自己动手做chatGPT:向量的概念和相关操作
chatGPT的横空出世给人工智能注入一针强心剂,它是历史上以最短时间达到一亿用户的应用。chatGPT的能力相当惊人,它可以用相当流利的语言和人对话,同时能够对用户提出的问题给出相当顺畅的答案。它的出现已经给各个行业带来不小冲击,据说有很多公司已经使用chatGPT来替代人工,于是引起了不少裁员事件。
chatGPT是人类科技史上一个里程碑。它基于一种叫大语言模型的技术,使得计算机具备了相当于人乃至超越人的能力,chatGPT的发明者openAI据说在推进下一代模型的开发,据说已经能达到通用AI的程度,我对此表示怀疑。无论如何基于大模型技术的AI将人类带入一个新时期,我们必须有所准备,我们既不需要过分狂热,以为它又是一个暴富风口;也不能漠不关心,认为它完全与自己无关,如果你从事信息技术行业,你必须要特意留一手,如果它真的是进入新纪元的钥匙,那么我们不会被落下,如果只是一阵骚动,那么基于技多不压身的原则,咱花点心思多学一门技术也不亏。
我们这个系列着重于探究发明出chatGPT的技术,我们基于可用的算力和数据从零开始做一个“类”chatGPT,也就是我们做出来的模型不可能有chatGPT那么厉害,但是我们掌握和使用的原理跟它一样,只不过我们没有对应的资源训练它而已。同时chatGPT底层还有一种技术叫transformer,基于这个技术我们可以把chatGPT的开源模型拿过来,然后使用小样本数据就能将其训练成某个特定领域的AI专家,于是chatGPT就能为我所用。
这个系列分为两部分,首先是介绍NLP(自然语言处理)的基本原理和技术,然后我们看看如何使用开源的大语言模型进行特定的开发,由此打造出属于我们自己的chatGPT.首先需要声明的是,涉及到人工智能和深度学习,它具有一定的门槛,那就是你至少要比较熟练大学阶段的高数,你要了解微积分相关内容,熟悉向量,矩阵等线性代数概念,要不然很难在这个领域发展。
现在我们回到技术层面。人工智能要解决的主要是传统算法处理不了的问题,传统算法之所以对一些问题束手无措,主要是因为要处理的对象无法使用结构化的数据结构进行表达。例如给定一张人脸图片,我们如何使用传统数据结构来描述呢,是使用链表,二叉树,哈希表吗,显然不行。由于这个原因,传统算法处理不了这些范畴的问题。那么人工智能怎么用数据区描述例如人脸,单词都这些对象呢,方法是用向量,面对的对象性质越复杂,向量的长度就越大,例如人脸通常用长度为256或者更大的实数向量来表示。对NLP而言,它处理的对象是文本,因此它会使用向量来表示文本的基本单位,如果文本是英语,那么就用向量来表示单词,如果是中文,那么就用向量表示一个字。
我们看一个具体例子,假设我们有一段英语文本:
Times flies like an arrow
Fruit flies like a banana.
显然传统数据结构是无法表达上面的句子和单词,因此我们转向向量来表达。首先我们把所有单词转换为小写,然后将其排列起来,单词排列的先后顺序没有关系,于是有:
time fruit flies like a an arrow banana
接下来我们使用一种叫one-hot-vector的向量来表示单词,可以看到上面有8个不同的单词,因此向量包含8个元素,由于time排在第一个,于是我们把向量第一个元素设置为1,其他元素设置为0,因此time的向量表示就是[1,0,0,0,0,0,0], 同理fruit排在第2位,因此它对应的向量就是第二个元素为1,其他元素为0,于是其对应向量为[0,1,0,0,0,0,0,0],其他以此类推。这种对单词的向量描述方式在我们后面的深度学习算法中会发挥很大作用。对于一个句子而言,它的向量描述方式就是把单词对应的向量进行“或”操作,例如句子like a banana,组成它三个单词的向量是[0,0,0,1,0,0,0,0], [0,0,0,0,1,0,0,0],[0,0,0,0,0,0,0,1], 进行“或”操作后结果就是[0,0,0,1,1,0,0,1],我们用代码来实践看看:
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns corpus = ['Time flies flies like an arraw.', 'Friut flies like a banana']
one_hot_vectorizer = CountVectorizer(binary = True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
vocab = one_hot_vectorizer.get_feature_names_out()
sns.heatmap(one_hot, annot=True, cbar = False, xticklabels = vocab, yticklabels=['Sentence 1','Sentence 2'])
上面代码运行后结果如下:
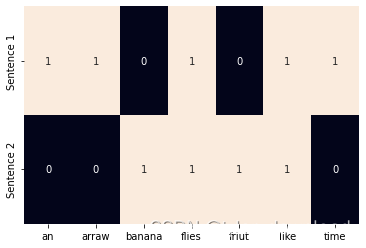
从上图我们能看到图形化的,两个句子对应的向量表示,如果给的单词在句子中出现了,他们向量对应位置设置为1,要不然就设置为0.one-hot-vector只是对单词或句子最基本的数学描述方式,事实上在不同的文本或应用场景下,单词或句子的向量绝对不会那么简单,他们依然需要以向量来表示,但是向量的长度和每个元素的取值都得靠深度学习算法来分析出来,具体情况在后面章节详细阐明。
下面我们看看深度学习的基本原理。有过微积分基础的同学会了解,对于一个连续函数f(x),如果在某一点求导所得结果为0:f’(x)=0,那么这个点就可能是在局部范围内的最大值或最小值。深度学习本质上就是通过微分求极小值的过程,只不过它对应的函数包含不止一个变量,例如chatGPT对应的模型就是一个包含1750亿个参数的函数,训练的目的就是找出这1750亿参数的合适取值,这样它才能根据输入的句子给出合适的回复,因此用于它训练的算力和数据无疑是及其巨大的,以下我们给出深度学习网络训练的基本流程:
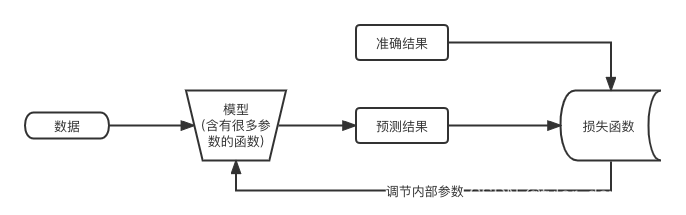
对深度学习基本原理不熟悉的同学可以参考《神经网络与深度学习实战》,或者我在云课堂上的课程:http://m.study.163.com/provider/7600199/index.htm?share=2&shareId=7600199
下面我们看运算图的概念。在上图中“模型”其实可以使用传统数据结构中的“图论”来表示。“含有很多个参数的函数”其实可以使用链表来表示,当算法对函数的参数进行求导时,这些运算就可以通过链表来完成,我们看一个具体例子,对于函数y = wx+b,我们可以用链表表示如下:
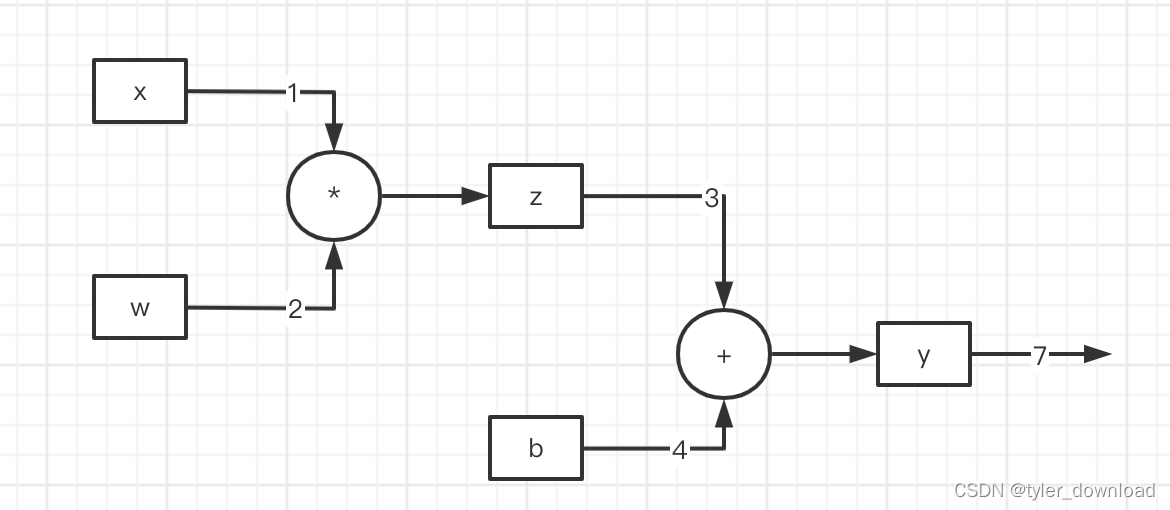
参数x, w, b, y使用矩形节点表示,运算符则使用圆形节点表示。箭头上的值表示对应参数的值,他们经过圆形节点后执行对应运算然后输出结果。前面我们提到过chatGPT的参数有1370亿个,那意味着其对应的运算图将非常庞大和复杂,因此我们通常使用特定框架来完成运算图的构建以及执行基于其的运算,常用的框架有tensorflow, pytorch还有百度的飞桨,目前用的比较多的还是meta的pytorch框架。
在具体的深度学习应用中,参数节点往往不会像上面那么简单,他们通常是高维度向量,我们上面显示的是0维度的向量,也就是他们是单个参数,在实际应用中x,b通常是一维向量,w是二维向量也就是矩阵。如果我们要处理的输入是图片,那么x可能就是二维向量,如果处理的是视频,那么可能就是三维向量,因为视频是具有时间维度的图片,对于NLP而言,也就是自然语言处理而言,输入的x通常是一维或者二维向量.接下来我们看看如何在基于pytorch框架的基础上实现向量的各自运算。
我们所有代码将运行在谷歌的colab开发环境,这个环境好在于集成了pytorch框架,同时还能让我们免费使用gpu加快运算效率。首先我们用一段代码展示如何使用pytorch创建各种维度的向量:
import torch
def describeTensor(tensor):#输出向量的维度,类型,以及元素值print(f"Type: {tensor.type()}")print(f"shape/size: {tensor.shape}")print(f"values: {tensor}")describeTensor(torch.Tensor(2,3)) #创建二维向量,也就是2*3矩阵
上面代码执行后输出如下:
Type: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[-7.9076e-20, 4.5766e-41, -7.7950e-20],[ 4.5766e-41, -7.7948e-20, 4.5766e-41]])
这里需要注意的是,向量中每个元素的值是随意初始化的,一般情况下向量初始值是什么不重要。在深度学习中,我们往往需要对输入数据进行正规化处理,也就是把向量元素进行加工,使得他们加总的值为1,我们看个例子:
#对向量进行正规化处理,也就是向量元素加起来等于1
describeTensor(torch.randn(2,3))
上面代码运行后结果如下:
ype: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[ 0.5474, 0.7511, 0.7454],[ 0.7795, -1.8067, 0.4035]])
不难看到,上面输出的每个向量,它对应元素加起来值正好等于1.0.在某些情况下,我们创建向量后,希望初始化向量中每个分量的值,因此我们可以如下操作:
#把向量每个元素初始化为0
describeTensor(torch.zeros(2,3))
#把每个元素初始化为1
x = torch.ones(2,3)
#把每个元素设置为5,下划线表示函数对应的操作会直接作用在给定的向量上
x.fill_(5)
describeTensor(x)
上面代码执行后结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[0., 0., 0.],[0., 0., 0.]])
Type: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[5., 5., 5.],[5., 5., 5.]])
在python的数值应用中,numpy是必不可少的函数库,因此我们能把numpy对应的列表直接转换成向量,例如下面的方式
import numpy as np
npy = np.random.rand(2,3)
#直接从numpy向量转换为pytorch向量
describeTensor(torch.from_numpy(npy))
上面代码运行后输出结果如下:
Type: torch.DoubleTensor
shape/size: torch.Size([2, 3])
values: tensor([[0.2552, 0.2467, 0.9570],[0.3357, 0.8942, 0.2779]], dtype=torch.float64)
注意看,这里向量的类型变成了double而不是float。另外我们还可以将运算作用在向量上,例如把向量的行相加得到一个一维向量,例如下面代码:
x = torch.Tensor([[1, 2, 3], [4, 5, 6]])
#将向量按照行相加,
y = torch.sum(x, dim = 0)
describeTensor(y)
#将向量按照列相加,这个稍微有点抽象,它的做法是想取出一行,然后将所有元素加总,然后取出第二行,将所有元素加总
#第一行的元素为[1,2,3]加总后就是1+2+3 = 6, 第二行是【4,5,6】加总后就是4+5+6=15,结果就是一个包含两个元素的1维向量[6,15]
z = torch.sum(x, dim = 1)
describeTensor(z)
上面代码运行后结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([3])
values: tensor([5., 7., 9.])
Type: torch.FloatTensor
shape/size: torch.Size([2])
values: tensor([ 6., 15.])
针对向量的运算,比较令人混乱的是对向量进行转换,这些操作统称为indexing, slicing, 和joining,我们看几个具体例子:
x = torch.Tensor([[0, 1, 2], [3,4,5]])
'''
:1是针对行进行选取,:1表示选取所有下标不超过1的行,由于向量只有两行,因此只有第0行满足条件,于是:1的作用是把第0行选取出来。
:2是针对列进行选取,它表示选取下标不超过2的列,由于前面我们已经选取了第0行,因此:2表示在第0行基础上选出下标不超过2的列,于是
操作结果就是[0,1]
'''
describeTensor(x[:1, :2])
上面代码运行后结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([1, 2])
values: tensor([[0., 1.]])
我们再看看如何针对高维向量,选取它指定的列:
indices = torch.LongTensor([0, 2])
'''
dim = 1 ,表示操作将针对列进行,(行对应的dim为0),index指定将给定下标的列选取出来
由于indices对应的值为0,2,因此下面操作就是将第0列和第2列选取出来,于是结果就是[[0,2],[3,5]]
由于indices对应的数值必须是整形,因此我们设置向量的类型为long,也就是每个分量的类型是int64
'''
describeTensor(torch.index_select(x, dim = 1, index = indices))
上面代码运行后结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([2, 2])
values: tensor([[0., 2.],[3., 5.]])
我们再看一个更令人困惑的操作:
indices = torch.LongTensor([0, 0])
'''
本次操作作用于向量的行,也就是dim = 0,我们要把下标为indices的行选取出来,由于
indices对应的参数为两个0,因此下面操作把第0行选取两次,于是形成结构就是[[0,1,2],[0,1,2]]
'''
describeTensor(torch.index_select(x, dim = 0, index = indices))
上面操作运行后结果如下;
Type: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[0., 1., 2.],[0., 1., 2.]])
我们还能同时选取向量的行和列,例如:
x = torch.Tensor([[0, 1, 2], [3,4,5]])
#用于设置下标的向量必须是整形,而向量默认是浮点型,因此如果向量用于存储下标,那么需要明确生成long型的向量
row_indecies = torch.LongTensor([0,1])
col_indecies = torch.LongTensor([0, 1])
'''
先选取第0,1两行,然后选取第0行的第0列,接着选取第1行的第1列,所得结果就是[0,4]
'''
describeTensor(x[row_indecies, col_indecies])
上面代码运行后所得结果为:
Type: torch.FloatTensor
shape/size: torch.Size([2])
values: tensor([0., 4.])
不同向量之间还能进行组合,合并等操作,这些操作也很容易让人头疼和困惑,我们看几个例子:
x = torch.Tensor([[1,2,3], [4,5,6]])
y = torch.Tensor([[7,8,9], [10, 11, 12]])
'''
将x,y在行的维度上叠加,这个操作要求两个向量要有相同数量的列
'''
z = torch.cat([x, y], dim = 0)
describeTensor(z)
上面代码运行后所得结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([4, 3])
values: tensor([[ 1., 2., 3.],[ 4., 5., 6.],[ 7., 8., 9.],[10., 11., 12.]])
同样我们可以将两个向量的列进行叠加:
x = torch.Tensor([[1,2,3], [4,5,6]])
y = torch.Tensor([[7,8,9], [10, 11, 12]])
'''
将两个向量在列的维度进行叠加,也就是把两个向量的第一行合成一行[1,2,3]+[7,8,9]->[1,2,3,7,8,9],
然后把两个向量的第二行合成一行[4,5,6]+[10,11,12]->[4,5,6,10,11,12],
老实说我对这个操作也感觉困惑
'''
z = torch.cat([x, y], dim = 1)
describeTensor(z)
上面代码运行结果为:
Type: torch.FloatTensor
shape/size: torch.Size([2, 6])
values: tensor([[ 1., 2., 3., 7., 8., 9.],[ 4., 5., 6., 10., 11., 12.]])
我们还能将多个向量作为新向量的分量,例如:
x = torch.Tensor([[1,2,3], [4,5,6]])
y = torch.Tensor([[7,8,9], [10, 11, 12]])
'''
把两个向量叠起来,也就是把两个向量分别作为新向量的分量,由于现在向量维度是2行3列,
因此把这两个向量作为新向量的分量时,新向量就会有2个分量,同时每个分量的维度就是2行3列,
于是新向量的维度就是[2, 2, 3]
'''
z = torch.stack([x,y])
describeTensor(z)
上面操作结果为:
Type: torch.FloatTensor
shape/size: torch.Size([2, 2, 3])
values: tensor([[[ 1., 2., 3.],[ 4., 5., 6.]],[[ 7., 8., 9.],[10., 11., 12.]]])
我们还能对向量进行运算,例如让某一行或某一列乘以一个值,例如:
#初始化三行两列的矩阵,并让每个分量取值1
x = torch.ones(3,2)
'''
x[:, 1]表示选取向量所有行,同时选取行中下标为1的元素,让这些元素加上数值1
'''
x[:, 1] += 1
describeTensor(x)
上面代码运行后结果为:
Type: torch.FloatTensor
shape/size: torch.Size([3, 2])
values: tensor([[1., 2.],[1., 2.],[1., 2.]])
对应高维向量,我们还能把他们当做矩阵来相乘
x = torch.Tensor([[1,2], [3,4]])
y = torch.Tensor([[5,6], [7,8]])
#将两个向量执行矩阵乘法,第一个元素是第一个向量的第一行乘以第二个向量的第一列,也就是[1,2] X [5,7] = 1*5 + 2*7 = 19,以此类推
z = torch.mm(x, y)
describeTensor(z)
上面代码执行后所得结果我:
Type: torch.FloatTensor
shape/size: torch.Size([2, 2])
values: tensor([[19., 22.],[43., 50.]])
下一节我们看看自然语言处理的深度学习算法中,我们需要涉及的一些概念和流程,更多信息请在b站搜索coding迪斯尼。
相关文章:
自己动手做chatGPT:向量的概念和相关操作
chatGPT的横空出世给人工智能注入一针强心剂,它是历史上以最短时间达到一亿用户的应用。chatGPT的能力相当惊人,它可以用相当流利的语言和人对话,同时能够对用户提出的问题给出相当顺畅的答案。它的出现已经给各个行业带来不小冲击࿰…...
【洛谷刷题】蓝桥杯专题突破-深度优先搜索-dfs(7)
目录 写在前面: 题目:P1596 [USACO10OCT]Lake Counting S - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述: 输入格式: 输出格式: 输入样例: 输出样例: 解题思路: …...

Python嵌套函数(Nested function)和闭包(closure)
Python嵌套函数(Nested function)和闭包(closure) 闭包(closure)是建立在嵌套函数基础上的,是一种特殊的嵌套函数结构。 先看嵌套函数(Nested function)。 Python允许…...
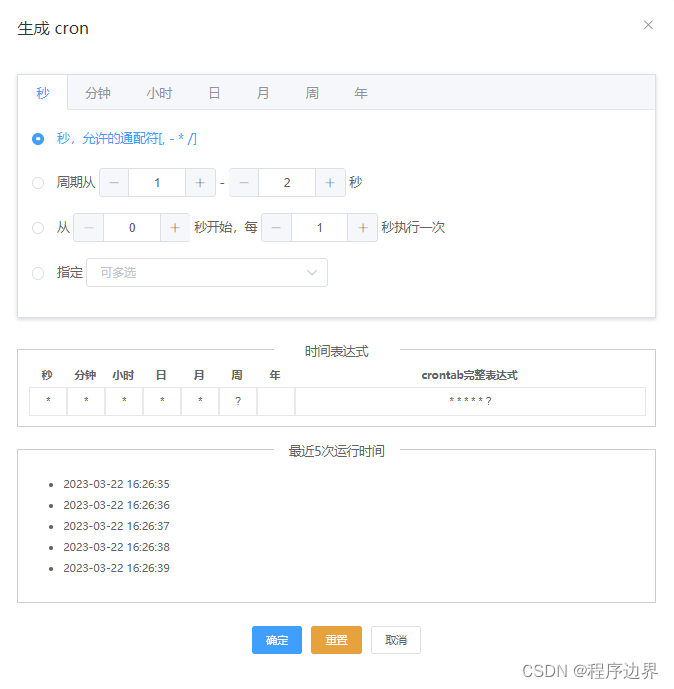
【实战】React 必会第三方插件 —— Cron 表达式生成器(qnn-react-cron)
文章目录一、引子二、配置使用1.安装2.使用(1)直接调用(2)赋值到表单(Form)(3)自定义功能按钮(4)隐藏指定 Tab(5)其他三、常见问题及解…...

C# 教你如何终止Task线程
我们在多线程中通常使用一个bool IsExit类似的代码来控制是否线程的运行与终止,其实使用CancellationTokenSource来进行控制更为好用,下面我们将介绍CancellationTokenSource相关用法。C# 使用 CancellationTokenSource 终止线程使用CancellationTokenSo…...
整合SpringCache
整合SpringCache 1、引入依赖cache还有redis <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId> </dependency>2、写配置 spring:cache:type: redis3、测试使用缓存 Cache…...
05 - 环境变量编程
---- 整理自狄泰软件唐佐林老师课程 查看所有文章链接:(更新中)Linux系统编程训练营 - 目录 文章目录1. 初识环境变量1.1 问题1.2 main函数(默认进程入口)1.3 什么是环境变量?1.4 环境表的构成1.5 思考2. 深…...

vue3后台管理系统
后面可参考下:vue系列(三)——手把手教你搭建一个vue3管理后台基础模板 以下代码项目gitee地址 文章目录1. 初始化前端项目初始化项目添加加载效果配置 vite.config.js2. 使用路由安装路由配置路由配置别名和跳转安装pathvite.config.jsjsco…...

掷骰子式的乐趣:探究C语言生成随机数的奥秘
掷骰子式的乐趣:探究C语言生成随机数的奥秘一、引言二、C标准库的rand函数三、srand函数的使用四、基于时间的种子生成五、高质量随机数的应用一、引言 C语言中生成随机数是一项非常重要的功能,因为许多现代应用程序需要使用随机数。随机数可以用于密码…...

一线大厂软件测试常见面试题1500问,背完直接拿捏面试官,
三、测试理论 3.1 你们原来项目的测试流程是怎么样的? 我们的测试流程主要有三个阶段:需求了解分析、测试准备、测试执行。 1、需求了解分析阶段 我们的SE会把需求文档给我们自己先去了解一到两天这样,之后我们会有一个需求澄清会议, 我…...

小迪安全day12WEB漏洞-SQL注入之简要SQL注入
小迪安全day12WEB漏洞-SQL注入之简要SQL注入 注入产生原理详细分析 可控变量带入数据库查询变量未存在过滤或过滤不严谨 连接符区分 and是sql语句连接符,&是uel参数连接符 and 11是注入语句, &是添加一个新变量 数据库内容 数据库A 网站…...

自动化测试学习(七)-正则表达式,你真的会用吗?
目录 一、正则表达式在python中如何使用 二、用正则表达式匹配更多模式 三、常用字符分类的缩写代码 总结 所谓正则表达式(regex),就是一种模式匹配,学会用正则匹配,就可以达到事半功倍的效果。 一、正则表达式在…...

验证码——vue中后端返回的图片流如何显示
目录 前言 一、p调用接口获取验证码 canvas画布渲染? 二、后端返回图片(图片流),前端显示 1.blob 2.arraybuffer 总结 前言 登录界面经常会有验证码,验证码的实现方式也有很多,我目前做过以下两种&…...

聚观早报 | 拼多多驳斥Google的指控;80%美国人工作将被AI影响
今日要闻:拼多多驳斥Google“恶意软件”的指控;80%美国人工作将被AI影响;iPhone 15 Pro设计图上热搜;贾扬清离职阿里投身AI大模型创业;OPPO Find X6 系列发布拼多多驳斥Google“恶意软件”的指控 3 月 21 日࿰…...

define,typedef,inline 的区别
define 1.用于在代码中创建宏定义,将一个标识符替换为一个表达式或语句。例如: #define PI 3.14159 #define SQUARE(x) ((x) * (x))这样,程序中所有出现的 PI 都将被替换为 3.14159,SQUARE(x) 则被替换成了 (x) * (x)。 使用 #…...
百度文心一言正式亮相
OpenAI 刚发布了 GPT-4,百度预热已久的人工智能生成式对话产品也终于亮相了。昨天下午,文心一言 (ERNIE Bot)—— 百度全新一代知识增强大语言模型、文心大模型家族的新成员,正式在百度总部 “挥手点江山” 会议室里发布。 发布会一开场&…...
使用Android架构模板
使用Android架构模板 项目介绍 为了方便开发者引入最新的Android架构组建进行开发,Google官方给我们引入了一个架构模板,方便我们快速进入开发。 github地址: https://github.com/android/architecture-templates 该模板遵循官方架构指南 …...
2023年天津市逆向re2.exe解析-比较难(超详细)
2023年天津市逆向re2.exe解析(较难) 1.拖进IDA里进行分析2.动态调试3.编写EXP脚本获取FLAG4.获得FLAG1.拖进IDA里进行分析 进入主程序查看伪代码 发现一个循环,根据行为初步判定为遍历输入的字符并对其ascii^7进行加密 初步判断sub_1400ab4ec为比较输入和flag的函数 跟进u…...

springboot: mybatis动态拼接sql查询条件
目录 需求01: 根据不同类型 查询不同的订单名, 1. 书写订单 类型转换方法 2. 使用方式: 3.. 构建条件构造器并进行查询, 传递查询参数 4. Mapper 写法 5. 最核心位置 xml位置 6. sql执行效果: 需求01: 根据不同类型 查询不同的订单名, 条件也是不同的, 需要复用sql…...

最优化算法 - 动态规划算法
动态规划算法简介 动态规划(Dynamic programming)是一种在数学、管理科学、计算机科学、经济学和生物信息学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。 动态规划常常适用于有重叠子问题和最优子结构性质的问题…...

Halcon机器视觉实战:表面划痕检测的优化策略与形态学处理
1. 表面划痕检测的工业挑战与Halcon优势 在工业质检领域,表面划痕检测一直是让工程师头疼的难题。想象一下汽车发动机缸体上的发丝状划痕,或是手机玻璃盖板上若隐若现的加工痕迹——这些缺陷往往与背景对比度差异不足5%,人眼盯着看十分钟都可…...

工业质检项目从零开始:如何用‘主动学习’策略,把标注成本降低70%以上?
工业质检降本实战:用主动学习策略实现70%标注成本压缩 当某汽车零部件制造商首次将5000张未标注的焊接缺陷图片交到我们团队时,质检主管提出了两个灵魂拷问:"这批数据标注预算只有行业平均水平的30%,能不能做?&q…...

失真度测量仪校准 失真度测量仪校准检定装置应用方案 失真度仪校准器 失真度仪检定装置
在电子测量、计量检定、设备运维及科研生产等领域,失真度仪是检测信号纯净度的核心仪器,其测量精度直接决定产品质量管控、设备运维可靠性及科研数据准确性。但实际应用中,传统校准设备普遍存在精度不足、操作繁琐、场景适配性差、数据管理不…...

3个步骤精通华硕笔记本性能调优:G-Helper完全指南
3个步骤精通华硕笔记本性能调优:G-Helper完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址: h…...

QtScrcpy完全指南:从多设备控制到游戏键位映射的全方位应用
QtScrcpy完全指南:从多设备控制到游戏键位映射的全方位应用 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtSc…...

中国象棋AlphaZero:零基础构建超越人类棋力的AI对战系统
中国象棋AlphaZero:零基础构建超越人类棋力的AI对战系统 【免费下载链接】ChineseChess-AlphaZero Implement AlphaZero/AlphaGo Zero methods on Chinese chess. 项目地址: https://gitcode.com/gh_mirrors/ch/ChineseChess-AlphaZero 中国象棋AlphaZero是一…...

从合合技术揭秘到自建数据集:手把手训练你的文档矫正模型
从合合技术揭秘到自建数据集:手把手训练你的文档矫正模型 在数字化办公场景中,文档图像矫正技术正成为提升OCR识别精度的关键环节。当开发者面对弯曲、折叠或透视变形的文档时,传统参数化方法往往难以应对复杂形变,而基于深度学习…...

RAG系统意图识别模块设计与实现思路
前言在RAG(检索增强生成)系统的实际应用中,我们经常会遇到一个问题:所有用户问题都走相同的检索-生成流程。这会导致闲聊问题浪费检索资源、分析型问题检索不足、操作型问题无法正确处理等一系列问题。本文将介绍如何在RAG系统中加…...

GME多模态向量-Qwen2-VL-2B实操手册:日志监控、错误追踪与WebUI响应延迟分析
GME多模态向量-Qwen2-VL-2B实操手册:日志监控、错误追踪与WebUI响应延迟分析 你是不是也遇到过这种情况:部署了一个看起来很酷的AI模型服务,用起来效果不错,但一旦出问题就两眼一抹黑?日志在哪看?为什么响…...

痕迹的痕迹:从朱君鸿论牟宗三与林安梧看学术争论的自感根源
痕迹的痕迹:从朱君鸿论牟宗三与林安梧看学术争论的自感根源 岐金兰 --- 摘要 朱君鸿的文章《从“横摄系统”到“横摄归纵”》是对牟宗三与林安梧不同朱子观的比较研究。从AI元人文的视角看,这篇文章本身是一层“痕迹”——它是对牟宗三、林安梧痕迹的再痕…...