二叉树相关的算法题
二叉树相关的算法题
单值二叉树
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
只有给定的树是单值二叉树时,才返回 true;否则返回 false。
示例 1:

输入:[1,1,1,1,1,null,1]
输出:true
示例 2:

输入:[2,2,2,5,2]
输出:false
提示:
- 给定树的节点数范围是
[1, 100]。 - 每个节点的值都是整数,范围为
[0, 99]。
思路如下:

代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/typedef struct TreeNode TreeNode;
bool isUnivalTree(struct TreeNode* root) {//根节点为空if(root==NULL){return true;}//根节点不为空if(root->left&&root->left->val!=root->val){return false;}if(root->right&&root->right->val!=root->val){return false;}return isUnivalTree(root->left)&&isUnivalTree(root->right);
}
相同的树
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1:

输入:p = [1,2,3], q = [1,2,3]
输出:true
示例 2:

输入:p = [1,2], q = [1,null,2]
输出:false
示例 3:

代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
bool isSameTree(struct TreeNode* p, struct TreeNode* q) {//该树为空if(p==NULL&&q==NULL){return true;}//其中一个为空if(p==NULL||q==NULL){return false;}//值不同if(p->val!=q->val){return false;}return isSameTree(p->left,q->left)&&isSameTree(p->right,q->right);
}
对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:

输入:root = [1,2,2,3,4,4,3]
输出:true
示例 2:

输入:root = [1,2,2,null,3,null,3]
输出:false
提示:
- 树中节点数目在范围
[1, 1000]内 -100 <= Node.val <= 100
这道题是基于上一题相同的树来完成的。
代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/bool isSameTree(struct TreeNode*p,struct TreeNode*q){if(p==NULL&&q==NULL){return true;}if(p==NULL||q==NULL){return false;}if(p->val!=q->val){return false;}return isSameTree(p->left,q->right)&&isSameTree(p->right,q->left);//不同点在于这里两个树的结构进行比较,不是说树的内部进行比较}
bool isSymmetric(struct TreeNode* root) {return isSameTree(root->left,root->right);
}
另一个树的子树
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
示例 1:

输入:root = [3,4,5,1,2], subRoot = [4,1,2]
输出:true
示例 2:

输入:root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2]
输出:false
提示:
root树上的节点数量范围是[1, 2000]subRoot树上的节点数量范围是[1, 1000]-104 <= root.val <= 104-104 <= subRoot.val <= 104
代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/bool isSameTree(struct TreeNode*p,struct TreeNode*q)
{if(p==NULL&&q==NULL){return true;}if(p==NULL||q==NULL){return false;}if(p->val!=q->val){return false;}return isSameTree(p->left,q->left)&&isSameTree(p->right,q->right);
}
bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot){if(root==NULL){return false;}if(isSameTree(root,subRoot)){return true;}return isSubtree(root->left,subRoot)||isSubtree(root->right,subRoot);
}
这几道题我们可以发现重要的规律,都要用到相同的二叉树里面的代码,这里有所不同的地方在于让根节点的左右子树分别和subRoot进行比较。
二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:

输入:root = [1,null,2,3]
输出:[1,2,3]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
示例 4:

输入:root = [1,2]
输出:[1,2]
示例 5:

输入:root = [1,null,2]
输出:[1,2]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
/*** Note: The returned array must be malloced, assume caller calls free().*/typedef struct TreeNode TreeNode;int TreeSize(TreeNode*root){if(root==NULL){return 0;}return 1+TreeSize(root->left)+TreeSize(root->right);}
//前序遍历:根左右void _preorderTraversal(TreeNode*root,int*arr,int*pi){if(root==NULL){return;}//为什么这里不是传值,而是要传地址呢,因为传值是放到另一块空间,并没有改变本身,也就意味着,从始至终都是从0开始//形参要想改变实参就要传址调用arr[(*pi)++]=root->val;_preorderTraversal(root->left,arr,pi);_preorderTraversal(root->right,arr,pi);}
int* preorderTraversal(struct TreeNode* root, int* returnSize) {//求节点个数*returnSize=TreeSize(root);//计算数组大小int*returnArr=(int*)malloc(sizeof(int)*(*returnSize));int i=0;_preorderTraversal(root,returnArr,&i);return returnArr;
}
二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:

输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
/*** Note: The returned array must be malloced, assume caller calls free().*/typedef struct TreeNode TreeNode;int TreeSize(TreeNode*root){if(root==NULL){return 0;}return 1+TreeSize(root->left)+TreeSize(root->right);}void _inorderTraversal(struct TreeNode*root,int*arr,int*pi){if(root==NULL){return;}_inorderTraversal(root->left,arr,pi);arr[(*pi)++]=root->val;_inorderTraversal(root->right,arr,pi);}
int* inorderTraversal(struct TreeNode* root, int* returnSize) {*returnSize=TreeSize(root);int* returnArr=(int*)malloc(sizeof(int)*(*returnSize));int i=0;_inorderTraversal(root,returnArr,&i);return returnArr;
}
二叉树的后序遍历
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[3,2,1]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
提示:
- 树中节点的数目在范围
[0, 100]内 -100 <= Node.val <= 100
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
/*** Note: The returned array must be malloced, assume caller calls free().*/typedef struct TreeNode TreeNode;int TreeSize(TreeNode*root){if(root==NULL){return 0;}return 1+TreeSize(root->left)+TreeSize(root->right);}
void _postorderTraversal(struct TreeNode*root,int*arr,int*pi)
{if(root==NULL){return;}_postorderTraversal(root->left,arr,pi);_postorderTraversal(root->right,arr,pi);arr[(*pi)++]=root->val;
}
int* postorderTraversal(struct TreeNode* root, int* returnSize) {*returnSize=TreeSize(root);int*returnArr=(int*)malloc(sizeof(int)*(*returnSize));int i=0;_postorderTraversal(root,returnArr,&i);return returnArr;
}
这三道题我们可以感受到只要掌握了怎样遍历二叉树就会变得简单许多
二叉树遍历
描述
编一个程序,读入用户输入的一串先序遍历字符串,根据此字符串建立一个二叉树(以指针方式存储)。 例如如下的先序遍历字符串: ABC##DE#G##F### 其中“#”表示的是空格,空格字符代表空树。建立起此二叉树以后,再对二叉树进行中序遍历,输出遍历结果。
输入描述:
输入包括1行字符串,长度不超过100。
输出描述:
可能有多组测试数据,对于每组数据, 输出将输入字符串建立二叉树后中序遍历的序列,每个字符后面都有一个空格。 每个输出结果占一行。
示例1
abc##de#g##f###
c b e g d f a 思路如下:

代码如下:
include <stdio.h>
#include <stdlib.h>
typedef struct BinaryTreeNode
{char data;struct BinaryTreeNode*left;struct BinaryTreeNode*right;
}BTNode;
BTNode* BuyNode(char x)
{BTNode*newnode=(BTNode*)malloc(sizeof(BTNode));newnode->data=x;newnode->left=newnode->right=NULL;return newnode;
}
BTNode*CreateNode(char*arr,int*pi)
{if(arr[*pi]=='#'){(*pi)++;return NULL;}BTNode*root=BuyNode(arr[(*pi)++]);root->left=CreateNode(arr, pi);root->right=CreateNode(arr, pi);return root;
}void Inorder(BTNode*root)
{if(root==NULL){return;}Inorder(root->left);printf("%c ",root->data);Inorder(root->right);
}
int main() {char arr[100];scanf(" %s ",arr);int i=0;BTNode*root=CreateNode(arr,&i);Inorder(root);return 0;
}
相关文章:
二叉树相关的算法题
二叉树相关的算法题 单值二叉树 如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。 只有给定的树是单值二叉树时,才返回 true;否则返回 false。 示例 1: 输入:[1,1,1,1,1,null,1] 输出:t…...

Unity URP 曲面细分学习笔记
学百人时遇到了曲面着色器的内容,有点糊里糊涂,于是上知乎找到了两篇大佬的文章 Unity URP 曲面细分 和 Unity曲面细分笔记,本文只是自己做学习记录使用 1.曲面细分与镶嵌 曲面细分或细分曲面(Subdivision surface)是…...

每天五分钟深度学习pytorch:训练神经网络模型的基本步骤
本文重点 本文个人认为是本专栏最重要的章节内容之一,前面我们学习了pytorch中的基本数据tensor,后面我们就将学学习深度学习模型的内容了,在学习之前,我们先来看一下我们使用pytorch框架训练神经网络模型的基本步骤,然后我们下面就将这些步骤分解开来,详细学习。 代码…...

【langchain学习】使用缓存优化langchain中的LLM调用性能:内存、SQLite与Redis的对比
在处理语言模型(LLM)调用时,特别是在需要多次执行相同请求的情况下,缓存机制能够显著提升系统的性能。本文通过对比内存缓存(InMemoryCache)、SQLite缓存(SQLiteCache)和Redis缓存(RedisCache),探讨了如何在Langchain中使用这些缓存机制来优化LLM调用的性能。 代码…...

spring boot 集成EasyExcel
EasyExcel 是一个基于 Java 的快速、简洁的 Excel 处理工具,它能够在不用考虑性能和内存等因素的情况下,快速完成 Excel 的读写功能。 首先,需要在 Spring Boot 项目中引入 EasyExcel 依赖。在 pom.xml 文件中添加以下依赖: <d…...

获取对象中第一个存在的值
在JavaScript中,要从一个对象中获取第一个存在的(非undefined、非null、非空数组等)值,你可以使用Object.values()方法结合Array.prototype.find()方法。以下是一个示例代码,演示如何实现这一点: const ob…...

Python学习笔记----集合与字典
1. 字符串、列表和元组的元素都是按下标顺序排列,可通过下 标直接访问,这样的数据类型统称为序列。 其中,字符串和元组中的元素不能修改,而列表中的元素可以修改。 集合 1. 与元组和列表类似,Set (集合&a…...

c# 排序、强转枚举
List<Tuple<double,int>> mm中doble从小到大排序 mm本身排序 在C#中,如果你有一个List<Tuple<double, int>>类型的集合mm,并且你想要根据Tuple中的double值(即第一个元素)从小到大进行排序,同…...

“华为杯”第十六届中国研究生数学建模竞赛-C题:视觉情报信息分析
目录 摘 要: 一、问题重述 二、模型假设 三、符号说明 四、问题一分析与求解 4.1 问题一分析 4.2 模型建立 4.2.1 位置变换模型建立 4.2.4 多平面转换模型建立 4.3 模型求解 4.3.1 问题一图 1 结果 4.3.2 问题一图 2 结果 4.3.3 问题一图 3 结果 4.3.4 问题一图 4 结果 4.4 模…...

html+css+js网页设计 找法网2个页面(带js)ui还原度百分之90
htmlcssjs网页设计 找法网2个页面(带js)ui还原度百分之90 网页作品代码简单,可使用任意HTML编辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及修改编辑…...
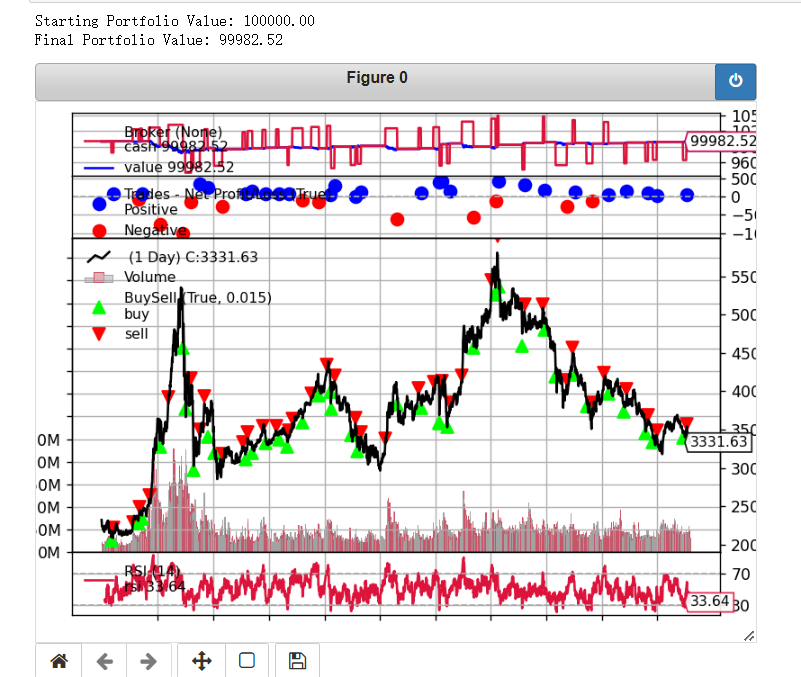
018 | backtrader回测反转策略
什么是反转策略? 反转策略(Reversal Strategy)是一种试图捕捉市场价格趋势逆转的交易策略。与趋势跟随策略不同,反转策略的核心理念是“物极必反”,即价格在经过一段时间的单边趋势后,往往会出现逆转的机会…...

《图解HTTP》全篇目录
前言 目前,国内讲解 HTTP 协议的书实在太少了。在我的印象中,讲解网络协议的书仅有两本。一本是《HTTP 权威指南》,但其厚度令人望而生畏;另一本是《TCP/IP 详解,卷 1》,内容艰涩难懂,学习难度…...
+Qt的软件开发—环境配置)
基于VS2019(Release_x64)+Qt的软件开发—环境配置
前置博客: 基于C高级编程语言的软件开发随记——环境变量-CSDN博客 (一)一种避免设置大量环境变量的VS2019环境配置方法 Ⅰ 解决方案资源管理器->VC目录->在包含目录/库目录中添加对应的include/lib文件夹($(So…...

【书生大模型实战营(暑假场)闯关材料】入门岛:第1关 Linux 基础知识
【书生大模型实战营(暑假场)闯关材料】入门岛:第1关 Linux 基础知识 1. 使用VScode进行SSH远程连接服务器2. 端口映射及实例参考文献 这一博客主要介绍使用VScode进行服务器远程连接及端口映射。 1. 使用VScode进行SSH远程连接服务器 安装V…...

240810-Gradio通过HTML组件打开本地文件+防止网页跳转到about:blank
A. 最终效果 B. 可通过鼠标点击打开文件,但会跳转到about:blank import gradio as gr import subprocessdef open_pptx():pptx_path /Users/liuguokai/Downloads/240528-工业大模型1.pptxtry:subprocess.Popen([open, pptx_path])return "PPTX file opened s…...

go在linux上安装
1.首先要确定Linux架构 uname -m如果你的系统是 armv7l(32-bit ARM),你需要下载 armv6l 版的Go语言。 如果你的系统是 aarch64(64-bit ARM),你需要下载 arm64 版的Go语言。 如果你的系统是 x86_64…...
)
算法日记day 35(动归之分割等和子集|最后一块石头的重量2)
一、分割等和子集 题目: 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。 示例 1: 输入:nums [1,5,11,5] 输出:true 解释:数组可以分…...
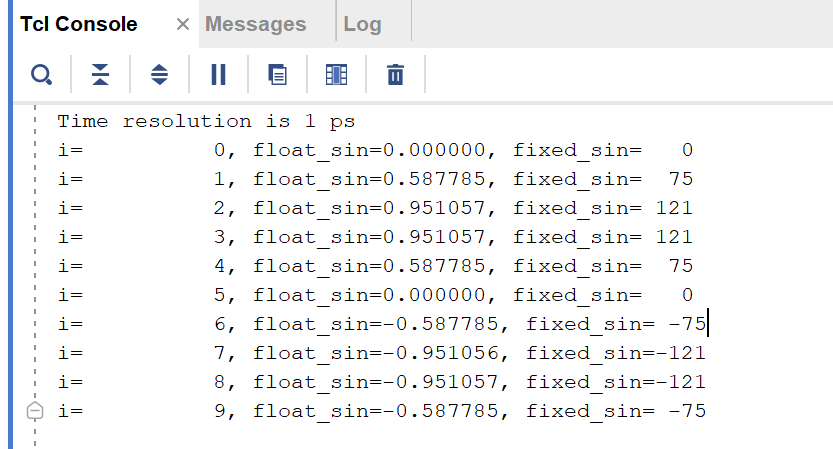
FPGA使用sv生成虚拟单音数据
FPGA使用sv生成虚拟单音数据 之前一直使用matlab生成虚拟的数据,导出到txt或是coe文件中,再导入到fpga中进行仿真测试。 复杂的数据这样操作自然是必要的,但是平日使用正弦数据进行测试的话,这样的操作不免复杂,今日…...

Linux shell编程:监控进程CPU使用率并使用 perf 抓取高CPU进程信息
0. 概要 本文将介绍一个用于监控一组进程CPU使用率的Shell脚本,,当检测到某进程的CPU使用率超出阈值时,使用 perf 工具抓取该进程的详细信息。 本shell脚本为了能在普通嵌入式系统上运行做了妥协和优化。 1. shell脚本流程的简要图示&#…...
)
Linux网络编程的套接字分析(其一,基本知识)
文章目录 套接字的类型流套接字数据报套接字原始套接字 套接字地址获取套接字地址 协议族和地址族 套接字的类型 Linux系统的套接字有三类:流套接字(SOCK_STREAM),数据报套接字(SOCK_DGRAM),原始套接字(SOCK_RAM)。 流套接字 用于面向连接…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

掌握Umi-OCR:5分钟上手开源免费离线文字识别工具
掌握Umi-OCR:5分钟上手开源免费离线文字识别工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...

基于ESP8266的可穿戴Wi-Fi设备:从硬件设计到ESPHome智能控制
1. 项目概述:一个可穿戴的Wi-Fi智能小玩意最近在捣鼓智能家居和可穿戴电子,总想把手边的小物件变得更“聪明”一点。于是,我设计并制作了一个基于ESP8266的可穿戴Wi-Fi设备。它的核心思路很简单:把一块功能强大的Wi-Fi微控制器&am…...