线程池原理(一)线程池核心概述
更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验
线程回顾
创建线程的方式
- 继承 Thread 类
- 实现 Runnable 接口
创建后的线程有如下状态:
NEW:新建的线程,无任何操作
public static void main(String[] args) {Thread thread = new Thread(() -> System.out.println(Thread.currentThread().getName() + "is running"));Thread.State state = thread.getState();// 线程刚创建还未执行,状态为 NEWSystem.out.println(state);}
RUNNABLE:可执行的线程,在 JVM 中执行但是在等待操作系统的资源
public static void main(String[] args) {Thread thread = new Thread(() -> System.out.println(Thread.currentThread().getName() + "is running"));thread.start();Thread.State state = thread.getState();// 调用 start() 方法,可以执行,但不代表一定在执行System.out.println(state);
}
BOLCKED:阻塞,获取不到锁
public static void main(String[] args) {Thread thread1 = new Thread(() -> {synchronized (Test.class) {try {Thread.sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}}});Thread thread2 = new Thread(() -> {synchronized (Test.class) {}});thread1.start();thread2.start();// 等待,保证 线程1 开始执行try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}Thread.State state = thread2.getState();System.out.println(state);}
WAITING:等待,等待其他线程进行操作,时间不确定
public static void main(String[] args) {Thread thread = new Thread(LockSupport::park);thread.start();// 等待线程开始执行try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}Thread.State state = thread.getState();System.out.println(state);// 等待状态解除禁止,线程执行完毕LockSupport.unpark(thread);try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}state = thread.getState();System.out.println(state);}
TIMED_WAITING:等待,等待的时间是确定的
public static void main(String[] args) {Thread thread = new Thread(() -> {try {Thread.sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}});thread.start();try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}Thread.State state = thread.getState();System.out.println(state);}
TERMINATED:终止,线程已经运行完毕
public static void main(String[] args) {Thread thread = new Thread(() -> System.out.println(Thread.currentThread().getName() + "is running"));thread.start();try {// 等待线程执行完毕Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}Thread.State state = thread.getState();System.out.println(state);}
引入线程池
上述创建线程的方式存在如下缺陷:
- 线程使用完后会被销毁,高并发场景下频繁创建和销毁线程的性能开销不可忽略
- 无法控制线程并发数量,线程过多会导致 JVM 宕机
线程池是一种池化思想,由于创建和销毁线程需要时间,以及系统资源开销,我们需要一个“管理者"来统一管理线程及任务分配,减少这些开销,解决资源不足的问题。
在主要大厂的编程规范中,不允许在应用中自行显式地创建线程,线程必须通过线程池提供。
线程池解决了什么问题
- 降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗:
- 提高系统响应速度,当有任务到达时,通过复用已存在的线程,无需等待新线程的创建便能立即执行:
- 方便线程并发数的管控。因为线程若是无限制的创建,可能会导致内存占用过多而产生OOM
- 节省CPU切换线程的时间成本(需要保持当前执行线程的现场,并恢复要执行线程的现场)。
- 提供更强大的功能,延时定时线程池
线程池引发了什么问题
- 异步任务提交后,如果JVM宕机,已提交的任务会丢失,需要考虑确认机制
- 使用不合理可能导致内存溢出问题
- 参数过多,代码结构引入数据结构与算法,增加使用难度
线程池概述
线程池继承结构

- 最常用的是 ThreadPoolExecutor
- 调度用 ScheduledThreadPoolExecutor,类似 Timer 和 TimerTask。
- 任务拆分合并用 ForkJoinPool
- Executors是工具类,协助创建线程池的
线程池工作状态

-
RUNNING(运行状态):这是线程池的初始状态。
- 在此状态下,线程池接受新任务,并且也会处理等待队列中的任务。
- 线程池的线程会一直运行,直到被转换到其他状态。
-
SHUTDOWN(关闭状态):当调用线程池的shutdown()方法时,线程池会进入此状态。
- 在此状态下,线程池不接受新任务,但会继续处理等待队列中的任务。
- 等待队列中的任务处理完毕后,线程池中的线程会逐渐结束,直到所有线程结束运行。
-
STOP(停止状态):当调用线程池的shutdownNow()方法时,线程池会进入此状态。
- 在此状态下,线程池不接受新任务,同时也不处理等待队列中的任务
- 而是尝试停止所有正在执行的任务,并且回收线程池中的所有线程。
-
TIDYING(整理状态):当所有的任务已经终止,workerCount(工作线程数)为0时,线程池会进入此状态。
- 此时,会执行terminated()钩子方法,允许线程池执行一些收尾工作。
-
TERMINATED(终止状态):terminated()钩子方法执行完毕后,线程池会进入此状态。
- 在终止状态下,线程池的任务完全结束,不再有任何活动。
七个核心参数
| 参数名 | 描述 |
|---|---|
corePoolSize | 核心线程池基本大小,核心线程数 |
maximumPoolSize | 线程池最大线程数 |
keepAliveTime | 线程空闲后的存活时间 |
TimeUnit unit | 线程空闲后的存活时间单位 |
BlockingQueue workQueue | 存放任务的阻塞队列 |
ThreadFactory threadFactory | 创建线程的工厂 |
RejectedExecutionHandler handler | 当阻塞队列和最大线程池都满了之后的饱和策略 |
corePoolSize
核心线程数
- 线程池刚创建时,线程数量为0,当每次执行 execute 添加新的任务时会在线程池创建一个新的线
程,直到线程数量达到 corePoolSize 为止。 - 核心线程会一直存活,即使没有任务需要执行,当线程数小于核心线程数时,即使有线程空闲,线程
池也会优先创建新线程处理 - 设置 allowCoreThreadTimeout=true (默认false)时,核心线程超时会关闭
maximumPoolSize
最大线程数
- 当池中的线程数 >= corePoolSize ,且任务队列已满时。线程池会创建新线程来处理任务
- 当池中的线程数 = maximumPoolSize ,且任务队列已满时,线程池会拒绝处理任务而抛出异常
如果使用无界的阻塞队列,该参数不生效
BlockingQueue
阻塞队列
- 当线程池正在运行的线程数量已经达到 corePoolSize ,那么再通过 execute 添加新的任务则会被加到 workQueue 队列中
- 任务会在队列中排队等待执行,而不会立即执行
- 一般来说,这里的阻塞队列有以下几种选择:ArrayBlockingQueue , LinkedBlockingQueue , SynchronousQueue
keepAliveTime & TimeUnit
保活时间及其单位
- 当线程空闲时间达到 keepAliveTime 时,线程会退出,直到线程数量 =corePoolSize
- 如果 allowCoreThreadTimeout=true ,则会直到线程数量=0
keepAliveTime 是时间的大小,TimeUnit 是时间单位
ThreadFactory
线程工厂
- 主要用来创建线程
- 通过newThread()方法提供创建线程,该方法创建的线程都是“非守护线程”而且“线程优先级都是默认优先级”
RejectedExecutionHandler
拒绝策略
- 当线程数已经达到 maxPoolSize ,且队列已满,会拒绝新任务
- 当线程池被调用 shutdown() 后,会等待线程池里的任务执行完毕,再 shutdown 。如果在调用shutdown() 和线程池真正 shutdown 之间提交任务,会拒绝新任务
- 当拒绝处理任务时线程池会调用 rejectedExecutionHandler 来处理这个任务。
如果没有设置默认是 AbortPolicy ,另外在 ThreadPoolExecutor 类有几个内部实现类来处理这类情况:
- ThreadPoolExecutor.AbortPolicy :丢弃任务并抛出 RejectedExecutionException 异常。
- ThreadPoolExecutor.CallerRunsPolicy :由调用线程处理该任务
- ThreadPoolExecutor.DiscardPolicy :也是丢弃任务,但是不抛出异常
- ThreadPoolExecutor.DiscardOldestPolicy :丢弃队列最前面的任务,然后重新尝试执行任务
另外实现 RejectedExecutionHandler 接口即可实现自定义的拒绝策略
线程池逻辑结构
线程池的编程模式下,任务是提交给整个线程池,而不是直接提交给某个线程,线程池在拿到任务后,就在内部协调空闲的线程,如果有,则将任务交给某个空闲的华线程。
一个线程同时只能执行一个任务,但可以同时向一个线程池提交多个任务。
当一个任务被提交,线程池会进行如下工作:
-
首先判断当前的核心线程数量如果小于核心线程数,创建一个核心线程并执行任务
-
如果大于核心线程数,则尝试将其放入等待队列,如果队列没有满则放入队列等待执行
-
如果队列已满,则判断非核心线程数的数量+核心线程数是否小于最大线程数量
-
小于:则创建一个非核心线程并执行任务(并不会取队列中的任务)
-
大于:执行拒绝策略
线程池线程数设置
虽然使用线程池的好处很多,但是如果其线程数配置得不合理,不仅可能达不到预期效果,反而可能降低应用的性能。
因此按照任务类型分类,对不同的任务类型确定不同的线程数量。
任务类型分类
- IO密集型任务:
- 此类任务主要是执行 IO 操作。由于执行 lO 操作的时间较长,导致 CPU 的利用率不高,这类任务 CPU 常处于空闲状态。
- Netty 的 IO 读写操作为此类任务的典型例子
- CPU 密集型任务:
- 此类任务主要是执行计算任务。由于响应时间很快,CPU 一直在运行,这种任务 CPU 的利用率很高。
- 例如设计加密解密算法等大量需要 CPU 运算的场景
- 混合型任务:
- 此类任务既要执行逻辑计算,又要进行 IO 操作(如 RPC 调用、数据库访问)相对来说,由于执行 IO 操作的耗时较长(一次网络往返往往在数百毫秒级别),这类任务的 CPU 利用率也不是太高。
- Web 服务器的 HTTP 请求处理操作为此类任务的典型例子
确定任务线程数
-
IO 密集型任务:
- 由于 IO 密集型任务的CPU使用率较低,导致线程空余时间很多,因此通常需要开 CPU 核心数两倍的线程
- Netty 的 IO 处理任务就是典型的 IO 密集型任务,所以,Netty 的 Reactor 实现类(定制版的线程池)的 IO 处理线程数默认正好为 CPU 核数的两倍
-
CPU密集型任务:
- CPU 密集型的任务并行的任务越多,花在任务切换的时间就越多,CPU 执行任务的效率就越低,一般开等于 CPU 的核心数的线程数量
- 比如 4 个核心的 CPU,通过 4 个线程并行地执行 4 个 CPU 密集型任务,此时的效率是最高的。但是如果线程数远远超出 CPU 核心数量,就需要频繁地切换线程,线程上下文切换时需要消耗时间,反而会使得任务效率下降。
-
混合型任务:
-
业界有一个比较成熟的估算公式,具体如下:
-
最佳线程数 = ((线程等待时间 + 线程 CPU 时间) / 线程 CPU 时间) * CPU核数 -
通过公式可以看出:等待时间所占的比例越高,需要的线程就越多,CPU 耗时所占的比例越高,需要的线程就越少
-
比如在 Web 服务器处理 HTTP 请求时,假设平均线程 CPU 运行时间为 100 毫秒,而线程等待时间(比如包括 DB 操作、RPC 操作作、缓存操作等)为 900 毫秒,如果 CPU 核数为 8 那么根据上面这个公式,估算如下:
(900 毫秒+100 毫秒) / 100 毫秒 * 8 = 10 * 8 = 80,最好开 80 个线程
-
相关文章:
线程池原理(一)线程池核心概述
更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验 线程回顾 创建线程的方式 继承 Thread 类实现 Runnable 接口 创建后的线程有如下状态: NEW:新建的线程,无任何操作 public static void main(String[] args) {Thread…...

关于redisson的序列化配置
由于使用redisson来存储list,返回的数据格式总是不对 原因是配置的序列化格式不对 Bean(value "redissonDtClient") public RedissonClient redissonClient() {RedisConnectionProperties.RedisConfigEntity configEntity properties.getDt();log.inf…...

CentOS安装ax200驱动
如果内核低于5.1需要安装一下内核 详细移步:Centos7安装高版本内核 大致如下: rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm yum --enablerepoelrepo-ke…...

FFMPEG Mac版本编译
Mac下FFMPEG使用 There are a few ways to get FFmpeg on OS X. One is to build it yourself. Compiling on Mac OS X is as easy as any other *nix machine, there are just a few caveats(警告). The general procedure is get the source, then ./configure <flags&g…...

Reactive Programing与“响应式”
将Reactive Programing翻译为“响应式编程”,的确不好理解。什么是Reactive?Reactive被翻译为“反应”,其英文原意是“事物对变化信号的回应、反应”。我热了,空调自动开,这就是空调对我的Reaction,我和空调…...
Pinterest:从 Druid 到 StarRocks,实现 6 倍成本效益比提升
导读: 开源无国界,StarRocks 自开源以来,近3年的时间里已在全球数据技术领域崭露头角。我们欣喜地发现,越来越多的海外用户正在使用并积极推广着 StarRocks。为了促进知识共享,StarRocks中文社区将精选优秀文章与大家共…...
代码+视频,R语言VRPM绘制多种模型的彩色列线图
列线图,又称诺莫图(Nomogram),它是建立在回归分析的基础上,使用多个临床指标或者生物属性,然后采用带有分数高低的线段,从而达到设置的目的:基于多个变量的值预测一定的临床结局或者…...

Python 设计模式之工厂函数模式
文章目录 案例基本案例逐渐复杂的案例 问题回顾什么是工厂模式?为什么会用到工厂函数模式?工厂函数模式和抽象工厂模式有什么关系? 工厂函数模式是一种创建型设计模式,抛出问题: 什么是工厂函数模式?为什么…...
——开发:数据挖掘——概述、关注焦点)
数据赋能(171)——开发:数据挖掘——概述、关注焦点
概述 数据挖掘是从大量的数据中,提取隐藏在其中的、事先不知道的、但潜在有用的信息的过程。 数据挖掘是数据分析过程中的一个核心环节。 数据挖掘的主要目的是从大量数据中自动发现隐藏的模式、关联和趋势,以揭示数据的潜在价值。数据挖掘技术可以帮…...

L1 - OpenCompass 评测 InternLM-1.8B 实践
基础任务(完成此任务即完成闯关) 使用 OpenCompass 评测 internlm2-chat-1.8b 模型在 ceval 数据集上的性能,记录复现过程并截图。 按照教程中的顺序安装包有问题,网上找了解决方案,按一下顺序能正常执行 使用OpenCo…...
)
JS【详解】数据类型检测(含获取任意数据的数据类型的函数封装、typeof、检测是否为 null、检测是否为数组、检测是否为非数组/函数的对象)
【函数封装】获取任意数据的数据类型 /*** 获取任意数据的数据类型** param x 变量* returns 返回变量的类型名称(小写字母)*/ function getType(x) {// 获取目标数据的私有属性 [[Class]] 的值const originType Object.prototype.toString.call(x); //…...

OpenCV图像滤波(10)Laplacian函数的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 功能描述 计算图像的拉普拉斯值。 该函数通过使用 Sobel 运算符计算出的 x 和 y 的二阶导数之和来计算源图像的拉普拉斯值: dst Δ src ∂…...
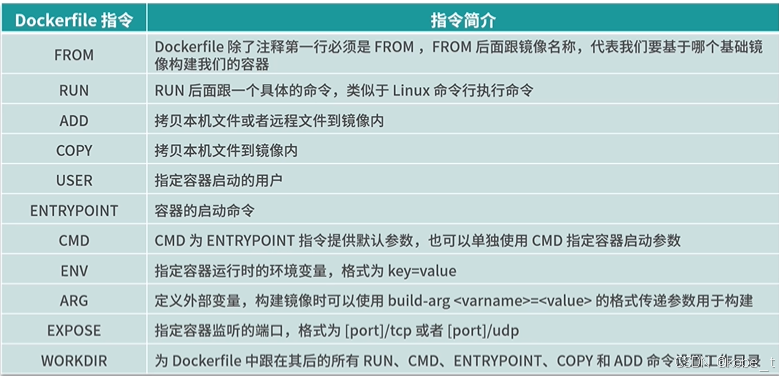
docker系列11:Dockerfile入门
传送门 docker系列1:docker安装 docker系列2:阿里云镜像加速器 docker系列3:docker镜像基本命令 docker系列4:docker容器基本命令 docker系列5:docker安装nginx docker系列6:docker安装redis docker系…...

LVS(Linux virual server)详解
目录 一、LVS(Linux virual server)是什么? 二、集群和分布式简介 2.1、集群Cluster 2.2、分布式 2.3、集群和分布式 三、LVS运行原理 3.1、LVS基本概念 3.2、LVS集群的类型 3.2.1 nat模式 3.2.2 DR模式 3.2.3、LVS工作模式总结 …...

Session共享方法
在Web开发中,会话(Session)管理是跟踪用户与服务器之间交互的一种常见方法。Session 共享通常指的是在一个应用集群或多个应用服务之间保持用户的会话状态一致。这在负载均衡、微服务架构或者分布式系统中尤为重要 一、基于SQL的session管理…...
Ubuntu 22.04 Docker安装笔记
1、准备一台虚机 可以根据《VMware Workstation安装Ubuntu 22.04笔记》来准备虚拟机。完成后,根据需求安装必要的软件,并设置root权限进行登录。 sudo apt update sudo apt install iputils-ping -y sudo apt install vim -y允许root ssh登录࿱…...

编程-设计模式 6:适配器模式
设计模式 6:适配器模式 定义与目的 定义:适配器模式将一个类的接口转换成客户希望的另一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。目的:该模式的主要目的是解决接口不匹配的问题,使得一个…...

ERC721 概念解释
目录 FeaturesVotesAccess ControlUpgradeabilityFeatures Mintable: 允许创建新的代币(minting)。合约的所有者或有权限的账户可以调用 mint 函数来生成新的代币,并将其分配给指定的地址。 Auto Increment Ids:自动递增 ID。每次创建新的代币时,代币的 ID 会自动递增,确保…...
--串)
数据结构(其五)--串
目录 12.串 12.1 基本操作 12.2 串的存储结构 12.3 字符串的模式匹配算法 (1).朴素模式匹配算法 (2).KMP算法 i.next[]数组的求解 ii.next[]数组的优化——nextval数组 iii.手算nextval数组 iiii.机算nextval数组 + KMP函数 12.串 串,即字符串(string),由零个或多…...

LeetCode Hot100 LRU缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -…...

AMLP:基于大语言模型的自动化机器学习势函数构建平台
1. 项目概述:当AI遇见原子模拟,AMLP如何重塑机器学习势函数构建在计算材料科学和化学物理领域,分子动力学模拟是我们窥探微观世界动态行为的“显微镜”。无论是研究新材料的相变过程,还是探索生物大分子的折叠机制,其核…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...