停止项目大小调整,开始搜索层自动缩放!
作者:来自 Elastic Matteo Piergiovanni,John Verwolf

我们新的 serverless 产品的一个关键方面是允许用户部署和使用 Elastic,而无需管理底层项目节点。为了实现这一点,我们开发了搜索层自动扩展,这是一种根据我们将在本博客中深入探讨的大量参数动态选择节点大小和数量的策略。这项创新确保你不再需要担心资源配置不足或过度配置。
无论你处理的是波动的流量模式、意外的数据峰值还是逐渐增长,搜索层自动扩展都会根据搜索活动无缝地将分配的硬件动态调整到搜索层。自动扩展是按项目执行的,对最终用户完全透明。
简介
Elastic serverless 是 Elastic 推出的一款完全托管产品,它使你无需管理底层 Elastic 基础设施即可部署和使用 Elastic 产品,而是专注于最大限度地利用数据。
自我管理基础设施面临的挑战之一是应对客户不断变化的需求。在动态的数据管理世界中,灵活性和适应性至关重要,而传统的扩展方法往往不够完善,需要手动调整,这既耗时又不精确。借助搜索层自动扩展,我们的 serverless 产品会自动调整资源以实时满足你的工作负载需求。
本文中描述的自动扩展特定于 Elastic serverless 产品中的 Elasticsearch 项目类型。可观察性和安全性可能具有针对其独特要求量身定制的不同自动扩展机制。
在深入了解自动扩展的细节之前,还需要了解另一个重要信息,即我们如何管理数据以实现强大且可扩展的基础设施。我们使用 S3 作为主要事实来源,提供可靠且可扩展的存储。为了提高性能并减少延迟,搜索节点使用本地缓存来快速访问经常请求的数据,而无需反复从 S3 检索数据。S3 存储和搜索节点缓存的这种组合形成了一个高效的系统,确保持久存储和快速数据访问都能有效满足用户的需求。
搜索层自动扩展输入
为了演示自动扩展的工作原理,我们将深入研究用于做出扩展决策的各种指标。
在启动新的 serverless Elasticsearch 项目时,用户可以选择两个会影响自动扩展行为的参数:
- 增强窗口:定义搜索数据被视为增强的特定时间范围。
- 增强数据:在增强窗口内的数据被归类为增强数据。所有在增强窗口范围内具有 @timestamp 的基于时间的文档以及所有非基于时间的文档都将属于增强数据类别。这种基于时间的分类允许系统在分配资源时优先考虑这些数据。
- 非增强数据:增强窗口之外的数据被视为非增强数据。这些较旧的数据仍然可以访问,但与增强数据相比分配的资源较少。
- 搜索能力:控制分配给项目中增强数据的虚拟计算单元 (virtual compute units - VCU) 数量的范围。搜索能力可以设置为:
- 成本效益:限制增强数据的可用缓存大小,优先考虑成本效益而不是性能。非常适合希望以低成本存储大量数据的客户。
- 平衡:确保所有增强数据都有足够的缓存,以便更快地进行搜索。
- 性能:提供更多资源,以更快地响应更大容量和更复杂的查询。
增强窗口将决定项目的增强数据和非增强数据量。
我们将项目的增强数据定义为增强窗口内的数据量。
增强数据的总大小以及所选搜索能力范围的下限将决定项目的基本硬件配置。这种方法比扩展到零(或接近零)更受欢迎,因为它有助于保持后续请求的可接受延迟。这是通过保留我们的缓存并确保 CPU 可立即用于处理传入请求来实现的。这种方法避免了与从 CSP(cloud server provider) 配置硬件相关的延迟,并确保系统随时准备及时处理传入请求。
请注意,基本配置可以通过提取更多数据而随时间推移而增加,如果时间序列数据超出增强窗口,则基本配置会减少。
这是自动扩展的第一部分,我们提供了一个基本硬件配置,可以随时间推移适应用户的提升数据。
基于负载的自动扩展
基于交互式数据的自动扩展只是难题的一部分。它不考虑传入搜索流量对搜索节点造成的负载。为此,我们引入了一个名为 “search load -搜索负载” 的新指标。搜索负载是处理当前搜索流量所需的物理资源量的度量。
搜索负载考虑了搜索流量在给定时间对节点造成的资源使用情况,因此允许动态自动扩展。
什么是搜索负载?
搜索负载(search load)是处理当前搜索流量所需的物理资源量的度量。我们将其报告为每个节点所需的处理器数量的度量。但是,这里有一些细微差别。
在扩展时,我们在具有设置值的 CPU、内存和磁盘的硬件配置之间上下移动。这些值根据给定的比率一起缩放。例如,为了获得更多 CPU,我们将扩展到具有更多内存和更多磁盘的硬件配置的节点。
搜索负载间接考虑了这些资源。它通过使用搜索线程在给定测量间隔内所花费的时间来做到这一点。如果线程在等待资源 (IO) 时阻塞,这也会增加线程的执行时间。如果除了排队之外,所有线程都 100% 利用率,则表示需要扩大规模。相反,如果没有排队并且搜索线程池的利用率低于 100%,则表示可以缩小规模。
如何计算搜索负载?
搜索负载由两个因素组成:
- 线程池负载:处理正在处理的搜索流量所需的处理器核心数。
- 队列负载:在可接受的时间范围内处理排队的搜索请求所需的处理器核心数。
为了描述如何计算搜索负载,我们将逐步介绍每个方面以解释基本原理。
我们将从描述线程池负载(Thread Pool Load)开始。首先,我们监控负责在采样间隔内处理搜索请求的线程的总执行时间,称为 totalThreadExecutionTime(总线程执行时间)。将此采样间隔的长度乘以处理器核心以确定最大 availableTime。为了获得 threadUtilization(线程利用率)百分比,我们将总线程执行时间除以这个 availableTime。
double availableTime = samplingInterval * processorCores;
double threadUtilization = totalThreadExecutionTime / availableTime;
例如,采样间隔为 1 秒的 4 核机器将有 4 秒的可用时间(4 核 * 1 秒)。如果总任务执行时间为 2 秒,则线程池利用率(hread pool utilization)为 50%(2 秒 / 4 秒 = 0.5)。
然后,我们将 threadUtilization 百分比乘以 numProcessors 以确定 processingsUsed,它衡量使用的处理器核心数。我们通过指数加权移动平均线(有利于最近添加的移动平均线)记录此值,以平滑小规模的活动突发。这会产生用于 threadPoolLoad 的值。
double processorsUsed = threadUtilization * numProcessors;
exponentialWeightedMovingAvg.add(processorUtilization);
double threadPoolLoad = exponentialWeightedMovingAvg.get();
接下来,我们将描述如何确定队列负载(Queue Load)。计算的核心是配置 maxTimeToClearQueue,它设置搜索请求可以排队的最大可接受时间范围。我们需要知道给定线程在此时间范围内可以执行多少个任务,因此我们将 maxTimeToClearQueue 除以搜索执行时间的指数加权移动平均值。接下来,我们将 searchQueueSize 除以此值,以确定在配置的时间范围内清除队列需要多少个线程。要将其转换为所需的处理器数量,我们将其乘以 processorsPerThread 的比率。这会产生用于 queueLoad 的值。
double taskPerThreadWithinSetTimeframe = maxTimeToClearQueue / ewmaTaskExecutionTime;
double queueThreadsNeeded = searchQueueSize / taskPerThreadWithinSetTimeframe;
double queueLoad = queueThreadsNeeded * processorsPerThread;
那么给定节点的搜索负载(Search Load )就是 threadPoolLoad 和 queueLoad 的总和。
搜索负载报告
每个搜索节点都会定期向主节点发布负载读数。这将在设定的时间间隔后或检测到负载大幅变化时发生。
主节点会分别跟踪每个搜索节点的状态,并根据各种生命周期事件执行记账。添加/删除搜索节点时,主节点会添加或删除其各自的负载条目。
主节点还会报告每个条目的质量评级:Exact、Minimum 或 Missing。Exact 表示最近报告了该指标,而 Missing 则表示新节点尚未报告搜索负载。
当主节点在配置的时间段内未收到来自搜索负载的更新时(例如,如果某个节点暂时不可用),搜索负载质量被视为最低。当搜索节点的负载值考虑了不被视为未来工作的工作(例如下载随后将缓存的文件)时,质量也会报告为最低。
质量用于通知扩展决策。当任何节点的质量不准确时,我们不允许缩小规模。但是,无论质量评级如何,我们都允许扩大规模。
自动扩缩器 - Autoscaler
自动扩缩器是 Elastic serverless 的一个组件,旨在通过根据实时指标调整项目中节点的大小和数量来优化性能和成本。它监控来自 Elasticsearch 的指标,确定理想的硬件配置,并将配置应用于托管的 Kubernetes 基础架构。了解搜索层指标所涉及的输入和计算后,我们现在可以探索自动扩缩器如何利用这些数据来动态调整项目节点大小和数量,以实现最佳性能和成本效益。
自动扩缩器每 5 秒监控一次搜索层指标。当收到有关总交互式和非交互式数据大小的新指标以及搜索能力范围时,自动扩缩器将确定可能的硬件配置范围。这些配置的范围从最小到最大,由搜索能力范围定义。
然后,自动扩缩器使用 Elasticsearch 报告的搜索负载在可用范围内选择 “所需” 硬件配置,该配置至少具有与测量的搜索负载相匹配的处理器核心数量。
此所需配置可作为稳定阶段的输入,在此阶段,自动扩缩器将决定是否可以立即应用所选的扩缩方向;如果不能,则将其丢弃。缩减有一个 15 分钟的稳定窗口,这意味着需要 15 分钟的连续缩减事件才能发生缩减。扩大规模没有稳定期。扩展事件是非阻塞(non-blocking)的;因此,我们可以在后续操作仍在进行时继续做出扩展决策。对此的唯一限制由上述稳定窗口定义。
然后根据 Elasticsearch 中索引的最大副本数检查配置,以确保有足够的搜索节点来容纳所有配置的副本。
最后,将配置应用于托管的 Kubernetes 基础架构,该基础架构会相应地配置项目大小。
结论
搜索层自动扩展彻底改变了 Elasticsearch serverless 项目的管理。通过利用详细的指标,自动扩展器可确保项目始终保持最佳规模。借助无服务器,用户可以专注于业务需求,而不必担心管理基础设施或在工作负载发生变化时措手不及。
这种方法不仅可以在高需求期间提高性能,还可以在活动较少时降低成本,同时对最终用户完全透明。
因此,用户可以将更多精力放在核心活动上,而不必担心手动调整项目以满足不断变化的需求。这项创新标志着 Elasticsearch 在无服务器计算领域迈出了重要一步,使其既强大又易于使用。
试试看!
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证吗?了解下一期 Elasticsearch 工程师培训何时开始!
原文:Elasticsearch Serverless: Search tier autoscaling — Search Labs
相关文章:
停止项目大小调整,开始搜索层自动缩放!
作者:来自 Elastic Matteo Piergiovanni,John Verwolf 我们新的 serverless 产品的一个关键方面是允许用户部署和使用 Elastic,而无需管理底层项目节点。为了实现这一点,我们开发了搜索层自动扩展,这是一种根据我们将在…...

VScode的环境编译器选择
按快捷键 Ctrl Shift P 选择即可...

在Linux中通过docker安装和配置supervisor进程守护
先在Linux中安装docker,然后在docker中安装appnode,并进行docker网络端口映射。接着登录appnode面板安装supervisor。 supervisor用于守护进程,在进程意外终止后将其重启。 supervisor没有监听内部程序和自动重启的功能。 docker安装 第一…...
)
CanMV-K230自学笔记系列(不定期更新)
笔记内容主要为CanMV-K230的学习过程,目前陆续有新的k230开发板 CanMV-K230 V1.0 V1.1(已上市) CanMV-K230-01Studio(刚上市) DshanPI-CanMV K230(刚上市) BPI-CanMV-K230D-Zero(待…...

[GXYCTF2019]禁止套娃-使用无参数读文件
点开靶场 发现源码、以及抓包啥都看不出来 用dirsearch扫描发现是git源码泄露,用githack获取源码 查看源码发现最终目标要执行eval($_GET[exp]) 要执行eval就要通过这些正则,第一个正则匹配不分大小写的php伪协议之类的 重点是第二个正则 preg_repl…...

SpringBoot+MyBatis模板
SpringBootMyBatis模板见附件...

Springboot 定时任务 @EnableScheduling @Scheduled
EnableScheduling 是Spring框架中的一个注解,它用于开启基于注解的任务调度支持。当你在你的Spring应用程序中使用这个注解时,它允许你通过Scheduled注解来配置和执行定时任务。 以下是如何使用 EnableScheduling 的基本步骤: 1. **添加Ena…...

STM32F407ZET6使用LCD(9341)
1.原理图 屏幕是中景园2.8寸液晶屏,9341驱动不带触摸屏版本 2.STM32CUBEMX配置 3.编写驱动程序...
动手学深度学习7.3 网络中的网络(NiN)-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:26 网络中的网络 NiN【动手学深度学习v2】_哔哩哔哩_bilibili 本节教材地址:7.3. 网络…...

SQL语言-select的使用方法
select语法的使用(SQLyog) 设定查询结果返回的行数 #设定查询结果返回的行数,需要使用limit,指定返回的行数 #格式:select 列名 from 表名 limit n; #n代表限定的行数 SELECT stu_name FROM student LIMIT 3;#格式&a…...

深入理解Python中的排序算法:快速排序与归并排序实现
深入理解Python中的排序算法:快速排序与归并排序实现 排序是计算机科学中一个基本而重要的操作,几乎在所有的编程任务中都会遇到。Python提供了内置的排序函数,但了解排序算法的实现原理对于提升编程能力和解决问题的能力至关重要。本文将深入探讨两种经典的排序算法:快速…...

Linux基础命令 ② 未完成
linux系统目录结构 解释 bin: 包含基本的可执行二进制文件,供所有用户使用。 boot: 存储操作系统启动所需的关键文件,如内核和初始化 RAM 磁盘(initramfs)。 dev: 包含设备节点,表示物理设备或虚拟设备。 etc: 存储…...

怎么加密文件?分享文件加密四个方法,2024新版操作教程,教你搞定!
数据的安全性与隐私保护显得尤为重要。 无论是个人敏感信息、企业商业机密还是创意作品,文件加密都是保障其不被未授权访问的重要手段。 本文将为您详细介绍四种文件加密方法,并附上2024年新版操作教程,助您轻松搞定文件加密,守护…...

cesium加载魔方立方体
cesium加载多个小立方体,组合拼成一个大立方体。 地理坐标拼合的大立方体有错位问题。必须进行坐标转换。 <template><div class"map"><div id"mapContainer" ref"mapContainer" class"map-container">&…...

unity 粒子系统学习
差不多了解了基本的ui面板,学一下粒子系统 取消轮廓线 这样粒子biubiu的时候就没有橙黄色的轮廓线了 三个子模块概念...

CogVideoX环境搭建推理测试
引子 智谱AI版Sora开源,首个可商用,18G显存即可运行。前文写了Open-Sora1.2的博文,感兴趣的童鞋请移步(Open-Sora1.2环境搭建&推理测试_open sora 1.2-CSDN博客)。对于这种占用资源少,且效果不错的多模…...
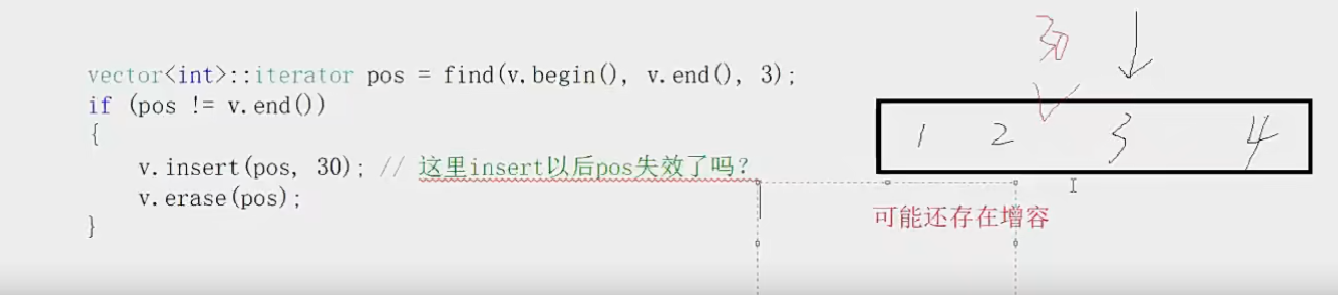
STL—容器—list【list的介绍和基本使用】【list的迭代器失效问题】
STL—容器—list list的使用并不难,有了之前使用string和vector的基础后,学习起来并不难。因此这里不在详细的讲解如何使用,而是大致的将其基本接口都熟悉一下 1.list介绍 list的文档介绍 list是可以在常数范围内在任意位置进行插入和删除…...

【面试宝典】MySQL 面试问题
一、MySQL 中有哪几种锁? MySQL中的锁机制是数据库并发控制的重要组成部分,它用于管理多个用户对数据库资源的访问,确保数据的一致性和完整性。MySQL中的锁可以根据不同的分类标准进行分类,以下是一些常见的分类方式及对应的锁类…...

【Cpp筑基】三、对象和类
【Cpp筑基】三、对象和类 Cpp系列笔记目录 【Cpp筑基】一、内联函数、引用变量、函数重载、函数模板 【Cpp筑基】二、声明 vs 定义、头文件、存储持续性作用域和链接性、名称空间 【Cpp筑基】三、对象和类 【Cpp筑基】四、重载运算符、友元、类的转换函数 【Cpp筑基】五、类的继…...

数据库原理面试-核心概念-问题理解
目录 1.数据库、数据库系统与数据库管理系统 2.理解数据独立性 3.数据模型 4.模式、外模式和内模式 5.关系和关系数据库 6.主键与外键 7.SQL语言 8.索引与视图 9.数据库安全 10.数据库完整性 11.数据依赖和函数依赖 12.范式?三范式?为什么要遵…...

WPF虚拟桌宠组件:可嵌入、高性能、工程化UI生命体
1. 这不是“桌面宠物”,而是一个可嵌入的WPF UI组件化生命体你可能在Windows XP时代见过那只晃着尾巴、偶尔打哈欠的3D小猫,也可能在Win10系统托盘里点开过一个会眨眼的像素狐狸——但那些是独立进程、是系统级小工具、是“看一眼就关掉”的轻量娱乐。而…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

【DeepSeek集成测试黄金标准】:20年专家亲授5大避坑指南与自动化落地框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试黄金标准的演进与核心价值 集成测试在大语言模型工程化落地过程中已从“验证功能可用”跃迁为“保障推理一致性、上下文鲁棒性与安全边界的三位一体质量门禁”。DeepSeek系列模型&…...