深入InnoDB核心:揭秘B+树在数据库索引中的高效应用
目录
一、索引页与数据行的紧密关联
(一)数据页的双向链表结构
(二)记录行的单向链表结构
二、未创建索引情况
(一)无索引下的单页查找过程
以主键为搜索条件
以非主键列为搜索条件
(二)无索引下的多页查找过程
三、InnoDB中的B+ 树索引方案初体会
(一)前置说明
行格式示意图
页内格式示意图
(二)目录项记录与用户记录的区别及其存储
目录项放到数据页
查找主键为20的记录
(三)分配新目录项记录页
更新后的数据页结构
查找主键值为20的记录的步骤
确定目录项记录页
通过目录项记录页确定用户记录所在的页
在用户记录页中定位具体记录
(四)多级目录项记录页的介绍
高级目录页说明
高级目录页(页33)
页30(目录项记录页)
页32(目录项记录页)
查找主键值为20的记录的步骤(更新后的过程)
四、InnoDB中的B+ 树索引方案确立
(一)B+树的数据页结构
(二)B+树的层次结构
(三)B+树的查找效率
五、总结
参考文献、书籍及链接
干货分享,感谢您的阅读!
在现代数据库系统中,如何高效地管理和查找海量数据是一个至关重要的问题。InnoDB作为MySQL的存储引擎,通过引入B+树这种数据结构,解决了这一挑战。B+树不仅在索引性能方面表现优异,还在数据存储和检索上提供了极高的效率。我们探讨下B+树在InnoDB中的实现和应用,更好地理解其工作原理和优势。
一、索引页与数据行的紧密关联
在解读InnoDB数据库索引页与数据行的紧密关联-CSDN博客中我们已经强调过:在 InnoDB 中,数据页通过双向链表连接,每个数据页内的记录行按照主键值从小到大的顺序组成单向链表,并且每个数据页都有一个页目录用于快速定位记录。

查找记录时,先在页目录中使用二分法定位到特定槽,再在该槽对应的记录组中顺序遍历找到目标记录。通过这种设计,InnoDB 能够高效地管理和查找数据,确保数据库系统的高性能和可靠性。
(一)数据页的双向链表结构
每个数据页被组织成一个双向链表,这意味着每个数据页都有指向前一个页和后一个页的指针(File Header 记录了页的基础信息和链表指针)。通过这种双向链表结构,InnoDB 可以方便地进行数据页的插入、删除和遍历操作。这种设计保证了数据页之间的高效连接和管理。

(二)记录行的单向链表结构
具体可见:数据库记录行在页内查询探索分析_检查代码中循环依赖-CSDN博客
在每个数据页中,记录行按照主键值从小到大的顺序组织成一个单向链表。这种有序的结构使得在数据页内查找记录变得更加高效。每条记录不仅存储了自身的数据,还包含指向下一条记录的指针,这样可以顺序遍历记录。

每个数据页都有一个页目录,页目录可以看作是数据页内的索引结构。页目录将记录分成多个组,每个组在页目录中都有一个槽。通过页目录,InnoDB 可以快速定位到特定记录所在的组,从而减少遍历记录的时间。
当需要通过主键查找某条记录时,InnoDB 会先在页目录中使用二分法快速定位到对应的槽。页目录中的槽指向该槽对应的记录组,接着在该组中遍历记录,直到找到目标记录。这种查找过程结合了二分查找和顺序遍历的优点,既高效又精确。
二、未创建索引情况
在数据库中,当没有针对特定列建立索引时,查询过程通常会面临效率低下的问题。特别是对于非主键列的精确匹配查询,数据库引擎无法利用索引结构,从而导致需要全表扫描来寻找符合条件的记录。
(一)无索引下的单页查找过程
在数据库中,当所有记录都能够存放在一个数据页中时,查找记录的过程可以根据查询条件的不同分为以下两种情况:
以主键为搜索条件
对于主键列的精确匹配查询:
- 页目录查找:数据页通常会维护一个页目录,用于存储每条记录的偏移位置。由于页目录是按照主键排序的,因此可以使用二分查找法快速定位到对应的记录槽。
- 记录遍历:找到对应槽后,只需遍历该槽中的记录,即可快速找到符合条件的记录。
这种方法由于利用了页目录的有序性,因此查找效率较高。这部分其实就是我们上文中讲到的理想情况,但在开发过程中我们不可能每次都是直接查主键id的情况。
以非主键列为搜索条件
对于非主键列的精确匹配查询:
- 全页扫描:由于非主键列没有对应的页目录,也没有任何排序信息,无法使用二分查找等高效查找算法。此时,数据库需要从数据页的最小记录开始,逐条遍历每条记录。
- 逐条比较:在遍历过程中,逐条对比记录是否符合搜索条件。如果记录数较多,这种方法的查找效率将会非常低。
显然,对于非主键列的查找,由于缺乏索引的支持,只能进行全页扫描,这在数据量较大时,性能会变得极为低下。
(二)无索引下的多页查找过程
在大部分实际应用中,表中的记录数量非常庞大,往往需要多个数据页来存储这些记录。当在多页中查找记录时,查找过程通常可以分为两个步骤:
- 定位到记录所在的页。
- 从所在的页中查找相应的记录。
在没有索引的情况下,无论是根据主键列还是其他列的值进行查找,由于无法快速定位到记录所在的页,只能沿着数据页的双向链表逐页查找。

这意味着:
- 遍历页链表:从第一个数据页开始,沿着双向链表依次访问每一个数据页。
- 逐页查找:在每个数据页中,使用前面介绍的单页查找方式来查找指定的记录。
由于需要遍历所有数据页并在每个页中逐条比较记录,这种方式的效率非常低。
三、InnoDB中的B+ 树索引方案初体会

(一)前置说明
为了更好地理解 InnoDB 中 B+ 树索引的工作机制,我们从创建一个示例表index_demo开始,并通过详细的示意图展示记录在页中的存储结构及索引的作用。
CREATE TABLE index_demo (c1 INT,c2 INT,c3 CHAR(1),PRIMARY KEY (c1)
) ROW_FORMAT = Compact;
这个表中有两个 INT 类型的列 c1 和 c2,一个 CHAR(1) 类型的列 c3,并且 c1 列为主键。表的行格式为 Compact。
行格式示意图
为了更好地展示记录在页中的存储,简化 index_demo 表的行格式示意图:

每条记录由以下部分组成:
(背景:解析MYSQL行头信息数据详细和探究InnoDB Compact行格式背后)
- record_type:记录头信息的一项属性,表示记录的类型:0 表示普通记录;1 表示目录项记录;2 表示最小记录;3 表示最大记录
- next_record:记录头信息的一项属性,表示下一条记录地址相对于本记录的地址偏移量。
- 各个列的值:记录
index_demo表中的三个列c1、c2和c3的值。 - 其他信息:除了上述三种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息。
为了节省篇幅,我们省略记录的其他信息部分并将记录竖着展示:

页内格式示意图
把一些记录放到页里边的示意图就是:

(二)目录项记录与用户记录的区别及其存储
在 InnoDB 中,为了灵活管理 B+ 树索引的目录项,设计者们选择了复用存储用户记录的数据页来存储目录项记录。这种设计使得 InnoDB 能够高效地管理和查询数据。我们来详细分析并讲解这一机制。
目录项放到数据页
有效地利用已有的数据结构和存储机制,通过记录头信息中的 record_type 属性,InnoDB 可以轻松区分目录项记录和用户记录。record_type 值为 1 表示目录项记录,值为 0 表示普通用户记录。

目录项记录仅包含主键值和页号,这使得它们非常简洁高效。而普通用户记录则包含用户定义的多个列。
min_rec_mask 属性帮助 InnoDB 快速定位页中主键值最小的目录项记录,优化了索引的管理和查询性能。在存储目录项记录的页中,主键值最小的目录项记录的 min_rec_mask 值为 1,其他记录的 min_rec_mask 值为 0。
查找主键为20的记录
现在以查找主键为20的记录为例,根据某个主键值去查找记录的步骤就可以大致拆分成下面两步:
-
先到存储
目录项记录的页,也就是页30中通过二分法快速定位到对应目录项,因为12 < 20 < 209,所以定位到对应的记录所在的页就是页9。 -
再到存储用户记录的
页9中根据二分法快速定位到主键值为20的用户记录。
(三)分配新目录项记录页
尽管目录项记录只存储主键值和对应的页号,相比于用户记录所需的存储空间要小得多,但由于每个数据页只有16KB的大小,能够存放的目录项记录数量也是有限的。如果表中的数据非常多,以至于单个数据页无法存放所有的目录项记录,那么就需要分配更多的目录项记录页。
假设一个存储目录项记录的页最多只能存放4条目录项记录(请注意这只是个假设,实际情况可以存放更多)。当需要插入新的目录项记录时,比如主键值为320的记录,就会出现需要分配新目录项记录页的情况。

插入一条主键值为320的用户记录后,我们需要新增两个数据页:
- 页31:用于存储新的用户记录。
- 页32:用于存储新的目录项记录,因为原先存储目录项记录的页30已经满了(假设只能存储4条目录项记录)。
更新后的数据页结构
- 页30:存储目录项记录,主键值范围为 [1, 320)。
- 页32:存储目录项记录,主键值范围为 [320, ∞)。
查找主键值为20的记录的步骤
现在因为存储目录项记录的页不止一个,所以如果我们想根据主键值查找一条用户记录,大致需要三个步骤。以查找主键值为20的记录为例:
确定目录项记录页
- 现在的存储目录项记录的页有两个:页30和页32。
- 页30存储的目录项的主键值范围是 [1, 320),页32存储的目录项的主键值范围是不小于320。
- 因此,主键值为20的记录对应的目录项记录在页30中。
通过目录项记录页确定用户记录所在的页
在页30中,通过二分法快速定位到主键值为20的目录项记录,从而确定该用户记录存储在页9中。
在用户记录页中定位具体记录
在页9中,通过二分法快速定位到主键值为20的用户记录。
(四)多级目录项记录页的介绍
在查询步骤的第1步中,我们需要定位存储目录项记录的页。然而,这些页在存储空间中可能不连续排列。如果表中的数据量非常大,会产生许多存储目录项记录的页。那我们怎么根据主键值快速定位一个存储目录项记录的页呢?
为了解决这个问题,我们可以为这些存储目录项记录的页生成一个更高级的目录,形成多级目录结构。大目录中嵌套小目录,小目录中存储实际的数据。现在各个页的示意图如下:

高级目录页说明
高级目录页(页33)
页33存储更高级的目录项记录,用于指向存储目录项记录的页(例如页30和页32)。页33包含两个目录项记录:
- 目录项记录1:指向页30,范围为[1, 320)
- 目录项记录2:指向页32,范围为[320, ∞)
页30(目录项记录页)
- 页30存储具体的目录项记录,指向用户记录页。
- 目录项记录指向主键值范围在[1, 320)内的用户记录页。
页32(目录项记录页)
- 页32存储具体的目录项记录,指向用户记录页。
- 目录项记录指向主键值范围在[320, ∞)内的用户记录页。
查找主键值为20的记录的步骤(更新后的过程)
- 确定高级目录页:首先,根据主键值在高级目录页(页33)中进行查找。由于主键值20在范围[1, 320)内,所以对应的目录项记录在页30中。
- 确定具体的目录项记录页:在页30中,通过二分法快速定位到主键值为20的目录项记录,从而确定用户记录存储在页9中。
- 在用户记录页中定位具体记录:在页9中,通过二分法快速定位到主键值为20的用户记录。
这里注意我们之前的假设:假设一个存储目录项记录的页最多只能存放4条目录项记录(请注意这只是个假设,实际情况可以存放更多)
四、InnoDB中的B+ 树索引方案确立
在介绍B+树之前,我们已经看到了如何通过多级目录结构管理和查找数据。这种结构就像一棵倒过来的树,上头是树根,下头是树叶。其实,这是一种组织数据的形式,或者说是一种数据结构,它的名称是B+树。

(一)B+树的数据页结构
不论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把它们存放到B+树这个数据结构中,所以我们也称这些数据页为节点。
从图中可以看出来,我们的实际用户记录都存放在B+树的最底层的节点上,这些节点也被称为叶子节点或叶节点,其余用来存放目录项的节点称为非叶子节点或者内节点,其中B+树最上面的那个节点也称为根节点。
(二)B+树的层次结构
设计InnoDB的大佬们为了讨论方便,规定最下面的那层,也就是存放我们用户记录的那层为第0层,之后依次往上加。为了简化,我们之前做了一个非常极端的假设:存放用户记录的页最多存放3条记录,存放目录项记录的页最多存放4条记录。其实在真实环境中,一个页存放的记录数量是非常大的。
假设所有存放用户记录的叶子节点代表的数据页可以存放100条用户记录,所有存放目录项记录的内节点代表的数据页可以存放1000条目录项记录,那么:
- 如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放100条记录。
- 如果B+树有2层,最多能存放1000×100=100,000条记录。
- 如果B+树有3层,最多能存放1000×1000×100=100,000,000条记录。
- 如果B+树有4层,最多能存放1000×1000×1000×100=100,000,000,000条记录。
哇咔咔~这么多的记录!!!
但实际上,可推演得出结论:当单行数据大小为S字节,树高为H时,一个bigint类型的主键B+树索引中可以存放的数量行数N等于:
![]()
按公式计算:当树高为4时,可以存放200百多亿行数据。这样的数据容量,可以满足绝大部分应用的需求,因此我们可以说在绝大部分应用中,B+树高度为3或4就可以满足数据存储的需求。B+树这种高扇出低树高的特征,也大大的提高了主键查询性能。具体推导可见:InnoDB存储引擎B+树的树高推导_b+树一般多少层-CSDN博客
(三)B+树的查找效率
你的表里能存放100,000,000,000条记录么?所以一般情况下,我们用到的B+树都不会超过4层,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找(查找3个目录项页和一个用户记录页),又因为在每个页面内有所谓的Page Directory(页目录),所以在页面内也可以通过二分法实现快速定位记录,这不是很牛么!
通过引入B+树,InnoDB能够高效地管理和查找大量数据。B+树的结构保证了即使在处理大规模数据时,查找过程仍然高效。每一层增加的节点数,使得数据的管理和查找变得更加迅速和可靠。
B+树是数据库系统中广泛使用的索引结构,通过这种结构,InnoDB能够在庞大的数据集中快速、准确地找到所需的记录,为数据库性能提供了有力的保障。
五、总结
综上所述,B+树作为InnoDB的核心索引结构,通过多级目录和高效的节点管理,实现了快速的数据查找和管理。其高扇出、低树高的特性,使得即使在处理大规模数据时,查找过程仍然保持高效,通常不超过四层的树结构足以满足大部分应用需求。
通过B+树,InnoDB在庞大的数据集中能够快速、准确地找到所需记录,显著提高了数据库的性能和可靠性。其页目录、双向链表和单向链表等设计进一步优化了数据存储和查找过程,使得数据库系统在面对复杂查询时依然能够保持高效运作。
B+树不仅在数据组织和存储方面展现了强大的能力,更通过实际应用证明了其在数据库管理系统中的不可替代性。总之,B+树的引入和使用,使得InnoDB能够在现代数据库系统中脱颖而出,成为高性能、高可靠性的代名词。
参考文献、书籍及链接
- 《MySQL技术内幕:InnoDB存储引擎》(第2版):MySQL技术内幕 (豆瓣)
- 《MySQL 是怎样运行的:从根儿上理解 MySQL》
- 《Inside InnoDB: The InnoDB Storage Engine》:MySQL :: MySQL 8.0 Reference Manual :: 15 The InnoDB Storage Engine
- 《InnoDB: The Ultimate Guide》:https://www.percona.com/blog/2018/06/05/innodb-the-ultimate-guide/
- 《InnoDB Storage Engine Internals》:https://mariadb.com/kb/en/innodb-storage-engine-internals/
- InnoDB的数据页结构
相关文章:
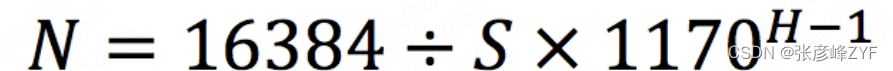
深入InnoDB核心:揭秘B+树在数据库索引中的高效应用
目录 一、索引页与数据行的紧密关联 (一)数据页的双向链表结构 (二)记录行的单向链表结构 二、未创建索引情况 (一)无索引下的单页查找过程 以主键为搜索条件 以非主键列为搜索条件 (二…...

c++(面向对象的性质:抽象,封装,继承,多态)
ctrla全选,ctrli对齐 ctrl/ 一起注释 ctrlz 退回上一步 一些基础的内容: cout:输出流对象 cin:输入流对象 输入一个i和一个j,然后输出ij的和: 值不变的原因: 值传递,a和i是…...

java基础学习笔记1
Java编程规范 命名风格 1. 【强制】代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。 反例:_name / __name / $name / name_ / name$ / name__ 2. 【强制】代码中的命名严禁使用拼音与英文混合的方式,更不允许直…...

[VBA]使用VBA在Excel中 操作 形状shape 对象
excel已关闭地图插件,对于想做 地图可视化 的,用形状来操作是一种办法,就是要自行找到合适的 地图形状,修改形状颜色等就可以用于 可视化展示不同省市销量、人口等数据。 引言 在Excel中,通过VBA(Visual Basic for Applications)可以极大地增强数据可视化和报告自动化…...

Apache POI 实现 Excel 表格下载
这里以苍穹外卖中数据导出功能为例,记录下 Apache POI 导出 Excel 表格的过程。 首先在 pom.xml 中导入相关依赖 <!-- poi 用于操作 excel 表格--> <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId&…...
)
大华嵌入式面试题大全及参考答案(2万字长文)
目录 在C语言中,static 关键字有哪些主要用途? static 修饰的全局变量与普通全局变量有什么区别? 为什么要在嵌入式系统中使用 static 修饰函数? 虚函数与纯虚函数了解么? strcpy 给你加结束符吗,还是要自己加? select 的作用是什么,它和 epoll 的区别? map 与…...

C语言——查漏补缺
前言 本篇博客主要记录一些C语言的遗漏点,完成查漏补缺的工作,如果读者感兴趣,可以看看下面的内容。都是一些小点,下面进入正文部分。 1. 字符汇聚 编写代码,演示多个字符从两端移动,向中间汇聚 #inclu…...

Python | Leetcode Python题解之第328题奇偶链表
题目: 题解: class Solution:def oddEvenList(self, head: ListNode) -> ListNode:if not head:return headevenHead head.nextodd, even head, evenHeadwhile even and even.next:odd.next even.nextodd odd.nexteven.next odd.nexteven even…...

吉瑞外卖笔记
1.项目整体搭建 这里用到的是springboot3mybatisplus 1.1数据库搭建 整体表搭建,这里我是直接用的老师给的数据库 1.2maven项目搭建 依赖 这两个jar包第一次用,记录一下 fastjson json处理,可将对象转化为json形式 可将对象中的属性…...

Perl套接字编程指南:构建网络通信应用
摘要 Perl是一种功能强大的脚本语言,广泛应用于系统管理、网络编程等多种场景。Perl的套接字编程能力允许开发者创建客户端和服务器端的网络应用。本文将详细介绍Perl中套接字的使用,包括基础概念、API的使用,以及构建简单客户端和服务器的示…...

达梦数据库(十) -------- mybatis-plus 整合达梦时,自动生成的 sql 语句报错
一丶【问题描述】: mybatis-plus 整合达梦时,应用系统项目的 sql 语句中包含数据库关键字,导致 mybatis-plus 自动生成的 sql 语句会报错,如下图所示: 二丶【问题解决】: 问题原因:mybatis-pl…...

停止项目大小调整,开始搜索层自动缩放!
作者:来自 Elastic Matteo Piergiovanni,John Verwolf 我们新的 serverless 产品的一个关键方面是允许用户部署和使用 Elastic,而无需管理底层项目节点。为了实现这一点,我们开发了搜索层自动扩展,这是一种根据我们将在…...

VScode的环境编译器选择
按快捷键 Ctrl Shift P 选择即可...

在Linux中通过docker安装和配置supervisor进程守护
先在Linux中安装docker,然后在docker中安装appnode,并进行docker网络端口映射。接着登录appnode面板安装supervisor。 supervisor用于守护进程,在进程意外终止后将其重启。 supervisor没有监听内部程序和自动重启的功能。 docker安装 第一…...
)
CanMV-K230自学笔记系列(不定期更新)
笔记内容主要为CanMV-K230的学习过程,目前陆续有新的k230开发板 CanMV-K230 V1.0 V1.1(已上市) CanMV-K230-01Studio(刚上市) DshanPI-CanMV K230(刚上市) BPI-CanMV-K230D-Zero(待…...

[GXYCTF2019]禁止套娃-使用无参数读文件
点开靶场 发现源码、以及抓包啥都看不出来 用dirsearch扫描发现是git源码泄露,用githack获取源码 查看源码发现最终目标要执行eval($_GET[exp]) 要执行eval就要通过这些正则,第一个正则匹配不分大小写的php伪协议之类的 重点是第二个正则 preg_repl…...

SpringBoot+MyBatis模板
SpringBootMyBatis模板见附件...

Springboot 定时任务 @EnableScheduling @Scheduled
EnableScheduling 是Spring框架中的一个注解,它用于开启基于注解的任务调度支持。当你在你的Spring应用程序中使用这个注解时,它允许你通过Scheduled注解来配置和执行定时任务。 以下是如何使用 EnableScheduling 的基本步骤: 1. **添加Ena…...

STM32F407ZET6使用LCD(9341)
1.原理图 屏幕是中景园2.8寸液晶屏,9341驱动不带触摸屏版本 2.STM32CUBEMX配置 3.编写驱动程序...
动手学深度学习7.3 网络中的网络(NiN)-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:26 网络中的网络 NiN【动手学深度学习v2】_哔哩哔哩_bilibili 本节教材地址:7.3. 网络…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...