MySQL —— 聚合查询,分组查询 与 联合查询
聚合函数
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
|---|---|
| count() | 统计数据总数 |
| sum() | 求和 |
| avg() | 求平均值 |
| max() | 求最大值 |
| min() | 求最小值 |
注意凡是涉及运算的,数据库会自动掉 NULL 值
注意NULL 是不参与比较 max 与 min 的
解析:
以此表为例

count()
count(),会统计数据总数
使用 count(*) 会查询一共有多少条数据行

使用 count(列名),会统计该列有多少行数据

如果列中有NULL 值,则不会被统计在内

建议使用 count(*) 来统计数据行,这是SQL 标准提出的。
sum()
如果运算中有NULL 值会自动过滤NULL,因为NULL 经过运算后为 NULL这个数据是没有意义的,所以数据库的开发者们进行了这样的运算设计。

如果运算遇到非数字型数据,则无法进行运算,会报警告:

注意可以使用表达式,但是如果想分别求每一列的总分还是要分开写的。

avg()

max() 与 min()

注意NULL 是不参与比较的

实践
1.统计班级共有多少同学
select count(name) from exam;
2.统计班级收集的 math 数学成绩数据 有多少个
select count(math) from exam;
3.统计数学成绩总分
select sum(math) from exam;
4.统计所有数学成绩不及格 (< 60) 的同学的数学总分
select sum(math) from exam where math < 60;
5.统计三科的平均总分
select avg(chinese + math + english) 三科平均分 from exam;
6.返回英语最高分
select max(english) from exam;
7.返回 > 70 分以上的数学最低分
select min(math) from exam where math > 70;
分组查询
group by
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
select column1, sum(column2), .. from table group by column1,column3;
演示表:

计算每种职位的平均工资:

这里的执行顺序是先分组再计算。
拓展 round
可以使用 round(数值,小数点后的位数) 来指定数值的形式:
group by 后面可以跟 order by 子句

练习:
查询每个角色的最高工资、最低工资和平均工资
select role 职位, max(salary) 最高工资, min(salary) 最低工资 from emp group by 职位;

having
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用
HAVING
where 是对表中每一行的真实数据进行过滤的
having 是在 group by 之后,对计算结果进行过滤的。
所以两个执行顺序是不一样的,having 可以使用别名来过滤
演示:
显示平均工资低于1500的角色和它的平均工资
select role 职位, avg(salary) 平均工资 from emp group by 职位 having 平均工资 < 1500;

联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:

笛卡尔积实际上就是对数据进行全排列,举个例子,有两张表,其中一张表的一条数据要和另一张表的所有的数据进行组合:

我们也可以通过 SQL 代码来查看笛卡尔积:select * from table_name1, table_name2;

通过观察我们得知上面全排列的数据不全是正确的,那我们如果过滤掉这些无效的数据,从而获取正确的数据?
请看下面揭晓
内连接
语法格式:select 字段 from 表1 别名1, 表2 别名2 where 条件; 或者 select 字段 from 表1 别名1 [inner] join 表2 别名2 on 条件;
两个表之间存在主外键关系的话,只需要判断这两个表中主外键字段是否相同即可。
查询列表的字段 可以使用
表名.列名
我们可以通过给表名取字段的方式来减少我们的书写量。
演示:
select s.student_id, s.sn, s.name, s.mail, c.name from student s, class c where s.class_id = c.class_id;

select s.student_id, s.sn, s.name, s.mail, c.name from student s inner join class c on s.class_id = c.class_id;


当你给表取了别名之后,那就将表名的地方全部替换成别名,否则 where 子句会识别不出。
联合查询的步骤:
首先确定查询中涉及哪些表,然后对这些表取笛卡尔积,再确定连接条件与过滤条件,最后简化语句(使用别名)
实践:
查询白素贞的成绩:
首先确定需要哪些表:学生表和成绩表,取笛卡尔积:

然后确定连接条件:student_id 是相同的
确定过滤条件:姓名是白素贞
简化 sql 语句,将student 取 stu , score 取 sco
select stu.name, sco.score from student stu, score sco where name = '白素贞' and stu.student_id = sco.student_id;
select stu.name, sco.score from student stu join score sco on name = '白素贞' and stu.student_id = sco.student_id;

查询所有同学的总成绩,及同学的个人信息:
首先确定需要什么表:学生表,成绩表;然后取笛卡尔积:

然后确定连接条件与过滤条件:首先是由于需要的是总成绩,所以要使用聚合函数 sum(),那么就要使用到 分组查询 group by 子句,接着成绩表和学生表的连接是 student_id 要相同
这里要注意分组的依据,我们是对成绩表进行分组的,成绩表有学生的 id 和 成绩,那就应该是要按学生的 id 作为分组的依据。
最后简化 sql 语句 将student 取 stu , score 取 sco
select stu.name, stu.mail, sum(sco.score) from student stu, score sco where stu.student_id = sco.student_id group by sco.student_id;

查询所有同学的总成绩,及同学的个人信息 以及 学生所在的班级信息:
首先确定要几张表:学生表,班级表 以及 成绩表,然后取笛卡尔积:

然后确定连接条件与过滤条件:学生表和班级表的联系是 class_id 相同,学生表和成绩表的联系是 student_id 相同,总成绩就和上面的方式一样使用 sum() 通过 student_id 来进行分组。
然后简化 sql 语句:
select stu.sn 学号, stu.name 姓名, stu.mail 邮箱, sum(sco.score) 总成绩, c.name from student stu, score sco, class c where stu.student_id = sco.student_id and stu.class_id
= c.class_id group by sco.student_id;

外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示就是左外连接;右侧的表完全显示就是右外连接。
语法:左外连接: select 字段名 from 表名1 left join 表名2 on 连接条件; 与 右外连接: select 字段 from 表名1 right join 表名2 on 连接条件;
大家来看一下下面两张表,你会发现 3班 是没有学生的。


现在我们基于上述的式子,演示左外连接:select * from class c left join student s on c.class_id = s.class_id;

即使 3 班是没有同学的,但是3班这个字段还是会显示出来,只是对应的学生列表为空。
现在我们插入一个没有班级的学生数据:

然后我们来演示右外连接:select * from class c right join student s on c.class_id = s.class_id; 这里会将 student 表全部显示,即使有学生没有班级这个数据。

进行外连接如果遇到没有数据的时候,数据库会使用 NULL 填充。
自连接
自连接是指在同一张表连接自身进行查询。
语法:select * from 表名1 别名1, 表名1 别名2;
注意一定要起别名,不然MySQL 无法识别:

一般自连接会用在自己要和自己比较的时候
演示:
查询哪些学生的 Java 成绩 比 计算机原理要低:可以先查出Java 和 计算机原理的 course_id
select * from score s1, score s2 where s1.course_id = 1 and s2.course_id = 3 and s1.score < s2.score;

子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:
基本语法:select * from table_name where 列名 = (select 列名 from table_name where 条件);
查询与“白素贞” 同学的同班同学:select * from student where class_id = (select class_id from student where name = '白素贞');

多行子查询:
[NOT] IN
in 之前提到过就是在不在 in 括号的字段范围内
语法:select * from table_name1 where 列名 [not] in (select * from table_name2);
举例:查询 Java 和 计算机的成绩
select * from score where course_id in (select course_id from course where name = 'Java' or name = '计算机原理');

[NOT] EXISTS
exists 表示存在,如果 exists 后面括号中的查询语句,如果返回的是空结果集,那就类似flase ,不会执行外层的查询,如果返回的是 true ,就会执行外层的查询。
语法:select * from table_name where [not] exists (select * from table_name);
注意如果集合是 select null; 集合不为空(empty),只是集合内容是 null

演示:

合并查询
合并查询可以将多个结果集合并。
使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
union 【会去重】
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
union all 【不会去重】
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
查询id小于3,或者名字为“英文”的课程:



在单表查询时,推荐使用 or, 多表查询时可以使用 union 或者 union all
相关文章:
MySQL —— 聚合查询,分组查询 与 联合查询
聚合函数 常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有: 函数说明count()统计数据总数sum()求和avg()求平均值max()求最大值min()求最小值 注意凡是涉及运算的,数据库会自动掉 NULL 值 注意NULL …...

Spring声明式事务失效场景
Spring声明式事务失效场景 背景搭建测试环境测试事务失效场景Transactional 注解标注在 private 方法上异常被 catch 了,事务失效方法抛出的是受检异常,事务也会失效事务传播行为配置不合理导致事务失效 背景 Spring 针对 Java Transaction API (JTA)、…...

基于SpringBoot+UniAPP宠物食品外卖点单小程序的设计与实现》
✅博主简介:Java 全栈开发工程师,抖音优质技术创作者,日常分享实用的前端、后端、运维开发技术。 ✅技术栈:Java、SpringBoot、Vue、React、Node.js、Nest.js、Nuxt.js、uni-app ✅技术擅长:计算机毕设选题、开题报告、…...

ssrf 内网访问 伪协议 读取文件 端口扫描
SSRF(Server-Side Request Forgery,服务器侧请求伪造)是一种利用服务器发起网络请求的能力来攻击内网资源或执行其他恶意活动的技术。SSRF可以用于访问通常不可由外部直接访问的内网资源,读取文件,甚至进行端口扫描。以…...

发布包到npm
目录 注册npm账号 创建包 登录npm 上架包 更新包 删除包 注册npm账号 首先注册npm账号:npm | Sign Up (npmjs.com) 创建包 可以在桌面上新建一个文件夹:文件夹名随便起,但是别跟npm已经上架的包名重复了 可以通过下面的指令查看&…...

Python | Leetcode Python题解之第324题摆动排序II
题目: 题解: def quickSelect(a: List[int], k: int) -> int:seed(datetime.datetime.now())shuffle(a)l, r 0, len(a) - 1while l < r:pivot a[l]i, j l, r 1while True:i 1while i < r and a[i] < pivot:i 1j - 1while j > l an…...
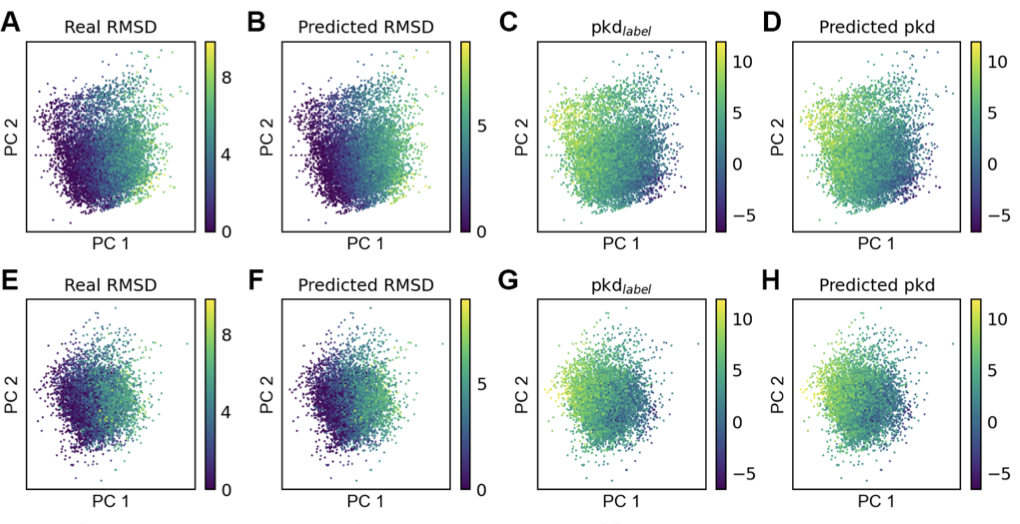
IGModel——提高基于 GNN与Attention 机制的方法在药物发现中的实用性
导言 深度学习在药物发现(发现治疗药物)领域的应用以及传统方法面临的挑战。 药物(尤其是我们将在本文中讨论的被称为抑制剂的药物)通过与在人体中发挥不良功能的蛋白质结合并改变这些蛋白质的功能来发挥治疗效果。因此…...

AArch64中的寄存器
目录 通用寄存器 其他寄存器 系统寄存器 通用寄存器 大多数A64指令在寄存器上操作。该架构提供了31个通用寄存器。 每个寄存器可以作为64位的X寄存器(X0..X30)使用,或者作为32位的W寄存器(W0..W30)使用。这两种是查…...
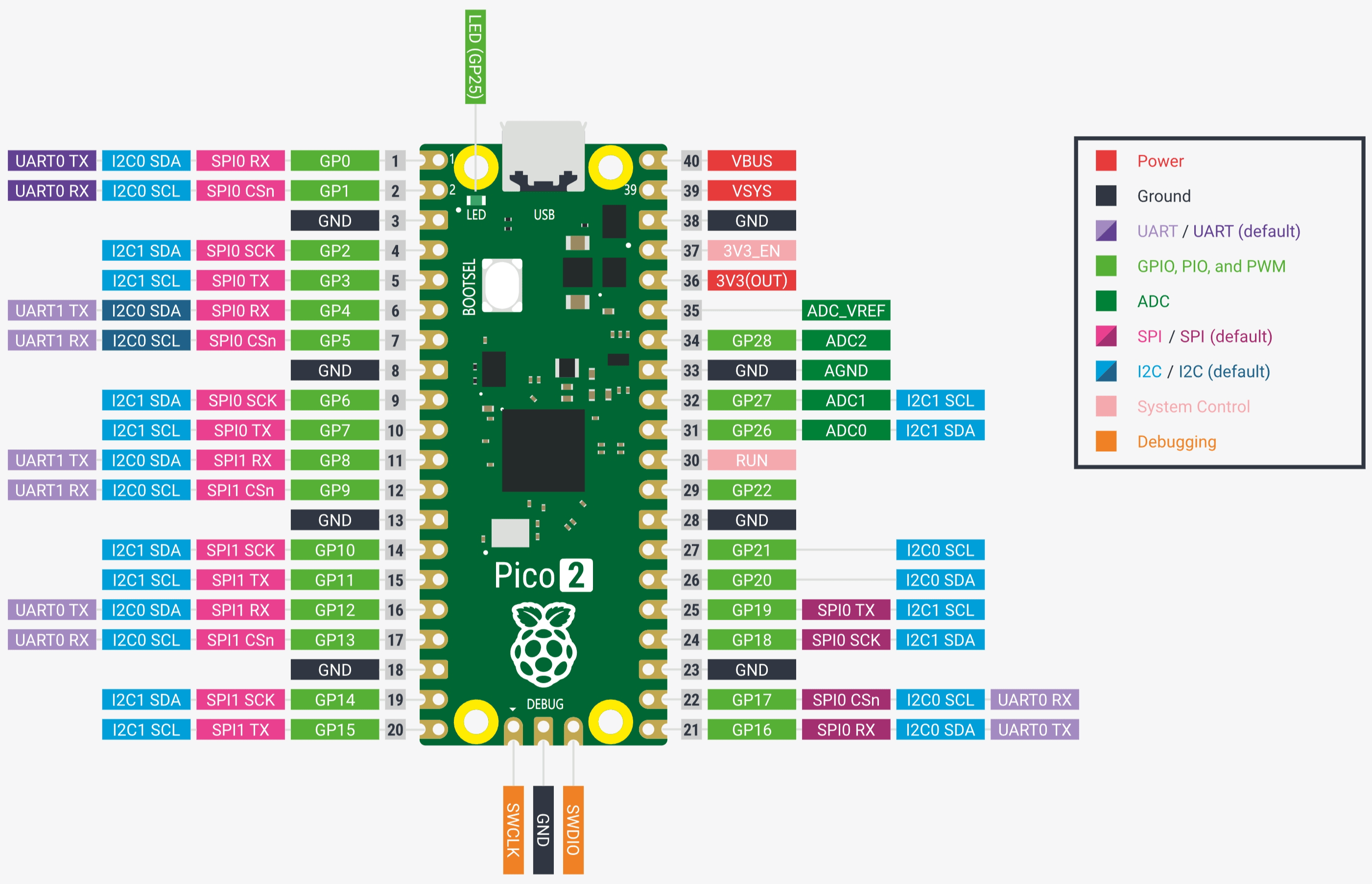
树莓派Pico 2来了
这两天开源圈的大事之一,就是树莓派基金会发布了树莓派Pico 2。 帖子原文:Raspberry Pi Pico 2, our new $5 microcontroller board, on sale now 总结一些关键信息: 产品发布:Raspberry Pi Pico 2 是 Raspberry Pi 基金会推出的…...

LeetCode面试题Day7|LeetCode135 分发糖果、LeetCode42 接雨水
题目1: 指路: . - 力扣(LeetCode)135 分发糖果 思路与分析: 给n个孩子按照评分给糖果,要求有二,其一为每个孩子最少有一颗糖果;其二为相邻孩子评分更高的糖果越多。那么在这里第…...
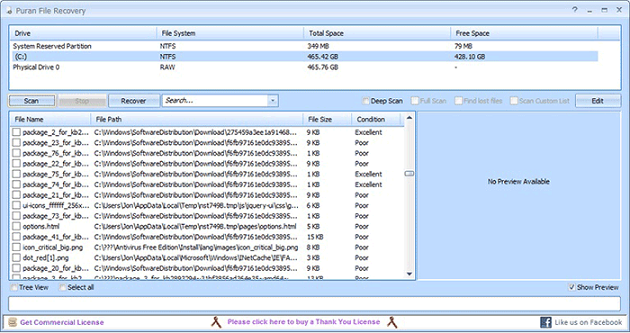
[免费]适用于 Windows 10 的十大数据恢复软件
Windows 10 是 Microsoft 开发的跨平台和设备应用程序操作系统。它启动速度更快,具有熟悉且扩展的“开始”菜单,甚至可以在多台设备上以新的方式工作。因此,Windows 10 非常受欢迎,我们用它来保存照片、音乐、文档和更多文件。但有…...

Win11+docker+vscode配置anomalib并训练自己的数据(3)
在前两篇博文中,我使用Win11+docker配置了anomalib,并成功的调用了GPU运行了示例程序。这次我准备使用anomalib训练我自己的数据集。 数据集是我在工作中收集到的火腿肠缺陷数据,与MVTec等数据不同,我的火腿肠数据来源于多台设备和多个品种,因此,它们表面的纹理与颜色差异…...

Java | Leetcode Java题解之第332题重新安排行程
题目: 题解: class Solution {Map<String, PriorityQueue<String>> map new HashMap<String, PriorityQueue<String>>();List<String> itinerary new LinkedList<String>();public List<String> findItine…...
有限公司)
招聘公告|健安环保科技(广东)有限公司
招聘岗位:销售经理 岗位职责: 对PCB线路板和电镀行业的客户,推广针对镀锡漂洗水的低浓度锡回收技术(投资运营或设备销售),并销售无耗材材的电镀智能过滤设备,达成销售目标; 任职要求: 1、大专以上学历&…...

小程序的安全设计
小程序的安全设计 安全指引 | 微信开放文档 (qq.com) 开发原则与注意事项 本文档整理了部分小程序开发中常见的安全风险和漏洞,用于帮助开发者在开发环节中发现和修复相关漏洞,避免在上线后对业务和数据造成损失。 开发者在开发环节中必须基于以下原则: 互不信任原则,不要…...

【Android】网络技术知识总结之WebView,HttpURLConnection,OKHttp,XML的pull解析方式
文章目录 webView使用步骤示例 HttpURLConnection使用步骤示例GET请求POST请求 okHttp使用步骤1. 添加依赖2. 创建OkHttpClient实例3. 创建Request对象构建请求4. 发送请求5. 获取响应 Pull解析方式1. 准备XML数据2. 创建数据类3. 使用Pull解析器解析XML webView WebView 是 An…...

Kubernetes—k8s集群存储卷(pvc存储卷)
目录 一、PVC 和 PV 1.PV 2.PVC 3.StorageClass 4.PV和PVC的生命周期 二、实操 1.创建静态pv 1.配置nfs 2.创建pv 3.创建pvc 4.结合pod,将pv、pvc一起运行 2.创建动态pv 1.上传 2.创建 Service Account,用来管理 NFS Provisioner 在 k8s …...

用网格大师转换的3D Tiles数据,在进行了顶点重建后,尝试加载到Cesium中却无法显示内容。应该如何解决这一问题?
答: 建议首先尝试使用DasViewer来打开并检查这个3D Tiles的json文件。DasViewer能够迅速加载并显示3D Tiles数据,可以帮助快速验证数据是否完整且格式正确。 网格大师是一款能够解决实景三维模型空间参考、原点、瓦块大小不统一,重叠区域处理…...

display:flex布局,最简单的案例
1. 左右贴边 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><style>#parent{width: 800px;background: red;height: 200px;display: flex;justify-content: space-between…...

SQL注入实例(sqli-labs/less-17)
0、初始网页 1、确定闭合字符 注入点在于password框,闭合字符为单引号 2、爆库名 1 and updatexml(1,concat(0x7e,database(),0x7e),1)# 1 and (select 1 from (select count(*),concat((select database()),floor(rand()*2))x from information_schema.tables gr…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

百度文心一言开发者如何通过Taotoken低成本接入多模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心一言开发者如何通过Taotoken低成本接入多模型API 对于已经熟悉并正在使用百度文心一言等国产大模型API的开发者而言&#…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...