全面介绍 Apache Doris 数据灾备恢复机制及使用示例
引言
Apache Doris 作为一款 OLAP 实时数据仓库,在越来越多的中大型企业中逐步占据着主数仓这样的重要位置,主数仓不同于 OLAP 查询引擎的场景定位,对于数据的灾备恢复机制有比较高的要求,本篇就让我们全面的介绍和示范如何利用这些特性能力构建集群数据的灾备恢复机制。
这里恢复备份机制除 Backup 和 Restore 语法以外,所有可以导出后再导入的方式,都可被视为备份恢复的特性能力。
本文中所有的机制,我都已挨个搭建环境测试了一遍,并给了示例,可放心使用!
话不多说,上干货~
更好的阅读体验可前往原文阅读:全面介绍 Apache Doris 数据灾备恢复机制及使用示例 | 巨人肩膀
机制概览
Apache Doris 的灾备恢复机制非常丰富,可满足各式各样数据容灾备份的应用场景,以下是所有机制的概览表。
| 特性名称 | 适用场景 | 存储位置 | 吞吐速度 |
| MySQL Dump/Source | 小数据量数据以及表结构语句导出 | MySQL Client 节点指定位置 | 结果集数据量较小,数千条速度较快 |
| Export/Import | 大批量原始数据导出导入 | HDFS、支持S3协议的对象存储、本地文件系统 | 异步任务,速度中等 |
| Outfile | 导出数据需要经过复杂计算逻辑的,如过滤、聚合、关联等 | HDFS、支持S3协议的对象存储、本地文件系统 | 原始非压缩格式的数据导出,需要做行列转换,速度一般 |
| ADBC | 数据科学大规模吞吐场景 | 代码指定即可 | Pandas等高速数据吞吐场景,无需行列转换,相较传统JDBC快数十倍 |
| Backup/Restore | 原生备份和恢复 | HDFS、支持S3协议的对象存储 | 直接拷贝压缩后的数据文件备份,速度最快 |
| 冷热分层 | 冷热数据不同存储介质 | SSD、HDD、HDFS、支持S3协议的对象存储 | 数据自动Rebalance,速度取决于网卡带宽、介质IOPS、Balance线程数 |
| CCR | 跨集群近实时数据同步 | 主从集群本地盘介质 | 同步速度主要取决于网卡带宽和网络带宽 |
在导出的三种机制 MySQL Dump、Export、OutFile 中,分别适用于不同的场景内,三种导出方式的异同点如下:
| | SELECT INTO OUTFILE | EXPORT | MySQL DUMP |
| 同步/异步 | 同步 | 异步(提交 EXPORT 任务后通过 SHOW EXPORT 命令查看任务进度) | 同步 |
| 支持任意 SQL | 支持 | 不支持 | 不支持 |
| 导出指定分区 | 支持 | 支持 | 不支持 |
| 导出指定 Tablets | 支持 | 不支持 | 不支持 |
| 并发导出 | 支持且并发高(但取决于 SQL 语句是否有 ORDER BY 等需要单机处理的算子) | 支持且并发高(支持 Tablet 粒度的并发导出) | 不支持,只能单线程导出 |
| 支持导出的数据格式 | Parquet、ORC、CSV | Parquet、ORC、CSV | MySQL Dump 专有格式 |
| 是否支持导出外表 | 支持 | 部分支持 | 不支持 |
| 是否支持导出 View | 支持 | 支持 | 支持 |
| 支持的导出位置 | S3、HDFS、LOCAL | S3、HDFS、LOCAL | LOCAL |
示例演示
1、MySQL Dump/Source
适用场景
数据量在数万条以内或更小的数据量,比如BI使用者将查询以后的报表结果集数据导出为CSV、或者将表结构语句导出至指定存储目录等场景比较适用,不可用于大规模数据导出和导入。
使用示例
①Dump 常见使用语法
# 1. 导出指定数据库中的指定表
mysqldump -h ${FE_IP}-P ${FE_QUERY_PORT}-u ${USERNAME}-p ${PASSWORD}--no-tablespaces --databases ${DATABASE_NAME} --tables ${TABLES_NAME}# 2. 仅导出指定数据库中的指定表结构
mysqldump -h ${FE_IP}-P ${FE_QUERY_PORT}-u ${USERNAME}-p ${PASSWORD}--no-tablespaces --databases ${DATABASE_NAME} --tables ${TABLES_NAME} --no-data# 3. 导出多个数据库中所有表数据结构
mysqldump -h ${FE_IP}-P ${FE_QUERY_PORT}-u ${USERNAME}-p ${PASSWORD}--no-tablespaces --databases ${DATABASE_NAME_1} ${DATABASE_NAME_2} ${DATABASE_NAME_3} --no-data# 4. 导出所有数据库的表结构
mysqldump -h ${FE_IP}-P ${FE_QUERY_PORT}-u ${USERNAME}-p ${PASSWORD}--no-tablespaces --all-databases --no-data# 将结果导出至指定位置,以示例2为例
mysqldump -h ${FE_IP}-P ${FE_QUERY_PORT}-u ${USERNAME}-p ${PASSWORD}--no-tablespaces --databases ${DATABASE_NAME} --tables ${TABLES_NAME} --no-data > ${RESULT_FILE_PATH}参数说明FE_IP:Doris 的 FE 节点内网 IPFE_QUERY_PORT:默认值为9030USERNAME:Doris 用户名PASSWORD:Doris 用户密码DATABASE_NAME:数据库名TABLES_NAME:数据表名RESULT_FILE_PATH:导出文件路径同时请注意,由于 Doris 中没有 MySQL 里的 tablespace 概念,因此在使用 MySQL Dump 时要加上 --no-tablespaces 参数!
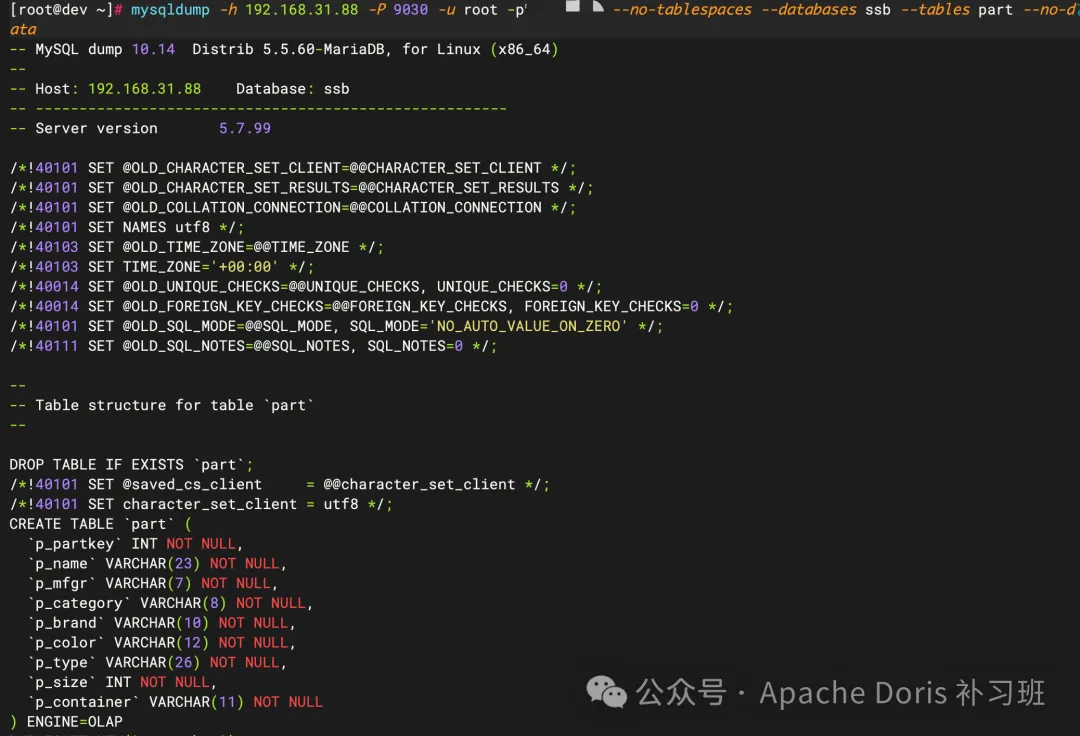
②Source 使用语法
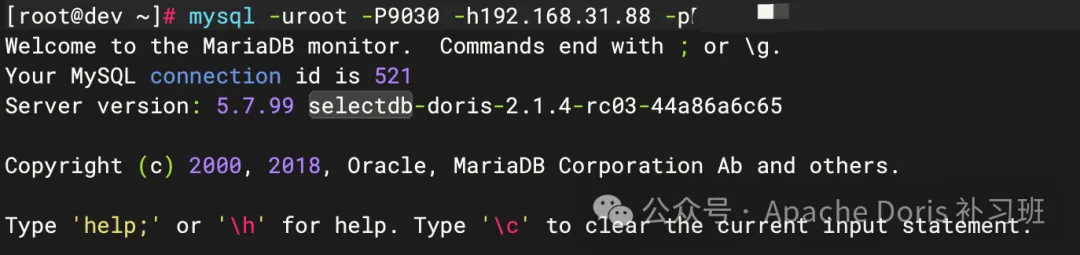
1.登入 Doris FE Client
mysql -u ${USERNAME} -P ${FE_QUERY_PORT} -h ${FE_HOST_IP} -p ${PASSWORD}
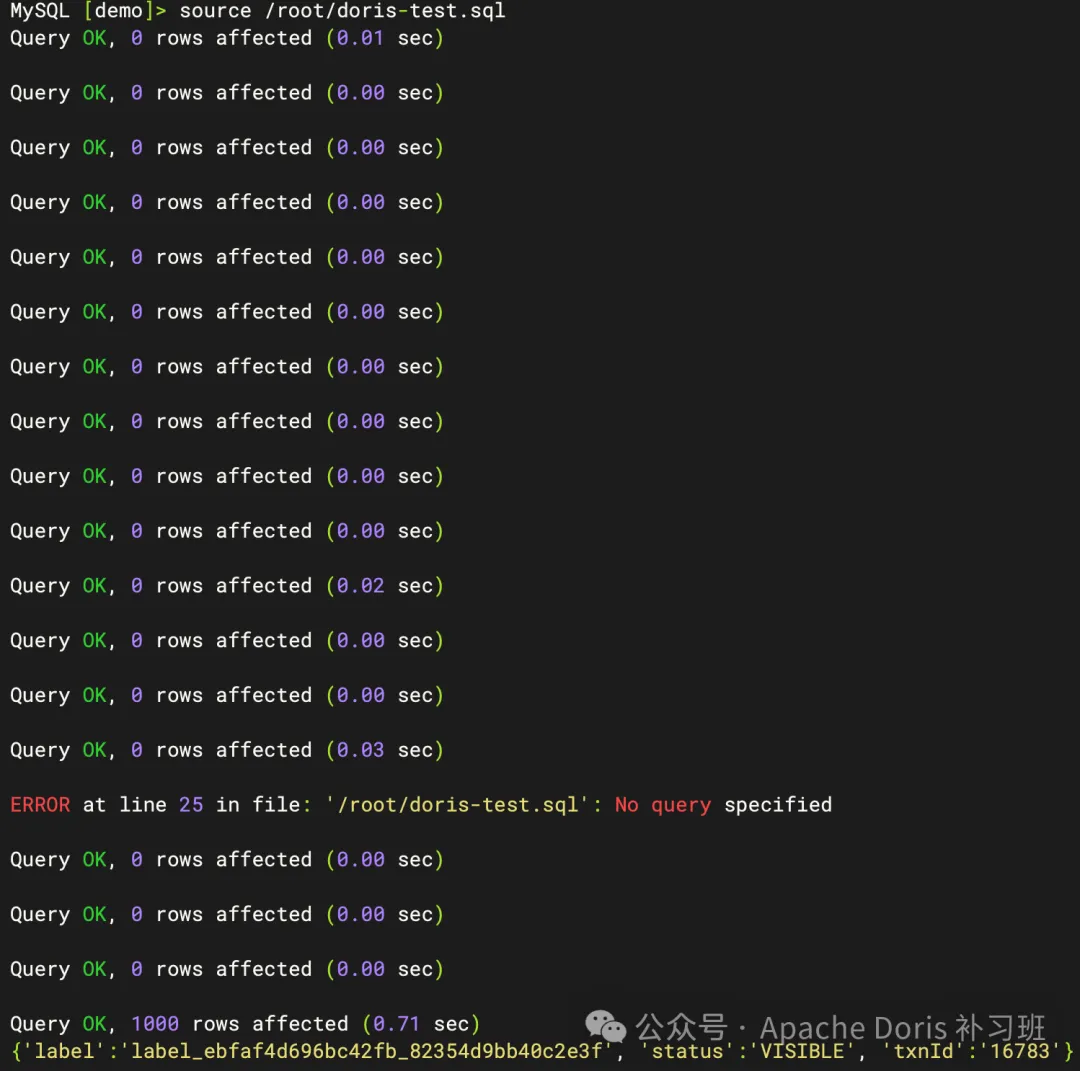
2.使用 Source 命令完成导入
source ${SQL_FILE_PATH}
2、Export/Import
适用场景
将大批量数据导出至远端存储系统中,如HDFS、支持S3协议的对象存储、本地文件系统等,这类导出会先将存储在 Doris 的压缩数据进行解压缩和列转行,然后再根据导出时候的参数定义转为指定的数据类型格式。
所以导出的数据量虽然可以相对较大,但是速度往往没有想象中的那么快,适合大数据量的单表导出、仅需简单的过滤条件和需要异步提交任务的场景。
底层导出函数调用为 Outfile。
使用示例
标准语法
EXPORT TABLE table_name
[PARTITION (p1[,p2])]
[WHERE]
TO export_path
[opt_properties]
WITH BROKER/S3/HDFS
[broker_properties];详细参数说明请参照:
https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-statements/Data-Manipulation-Statements/Manipulation/EXPORT
①导出至本地文件系统
导出至本地文件系统必须在 fe.conf 配置文件中配置参数 enable_outfile_to_local=true,重启 FE 后生效。
EXPORT TABLE ${TABLE_NAME} TO ${LOCAL_FILE_PATH}请注意,LOCAL_FILE_PATH 有以下限制:1. 格式前缀为 file://2. 仅可以指定至文件夹目录级3. 指定的文件夹目录必须为多个 BE 节点共有目录,如 /root/、/home 等,否则无法创建对应文件
示例
1.导出 demo 库中的 part 表,且放置在 /root 目录下
EXPORT TABLE demo.part TO "file:///root/";

2.查看异步导出任务
SHOW EXPORT\G;
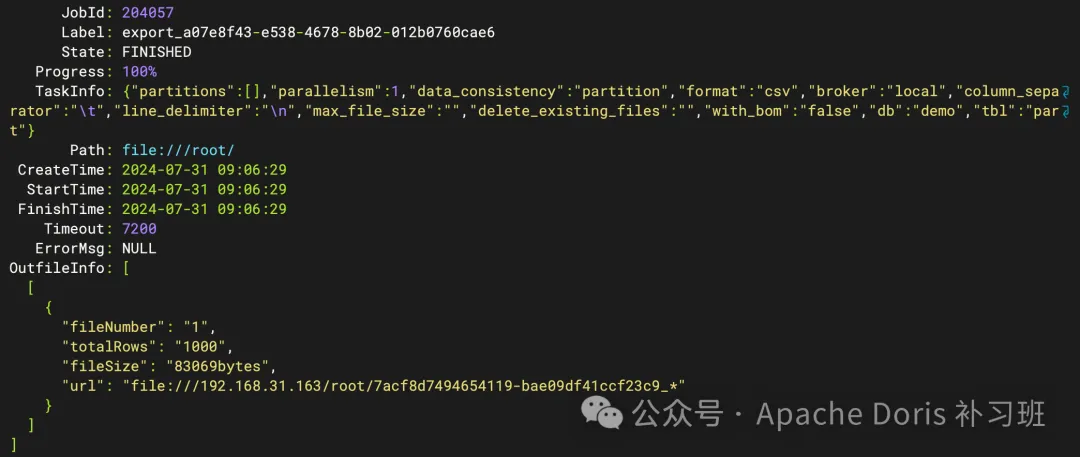
3.根据指定 URL 查看导出文件数据
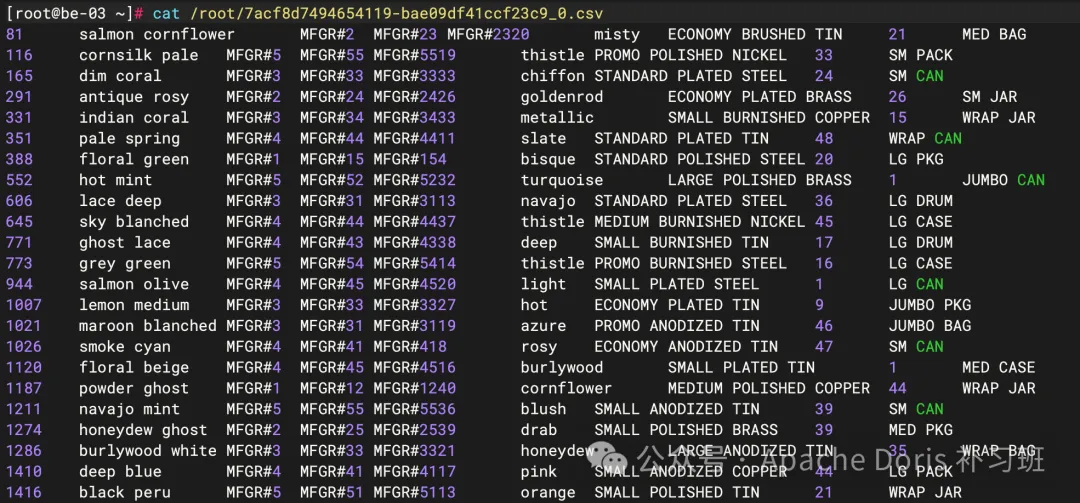
# 切换登录至导出 BE 节点
ssh 192.168.31.163
# 查看导出文件
cat /root/7acf8d7494654119-bae09df41ccf23c9_0.csv
若需要在导出过程中进行过滤、指定压缩格式等定制化能力,请参照本小节前的 EXPORT 命令说明链接内容,这里不做赘述。
②导出至 S3 对象存储
EXPORT TABLE ssb.port TO"s3://${BUCKET}/${S3_PATH}"
WITH s3 (
"s3.endpoint"="${S3_HTTP_API}",
"s3.region"="${S3_REGION}",
"s3.access_key"="${AK}",
"s3.secret_key"="${SK}"
);若使用 MinIO,参数需要注意以下几点: 1. 需要添加 "use_path_style" = "true" 配置项 2. S3_REGION 值默认为 us-east-1 3. AK、SK 可以使用 USERNAME & PASSOWORD,也可以使用在 MinIO 内创建的 AK、SK
示例
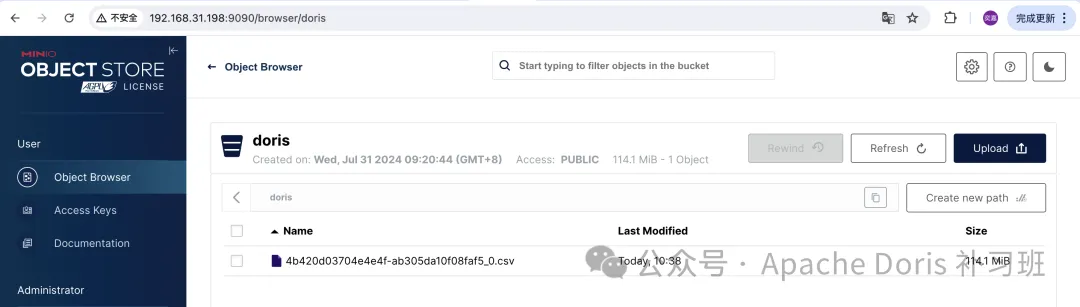
导出数据至 MinIO

导出后 MinIO Bucket 使用情况
③导出至 HDFS
EXPORT TABLE ${TABLE_NAME} TO "hdfs://${NAMENODE_IP}:{PORT}/${PATH}"
with HDFS (
"fs.defaultFS"="hdfs://${NAMENODE_IP}:{PORT}",
"hadoop.username" = "${HADOOP_USERNAME}"
);示例
1.创建导出任务

2.导出任务执行成功

3、Select Into Outfile
适用场景
Select Into Outfile 实则为 Export 的底层执行函数,作为同步导出任务,可执行较为复杂的逻辑查询后的结果集输出方式。
使用示例
标准语法
query_stmt
INTO OUTFILE "file_path"
[FORMAT_AS]
[PROPERTIES]更详细的参数说明,请翻阅官方文档:
https://doris.apache.org/zh-CN/docs/dev/data-operate/export/outfile
以 SSB 测试集的标准查询 Q2.2 作为查询语句,以 limit 100 作为条数限制,SQL 如下:
SELECT SUM(lo_revenue), d_year, p_brand
FROM lineorder, dates, part, supplier
WHERE
lo_orderdate = d_datekey
AND lo_partkey = p_partkey
AND lo_suppkey = s_suppkey
AND p_brand BETWEEN'MFGR#2221'AND'MFGR#2228'
AND s_region ='ASIA'
GROUPBY d_year, p_brand
ORDERBY d_year, p_brand;①导出至本地文件系统示例
SELECT SUM(lo_revenue), d_year, p_brand
FROM lineorder, dates, part, supplier
WHERE
lo_orderdate = d_datekey
AND lo_partkey = p_partkey
AND lo_suppkey = s_suppkey
AND p_brand BETWEEN'MFGR#2221'AND'MFGR#2228'
AND s_region ='ASIA'
GROUPBY d_year, p_brand
ORDERBY d_year, p_brand
LIMIT 100
INTO OUTFILE "s3://doris/"
PROPERTIES(
"use_path_style"="true",
"s3.endpoint"="http://192.168.31.198:19000",
"s3.region"="us-east-1",
"s3.access_key"="minioadmin",
"s3.secret_key"="minioadmin"
);1.执行导出任务

2.导出节点文件查看
②导出至 S3 对象存储示例
SELECT SUM(lo_revenue), d_year, p_brand
FROM lineorder, dates, part, supplier
WHERE
lo_orderdate = d_datekey
AND lo_partkey = p_partkey
AND lo_suppkey = s_suppkey
AND p_brand BETWEEN'MFGR#2221'AND'MFGR#2228'
AND s_region ='ASIA'
GROUPBY d_year, p_brand
ORDERBY d_year, p_brand
LIMIT 100
INTO OUTFILE "hdfs://192.168.31.198:8020/doris/"
PROPERTIES(
"fs.defaultFS"="hdfs://192.168.31.198:8020",
"hadoop.username"="hadoop"
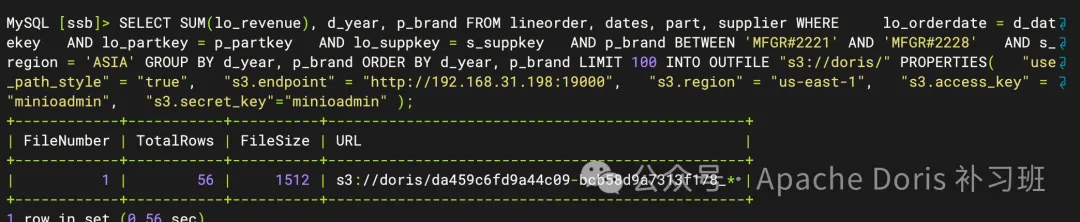
);1.执行导出任务
2.对象存储上的记录
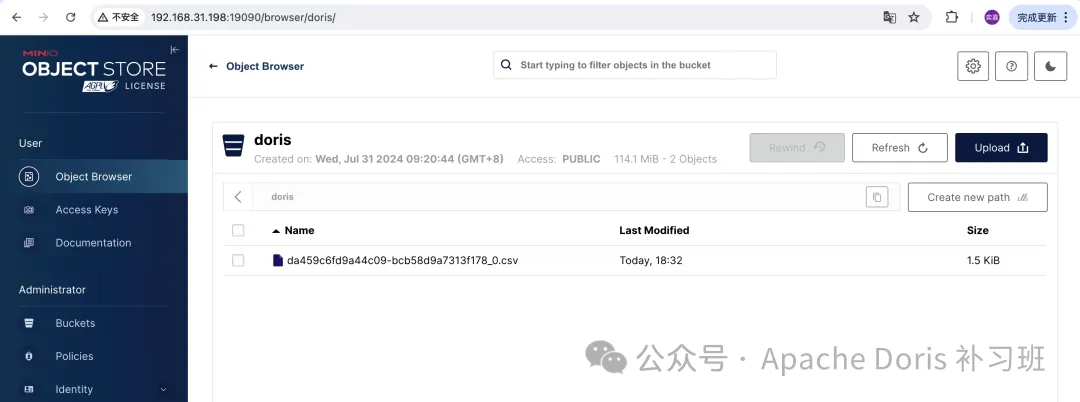
③导出至 HDFS 示例
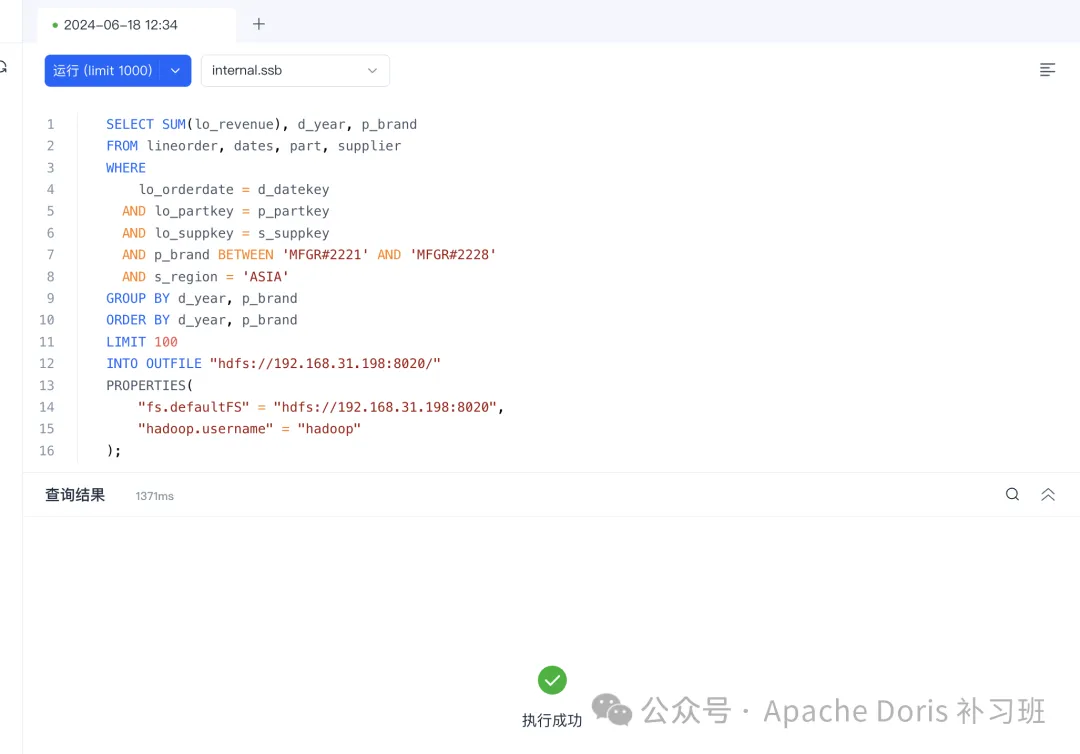
SELECT SUM(lo_revenue), d_year, p_brandFROM lineorder, dates, part, supplierWHERE lo_orderdate = d_datekeyAND lo_partkey = p_partkeyAND lo_suppkey = s_suppkeyAND p_brand BETWEEN'MFGR#2221'AND'MFGR#2228'AND s_region ='ASIA'GROUPBY d_year, p_brandORDERBY d_year, p_brandLIMIT 100INTO OUTFILE "hdfs://192.168.31.198:8020/doris/"PROPERTIES("fs.defaultFS"="hdfs://192.168.31.198:8020","hadoop.username"="hadoop");1.使用 SelectDB Web UI 执行命令
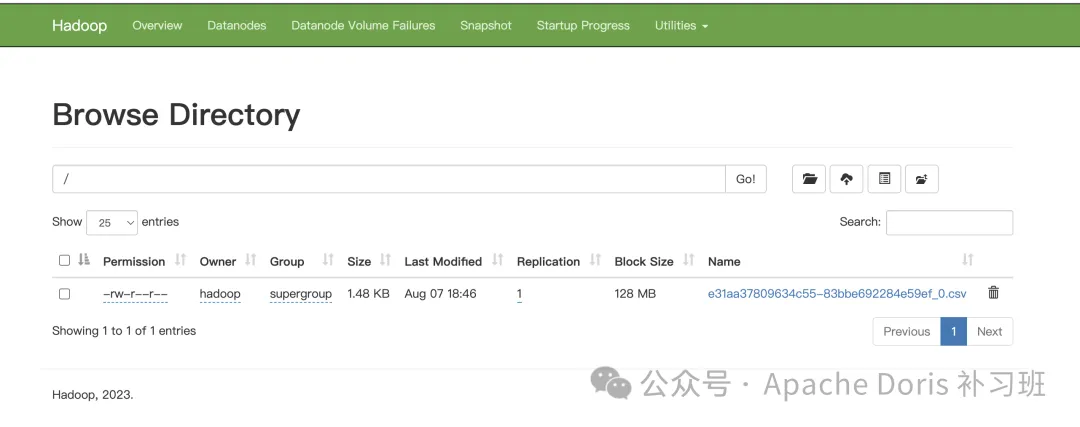
2.HDFS 文件系统界面查看是否上传成功
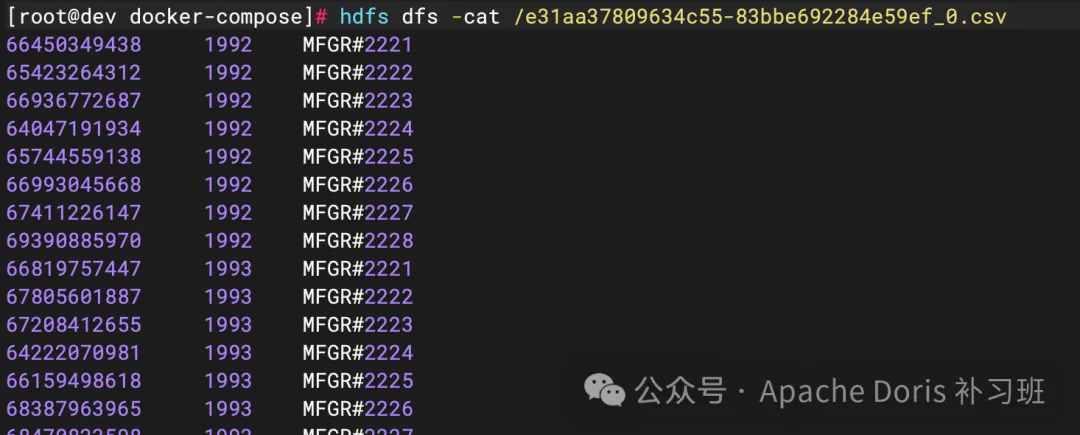
3.查看文件内容是否正确
4、ADBC
适用场景
ADBC 即 Arrow DataBase Connectivity,Doris 基于 Arrow Flight SQL 协议实现了高速数据链路,支持多种语言使用 SQL 从 Doris 高速读取大批量数据。
使用 ADBC 协议,可从 Doris 加载大批量数据到其他组件,如 Python/Java/Spark/Flink,可以使用基于 Arrow Flight SQL 的 ADBC/JDBC 替代过去的 JDBC/PyMySQL/Pandas 来获得更高的读取性能,这在数据科学、数据湖分析等场景中经常遇到。
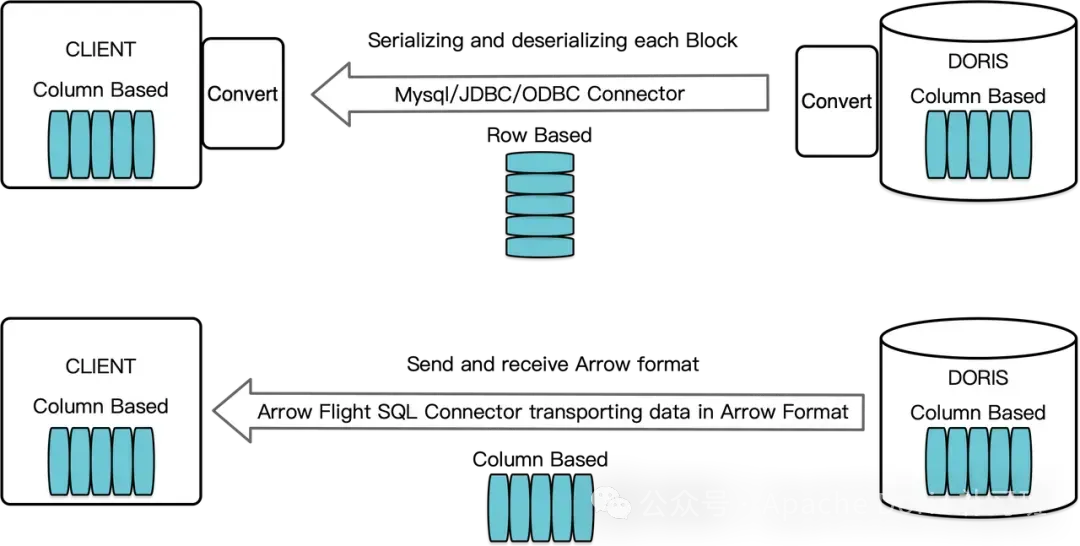
JDBC与ADBC数据流转原理简图
这里需要注意的是:ADBC不仅可以用于读,还可以用于其他常规语法操作,比如查询、写入。
使用示例
①Python 代码引用
ADBC Driver 安装步骤详见官网说明:https://doris.apache.org/zh-CN/docs/dev/db-connect/arrow-flight-sql-connect#adbc-driver这里不做详细赘述
# Import 引入
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql# 执行查询
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())Java 代码引用
POM 依赖引入同上所述,不做详细介绍,可移步至官网了解
②ADBC 方式链接使用
// 1. new driver
finalBufferAllocatorallocator=newRootAllocator();
FlightSqlDriverdriver=newFlightSqlDriver(allocator);
Map<String,Object> parameters =newHashMap<>();
AdbcDriver.PARAM_URI.set(parameters,Location.forGrpcInsecure("0.0.0.0",9090).getUri().toString());
AdbcDriver.PARAM_USERNAME.set(parameters,"root");
AdbcDriver.PARAM_PASSWORD.set(parameters,"");
AdbcDatabaseadbcDatabase= driver.open(parameters);// 2. new connection
AdbcConnectionconnection= adbcDatabase.connect();
AdbcStatementstmt= connection.createStatement();// 3. execute query
stmt.setSqlQuery("select * from information_schema.tables;");
QueryResultqueryResult= stmt.executeQuery();
ArrowReaderreader= queryResult.getReader();// 4. load result
List<String> result =newArrayList<>();
while(reader.loadNextBatch()){
VectorSchemaRootroot= reader.getVectorSchemaRoot();
StringtsvString= root.contentToTSVString();
result.add(tsvString);
}
System.out.printf("batchs %d\n", result.size());// 5. close
reader.close();
queryResult.close();
stmt.close();
connection.close();③JDBC 方式链接使用
final Map<String,Object> parameters =newHashMap<>();
AdbcDriver.PARAM_URI.set(
parameters,"jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false&cachePrepStmts=true&useSSL=false&useEncryption=false");
AdbcDriver.PARAM_USERNAME.set(parameters,"root");
AdbcDriver.PARAM_PASSWORD.set(parameters,"");
try(
BufferAllocatorallocator=newRootAllocator();
AdbcDatabasedb=newJdbcDriver(allocator).open(parameters);
AdbcConnectionconnection= db.connect();
AdbcStatementstmt= connection.createStatement()
){
stmt.setSqlQuery("select * from information_schema.tables;");
AdbcStatement.QueryResultqueryResult= stmt.executeQuery();
ArrowReaderreader= queryResult.getReader();
List<String> result =newArrayList<>();
while(reader.loadNextBatch()){
VectorSchemaRootroot= reader.getVectorSchemaRoot();
StringtsvString= root.contentToTSVString();
result.add(tsvString);
}
longetime=System.currentTimeMillis();
System.out.printf("batchs %d\n", result.size());reader.close();
queryResult.close();
stmt.close();
}catch(Exception e){
e.printStackTrace();
}性能对比
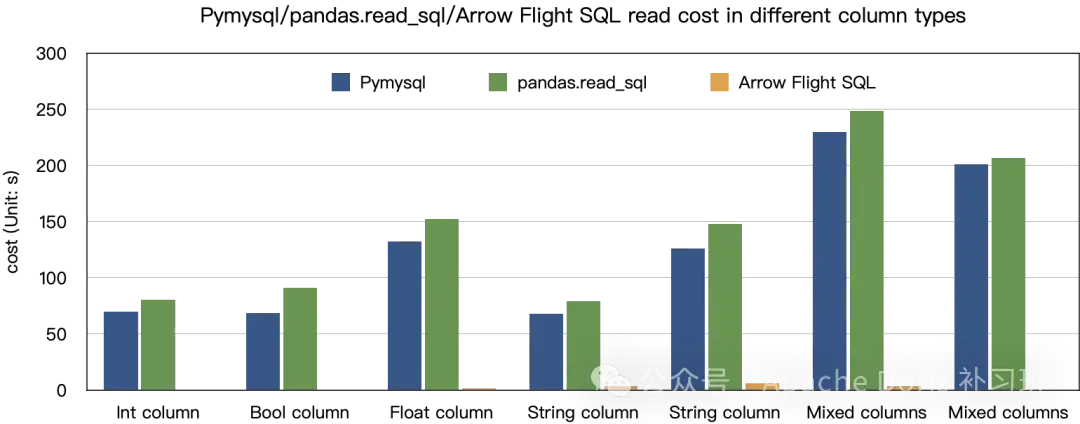
从实际测试对比来看,ADBC在查询数据吞吐方面,比传统 JDBC 能力超百倍左右,所以在诸如 Pandas 等科学计算框架应用方面,有非常明显的效率提升。
5、Backup/Restore
适用场景
正宗的库表级的数据备份/恢复能力,可选择整库备份,也可选择某些表进行备份,粒度有库、表、分区三个级别。
其备份原理是将已有的库表 Tablet 整理出一份完整、可靠的单副本,然后拷贝至 HDFS 或 S3 之上,中间不处理任何数据转换,所以速度是最快的。
同时增量备份能力现在也在研发阶段了。
使用示例
①备份至 HDFS
1.创建 HDFS repository
CREATE REPOSITORY `hdfs_repo`
WITH hdfs
ON LOCATION "hdfs://192.168.31.198:8020/doris-repo"
PROPERTIES
(
"fs.defaultFS"="hdfs://192.168.31.198:8020",
"hadoop.username"="user",
"dfs.replication"="1"
);2.备份单表至 HDFS
标准语法:
BACKUP SNAPSHOT [db_name].{snapshot_name}
TO`repository_name`
[ON|EXCLUDE](
`table_name`[PARTITION(`p1`,...)],
...
)
PROPERTIES ("key"="value", ...);备份 ssb 仓库的 lineorder 明细表的 p1 分区:
BACKUP SNAPSHOT ssb.back01
TO `hdfs_repo`
ON (
`lineorder` PARTITION(`p1`)
);
3.查看已备份数据
②备份至 S3
1.创建 S3 Repository
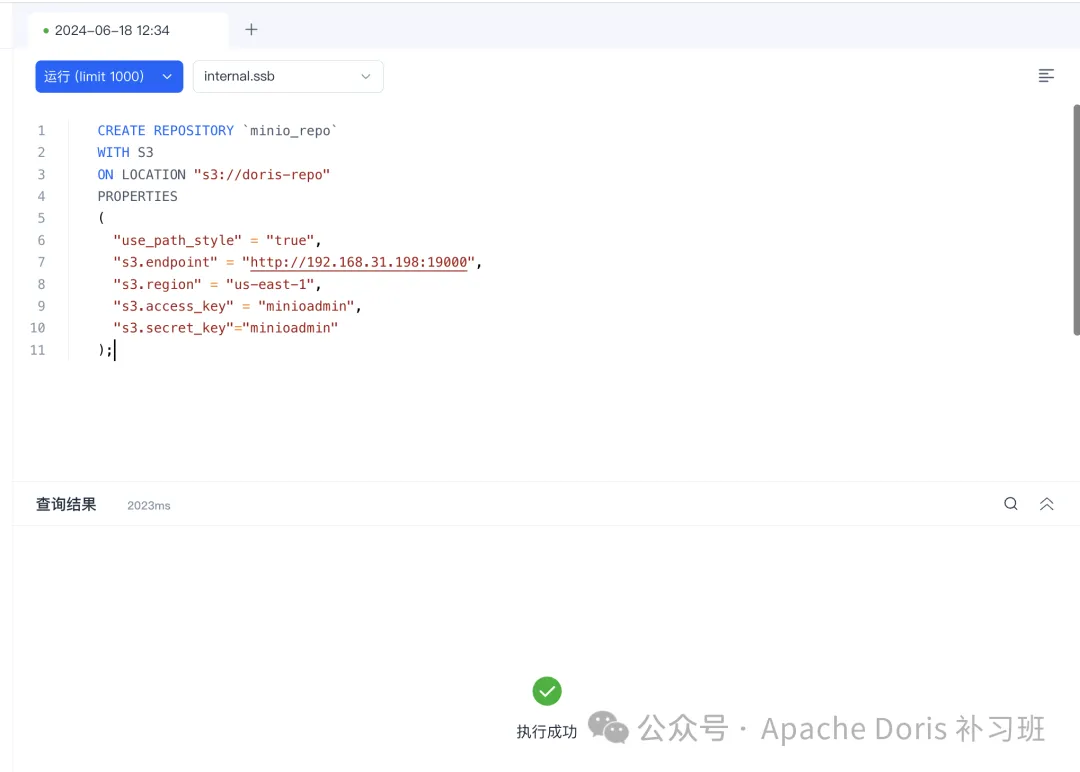
CREATE REPOSITORY `minio_repo`
WITH S3
ON LOCATION "s3://doris-repo"
PROPERTIES
(
"use_path_style"="true",
"s3.endpoint"="http://192.168.31.198:19000",
"s3.region"="us-east-1",
"s3.access_key"="minioadmin",
"s3.secret_key"="minioadmin"
);
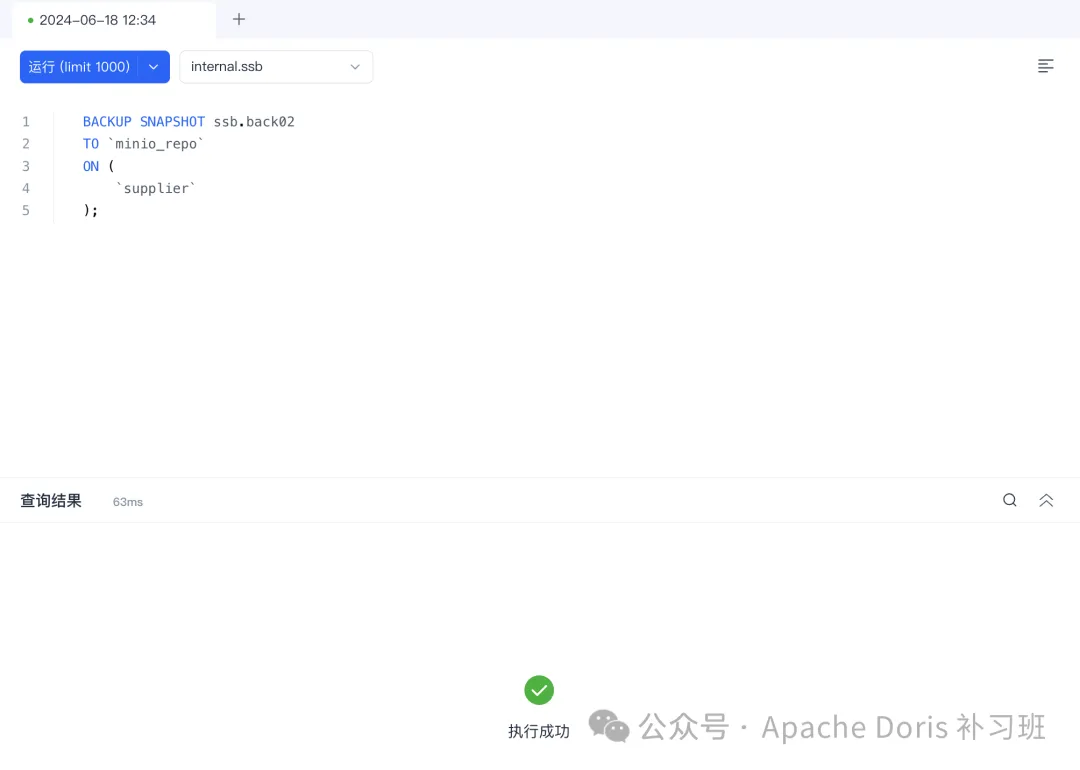
2.备份 ssb 仓库的 supplier 整表:
BACKUP SNAPSHOT ssb.back02
TO `minio_repo`
ON (
`supplier`
);
3.查看已备份的数据
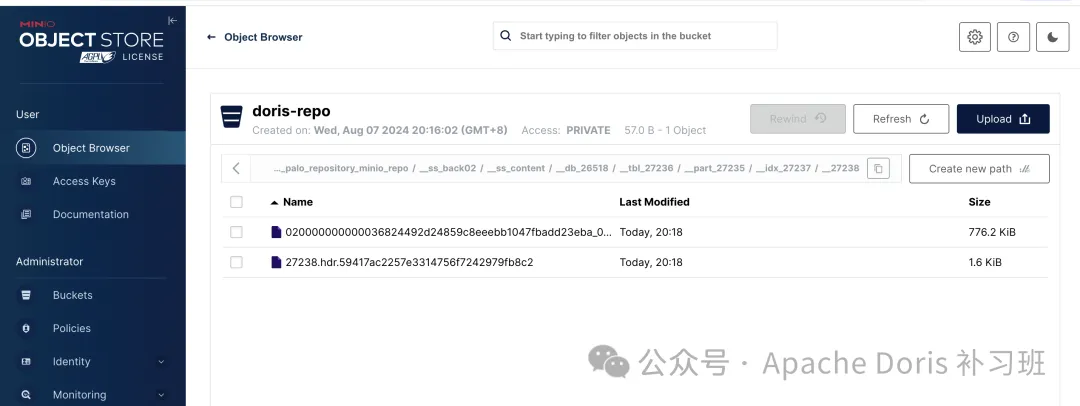
这里需要注意的是,同一数据库下只能有一个正在执行的 BACKUP 或 RESTORE 任务!
③从 HDFS 还原快照
1.删除 ssb 仓库的 lineorder 明细表的 p1 分区
DELETE FROM lineorder PARTITION p1 WHERE lo_orderkey is not null;
SELECT COUNT(*) FROM lineorder PARTITION p1;
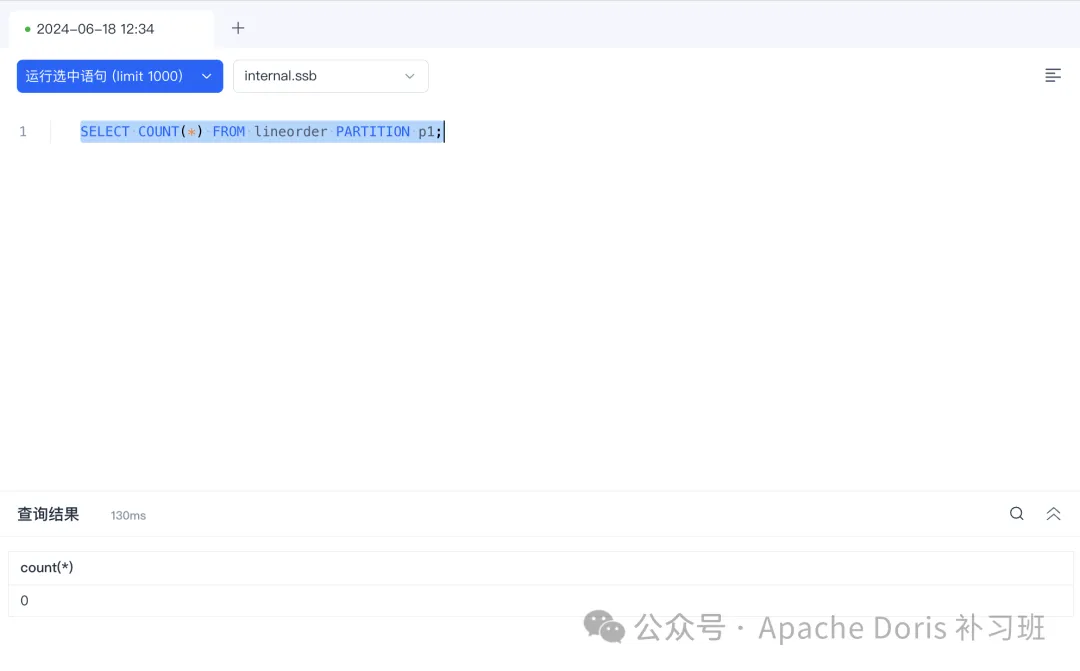
2.从 HDFS 恢复数据
标准语法:
RESTORE SNAPSHOT [db_name].{snapshot_name}
FROM`repository_name`
[ON|EXCLUDE](
`table_name`[PARTITION(`p1`,...)][AS`tbl_alias`],
...
)
PROPERTIES ("key"="value", ...);查看快照版本的时间:
SHOW SNAPSHOT ON repo;
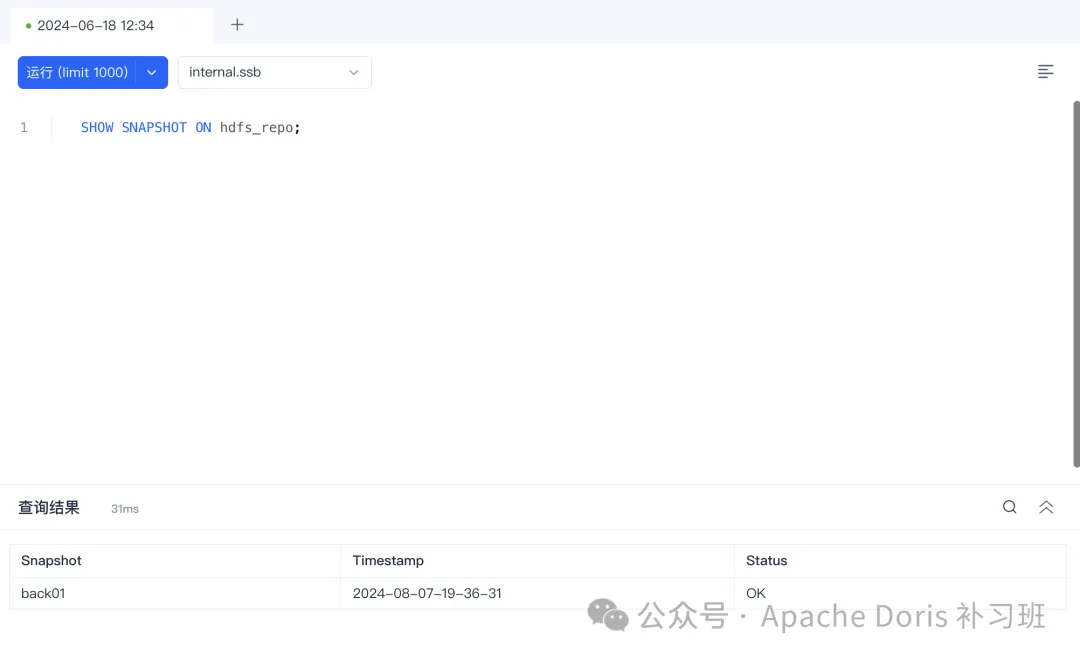
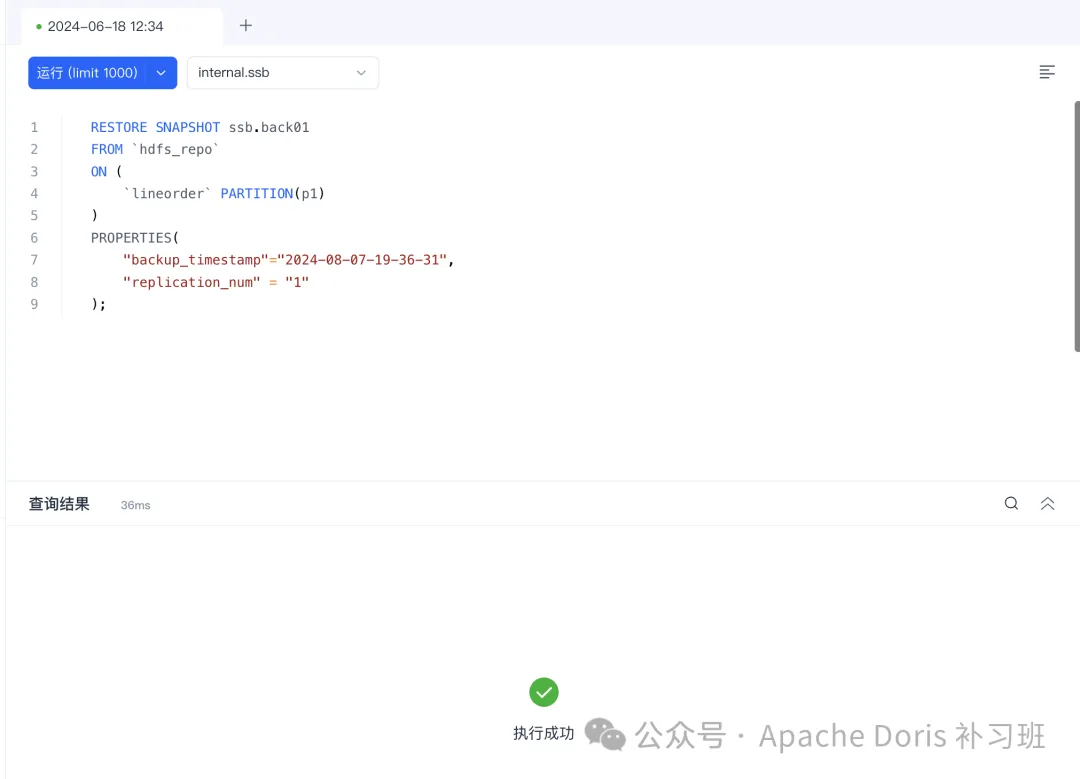
恢复 HDFS 数据:
RESTORE SNAPSHOT ssb.back01
FROM`hdfs_repo`
ON(
`lineorder`PARTITION(p1)
)
PROPERTIES(
"backup_timestamp"="2024-08-07-19-36-31",
"replication_num"="1"
);
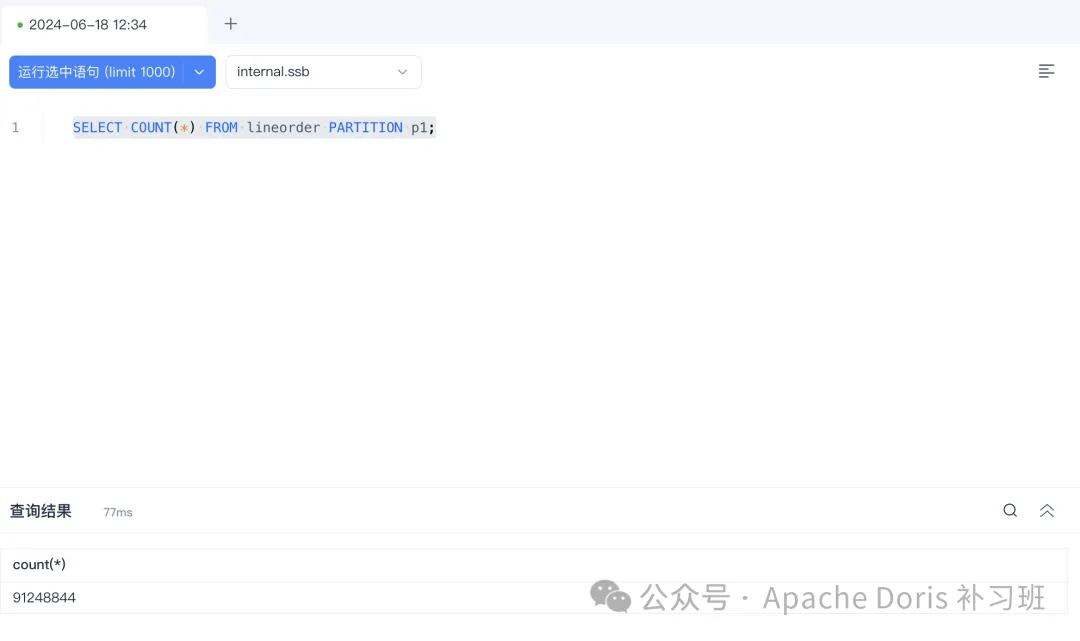
3.查看恢复结果
SELECT COUNT(*) FROM lineorder PARTITION p1;
④从 S3 还原快照
1.删除 supplier 表数据
DELETE FROM `supplier` WHERE s_suppkey is not null;
SELECT COUNT(*) FROM supplier;
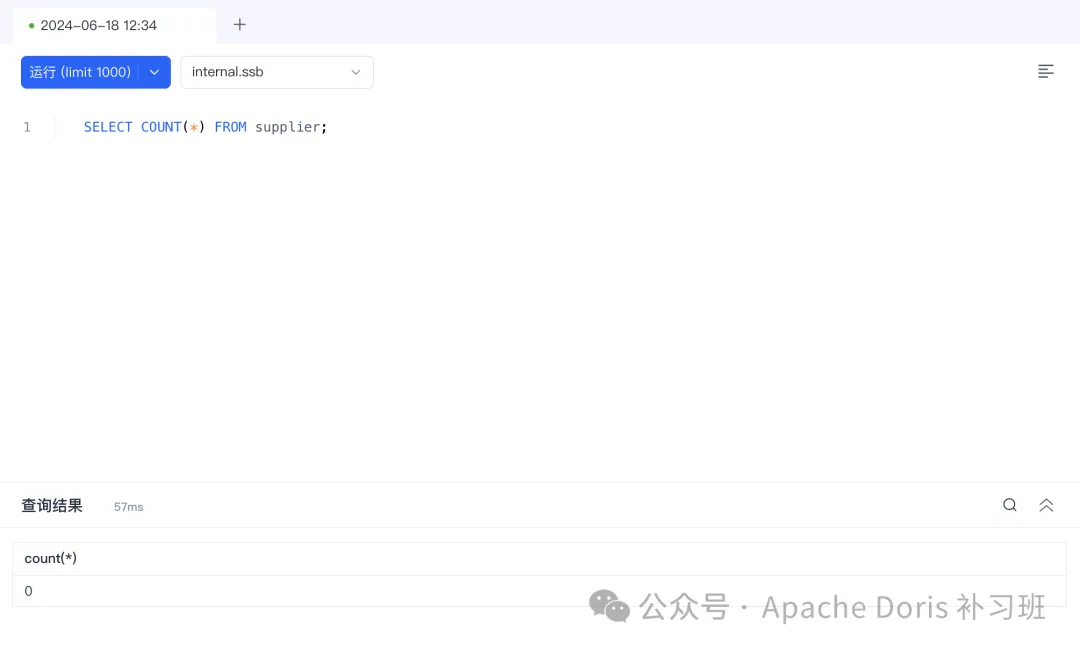
2.从 S3 备份恢复 supplier 表数据
RESTORE SNAPSHOT ssb.back02
FROM`minio_repo`
ON(
supplier
)
PROPERTIES(
"backup_timestamp"="2024-08-07-20-18-09",
"replication_num"="1"
);查看快照时间
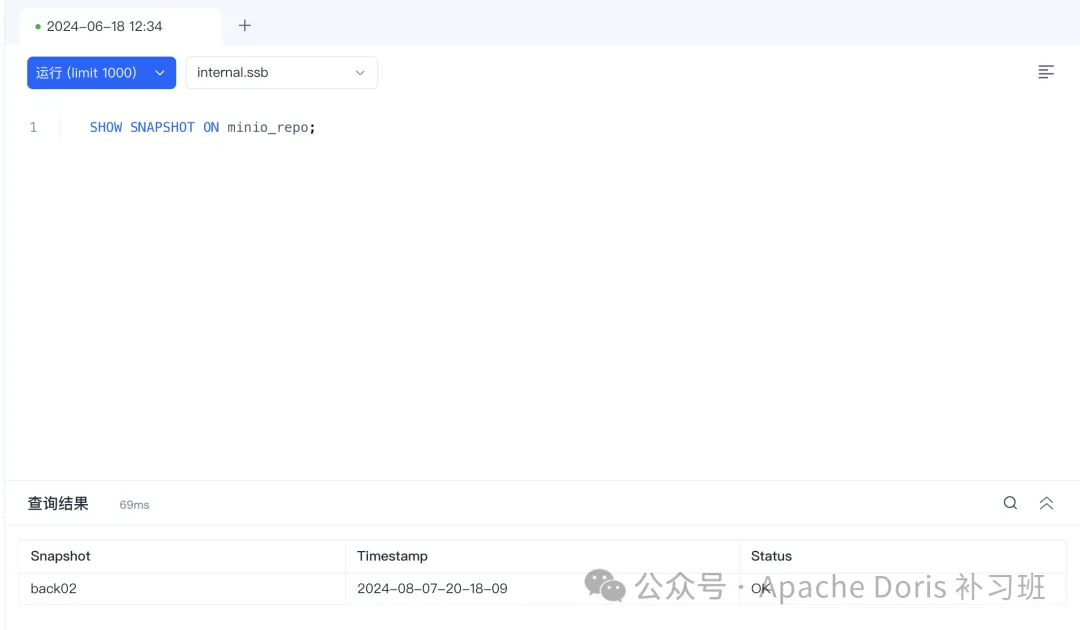
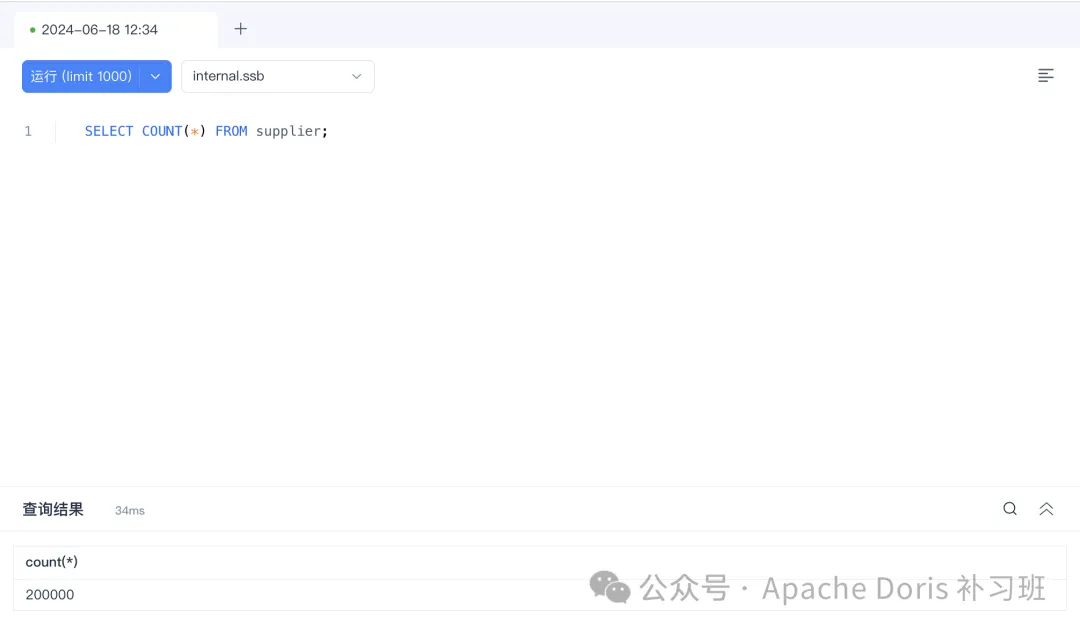
3.查看恢复结果
SELECT COUNT(*) FROM supplier;
6、冷热分层
适用场景
在存算一体架构下,希望将存储周期比较长的数据冷备至存储成本较低的介质中,比如某明细表,日增1TB,业务查询经常会用到30天内的数据,为了保证查询效率,这些热数据用 SSD 存储介质来存储,30天以前的数据希望用更便宜的存储介质来存储,以此降低整体架构成本。
这里需要说明的一点是,冷热分层不会改变查询使用习惯。
冷热数据是通过表配置来决定啥时候进行冷备,以及冷备到什么位置。
查询的数据会自动完成迁移,不需要任何人为干预。
使用示例
冷备至HDFS
1.创建 hdfs_resource Resource 资源
CREATE RESOURCE hdfs_resource
PROPERTIES (
"type"="hdfs",
"fs.defaultFS"="hdfs://192.168.31.198:8020",
"hadoop.username"="hadoop",
"dfs.namenode.rpc-address"="192.168.31.198:8020",
"dfs.replication"="1"
);
2.创建冷备策略,设置冷备资源为 HDFS_RESOURCE,冷备时间为存储后 60 秒。
CREATE STORAGE POLICY hdfs_policy PROPERTIES (
"storage_resource" = "hdfs_resource",
"cooldown_ttl" = "60"
)3.创建 customer_hdfs_cold 表,表结构使用 customer 的表结构,冷备策略设置为 hdfs_policy。
CREATE TABLE
`customer_hdfs_cold`(
`c_custkey`INTNOTNULL,
`c_name`VARCHAR(26)NOTNULL,
`c_address`VARCHAR(41)NOTNULL,
`c_city`VARCHAR(11)NOTNULL,
`c_nation`VARCHAR(16)NOTNULL,
`c_region`VARCHAR(13)NOTNULL,
`c_phone`VARCHAR(16)NOTNULL,
`c_mktsegment`VARCHAR(11)NOTNULL
) ENGINE = OLAP DUPLICATE KEY(`c_custkey`) COMMENT 'OLAP' DISTRIBUTED BY HASH(`c_custkey`) BUCKETS 12 PROPERTIES (
"replication_allocation"="tag.location.default: 1",
"storage_policy"="hdfs_policy"
);4.插入customer 的数据至 customer_hdfs_cold 表中,60秒后观察数据冷备情况。
INSERT INTO customer_hdfs_cold
SELECT * FROM customer;
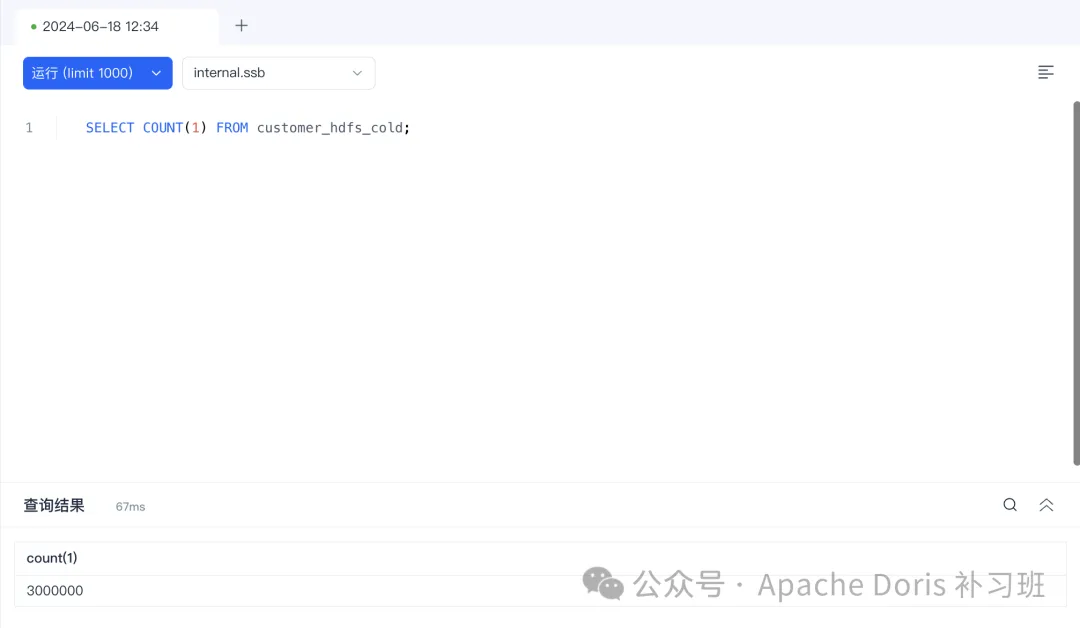
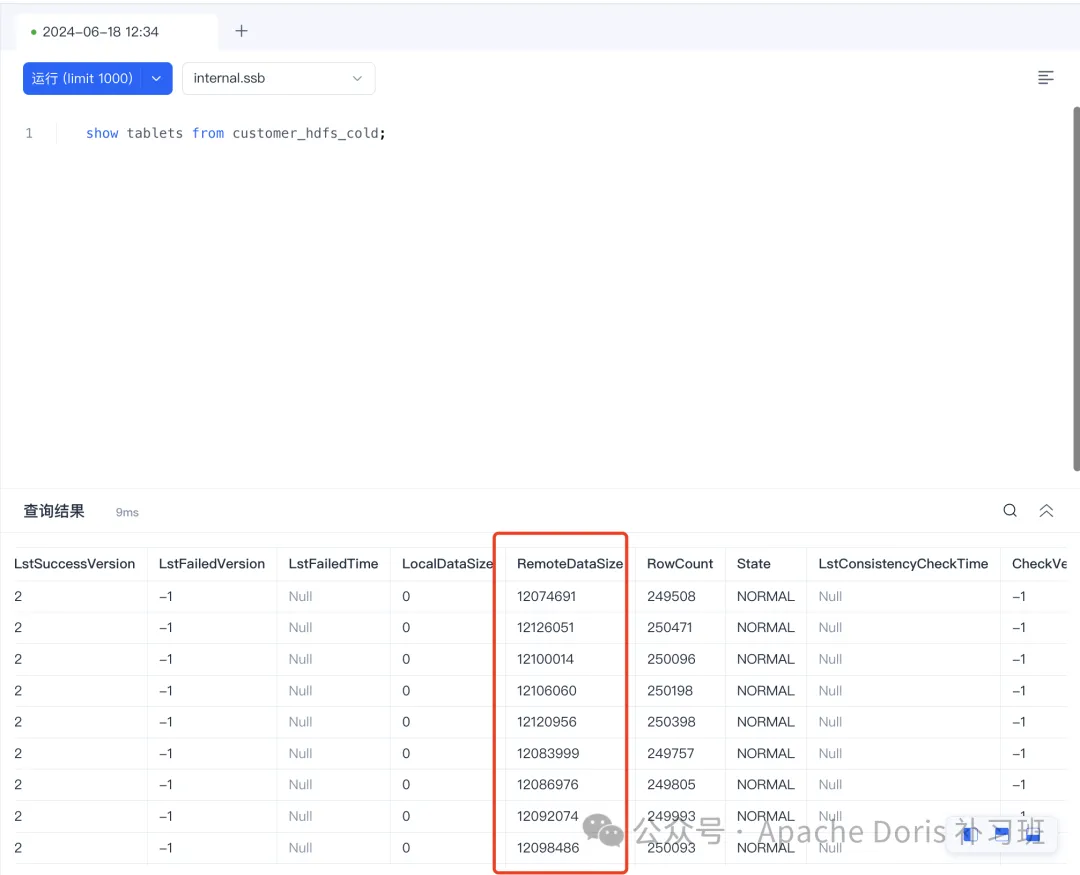
5.查看冷备数据情况
show tablets from customer_hdfs_cold;
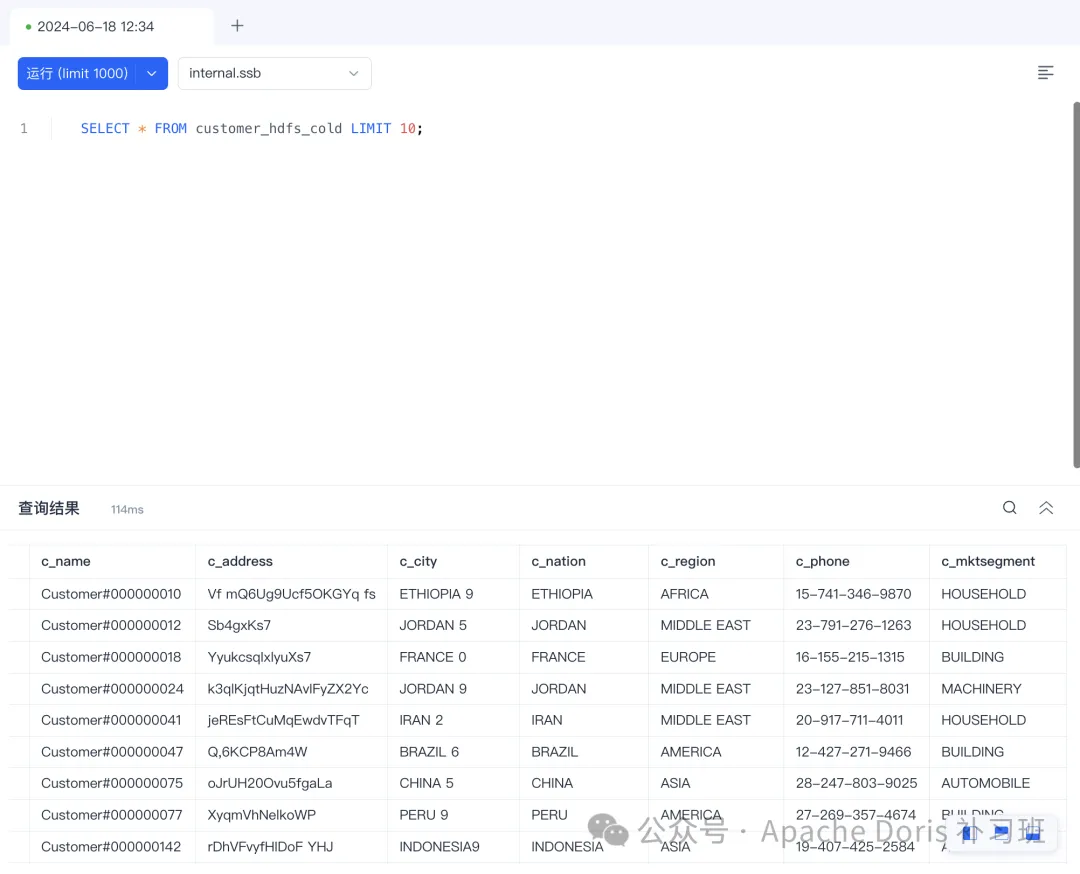
执行查询:
SELECT * FROM customer_hdfs_cold LIMIT 10;
6.查看远端存储情况
冷备至 S3
1.创建 remote_s3 Resource 资源
CREATE RESOURCE "remote_s3"
PROPERTIES
(
"type"="s3",
"use_path_style"="true",
"s3.endpoint"="http://192.168.31.198:19000",
"s3.region"="us-east-1",
"s3.access_key"="minioadmin",
"s3.secret_key"="minioadmin",
-- required by cooldown
"s3.root.path"="/cold",
"s3.bucket"="doris-repo"
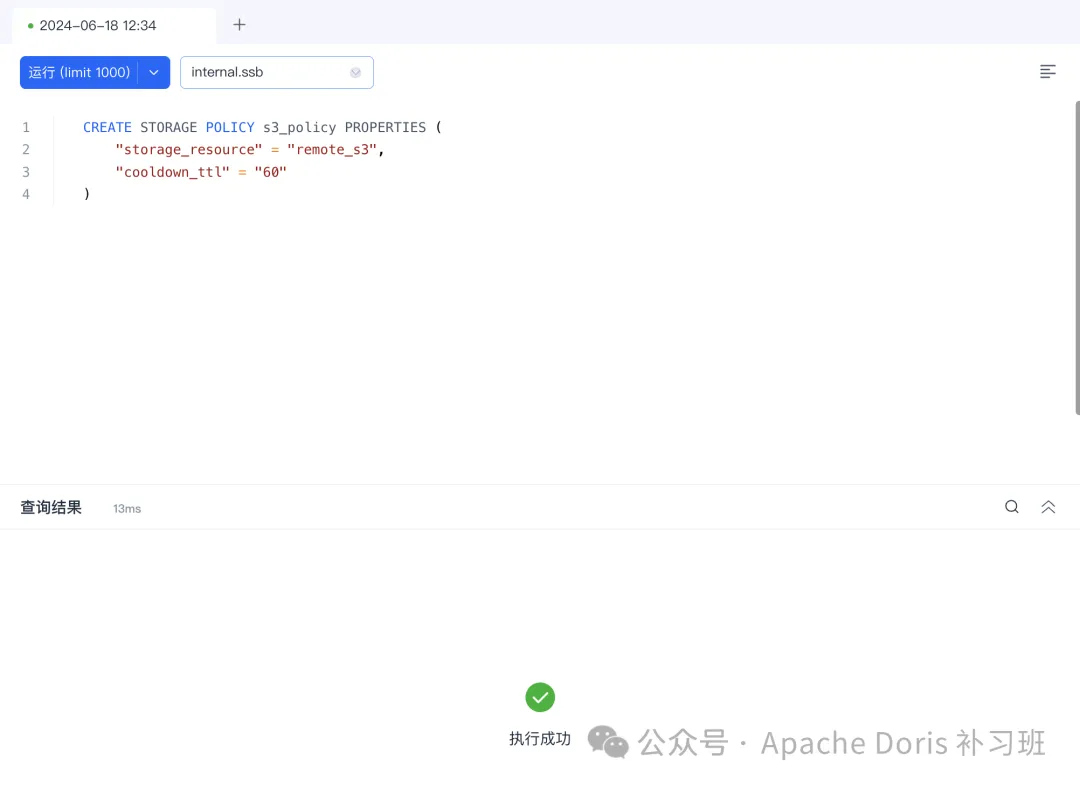
);2.创建冷备策略,设置冷备资源为 S3_RESOURCE,冷备时间为存储后 60 秒。
CREATE STORAGE POLICY s3_policy PROPERTIES (
"storage_resource" = "remote_s3",
"cooldown_ttl" = "60"
)
3.创建 customer_s3_cold 表,表结构使用 customer 的表结构,冷备策略设置为 hdfs_policy。
CREATE TABLE`customer_s3_cold`(`c_custkey`INTNOTNULL,`c_name`VARCHAR(26)NOTNULL,`c_address`VARCHAR(41)NOTNULL,`c_city`VARCHAR(11)NOTNULL,`c_nation`VARCHAR(16)NOTNULL,`c_region`VARCHAR(13)NOTNULL,`c_phone`VARCHAR(16)NOTNULL,`c_mktsegment`VARCHAR(11)NOTNULL) ENGINE = OLAP DUPLICATE KEY(`c_custkey`) COMMENT 'OLAP' DISTRIBUTED BY HASH(`c_custkey`) BUCKETS 12 PROPERTIES ("replication_allocation"="tag.location.default: 1","storage_policy"="s3_policy" );4.插入customer 的数据至 customer_s3_cold 表中,60秒后观察数据冷备情况。
INSERT INTO customer_s3_cold SELECT * FROM customer;
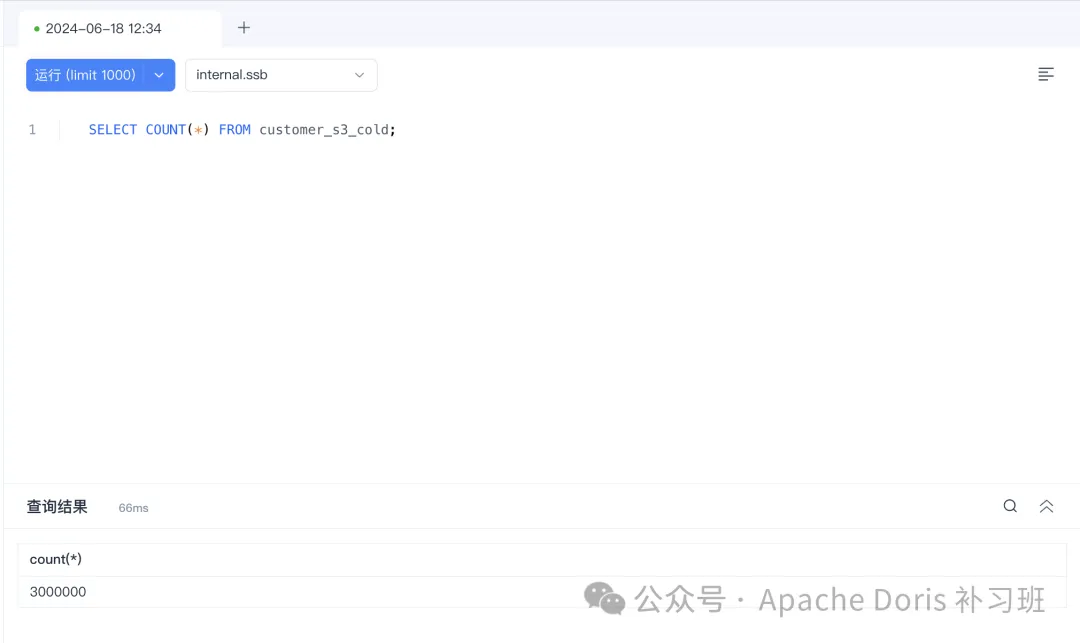
5.查看冷备数据情况
show tablets from customer_s3_cold;
执行查询:
SELECT * FROM customer_hdfs_cold LIMIT 10;
6.查看远端存储情况
7、CCR
适用场景
CCR(Cross Cluster Replication) 是跨集群数据同步,能够在库/表级别将源集群的数据变更同步到目标集群,可用于在线服务的数据可用性、隔离在离线负载、建设两地三中心。
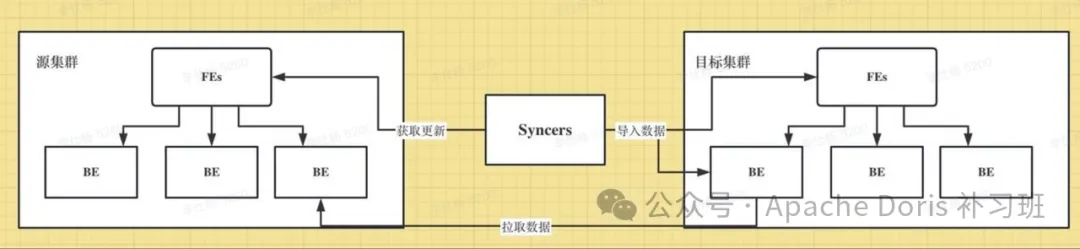
使用示例
使用非常简单,只需把Syncers服务启动,给他发一个命令,剩下的交个Syncers完成就行。
1.1. 部署源doris集群
2.2. 部署目标doris集群
3.3. 首先源集群和目标集群都需要打开binlog,在源集群和目标集群的fe.conf和be.conf中配置如下信息,这是大前提:
enable_feature_binlog=true1.1. 部署 syncers 获取CCR包
# 联系 SelectDB 同学即可免费获取 CCR 二进制包2.启动和停止syncer
# 启动
cd bin && sh start_syncer.sh --daemon
# 停止
sh stop_syncer.sh3.打开源集群中同步库/表的 binlog
-- 如果是整库同步,可以执行如下脚本,使得该库下面所有的表都要打开binlog.enable
vim shell/enable_db_binlog.sh
修改源集群的host、port、user、password、db-- 如果是单表同步,则只需要打开table的binlog.enable,在源集群上执行:
ALTER TABLE enable_binlog SET ("binlog.enable" = "true");4.向syncer发起同步任务
curl -X POST -H "Content-Type: application/json" -d '{
"name": "ccr_test",
"src": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "your_db_name",
"table": "your_table_name"
},
"dest": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "your_db_name",
"table": "your_table_name"
}
}' http://127.0.0.1:9190/create_ccr同步任务的参数说明:
name: CCR同步任务的名称,唯一即可
host、port:对应集群master FE的host和mysql(jdbc) 的端口
user、password:syncer以何种身份去开启事务、拉取数据等
database、table:
如果是db级别的同步,则填入your_db_name,your_table_name为空
如果是表级别同步,则需要填入your_db_name,your_table_name
向syncer发起同步任务中的name只能使用一次小结
本篇延续了个人的实操习惯,边搭环境边写文档,所以速度比较慢,基本上消耗了十天左右的工作后休息时间。
不过返回来在从头阅读时,感觉整体篇幅还是过于长了,其实每个机制都可以掰开揉碎了讲,比如底层机制,比如一些局限性和适用性,本篇文章希望能起一个提纲要领的引子作用,在各位看官老爷看完后,某天希望使用 Doris 完成各种场景下的备份恢复的话,大可收藏来翻阅。
看到这里,就别吝啬各位的点赞和在看以及评论转发啦!
每次良好的数据都是下次努力更新的绝对动力!
相关文章:
全面介绍 Apache Doris 数据灾备恢复机制及使用示例
引言 Apache Doris 作为一款 OLAP 实时数据仓库,在越来越多的中大型企业中逐步占据着主数仓这样的重要位置,主数仓不同于 OLAP 查询引擎的场景定位,对于数据的灾备恢复机制有比较高的要求,本篇就让我们全面的介绍和示范如何利用这…...

Python pandas常见函数
Pandas库 基本概念读取数据数据处理数据输出其他常用功能 pip install pandas基本概念 数据结构 Series: 一维数据结构 import pandas as pd data pd.Series([10, 20, 30, 40], index[a, b, c, d]) print(data)DataFrame: 二维数据结构 data {Name: [Alice, Bob, Charlie],Ag…...

行业落地分享:阿里云搜索RAG应用实践
最近这一两周看到不少互联网公司都已经开始秋招提前批了。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。 最近,我们又陆续整理了很多大厂的面试题,帮助一些球友…...

【SQL】温度比较
目录 题目 分析 代码 题目 表: Weather ------------------------ | Column Name | Type | ------------------------ | id | int | | recordDate | date | | temperature | int | ------------------------ id 是该表具有唯…...

Istio 项目会往用户的 Pod 里注入 Envoy 容器,用来代理 Pod 的进出流量,这是什么设计模式?
Istio 项目会往用户的 Pod 里注入 Envoy 容器,用来代理 Pod 的进出流量,这是什么设计模式? A. 装饰器 B. sidecar C. 工厂模式 D. 单例 选择B Sidecar模式是一种设计模式,它将应用程序的一部分功能作为单独的进程实现ÿ…...
(24.1) FPV和仿真的机载OSD(三))
(24)(24.1) FPV和仿真的机载OSD(三)
文章目录 前言 5 呼号面板 6 用户可编程警告 7 使用SITL测试OSD 8 OSD面板列表 前言 此面板允许在机载 OSD 屏幕上显示业余无线电呼号(或任何其他单个字符串)。它将从 SD 卡根目录下名为“callsign.txt”的文件中读取字符串。 5 呼号面板 此面板允…...

测试开发岗面试总结
某基金管理公司线下测试开发面试题总结。 测开题目如下 可以尝试自己先写,写完之后再去看参考解法哦 ~ 1、编写一段代码,把 list 的数平方(语言不限) ListA [1, 3, 5, 7, 9, 11] 2、使用 Python 语言编写一个日志装饰器 3、进程、线程、协程有什么…...

编程-设计模式 7:桥接模式
设计模式 7:桥接模式 定义与目的 定义:桥接模式将抽象部分与它的实现部分分离,使得它们都可以独立地变化。目的:该模式的主要目的是解耦一个类的抽象部分与其实现部分,使得这两部分可以独立地发展和变化。 实现示例…...

C语言----结构体
结构体 结构体的含义 自定义的数据类型 它是由很多的数据组合成的一个整体,结构型数据 其中的每一个数据,都是结构体的成员 书写的位置: 函数的里面:局部位置,只能再本函数中使用 函数的外面:全局位置,在所有的函数中都可以…...
基于HKELM混合核极限学习机多输出回归预测 (多输入多输出) Matlab代码
基于HKELM混合核极限学习机多输出回归预测(多输入多输出)Matlab代码 每个输出都有以下线性拟合图等四张图!!!具体看图,独家图像!!! 程序已经调试好,替换数据集根据输出个数修改out…...

经纬恒润荣获小米汽车优秀质量奖!
小米SU7上市已超百天,在品质经过客户严选的同时,产量与交付量屡创新高,6-7月连续两个月交付量均超过10000台。为奖励对小米汽车质量和交付做出卓越贡献的合作伙伴团队及个人,小米向质量表现突出的供应商授予了优秀质量奖。经纬恒润…...

Linux 软件编程学习第十一天
1.管道: 进程间通信最简单的形式 2.信号: 内核层和用户层通信的一种方式 1.信号类型: 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 1…...

hive udtf 函数:输入一个字符串,将这个字符串按照特殊的逻辑处理之后,输出4个字段
这里要继承GenericUDTF 这个抽象类,直接上代码: package com.xxx.hive.udf; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.hive.ql.exec.Description; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import …...

【实现100个unity特效之16】unity2022之前或者之后版本实现全屏shader graph的不同方式 —— 适用于人物受伤红屏或者一些其他状态效果
最终效果 文章目录 最终效果前言unity2022版本 Fullscreen shader graph首先,请注意你的Inity版本,是不是2022.2以上,并且项目是URP项且基本配置 修改shader graph边缘效果动起来优化科幻风制作一些变量最终效果最终节点图代码控制 2022之前版…...

比特币使用ord蚀刻符文---简单笔记
说明 毕竟符文热度过了,今年四月份做的笔记分享出来 蚀刻符文需要先同步完区块数据,和index文件,不然蚀刻会失败,在testnet和signet网络也一样。 创建钱包(会输出助记词): ord --bitcoin-da…...

大数据-74 Kafka 高级特性 稳定性 - 控制器、可靠性 副本复制、失效副本、副本滞后 多图一篇详解
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

c# 什么是扩展方法
官方解释 扩展方法使你能够向现有类型“添加”方法,而无需创建新的派生类型、重新编译或以其他方式修改原始类型。 扩展方法是一种静态方法,但可以像扩展类型上的实例方法一样进行调用。 对于用 C#、F# 和 Visual Basic 编写的客户端代码&#x…...
)
全屏组件封装(react18+antd)
基于reactts封装的公用全屏组件 1、封装组件 在components下面构建FullScreenButton文件: FullScreenButton/index.tsx import React, { useState, useCallback, useEffect } from "react"; import { FullscreenOutlined, FullscreenExitOutlined } fr…...

wordpress全局自适应网址导航整站打包源码,含主题和数据库
wordpress全局自适应网址导航整站打包源码,含主题和数据库。直接恢复就可以使用了。 这个是自适应的布局设计,体验还不错。用网址导航是可以的。 代码免费下载:百度网盘...

PyTorch深度学习框架
最近放假在超星总部河北燕郊园区实习,本来是搞前后端开发岗位的,然后带我的副总老大哥比较关照我,了解我的情况后得知我大三选的方向是大数据,于是建议我学学python、Hadoop,Hadoop我看了一下内容比较多,而…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...