Kafka Client客户端操作详解
文章目录
- 基础客户端版本
- 消息生产者
- 消息消费者
- 踩坑
- 客户端属性分析
- 消费者分组消费机制
- 生产者拦截器
- 消息序列化
- 消息分区路由机制
- 生产者消息缓存机制
- 发送应答机制
- 生产者消息幂等性
- 生产者消息事务
- 客户端流程总结
基础客户端版本
导入依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><spring-boot.version>2.3.12.RELEASE</spring-boot.version><fastjson.version>2.0.51</fastjson.version><!--我服务器安装的kafka版本是3.4.0 所以最好和安装版本对应--><kafka.version>3.4.0</kafka.version>
</properties><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka.version}</version>
</dependency>
消息生产者
package com.hs.kfk.basic;import org.apache.kafka.clients.producer.*;import java.util.Properties;
import java.util.concurrent.ExecutionException;/*** @Description: 基本版本的消息生产者,发送的消息就是一个简单是String* @Author 胡尚* @Date: 2024/8/7 18:33*/
public class BasicProducer {/*** 定义kafka服务端地址*/// private final static String BOOTSTRAP_SERVER = "192.168.75.61:9092,192.168.75.62:9092,192.168.75.63:9092";private final static String BOOTSTRAP_SERVER = "worker1:9092,worker2:9092,worker3:9092";/*** 生产者往哪个topic中发送消息*/private final static String TOPIC_NAME = "disTopic";public static void main(String[] args) throws ExecutionException, InterruptedException {// 设置发送者相关的属性Properties properties = new Properties();// 设置kafka端口properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);// 配置key的序列化类 去找org.apache.kafka.common.serialization.Serializer接口的实现类properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 配置value的序列化类properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 创建一个消息生产者对象Producer<String, String> producer = new KafkaProducer<>(properties);for (int i = 0; i < 5; i++) {// 构建一条消息, 构造方法中的传参是:String topic, K key, V value// 这里的key和value的泛型要和上方定义的序列化类型匹配上ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, Integer.toString(i), "MyProducer" + i);// 发送消息// 发送消息方式一:单向发送,不关心服务端的应答, 仅仅把消息发送给服务器
// producer.send(record);// 发送消息方式二: 同步发送:get()获取服务端应答消息前,会阻塞当前线程。RecordMetadata recordMetadata = producer.send(record).get();String topic = recordMetadata.topic();int partition = recordMetadata.partition();long offset = recordMetadata.offset();System.out.println("topic:" + topic + "\tpartition:" + partition + "\toffset: " + offset );// 发送消息方式三:异步发送:消息发送后不阻塞,服务端有应答后会触发回调函数
// producer.send(record, new Callback() {
// @Override
// public void onCompletion(RecordMetadata metadata, Exception exception) {
// // 使用 RecordMetadata 对象做相应的操作
// if (exception != null){
// // 消息发送失败 处理逻辑
// }
// }
// });}// 消息生产者 调用close()方法producer.close();}
}
控制台日志
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
topic:disTopic partition:0 offset: 4
topic:disTopic partition:3 offset: 4
topic:disTopic partition:0 offset: 5
topic:disTopic partition:3 offset: 5
topic:disTopic partition:1 offset: 2
消息消费者
package com.hs.kfk.basic;import org.apache.kafka.clients.consumer.*;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;/*** @Description: 基础班的消息消费方* @Author 胡尚* @Date: 2024/8/7 19:07*/
public class BasicConsumer {/*** 定义kafka服务端地址*/// private final static String BOOTSTRAP_SERVER = "192.168.75.61:9092,192.168.75.62:9092,192.168.75.63:9092";private final static String BOOTSTRAP_SERVER = "worker1:9092,worker2:9092,worker3:9092";/*** 生产者往哪个topic中发送消息*/private final static String TOPIC_NAME = "disTopic";/*** 消费者组名*/private final static String CONSUMER_GROUP = "test";public static void main(String[] args) {// 设置消费者相关的属性Properties properties = new Properties();// 设置kafka端口properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);// 每个消费者需要指定一个消费者组properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP);// 配置key的序列化类 去找org.apache.kafka.common.serialization.Deserializer接口的实现类properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 配置value的序列化类properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 创建一个消息消费者对象// 这里的key和value的泛型要和上方定义的序列化类型匹配上Consumer<String, String> consumer = new KafkaConsumer<>(properties);// 消费者可以订阅多个topicconsumer.subscribe(Arrays.asList(TOPIC_NAME));while (true) {// 消费者拉取消息 100毫秒超时时间// 这里一次拉取的是一批消息// 这里的key和value的泛型要和上方定义的序列化类型匹配上ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(100));// 处理消息for (ConsumerRecord<String, String> record : consumerRecords) {int partition = record.partition();long offset = record.offset();String topic = record.topic();String key = record.key();String message = record.value();System.out.println("topic:" + topic + "\tpartition:" + partition + "\toffset: " + offset + "\tkey: " + key + "\tmessage: " + message);}// 提交offset消息就不会重复消费//同步提交,表示必须等到offset提交完毕,再去消费下一批数据。consumer.commitSync();// 异步提交,表示发送完提交offset请求后,就开始消费下一批数据了。不用等到Broker的确认。// consumer.commitAsync();}}
}
控制台日志
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
topic:disTopic partition:3 offset: 4 key: 1 message: MyProducer1
topic:disTopic partition:3 offset: 5 key: 3 message: MyProducer3
topic:disTopic partition:1 offset: 2 key: 4 message: MyProducer4
topic:disTopic partition:0 offset: 4 key: 0 message: MyProducer0
topic:disTopic partition:0 offset: 5 key: 2 message: MyProducer2
踩坑
问题:消息生成者发送消息,一直阻塞,发送不出去,kafka也接收不到消息
生产者方面的代码
// 直接调单机测试 一个ip
private final static String BOOTSTRAP_SERVER = "192.168.75.61:9092";
private final static String TOPIC_NAME = "disTopic";public static void main(String[] args) throws ExecutionException, InterruptedException {Properties properties = new Properties();// 设置kafka端口properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);// 配置key的序列化类 去找org.apache.kafka.common.serialization.Serializer接口的实现类properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 配置value的序列化类properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 创建一个消息生产者对象Producer<String, String> producer = new KafkaProducer<>(properties);for (int i = 0; i < 5; i++) {// 构建一条消息, 构造方法中的传参是:String topic, K key, V valueProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, Integer.toString(i), "MyProducer" + i);// 发送消息方式二: 同步发送:get()获取服务端应答消息前,会阻塞当前线程。RecordMetadata recordMetadata = producer.send(record).get();String topic = recordMetadata.topic();int partition = recordMetadata.partition();long offset = recordMetadata.offset();System.out.println("topic:" + topic + "\tpartition:" + partition + "\toffset: " + offset );}// 消息生产者 调用close()方法producer.close();
}问题截图

检查kafka服务是否正常,手动启动生产者 能正常发送消息,并且Topic也存在

检查windows能不能连接linux服务器,使用telnet能连通,网络没问题

跟踪源码,看到发送消息时,Cluster对象中的确是保存了我kafka集群相关的节点信息,进一步确定网络没问题,java代码都能访问通

进入到发送消息的方法,这里也执行了

进入get()方法进行阻塞

消息也未发送至kafka,因为消费方这里还有一个窗口

问题具体的解决:
我三台 linux服务器中各自配置了域名解析
vi /etc/hosts192.168.75.61 worker1
192.168.75.62 worker2
192.168.75.63 worker3
这里和搭建kafka集群时,配置文件中中的配置没关系
而下图中也是直接返回的域名信息

接下来就在我windows上也配置了一个域名映射C:\Windows\System32\drivers\etc\hosts
192.168.75.61 worker1
192.168.75.62 worker2
192.168.75.63 worker3
现在就能正常发送接收消息了
从下图中可以发现,消费者也正常了,Topic中4个partition,其中两个分给了java应用,两个分给了控制台窗口的消费者

客户端属性分析
消费者分组消费机制
消费者消费消息时需要通过group.id参数来指定消费者组,源码中的描述如下
// 全类名org.apache.kafka.clients.CommonClientConfigs + org.apache.kafka.clients.consumer.ConsumerConfig// 标识此消费者所属的消费者组的唯一字符串。如果消费者使用<code>subscribe(topic)<code>或基于kafka的偏移量管理策略来使用组管理功能,则需要此属性。
public static final String GROUP_ID_CONFIG = "group.id";// 我们最好为每一个组成员设置一个固定的instanceId,这个参数通常可以用来减少Kafka不必要的rebalance。
// 如果不设置,每一次消费者变动,或者是网络问题,kafka都会为多个partition和consumer实例进行负载均衡,
// partition和consumer实例进行绑定,如三方最近的一张图片所示
public static final String GROUP_INSTANCE_ID_CONFIG = "group.instance.id";
我们通过消费者订阅某一个Topic就需要group.id这个参数
Consumer<String, String> consumer = new KafkaConsumer<>(properties);
// 消费者可以订阅多个topic
consumer.subscribe(Arrays.asList(TOPIC_NAME));
大致流程如下图所示,partition和某个Group中的consumer实例进行绑定

我们还可以基于kafka的偏移量管理策略的基础上,自己对offset偏移量进行扩展管理。
如果仅仅基于kafka来管理当前消费者组对某个partition的消费offset可能存在一些问题,因为这个offset是消费者通过下面两个方法调用kafka服务端再进行改变
//同步提交,表示必须等到offset提交完毕,再去消费下一批数据。
consumer.commitSync();
// 异步提交,表示发送完提交offset请求后,就开始消费下一批数据了。不用等到Broker的确认。
consumer.commitAsync();
这个关键的offset偏移量是保存在Broker中的,但是却是由“不靠谱”的客户端来主导推进的。Kafka服务端有以下的一些机制来保证服务端的稳定性。
-
如果客户端消费消息了一直不调用上方的commit方法,岂不是broker中的offset一直得不到推进?
kafka提供了一种自动提交的参数
// 如果为true,则消费者的偏移量将在后台定期提交 public static final String ENABLE_AUTO_COMMIT_CONFIG = "enable.auto.commit"; -
如果客户端瞎指定一个offset,就往kafka服务端发请求,这个offset在broker中根本就不存在
/**当Kafka中没有初始偏移量或者当前偏移量在服务器上不存在时该怎么办(例如,因为数据已被删除):earliest:自动将偏移量重置为最早的偏移量latest:自动将偏移量重置为最近的偏移量none:如果没有找到消费者组的先前偏移量则向消费者抛出异常anything else:向消费者抛出异常 */ public static final String AUTO_OFFSET_RESET_CONFIG = "auto.offset.reset"; -
消费者消费消息,Broker不会一直等待消费者的提交,如果消费者长时间不提交,Broker就会认为这个消费者挂了,此时就会把这个partition中的消息往同组的其他消费者进行投递
消息重复消费问题
消费者业务处理时间较长,此时消费者正常处理消息的过程中,Broker端就已经等不下去了,认为这个消费者处理失败了。这时就会往同组的其他消费者实例投递消息,这就造成了消息重复处理。
所有我们可以换一种思路,将Offset从Broker端抽取出来,放到第三方存储比如Redis里自行管理。这样就可以自己控制用业务的处理进度推进Offset往前更新。
我们在消费消息之前,判断当前消息的offset是否< redis中保存的offset,如果是那么就表示这一条消息已经被消费过了,就不要去消费了
redis中的key可以是:消费者组名 + Topic + partition 组成 value就是offset
伪代码如下:
// 每执行一条消息,都更新一次redis中的offset
public class RedisConsumer {private final static String BOOTSTRAP_SERVER = "worker1:9092,worker2:9092,worker3:9092";private final static String TOPIC_NAME = "disTopic";private final static String CONSUMER_GROUP = "test";public static void main(String[] args) {// 设置消费者相关的属性Properties properties = new Properties();properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP);properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 创建消费者Consumer<String, String> consumer = new KafkaConsumer<>(properties);consumer.subscribe(Arrays.asList(TOPIC_NAME));while (true) {// 消费者拉取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(100));// 处理消息for (ConsumerRecord<String, String> record : consumerRecords) {int partition = record.partition();long offset = record.offset();String topic = record.topic();String redisKey = "redisKeyPrefex" + topic + partition + CONSUMER_GROUP;String key = record.key();String message = record.value();// TODO 通过redisKey 查询redis中的offset,如果 redisOffset > offset 就表示重复消费了// TODO 消费消息// TODO 存入redis中 redisKey + offset}//异步提交。消费业务多时,异步提交有可能造成消息重复消费,通过Redis中的Offset,就可以过滤掉这一部分重复的消息。consumer.commitAsync();}}
}
改进一些的版本,按照partition来,每次去处理一个partition中的消息,一个partition中的消息处理完成后就更新一次redis中的offset
while (true) {// 消费者拉取消息ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(100));// 先获取所有的partition,然后每次取partition中的消息Set<TopicPartition> partitions = consumerRecords.partitions();partitions.forEach(partition -> {String redisKey = "redisKeyPrefex" +partition.topic() + partition.partition() + CONSUMER_GROUP;// TODO 根据redisKey 从redis中 获取这个消费者组下 这个partition对应的offset// 获取当前partition中所有的消息List<ConsumerRecord<String, String>> records = consumerRecords.records(partition);for (ConsumerRecord<String, String> record : records) {long offset = record.offset();// TODO 如果 redisOffset > offset 就表示重复消费了// TODO 消费消息}// 获取当前partition 多个消息中的最后一个offsetlong offset = records.get(records.size() - 1).offset();// TODO 根据redisKey,将上方的offset存入redis中});//异步提交。消费业务多时,异步提交有可能造成消息重复消费,通过Redis中的Offset,就可以过滤掉这一部分重复的消息。consumer.commitAsync();
}
继续改进,添加线程池去消费消息
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.data.redis.core.RedisTemplate;import javax.annotation.Resource;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;/*** 基于Redis管理消费者Offset,防止消息重复处理。* 伪代码,就不去具体实现了。*/
public class RedisConsumer {@Resourceprivate RedisTemplate redisTemplate;Logger logger = LoggerFactory.getLogger(RedisConsumer.class);//计算密集型任务private final static int CORES = 2* Runtime.getRuntime().availableProcessors();public static final String REDIS_PREFEX = "myoffset_";private volatile boolean IF_SLEEP = false;private volatile boolean RUNNING = true;private final ThreadPoolExecutor executorService;private String servers;private String topic;private String group;private final KafkaConsumer<String,String> consumer;public RedisConsumer(String servers,String topic,String group){this.servers = servers;this.topic = topic;this.group = group;executorService = (ThreadPoolExecutor) Executors.newFixedThreadPool(CORES,new ThreadFactory(){private final AtomicInteger threadNumber = new AtomicInteger();@Overridepublic Thread newThread(Runnable r) {return new Thread(null,r,"RedisConsumer_"+threadNumber.getAndIncrement());}});Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 45000);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, 500);//props.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, 1);props.put(ConsumerConfig.RECEIVE_BUFFER_CONFIG, 64 * 1024);props.put(ConsumerConfig.GROUP_ID_CONFIG,group);consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList(topic.split(",")));}public void doTask(){try{while (RUNNING){try{if(!IF_SLEEP){ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));records.partitions().forEach(partition ->{//从redis获取偏移量String redisKafkaOffset = redisTemplate.opsForHash().get(REDIS_PREFEX + partition.topic(),"" + partition.partition()).toString();long redisOffset = (null==redisKafkaOffset||"".equals(redisKafkaOffset))?-1:Long.valueOf(redisKafkaOffset);List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);logger.info("[pull partition] topic:{}, partition:{}, records size:{}", partition.topic(),partition.partition(), partitionRecords.size());partitionRecords.forEach(record ->{//redis记录的偏移量>=kafka实际的偏移量,表示已经消费过了,则丢弃。if(redisOffset >= record.offset()){logger.error("[pool discard] group id:{}, offset:{}, redisOffset:{} ,value:{}", group, record.offset(), redisOffset, record.value());return;}executorService.execute(()->{doMessage(record.topic(),record.value());});});//保存Redis偏移量long saveRedisOffset = partitionRecords.get(partitionRecords.size()-1).offset();redisTemplate.opsForHash().put(REDIS_PREFEX + partition.topic(),"" + partition.partition(),saveRedisOffset);});//异步提交。消费业务多时,异步提交有可能造成消息重复消费,通过Redis中的Offset,就可以过滤掉这一部分重复的消息。consumer.commitAsync();}}catch (Throwable e) {logger.warn("[consumer exception] {}", e);}}}catch (Throwable e) {logger.warn("[huge exception] to finish. {}", e);} finally {executorService.shutdown();try {executorService.awaitTermination(5, TimeUnit.SECONDS);logger.warn("[wait finish] RedisConsumer time beyond {}.", 5);} catch (InterruptedException e) {logger.warn("[wait finish exception] RedisConsumer e:{}.", e);}executorService.shutdownNow();consumer.close();logger.warn("[finish consumer] topic:{}, groupId:{}.", topic, group);}}//实际处理请求。通常可以交给子实现类去做。private void doMessage(String topic,String value){System.out.println("[deal message] topic : "+topic + "; value = "+value);}
}
生产者拦截器
生产者拦截机制允许客户端在生产者在消息发送到Kafka集群之前,对消息进行拦截,甚至可以修改消息内容。
// 我们自定义的拦截器需要实现org.apache.kafka.clients.producer.ProducerInterceptor接口,默认情况下是没有拦截器的
public static final String INTERCEPTOR_CLASSES_CONFIG = "interceptor.classes";
自定义一个拦截器
public class MyInterceptor implements ProducerInterceptor {@Overridepublic ProducerRecord onSend(ProducerRecord record) {System.out.println("send(ProducerRecord, Callback)方法,在key和value被序列化和分配分区partition之前调用");// 我们可以对record做相应的处理return record;}@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {System.out.println("当发送到服务器的记录已被确认/发送记录在发送到服务器之前失败/KafkaProducer.send()抛出异常时也会调用。");}@Overridepublic void close() {System.out.println("连接关闭时会被调用");}@Overridepublic void configure(Map<String, ?> configs) {System.out.println("整理配置项");System.out.println("=====config start======");for (Map.Entry<String, ?> entry : configs.entrySet()) {System.out.println("entry.key:"+entry.getKey()+" /t === entry.value: "+entry.getValue());}System.out.println("=====config end======");}
}
然后在生产者中指定拦截器类(多个拦截器类,用逗号隔开)
Properties properties = new Properties();
properties.setProperty(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.hs.kfk.intercepter.MyInterceptor");
测试发送消息,控制台打印结果如下
整理配置项
=====config start======
entry.key:interceptor.classes === entry.value: com.hs.kfk.intercepter.MyInterceptor
entry.key:bootstrap.servers === entry.value: 192.168.75.61:9092,192.168.75.62:9092,192.168.75.63:9092
entry.key:value.serializer === entry.value: org.apache.kafka.common.serialization.StringSerializer
entry.key:key.serializer === entry.value: org.apache.kafka.common.serialization.StringSerializer
entry.key:client.id === entry.value: producer-1
=====config end======send(ProducerRecord, Callback)方法,在key和value被序列化和分配分区partition之前调用
当发送到服务器的记录已被确认/发送记录在发送到服务器之前失败/KafkaProducer.send()抛出异常时也会调用。
topic:disTopic partition:0 offset: 11send(ProducerRecord, Callback)方法,在key和value被序列化和分配分区partition之前调用
当发送到服务器的记录已被确认/发送记录在发送到服务器之前失败/KafkaProducer.send()抛出异常时也会调用。
topic:disTopic partition:3 offset: 11send(ProducerRecord, Callback)方法,在key和value被序列化和分配分区partition之前调用
当发送到服务器的记录已被确认/发送记录在发送到服务器之前失败/KafkaProducer.send()抛出异常时也会调用。
topic:disTopic partition:0 offset: 12send(ProducerRecord, Callback)方法,在key和value被序列化和分配分区partition之前调用
当发送到服务器的记录已被确认/发送记录在发送到服务器之前失败/KafkaProducer.send()抛出异常时也会调用。
topic:disTopic partition:3 offset: 12send(ProducerRecord, Callback)方法,在key和value被序列化和分配分区partition之前调用
当发送到服务器的记录已被确认/发送记录在发送到服务器之前失败/KafkaProducer.send()抛出异常时也会调用。
topic:disTopic partition:1 offset: 5连接关闭时会被调用
消息序列化
之前的入门案例中就用到了这两个参数
// 消息生产者方 全类名 org.apache.kafka.clients.producer.ProducerConfig
// Serializer class for key that implements the <code>org.apache.kafka.common.serialization.Serializer</code> interface.
public static final String KEY_SERIALIZER_CLASS_CONFIG = "key.serializer";// Serializer class for value that implements the <code>org.apache.kafka.common.serialization.Serializer</code> interface.
public static final String VALUE_SERIALIZER_CLASS_CONFIG = "value.serializer";
// 消息消费者方 全类名 org.apache.kafka.clients.consumer.ConsumerConfig
// Deserializer class for key that implements the <code>org.apache.kafka.common.serialization.Deserializer</code> interface.
public static final String KEY_DESERIALIZER_CLASS_CONFIG = "key.deserializer";// Deserializer class for value that implements the <code>org.apache.kafka.common.serialization.Deserializer</code> interface.
public static final String VALUE_DESERIALIZER_CLASS_CONFIG = "value.deserializer";
消息生产者再发送消息时,就是通过这里指定的key 和 value的序列化类,对我们指定的消息keyvalue和 进行序列化,转换为二进制数组进行网络传输。
如果生产者没有指定消息的key,那么Kafka默认按照轮训的方式选择该消息应该发送到哪一个partition中,如果指定了key就会可以的hash再去选择partition
消息消费方拉取消息后,就会通过指定的key 和 value的反序列化类,将字节数组转换为原始类型
在大部分的场景下,传输String就已经能够满足业务需求了,当然也可以自己定制序列化与反序列化类。
因为最终传输的数据是字节数组,对于一个POJO类型的对象,我们就可以分为定长的基础类型和不定长的引用类型来分别处理,不定长类型我们可以先保存该数据的实际长度,再保存该数据。比如User类
public class User {private Long uId;private String username;private Integer age;
}
创建一个序列化类
package com.hs.kfk.serializer;import org.apache.kafka.common.serialization.Serializer;import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;/*** @Description: User序列化类* @Author 胡尚* @Date: 2024/8/8 12:41*/
public class UserSerializer implements Serializer<User> {@Overridepublic byte[] serialize(String topic, User data) {// 简单粗暴的方式 直接转json// byte[] bytes = JSON.toJSON(data).toString().getBytes(StandardCharsets.UTF_8);// 传输效率更高的方式byte[] userNameBytes = data.getUsername().getBytes(StandardCharsets.UTF_8);// id:Long8字节 + 4字节保存不定长长度 + username不定长长度 + age int 4字节int cap = 8 + 4 + userNameBytes.length + 4;ByteBuffer byteBuffer = ByteBuffer.allocate(cap);byteBuffer.putLong(data.getuId());byteBuffer.putInt(userNameBytes.length);byteBuffer.put(userNameBytes);byteBuffer.putInt(data.getAge());return byteBuffer.array();}
}
反序列化类
package com.hs.kfk.serializer;import org.apache.kafka.common.serialization.Deserializer;import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;/*** @Description: User对象的反序列化类,按位取值* @Author 胡尚* @Date: 2024/8/8 12:52*/
public class UserDeserializer implements Deserializer<User> {@Overridepublic User deserialize(String topic, byte[] data) {// 简单粗暴的序列化
// return JSON.parseObject(data, User.class);ByteBuffer byteBuffer = ByteBuffer.wrap(data);long uid = byteBuffer.getLong();int userNameSize = byteBuffer.getInt();String username = new String(byteBuffer.get(data, 8 + 4, userNameSize).array(), StandardCharsets.UTF_8).trim();int age = byteBuffer.getInt();return new User(uid, username, age);}
}
消息生产者和消费者再指定相应的序列号与反序列化类
// 消息生产者 配置value的序列化类
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "com.hs.kfk.serializer.UserSerializer");// 消息消费者 配置value的反序列化类
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "com.hs.kfk.serializer.UserDeserializer");
消息分区路由机制
两个问题:
- producer生产消息,是如何根据key选择partition的
- consumer消费者端是否也提供了选择partition的机制。
首先是producer端
public static final String PARTITIONER_CLASS_CONFIG = "partitioner.class";
如果我们想自己实现partition选择策略的话就需要实现org.apache.kafka.clients.producer.Partitioner接口
如下图所示,Kafka提供了三种实现RoundRobinPartitioner,DefaultPartitioner和UniformStickyPartitioner

-
Kafka默认机制是给一个生产者分配了一个分区后,会尽可能一直使用这个分区。直到该分区至少产生
String BATCH_SIZE_CONFIG = "batch.size"(默认16KB)。它的工作策略是:-
如果没有指定分区,但存在一个键,则根据键的散列选择一个分区
-
如果没有分区或键,则选择在至少向分区生成
batch.size字节后,在往其他partition发送
-
-
RoundRobinPartitioner是在各个Partition中进行轮询发送,这种方式没有考虑到消息大小以及各个Broker性能差异,用得比较少。
consumer消费者端
public static final String PARTITION_ASSIGNMENT_STRATEGY_CONFIG = "partition.assignment.strategy";
如果想自定义则需要实现ConsumerPartitionAssignor接口,或者是继承AbstractPartitionAssignor抽象类
Kafka默认提供的消费者的分区分配策略
- range策略: 比如一个Topic有10个Partiton(partition 0~9) 一个消费者组下有三个Consumer(consumer13)。Range策略就会将分区03分给一个Consumer,46给一个Consumer,79给一个Consumer。
- round-robin策略:轮询分配策略,可以理解为在Consumer中一个一个轮流分配分区。比如0,3,6,9分区给一个Consumer,1,4,7分区给一个Consumer,然后2,5,8给一个Consumer
- sticky策略:粘性策略。
- 在开始分区时,尽量保持分区的分配均匀。比如按照Range策略分
- 分区的分配尽可能的与上一次分配的保持一致。比如在range分区的情况下,第三个Consumer的服务宕机了,那么按照sticky策略,就会保持consumer1和consumer2原有的分区分配情况。然后将consumer3分配的7~9分区尽量平均的分配到另外两个consumer上。这种粘性策略可以很好的保持Consumer的数据稳定性。
默认采用的是RangeAssignor+CooperativeStickyAssignor分配策略
生产者消息缓存机制
消息并不是一条一条的往Kafka服务端发送的,producer端存在一个高速缓存,将消息集中到缓存中后,批量进行发送。
其中涉及到了RecordAccumulator和Sender
int batchSize = Math.max(1, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG));
this.accumulator = new RecordAccumulator(......);
其中RecordAccumulator就是生产者这边的消息累加器,它会针对每一个partition维护一个Dqueue双端队列,每个Dequeue里会放入若干个ProducerBatch数据。生产者生产的消息经过分区路由机制后会被分配到对应的Dqueue中的某一个ProducerBatch中
// 发送消息缓冲总内存,默认32M
public static final String BUFFER_MEMORY_CONFIG = "buffer.memory";
// ProducerBatch大小,默认16KB,前文消息分区路由机制中也涉及到了该参数
public static final String BATCH_SIZE_CONFIG = "batch.size";
// 如果生产消息速度 > 缓存发送消息给服务器速度,那么生产者将阻塞 MAX_BLOCK_MS_CONFIG 后抛异常 ,默认60秒
public static final String MAX_BLOCK_MS_CONFIG = "max.block.ms";

每一个消息生产者都有一个 Sender发送消息的线程,该线程将RecordAccumulator中的Dqueue中的ProducerBatch发送给Kafka。
- Sender什么时候会从RecordAccumulator中取消息
- Sender读取ProducerBatch后,以Broker为key放入队列中,队列能放多少ProducerBatch
Sender只会从RecordAccumulator中获取内存达到String BATCH_SIZE_CONFIG = "batch.size"大小的ProducerBatch;当然也有可能消息生产频率不高,比较长时间都达不到batch.size,Sender也不会一直等待,最多等待String LINGER_MS_CONFIG = "linger.ms"时长就会去将ProducerBatch中的消息读取出来。linger.ms默认值是0,表示不会有等待时间,基本上生产一条消息就发一条消息。
Sender读取ProducerBatch后,以Broker为key缓存到一个对应的队列当中。这些队列当中的消息就称为InflightRequest。接下来这些Inflight就会发往Kafka对应的Broker中,直到收到Broker的ack应答,才会从队列中移除。这些队列也并不会无限缓存,最多缓存String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection"; 默认5
// Sender 等待ProducerBatch这一批消息的最大时长
public static final String LINGER_MS_CONFIG = "linger.ms";// 保存未ack确定批量消息的最大个数,默认是5,该没配置项必须>1 并且必须开启幂等性,如果开启幂等性该配置项的取值范围是(1,5]
public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection";

最后,Sender会通过其中的一个Selector组件完成与Kafka的IO请求,并接收Kafka的响应。
// org.apache.kafka.clients.producer.KafkaProducer#doSend
if (result.batchIsFull || result.newBatchCreated) {log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());this.sender.wakeup();
}
这一章就涉及到了两个知识点:Broker的ack应答、消息的幂等性
发送应答机制
Producer生产的消息发送到Broker后,Broker会发送一个ack应答给producer,producer才确认这一批ProducerBatch消息发送成功。
这其中涉及到了下面这个参数
public static final String ACKS_CONFIG = "acks";
-
acks=0
producer 将不等待Kafka的ack应答,producer也就拿不到partition等数据,offset还一直返回-1
-
acks=1
表示Leader partition将消息写入到了本地即可,不需等待其他follower partition的应答。缺点是Leader在同步该条消息之前宕机了,那么这条消息就不会同步到其他Follower上
-
acks=all 或者 acks=-1
等待整个partition副本集的ack应答。
这里可以和Kafka服务端的一个参数配合使用
min.insync.replicas,控制Leader Partition在完成多少个Partition的消息写入后,往Producer返回响应。这个参数需要再
config/server.properties文件中指定
生产者消息幂等性
上方生产者消息缓存机制中,下面这个参数必须开启幂等性idempotence
// 保存未ack确定消息的最大个数,默认是5,该没配置项必须>1 并且必须开启幂等性,如果开启幂等性该配置项的取值范围是(1,5]
public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection";
我们生产者发送应答机制acks=1或-1时,就一定要等待Broker端的应答,如下图所示,存在两次网络io,一次发送消息,一次ack应答
如果因为网络问题,producer没有接收到Broker的ack应答,它就认为这批消息发送失败了,就重新发送,默认重试次数String RETRIES_CONFIG = "retries" 默认值是Integer.MAX。。那么Broker端应该如何不重复保存多条消息呢? 这就涉及到了幂等性问题了

幂等性相关的参数如下
// 值为 true 或 false
// 如果要开启幂等性,那么生产者消息缓存机制中的 max.in.flight.requests.per.connection <=5 并且 重试次数retries>0 并且 应答机制中的acks必须为all
public static final String ENABLE_IDEMPOTENCE_CONFIG = "enable.idempotence";
- 如果没有设置冲突配置,则默认启用幂等性。
- 如果设置了冲突的配置,并且幂等性没有显式启用,则幂等性被禁用。
- 即显示开启的幂等性,又有冲突配置,就抛异常
分布式数据传递过程中的三个数据语义:
- at-leatst-once 最少一次
- at-most-once 最多一次
- exactly-once 精确一次
案例介绍:
你往银行中存100元,数据存入MQ时,这一步不能出现消息丢失,不然你肯定不满意,如果没有收到服务端的ack应答就一直重试,直到收到ack应答,这就是at-leatst-once 最少一次;你只存了100元,肯定不能有多条数据,多了银行肯定不满意,这就是at-most-once 最多一次;最终为了让双方都满意,也就必须是exactly-once 精确一次才行。
再对应到Kafka中,acks=0,这就保证了at-most-once 最多一次;acks=1或-1这就保证了at-leatst-once 最少一次;可是acks就只有一个,不管这么设置都不行,所以最终通过幂等性才能保证exactly-once 精确一次
Kafka保证消息幂等性的概念
- PID。为每一个producer都生成一个PID,这个PID对producer是不可见的
- Sequence Number。对于每一个PID,也就是producer针对Topic下的partition都会维护一个Sequence Number。初始值0,当要往同一个partition发送消息时+1。 producer每次发送消息都会携带PID和Sequence Number。
- SN。Broker会针对
<PID, Sequence Number>维护一个序列号SN。Broker接收到消息时就会先进行比较 Sequence Number = SN +1 才会去进行消息保存的逻辑,并且对应SN+1。如果Sequence Number < SN +1 就表示消息重复发送,重新应答即可,如果Sequence Number > SN +1就表示中间有消息丢失,给producer抛异常OutOfOrderSequenceException

生产者消息事务
消息的幂等性只能保证一个producer往一个partition写入消息的幂等性。而我们从生产者消息缓存机制中可知,producer每次发送的是一批消息ProducerBatch。而这一批消息的key是不同的,也就是说这里会往多个partition中发送消息,而多个partition是会分布在不同的Broker中的,那么现在就需要producer和多个Broker都要保证消息幂等性。
进而就引申出来消息事务的概念。Kafka中消息事务相关的api方法如下所示
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 提交事务
void commitTransaction() throws ProducerFencedException;
// 4 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
案例
package com.hs.kfk.transaction;import org.apache.kafka.clients.producer.*;import java.util.Properties;
import java.util.concurrent.ExecutionException;/*** @Description: 消息事务机制* @Author 胡尚* @Date: 2024/8/7 18:33*/
public class TransactionProducer {private final static String BOOTSTRAP_SERVER = "192.168.75.61:9092,192.168.75.62:9092,192.168.75.63:9092";private final static String TOPIC_NAME = "disTopic";public static void main(String[] args) {Properties properties = new Properties();properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 指定一个消息事务id, 可以随意指定properties.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "123");// 创建一个消息生产者对象Producer<String, String> producer = new KafkaProducer<>(properties);// 初始化事务 并 开启事务producer.initTransactions();producer.beginTransaction();try {for (int i = 0; i < 5; i++) {// 异步发送消息,当发送到id=3的消息时 抛异常ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, Integer.toString(i), "MyProducer" + i);producer.send(record);if (i == 3) {throw new NullPointerException();}}// 提交事务producer.commitTransaction();} catch (Exception e) {// 回滚事务System.out.println("出异常啦!!!");producer.abortTransaction();} finally {producer.close();}}
}
我们可以进行测试,此时再启动一个消费者,它也是不会消费到 i=0 i=1 i=2 这三条消息的。这一批消息都回滚了。
- 一个事务id只会对应一个PID; 如果当前一个Producer的事务没有提交,而另一个新的Producer保持相同的TransactionId,这时旧的生产者会立即失效,无法继续发送消息。
- 跨会话事务对齐;如果某个Producer实例异常宕机了,事务没有被正常提交。那么新的TransactionId相同的Producer实例会对旧的事务进行补齐。保证旧事务要么提交,要么终止。这样新的Producer实例就可以以一个正常的状态开始工作。
生产者的事务消息机制保证了Producer发送消息的安全性,但是,他并不保证已经提交的消息就一定能被所有消费者消费。
客户端流程总结
高清在线流程图

相关文章:
Kafka Client客户端操作详解
文章目录 基础客户端版本消息生产者消息消费者踩坑 客户端属性分析消费者分组消费机制生产者拦截器消息序列化消息分区路由机制生产者消息缓存机制发送应答机制生产者消息幂等性生产者消息事务 客户端流程总结 基础客户端版本 导入依赖 <properties><project.build.…...

【HarmonyOS NEXT星河版开发学习】小型测试案例15-博客列表
个人主页→VON 收录专栏→鸿蒙开发小型案例总结 基础语法部分会发布于github 和 gitee上面(暂未发布) 前言 该案例主要是ForEach渲染的练习,ForEach可以基于数组的个数,渲染组件个数(简化代码) 在…...

go-zero中统一返回前端数据格式的几种方式
方式一、直接定义一个成功和失败的方法,在代码里面修改(对代码有侵入,每次都要修改代码) 1、封装一个统一返回的方法 package utilsimport ("github.com/zeromicro/go-zero/rest/httpx""net/http" )type Body struct {Code int json:"code…...

【向量数据库】Ubuntu编译安装FAISS
参考官方的安装指导:https://github.com/facebookresearch/faiss/blob/main/INSTALL.md,不需要安装的可以跳过 ~$ wget https://github.com/facebookresearch/faiss/archive/refs/tags/v1.8.0.tar.gz ~$ tar -zxvf v1.8.0.tar.gz ~$ cd faiss-1.8.0 ~$ …...
制造知识普及(九)--企业内部物料编码(IPN)与制造商物料编码(MPN)
在日常的物料管理业务逻辑中,一物一码是物料管理的基本的业务规则,不管物料从产品开发还是仓库管理,甚至成本核算,都要遵循这个原则,才能保证产品数据的准确性,才具备唯一追溯的可行性。大部分企业都是这种…...

【整数规划】+【0—1规划】解决优化类问题(Matlab代码)
目录 文章目录 前言 一、整数规划 分类: 二、典例讲解 1.背包问题 2.指派问题 总结 前言 如果觉得本篇文章还不错的话,给作者点个赞鼓励一下吧😁😁😁 在规划问题中,有些最优解可能是分数或小数&am…...

Linux下如何使用Curl进行网络请求
在Linux系统上,Curl是一个非常强大的网络请求工具,可以用于发送各种类型的HTTP请求,并获取响应结果。它支持常见的HTTP方法,如GET、POST、PUT、DELETE等,还支持HTTPS、FTP等不同协议。Curl提供了丰富的参数选项&#x…...

PostgreSQL 触发器
PostgreSQL 触发器 PostgreSQL触发器是一种强大的数据库对象,它可以在特定的数据库事件发生时自动执行预定义的操作。这些事件可以是插入、更新或删除表中的行。触发器通常用于强制复杂的业务规则、提供审计跟踪、数据同步以及实现复杂的约束。 触发器的基本概念 …...

LeetCode——3131.找出与数组相加的整数I
通过万岁!!! 题目:给你两个数组nums1和nums2,然后让你找一个数,使得nums1的数加上这个数以后得到的数组nums1’与nums2是相同的。注意这里只要元素相同就好了,不一定顺序相同。思路:…...

【SpringMVC】详细了解SpringMVC中WEB-INF 目录资源,视图解析器和静态资源放行的使用。
目录 1. 回顾SpringMVC请求转发和重定向 2. WEB-INF资源目录 3. 视图解析器 4. 静态资源放行 1. 回顾SpringMVC请求转发和重定向 概念:在一个项目中功能非常多,也就意味着有非常多的Servlet,不同的Servlet的职不 同 ,而用户发起…...

如何学好uni-app
学习uni-app需要掌握以下技能: 1. 前端基础:熟悉HTML、CSS和JavaScript等前端开发技术,了解基本的前端框架如Vue.js。 2. Vue.js:因为uni-app是基于Vue.js构建的,所以需要对Vue.js有深入的理解。可以先通过官方文档或者…...

C++ QT使用stackwidget实现页面切换(含源码)
C++ QT使用stackwidget实现页面切换(含源码) 0.前言1.UI布局1.1使用stackwidget2.代码方式添加页面实现页面切换3.源码4.最终效果0.前言 在QT中一个界面中如何实现页面的切换,而不是新弹出的窗口,这里采用的stackwidget,以层叠widget的方式选定页面索引从而实现页面切换。…...

打工人上班适合用的蓝牙耳机推荐?几款开放式耳机推荐
日常工作的话,我还是比较推荐开放式蓝牙耳机的,它特别适合那些需要在长时间工作中保持专注和舒适度的环境,那开放式耳机其实还有一些主要的优点: 减少耳朵疲劳:由于开放式耳机不需要紧密贴合耳朵,因此可以…...
一款.NET开发的AI无损放大工具
一款.NET开发的AI无损放大工具 思维导航 前言项目功能支持语言系统要求项目源代码项目运行小图片进行无损放大项目源码地址优秀项目和框架精选 前言 今天大姚给大家分享一款由.NET开源(GPL-3.0 license)、基于腾讯ARC Lab提供的Real-ESRGAN模型开发的A…...

编程新手必看:彻底理解!与~的取反操作
在编程和计算机科学的语境中,! 和 ~ 都是取反操作符,但它们的应用方式和效果存在显著的区别。下面将从定义、应用场景、作用原理及示例等方面对 ! 和 ~ 进行详细解析。 一、定义 !(逻辑非运算符) 在C语言、Java等多数编程语言中&…...

【LeetCode】54. 螺旋矩阵
螺旋矩阵 题目描述: 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5]示例 2:…...

计算机毕业设计 奖学金评定管理系统 Java+SpringBoot+Vue 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

【JavaWeb项目】——外卖订餐系统之商家添加餐品、修改餐品、查询热卖餐品、查询出售车、进行发货操作
🎼个人主页:【Y小夜】 😎作者简介:一位双非学校的大二学生,编程爱好者, 专注于基础和实战分享,欢迎私信咨询! 🎆入门专栏:🎇【MySQL࿰…...

制作抖音私信卡片 - 一键调起并跳转微信二维码
抖音私信图文卡片,点击可以直接一键添加微信 可生成无风险链接,使用苹果手机转发创建出卡片 抖音内点击可以直接调起微信跳入小程序展示微信二维码...
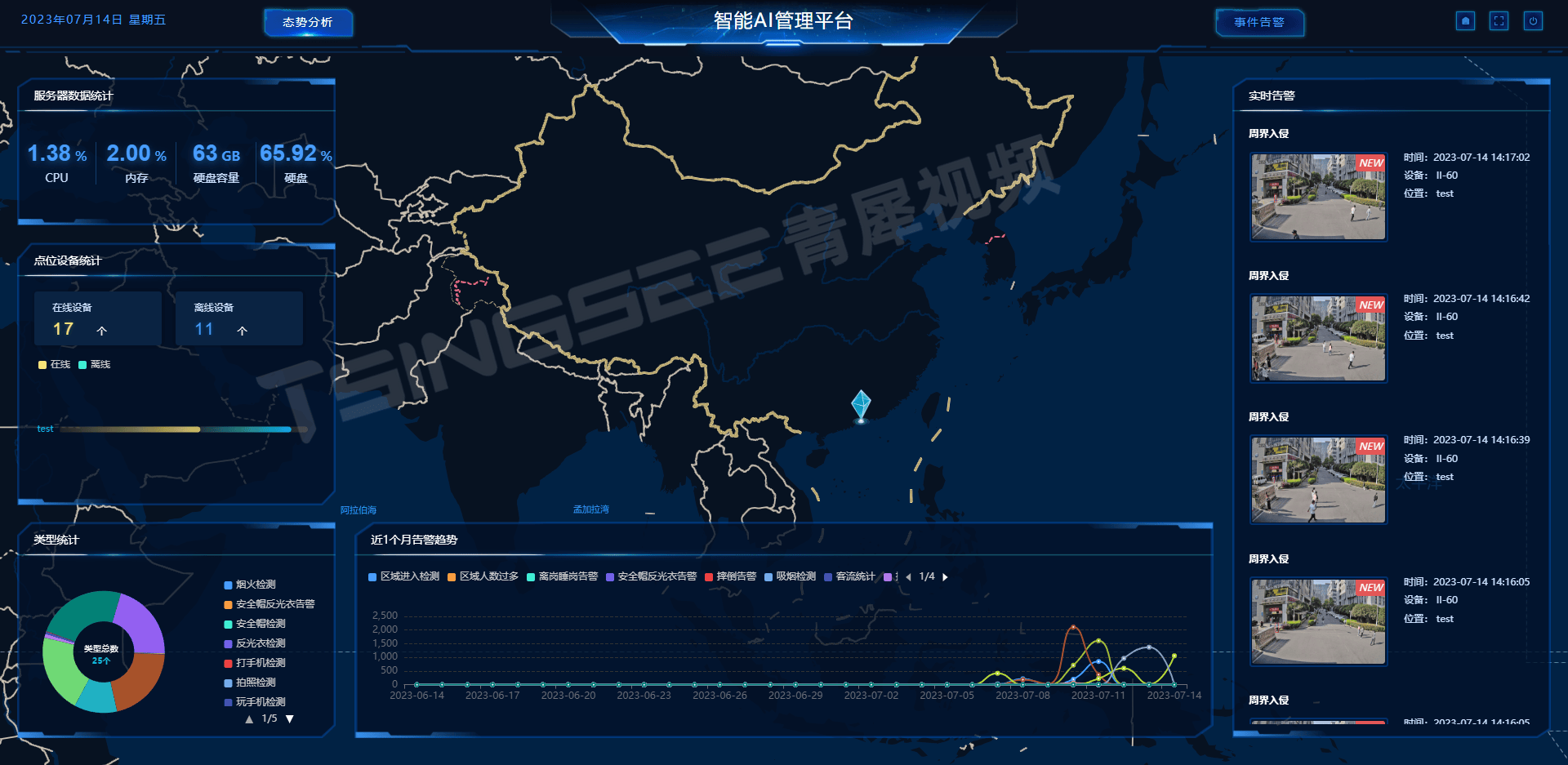
赋能未来园区:TSINGSEE视频AI智能管理平台如何引领园区管理智慧化转型
一、建设背景 随着经济的不断发展,园区产业集聚发展已成为趋势,园区逐渐成为产业聚集的重要载体。目前,国内现有的大部分园区的管理方式比较粗放、单一,范围局限于安全、环境等方面且不成体系,并且没有覆盖到应急、消…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

集成Taotoken为OpenClaw工作流提供持久化模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 集成Taotoken为OpenClaw工作流提供持久化模型支持 在构建基于OpenClaw的自动化Agent工作流时,一个稳定且可灵活切换的模…...