_w) - r_{\theta}(x,y_l)))] loss(θ)=−(2k)1E(x,yw,yl) D[log(σ(rθ(x,yw)−rθ(x,yl)))]
-
数据收集:让阶段1的SFT模型回答来自OpenAI API和labeler-written且规模大小为33k的数据集的一些问题比如 x n + 1 x_{n+1} xn+1,接着针对每个问题收集4-9个不同的模型输出从而获取4-9个回答。
为什么模型会有多个回答呢?在于模型每次预测一个词都有对应的概率,根据不同的概率大小可以采样出很多答案,比如通过beam search保留k个当前最优的答案(beam search相当于贪心算法的加强版,除了最好的答案外,还会保留多个比较好的答案供选择)。人工对这4-9个回答的好坏进行标注且排序,排序的结果用来训练一个奖励模型RM,具体做法就是学习排序结果从而理解人类的偏好。 对于标注者来说,对输出进行排序比从头开始打标要容易得多,这一过程可以更有效地扩展。在实践中,所选择的 prompt 的数量大约为 30-40k,并且包括排序输出的不同组合。
-
训练技巧:OpenAI发现如果对数据进行Shuffle,则训练一轮就会过拟合,但如果把针对1个指令模型的K个回复,K在4~9之间,得到 C K 2 C^2_K CK2 个pairwise对,放在一个batch里进行训练,会得到显著更高的准确率。这里一个batch包括64个指令生成的所有回复对,其中排名相同的样本对被剔除。这里感觉和对比学习要用大batch_size进行拟合的思路有些相似,是为了保证对比的全面性和充分性,使用全面对比后计算的梯度对模型进行更新。另一个原因可能是不同标注人员之间的偏好差异,shuffle之后这种偏好差异带来的样本之间的冲突性更高。
3. RLHF 是如何训练的
大体步骤:
- 首先 初始化PPO模型,
- 然后 让PPO模型去回答问题(这些问题没有人类标注,都是新问题)此时不用人工评估,而是让阶段二的RM来对结果进行打分,进而进行排序。
- 之后,通过不断更大化奖励而优化PPO模型的生成策略(因为生成策略更好,模型的回答便会更好),策略优化的过程中使用PPO算法限制策略更新范围
- 最后,根据优化后的策略再次生成 -> RM再评估 -> 模型再优化后再生成,如此循环进行,直到策略最优为止.

o b j e c t i v e ( ∅ ) = E ( x , y ) D π ∅ R L [ r θ ( x , y ) − β l o g ( π ∅ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x D p r e t r a i n [ l o g ( π ∅ R L ( x ) ) ] objective(\varnothing) = E_{(x,y)~D_{\pi_{\varnothing}RL}}[r_\theta(x,y) - \beta log(\pi_{\varnothing}^{RL}(y|x)/\pi^{SFT}(y|x))] + \gamma E_{x~D_{pretrain}}[log(\pi_{\varnothing}^{RL}(x))] objective(∅)=E(x,y) Dπ∅RL[rθ(x,y)−βlog(π∅RL(y∣x)/πSFT(y∣x))]+γEx Dpretrain[log(π∅RL(x))]
在RL微调的部分,OpenAI使用了PPO算法,基于Reward模型的打分进行微调,微调了2个epoch。在此基础上加入了两个目标:
- 微调模型和原始模型在token预测上的KL散度,避免模型过度拟合奖励函数偏离原始模型。后面也论证了KL的加入,可以加速RL收敛,核心是在相同的KL下最大化模型偏好的提升
- 10%的预训练目标(PPO-PTX): 降低RL对模型语言能力的影响
且论文提到样本的收集和RL训练是多次迭代的,也就是使用RL微调后的模型上线收集更多的用户请求,重新训练RM,再更新模型。不停在优化后的模型上收集用户反馈,会让RM模型学习到更充分的高偏好样本,强者愈强。

具体讲解RLHF 的loss 函数
首先目标函数如下:
o b j e c t i v e ( ∅ ) = E ( x , y ) − D π ∅ R L [ r θ ( x , y ) − β l o g ( π ∅ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x D p r e t r a i n [ l o g ( π ∅ R L ( x ) ) ] objective(\varnothing) = E_{(x,y)-D_{\pi_{\varnothing}^{RL}}}[r_\theta(x,y) - \beta log(\pi_{\varnothing}^{RL}(y|x)/\pi^{SFT}(y|x))] + \gamma E_{x~D_{pretrain}}[log(\pi_{\varnothing}^{RL}(x))] objective(∅)=E(x,y)−Dπ∅RL[rθ(x,y)−βlog(π∅RL(y∣x)/πSFT(y∣x))]+γEx Dpretrain[log(π∅RL(x))]
其中
- ∅ \varnothing ∅是我们要训练的参数,
- π S F T \pi^{SFT} πSFT是基线模型(基线策略),
- π ∅ R L \pi_{\varnothing}^{RL} π∅RL 是我们要训练得到的RL模型也是RL策略(这个模型是用SFT基线模型初始化的)
- x 是用于训练的Prompt,y 是将x输入到 π ∅ R L \pi_{\varnothing}^{RL} π∅RL后得到的输出
- r θ ( x , y ) r_\theta(x,y) rθ(x,y)是用第二步训练出来的参数为 θ \theta θ的Reward Model对 x和y 进行打分, 我们希望这个分数是最大的,我们优化的PPO目标就是最大化 E ( x , y ) − D π ∅ R L r θ ( x , y ) E_{(x,y)-D_{\pi_{\varnothing}^{RL}}}r_\theta(x,y) E(x,y)−Dπ∅RLrθ(x,y) 这样训练出来的 D π ∅ R L D_{\pi_{\varnothing}{RL}} Dπ∅RL 就是符号人类要求的输出得分最高的那个模型.
- 这里有一个问题是 每次更新 D π ∅ R L D_{\pi_{\varnothing}^{RL}} Dπ∅RL后,x 还是不变prompt不变,y会因为更新 π ∅ R L {\pi_{\varnothing}^{RL}} π∅RL策略而发生变化,然后采样到的数据就会发生变化,此时x,y输入到 r θ ( x , y ) r_\theta(x,y) rθ(x,y)中得到分数。
- RL中常见的是 模型输出-人排序-模型反向传播更新-输出-人排序 这是在线学习 on-policy.
真正计算时 实际上是如下展开:
o b j e c t i v e ( ∅ ) = E ( x , y ) D π ∅ R L ′ [ π ∅ R L π R L ′ r θ ′ ( x , y ) − β l o g ( π R L ′ ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x D p r e t r a i n [ l o g ( π ∅ R L ( x ) ) ] objective(\varnothing) = E_{(x,y)~D_{\pi_{\varnothing}^{RL'}}}[\frac{\pi_{\varnothing}^{RL}}{\pi^{RL'}}r_{\theta'}(x,y) - \beta log(\pi^{RL'}(y|x)/\pi^{SFT}(y|x))] + \gamma E_{x~D_{pretrain}}[log(\pi_{\varnothing}^{RL}(x))] objective(∅)=E(x,y) Dπ∅RL′[πRL′π∅RLrθ′(x,y)−βlog(πRL′(y∣x)/πSFT(y∣x))]+γEx Dpretrain[log(π∅RL(x))]
这里面: ∅ \varnothing ∅是我们要训练的参数, π S F T \pi^{SFT} πSFT是基线策略, π R L ′ \pi^{RL'} πRL′是旧策略, π ∅ R L \pi_{\varnothing}^{RL} π∅RL 是新策略。
- 第一部分 E ( x , y ) D π ∅ R L ′ [ π ∅ R L π R L ′ r θ ′ ( x , y ) ] E_{(x,y)~D_{\pi_{\varnothing}RL'}}[\frac{\pi_{\varnothing}^{RL}}{\pi^{RL'}}r_{\theta'}(x,y)] E(x,y) Dπ∅RL′[πRL′π∅RLrθ′(x,y)]: 由于 第二阶段已经得到了奖励模型,便可基于最大化奖励这个目标,通过PPO算法不断优化RL模型的策略 π R L \pi^{RL} πRL
- 第二部分 是带 β \beta β的惩罚项 β l o g ( π R L ′ ( y ∣ x ) / π S F T ( y ∣ x ) ) \beta log(\pi^{RL'}(y|x)/\pi^{SFT}(y|x)) βlog(πRL′(y∣x)/πSFT(y∣x)) 作用是通过KL散度对比RL 在最大化RM的目标下学到的策略 π R L ′ \pi^{RL'} πRL′ 和基线 π S F T \pi^{SFT} πSFT的差距,开始时 π R L ′ \pi^{RL'} πRL′的初始值就是 π S F T \pi^{SFT} πSFT,最终希望 π R L ′ \pi^{RL'} πRL′最终迭代结束后 他们两个之间的差距不至于太大。
- 如何避免差距太大呢?可以通过KL散度衡量两个策略的概率分布之间的差距,从而使得在优化策略时限制参数更新的范围。RL和RL’与PPO算法中的 θ / θ ′ \theta/\theta' θ/θ′相对应,比如与环境交互的 θ ′ \theta' θ′等同于旧策略 π R L ′ \pi ^{RL'} πRL′,但具体而言,则有以下4点:
-
- 已经掌握人类偏好的RM模型一旦判定现有回答不好,则会更新 π ∅ R L \pi_{\varnothing}^{RL} π∅RL 但是如果 π ∅ R L \pi_{\varnothing}^{RL} π∅RL发生变化,会导致后续的$R_\theta = E_{t~p_{\theta}(\tau)}[R(\tau)\nabla log p_\theta(\tau)] $ 计算一系列问答评分时中的 p θ ( τ ) p_{\theta}(\tau) pθ(τ)发生变化(策略轨迹必变化),进而已经采样的问答数据 < x n + 2 , y n + 2 1 , . . y n + 2 4 > < x n + 3 . . > <x_{n+2},{y^1_{n+2},..y^4_{n+2}}> <x_{n+3}..> <xn+2,yn+21,..yn+24><xn+3..> 便无法使用,而只能不断采样一批新的问答数据(更新一次 π ∅ R L \pi_{\varnothing}^{RL} π∅RL 后,得采样新一批数据,再更新一次 π ∅ R L \pi_{\varnothing}^{RL} π∅RL 后 再采样新一批数据…)
-
- 为了避免 π ∅ R L \pi_{\varnothing}^{RL} π∅RL 只要一更新便只能一次次去采样一批批新问题数据。(为了提高数据利用率),我们改成让 π ∅ R L ′ \pi_{\varnothing}^{RL'} π∅RL′去和环境交互,
- a. 首先,在使用旧策略 π R L ′ \pi^{RL'} πRL′生成一批数据,包括状态、动作和奖励等信息,这些数据可以类似DQN那样,存储在一个经验回放缓冲区中,
- b. 其次,在训练新策略 π ∅ R L \pi_{\varnothing}^{RL} π∅RL时,从经验回放缓冲区中随机抽取一批数据
- c.对于旧策略采样到的每个数据样本(x,y) 计算重要性采样权重w(x,y) w ( x , y ) = π ∅ R L ( y ∣ x ) π R L ′ ( y ∣ x ) w(x,y) = \frac{\pi_{\varnothing}^{RL}(y|x)}{\pi^{RL'}(y|x)} w(x,y)=πRL′(y∣x)π∅RL(y∣x)
- 比如 前几轮通过旧策略 π ( R L ′ ) \pi_{(RL')} π(RL′)采样的数据放在经验缓冲区中,把新策略多次迭代更新出 π ( R L 2 ) \pi_{(RL2)} π(RL2) π ( R L 3 ) \pi_{(RL3)} π(RL3),这个过程中重要性采样的比值为 π ( R L ) π ( R L ′ ) \frac{\pi_{(RL)}}{\pi_{(RL')}} π(RL′)π(RL) π ( R L 2 ) π ( R L ′ ) \frac{\pi_{(RL2)}}{\pi_{(RL')}} π(RL′)π(RL2)…
- 再之后,通过 π ( R L 3 ) \pi_{(RL3)} π(RL3)采样一批新数据再次放在经验缓冲区里,从而积雪迭代更新出 4 5 6 这个过程中重要性采样的比值变为 π ( R L 4 ) π ( R L 3 ) / \frac{\pi(RL4)}{\pi(RL3)}/ π(RL3)π(RL4)/. π ( R L 5 ) π ( R L 3 ) / \frac{\pi(RL5)}{\pi(RL3)}/ π(RL3)π(RL5)/… 以此类推。
- 且使用一些方法限制策略更新的幅度,例如PPO中截断重要性采样比率.
- d. 然后通过最大化奖励而不断迭代 π R L ′ \pi^{RL'} πRL′ 迭代过程中可一定程度的重复使用旧策略生成的已有数据反复验证。
- e. 按照更新后的目标函数进行梯度计算和参数更新
- f. 在训练过程中,可以多次重复使用经验回复缓冲区中的数据进行训练,但是需要注意的是 随着梯度更新,新旧策略之间的差异可能会变化大,这时重要性采样权重可能变得不稳定,从而影响训练的稳定性。
- 为了避免 π ∅ R L \pi_{\varnothing}^{RL} π∅RL 只要一更新便只能一次次去采样一批批新问题数据。(为了提高数据利用率),我们改成让 π ∅ R L ′ \pi_{\varnothing}^{RL'} π∅RL′去和环境交互,
- 第三部分是加在最后边的偏置项 γ E x D p r e t r a i n [ l o g ( π ∅ R L ) ] \gamma E_{x~D_{pretrain}}[log(\pi_{\varnothing}^{RL})] γEx Dpretrain[log(π∅RL)] 其中 D p r e t r a i n D_{pretrain} Dpretrain是GPT3的预训练分布,预训练损失系数 γ \gamma γ控制预训练梯度的强度,且为0 则是PPO模型,否则称为PPO-ptx模型。 之所以加最后这个偏置项是防止ChatGPT在训练过程中过度优化,从而避免过于放飞自我,通过某种刁钻的方式愉悦人类,而不是老实地根据问题给出正确答案。GPT3->SFT->RM->RLHF.
模型效果

PPO-Ptx/PPO > SFT > GPT(with prompted) > GPT
人类对齐的效果 好于 SFT 好于GPT with prompted 调整过的 好于GPT only。
参考链接:
李沐视频讲解
ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT
相关文章:
大模型学习笔记 - InstructGPT中的微调与对齐
LLM 微调 之 InstructGPT中的微调与对齐 LLM 微调 之 InstructGPT中的微调与对齐 技术概览 InstructGPT中的微调与对齐 大体步骤标注数据量模型训练 1. SFT 是如何训练的2. Reward Model是如何训练的3. RLHF 是如何训练的具体讲解RLHF 的loss 函数 模型效果参考链接…...
Unity近似的Transform实现
Unity近似的Transform实现 #include <stdint.h> #include<iomanip> #include <sstream>#include "Transform.h"//Transform::Transform(const Transform& a){ // LOGW("xww 2"); //}Transform::Transform(glm::vec3 localPositio…...

openvidu私有化部署
openvidu私有化部署 简介 OpenVidu 是一个允许您实施实时应用程序的平台。您可以从头开始构建全新的 OpenVidu 应用程序,但将 OpenVidu 集成到您现有的应用程序中也非常容易。 OpenVidu 基于 WebRTC 技术,允许开发您可以想象的任何类型的用例…...

基于深度学习的视频伪造检测
基于深度学习的视频伪造检测旨在利用深度学习技术来检测和识别伪造的视频内容。伪造视频,尤其是深伪(Deepfake)视频,近年来随着生成对抗网络(GAN)技术的发展,变得越来越逼真和难以识别。这对个人…...

python机器人编程——开发一个pymatlab工具箱(上)
目录 一、前言二、实现过程2.1 封装属性2.2 数据流化显示2.3 输入数据的适应性 三、核心代码说明3.1 设置缓存3.2 随机信号3.3 根据设置绘图 五、总结四、源码PS.扩展阅读ps1.六自由度机器人相关文章资源ps2.四轴机器相关文章资源ps3.移动小车相关文章资源 一、前言 我们知道m…...

输入类控件
目录 1.Line Edit 代码示例: 录入个人信息 代码示例: 使用正则表达式验证输入框的数据 代码示例: 验证两次输入的密码一致 代码示例: 切换显示密码 2.Text Edit 代码示例: 获取多行输入框的内容 代码示例: 验证输入框的各种信号 3.Combo Box 代码示例: 使用下拉框模拟…...

C++20中的模块
大多数C项目使用多个翻译单元(translation units),因此它们需要在这些单元之间共享声明和定义(share declarations and definitions)。headers的使用在这方面非常突出。模块(module)是一种language feature,用于在翻译单元之间共享声明和定义。它们是某些…...

Selenium与流行框架集成:pytest与Allure报告
Selenium与流行框架集成:pytest与Allure报告 在现代软件开发中,自动化测试是确保产品质量和快速迭代的关键。Selenium作为业界领先的Web自动化测试工具,其灵活性和强大的功能受到广泛认可。为了进一步提升测试效率和报告质量,本文…...

日撸Java三百行(day17:链队列)
目录 一、队列基础知识 1.队列的概念 2.队列的实现 二、代码实现 1.链队列创建 2.链队列遍历 3.入队 4.出队 5.数据测试 6.完整的程序代码 总结 一、队列基础知识 1.队列的概念 今天我们继续学习另一个常见的数据结构——队列。和栈一样,队列也是一种操…...

Android摄像头采集选Camera1还是Camera2?
Camera1还是Camera2? 好多开发者纠结,Android平台采集摄像头,到底是用Camera1还是Camera2?实际上,Camera1和Camera2分别对应相机API1和相机API2。Android 5.0开始,已经弃用了Camera API1,新平台…...

零基础5分钟上手亚马逊云科技AWS核心云开发/云架构 - 创建高可用数据库集群
简介: 欢迎来到小李哥全新亚马逊云科技AWS云计算知识学习系列,适用于任何无云计算或者亚马逊云科技技术背景的开发者,让大家零基础5分钟通过这篇文章就能完全学会亚马逊云科技一个经典的服务开发架构方案。 我将每天介绍一个基于亚马逊云科…...

力扣315.计算右侧小于当前元素的个数
力扣315.计算右侧小于当前元素的个数 离散化 树状数组 const int N 100010;int tr[N],n;class Solution {public:vector<int> countSmaller(vector<int>& nums) {n nums.size();vector<int> tmp(nums);vector<int> res(n);memset(tr,0,sizeo…...

websocket,css动画和css-position、display、区别
一、websocket codereturn {// 用于存储 WebSocket 返回的状态数据statusList: [],},mounted() {this.setupWebSocket();this.startBlinking();},methods: {setupWebSocket() {// 创建 WebSocket 连接const socket = new WebSocket(ws://xxx.xxx:xxx/xxx);// WebSocket 连接成功…...

前端获取视频文件宽高信息和视频时长
安装 yarn add video-metadata-thumbnails | npm install video-metadata-thumbnails引入依赖包 import { getMetadata } from video-metadata-thumbnails使用 if (file.name.includes(mp4)) {if (file) {try {console.log(file)// 获取视频的元数据const metadata await …...

【区块链+医疗健康】基于区块链的药品类监管应用管理系统 | FISCO BCOS应用案例
退热类药品的购药信息及政企互动信息等各项数据的安全性、保密性、真实性,不仅影响着监管部门的科学监管、 有效监管,也影响着企业的经营安全、诚信口碑,是区域药品安全监管工作进展的直观体现。 江苏数予科技有限公司构建基于区块链的药品类…...
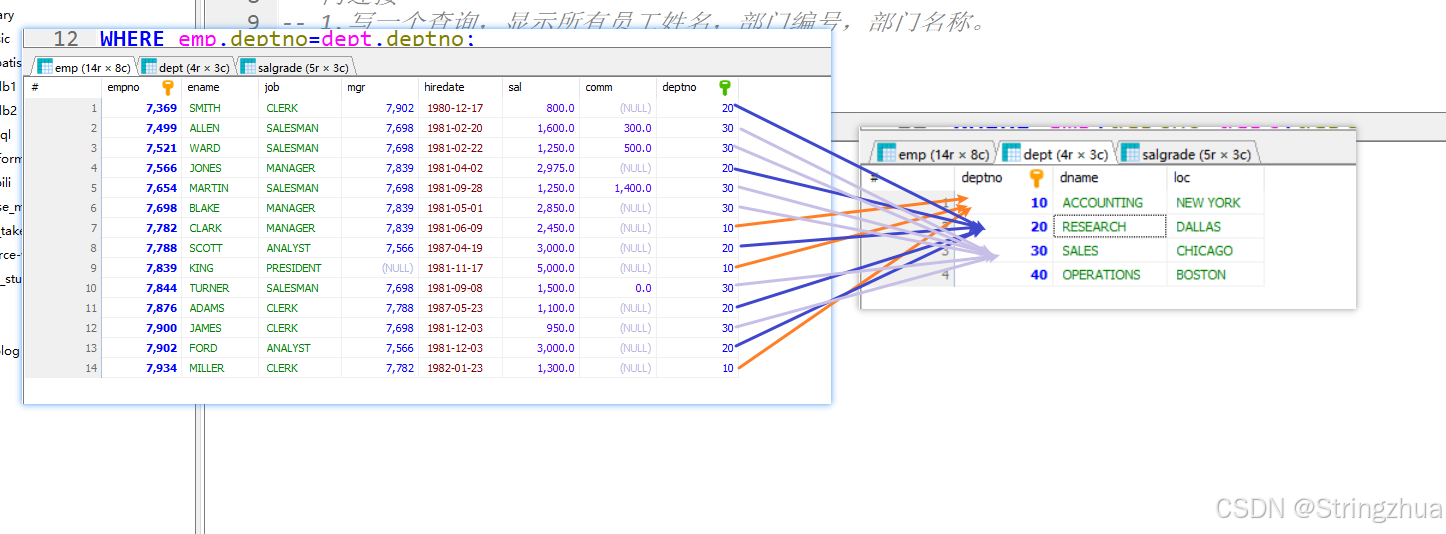
MySQL4多表查询 内连接
多表查询 数据准备 CREATE DATABASE db4; USE db4; -- 创建部门表 create table if not exists dept(deptno varchar(20) primary key , -- 部门号name varchar(20) -- 部门名字 );-- 创建员工表 create table if not exists emp(eid varchar(20) primary key , -- 员工编号…...

Java -数组
1.一维数组 1.1数组定义 public class Main {public static void main(String[] args) throws Exception {int[] a new int[10];float[] f new float[10];double[] d new double[10];char[] c new char[10];} } 1.2 初始化 public class Main {public static void main(S…...

.prettierrc.js 有什么用
.prettierrc.js 是 Prettier 代码格式化工具的配置文件。 1. 作用 Prettier 是一个用于统一代码风格的工具,它可以使代码更具可读性和一致性。.prettierrc.js 文件用于自定义 Prettier 的格式化规则。 通过配置 .prettierrc.js,团队中的开发者可以遵循…...

haproxy七层代理
一.haproxy的基本部署 1.RS上装nginx [rootwebserver1 ~]# dnf install nginx -y 2.再RS上写入测试信息 [rootwebserver1 ~]# echo webserver1 - 172.25.254.10 > /usr/share/nginx/html/index.html [rootwebserver1 ~]# systemctl enable --now nginx [rootwebserver…...

<数据集>柑橘缺陷识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:1290张 标注数量(xml文件个数):1290 标注数量(txt文件个数):1290 标注类别数:4 标注类别名称:[Orange-Green-Black-Spot, Orange-Black-Spot, Orange-Canker, Orange…...

C++性能调优第一步:手把手教你用QueryPerformanceCounter和chrono精准测量微秒级函数耗时
C性能调优实战:微秒级耗时测量的艺术与科学 在追求极致性能的世界里,每一微秒都至关重要。高频交易系统中,1微秒的延迟可能意味着数百万美元的损失;游戏引擎里,帧间时间的细微波动会导致画面卡顿;实时音视频…...

Linux内核中的驱动程序开发高级话题
Linux内核中的驱动程序开发高级话题 引言 驱动程序是Linux内核中负责与硬件设备交互的重要组成部分,它为操作系统和硬件之间提供了桥梁。随着硬件技术的发展和系统复杂性的增加,驱动程序开发面临着越来越多的挑战。本文将深入探讨Linux内核中驱动程序开发…...

GLM-4V-9B多模态入门必看:图片上传→提问→结构化输出三步走
GLM-4V-9B多模态入门必看:图片上传→提问→结构化输出三步走 想让AI看懂图片并回答你的问题吗?GLM-4V-9B多模态大模型就能做到。这个模型不仅能理解图片内容,还能用文字详细回答你的各种问题,就像有个专业的图片分析师随时待命。…...

Omni-Vision Sanctuary 算法优化:LSTM时序网络在视频分析中的应用
Omni-Vision Sanctuary 算法优化:LSTM时序网络在视频分析中的应用 1. 引言:视频分析中的时序挑战 视频数据与静态图像最大的区别在于时间维度。传统计算机视觉方法在处理连续帧时,往往将每一帧视为独立图像进行分析,忽略了帧与帧…...

2025_NIPS_Spatial-Aware Decision-Making with Ring Attractors in Reinforcement Learning Systems
文章核心总结与翻译 一、主要内容 文章提出将受神经回路动力学启发的环形吸引子(Ring Attractors)整合到强化学习(RL)系统中,以解决空间结构化环境中的高效动作选择问题。通过构建外源性连续时间循环神经网络(CTRNN)模型和内源性深度学习(DL)模块两种实现方式,环形…...

OpenClaw监控告警方案:Qwen3-14B驱动服务器异常检测
OpenClaw监控告警方案:Qwen3-14B驱动服务器异常检测 1. 为什么需要智能化的服务器监控 作为个人站长,我经历过太多次深夜被服务器宕机惊醒的噩梦。传统监控工具要么配置复杂(比如PrometheusGrafana全家桶),要么告警方…...

3分钟突破限制!用XiaoMusic让小爱音箱自由播放全网音乐
3分钟突破限制!用XiaoMusic让小爱音箱自由播放全网音乐 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否曾因音乐平台版权限制而无法播放喜欢的歌曲…...

释放桌游设计潜能:CardEditor如何重构卡牌创作流程
释放桌游设计潜能:CardEditor如何重构卡牌创作流程 【免费下载链接】CardEditor 一款专为桌游设计师开发的批处理数值填入卡牌生成器/A card batch generator specially developed for board game designers 项目地址: https://gitcode.com/gh_mirrors/ca/CardEdi…...

从NetworkManager冲突到配置文件错误:一步步教你排查Linux网络服务故障
从NetworkManager冲突到配置文件错误:一步步教你排查Linux网络服务故障 当你深夜加班部署服务器时,突然发现网络服务无法启动,屏幕上跳出那行熟悉的Job for network.service failed错误提示,是不是瞬间血压飙升?作为L…...
。)
Python爬虫入门:10步快速掌握网页数据抓取,【大数据实战】如何从0到1构建用户画像系统(案例+数据仓库+Airflow调度)。
准备工作 安装Python环境,确保版本在3.6以上。推荐使用Anaconda管理Python环境,避免版本冲突。安装必要的库,如requests、BeautifulSoup、lxml等。可以通过pip命令快速安装: pip install requests beautifulsoup4 lxml理解基本概念…...