YOLOv8+DeepSort实现
目录
1,YOLOv8算法简介
2,DeepSort算法介绍
1. SORT目标追踪
3,实现流程
1.检测
2. 生成detections
3. 卡尔曼滤波预测
4.使用匈牙利算法将预测后的tracks和当前帧中的detections进行匹配
5. 卡尔曼滤波更新
4,代码实现
结果:
1,YOLOv8算法简介
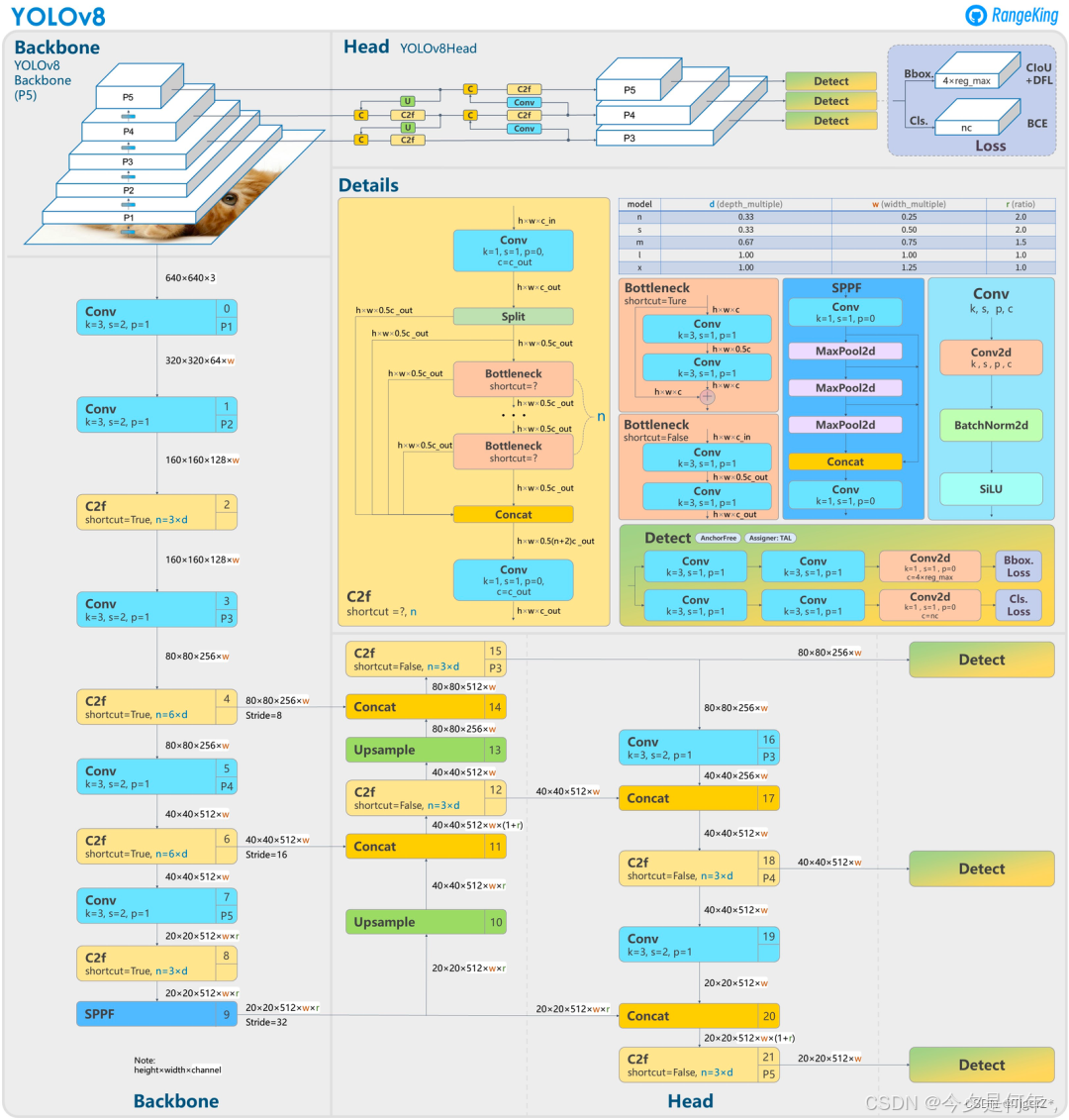
YOLOv8是由Ultralytics公司开发的最新一代目标检测算法,它是YOLO系列的一次重大更新,支持图像分类、物体检测和实例分割等多种视觉AI任务 。YOLOv8在继承了YOLO系列优点的基础上,进行了速度和精度的进一步优化,具有更快的推理速度和更高的检测精度 。
YOLOv8的核心特点包括:
- 网络架构:采用了轻量级的网络架构,引入了注意力机制,优化了网络结构,减少了冗余计算 。
- 损失函数:使用了多任务损失函数,结合了分类损失和定位损失,引入了IOU损失函数,更好地处理重叠目标 。
- 数据增强:在训练过程中应用了多种数据增强技术,如随机裁剪、旋转和缩放,提高了模型的泛化能力和鲁棒性 。
YOLOv8的实际应用非常广泛,它在安防监控、自动驾驶、智能家居等领域都有应用前景 。此外,YOLOv8的开源库被定位为算法框架,具有很好的可扩展性,不仅可以用于YOLO系列模型,还支持非YOLO模型以及分类分割姿态估计等任务 。
YOLOv8的创新之处在于它结合了当前多个SOTA技术,包括一个新的骨干网络、Ancher-Free检测头和新的损失函数,能够在多种硬件平台上运行 。YOLOv8的Backbone采用了C2f模块代替C3模块,增加了梯度流,提高了模型性能和收敛速度 。同时,YOLOv8的Head部分采用了解耦头结构,将分类和检测头分离,并从Anchor-Based变成了Anchor-Free 。
YOLOv8的训练策略也有所改进,训练总epoch数从300提升到了500,有助于进一步提升模型性能 。此外,YOLOv8还引入了TaskAlignedAssigner正样本分配策略和Distribution Focal Loss,优化了模型的Loss计算 。
在性能方面,YOLOv8在COCO数据集上的测试结果表明,相比YOLOv5,YOLOv8在精度上有了显著提升,但相应的参数量和FLOPs也有所增加 。尽管如此,YOLOv8依然保持了较高的推理速度,适用于实时目标检测任务 。
2,DeepSort算法介绍
DeepSORT是一种计算机视觉目标跟踪算法,旨在为每个对象分配唯一的ID并跟踪它们。它是SORT(Simple Online and Realtime Tracking,简单在线实时跟踪)算法的扩展和改进版本。SORT是一种轻量级目标跟踪算法,用于处理实时视频流中的目标跟踪问题。DeepSORT引入了深度学习技术,以加强SORT的性能,并特别关注在多个帧之间跟踪目标的一致性。
1. SORT目标追踪
SORT 是一种对象跟踪方法,其中使用卡尔曼滤波器和匈牙利算法等基本方法来跟踪对象,并声称比许多在线跟踪器更好。SORT 由以下 4 个关键组件组成:
- 检测:首先,在跟踪流程的第一步,目标检测器被用来检测当前帧中需要跟踪的目标对象。常用的目标检测器包括Faster R-CNN、YOLO等。
- 估计:在估计阶段,检测结果从当前帧传播到下一帧,使用恒速模型来估计下一帧中目标的位置。当检测结果与已知的目标相关联时,检测到的边界框信息用于更新目标的状态,包括速度分量,这是通过卡尔曼滤波器框架来实现的。
- 数据关联:在数据关联步骤中,目标的边界框信息与检测结果结合,从而形成一个成本矩阵,该矩阵计算每个检测与已知目标的所有预测边界框之间的交并比(IOU)距离。然后,使用匈牙利算法来优化分配,以确保正确地将检测结果与目标关联起来。这个技术有助于解决遮挡问题并保持目标的唯一身份。
- 管理目标ID的创建与删除:跟踪模块负责创建和销毁目标的唯一身份(ID)。如果检测结果与目标的IOU小于某个预定义的阈值(通常称为IOUmin),则不会将检测结果与目标相关联,这表示目标未被跟踪。此外,如果在连续TLost帧中没有检测到目标,跟踪将终止该目标的轨迹,其中TLost是一个可配置的参数。如果目标重新出现,跟踪将在新的身份下恢复。
3,实现流程
1.检测
在每一帧中,目标检测器识别并提取出边界框(bbox),这些边界框表示在当前帧中检测到的目标物体。
def detect(self,cv_src):boxes, scores, class_ids = self.detector(cv_src)pred_boxes = []for i in range(len(boxes)):x1,y1 = int(boxes[i][0]),int(boxes[i][1])x2,y2 = int(boxes[i][2]),int(boxes[i][3])lbl = class_names[class_ids[i]]# print(class_ids[i])# if lbl in ['person','sack','elec','bag','box','caron']:# continuepred_boxes.append((x1,y1,x2,y2,lbl,class_ids[i]))return cv_src,pred_boxes
2. 生成detections
从这些检测到的边界框中,生成称为"detections"的目标检测结果。每个detection通常包含有关目标的信息,如边界框坐标和可信度分数。
# deep_sort.py
def update(self, bbox_xywh, confidences, ori_img):self.height, self.width = ori_img.shape[:2]# 提取每个bbox的featurefeatures = self._get_features(bbox_xywh, ori_img)# [cx,cy,w,h] -> [x1,y1,w,h]bbox_tlwh = self._xywh_to_tlwh(bbox_xywh)# 过滤掉置信度小于self.min_confidence的bbox,生成detectionsdetections = [Detection(bbox_tlwh[i], conf, features[i]) for i,conf in enumerate(confidences) if conf > self.min_confidence]# NMS (这里self.nms_max_overlap的值为1,即保留了所有的detections)boxes = np.array([d.tlwh for d in detections])scores = np.array([d.confidence for d in detections])indices = non_max_suppression(boxes, self.nms_max_overlap, scores)detections = [detections[i] for i in indices]...
3. 卡尔曼滤波预测
对于已知的跟踪对象(“tracks”),在下一帧中进行卡尔曼滤波预测,以估计其新的位置和速度。
# track.py
def predict(self, kf):"""Propagate the state distribution to the current time step using a Kalman filter prediction step.Parameters----------kf: The Kalman filter."""self.mean, self.covariance = kf.predict(self.mean, self.covariance) # 预测self.age += 1 # 该track自出现以来的总帧数加1self.time_since_update += 1 # 该track自最近一次更新以来的总帧数加1
4.使用匈牙利算法将预测后的tracks和当前帧中的detections进行匹配
这是DeepSORT中的核心步骤。DeepSORT使用匈牙利算法来将预测的tracks和当前帧的detections进行匹配。这个匹配可以采用两种级联方法:首先,通过计算马氏距离来估算预测对象与检测对象之间的关联,如果马氏距离小于指定的阈值,则将它们匹配为同一目标。其次,DeepSORT还使用外观特征余弦距离度量,通过一个重识别模型获得不同物体的特征向量,然后构建余弦距离代价函数,以计算预测对象与检测对象的相似度。这两个代价函数的结果都趋向于小,如果边界框接近且特征相似,则将它们匹配为同一目标。
# tracker.py
def _match(self, detections):def gated_metric(racks, dets, track_indices, detection_indices):"""基于外观信息和马氏距离,计算卡尔曼滤波预测的tracks和当前时刻检测到的detections的代价矩阵"""features = np.array([dets[i].feature for i in detection_indices])targets = np.array([tracks[i].track_id for i in track_indices]# 基于外观信息,计算tracks和detections的余弦距离代价矩阵cost_matrix = self.metric.distance(features, targets)# 基于马氏距离,过滤掉代价矩阵中一些不合适的项 (将其设置为一个较大的值)cost_matrix = linear_assignment.gate_cost_matrix(self.kf, cost_matrix, tracks, dets, track_indices, detection_indices)return cost_matrix# 区分开confirmed tracks和unconfirmed tracksconfirmed_tracks = [i for i, t in enumerate(self.tracks) if t.is_confirmed()]unconfirmed_tracks = [i for i, t in enumerate(self.tracks) if not t.is_confirmed()]# 对confirmd tracks进行级联匹配matches_a, unmatched_tracks_a, unmatched_detections = \linear_assignment.matching_cascade(gated_metric, self.metric.matching_threshold, self.max_age,self.tracks, detections, confirmed_tracks)# 对级联匹配中未匹配的tracks和unconfirmed tracks中time_since_update为1的tracks进行IOU匹配iou_track_candidates = unconfirmed_tracks + [k for k in unmatched_tracks_a ifself.tracks[k].time_since_update == 1]unmatched_tracks_a = [k for k in unmatched_tracks_a ifself.tracks[k].time_since_update != 1]matches_b, unmatched_tracks_b, unmatched_detections = \linear_assignment.min_cost_matching(iou_matching.iou_cost, self.max_iou_distance, self.tracks,detections, iou_track_candidates, unmatched_detections)# 整合所有的匹配对和未匹配的tracksmatches = matches_a + matches_bunmatched_tracks = list(set(unmatched_tracks_a + unmatched_tracks_b))return matches, unmatched_tracks, unmatched_detections# 级联匹配源码 linear_assignment.py
def matching_cascade(distance_metric, max_distance, cascade_depth, tracks, detections, track_indices=None, detection_indices=None):...unmatched_detections = detection_indicematches = []# 由小到大依次对每个level的tracks做匹配for level in range(cascade_depth):# 如果没有detections,退出循环if len(unmatched_detections) == 0: break# 当前level的所有tracks索引track_indices_l = [k for k in track_indices if tracks[k].time_since_update == 1 + level]# 如果当前level没有track,继续if len(track_indices_l) == 0: continue# 匈牙利匹配matches_l, _, unmatched_detections = min_cost_matching(distance_metric, max_distance, tracks, detections, track_indices_l, unmatched_detections)matches += matches_lunmatched_tracks = list(set(track_indices) - set(k for k, _ in matches))return matches, unmatched_tracks, unmatched_detections5. 卡尔曼滤波更新
匹配后,DeepSORT使用检测到的detections来更新每个已知的跟踪对象的状态,例如位置和速度。这有助于保持跟踪对象的准确性和连续性。
def update(self, detections):"""Perform measurement update and track management.Parameters----------detections: List[deep_sort.detection.Detection]A list of detections at the current time step."""# 得到匹配对、未匹配的tracks、未匹配的dectectionsmatches, unmatched_tracks, unmatched_detections = self._match(detections)# 对于每个匹配成功的track,用其对应的detection进行更新for track_idx, detection_idx in matches:self.tracks[track_idx].update(self.kf, detections[detection_idx])# 对于未匹配的成功的track,将其标记为丢失for track_idx in unmatched_tracks:self.tracks[track_idx].mark_missed()# 对于未匹配成功的detection,初始化为新的trackfor detection_idx in unmatched_detections:self._initiate_track(detections[detection_idx])...
4,代码实现
首先去GitHub官网将项目下载或者拉下来
网址:MuhammadMoinFaisal/YOLOv8-DeepSORT-Object-Tracking: YOLOv8 Object Tracking using PyTorch, OpenCV and DeepSORT (github.com)然后按照readme文档将环境配置好
pip install -e '.[dev]'
进入到detect中
cd ultralytics/yolo/v8/detect
接着得去下面的网址下载一个DeepSORT文件
https://drive.google.com/drive/folders/1kna8eWGrSfzaR6DtNJ8_GchGgPMv3VC8?usp=sharing
然后运行
python predict.py model=yolov8l.pt source="test3.mp4" show=True
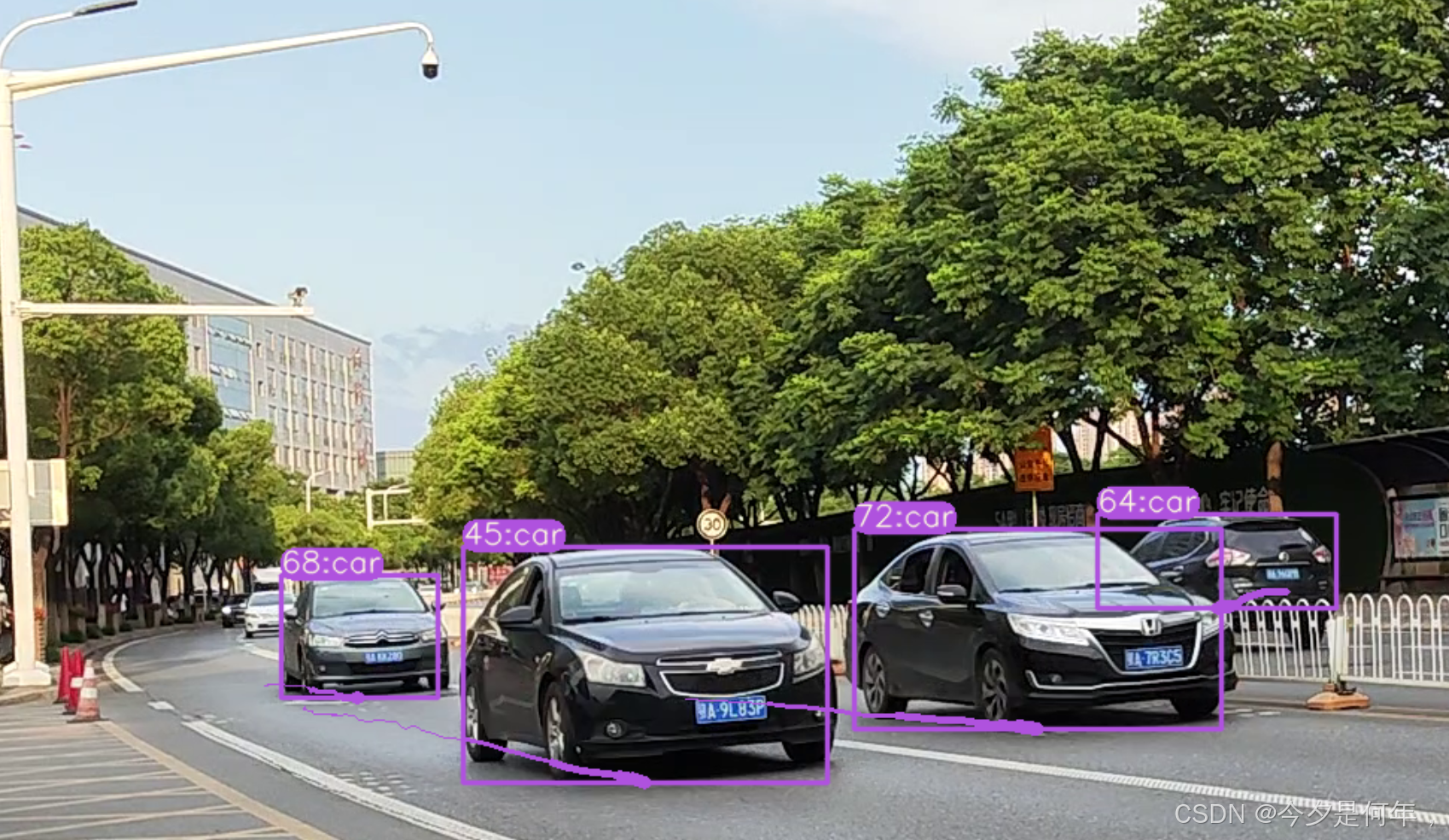
结果:
相关文章:
YOLOv8+DeepSort实现
目录 1,YOLOv8算法简介 2,DeepSort算法介绍 1. SORT目标追踪 3,实现流程 1.检测 2. 生成detections 3. 卡尔曼滤波预测 4.使用匈牙利算法将预测后的tracks和当前帧中的detections进行匹配 5. 卡尔曼滤波更新 4,代码实现 …...

「链表」链表原地算法合集:原地翻转|原地删除|原地取中|原地查重 / LeetCode 206|237|2095|287(C++)
概述 对于一张单向链表,我们总是使用双指针实现一些算法逻辑,这旨在用常量级别空间复杂度和线性时间复杂度来解决一些问题。 所谓原地算法,是指不使用额外空间的算法。 现在,我们利用双指针实现以下四种行为。 //Definition fo…...

【STM32】SPI通信和RTC实时时钟
个人主页~ SPI通信和RTC实时时钟 SPI通信一、简介二、硬件电路三、基本原理四、SPI时序1、时序基本单元2、时序 五、FLASH操作注意事项1、写入操作2、读取操作 六、SPI外设1、简介2、结构 七、传输方式1、主模式全双工连续传输2、非连续传输 RTC实时时钟一、Unix时间戳二、BKP1…...

DAMA学习笔记(十三)-大数据和数据科学
1.引言 大数据不仅指数据的量大,也指数据的种类多(结构化的和非结构化的,文档、文件、音频、视频、流数据等),以及数据产生的速度快。数据科学家是指从从数据中探究、研发预测模型、机器学习模型、规范性模型和分析方法…...
 方法详解)
【Java】Java 中的 toLowerCase() 方法详解
我最爱的那首歌最爱的angel 我到什么时候才能遇见我的angel 我最爱的那首歌最爱的angel 我不是王子也会拥有我的angel 🎵 张杰《云中的angel》 在 Java 编程中,字符串处理是一个非常常见的任务。为了便于开发者操作和格式化字符串&…...

Linux: 进程概念详解
1. 冯诺依曼体系结构 截至目前,我们所认识的计算机,都是有一个个的硬件组件组成 。 【注意】: a. 这里的存储器指的是内存 b. 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备) c.外…...
)
【C++】模板详细讲解(含反向迭代器)
欢迎来到我的Blog,点击关注哦💕 前言: C的模板在是泛型编程的重要组成部分,编写在不同类型上工作的代码,而无需为每个类型编写重复的代码,这有助于减少代码冗余并提高代码的可维护性。 模板 模板的介绍 …...

haproxy七层代理详解之-完整安装部署流程及负载均衡实现-及热更新方法
一.负载均衡 1.1负载均衡时什么 负载均衡:Load Balance,简称LB,是一种服务或基于硬件设备等实现的高可用反向代理技术,负载均网络流量等)分担给指定的一个或多个后端特定的服务器或设备,从而提高了衡将特定的业务(web服务、公司…...

C++11 bind
bind bind 用来将可调用对象和参数一起进行绑定。可调用对象包括普通函数、全局函 数、静态函数、类静态函数甚至是类成员函数,参数包括普通参数和类成员。绑定后的 结果,可以使用 std::function 进行保存,并延迟调用到我们需要的时候。 绑…...

LeetCode199 二叉树的右视图
前言 题目: 199. 二叉树的右视图 文档: 代码随想录——二叉树的右视图 编程语言: C 解题状态: 成功解决! 思路 二叉树层序遍历问题的变种,右视图即意味着二叉树每层的最后一个节点。 代码 /*** Definiti…...
——开发:数据挖掘——影响因素、直接作用、主要特征)
数据赋能(172)——开发:数据挖掘——影响因素、直接作用、主要特征
影响因素 主要影响因素如下: 数据类型与属性: 数据类型和对象的不同属性会使用不同的数据类型来描述,如年龄可能是整数类型,而生日则是日期类型。数据挖掘时需要对不同的数据类型进行不同的处理,这直接影响到挖掘算法…...

Vue:Vue3-TypeScript-Pinia-Vite-pnpm / 基础项目 / 20240807
一、项目技术栈 / 依赖 序号技术栈版本解释1node20.14.02vue 3.4.31 3vite 5.3.4 4TypeScript 5.2.2 5 types/node 22.0.2 解决TypeScript项目中缺少对应模块的类型定义文件的问题6 element-plus 2.7.8 ui组建7 types/js-cookie js-cookie 3.0.6 3.0.5 8 sass 1.77.8 9 hu…...

windows Qt 录屏 录音
启动录屏录音: connect(&m_Process, &QProcess::readyReadStandardOutput, [&]() {qDebug() << "Standard output:" << QString::fromLocal8Bit(m_Process.readAllStandardOutput()); });connect(&m_Process, &QProcess…...

AAC中的ADTS格式分析
😎 作者介绍:欢迎来到我的主页👈,我是程序员行者孙,一个热爱分享技术的制能工人。计算机本硕,人工制能研究生。公众号:AI Sun(领取大厂面经等资料),欢迎加我的…...

iOS内存管理---MRC vs ARC
系列文章目录 iOS基础—Block iOS基础—Protocol iOS基础—KVC vs KVO iOS网络—AFNetworking iOS网络—NSURLSession iOS内存管理—MRC vs ARC iOS基础—Category vs Extension iOS基础—多线程:GCD、NSThread、NSOperation iOS基础—常用三方库:Mason…...

【数学分析笔记】第1章第1节:集合(2)
这节我自己补了一些内容,要不然听不太懂陈纪修老师讲的 1. 集合与映射 1.3 子集与真子集 假如有 S \textbf{S} S和 T \textbf{T} T两个集合,其中, S \textbf{S} S的所有元素都属于 T \textbf{T} T,则称 S \textbf{S} S是 T \te…...

大话设计模式:七大设计原则
目录 一、单一职责原则(Single Responsibility Principle, SRP) 二、开放封闭原则(Open-Closed Principle, OCP) 三、依赖倒置原则(Dependency Inversion Principle, DIP) 四、里氏替换原则&am…...

利用多商家AI智能名片小程序提升消费者参与度与个性化体验:重塑零售行业的忠诚策略
摘要:在数字化浪潮席卷全球的今天,零售行业正经历着前所未有的变革。消费者对于购物体验的需求日益多样化、个性化,而零售商则面临着如何将一次性购物者转化为品牌忠诚者的巨大挑战。多商家AI智能名片小程序作为一种新兴的数字营销工具&#…...

Scala 闭包
Scala 闭包 Scala 闭包是一个非常重要的概念,它允许我们创建可以在稍后某个时间点执行的功能片段。闭包是一个函数,它捕获了封闭范围内的变量,即使在函数外部,这些变量也可以在函数内部使用。这使得闭包成为处理异步操作、回调和…...
)
前端JS总结(中)
目录 前言 正文 对象: 分类: 自定义对象: 内置对象: 重点: 常用内置对象: 字符串对象:String 获取字符串长度: 大小写转换: 获取某个字符: 截取字…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

Vue3 图片标框功能实现方案
基于 Vue3 组合式 API 的图片标框(画框、标注、选框)完整实现,核心逻辑封装在 GetBoxes 组件里,复制就能用 一、功能说明 ✅ 在图片上鼠标拖拽画矩形框 ✅ 实时显示框坐标(x, y, width, height) ✅ 支持多…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...