大数据-72 Kafka 高级特性 稳定性-事务 (概念多枯燥) 定义、概览、组、协调器、流程、中止、失败
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(正在更新…
章节内容
上节我们完成了如下内容:
- 磁盘存储
- 零拷贝
- 磁盘文件传输
- JavaNIO、mmap、sendfile

事务场景
- 如producer发的多条消息组成一个事务,这些消息需要对consumer同时可见又同时不可见。
- producer可能会给多个Topic,多个Partition发消息,这些消息也需要能放一个事务里面,这就形成了一个典型的分布式事务。
- Kafka的应用场景经常是应用先消费一个topic,然后做处理再发到另一个topic,这个consumer-transform-produce过程需要放到一个事务里面,必须在消息处理或者发送过程中失败了,消费偏移量也不能提交。
- producer或者producer所在的应用可能会挂掉,新的producer启动以后需要知道怎么处理之前未完成的事务。
- 在一个原子操作中,根据包含的操作类型,可以分为三种情况,前两种情况是事务引入的场景,最后一种没用。
这三种情况是:
- 只有Producer生产消息
- 消费消息和生产消息并存,这个是事务场景中最常用的情况,就是我们常说的consume-transform-produce模式
- 只有consumer消费消息,这种操作其实没有什么意义,跟使用手动提交一样,而且也不是事务属性引入的目的,所以一般不会使用这种情况。
关键概念和推导
- 因为producer发送消息可能是分布式事务,所以引入了常用的2PC,所以有事务协调者(Transaction Coordinator)。Transaction Coordinate和之前为了解决脑裂和惊群问题引入Group Coordinate在选举上类似。
- 事务管理上事务日志是必不可少的,Kafka使用一个内部的topic来保存事务日志,这个设计和之前使用内部topic保存偏移量的设计保持一致。事务日志是TransactionCoordinate管理的状态的持久化,因为不需要回溯事务的历史状态,所以事务日志只用保存最近的事务状态,_transaction_state
- 因为事务存在commit和abort两种操作,而客户端又read commit和read uncommited两种隔离级别,所以消息队列必须能标识事务状态,这个被称作Control Message。
- procuer挂掉重启或者漂移到其他机器需要能关联的之前的未完成的事务,所以需要有一个唯一标识符来进行关联,这个就是Transcational Id,一个producer挂了,另一个相同Transaction Id的producer能够接着处理这个事务未完成的状态。Kafka目前没有引入全局序,所以也没有transaction id,这个Transcation Id是用户提前配置的。
- TranscationId能关联producer,也需要避免两个使用相同Transaction Id的producer同时存在,所以引入了producer epoch来保证对应一个Transcation Id只有一个活跃的producer。
事务语义
多分区原子写入
事务能够保证KafkaTopic下每个分区的原子写入,事务中所有的消息都将被写入或者丢弃。
首先,我们来考虑一下子原子:读取-处理-写入周期是什么意思。简而言之,这意味着如果某个应用程序在某个Topic0的偏移量X处读取的消息A,并且在对消息A进行了一些处理(如B=F(A))之后将消息B写入Topic tp1,则只有当消息A和B被认为被成功的消费并一起发布,或者完全不发布时,整个读取过程写入操作时原子的。
现在,只有当消息A的偏移量X被标记为已消费,消息A才从topic tp0消费,消费到的数据偏移量(record offset)将被标记为提交偏移量(Committing offset)。在Kafka中,我们通过写入一个名为offset topic的内部KafkaTopic来记录offset commit。消息仅在其offset被提交给offsets topic时才被认为成功消费。
由于offset commit只是对KafkaTopic的另外一次,并且由于消息仅在提交偏移量时被视为成功消费,所以跨多个主题和分区的原子写入也启用原子 读取-处理-写入 循环:提交偏移量X到offset topic和消息B到tp1的写入将是单个事务的一部分,所以整个步骤都是原子的。
粉碎“僵尸案例”
我们通过每个事务Producer分配一个称为Transcation Id的唯一标识来解决僵尸实例的问题,在进程重新启动时能够识别相同的Producer实例。
API要求事务性Producer的第一个操作应该是在Kafka集群中显示注册的TranscationId,当注册的时候,KafkaBroker用给定的Transcational Id检查打开的事务并完成处理。
Kafka也增加了一个与Transcational Id相关的epoch,epoch存储每个id内部元数据。
一旦epoch被触发,任何具有相同的Transcation Id和旧的epoch的生产者视为僵尸,Kafka拒绝来自这些生产者的后续事务性写入。
简而言之:Kafka可以保证Consumer最终只能消费非事务性消息或已提交事务性消息,它将保留来自未完成事务的消息,并过滤已终止事务的消息。
事务消息定义
生产者可以显式的发起事务会话,在这些会话中发送(事务)消息,并提交或中止事务。有如下的要求:
- 原子性:消费者的应用程序不应暴露于未提交的消息中
- 持久性:Broker不能丢失任何已提交的事务
- 排序:事务消费者应在每个分区中以原始顺序查看事务消息
- 交织:每个分区都应该能够接受来自事务性生产者非事务生产者的消息
- 事务中不应该有重复的消息
如果允许事务性和非事务性消息的交织,则非事务和事务性消息的相对顺序将基于相加(对于非事务性消息)和最终提交(对于事务性消息)的相对顺序。

在上图中,分区P0和P1接收事务X1和X2的消息,以及非事务性消息。时间线是消息到达Broker的时间,由于首先提交了X2,所以每个分区都将在X1之前公开来自X2的消息,由于非事务性消息在X1和X2的提交之前到达,因此这些消息将在来自任一事务的消息之前公开。
事务配置
消费者
创建消费者代码,需要:
● 将配置中的自动提交属性(auto.commit)进行关闭
● 而且在代码里面也不能使用手动提交commitSync()或者commitAsync()
● 设置Isolation.level:READ_COMMITED或READ_UNCOMMITED
生产者
创建生产者,代码如下:
● 配置transacational.id属性
● 配置enable.idempotence属性
事务概览
生产者将表示事务开始、结束、中止状态的事务控制消息发送给使用多阶段协议管理事务的高可用事务协调器。生产者将事务控制记录(开始、结束、中止)发送到事务协调器,并将事务的消息直接发送到目标数据分区,消费者需要了解事务并缓冲每个待处理的事务,直到它们到达其相应的结束(提交、中止)记录为止。
- 事务组
- 事务组中的生产者
- 事务组的事务协调器
- Leader Brokers(事务数据所在的分区的Broker)
- 事务的消费者
事务组
事务组用于映射到特定的事务协调器(基于日志分区数字的哈希)。该组中的生产者需要配置为该组事务生产者,由于来自这些生产者的所有事务都通过此协调器进行,因此我们可以在这些事务生产者之间实现严格有序。
生产者ID和事务组状态
事务生产者需要两个参数:
- 生产者ID
- 生产组
需要将生产者的输入状态与上一个已提交的事务相关联,这使事务生产者能够重试事务(通过为该事务重新创建输入状态:在我们用例中通过是偏移量的向量)
可以使用消费者偏移管理机制来管理这些状态,消费者偏移量管理器将每个键(consumergroup-topic-partition)与该分区的最后一个检查点偏移量和元数据相关联。在事务生产者中,我们保存消费者的偏移量,该偏移量与事务的提交点关联。此偏移提交记录,(在__consumer_offsets主题中) 应作为事务的一部分写入。
即,存储消费组偏移量的(__consumer_offsets)主题分区将需要参与事务。因此,假定生产者在事务中间失败(事务协调器随后到期)。当生产者恢复时,它可以发出偏移量获取请求,以恢复与最后提交的事务相关联的输入偏移量,并从该点恢复事务处理。
为了支持此功能,我们需要对偏移量管理器和压缩的(__consumer_offsets)主题进行一些增强。
首先,压缩的主题现在还将包含事务控制记录,我们将需要为这些控制记录提出剔除策略。
其次,偏移量管理器需要具有事务意识,特别是,如果组与待处理的事务相关联,则偏移量提取请求应返回错误。
事务协调器
事务协调器 __transaction_state 主题特定分区的Leader分区所在的Broker,它负责初始化、提交以及回滚事务。事务协调器在内存管理如下的状态:
- 对应正在处理的事务的第一个消息的HW,事务协调器周期性的将HW写到ZK中。
- 事务控制日志中存储对应于日志HW的所有正在处理的事务
- 事务消息主题分区的列表:事务的超时时间、与事务关联的Producer ID
需要确保无论是什么样的保留策略(日志分区的删除还是压缩),都不能删除包含事务HW的日志分段。
事务流程
初始阶段
- Producer:计算哪个Broker作为事务协调器
- Producer:向事务协调器发送BeginTransaction(producerId,generation、partitions)请求,当然也可以发送另一个包含事务过期时间的,如果生产者需要将消费者状态作为事务的一部分提交事务,则需要在BeginTransaction中包含对应的 __consumer_offsets 主题分区的信息。
- Broker:生成事务ID
- Coordinator:向事务协调主题追加BEIGIN(TxId,ProducerId,Generattion、Partitions)消息,然后发送响应给生产者
- Producer:读取响应(包含了事务ID:TxId)
- Coordinator(and followers):在内存更新当前事务的待确认事务状态和数据分区信息
发送阶段
- Producer:发送事务消息给主题Leader分区所在的Broker
- 每个消息包含TxId和TxCtl字段
- TxCtl仅用于标记事务的最终状态(提交还是中止),生产者请求也封装了生产者ID,但不是不追加到日志中。
结束阶段
(生产者准备提交事务)
- Producer:发送OffsetCommitRequest请求提交与事务结束状态关联的输入法状态(如下一个事务输入从哪儿开始)
- Producer:发送CommitTranscation(TxId,ProducerId,Generation)请求给事务协调器并等待响应(如果响应中没有错误信息,表示将提交事务)。
- Coordinator:向事务控制主题追加PREPARE_COMMIT(TxId)请求并向生产者发送响应。
- Coordinator:向事务设计到的每个Leader分区(事务的业务数据的目标主题)的Broker发送一个CommitTranscation(TxId,Partitions…)请求。
- 事务业务数据的目标主题相关Leader分区Broker:(情况1:)如果不是__consumer_offsets主题的Learder分区,一收到CommitTransaction(TxId,Partition1,Partition2)请求就会向对应的分区Broker发送空(NULL)消息,并给该消息设置TxId和TxCtl(设置为COMMITED)字段,Leader分区的Broker给协调器发送响应。
- 事务业务数据的目标主题相关Leader分区Broker:(情况2:)如果是__consumer_offsets主题的Leader分区:追加消息,该消息的key是G-LAST-COMMIT,Value就是TxId的值,同时也应该给该消息设置TxId和TxCtl字段。
- Coordinator:向事务控制主题发送COMMITED(TxId)请求,__transaction_state
- Coordinator(and followers):尝试更新HW。
事务中止
当事务生产者发送业务消息的时候如果发生了异常,可以中止该事务,如果事务提交超时,事务协调器也会中止当前事务。
- Producer:向事务协调器发送AbortTransaction(TxId)请求并等待响应。(一个没有异常的响应表示事务将会中止)
- Coordinator:向事务控制主题追加PREPARE_ABORT(Txid)消息,然后向生产者发送响应。
- Coordinator:向事务业务数据的目标主题的每个涉及到的Leader分区Broker发送AbortTranscation(TxId,Partition)请求。
基本事务流程的失败
- 生产者发送BeginTranscation(TxId)的时候超时或响应中包含异常,生产者使用相同的TxId重试。
- 生产者发送数据时的Broker错误:生产者中止(然后重做)事务(使用新的TxId)。
- 如果生产者没有中止事务,则协调器将在事务超时后中止事务。仅在可能已将请求数据附加并复制到Follower的错误的情况下才需要重做事务。例如:生产者请求超时将需要重做,而NotLeaderForPartitionException不需要重做。
- 生产者发送CommitTranscation(TxId)请求超时或响应中包含异常,生产者使用相同的TxId重试事务,此时需要幂等性。
相关文章:
大数据-72 Kafka 高级特性 稳定性-事务 (概念多枯燥) 定义、概览、组、协调器、流程、中止、失败
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

MySQl 中对数据表的增删改查(基础)
MySQl 中对数据表的增删改查(基础) 新增演示插入一条数据插入多条数据 查询全列查询部分列查询查询关于列名的表达式查询时用别名查询去重后的结果查询排序后的结果条件查询比较运算符和逻辑运算符 分页查询 修改删除 黑白图是在命令行里的,彩…...

LVS知识点整理及实践
LVS知识点整理及实践 LVSlvs集群概念lvs概念lvs集群类型lvs-nat模型数据逻辑: lvs-DR模式数据传输和过程:特点: lvs-tun模式数据传输过程:特点: lvs-fullnet模式数据传输过程 lvs调度算法lvs调度算法类型lvs静态调度算法lvs动态调度算法4.15版本内核以后新增调度算法 ipvsadm命…...

Ubuntu gnome WhiteSur-gtk-theme类mac主题正确安装和卸载方式
目录 摘要目的安装和卸载特别说明 Ubuntu gnome WhiteSur-gtk-theme类mac主题正确安装和卸载方式 摘要 Ubuntu版本:ubuntu24.04 主题下载地址:https://github.com/vinceliuice/WhiteSur-gtk-theme 参考的安装教程:https://blog.51cto.com/u_…...

计算机毕业设计选题推荐-办公用品管理系统-Java/Python项目实战
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...

计算机毕业设计选题推荐-网上考试系统-Java/Python项目实战
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...

白骑士的Matlab教学基础篇 1.4 函数与脚本
系列目录 上一篇:白骑士的Matlab教学基础篇 1.3 控制流 函数和脚本是 MATLAB 编程中的基本组成部分,它们使得代码更加模块化、可重用和组织化。通过理解函数的定义与调用、参数与返回值,以及 MATLAB 脚本与批处理,可以显著提高编…...

Qt——多线程
一、QThread类 如果要设计多线程程序,一般是从QThread继承定义一个线程类,并重新定义QThread的虚函数 run() ,在函数 run() 里处理线程的事件循环。 应用程序的线程称为主线程,创建的其他线程称为工作线程。主线程的 start() 函数…...
)
技术周总结 08.05-08.11周日(scala git回滚)
文章目录 一、08.06 周二1.1) 问题01 mac安装 scala:1. 使用 Homebrew2. 使用 SDKMAN!其他注意事项1. 确认 Scala 安装位置2. 设置 PATH 环境变量对于 zsh (macOS Catalina 及更高版本默认使用 zsh):对于 bash (如果您使用的是 bash shell): 3. 验证安装 二、08.09 周五2.1&…...

ffmpeg 命令图片和视频转换
1、截图 ffmpeg -i d:\input.mp4 -ss 0:0:10 d:\output.jpg //指定输出分辨率 ffmpeg -i d:\input.mp4 -y -f image2 -ss 0:0:10 -vframes 1 -s 640x360 d:\output.jpg 2、视频分拆图片 ffmpeg -r 输入帧率 -i d:\input.mp4 -r 输出帧率 "d:\outputDir\frame_%04d.jp…...

力扣 | 动态规划 | 在字符串的应用 | 最长回文子串、最长回文子序列、单词拆分、编辑距离
文章目录 1.最长回文子串2.最长回文子序列3.单词拆分4.编辑距离5. 共同点和思路6. 各个问题的思路和扩展1. 最长回文子串2. 最长回文子序列3. 单词拆分4. 编辑距离 在解答字符串动态规划的应用时,我们需要非常注意一个问题: 有时候我们定义 d p [ i …...

【docker】docker容器部署常用服务
1、容器部署nginx,并且新增一个页面 docker run -d -p 81:80 --name nginx2 nginx docker exec -it nginx2 /bin/bashcd /usr/share/nginx/html/ echo "hello world">>hello.html2、容器部署redis,成功部署后向redis中添加一条数据 do…...
CentOS 7.6 安装 Weblogic
注:本教程是以虚拟机作为安装环境,如果您公司需要安装 Weblogic 服务器,请先以虚拟机模拟安装一遍,否则出现失误,概不负责😁。 一、环境 虚拟机:VMware Workstation 16 Linux:Cent…...

一键清除电脑隐私痕迹,Privacy Eraser助你轻松搞定!
前言 在数字时代,隐私就像是我们手中的细沙,不经意间就可能从指缝间溜走;你是否也曾担心,自己的每一次点击、每一次浏览,都可能成为别人眼中的“秘密”?别急,今天小江湖就要带你走进一款神秘的…...
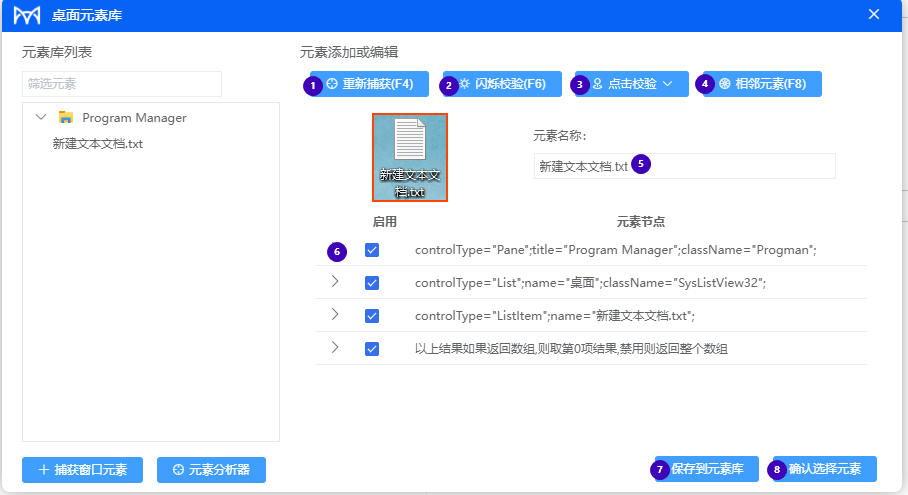
火语言RPA桌面元素库使用方法
使用火语言RPA自动选取工具获得桌面中元素: 工具标识 桌面 分组下组件若有此标识,则包含选择元素工具,点击此标识会进行选择元素操作。 桌面元素库介绍 ① 根据元素名称筛选元素库中保存的元素 ② 元素库,显示已经保存的元素名…...

FTP.JBoss,Ldap,Rsync未授权访问漏洞(附带修复方法)
一.FTP未授权访问漏洞(匿名登陆) FTP 弱⼝令或匿名登录漏洞,⼀般指使⽤ FTP 的⽤户启⽤了匿名登录功能,或系统⼝令的⻓度太短、复杂度不够、仅包含数字、或仅包含字⺟等,容易被⿊客攻击,发⽣恶意⽂件上传或更严重的⼊侵⾏为。 漏…...

全新在线客服系统源码(pc+h5+uniapp+公众号小程序+抖音)附搭建接入教程
全新在线客服系统源码介绍 一、系统概述与优势 本系统是一款基于PHP的开源在线客服系统,支持PC端、移动端(小程序)、H5页面以及Uniapp多端接入。系统利用网络技术和人工智能技术,实现用户与客服人员的即时聊天沟通,有…...

为具有公网IPV6地址的服务器安装nextcloudAIO并使用NginxProxyManager配置反向代理
软件和硬件环境 ubuntu server 24.04,并已配置好ipv6公网地址,已安装好docker和docker-compose。一块单独的硬盘,用于单独存储nextcloud数据。(非必需)有一个能够正常解析的域名,并已配置好AAAA记录解析。…...

挖矿宝藏之TCP/IP
目录 一、TCP/IP简介 1.TCP自述 2.IP自述 二、TCP/IP 寻址 1.IP V6 2.域名 三、TCP/IP协议 一、TCP/IP简介 TCP/IP 指传输控制协议/网际协议(Transmission Control Protocol / Internet Protocol),是供已连接因特网的计算机进行通信的…...
略谈set与map的pair封装与进入哈希
引子:之前我们讲了红黑树的自实现,与小小的接口实现,那set与map的pair封装是如何实现的呢?,今天我们来一探究竟,而且我们也要进入新章节--哈希 对于operator--()的封装: 注意:牢记思…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

【DeepSeek集成测试黄金标准】:20年专家亲授5大避坑指南与自动化落地框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试黄金标准的演进与核心价值 集成测试在大语言模型工程化落地过程中已从“验证功能可用”跃迁为“保障推理一致性、上下文鲁棒性与安全边界的三位一体质量门禁”。DeepSeek系列模型&…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...
与 NOT EXISTS 优化)
PostgreSQL Join 执行策略(Nested Loop、Hash Join、Merge Join)与 NOT EXISTS 优化
以集成数据压缩 SQL 优化为例,用大白话讲清楚 Nested Loop、Hash Join、Merge Join 三种执行策略。一、背景:一条慢 SQL 引发的思考 在对上游下发数据做压缩时,有这样一条 UPDATE SQL: -- ❌ 原始写法 UPDATE magellan_nk_order_i…...