探索算法系列 - 前缀和算法
目录
一维前缀和(原题链接)
二维前缀和(原题链接)
寻找数组的中心下标(原题链接)
除自身以外数组的乘积(原题链接)
和为 K 的子数组(原题链接)
和可被 K 整除的子数组(原题链接)
连续数组(原题链接)
矩阵区域和(原题链接)

一维前缀和(原题链接)
描述:
给定一个长度为n的数组a1,a2,....ana1,a2,....an.
接下来有q次查询, 每次查询有两个参数l, r.
对于每个询问, 请输出
输入描述:
第一行包含两个整数n和q.
第二行包含n个整数, 表示a1,a2,....ana1,a2,....an.
接下来q行,每行包含两个整数 l和r.

输出描述:
输出q行,每行代表一次查询的结果.

解题思路:
- 读取输入:读取数组的长度
n和查询的次数q,接着读取数组的元素。- 前缀和计算:
- 创建一个
dp数组,其中dp[i]存储从数组的起始位置到第i个元素的和。- 通过前缀和数组
dp,可以快速计算任意子区间[l, r]的和。- 处理查询:
- 对于每个查询
(l, r),利用前缀和数组dp来计算区间和dp[r] - dp[l-1],并输出结果。
步骤说明:
输入处理:
- 使用
cin读取输入的数组大小n和查询次数q。- 读取数组的元素并存储到
arr中。计算前缀和:
- 初始化前缀和数组
dp。- 使用一个循环来填充
dp数组,其中dp[i]是从数组的开始到第i个元素的累积和。查询处理:
- 读取每个查询的区间
[l, r]。- 计算并输出区间
[l, r]的和,这通过前缀和数组dp来实现。
具体代码:
#include <iostream> #include <vector>using namespace std;int main() {int n, q;cin >> n >> q; // 读取数组的大小 n 和查询的数量 qvector<int> arr(n + 1); // 创建一个大小为 n + 1 的数组,索引从 1 开始for(int i = 1; i <= n; i++)cin >> arr[i]; // 读取数组元素vector<long long> dp(n + 1); // 创建前缀和数组 dp,大小为 n + 1for(int i = 1; i <= n; i++)dp[i] = dp[i-1] + arr[i]; // 计算前缀和,dp[i] 是从 arr[1] 到 arr[i] 的累积和int l, r;while(q--) // 对于每个查询{cin >> l >> r; // 读取查询的区间 [l, r]// 计算并输出区间 [l, r] 的和cout << dp[r] - dp[l - 1] << endl; }return 0; }
二维前缀和(原题链接)
描述:
给你一个 n 行 m 列的矩阵 A ,下标从1开始。
接下来有 q 次查询,每次查询输入 4 个参数 x1 , y1 , x2 , y2
请输出以 (x1, y1) 为左上角 , (x2,y2) 为右下角的子矩阵的和,
输入描述:
第一行包含三个整数n,m,q.
接下来n行,每行m个整数,代表矩阵的元素
接下来q行,每行4个整数x1, y1, x2, y2,分别代表这次查询的参数

输出描述:
输出q行,每行表示查询结果。

解题思路:
输入处理:
- 读取二维数组的行数
n、列数m和查询的次数q。- 读取二维数组的数据并存储到
arr中。前缀和计算:
- 创建一个二维前缀和数组
dp,用来存储从(1, 1)到(i, j)的矩阵和。- 计算
dp数组的值,通过动态规划公式进行填充:dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + arr[i][j]这个公式用于去除重复计算的区域,并包含当前元素arr[i][j]。查询处理:
- 对于每个查询
(x1, y1, x2, y2),使用前缀和数组dp快速计算子矩阵的和:dp[x2][y2] - dp[x1-1][y2] - dp[x2][y1-1] + dp[x1-1][y1-1]其中,dp[x2][y2]是从 (1, 1) 到 (x2, y2) 的矩阵和,减去dp[x1-1][y2]和dp[x2][y1-1],再加上dp[x1-1][y1-1]修正重叠区域。
步骤说明:
取输入数据:
- 读取
n、m和q。- 读取二维数组的元素到
arr中。计算二维前缀和:
- 初始化
dp数组为零。- 通过嵌套循环填充
dp数组,使用动态规划公式来计算前缀和。处理查询并输出结果:
- 对每个查询
(x1, y1, x2, y2),利用前缀和数组dp计算子矩阵的和,并输出结果。
具体代码:
#include <iostream> #include <vector> using namespace std;int main() {int n = 0, m = 0, q = 0;cin >> n >> m >> q; // 读取矩阵的行数 n、列数 m 和查询的数量 q// 创建并填充二维数组 arr,索引从 1 开始vector<vector<int>> arr(n + 1, vector<int>(m + 1));for(int i = 1; i <= n; i++)for(int j = 1; j <= m; j++)cin >> arr[i][j]; // 读取矩阵元素// 创建并计算二维前缀和数组 dpvector<vector<long long>> dp(n + 1, vector<long long>(m + 1));for(int i = 1; i <= n; i++)for(int j = 1; j <= m; j++)dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + arr[i][j]; // 计算前缀和int x1 = 0, y1 = 0, x2 = 0, y2 = 0;while(q--) // 处理每一个查询{cin >> x1 >> y1 >> x2 >> y2; // 读取查询的四个角坐标// 计算并输出子矩阵的和cout << dp[x2][y2] - dp[x1 - 1][y2] - dp[x2][y1 - 1] + dp[x1 - 1][y1 - 1] << endl;}return 0; }
寻找数组的中心下标(原题链接)
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。

解题思路:
定义前缀和和后缀和:
- 使用两个数组
f和g,分别存储当前索引i左侧和右侧元素的和。f[i]代表从数组开头到索引i-1的和,即索引i之前的所有元素的和。g[i]代表从索引i+1到数组末尾的和,即索引i之后的所有元素的和。计算前缀和和后缀和:
- 从左到右计算前缀和
f。- 从右到左计算后缀和
g。查找枢轴索引:
- 遍历数组,如果
f[i]等于g[i],则i是一个枢轴索引,返回i。- 如果没有找到合适的索引,返回 -1。
步骤说明:
初始化和计算前缀和
f:
- 遍历数组,从索引
1开始到数组的最后一个元素,逐步累加前面的元素和。初始化和计算后缀和
g:
- 从数组的倒数第二个元素开始,逐步累加后面的元素和。
查找满足条件的索引:
- 遍历整个数组,如果某个索引
i的前缀和f[i]等于后缀和g[i],返回i。返回结果:
- 如果没有找到符合条件的索引,返回 -1。
具体代码:
class Solution { public:int pivotIndex(vector<int>& nums) {int n = nums.size();vector<int> f(n, 0), g(n, 0);// 计算前缀和 ffor(int i = 1; i < n; i++)f[i] = f[i - 1] + nums[i - 1];// 计算后缀和 gfor(int i = n - 2; i >= 0; i--)g[i] = g[i + 1] + nums[i + 1];// 查找枢轴索引for(int i = 0; i < n; i++){if(f[i] == g[i])return i;}// 没有找到枢轴索引return -1;} };
除自身以外数组的乘积(原题链接)
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法,且在 O(n) 时间复杂度内完成此题。

解题思路:
定义前缀积和后缀积:
lprod[i]表示数组nums中从起始位置到索引i-1的所有元素的乘积(前缀积)。rprod[i]表示数组nums中从索引i+1到末尾的所有元素的乘积(后缀积)。计算前缀积:
- 从左到右遍历数组,计算每个位置
i左侧所有元素的乘积并存储在lprod[i]中。计算后缀积:
- 从右到左遍历数组,计算每个位置
i右侧所有元素的乘积并存储在rprod[i]中。计算结果数组:
- 对于每个位置
i,结果数组ret[i]是lprod[i]和rprod[i]的乘积,表示去掉nums[i]后的所有元素的乘积。
步骤说明:
初始化:
lprod和rprod数组的大小都为n + 1。lprod[0]初始化为 1,因为没有元素在位置 0 的左边。rprod[n-1]初始化为 1,因为没有元素在位置n-1的右边。计算前缀积:
- 遍历数组,从位置 1 开始,逐步计算前缀积并填充
lprod。计算后缀积:
- 遍历数组,从位置
n-2开始,逐步计算后缀积并填充rprod。生成结果数组:
- 遍历数组,将每个位置的
ret[i]计算为lprod[i] * rprod[i]。
具体代码:
class Solution { public:vector<int> productExceptSelf(vector<int>& nums) {int n = nums.size();// lprod 表示 [0, i - 1] 区间内所有元素的乘积// rprod 表示 [i + 1, n - 1] 区间内所有元素的乘积vector<int> lprod(n, 1), rprod(n, 1); // 不需要 n + 1 的大小// 计算前缀积for (int i = 1; i < n; i++)lprod[i] = lprod[i - 1] * nums[i - 1];// 计算后缀积for (int i = n - 2; i >= 0; i--)rprod[i] = rprod[i + 1] * nums[i + 1];// 生成结果数组vector<int> ret(n);for (int i = 0; i < n; i++)ret[i] = lprod[i] * rprod[i];return ret;} };
和为 K 的子数组(原题链接)
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。

解题思路:
前缀和:
- 使用前缀和来表示从数组开始到当前位置的和。
- 对于每个位置
i,计算到当前位置的前缀和sum。哈希表记录前缀和的出现次数:
- 使用一个哈希表
hash来记录前缀和及其出现的次数。hash[sum]代表前缀和sum出现的次数。查找目标和:
- 对于当前位置的前缀和
sum,检查sum - k是否在哈希表中存在。- 如果存在,则表示存在子数组和为
k,将hash[sum - k]加到结果ret中,hash[sum - k]表示到当前位置的子数组个数。更新哈希表:
- 每次更新当前前缀和
sum在哈希表中的计数。
步骤说明:
初始化:
- 创建一个哈希表
hash,并将hash[0]初始化为 1。这个设置是为了处理前缀和等于k的情况。计算前缀和并查找目标和:
- 遍历数组,累加前缀和
sum。- 如果
sum - k在哈希表中存在,则结果ret增加hash[sum - k],表示找到的符合条件的子数组的个数。更新哈希表:
- 将当前前缀和
sum的计数增加。
具体代码:
class Solution { public:int subarraySum(vector<int>& nums, int k) {unordered_map<int, int> hash; // 统计前缀和出现的次数hash[0] = 1; // 处理前缀和等于 k 的情况int sum = 0, ret = 0;for (auto x : nums) {sum += x; // 计算当前位置的前缀和// 检查 sum - k 是否在哈希表中if (hash.count(sum - k))ret += hash[sum - k]; // 如果存在,累加结果// 更新哈希表hash[sum]++;}return ret;} };
和可被 K 整除的子数组(原题链接)
给定一个整数数组 nums 和一个整数 k ,返回其中元素之和可被 k 整除的非空 子数组 的数目。
子数组 是数组中 连续 的部分。

解题思路:
前缀和:
- 计算从数组起始到当前位置的前缀和
sum。- 对于每个位置
i,前缀和sum是从数组开始到位置i的所有元素之和。余数计算:
- 对于每个前缀和
sum,计算它模k的余数r。- 由于余数可能是负数,因此需要进行调整,使余数始终是非负的。计算公式为
(sum % k + k) % k。哈希表记录余数出现次数:
- 使用一个哈希表
hash来记录每个余数出现的次数。- 如果当前余数
r已经在哈希表中出现过,那么存在以之前某个位置为结束的子数组和能被k整除。累加hash[r]到结果ret。更新哈希表:
- 每次更新当前余数
r的计数。
步骤说明:
初始化哈希表:
hash[0 % k] = 1:这个设置是为了处理从数组开头到当前位置的和能被k整除的子数组。初始值为 1 表示前缀和为 0(即不包括任何元素)的情况。计算前缀和和余数:
- 遍历数组,对每个元素
x更新前缀和sum。- 计算当前前缀和
sum的模k的余数r,并调整为非负值。查找和更新哈希表:
- 如果余数
r存在于哈希表中,将其出现次数hash[r]加到结果ret。- 更新哈希表中余数
r的计数。
具体代码:
class Solution { public:int subarraysDivByK(vector<int>& nums, int k) {unordered_map<int, int> hash;hash[0 % k] = 1; // 初始余数 0 的出现次数为 1int sum = 0, ret = 0;for (auto x : nums) {sum += x; // 计算当前位置的前缀和int r = (sum % k + k) % k; // 修正后的余数// 如果该余数曾出现过,则累加结果if (hash.count(r))ret += hash[r];// 更新当前余数的计数hash[r]++;}return ret;} };
连续数组(原题链接)
给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。

解题思路:
前缀和的概念:
- 计算当前前缀和,将数组中的 0 视为 -1,将 1 视为 +1。这样,如果一个子数组中的 0 和 1 的数量相等,那么该子数组的前缀和在开始和结束的位置是相同的。
使用哈希表记录前缀和的第一次出现位置:
- 使用哈希表
hash来记录每个前缀和首次出现的位置。- 如果前缀和已经出现过,则表示从之前出现位置到当前的位置形成的子数组是 0 和 1 数量相等的子数组。计算这个子数组的长度,并更新最大长度
ret。处理前缀和为 0 的特殊情况:
- 初始化哈希表时,将
hash[0]设置为 -1。这是为了处理从数组开头到当前索引的子数组,前缀和为 0 的情况。
步骤说明:
初始化哈希表:
hash[0] = -1:这个设置表示前缀和为 0 的情况发生在虚拟的数组起点之前的位置 -1。计算前缀和并查找:
- 遍历数组,对每个元素
nums[i],将其转化为 1(如果是 1)或者 -1(如果是 0),并累加到sum中。- 使用哈希表检查当前前缀和
sum是否已出现过。如果出现过,计算当前子数组的长度,并更新最大长度ret。- 如果当前前缀和
sum未出现过,将其位置i存储到哈希表中。
具体代码:
class Solution { public:int findMaxLength(vector<int>& nums) {unordered_map<int, int> hash;hash[0] = -1; // 默认前缀和为 0 的情况int sum = 0, ret = 0;for (int i = 0; i < nums.size(); i++) {// 将 0 转换为 -1,1 保持不变,计算前缀和sum += nums[i] == 0 ? -1 : 1;// 如果当前前缀和 sum 已出现,计算当前子数组长度if (hash.count(sum))ret = max(ret, i - hash[sum]);else// 记录当前前缀和的第一次出现位置hash[sum] = i;}return ret;} };
矩阵区域和(原题链接)
给你一个 m x n 的矩阵 mat 和一个整数 k ,请你返回一个矩阵 answer ,其中每个 answer[i][j] 是所有满足下述条件的元素 mat[r][c] 的和:

解题思路:
前缀和矩阵:
- 构建一个前缀和矩阵
dp,使得dp[i][j]表示从矩阵的左上角到位置(i-1, j-1)的所有元素的和。- 前缀和的公式是:
dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + mat[i-1][j-1]。计算每个位置的 k x k 子矩阵的和:
- 对于每个位置
(i, j),计算以该位置为中心的k x k子矩阵的和。- 确定子矩阵的边界:上边界
x1、左边界y1、下边界x2和右边界y2。- 使用前缀和矩阵
dp来计算子矩阵的和: sum=dp[x2][y2]−dp[x1−1][y2]−dp[x2][y1−1]+dp[x1−1][y1−1]\text{sum} = dp[x2][y2] - dp[x1 - 1][y2] - dp[x2][y1 - 1] + dp[x1 - 1][y1 - 1]sum=dp[x2][y2]−dp[x1−1][y2]−dp[x2][y1−1]+dp[x1−1][y1−1]- 处理边界条件以确保索引不越界。
步骤说明:
构建前缀和矩阵:
- 遍历矩阵
mat,使用前缀和的公式计算dp矩阵。计算每个位置的 k x k 子矩阵的和:
- 对于每个位置
(i, j),计算子矩阵的边界并通过前缀和矩阵dp计算和。
具体代码:
class Solution { public:vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k) {int m = mat.size(), n = mat[0].size();vector<vector<int>> dp(m + 1, vector<int>(n + 1));// 1. 预处理前缀和矩阵for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++)dp[i][j] = dp[i - 1][j] + dp[i][j - 1] - dp[i - 1][j - 1] +mat[i - 1][j - 1];// 2. 使用前缀和矩阵计算每个位置的 k x k 子矩阵的和vector<vector<int>> ret(m, vector<int>(n));for (int i = 0; i < m; i++)for (int j = 0; j < n; j++) {int x1 = max(0, i - k) + 1, y1 = max(0, j - k) + 1;int x2 = min(m - 1, i + k) + 1, y2 = min(n - 1, j + k) + 1;ret[i][j] = dp[x2][y2] - dp[x1 - 1][y2] - dp[x2][y1 - 1] +dp[x1 - 1][y1 - 1];}return ret;} };
相关文章:
探索算法系列 - 前缀和算法
目录 一维前缀和(原题链接) 二维前缀和(原题链接) 寻找数组的中心下标(原题链接) 除自身以外数组的乘积(原题链接) 和为 K 的子数组(原题链接) 和可被 …...

Stable Diffusion绘画 | 提示词基础原理
提示词之间使用英文逗号“,”分割 例如:1girl,black long hair, sitting in office 提示词之间允许换行 但换行时,记得在结尾添加英文逗号“,”来进行区分 权重默认为1,越靠前权重越高 每个提示词自身的权重默认值为1,但越靠…...

利用python写一个可视化的界面
要利用Python编写一个可视化界面,你可以使用一些图形库来实现,例如Tkinter、PyQt、wxPython等。以下是一个使用Tkinter的示例代码: import tkinter as tk# 创建一个窗口对象 window tk.Tk()# 定义一个按钮点击事件的处理函数 def buttonCli…...

第13节课:Web Workers与通信——构建高效且实时的Web应用
目录 Web Workers简介Web Workers的基本概念创建和使用Web WorkersWeb Workers的应用场景 WebSocket通信WebSocket的基本概念创建和使用WebSocketWebSocket的应用场景 实践:使用Web Workers和WebSocket示例:使用Web Workers进行大数据集处理示例…...

pam_pwquality.so模块制定密码策略
目录 设置密码策略的方法pam_pwquality.so配置详解pam_pwquality.so默认密码规则pam_pwquality.so指定密码规则问题补充设置密码策略的方法 这篇文章重点讲通过pam_pwquality.so模块配置密码策略 指定pam_pwquality.so模块参数Centos7开始使用pam_pwquality模块进行密码复杂度…...
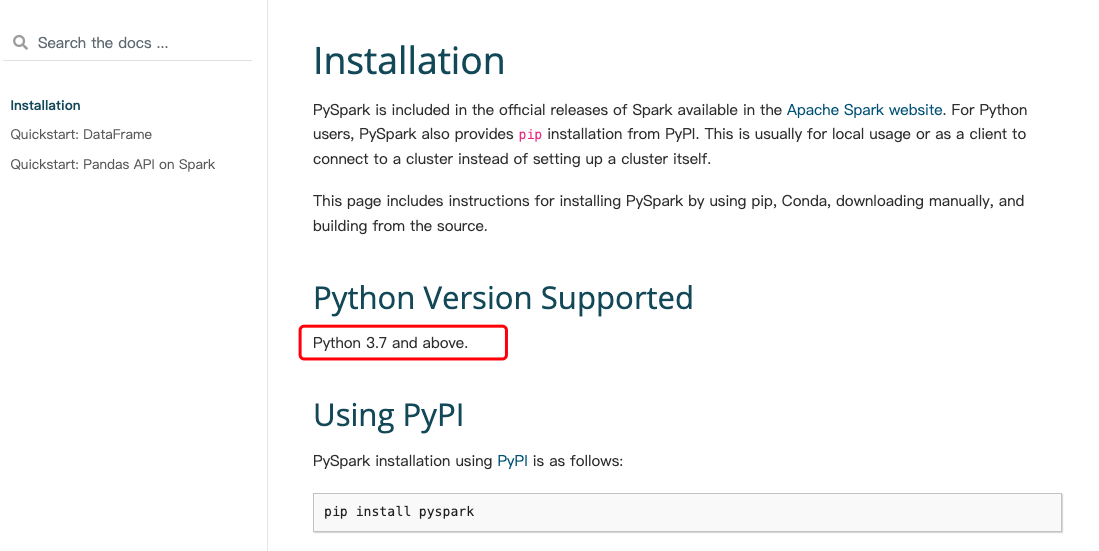
spark3.3.4 上使用 pyspark 跑 python 任务版本不一致问题解决
问题描述 在 spark 上跑 python 任务最常见的异常就是下面的版本不一致问题了: RuntimeError: Python in worker has different version 3.7 than that in driver 3.6, PySpark cannot run with different minor versions. Please check environment variables PY…...

处理Pandas中的JSON数据:从字符串到结构化分析
在数据科学领域,JSON作为一种灵活的数据交换格式,被广泛应用于存储和传输数据。然而,JSON数据的非结构化特性在进行数据分析时可能会带来一些挑战。本文将指导读者如何使用Pandas库将DataFrame中的JSON字符串列转换为结构化的表格数据&#x…...

国内的 Ai 大模型,有没有可以上传excel,完成数据分析的?
小说推文AI视频生成:小说文案智能分镜智能识别角色和场景批量Ai绘图自动配音添加音乐一键合成视频百万播放量https://aitools.jurilu.com/ 有啊!智谱清言、KiMI、豆包都可以做数分,在计算领域尤其推荐智谱清言,免费、快速还好使&a…...

Spring: jetcache
一、介绍 JetCache是一个基于Java的缓存系统封装,提供统一的API和注解来简化缓存的使用。 JetCache提供了比SpringCache更加强大的注解,可以原生的支持TTL(Time To Live,即缓存生存时间)、两级缓存、分布式自动…...
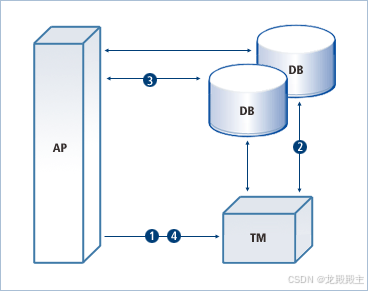
什么是分布式事务?
分布式事务跨越多个系统,确保所有操作一起成功或失败,这对于在现代计算环境中跨不同地理位置分离的资源维护数据完整性和一致性至关重要。 1. 为什么需要分布式事务? 分布式事务的需求源于确保分布式计算环境中多个独立系统或资源之间的数据…...

深入Java内存区域:堆栈、方法区与程序计数器的奥秘
引言 在Java开发过程中,合理地管理和利用内存资源对于提高程序的运行效率至关重要。特别是在大型项目或高并发场景下,一个小小的内存泄漏就可能导致整个系统崩溃。因此,掌握Java内存区域的相关知识,不仅能帮助我们更好地理解程序…...

【ML】异常检测、二分类问题
【ML】异常检测、二分类问题 1. 异常检测、二分类问题1.1 异常检测(Anomaly Detection)1.2 二分类问题(Binary Classification)1.3 异常检测与二分类问题的对比1.4 总结 2. 模型额训练与评估3. 为什么会出现比较高的误识别&#x…...

8.8-配置python3环境+python语法的使用
1.环境 python2 ,python3 [rootpython ~]# yum list installed|grep python [rootpython ~]# yum list installed|grep epel epel-release.noarch 7-11 extras #安装python3 [rootpython ~]# yum -y install python3…...

高质量WordPress下载站模板5play主题源码
5play下载站是由国外站长开发的一款WordPress主题,主题简约大方,为v1.8版本, 该主题模板中包含了上千个应用,登录后台以后只需要简单的三个步骤就可以轻松发布apk文章, 我们只需要在WordPress后台中导入该主题就可以…...

【C++】类的概念与基本使用介绍
C类是面向对象编程(OOP)的基础,它允许我们将数据(属性)和行为(方法)封装在一起,形成一个自定义的数据类型。以下是C类的基本概念、特点、特性以及使用注意事项,最后会提供…...

基于Python和OpenCV的图像处理的轮廓查找算法及显示
文章目录 概要轮廓查找算法示例代码代码解释小结 概要 在图像处理中,轮廓查找是一个重要的步骤,它可以帮助我们识别图像中的形状和边界。Python结合OpenCV库可以非常方便地实现这一功能。本文将详细介绍如何使用Python和OpenCV来查找图像中的轮廓&#…...

使用ant design的modal时,发现自定义组件的样式(组件高度)被改变了!
一 问题描述 在项目中,自定义了一个组件,分别在界面和 antd的modal中都有使用到。但是突然发现,界面中的组件样式跟modal中的组件样式高度不一样。modal中的组件整体要比页面中的组件要高一点。 项目中的自定义组件比较复杂,因此&…...

NLP从零开始------8文本进阶处理之文本向量化
1. 文本向量化概述 随着计算机计算能力的大幅度提升,机器学习和深度学习都取得了长足的发展。NLP越来越多的通过应用机器学习和深度学习工具解决问题,例如通过深度学习模型从网络新闻报道中分析出关键词汇与舆论主题并构建关系图谱。在这种背景下&#x…...

【网络编程】字节序,IP地址、点分十进制、TCP与UDP的异同
记录学习,思维导图绘制 目录 1、字节序编辑 2、IP地址 3、点分十进制 4、TCP与UDP的异同 1、字节序 2、IP地址 3、点分十进制 4、TCP与UDP的异同...

关于k8s的pvc存储卷
目录 1.PVC 和 PV 1.1 PV 1.2 PVC 1.3 StorageClass 1.4 PV和PVC的生命周期 2.实战演练 2.1 创建静态pv 2.2 创建动态pv 3.总结 1.PVC 和 PV 1.1 PV PV 全称叫做 Persistent Volume,持久化存储卷。它是用来描述或者说用来定义一个存储卷的,…...

Kandinsky-5.0-I2V-Lite-5s图生视频工作流整合:接入Notion/Airtable自动化生成
Kandinsky-5.0-I2V-Lite-5s图生视频工作流整合:接入Notion/Airtable自动化生成 1. 产品介绍与核心价值 Kandinsky-5.0-I2V-Lite-5s是一款革命性的轻量级图生视频模型,它让短视频创作变得前所未有的简单。你只需要准备一张首帧图片,再补充一…...

如何使用Unlocker工具在VMware中启用macOS虚拟机支持
如何使用Unlocker工具在VMware中启用macOS虚拟机支持 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker Unlocker是一款开源工具,能够帮助用户在VMware虚拟机软件中解锁对macOS操作系统的支持。…...

西门子PID调节仿真程序:1200/1500 PLC 的学习利器
西门子PID调节仿真程序1200plc和1500plc通用,只需一个PLC实物,就能轻松实现PID工艺对象的仿真,是学习PID的参数的好工具。针对这套程序,录制了一段视频解说,手把手教你如何使用博途PID调节工具和触摸屏PID画面的操作。…...

JetBrains Runtime实战配置指南:解决IDE性能瓶颈的5个核心技巧
JetBrains Runtime实战配置指南:解决IDE性能瓶颈的5个核心技巧 【免费下载链接】JetBrainsRuntime Runtime environment based on OpenJDK for running IntelliJ Platform-based products on Windows, macOS, and Linux 项目地址: https://gitcode.com/gh_mirrors…...

效率提升秘籍:借助快马AI自动生成健壮的视频续播管理模块
最近在开发视频播放功能时,遇到了一个很常见的需求:实现"继续播放上次观看位置"的功能。本以为是个简单的功能,但实际开发中发现要考虑的细节还真不少。经过一番折腾,我总结出了一套高效的解决方案,分享给大…...
上 Python 3.13.0 版本的 Windows 下载选项说明)
Python 官方网站(python.org)上 Python 3.13.0 版本的 Windows 下载选项说明
Python 官方网站(python.org)上 Python 3.13.0 版本的 Windows 下载选项说明。以下是各选项的简要解释,帮助你选择合适的安装包: ✅ Windows installer (64-bit):标准 .exe 安装程序,适用于大多数现代 64 位…...

低功耗psram在嵌入式存储领域的作用
在嵌入式存储领域,低功耗PSRAM(伪静态随机存取存储器)正逐渐成为智能穿戴、物联网设备等对功耗和体积敏感应用的理想选择。那么,PSRAM究竟有什么作用?为什么它能在低功耗场景中脱颖而出? 1.psram是什么 PS…...

[开源工具]问题解决指南:Axure本地化方案的效率提升实践
[开源工具]问题解决指南:Axure本地化方案的效率提升实践 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 作为原型设计…...

HAL_NVIC
文章目录一、NVIC简介 NVIC 做什么?二、NVIC模块详解 1、NVIC 寄存器 2、优先级的定义 1.优先级寄存器NVIC_IPRx 2.优先级分组3、NVIC 工作完整流程 4、F103中断向量表 1.内核异常向量(固定,所有 CM…...

Qwen3-TTS语音合成5分钟快速部署:10种语言+方言一键搞定
Qwen3-TTS语音合成5分钟快速部署:10种语言方言一键搞定 1. 快速部署指南 1.1 系统环境准备 在开始前,请确保您的系统满足以下基本要求: 操作系统:支持Linux/Windows/macOSPython版本:3.8-3.10内存:至少…...