【多模态大模型】FlashAttention in NeurIPS 2022
一、引言
论文: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
作者: Stanford University
代码: FlashAttention
特点: 该方法提出将Q、K、V拆分为若干小块,使执行注意力时不需要频繁进行读写操作,而是每个小块只进行一次读写,从而提升注意力的执行速度。
⚠️ 在学习该方法前,建议补充Attention的相关知识。
二、详情
GPU中SRAM和HBM的计算和存储能力如下图:

可见,SRAM计算能力强(17TB/s),HBM的存储容量大(40GB)。因此,GPU的运算通常在SRAM上进行,如果运算结果的内存占用太大,系统会把运算结果先写入HBM,然后从HBM读出来再在SRAM上进行下一步的运算。
于是,我们就得到原始Attention的执行过程:

其中,Q、K、V分别是Query、Key、Value矩阵,S是相似度矩阵,P是权重矩阵,O是输出矩阵。
这里没写除以 d k \sqrt{d_k} dk的操作,不过无伤大雅,因为它对运算的影响并不大。
可见,计算S、P、O时都要进行读取,计算完成后也都要进行写入。然而,运算速度领先于读写速度导致SRAM运算完了要等数据过来才能进行下一步运算,这就拖慢了整体的速度。
2.1 拆分
FlashAttention提出将Q、K、V拆分成若干小块,这样每个小块的S、P矩阵不至于太大到需要写入HBM中,这样就能只在最开始读取Q、K、V、O(之前的运算结果),在SRAM中完成所有运算后,再将新的O写入HBM。
如果没有SoftMax操作,该过程很容易实现,如下图:


分别循环Q和K、V的小块,循环结果求和就是我们所有期望的O。但是,SoftMax阻碍了它的实现,回顾原始SoftMax公式:
s o f t m a x ( s ) j = e s j ∑ k = 1 N e s k softmax(\boldsymbol{s})_j=\frac{e^{s_j}}{\sum_{k=1}^{N}e^{s_k}} softmax(s)j=∑k=1Neskesj
可见,它要把相似度矩阵S的每一行转为一个概率分布。但是分块策略无法一次性获得完整的S中的行,于是FlashAttention在SoftMax中引入了 m ( s ) m(\boldsymbol{s}) m(s),新的SoftMax公式如下:
s o f t m a x ( s ) i = e s i − m ( s ) ∑ j = 1 N e s j − m ( s ) = f i l ( s ) softmax(\boldsymbol{s})_i=\frac{e^{s_i-m(\boldsymbol{s})}}{\sum_{j=1}^{N}e^{s_j-m(\boldsymbol{s})}}=\frac{f_i}{l(\boldsymbol{s})} softmax(s)i=∑j=1Nesj−m(s)esi−m(s)=l(s)fi
其中,最大值 m ( s ) = max i s i m(\boldsymbol{s})=\max_i s_i m(s)=maxisi,指数和 l ( s ) = ∑ i f i l(\boldsymbol{s})=\sum_i f_i l(s)=∑ifi。事实上,该操作不会影响SoftMax的结果,如下:
s o f t m a x ( [ 1 , 2 , 3 , 10 ] ) = [ e 1 e 1 + e 2 + e 3 + e 10 , e 2 e 1 + e 2 + e 3 + e 10 , e 3 e 1 + e 2 + e 3 + e 10 , e 10 e 1 + e 2 + e 3 + e 10 ] = [ e 1 − 10 e 1 − 10 + e 2 − 10 + e 3 − 10 + e 10 − 10 , e 2 − 10 e 1 − 10 + e 2 − 10 + e 3 − 10 + e 10 − 10 , e 3 − 10 e 1 − 10 + e 2 − 10 + e 3 − 10 + e 10 − 10 , e 10 − 10 e 1 − 10 + e 2 − 10 + e 3 − 10 + e 10 − 10 ] softmax([1,2,3,10])=[\frac{e^{1}}{e^{1}+e^{2}+e^{3}+e^{10}},\frac{e^{2}}{e^{1}+e^{2}+e^{3}+e^{10}},\frac{e^{3}}{e^{1}+e^{2}+e^{3}+e^{10}},\frac{e^{10}}{e^{1}+e^{2}+e^{3}+e^{10}}]\\=[\frac{e^{1-10}}{e^{1-10}+e^{2-10}+e^{3-10}+e^{10-10}},\frac{e^{2-10}}{e^{1-10}+e^{2-10}+e^{3-10}+e^{10-10}},\frac{e^{3-10}}{e^{1-10}+e^{2-10}+e^{3-10}+e^{10-10}},\frac{e^{10-10}}{e^{1-10}+e^{2-10}+e^{3-10}+e^{10-10}}] softmax([1,2,3,10])=[e1+e2+e3+e10e1,e1+e2+e3+e10e2,e1+e2+e3+e10e3,e1+e2+e3+e10e10]=[e1−10+e2−10+e3−10+e10−10e1−10,e1−10+e2−10+e3−10+e10−10e2−10,e1−10+e2−10+e3−10+e10−10e3−10,e1−10+e2−10+e3−10+e10−10e10−10]
可见,上下同乘 e 10 e^{10} e10即可还原为原公式。
此时,我们分 T r = 2 T_r=2 Tr=2块分别计算上述SoftMax,有:
s o f t m a x ( [ 1 , 2 ] ) = [ e 1 − m 1 e 1 − m 1 + e 2 − m 1 , e 2 − m 1 e 1 − m 1 + e 2 − m 1 ] = [ f 1 l 1 , f 2 l 1 ] , m 1 = 2 s o f t m a x ( [ 3 , 10 ] ) = [ e 3 − m 2 e 3 − m 2 + e 10 − m 2 , e 10 − m 2 e 3 − m 2 + e 10 − m 2 ] = [ f 3 l 2 , f 4 l 2 ] , m 2 = 10 softmax([1,2])=[\frac{e^{1-m_1}}{e^{1-m_1}+e^{2-m_1}},\frac{e^{2-m_1}}{e^{1-m_1}+e^{2-m_1}}]=[\frac{f_1}{l_1},\frac{f_{2}}{l_1}],m_1=2\\ softmax([3,10])=[\frac{e^{3-m_2}}{e^{3-m_2}+e^{10-m_2}},\frac{e^{10-m_2}}{e^{3-m_2}+e^{10-m_2}}]=[\frac{f_3}{l_2},\frac{f_4}{l_2}],m_2=10 softmax([1,2])=[e1−m1+e2−m1e1−m1,e1−m1+e2−m1e2−m1]=[l1f1,l1f2],m1=2softmax([3,10])=[e3−m2+e10−m2e3−m2,e3−m2+e10−m2e10−m2]=[l2f3,l2f4],m2=10
其中,每个小块里减去的是当前块的最大值,记为 m i m_i mi;当前块的分子,记为 p i \boldsymbol{p}_i pi(是多个 f i f_i fi组成的向量);当前块的分母指数和,记为 l i l_i li。对应地,当前块的输出 p i / l i \boldsymbol{p}_i/l_i pi/li,记为 o \boldsymbol{o} o。
在不同块的遍历计算过程中,我们可以不断更新最大值 m ( s ) m(\boldsymbol{s}) m(s)(初始为负无穷)、指数和 l ( s ) l(\boldsymbol{s}) l(s)(初始为0)。
对于 m ( s ) m(\boldsymbol{s}) m(s),更新公式为 m ( s ) n e w = max ( m ( s ) , m i ) m(\boldsymbol{s})^{new}=\max(m(\boldsymbol{s}),m_i) m(s)new=max(m(s),mi)。
对于 l ( s ) l(\boldsymbol{s}) l(s),更新公式为 l ( s ) n e w = e m ( s ) − m ( s ) n e w × l ( s ) + e m i − m ( s ) n e w × l i l(\boldsymbol{s})^{new}=e^{m(\boldsymbol{s})-m(\boldsymbol{s})^{new}}\times l(\boldsymbol{s})+e^{m_i-m(\boldsymbol{s})^{new}}\times l_i l(s)new=em(s)−m(s)new×l(s)+emi−m(s)new×li。
在第一块中,
- m ( s ) n e w = max ( − inf , m 1 ) = 2 m(\boldsymbol{s})^{new}=\max(-\inf,m_1)=2 m(s)new=max(−inf,m1)=2
- l ( s ) n e w = e m ( s ) − m ( s ) n e w × l ( s ) + e m 1 − m ( s ) n e w × l 1 = e − inf − 2 × 0 + e 2 − 2 × ( e 1 − 2 + e 2 − 2 ) l(\boldsymbol{s})^{new}=e^{m(\boldsymbol{s})-m(\boldsymbol{s})^{new}}\times l(\boldsymbol{s})+e^{m_1-m(\boldsymbol{s})^{new}}\times l_1=e^{-\inf-2}\times 0+e^{2-2}\times(e^{1-2}+e^{2-2}) l(s)new=em(s)−m(s)new×l(s)+em1−m(s)new×l1=e−inf−2×0+e2−2×(e1−2+e2−2)
- 令 m ( s ) ← m ( s ) n e w m(\boldsymbol{s})\leftarrow m(\boldsymbol{s})^{new} m(s)←m(s)new, l ( s ) ← l ( s ) n e w l(\boldsymbol{s})\leftarrow l(\boldsymbol{s})^{new} l(s)←l(s)new
在第二块中,
- m ( s ) n e w = max ( 2 , m 2 ) = 10 m(\boldsymbol{s})^{new}=\max(2,m_2)=10 m(s)new=max(2,m2)=10
- l ( s ) n e w = e m ( s ) − m ( s ) n e w × l ( s ) + e m 2 − m ( s ) n e w × l 2 l(\boldsymbol{s})^{new}=e^{m(\boldsymbol{s})-m(\boldsymbol{s})^{new}}\times l(\boldsymbol{s})+e^{m_2-m(\boldsymbol{s})^{new}}\times l_2 l(s)new=em(s)−m(s)new×l(s)+em2−m(s)new×l2
= e 2 − 10 × ( e 1 − 2 + e 2 − 2 ) + e 10 − 10 × ( e 3 − 10 + e 10 − 10 ) = e 1 − 10 + e 2 − 10 + e 3 − 10 + e 10 − 10 =e^{2-10}\times(e^{1-2}+e^{2-2})+e^{10-10}\times(e^{3-10}+e^{10-10})=e^{1-10}+e^{2-10}+e^{3-10}+e^{10-10} =e2−10×(e1−2+e2−2)+e10−10×(e3−10+e10−10)=e1−10+e2−10+e3−10+e10−10
可见,最后的输出结果 m ( s ) m(\boldsymbol{s}) m(s)和 l ( s ) l(\boldsymbol{s}) l(s)已经与实际 s o f t m a x ( [ 1 , 2 , 3 , 10 ] ) softmax([1,2,3,10]) softmax([1,2,3,10])中的一致。
m ( s ) m(\boldsymbol{s}) m(s)的更新公式能使 m ( s ) n e w m(\boldsymbol{s})^{new} m(s)new始终为当前行的最大值, l ( s ) l(\boldsymbol{s}) l(s)的更新公式能使 l ( s ) n e w l(\boldsymbol{s})^{new} l(s)new的指数项始终减的是 m ( s ) n e w m(\boldsymbol{s})^{new} m(s)new。
同样地,在遍历过程中,我们也可以根据新的 m ( s ) m(\boldsymbol{s}) m(s)和 l ( s ) l(\boldsymbol{s}) l(s)计算和更新当前的 o \boldsymbol{o} o(初始为0向量)。
对于 o \boldsymbol{o} o,更新公式为
o n e w = l ( s ) × e m ( s ) − m ( s ) n e w × o + e m i − m ( s ) n e w × p i × V i l ( s ) n e w \boldsymbol{o}^{new}=\frac{l(\boldsymbol{s})\times e^{m(\boldsymbol{s})-m(\boldsymbol{s})^{new}}\times \boldsymbol{o}+e^{m_i-m(\boldsymbol{s})^{new}}\times \boldsymbol{p}_i\times\boldsymbol{V}_i}{l(\boldsymbol{s})^{new}} onew=l(s)newl(s)×em(s)−m(s)new×o+emi−m(s)new×pi×Vi
其中, p i = [ f i ∗ B r , ⋯ , f ( i + 1 ) ∗ B r ] \boldsymbol{p}_i=[f_{i*Br},\cdots,f_{(i+1)*B_r}] pi=[fi∗Br,⋯,f(i+1)∗Br], V i \boldsymbol{V}_i Vi为V矩阵的第 i i i块。
我们假设 V = [ [ 1 , 2 ] , [ 3 , 4 ] , [ 5 , 6 ] , [ 7 , 8 ] ] \boldsymbol{V}=[[1,2],[3,4],[5,6],[7,8]] V=[[1,2],[3,4],[5,6],[7,8]],则有
在第一块中,
- m ( s ) n e w = 2 m(\boldsymbol{s})^{new}=2 m(s)new=2
- l ( s ) n e w = e − inf − 2 × 0 + e 2 − 2 × ( e 1 − 2 + e 2 − 2 ) = e 1 − 2 + e 2 − 2 l(\boldsymbol{s})^{new}=e^{-\inf-2}\times 0+e^{2-2}\times(e^{1-2}+e^{2-2})=e^{1-2}+e^{2-2} l(s)new=e−inf−2×0+e2−2×(e1−2+e2−2)=e1−2+e2−2
- o n e w = 0 × e − inf − 2 × 0 + e 2 − 2 × [ e 1 − 2 , e 2 − 2 ] × [ 1 2 3 4 ] e − inf − 2 × 0 + e 2 − 2 × ( e 1 − 2 + e 2 − 2 ) = [ e 1 − 2 , e 2 − 2 ] × [ 1 2 3 4 ] ( e 1 − 2 + e 2 − 2 ) \boldsymbol{o}^{new}=\frac{0\times e^{-\inf-2}\times 0+e^{2-2}\times [e^{1-2},e^{2-2}]\times\begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}}{e^{-\inf-2}\times 0+e^{2-2}\times(e^{1-2}+e^{2-2})}=\frac{[e^{1-2},e^{2-2}]\times\begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}}{(e^{1-2}+e^{2-2})} onew=e−inf−2×0+e2−2×(e1−2+e2−2)0×e−inf−2×0+e2−2×[e1−2,e2−2]×[1324]=(e1−2+e2−2)[e1−2,e2−2]×[1324]
- 令 m ( s ) ← m ( s ) n e w m(\boldsymbol{s})\leftarrow m(\boldsymbol{s})^{new} m(s)←m(s)new, l ( s ) ← l ( s ) n e w l(\boldsymbol{s})\leftarrow l(\boldsymbol{s})^{new} l(s)←l(s)new, o ← o n e w \boldsymbol{o}\leftarrow \boldsymbol{o}^{new} o←onew
在第二块中,
- m ( s ) n e w = 10 m(\boldsymbol{s})^{new}=10 m(s)new=10
- l ( s ) n e w = e 1 − 10 + e 2 − 10 + e 3 − 10 + e 10 − 10 l(\boldsymbol{s})^{new}=e^{1-10}+e^{2-10}+e^{3-10}+e^{10-10} l(s)new=e1−10+e2−10+e3−10+e10−10
- o n e w = ( e 1 − 2 + e 2 − 2 ) × e 2 − 10 × [ e 1 − 2 , e 2 − 2 ] × [ 1 2 3 4 ] ( e 1 − 2 + e 2 − 2 ) + e 10 − 10 × [ e 3 − 10 , e 10 − 10 ] × [ 5 6 7 8 ] e 1 − 10 + e 2 − 10 + e 3 − 10 + e 10 − 10 = [ e 1 − 10 , e 2 − 10 ] × [ 1 2 3 4 ] + [ e 3 − 10 , e 10 − 10 ] × [ 5 6 7 8 ] e 1 − 10 + e 2 − 10 + e 3 − 10 + e 10 − 10 \boldsymbol{o}^{new}=\frac{(e^{1-2}+e^{2-2})\times e^{2-10}\times \frac{[e^{1-2},e^{2-2}]\times\begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}}{(e^{1-2}+e^{2-2})}+e^{10-10}\times [e^{3-10},e^{10-10}]\times \begin{bmatrix} 5 & 6 \\ 7 & 8 \end{bmatrix}}{e^{1-10}+e^{2-10}+e^{3-10}+e^{10-10}}\\=\frac{[e^{1-10},e^{2-10}]\times\begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}+[e^{3-10},e^{10-10}]\times \begin{bmatrix} 5 & 6 \\ 7 & 8 \end{bmatrix}}{e^{1-10}+e^{2-10}+e^{3-10}+e^{10-10}} onew=e1−10+e2−10+e3−10+e10−10(e1−2+e2−2)×e2−10×(e1−2+e2−2)[e1−2,e2−2]×[1324]+e10−10×[e3−10,e10−10]×[5768]=e1−10+e2−10+e3−10+e10−10[e1−10,e2−10]×[1324]+[e3−10,e10−10]×[5768]
可见,最后的结果已经与实际 s o f t m a x ( [ 1 , 2 , 3 , 10 ] ) × V softmax([1,2,3,10])\times\boldsymbol{V} softmax([1,2,3,10])×V一致。
o \boldsymbol{o} o的更新公式能使各块分子指数项上减去最新的 m ( s ) n e w m(\boldsymbol{s})^{new} m(s)new,并使各块的最新的指数和合并。
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
Flash Attention 为什么那么快?原理讲解
Flash Attention论文解读
相关文章:
【多模态大模型】FlashAttention in NeurIPS 2022
一、引言 论文: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness 作者: Stanford University 代码: FlashAttention 特点: 该方法提出将Q、K、V拆分为若干小块,使执行注意力时不需要频…...

过滤器doFilter 方法
在Java EE中,过滤器的放行是指在过滤器的 doFilter 方法中调用 FilterChain 对象的 doFilter 方法,将请求传递给下一个过滤器或目标 servlet 进行处理。这个过程可以理解为过滤器的责任链传递。 过滤器的 doFilter 方法 在过滤器中,实现 Fil…...

WPF篇(9)-CheckBox复选框+RadioButton单选框+RepeatButton重复按钮
CheckBox复选框 CheckBox继承于ToggleButton,而ToggleButton继承于ButtonBase基类。 案例 前端代码 <StackPanel Orientation"Horizontal" HorizontalAlignment"Center" VerticalAlignment"Center"><TextBlock Text"…...

【机器学习基础】线性回归
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,…...

java基础概念12-二维数组
一、二维数组的定义 二维数组可以被视为数组的数组,即每个元素都是一个数组。 二维数组的应用场景: 当我们需要把数据分组管理的时候,就需要用到二维数组。 二、二维数组的初始化 2-1、静态初始化 阿里巴巴规范手册: // 静态初始…...

56 锐键交换机开局
锐键交换机开局 一 锐键视图切换 1 Ruijie> 用户视图 2 Ruijie# 特权模式 3 Ruijie(config)# 全局配置模式 4 Ruijie(config-if-GigabitEthernet 1/1/1)# 接口配置模式 5 Ruijie(config)#show vlan 6 exit (退出) 7 enable(进入)...

VR虚拟展厅与传统实体展厅相比,有哪些优势?
视创云展虚拟展厅相比传统的实体展厅具有多方面的优势,主要体现在以下几个方面: 1、降低成本: 虚拟展厅无需租赁或建设物理空间,减少了场地、装修和维护等方面的开支。同时,参观者和参展商无需现场参观或布展&#x…...

Vue的事件处理、事件修饰符、键盘事件
目录 1. 事件处理基本使用2. 事件修饰符3. 键盘事件 1. 事件处理基本使用 使用v-on:xxx或xxx绑定事件,其中xxx是事件名,比如clickmethods中配置的函数,都是被Vue所管理的函数,this的指向是vm或组件实例对象 <!DOCTYPE html&g…...
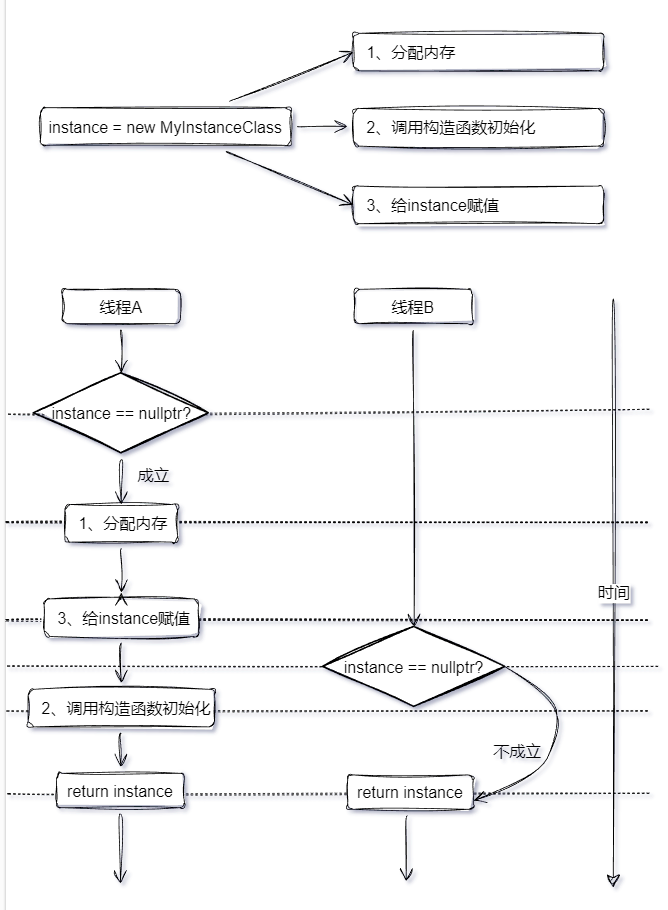
c++单例实践
C单例实践 在日常开发中,虽然太多的单例调用会让代码的耦合度变高,但是例如日志类这种,单例模式就变得非常有。所以这篇文章为大家介绍static 关键字相关知识以及如何实现自己的C单例类。 static关键字 首先让我们请出今天的主角: static。…...

SQL注入实例(sqli-labs/less-9)
0、初始页面 1、爆库名 使用python脚本 def inject_database1(url):name for i in range(1, 20):low 32high 128mid (low high) // 2while low < high:payload "1 and if(ascii(substr(database(),%d,1)) > %d ,sleep(2),0)-- " % (i, mid)res {"…...

http不同类型方法的作用,get和post区别
在HTTP协议中,不同的请求方法用于不同的操作。常见的HTTP方法包括GET、POST、PUT、DELETE、HEAD、OPTIONS、PATCH等,每种方法有其特定的作用。 常见的HTTP方法及其作用 1. GET - **作用**: 从服务器请求指定资源。GET方法通常用于获取数据而不会修改数据…...

# 利刃出鞘_Tomcat 核心原理解析(二)
利刃出鞘_Tomcat 核心原理解析(二) 一、 Tomcat专题 - Tomcat架构 - HTTP工作流程 1、Http 工作原理 HTTP 协议:是浏览器与服务器之间的数据传送协议。作为应用层协议,HTTP 是基于 TCP/IP 协议来传递数据的(HTML文件…...
求助帖)
美团秋招笔试第三题(剪彩带)求助帖
题目描述及代码如下。 我使用模拟打表法,示例通过了,但是提交通过率为0。诚心求教。欢迎补充题目,或者有原题链接更好~。我觉得可能出错的点:int -> long long ?或者一些临界条件。 /* 美团25毕业秋招第三题,做题…...

LeetCode 算法:最小栈 c++
原题链接🔗:最小栈 难度:中等⭐️⭐️ 题目 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。void push(int val) 将元素val推…...

【解压既玩】PS3模拟器v0.0.32+战神3+战神升天+各存档 整合包 ,完美不死机,没有BUG,旷世神作,强力推荐
战神3是圣莫尼卡公司的大作,PS3 上必玩的游戏之一。 本文收集了战神3和升天两作,附存档,完美不死机,没有BUG,强烈推荐。 解压即玩。 立即下载:【chumenx.com】【解压既玩】PS3模拟器v0.0.32战神3战神升天…...

bootstrap- X-editable 行内编辑
前面不要忘记引入editable {field: weigh, title: __(Weigh),editable: {type: text,url: "api/cat/editWeigh",validate: function (v) {if($.trim(v) ) return 值不能为空;if(!$.isNumeric(v)) return 值只能为数字;if(v<0 || v%1!0) return 值必需为正整数;}…...

【LabVIEW学习篇 - 12】:通知器
文章目录 通知器案例一案例二案例三(在不同VI中用同一个通知器) 通知器 同步技术:同步技术用来解决多个并行任务之间的同步或通信问题。 通知器比较适合一对多的操作,类似于广播,一点发出的通知消息, 其它…...

Oracle一对多(一主多备)的DG环境如何进行switchover切换?
本文主要分享Oracle一对多(一主多备)的DG环境的switchover切换,如何进行主从切换,切换后怎么恢复正常同步? 1、环境说明 本文的环境为一主两备,数据库版本为11.2.0.4,主要信息如下: 数据库IPdb_unique_n…...

【浏览器插件】Chrome扩展V3版本
前言:Chrome从2022年6月开始,新发布插件只接受V3版。2024年V2版已从应用商店下架。 浏览器扩展插件开发API文档 chrome官网(要翻墙): https://developer.chrome.com/docs/extensions/mv3 MDN中文:https:/…...

编码器信号干扰问题、编码器选型
系列文章目录 1.元件基础 2.电路设计 3.PCB设计 4.元件焊接 5.板子调试 6.程序设计 7.算法学习 8.编写exe 9.检测标准 10.项目举例 11.职业规划 文章目录 前言一、屏蔽技术1.静电屏蔽:2.低频磁屏蔽:3.电磁屏蔽:4.减少“天线” 二、增量编码器的信号选择三、信号电缆选择四、…...

终极指南:如何用KCN-GenshinServer轻松搭建原神私服
终极指南:如何用KCN-GenshinServer轻松搭建原神私服 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 还在为复杂的命令行配置而头疼吗?KCN-GenshinSe…...

如何通过GitHub配置Resume简历:无需代码的终极解决方案
如何通过GitHub配置Resume简历:无需代码的终极解决方案 【免费下载链接】resume 🚀 在线简历生成器 项目地址: https://gitcode.com/gh_mirrors/resu/resume Resume是一款功能强大的在线简历生成器,让你无需编写代码即可轻松创建专业简…...

让论文润色提速的秘密武器
对于每一位科研人员而言,将心血凝聚成论文初稿仅仅是万里长征的第一步。紧接着,一场更为煎熬的“拉锯战”往往在修改环节悄然打响。你是否也经历过这样的时刻:为了一个地道的表达,对着电脑屏幕逐字逐句地斟酌,耗费数小…...

快马平台快速原型:十分钟搭建openclaw skills机器人抓取仿真环境
最近在研究机器人抓取技能(openclaw skills)的仿真验证,发现用InsCode(快马)平台可以快速搭建原型环境。整个过程比想象中简单很多,十分钟就能跑通基础功能,分享下具体实现思路: 场景搭建 先用Three.js创建…...

告别B站缓存格式困扰:m4s-converter让视频文件处理效率提升80%
告别B站缓存格式困扰:m4s-converter让视频文件处理效率提升80% 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 一、痛点直击…...
)
KEIL MDK实战:3分钟将常用C文件封装成LIB库(附标准库管理技巧)
KEIL MDK高效工程管理:C文件封装LIB库的进阶实践 在嵌入式开发领域,随着项目规模扩大,工程文件管理往往成为影响开发效率的关键瓶颈。特别是对于STM32开发者而言,标准外设库、常用算法模块等重复使用的代码如何高效管理࿰…...

基于YOLOV8的车辆检测系统:快速上手与实用功能
基于YOLOV8的车辆检测系统 基于深度学习的车辆检测系统有数据集 模型已经训练好 直接用即可 报告 30r 就是售价 包搭配环境 远程运行跑通程序 本项目已经训练好模型,配置好环境可直接使用,运行效果见图像(可找我要演示视频) 项…...

解决Swagger2集成中v2/api-docs接口404问题的关键:正确配置Docket分组
1. 为什么访问v2/api-docs会返回404? 这个问题困扰过不少开发者。当你兴冲冲地集成完Swagger2,打开swagger-ui.html页面,却发现页面一片空白,控制台报错显示v2/api-docs接口返回404。更让人抓狂的是,单独访问这个接口时…...

【后端】主流后端语言横向对比:JAVA、C、C++、GO、PYTHON的实战应用与选型指南
1. 五种主流后端语言的核心特性对比 第一次接触后端开发时,面对众多编程语言的选择确实容易犯难。我至今记得2013年参与电商系统重构时,团队为选择Java还是Go争论了两周。这五种语言就像不同的工具——没有绝对的好坏,关键要看用在什么场景。…...

SOLIDWORKS自定义属性模板制作全攻略:从零开始驱动模型参数
SOLIDWORKS自定义属性模板制作全攻略:从零开始驱动模型参数 在机械设计领域,SOLIDWORKS作为主流的三维CAD软件,其自定义属性功能往往被初学者低估。想象一下这样的场景:当你需要批量修改上百个零件的材料规格时,是否还…...