【多模态处理】利用GPT逐一读取本地图片并生成描述并保存,支持崩溃后从最新进度恢复
【多模态处理】利用GPT逐一读取本地图片并生成描述,支持崩溃后从最新进度恢复题
- 代码功能:
- 核心功能
- 最后碎碎念
- 代码(使用中转平台url):
- 代码(直接使用openai的key)
- 注意
代码功能:
读取本地图片文件,并使用GPT模型生成图像的元数据描述。生成的结果会保存到一个JSON文件中。代码还包含了检查点机制,以便在处理过程中程序崩溃时能够从最新的位置继续生成。
核心功能
- 读取文件并设置变量:
- 从JSON文件中读取图像路径、宽度和高度等变量。
- 根据读取的变量设置prompt,调用GPT模型。
- 调用GPT模型:
- 使用openai.ChatCompletion.create方法调用GPT模型,生成图像的元数据描述。
- 将生成的结果保存到JSON文件中。
- 保存输出到JSON:
- 每处理一张图片,就将结果追加到JSON文件中。
- 使用检查点机制:
- 每处理一张图片后,保存当前处理的位置。
- 如果处理过程中出现错误,程序可以从上次保存的位置继续处理。
- 处理本地图片文件:
- 从本地文件夹读取图片文件,并对每张图片进行处理。
最后碎碎念
提供一个模板,方便大家理解其思想,使用的时候,可以和openai最基本的代码对比着看
代码(使用中转平台url):
使用中转平台(需要设置中转平台url):
from PIL import Image
import os
import base64
import openai
import pickle
import json# 设置API密钥和中转平台URL
API_SECRET_KEY = "your_api_secret_key"
BASE_URL = "https://api.your_base_url.com/v1"# 图像文件夹路径
image_directory_path = 'your_image_directory_path'# 设置要处理的图像数量
number_of_images_to_process = 50# 输出文件路径
output_file_path = "output_results.json"# 初始化计数器
image_counter = 0# 读取 JSON 数据文件
data_file = 'your_data_file.json'
with open(data_file, 'r') as f:data = json.load(f)def encode_image(image_path):with open(image_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode('utf-8')def get_image_details(image_path):"""获取图像的详细信息,包括图像ID和尺寸。参数:image_path (str): 图像文件的路径。返回:tuple: 包含图像ID(文件名,不包括扩展名)和图像尺寸(宽度,高度)的元组。示例:get_image_details('path/to/image.jpg') -> ('image', (800, 600))"""image_filename = os.path.basename(image_path)image_id = os.path.splitext(image_filename)[0]with Image.open(image_path) as img:image_size = img.sizereturn image_id, image_sizedef chat_completions(image_path, width, height):base64_image = encode_image(image_path)image_id, image_size = get_image_details(image_path)client = OpenAI(api_key=API_SECRET_KEY, base_url=BASE_URL)response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "system", "content": "You are an assistant that provides metadata information about images."},{"role": "user", "content": f"Image ID: {image_id}, Width: {width}, Height: {height}"}],max_tokens=3000,timeout=999,)return response# 初始化结果字典
results_dict = {}# 检查是否存在检查点文件
checkpoint_file = "checkpoint.pkl"
if os.path.exists(checkpoint_file):with open(checkpoint_file, "rb") as f:start_index = pickle.load(f)
else:start_index = 0# 处理图像文件
for i, image in enumerate(data[start_index:], start=start_index):image_name = image['image_path']image_file = os.path.join(image_directory_path, image_name)image_width = image['width']image_height = image['height']if image_name.lower().endswith(('.png', '.jpg', '.jpeg', '.tiff', '.bmp', '.gif')):try:response = chat_completions(image_file, image_width, image_height)result = {image_name: response.choices[0].message['content']}with open(output_file_path, "a") as output_file:output_file.write(json.dumps(result) + "\n")except Exception as e:print(f"Error processing image {image_name}: {e}")continueimage_counter += 1if image_counter >= number_of_images_to_process:breakwith open(checkpoint_file, "wb") as f:pickle.dump(i+1, f)代码(直接使用openai的key)
from PIL import Image
import os
import base64
import openai
import pickle
import json# 设置API密钥
API_SECRET_KEY = "your_api_secret_key"# 图像文件夹路径
image_directory_path = 'your_image_directory_path'# 设置要处理的图像数量
number_of_images_to_process = 50# 输出文件路径
output_file_path = "output_results.json"# 初始化计数器
image_counter = 0# 读取 JSON 数据文件
data_file = 'your_data_file.json'
with open(data_file, 'r') as f:data = json.load(f)def encode_image(image_path):with open(image_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode('utf-8')def get_image_details(image_path):"""获取图像的详细信息,包括图像ID和尺寸。参数:image_path (str): 图像文件的路径。返回:tuple: 包含图像ID(文件名,不包括扩展名)和图像尺寸(宽度,高度)的元组。示例:get_image_details('path/to/image.jpg') -> ('image', (800, 600))"""image_filename = os.path.basename(image_path)image_id = os.path.splitext(image_filename)[0]with Image.open(image_path) as img:image_size = img.sizereturn image_id, image_sizedef chat_completions(image_path, width, height):base64_image = encode_image(image_path)image_id, image_size = get_image_details(image_path)openai.api_key = API_SECRET_KEYresponse = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "system", "content": "You are an assistant that provides metadata information about images."},{"role": "user", "content": f"Image ID: {image_id}, Width: {width}, Height: {height}"}],max_tokens=3000,timeout=999,)return response# 初始化结果字典
results_dict = {}# 检查是否存在检查点文件
checkpoint_file = "checkpoint.pkl"
if os.path.exists(checkpoint_file):with open(checkpoint_file, "rb") as f:start_index = pickle.load(f)
else:start_index = 0# 处理图像文件
for i, image in enumerate(data[start_index:], start=start_index):image_name = image['image_path']image_file = os.path.join(image_directory_path, image_name)image_width = image['width']image_height = image['height']if image_name.lower().endswith(('.png', '.jpg', '.jpeg', '.tiff', '.bmp', '.gif')):try:response = chat_completions(image_file, image_width, image_height)result = {image_name: response.choices[0].message['content']}with open(output_file_path, "a") as output_file:output_file.write(json.dumps(result) + "\n")except Exception as e:print(f"Error processing image {image_name}: {e}")continueimage_counter += 1if image_counter >= number_of_images_to_process:breakwith open(checkpoint_file, "wb") as f:pickle.dump(i+1, f)注意
上面的代码,最后四行:(先判断处理图像数量是否大于规定处理图像数量,再保存checkpoint)
if image_counter >= number_of_images_to_process:break
with open(checkpoint_file, "wb") as f:pickle.dump(i+1, f)
有时候要替换逻辑为这样(先保存checkpoint,再判断处理图像数量是否大于规定处理图像数量)
with open(checkpoint_file, "wb") as f:pickle.dump(i+1, f)
if image_counter >= number_of_images_to_process:break
然后,每次程序运行结束时,比如5.jpg处理完,第二次运行程序,不是再处理一遍5.jpg,而是从6.jpg开始。但有的时候不用替换,也仍然从6.jpg开始,不知道为什么。
但确实下方替换后更好一点,因为有的时候break完后直接跳出循环,导致最后一次的i+1没有更新。
相关文章:

【多模态处理】利用GPT逐一读取本地图片并生成描述并保存,支持崩溃后从最新进度恢复
【多模态处理】利用GPT逐一读取本地图片并生成描述,支持崩溃后从最新进度恢复题 代码功能:核心功能最后碎碎念 代码(使用中转平台url):代码(直接使用openai的key) 注意 代码功能: 读…...

【rk3588】获取相机画面
需求:获取相机画面,并在连接HDMI线,在显示器上显示 查找设备 v4l2-ctl --list-devices H65 USB CAMERA: H65 USB CAMERA (usb-0000:00:14.0-1):/dev/video2/dev/video3播放视频 gst-launch-1.0 v4l2src device/dev/video22 ! video/x-ra…...

数据结构的基本概念
数据结构的基本概念 数据是什么? 数据 : 数据是信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序识别(二进制0|1)和处理的符号的集合。数据是计算机程序加工的原料。 早期计算机处理的…...

AI人工智能机器学习
AI人工智能 机器学习的类型(ML) 学习意味着通过学习或经验获得知识或技能。 基于此,我们可以定义机器学习(ML) 它被定义为计算机科学领域,更具体地说是人工智能的应用,它提供计算机系统学习数据和改进经验而不被明确编程的能力。 基本上&…...

试用AWS全新神器:Amazon Bedrock的「Open Artifacts」版Claude.ai Artifacts
Claude.ai的Artifacts真是太方便了。 GitHub上的AWS Samples仓库中有一个仿制Artifacts的应用程序。 Open Artifacts for Amazon Bedrock https://github.com/aws-samples/open_artifacts_for_bedrockhttps://github.com/aws-samples/open_artifacts_for_bedrock本文将介绍「…...

W3C XML 活动
关于W3C的XML活动,XML(可扩展标记语言)是一种用于描述、存储、传送及交换数据的标准。W3C(万维网联盟)对XML的发展起到了关键作用,推出了一系列的版本和相关的技术规范。 XML版本历史: XML 1.0&…...

vue请求springboot接口下载zip文件
说明 其实只需要按照普通文件流下载即可,以下是一个例子,仅供参考。 springboot接口 RestController RequestMapping("/api/files") public class FileController {GetMapping("/download")public ResponseEntity<Resource>…...

PySide6||QPushButton的QSS样式
1、狗狗拜按钮 QQ202484-03338 (online-video-cutter.com) /* QPushButton的基本样式 */ QPushButton { background-image:url(:/xxx/第1帧.png); /* 设置背景图片 */ background-repeat: no-repeat; /* 不重复背景图片 */ background-position: center; /* 将背景图片居中…...

HarmonyOS鸿蒙应用开发之ArkTS基本语法
ArkTS(Ark TypeScript)是一种基于TypeScript的扩展语言,专为鸿蒙应用开发设计。它在保持TypeScript基本语法风格的基础上,对TypeScript的动态类型特性施加了更严格的约束,并引入了静态类型,以减少运行时开销…...

Web开发-CSS篇-上
CSS的发展历史 CSS(层叠样式表)最初由万维网联盟(W3C)于1996年发布。CSS1是最早的版本,它为网页设计提供了基本的样式功能,如字体、颜色和间距。随着互联网的发展,CSS也不断演进: C…...

在mac上通过 MySQL 安装包安装 MySQL 之后,终端执行 mysql 命令报错 command not found: mysql
在 mac 上通过 MySQL 安装包安装 MySQL 之后,如果在终端中运行 mysql 命令时遇到 command not found: mysql 错误,通常是因为 MySQL 的二进制文件没有被添加到系统的 PATH 环境变量中。 解决方法:手动添加 MySQL 到 PATH 环境变量 1.找到 M…...

Unity入门4——常用接口
C#中常用类和接口 DateTime:表示某个时刻 DateTime.Now:拿到系统当前时间DtaTime.TimeOfDay:获取此实例当天的时间 Quaternion:用来旋转,采用四元数,由w(实部)和x,y,z(虚…...
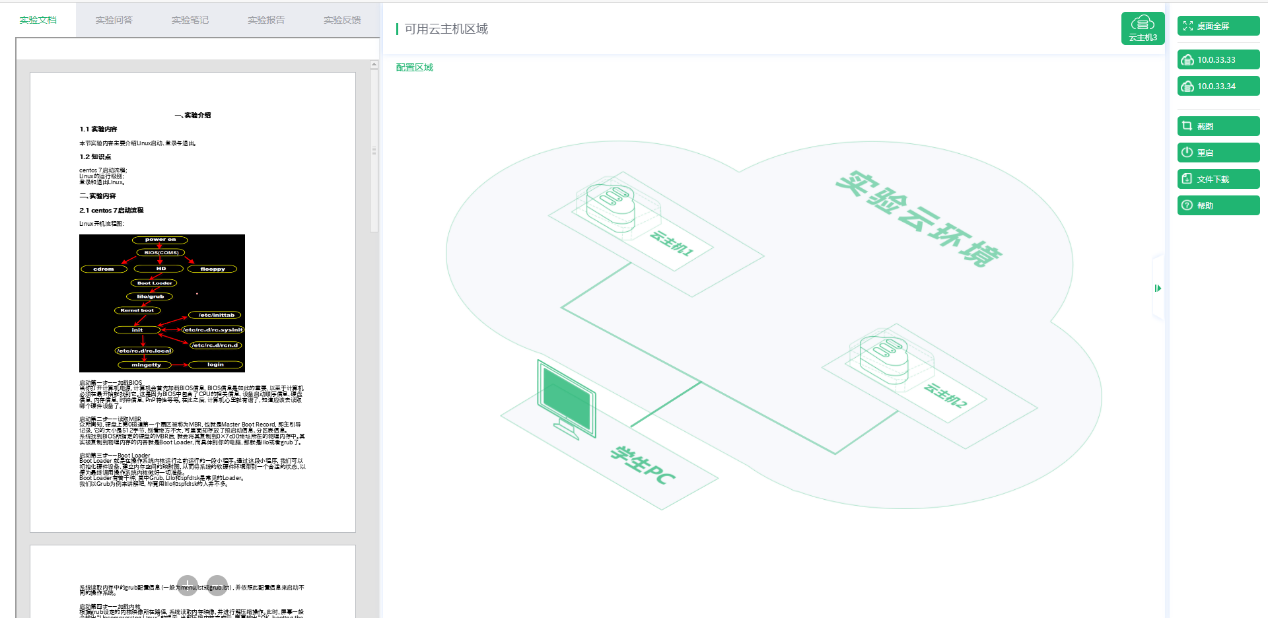
职业教育云计算实验实训室建设应用案例
云计算作为信息技术领域的一次革命,正在深刻改变着我们的工作和生活方式。随着企业对云计算技术的依赖日益加深,对具备云计算技能的专业人才的需求也日益迫切。职业院校面临着培养符合行业标准的云计算人才的挑战。唯众凭借其在教育技术领域的专业经验&a…...

MySQL-MHA高可用配置及故障切换
目录 案例搭建 1:所有服务器关闭防火墙 2:设置hosts文件 3:安装 MySQL 数据库 4:修改参数 5:安装 MHA 软件 6:配置无密码认证 7:配置 MHA 8:模拟 master 故障 MHA(MasterHi…...

Sentinel 滑动时间窗口源码分析
前言: Sentinel 的一个重要功能就是限流,对于限流来说有多种的限流算法,比如滑动时间窗口算法、漏桶算法、令牌桶算法等,Sentinel 对这几种算法都有具体的实现,如果我们对某一个资源设置了一个流控规则,并…...

猎码安卓APP开发IDE,amix STUDIO中文java,HTML5开发工具
【无爱也能发电】Xili 2024/8/2 10:41:20 猎码安卓APP开发IDE,amix java开发工具 我研发这些只有一小部分理由是为了赚钱,更多是想成就牛逼的技术产品。 目前的产品就够我赚钱的,我持续更新就好了,没必要继续研究。 IDE不赚钱,谁…...

【Deep-ML系列】Linear Regression Using Gradient Descent(手写梯度下降)
题目链接:Deep-ML 这道题主要是要考虑矩阵乘法的维度,保证维度正确,就可以获得最终的theata import numpy as np def linear_regression_gradient_descent(X: np.ndarray, y: np.ndarray, alpha: float, iterations: int) -> np.ndarray:…...

NVIDIA A100 和 H100 硬件架构学习
目前位置NV各种架构代号: NVIDIA GPU 有多个代号和架构,这些架构对应不同的世代和硬件特性。以下是 NVIDIA 主要 GPU 架构及其计算能力(Compute Capability)代号的简要概述: Tesla 架构 G80、GT200 Compute Capabi…...

企业研发设计协同解决方案
新迪三维设计,20年深耕三维CAD 全球工业软件研发不可小觑的中国力量 2003-2014 年 新迪数字先后成为达 索SolidWorks、 ANSYS Spaceclaim、MSC等三维CAD/CAE 软件厂商的中国研发中心,深度参与国际 一流工业软件的研发过程,积累了丰富的 技术经…...

iOS 18(macOS 15)Vision 中新增的任意图片智能评分功能试玩
概述 在 WWDC 24 中库克“大厨”除了为 iOS 18 等平台重磅新增了 Apple Intelligence 以外,苹果也利用愈发成熟的机器学习引擎扩展了诸多内置框架,其中就包括 Vision。 想用本机人工智能自动为我们心仪的图片打一个“观赏分”吗?“如意如意&…...

番茄小说下载器:终极开源工具,让数字阅读更简单高效
番茄小说下载器:终极开源工具,让数字阅读更简单高效 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾经遇到过这样的困境:正在追更的…...

视觉化看板工具怎么选?9 款创意团队项目协作平台优势分析
本文将深入对比 9 款支持视觉化看板的项目协作工具:Worktile、Trello、Asana、monday.com、ClickUp、Wrike、Notion、Jira、Teambition,重点分析它们在创意团队中的项目管理能力、适用场景、部署方式、协作效率与安全合规差异,帮助企业选型者…...

目前遇到问题
手机重启以后,app虽然已经启动了自启动,但是实际并没有启动应该是没有启动监听开机广播...
)
SPSS老版本用户必看:如何用R3.2.5实现高级统计分析(附完整语法示例)
SPSS老版本用户必看:如何用R3.2.5实现高级统计分析(附完整语法示例) 对于长期使用SPSS老版本的研究者来说,面对日益复杂的数据分析需求时,常常会遇到软件功能受限的困境。特别是在临床医学和社会科学研究中,…...

Linux 的 ls 命令
Linux 的 ls 命令是最基础且常用的文件管理命令之一,用于列出目录中的文件和子目录。作为Unix/Linux系统中最古老且最核心的命令之一,ls 最早出现在1971年的Unix系统中。下面是该命令的详细说明: 基本语法 ls [选项] [文件/目录]如果不指定…...

经典入门教程:Simulink二次调频AGC系统解析,含储能与火电机组应用
simulink二次调频AGC,含储能、火电机组。 经典两区域系统二次调频,适合初学者入门。电力系统二次调频就像给电网做瑜伽——既要保持平衡,又要灵活应对突发状况。今天咱们用Simulink撸个带储能的两区域AGC模型,手把手感受火力发电机…...

AI辅助开发新范式:让快马智能模型为你规划互联网问卷系统架构
今天在开发一个在线问卷调查系统时,遇到了几个技术难点。经过在InsCode(快马)平台上的实践和AI辅助,总结出了一套完整的解决方案,分享给大家。 前端问卷页面的动态渲染逻辑 对于不同题型(单选、多选、填空)的渲染&am…...
)
亚马逊德国站VAT发票自动筛选:手把手教你用浏览器控制台JS代码搞定(附Edge/Chrome/Firefox全版本)
亚马逊德国站VAT发票智能筛选:浏览器控制台JS代码实战指南 每次月底处理税务发票时,跨境电商卖家们是否总被海量的PDF文件淹没?特别是亚马逊德国站的卖家,面对后台密密麻麻的发票列表,手动筛选符合特定税号条件的文件不…...
)
单目相机实战:用OpenCV的solvePnP实现物体位姿估计(附Python代码)
单目相机实战:用OpenCV的solvePnP实现物体位姿估计(附Python代码) 在机器人导航、增强现实和工业检测等领域,精确获取物体相对于相机的位置和姿态是关键挑战。单目相机因其成本优势和轻量化特点,成为许多视觉系统的首选…...

推荐系统中的特征工程
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。所以特征工程的目的是最大限度地从原始数据中提取特征, 以供算法和模型使用。 特征类型 普通离散特征 职业, 婚姻状态等, 同常枚举值不超过100个.id类特…...