【数据分析---- Pandas进阶指南:核心计算方法、缺失值处理及数据类型管理】
前言:
💞💞大家好,我是书生♡,本阶段和大家一起分享和探索数据分析,本篇文章主要讲述了:Pandas进阶指南:核心计算方法、缺失值处理及数据类型管理等等。欢迎大家一起探索讨论!!!
💞💞代码是你的画笔,创新是你的画布,用它们绘出属于你的精彩世界,不断挑战,无限可能!
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
- 1. Pandas 计算方式
- 1.1 排序函数
- 1.1.1 nlargest和nsmallest函数
- 1.1.2 sort_values函数
- 1.2 聚合函数
- 1.2.1 min最小值
- 1.2.2 mean 平均值
- 1.2.3 sum 求和
- 1.2.4 count 计数
- 1.2.5 std函数计算标准偏差
- 1.2.6 median:中位数
- 1.2.7 cumsum 累计求和
- 1.2.8 quantile函数计算分位数
- 1.2.9 describe() 统计描述
- 1.2.10 corr 相关系数
- 1.3 Pandas函数小结
- 2. Pandas 缺失值
- 2.1 Pandas缺失值的特点
- 2.2 加载包含缺失的数据
- 2.3 查看缺失值
- 2.3.1 info查看缺失值个数
- 2.3.2 判断数据值是否是缺失值
- 2.2.3 统计缺失值个数
- 2.4 Missingno库对缺失值的情况进行可视化探查
- 2.4.1 missingno.bar(df)缺失值数量可视化
- 2.4.2 missingno.matrix(df)缺失值位置的可视化
- 2.4.3 missingno.heatmap(df)缺失值之间相关性可视化
- 3. 缺失值处理
- 3.1 dropna删除缺失值
- 3.2 填充缺失值
- 3.2.1 常数值填充
- 3.2.2 fillna前后值填充缺失值
- 3.2.3 interpolate线性插值
- 3.3 缺失值处理小结
- 4. Pandas数据类型
- 4.1 Pandas 的数据结构
- 4.2 查看数据类型
- 4.3 数据类型转换
- 4.3.1 seriers.astype函数转换数据类型
- 4.3.2 pd.to_numeric函数字符串转数字类型
- 4.4 category 分类类型
- 4.4.1 创建 category 分类类型
- 4.4.2 category 分类类型转换
- 4.5 datetime时间类型
- 4.5.1 查看数据时间
- 4.5.2 创建日期时间
- 4.5.3 时间戳
- 4.5.4 时间函数格式化
- 4.5.5 日期类型的转换
- 4.6 提取日期类型的部分时间
- 注意事项
- 4.7 日期类型运算
- 4.8 日期类型列作为索引
- 4.8.1 df.set_index(keys='列名') 设置索引
- 4.8.2 加载数据的时候指定索引
- 4.8.3 日期类型索引获取部分数据
- 5. timedelta时间差类型
- 5.1 timedelta时间差类型 介绍
- 5.2 时间差类型运算
- 5.3 pd.to_timedelta函数转换timedelta类型
- 5.4 timedelta类型数据作为df索引
- 6. Pandas 数据类型的小结
- 6.1 Pandas中的数据类型
- 6.2 Pandas中数据结构和数据类型的关系
- 6.3 Pandas数据类型转换基本方法
- 6.4 category分类类型
- 6.5 datetime时间类型
- 6.6 timedelta时间差类型
1. Pandas 计算方式
Pandas 是一个强大的 Python 数据分析库,提供了许多用于数据处理和分析的高效函数。以下是一些常用的计算函数:
基本统计函数
mean(): 计算平均值。median(): 计算中位数。sum(): 计算总和。min(),max(): 分别计算最小值和最大值。std(),var(): 计算标准差和方差。quantile(): 计算分位数。
描述性统计
describe(): 返回描述性统计信息,包括计数、平均值、标准差、最小值、四分位数和最大值等。
排序
sort_values(): 按值排序。sort_index(): 按索引排序。
聚合与分组
groupby(): 对数据进行分组操作,之后可以应用其他聚合函数如sum(),mean()等。agg(): 应用多个聚合函数到不同的列上。
索引和切片
iloc[]: 通过位置索引选择数据。loc[]: 通过标签索引选择数据。
数据转换
apply(): 应用自定义函数到每一行或每一列。map(): 应用于 Series 中的元素,通常用于替换值。replace(): 替换 DataFrame 或 Series 中的值。
缺失值处理
isnull(): 判断值是否为空。notnull(): 判断值是否非空。dropna(): 删除缺失值。fillna(): 填充缺失值。

1.1 排序函数
1.1.1 nlargest和nsmallest函数
nlargest(n=, columns=[列名1, 列名2, ...]): 实现对指定列的值由大到小排序, 返回前n行数据nsmallest(n=, columns=[列名1, 列名2, ...]): 实现对指定列的值由小到大排序, 返回前n行数据、n: 整数, n行数据, 默认为5
列名: 指定排序的列名
第一个列有一样的再根据在下一个列排序
加载数据:
import pandas as pd
import numpy as np
# 加载数据集
df = pd.read_csv('../data/LJdata.csv')
df2 = df.head(10)
df2

- 对列值进行降序后取前n个
# 按面积和价格排序,取前5个
df2.nlargest(n=5, columns=['面积', '价格'])

- 对列值进行升序后取前n个
# 按面积和价格排序,取后5个
# #keep 默认为first ,值相同时谁在前,索引小的在前面
df2.nsmallest(n=5, columns=['面积', '价格'])

1.1.2 sort_values函数
通过
df.sort_values(by=列名列表, ascending=)方法根据指定列指定排序方式排序
ascending: True或False, 默认True->升序, 也可以接收布尔值列表, 每列指定排序方式
等同于 order by 列名 排序方式
- 升序
# 对价格列进行升序排列
df2.sort_values(by='价格', ascending=True)

- 降序
如果前面有多个列名,但是只有一个TRUE或者FALSE那么全部列都按照这个排序,ascending也可以跟排序列表scending=[False,True] 第一个列按照降序,第一个相同的时候在第二个按照升序排序
# 对价格和面积列进行降序排列
df2.sort_values(by=['价格','面积'], ascending=False)
df2.sort_values(by=['价格','面积'], ascending=[False,True])

- 索引值排序
# 索引值排序
print(df2.sort_index(ascending=True).head(5))
df2.sort_index(ascending=False).head(5)

1.2 聚合函数
常用聚合函数有:不统计NAN值
- corr 相关性
- min 最小值
- max 最大值
- mean 平均值
- std 标准偏差
- quantile 分位数
- sum 求和
1.2.1 min最小值
df.min()对每一列求最小值,会返回df中每一列的最小值构成的Series
df['列名'].min()对某一列求最小值
# min 最小值 # 对某一列求最小值
print(df2['价格'].min())
# 对每一列求最小值
df2.min()

1.2.2 mean 平均值
df.mean()对每一列求平均值
df['列名'].mean()对某一列求平均值
mean函数计算平均值,用法和min函数的用法一致,但只会对数值类型的数据进行计算
只对数值列有效
# mean 平均值,只对数值列有效
df2.mean()

1.2.3 sum 求和
df.sum()对每一列求求和
df['列名'].sum()对某一列求求和
# sum 求和
# 对某一列求和
print(df2['面积'].sum())
# 对每一列求和
df2.sum()

1.2.4 count 计数
df.count()对每一列计数
df['列名'].count()对某一列计数
不统计NAN
# count 计数
# 对每一列计数,不统计NAN
print(df2.count())

统计包含空值个数:行数
# 统计包含空值个数:行数
print(len(df2))
print(df2.shape[0])
print(df2['价格'].size)
# 包含NAN 列数
df2.count(axis=1)

1.2.5 std函数计算标准偏差
df.std()对每一列标准差
df['列名'].std()对某一列标准差
df.var()对每一列方差
df['列名'].var()对某一列方差
标准偏差:用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。
标准差=方差开方
方差=每个值和平均值差值的平方
只对数值计算
# 标准差: sqrt(mean(x-mean(x))^2) 方差开方
# 衡量数据值的离散程度 -> 标准差越小, 数据值越集中
# 对每列求标准差
print(df2.std())
# 对一列求标准差
print(df2['价格'].std())
# 方差: mean(x-mean(x))^2
# 对每一列求方差
print(df2.var())
# 对某一列求方差
print(df2['价格'].var())

1.2.6 median:中位数
df.median()对每一列中位数
df['列名'].median()对某一列中位数
df.mode()对每一列众数
df['列名'].mode()对某一列众数
print(df2['价格'].var())
#%%
# median:中位数
# 对每一列求中位数
print(df2.median())
# 对某一列求中位数
print(df2['价格'].median())
# mode:众数
# 对每一列求众数
print(df2.mode())
# 对某一列求众数
print(df2['价格'].mode())

1.2.7 cumsum 累计求和
df.cumsum()对每一列累计求和
df['列名'].cumsum()对某一列累计求和
# cumsum:累计求和
print(df2['看房人数'].cumsum())
# 累计比较最大值
df2['看房人数'].cummax()

1.2.8 quantile函数计算分位数
- 分位数(Quantile),亦称分位点,常用的有中位数(即二分位数)、四分位数、百分位数等;那什么是分位数呢?我们以中位数为例:通过把一堆数字按大小排序后找出正中间的一个数字作为中位数,如果这一堆数字有偶数个,则中位数不唯一,通常取最中间的两个数值的平均数作为中位数,即二分位数。
- quantile函数默认返回二分位数;可以通过传入参数来控制返回的四分位数,或其他分位数
quantile(q=): 分位数, 将列值排序后计算分位值
q: 设置分位点 [0.25, 0.5, 0.75] [1/3, 2/3],不设置默认是二位分
# quantile(q=): 分位数, 将列值排序后计算分位值
# q: 设置分位点 [0.25, 0.5, 0.75] [1/3, 2/3], 不设置默认是二位分
print(df2['看房人数'].quantile())
# 查询80%的看房人数信息
df2[df2['看房人数'] <= df2['看房人数'].quantile(q=0.8)]

- quantile(q=[]):设置分位点
# quantile(q=[]):设置分位点
df2['看房人数'].quantile(q=[0, 0.25, 0.5, 0.75, 1])

1.2.9 describe() 统计描述
df.describe()对每一列统计描述
df['列名'].describe()对某一列统计描述
# describe(): 统计描述
df2['看房人数'].describe()

1.2.10 corr 相关系数
corr(method=): 计算列之间的相关系数
method: 相关系数计算方式
查看列之间是否存在相关性 -> 面积和房价成正比 正比 反比
相关性值 -> [-1, 1] 值越大表示正相关越强, 值越小表示负相关越强
print(df2.corr())
print(df.corr()) # 数量越多, 相关性可信度越强
df.corr(method='spearman')

1.3 Pandas函数小结
- 排序
- nlargest函数 由大到小排序获取指定数量的数据
- nsmallest函数 由小到大排序获取指定数量的数据
- sort_values函数 按值排序
- 聚合函数
- corr函数 相关性计算
- min函数 计算最小值
- max函数 计算最大值
- mean函数 计算平均值
- std函数 计算标准偏差
- quantile函数 计算分位数
- sum函数 计算所有数值的和
- count函数 计算非空数据的个数
2. Pandas 缺失值
好多数据集都含缺失数据。缺失数据有多种表现形式
- 数据库中,缺失数据表示为
NULL- 在某些编程语言中用
NA或None表示- 缺失值也可能是空字符串
''或数值0- 在Pandas中使用
NaN表示缺失值
- Pandas中的NaN值来自NumPy库,NumPy中缺失值有几种表示形式:NaN,NAN,nan,他们都一样
2.1 Pandas缺失值的特点
- 缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空字符串
print(NaN==NaN)
print(NaN==NAN)
print(NaN==nan)

print(nan==0)
print(nan=='')
print(nan==False)

- 缺失值从何而来呢?缺失值的来源有两个:
- 原始数据包含缺失值
- 数据整理过程中产生缺失值
2.2 加载包含缺失的数据
加载数据时可以通过
keep_default_na与na_values指定加载数据时的缺失值
pd.read_csv(keep_default_na=, na_values=)pd.read_excel(keep_default_na=, na_values=)
keep_default_na=: 是否将空值加载成缺失值, 默认True
na_values: 指定哪些值在加载时转换成缺失值, 接受列表类型 0->NaN
读取数据, 不将空值加载成缺失值,直接显示空白
# 读取数据, 不将空值加载成缺失值,直接显示空白
df1 = pd.read_csv('../data/city_day.csv',keep_default_na=False)
df1.head(10)

默认是显示NAN值的,也就是keep_default_na=True 为默认
keep_default_na=False

指定将哪些值转换成缺失值
# 加载数据集时, 指定将哪些值转换成缺失值
# na_values=['数据值']
df3 = pd.read_csv('../data/city_day.csv',na_values=['Ahmedabad'],keep_default_na=False)
df3.head(10)

2.3 查看缺失值
2.3.1 info查看缺失值个数
- 查看有多少缺失值
df.info()
# 查看有多少个缺失值
# 没处理的
print(df.info())# 处理了
df1.info()

2.3.2 判断数据值是否是缺失值
isnull()/isna(): 判断数据值是否是缺失值,是缺失值返回True,不是返回False
notnull()/notna(): 判断数据值是否不是缺失值,是缺失值返回False,不是返回True
- 判断全部数据值是否是缺失值,为true是缺失值
# 判断全部数据值是否是缺失值
df.isnull()

- 判断某一列数据值是否是缺失值
# 判断某一列数据值是否是缺失值
df['City'].isnull()

- 判断全部数据值是否不是缺失值
# 判断全部数据值是否不是缺失值
df.notnull()

- 判断某一列数据值是否不是缺失值
# 判断某一列数据值是否不是缺失值
df['City'].notnull()

- 使用isna 或者是 notna 判断
# 判断全部数据值是否是缺失值
df.isna()
# 判断某一列数据值是否是缺失值
df['City'].isna()
# 判断全部数据值是否不是缺失值
df.notna()
# 判断某一列数据值是否不是缺失值
df['City'].notna()

2.2.3 统计缺失值个数
df.isnull().sum()是缺失值返回1,不是返回0
# 统计每一列缺失值个数,是缺失值返回1,不是返回0
# true-》1 ,false-》0
df.isnull().sum()

df.isnull().sum(axis=1)统计每一行缺失值个数,是缺失值返回1,不是返回0
# 统计每一行缺失值个数,是缺失值返回1,不是返回0
df.isnull().sum(axis=1)

notnull().sum()统计每一列非缺失值个数,是缺失值返回1,不是返回0
count 也是这个效果

df.notnull().sum(axis=1)统计每一行非缺失值个数,是缺失值返回1,不是返回0
等价于df.count(axis=1)

2.4 Missingno库对缺失值的情况进行可视化探查
可以使用第三方库Missingno来对缺失值进行可视化
-
通过pip安装missingno
pip install missingno -i https://pypi.tuna.tsinghua.edu.cn/simple/

- 导包
# 导包
import missingno as msno
import matplotlib.pyplot as plt
2.4.1 missingno.bar(df)缺失值数量可视化
利用
missingno.bar(df)函数查看数据集数据完整性
msno.bar(df)
df=pd.read_csv('../data/city_day.csv')
# 绘制缺失值柱状图
msno.bar(df)
# 上面显示的是非缺失值个数
# 区别在于是否有上面的一串数据
plt.show()

2.4.2 missingno.matrix(df)缺失值位置的可视化
msno.matrix(df)
# 全部数据绘制缺失值位置
msno.matrix(df)

随机采样1000条数据,绘制缺失值位置
# 随机采样1000条数据,绘制缺失值位置
msno.matrix(df.sample(1000))

2.4.3 missingno.heatmap(df)缺失值之间相关性可视化
绘制缺失值之间相关性
msno.heatmap(df)
# 绘制缺失值之间相关性
print(msno.heatmap(df))
plt.show()

3. 缺失值处理
缺失值的处理方法有以下几种方式:
- 删除缺失值:删除缺失值会损失信息,并不推荐删除,当缺失数据占比较高的时候,或可以忽略相关性时,可以尝试使用删除缺失值
- 填充缺失值:填充缺失值是指用一个估算的值来去替代缺失数
- 平均值、中位数
- 前后值填充,数据呈现顺序变化的时候可以使用缺失值前边或后边的值进行填充
- 线性插值:假定数据点之间存在严格的线性关系,并利用相邻数据点中的非缺失值来计算缺失数据点的值
3.1 dropna删除缺失值
- 删除缺失值: 当数据中缺失值占比很高时, 可以选择删除; 删除会导致丢失一些数据, 影响分析
- 通过drop()方法删除已知占比比较高的行或列
df.dropna(how=, subset=, axis=, inplace=, thresh=)
axis=0
- 可选参数 ,默认为0按行删
- 0, or ‘index’:删除包含缺失值的行
- 1, or ‘columns’:删除包含缺失值的列
how='any'
- 可选参数,默认为any
- any: 如果存在NA值,则删除该行或列
- all: 如果所有值都是NA,则删除该行或列
inplace=False
- 可选参数,不建议使用这个参数
- 默认False, 不对原数据集进行修改
- inplce=True,对原数据集进行修改
subset接收一个列表
- 接收一个列表,列表中的元素为列名: 对特定的列进行缺失值删除处理
thresh=n
- 可选参数
- 参数值为int类型,按行/列去除NaN值,去除NaN值后该行/列剩余数值的数量(列数)大于等于n,便保留这一行/列
加载数据:
df=pd.read_csv('../data/city_day.csv')
- 删除列缺失值,只要有1个缺失值,就删除整列数据
- df.dropna(axis=1,inplace=False)
# 删除列缺失值,只要有1个缺失值,就删除整列数据
df.dropna(axis=1,inplace=False)

- 删除行缺失值,只要有1个缺失值,就删除整行数据
- df.dropna(axis=0,inplace=False)
# 删除行缺失值,只要有1个缺失值,就删除整行数据
df.dropna(axis=0,inplace=False)

- 删除所有值为缺失值的行数据 // 删除所有值为缺失值的列数据(一行或者一列全部为缺失值才会删除)
# 删除所有值为缺失值的行数据
df.dropna(axis=0,how='all',inplace=False)
# 删除所有值为缺失值的列数据
df.dropna(axis=1,how='all',inplace=False)

- 删除指定列中缺失值
- df.dropna(axis=0,subset=[‘列名’],inplace=False)
# 删除指定列中缺失值
df.dropna(axis=0,subset=['PM2.5'],inplace=False)

- 删除指定列中缺失值,这个列中有缺失值,就删除这一行数据
# 删除指定列中缺失值,这个列中有缺失值,就删除这一行数据
df.dropna(axis=0,subset=['PM2.5','PM10'],inplace=False)

- 行数据中非缺失值个数大于等于thresh阈值就保留当前行数据
# 行数据中非缺失值个数大于等于thresh阈值就保留当前行数据
(df.head(10).dropna(axis=0,thresh=11,inplace=False))

3.2 填充缺失值
- 填充缺失值: 使用均值/中位数/众数等值替换缺失值 优先考虑的处理缺失值方式
df/s.fillna(value=, inplace=, method=)
- value: 需要填充的值 非时间序列的数据
- method: ffill->取缺失值的前一个值进行填充 bfiil->取缺失值的后一个值进行填充 时间序列的数据
3.2.1 常数值填充
填充全部缺失值
df.fillna(value=常数)
# 常数值填充缺失值 - -全部缺失值
df.fillna(value=9999)

指定列填充缺失值
df【‘列名’】.fillna(value=常数)
# 指定列填充缺失值
df['PM2.5'].fillna(value=9999)
# 指定列填充缺失值,以该列的均值填充
df['PM2.5'].fillna(value=df['PM2.5'].mean())

选择数据填充缺失值
# 选择数据填充缺失值
df['Xylene'][54:64].fillna(value=9999)

3.2.2 fillna前后值填充缺失值
时序数据在某一列值的变化往往有一定线性规律,绝大多数的时序数据,具体的列值随着时间的变化而变化,所以对于有时序的行数据缺失值处理可以使用上一个非空值或下一个非空值填充
- 使用上一个非空值(参数method=‘ffill’)填充空值
# 使用缺失值上一个非缺失值填充
df['Xylene'][54:64].fillna(method='ffill')

- 使用缺失值下一个非缺失值填充
# 使用缺失值下一个非缺失值填充
df['Xylene'][54:64].fillna(method='bfill')

3.2.3 interpolate线性插值
绝大多数的时序数据,具体的列值随着时间的变化而变化。 因此,除了使用bfill和ffill进行插补以外还可以使用线性插值法:它假定数据点之间存在严格的线性关系,并利用相邻数据点中的非缺失值来计算缺失数据点的值。
线性差值方式填充缺失值 时间序列的数据 了解
线性插值: 将缺失值前后的数据组合成线性关系, 根据线性计算推测出缺失位置的实际值
使用
df.interpolate(limit_direction="both")对缺失数据进行线性填充
# 线性插值方式填充缺失值
df['Xylene'][54:64].interpolate(method='linear')

3.3 缺失值处理小结
-
缺失值会影响分析计算的结果,这个结果又要用来指导生产经营,所以要重视缺失值
-
空值仅指Pandas中的空值类型,比如
NaN -
缺失值包含空值,也有可能是空字符串、数字0、False或None等
-
不是空值的缺失值可以通过
replace函数先替换为NaN空值,之后再按空值进行处
理解上面的内容,并请对下面的API 有印象、能找到、能理解、能看懂 -
查看空值
df.info()可以查看数据集每一列非空值的数量isnull¬null函数 判断是否存在空值df.isnull().sum()统计空值数量missingno库可以对空值进行可视化探查missingno.matrix(df)查看缺失值的位置missingno.heatmap(df)查看缺失值之间的相关性
-
缺失值的处理
df.dropna()删除缺失值df.fillna(具体值)将缺失值填充为具体指df.fillna(method='ffill')使用上一个非空值进行填充df.fillna(method='bfill')使用下一个非空值进行填充df.interpolate()线性插值:假定数据点之间存在严格的线性关系,并利用相邻数据点中的非缺失值来计算缺失数据点的值
4. Pandas数据类型
4.1 Pandas 的数据结构
Pandas 支持多种数据类型,这使得它能够灵活地处理各种数据结构。以下是 Pandas 中主要的数据类型:
数据结构
- Series: 一维数组,可以保存任何数据类型(整数、字符串、浮点数等),并且有一个与之相关的索引。
- DataFrame: 二维表格型数据结构,可以存储不同类型的数据(每列可以有不同的数据类型)。它类似于 SQL 表格或者 Excel 工作表。
内置数据类型
Pandas 中的数据类型主要基于 NumPy 的数据类型。以下是 Pandas 中常见的数据类型:
-
整数类型
int8: 8 位有符号整数。int16: 16 位有符号整数。int32: 32 位有符号整数。int64: 64 位有符号整数。- 类似的,还有无符号整数类型
uint8,uint16,uint32,uint64。
-
浮点数类型
float16: 半精度浮点数。float32: 单精度浮点数。float64: 双精度浮点数。
-
布尔类型
bool: 布尔值类型。
-
对象类型
object: 通常用于字符串或其他不能用上述类型表示的对象。
-
特殊数据类型
datetime64: 日期时间类型,支持多种日期时间格式。timedelta64: 时间间隔类型,用于表示两个日期时间之间的差异。category: 分类类型,用于分类变量。
查看和修改数据类型
-
查看数据类型
- 使用
.dtypes属性来查看 DataFrame 中各列的数据类型。
- 使用
-
修改数据类型
- 使用
.astype()方法来改变数据类型。
- 使用
| Pandas数据类型 | Python类型 | 说明 |
|---|---|---|
| object | str | 字符串 |
| int64 | int | 整数 |
| float64 | float | 浮点数 |
| bool | bool | 布尔值 |
| category | 无原生类型 | 分类类型 |
| datetime | 无原生类型 | 时间日期类型 |
| timedelta | 无原生类型 | 时间差类型 |
4.2 查看数据类型
字符串object 、整数int、小数float 以及 布尔值bool类型都是比较常见的一般类型
加载数据:
df = pd.read_csv('../data/city_day.csv')
- 查看每一列数据类型
# 查看每一列数据类型
df.info()
df.dtypes

4.3 数据类型转换
通过 astype() 或 to_numeric() 实现类型转换
s.astype(dtype=类型名)
df.astype(dtype={列名:类型名, 列名:类型名, ...})
4.3.1 seriers.astype函数转换数据类型
- 将一列转换为object类型
object 和 str 都是字符串类型,因此使用哪一个都可以
# 类型转换
# 将一列转换为object类型
df['PM2.5'] = df['PM2.5'].astype(dtype = object)
df['PM2.5'] = df['PM2.5'].astype(dtype = str)
df.info()

- 多列转换为object类型
多个列的时候需要使用字典进行类型的转换
# 多列转换为object类型df.astype(dtype = {'PM2.5':object, 'PM10':object, 'SO2':object, 'NO2':object, 'CO':object, 'O3':object}).info()

- 将所有列转换为object类型
不指定任何列,就是全部列都进行转换
# 将所有列转换为object类型
df.astype(dtype=object).info()
注意:需要将有意义的列进行类型转换
astype函数要求DataFrame列的数据类型必须相同,当有些数据中有缺失,但不是NaN时(如’missing’,'null’等),会使整列数据变成字符串类型而不是数值型,这个时候就会报错
# 注意点: 需要将有意义的列进行类型转换
df2 = df.head().copy()
df2.loc[::2, 'NO'] = 'missing'
print(df2)
df2.info()
# df2['NO'].astype(dtype=float) # 报错
此时运行下面的代码会报错
ValueError: could not convert string to float: 'missing',无法使用astype函数进行类型转换;这个时候我们可以使用to_numeric函数
print(df2[‘NO’].astype(float))
4.3.2 pd.to_numeric函数字符串转数字类型
astype函数要求DataFrame列的数据类型必须相同,当有些数据中有缺失,但不是NaN时(如’missing’,'null’等),会使整列数据变成字符串类型而不是数值型,这个时候可以使用to_numeric处理
- pd.to_numeric函数的参数errors, 它决定了当该函数遇到无法转换的数值时该如何处理
- 默认情况下,该值为raise,如果to_numeric遇到无法转换的值时,会抛出异常
- coerce: 如果to_numeric遇到无法转换的值时,会返回NaN值
- ignore: 如果to_numeric遇到无法转换的值时会放弃转换,什么都不做
pd.to_numeric(df2['NO'], errors='coerce')

df2['NO'] = pd.to_numeric(df2['NO'], errors='coerce')
df2.info()

4.4 category 分类类型
- category类型是比较特殊的数据类型,是由固定的且有限数量的变量组成的,比如性别,分为男、女、保密;转换方法可以使用astype函数
- category类型的数据中的分类是有顺序的
- category类型在内存中使用的空间比字符串或其他数据类型更小。这对于数据集中有限且重复的值非常有用
4.4.1 创建 category 分类类型
- 方式一
# 创建分类类型数据
# 指定的分类类别为12345, 数据就对应这5类, 不属于指定分类类别的用NaN替换
s1= pd.Series(data=pd.Categorical(values = [1,2,3,4,5,6,7,8,9,10], categories=[1,2,3,4,5]))
s1

- 方式二
s2 = pd.Series(data=[1,5,6,7,8,1,5,6],dtype='category')
print(s2)
print(type(s2))

4.4.2 category 分类类型转换
通过
astype方法转换成category类型
#通过astype方法转换成category类型
df['City'] = df['City'].astype(dtype='category')
df.info()

4.5 datetime时间类型
python没有原生的datetime数据类型,需要使用datetime包
from datetime import datetime
now = datetime.now()
someday = datetime(2020, 1, 1)
print(now)
print(type(now))
print(someday)
print(type(someday))

4.5.1 查看数据时间
# python中的日期时间
# 需要借助datetime模块进行处理
from datetime import datetime
# 获取当前时间
datetime.now()
# 获取当前类型
print(type(datetime.now()))
# 获取当前日期和时间
print(datetime.now())
# 获取当前日期
print(datetime.now().date())
# 获取当前年份
print(datetime.now().year)
# 获取当前时间
print(datetime.now().time())
# 获取当前月份
print(datetime.now().month)
4.5.2 创建日期时间
datetime(年,月,日,小时,分钟,秒)
# 创建日期时间
someday = datetime(2024,8,10)
print(someday)
print(type(someday))

4.5.3 时间戳
datetime.now().timestamp()
# 时间戳
print(datetime.now().timestamp())
# 或者now()也可以查看
datetime.now()

4.5.4 时间函数格式化
strftime() -> f:format日期时间格式化后转换成字符串类型
strptime()-> p:parse 字符串类型的日期时间解析成日期时间类型
datetime.now().strftime(格式)
datetime.strptime(s1, 格式)
# strftime() -> f:format 日期时间格式化后转换成字符串类型
print(datetime.now().strftime(format='%Y-%m-%d %H:%M:%S'))
# # strptime() -> p:parse 字符串类型的日期时间解析成日期时间类型
# '%Y-%m-%d %H:%M'->字符串是什么日期时间格式就写什么格式, 格式不一致会发生报错!!!
s1= datetime.now().strftime(format='%Y-%m-%d %H:%M:%S')
s2 =datetime.strptime(s1, '%Y-%m-%d %H:%M:%S')
print(s2)
print(type(s2))

4.5.5 日期类型的转换
加载数据集时转换成日期类型
pd.read_csv(parse_dates=[列名1, 列名2, …])
pd.read_excel(parse_dates=[列名1, 列名2, …])
df = pd.read_csv(‘data/city_day.csv’, parse_dates=[‘Date’])
- 加载数据集时转换成日期类型
可以通过列名 或者是 列下标
# 加载数据集时转换成日期类型,通过列名转换
df = pd.read_csv('../data/city_day.csv', parse_dates=['Date'])
df.info()
# 通过下标进行转换
df1 = pd.read_csv('../data/city_day.csv', parse_dates=[1])
df1.info()

- 通过 astype(dtype=日期类型) 将一列转化为时间类型
- 通过 pd.to_datetime(df[‘列名’]) 将字符串转换为时间日期类型
# astype(dtype=日期类型)
df = pd.read_csv('../data/city_day.csv')
df['Date'] = df['Date'].astype(dtype='datetime64[ns]')
df.info()

# pd.to_datetime(列名,unit )
df = pd.read_csv('../data/city_day.csv')
df['Date'] = pd.to_datetime(df['Date'])
df.info()

4.6 提取日期类型的部分时间
在 Pandas 中,如果有一个包含日期时间的 Series 或 DataFrame 列,您可以轻松地提取日期时间的不同部分。
通过使用
.dt属性访问日期时间组件来实现。
常用的日期时间组件
- Year: 年份
- Month: 月份
- Day: 日
- Hour: 小时
- Minute: 分钟
- Second: 秒
- Week: 星期
- Day of Week: 星期几(0-6,其中 0 代表周一)
- Quarter: 季度
- Timestamp: 完整的时间戳
注意事项
- 确保您的日期时间数据已经正确转换为
datetime64类型。 - 如果日期时间数据包含时区信息,可以使用
.dt.tz_localize()和.dt.tz_convert()来处理时区转换。
# 提取日期类型中的部分时间
# 获取日期类型的s对象的部分时间
# 列名.dt.year 年
# 列名.dt.month 月
# 打印数据中的年份
print(df['Date'].dt.year.head())
# 打印数据中的月份
print(df['Date'].dt.month.head())
# 打印数据中的日期
print(df['Date'].dt.day.head())
# 打印数据中的小时
print(df['Date'].dt.hour.head())
# 打印数据中的季度
print(df['Date'].dt.quarter.head())
# 打印数据中的周数
print(df['Date'].dt.week.head())
# 打印数据中的工作日
print(df['Date'].dt.weekday.head())
# 打印数据中的年内天数
print(df['Date'].dt.dayofyear.head())
# 打印数据中的是否为闰年
print(df['Date'].dt.is_leap_year.head())
# 打印数据中的是否为月初
print(df['Date'].dt.is_month_start.head())
# 打印数据中的是否为月末
print(df['Date'].dt.is_month_end.head())
# 打印数据中的是否为季度初
print(df['Date'].dt.is_quarter_start.head())
# 打印数据中的是否为季度末
print(df['Date'].dt.is_quarter_end.head())
# 打印数据中的是否为年初
print(df['Date'].dt.is_year_start.head())
# 打印数据中的是否为年末
print(df['Date'].dt.is_year_end.head())
- python中提取一个时间值中的部分时间 变量名.year
# python中提取一个时间值中的部分时间 变量名.year
someday = datetime(2024, 6, 17)
print(someday)
print(someday.year)

4.7 日期类型运算
可以通过S对象的内置函数获取数据
df['列名'].min()
df['列名'].max()
# 日期运算, 获取日期类型中的最小值和最大值
print(df['Date'].min())
print(df['Date'].max())
# 获取日期类型中的差值
print(df['Date'].max() - df['Date'].min())

4.8 日期类型列作为索引
4.8.1 df.set_index(keys=‘列名’) 设置索引
df.set_index(keys='列名')
temp_df = df.set_index(keys='Date')
temp_df.head()

查看索引
temp_df.index

4.8.2 加载数据的时候指定索引
pd.read_csv(路径,index_col='列名',parse_dates=True)
# index_col: 指定列为索引
# parse_dates: True->将索引转换成日期类型
df1 = pd.read_csv('../data/city_day.csv',index_col='Date',parse_dates=True)
df1.index

4.8.3 日期类型索引获取部分数据
# 日期类型索引可以获取部分数据
# 先要对日期类型索引进行排序
df1.sort_index(inplace=True)
# 获取2015年8月的数据子集
print(df1.loc['2015-08'])
# 获取2015年的数据子集
print(df1.loc['2015'])
# 获取时间范围内的数据子集
print(df1.loc['2015-01-01 22':'2015-05-05 10:22:33'])

5. timedelta时间差类型
5.1 timedelta时间差类型 介绍
在 Pandas 中,Timedelta 类型用于表示两个日期时间之间的差值。这种类型非常有用,尤其是在处理时间序列数据时。下面是一些关于 Timedelta 类型的基础知识和示例。
- 创建 Timedelta 对象
可以使用pd.Timedelta或者字符串来创建Timedelta对象。
使用 pd.Timedelta 创建
import pandas as pd# 创建 Timedelta 对象
td1 = pd.Timedelta(days=10, hours=2, minutes=30)
print(td1)
使用字符串创建
# 使用字符串创建 Timedelta 对象
td2 = pd.Timedelta('1 days 2 hours 30 minutes')
print(td2)
Timedelta 属性
Timedelta 对象有一些有用的属性来获取时间差的具体组成部分。
- 属性示例
# 获取 Timedelta 的属性
print(td1.days) # 天数
print(td1.seconds) # 秒数
print(td1.microseconds) # 微秒数
print(td1.components) # 各个时间单位的组成部分
-
运算操作
Timedelta对象可以与其他Timedelta对象或日期时间对象进行运算。 -
加法和减法
# 创建另一个 Timedelta 对象
td3 = pd.Timedelta('2 days 1 hour')# 加法
result_add = td1 + td3
print(result_add)# 减法
result_subtract = td1 - td3
print(result_subtract)
- 与日期时间的运算
# 创建日期时间对象
dt = pd.Timestamp('2024-01-01')# 加法
result_add_dt = dt + td1
print(result_add_dt)# 减法
result_subtract_dt = dt - td1
print(result_subtract_dt)
- 比较运算
可以使用比较运算符来比较Timedelta对象。
# 比较运算
print(td1 > td3) # 大于
print(td1 < td3) # 小于
print(td1 == td3) # 等于
5.2 时间差类型运算
# 获取当前时间与任意一个之间的时间差
print(datetime.now()-datetime(2020, 8, 10))
print(type(datetime.now()-datetime(2020, 8, 10)))

- pandas 时间差类型
# pandas 时间差类型
df2 = pd.read_csv('../data/city_day.csv',parse_dates=['Date'])
df2['ref_date'] = datetime.now() - df2['Date']
df2.head()

- 获取时间差类型中的整数部分
# 获取时间差类型中的整数部分
df2['ref_date'].dt.days

5.3 pd.to_timedelta函数转换timedelta类型
可以使用astype 也可以使用 to_timedelta 将字符串数据转换为时间数据
# 字符串类型转换成时间差类型
print(df2['ref_date'].astype(dtype='timedelta64[ns]'))
pd.to_timedelta(df2['ref_date'])

5.4 timedelta类型数据作为df索引
将timedelta类型数据作为df索引,就可以基于时间差范围来选择数据(将时间差列设置为索引, 获取数据子集)
修改数据将时间差列作为索引
# 将时间差列设置为索引, 获取数据子集
df2['ref_date']= df2['ref_date'].dt.days
df2.set_index(keys='ref_date', inplace=True)
df2

索引排序,不排序会发生报错
通过**
df2.loc['索引值1' : '索引值2']**,来获取部分数据,拿到索引值1 到 索引值2 之间的数据
# 索引排序,不排序会发生报错
df2.sort_index(inplace=True)
df2.loc['3506']
df2.loc['3500' : '3509']

6. Pandas 数据类型的小结
6.1 Pandas中的数据类型
| Pandas数据类型 | Python类型 | 说明 |
|---|---|---|
| object | str | 字符串 |
| int64 | int | 整数 |
| float64 | float | 浮点数 |
| bool | bool | 布尔值 |
| category | 无原生类型 | 分类类型 |
| datetime | 无原生类型 | 时间日期类型 |
| timedelta | 无原生类型 | 时间差类型 |
6.2 Pandas中数据结构和数据类型的关系
- pandas是基于numpy构建的包,所以pandas中的数据类型都是基于Numpy中的ndarray类型实现的
- Pandas中的数据结构对象和数据类型对象:
- dataframe 表 【数据结构】
- series 列【数据结构】
- object --> python str 字符串 【数据类型】
- int64 --> python int 整数 【数据类型】
- float64 --> python float 小数 【数据类型】
- bool --> python bool True False 【数据类型】
- datetime64 --> python datetime 时间日期 【数据类型】
- series 列【数据结构】
- dataframe 表 【数据结构】
- timedelta[ns]–> 两个时间点之间相距的时间差,单位是纳秒 【数据类型】
- category --> 特定分类数据类型,比如性别分为男、女、其他 【数据类型】
6.3 Pandas数据类型转换基本方法
df['列名'].astype(str)- 当Seriers对象使用astype函数转换的结果中数据类型不同时,使用to_numeric函数
pd.to_numeric(df['列名'], errors='coerce')无法转换的值返回NaNpd.to_numeric(df['列名'], errors='ignore')无法转换的值返回原值
6.4 category分类类型
- 创建方式
s = pd.Series(['B','D','C','A'], dtype='category')
6.5 datetime时间类型
- datetime时间类型的Seriers来源两种方式:
- 读取时指定
df = pd.read_csv('..xxx.csv', parse_dates=[1]) - 转换
df['Date'] = pd.to_datetime(df['Date'])
- 读取时指定
- 提取datetime时间类型的Seriers中的具体年月日时分秒星期
df['Date'].dt.yeardf['Date'].dt.quarter# 季度df['Date'].dt.dayofweek + 1# 星期
- 提取datetime时间类型的Seriers中的某一个值的具体年月日时分秒星期
df4['Date'][0].dayofweek+1 # 星期
- datetime时间类型的Seriers可以进行时间计算
- 直接调用聚合函数
df['Date'].max() # 最近的日期 - 计算时间差
df['Date'] - df['Date'].min() # 返回时间差类型数据构成的Seriers
- 直接调用聚合函数
- datetime时间类型的S对象作为索引的两种方式
df = pd.read_csv('..xxx.csv', index_col='Date', parse_dates=True)df.index = df['date']- 注意:要对索引进行重新排序 必要步骤
df = df.sort_index()
- datetime时间类型索引可以按照时间范围取子集
df['2018']df['2016-06']df.loc['2015-3-4 22': '2016-1-1 23:45:00']
6.6 timedelta时间差类型
- timedelta时间差类型的创建:
df['date_diff'] = df['Date'] - df['Date'].min()
- 字符串类型转换为时间差类型
s2 = pd.to_timedelta(s1)
- timedelta时间差类型设为索引
df.index = df['Date'] - df['Date'].min()
- 基于时间差范围来选择数据
df['0 days':'4 days']
相关文章:
【数据分析---- Pandas进阶指南:核心计算方法、缺失值处理及数据类型管理】
前言: 💞💞大家好,我是书生♡,本阶段和大家一起分享和探索数据分析,本篇文章主要讲述了:Pandas进阶指南:核心计算方法、缺失值处理及数据类型管理等等。欢迎大家一起探索讨论&#x…...

2024世界机器人大会将于8月21日至25日在京举行
2024年的世界机器人大会预定于8月21日至25日,在北京经济技术开发区的北人亦创国际会展中心隆重举办。 本届大会以“共育新质生产力 共享智能新未来”为核心主题,将汇聚来自全球超过300位的机器人行业专家、国际组织代表、杰出科学家以及企业家࿰…...

【Linux】lvm被删除或者lvm丢失了怎么办
模拟案例 接下来模拟lvm误删除如何恢复的案例: 模拟删除: 查看vg名: vgdisplayvgcfgrestore --list uniontechos #查看之前的操作 例如我删除的,现场没有删除就用最近的操作文件: 还原: vgcfgrestore…...
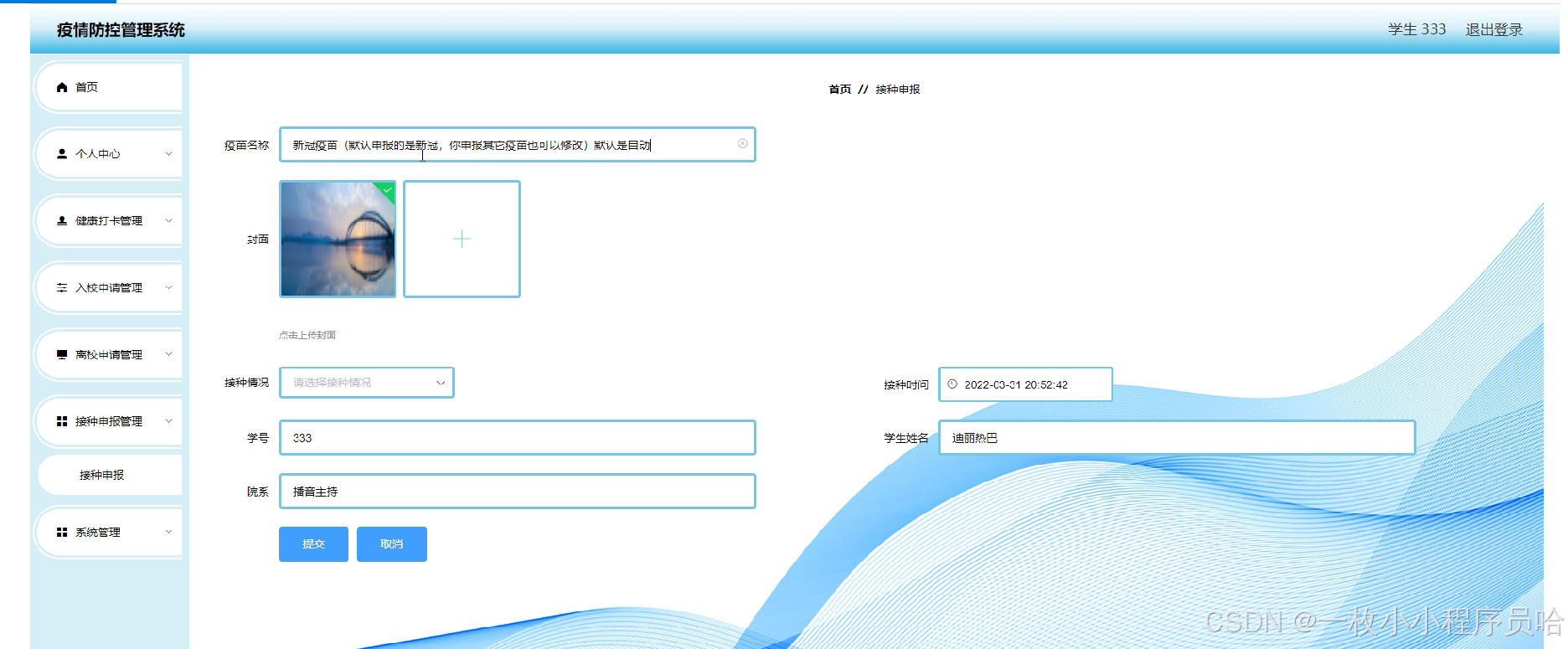
疫情防控管理系统
摘 要 由于当前疫情防控形势复杂,为做好学校疫情防控管理措施,根据上级防疫部门要求,为了学生的生命安全,要求学校加强疫情防控的管理。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生&#x…...

永久删除的Android 文件去哪了?在Android上恢复误删除的消息和照片方法?
丢失重要消息和照片可能是一种令人沮丧的经历,尤其是在您没有备份的情况下。但别担心,在本教程中,我们将指导您完成在Android设备上恢复已删除消息和照片的步骤。无论您是不小心删除了它们还是由于软件问题而消失了,这些步骤都可以…...
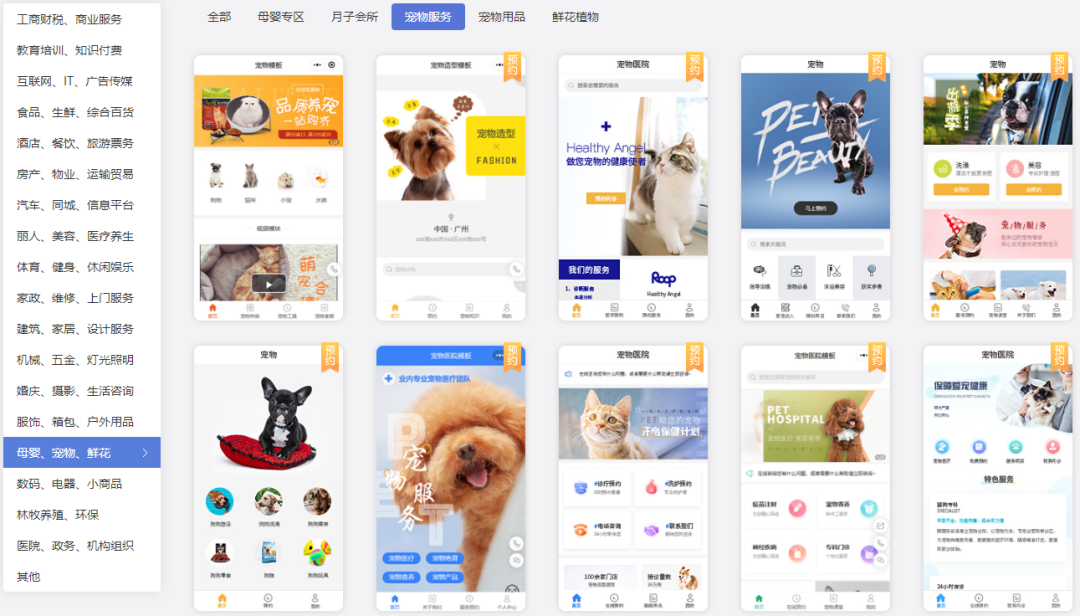
宠物服务小程序多生态转化
宠物服务如美容造型、医疗、看护寄养等有着不少需求,尤其是年轻人从宠物生活到饮食起居等面面俱到,往往不惜金钱给到较好的环境,如定时除虫、优质食物、玩具、检查身体、服饰; 近些年宠物服务店新开数量也较多,同行竞…...

今天细说一下工业制造行业MES系统
文章目录 前言什么是MES? 前言 最近几个月在做制造行业的MES系统开发,这类面向制造业的系统是今年做的第三个系统了,也算是了解较深的了,和一个之前转行做这一块的朋友聊了聊,他们集团要扩大规模,准备招ME…...
)
C++ 知识点(长期更新)
C++ 知识点 C/C++1. `cin`, `cin.get()`, `getchar()`, `getline()`, 和 `cin.getline()`的区别。2. 有关 cin >>3. 定义和声明的区别4. `union`、`struct`和`class`的区别5. 深拷贝 vs 浅拷贝6. new 和 malloc 的区别7. 被free回收的内存是立即返还给操作系统吗?为什么…...

Spring AI + 通义千问 入门学习
Spring AI 通义千问 入门学习 文章目录 Spring AI 通义千问 入门学习一,开发环境配置二,项目搭建2.1 pom文件2.2 配置文件 三,AI使用3.1 对话问答3.1.1 普通方式3.1.2 流方式 3.2 文字生成图片 最近AI很火,而Spring也出了Spring…...

38.【C语言】指针(重难点)(C)
目录: 8.const 修饰指针 *修饰普通变量 *修饰指针变量 9.指针运算 *指针或-整数 *指针-指针 *指针关系运算 往期推荐 承接上篇37.【C语言】指针(重难点)(B) 8.const 修饰指针 const 全称 constant adj.不变的 *修饰普通变量 #…...

Vue-05.指令-v-for
v-for 列表渲染,遍历容器的元素或者对象的属性 v-for“列表元素名 in 列表名” <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-wi…...

自动驾驶的一些大白话讲解
无人驾驶牛逼吗?我来帮你祛魅【原理缺陷解析】_哔哩哔哩_bilibili 5分钟讲明白自动驾驶端到端,解释为什么华为智驾并不是遥遥领先 到底什么是端到端自动驾驶系统?为何我会说这是智能驾驶的弯道超车机会?我希望今天用5分钟的时间&…...

Python学习笔记--参数
目录 实参与形参 不定长参数 拆分参数列表 返回值 实参与形参 1. 定义函数时,带默认值的形参必须放在不带默认值的形参后面 下面程序的输出结果是( )。 def StudentInfo(country中国,name): print(%s,%s%(name,country)…...

刷题——大数加法
大数加法_牛客题霸_牛客网 string solve(string s, string t) {if(s.size() < t.size()) return solve(t, s);reverse(s.begin(), s.end());reverse(t.begin(), t.end());string ans;int d 0;//进位制for(int i0; i < s.size(); i){d s[i] - 0;//取得数字值if(i < …...
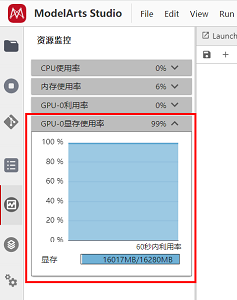
Pytorch人体姿态骨架生成图像
ControlNet是一个稳定扩散模型,可以复制构图和人体姿势。ControlNet解决了生成想要的确切姿势困难的问题。 Human Pose使用OpenPose检测关键点,如头部、肩膀、手的位置等。它适用于复制人类姿势,但不适用于其他细节,如服装、发型和…...
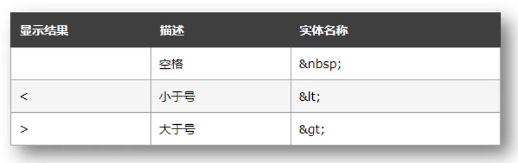
前端面试常考的HTML标签知识!!!
语义标签 标签名语义描述header网页头部网页的主要头部区域nav网页导航网页的导航链接区域footer网页底部网页的底部区域aside网页侧边栏网页的侧边栏区域section网页区块网页的独立区块 | article | 网页文章 | 网页的独立文章区域 | 字符实体 作用:在网页中显…...

Oracle触发器
Oracle触发器就是特定事件发生时自动执行的存储过程。 触发器基本使用 基本语法: create [or replace] trigger 触发器名称 alter | before | instead of [insert] [[or] update [of 列1,列2,...]] [[or] delete] on 表名 [referencing {OLD [as] old / NEW [as]…...

GPT-5:未来已来,我们如何共舞于智能新纪元?
GPT-5:未来已来,我们如何共舞于智能新纪元? 在科技日新月异的今天,人工智能(AI)的每一次飞跃都深刻地改变着人类社会的面貌。从AlphaGo击败围棋世界冠军,到GPT系列模型引领自然语言处理&#x…...

2024年6月 青少年机器人技术等级考试理论综合试卷(五级)
202406 青少年等级考试机器人理论真题五级 第 1 题 ESP32 for Arduino,通过引脚2读取按键开关的返回值,电路如下图所示,程序pinMode(2, mode);中,参数mode的值是?( ) A:INPUT B&…...

【Go】 HTTP编程3-路由httprouter
HttpRouter httprouter httprouter是第三方的库,不是go的标准库,使用命令 go get -u github.com/julienschmidt/httprouter ,下载该模块,-u表示如果已经下载但更新到最新版本Router 实现了http.Handler接口,为各种 re…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

在Hermes Agent项目中接入Taotoken作为自定义模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Hermes Agent项目中接入Taotoken作为自定义模型供应商 基础教程类,针对使用Hermes Agent框架的开发者,详…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...

告别KITTI!用TartanAir数据集在Unreal Engine+AirSim里复现那些让VSLAM算法“翻车”的雨天和黑夜
超越KITTI:用TartanAir数据集在虚拟极端环境中锤炼VSLAM算法当视觉SLAM算法在KITTI数据集上取得95%的准确率时,开发者们常常会松一口气——直到这些算法被部署到真实世界的雨夜街道上。突然之间,那些在阳光明媚的德国道路上表现优异的特征点检…...