基于Python爬虫+机器学习的长沙市租房价格预测研究

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
写在前面
最近有粉丝问我“什么 AI 工具好”,其实还是得看自己的使用场景,很难说有最好用,只有最合自己胃口的。对我来说,好用的 AI 工具满足几个标准:
- 使用方便。用的时候不要太麻烦,最好一键就能启用
- 功能丰富。这样可以覆盖绝大多数的使用场景
- 性能一流。决定上限
- 价格实惠。这很重要
以前我用 ChatGPT 最多,主要是当时没别的可选,就它最厉害,但现在大模型之间的性能差距越来越小,所以慢慢地其他工具就一块用了,比如 Claude、Kimi,AI 搜索的 Perplexity,综合起来看,我目前用得频率最高、也是最顺手的 AI 工具反而是一个浏览器插件“灵办 AI”。功能挺多,该有的都有,比如:
- AI 对话
- 翻译
- 阅读(网页+文档)
- 联网搜索
- AI 写作
- .....
感兴趣的小伙伴点击下方链接即可免费注册使用:(推荐使用电脑)
https://ilingban.com/browser_extension/?from=aps
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3数据可视化
4.4特征工程
4.5构建模型
4.6特征重要性
4.7模型预测
源代码
1.项目背景
在当今数字化快速发展的时代,数据已成为驱动决策和预测未来的重要力量。房地产市场作为国民经济的重要组成部分,其价格的波动不仅直接影响着居民的生活水平,也反映了国家宏观经济的运行状况。长沙市,作为湖南省的省会城市,近年来随着经济的快速发展和城市化进程的加速,租房市场也呈现出蓬勃发展的态势。
然而,租房价格的波动受到多种因素的影响,包括供求关系、地理位置、房屋类型、装修状况、交通便捷性、周边设施等。这些因素之间相互交织,形成了复杂的动态系统,使得租房价格的预测变得尤为困难。传统的预测方法,如基于经验或简单统计的预测,往往难以准确反映市场变化,且难以适应复杂多变的市场环境。
为了更准确地预测长沙市租房价格,本研究将采用基于Python爬虫和机器学习的方法。Python爬虫技术可以从互联网上大量抓取相关的租房数据,包括房源信息、价格、地理位置、房屋类型等,为后续的机器学习模型提供丰富的数据基础。而机器学习技术则可以通过对大量数据的分析和学习,自动发现数据中的规律和模式,从而实现对租房价格的准确预测。
具体来说,本研究将分为以下几个步骤:首先,利用Python爬虫技术从各大租房网站和平台上抓取相关的租房数据;其次,对抓取的数据进行清洗、预处理和特征工程,提取出与租房价格相关的关键特征;然后,选择合适的机器学习算法(如线性回归、决策树、随机森林、神经网络等),构建租房价格预测模型;最后,通过模型训练和验证,不断优化模型参数,提高预测精度。
本研究旨在通过Python爬虫和机器学习技术的结合,实现对长沙市租房价格的准确预测,为政府决策、房地产开发商、租赁企业和租户等提供有价值的参考信息。同时,本研究也将为机器学习在房地产价格预测领域的应用提供新的思路和方法,具有一定的理论意义和实践价值。
2.数据集介绍
本实验数据集来源于房天下官网,通过使用python爬虫获取了长沙市的租房数据
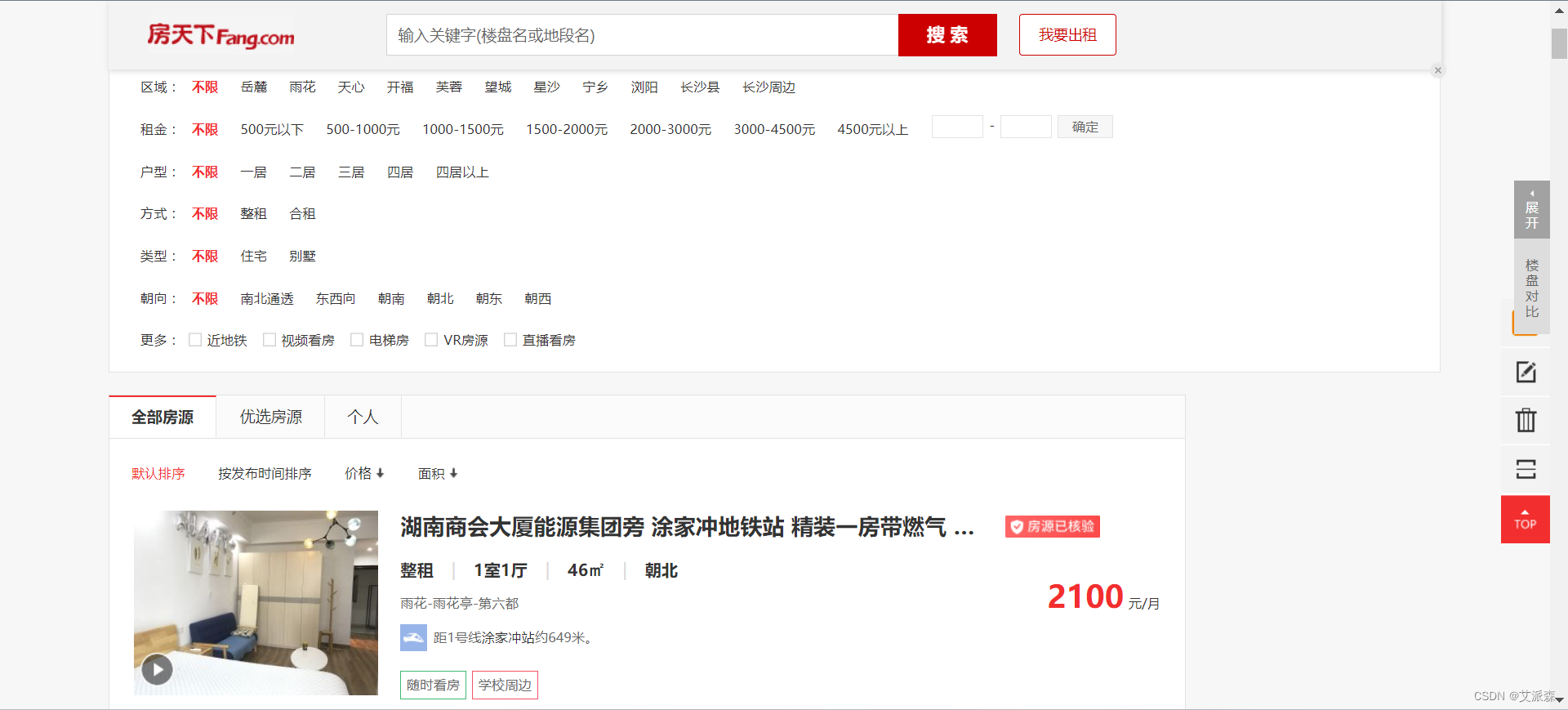
获取了房屋租金、交付方式、房屋户型、房屋面积、装修情况、校区、地址、配套设施、房源亮点等字段信息,具体如下图所示。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
导入数据分析的第三方库并加载数据集
查看数据大小
查看数据基本信息

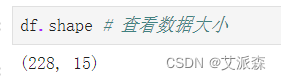
查看数据描述性统计
4.2数据预处理
统计缺失值情况
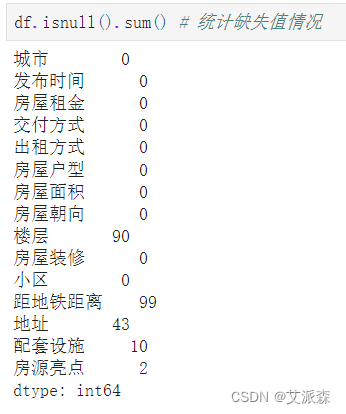
发现个别变量存在少量或大量缺失值
这里我们先直接删除“楼层”和“距地铁距离”这两个变量(因为这两个变量缺失值较多),最后统一删除缺失值

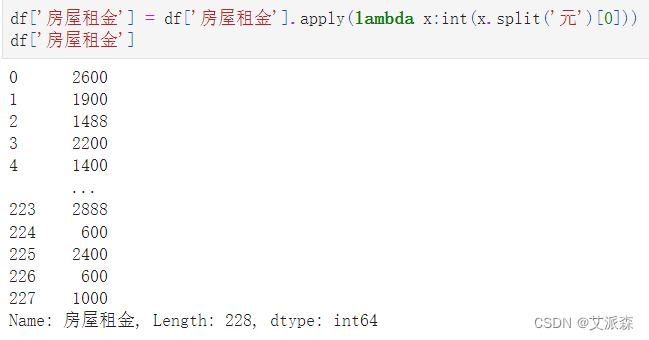
处理“房屋租金”变量,只提取出金额数值
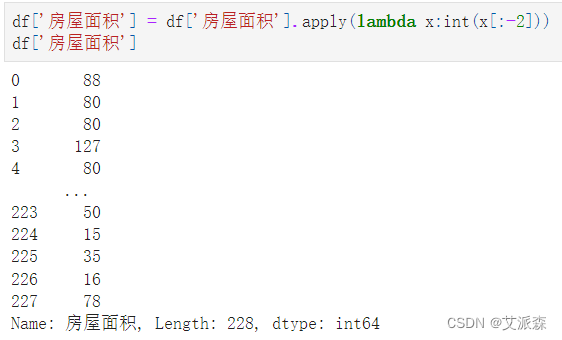
处理房屋面积,只提取出数值
4.3数据可视化
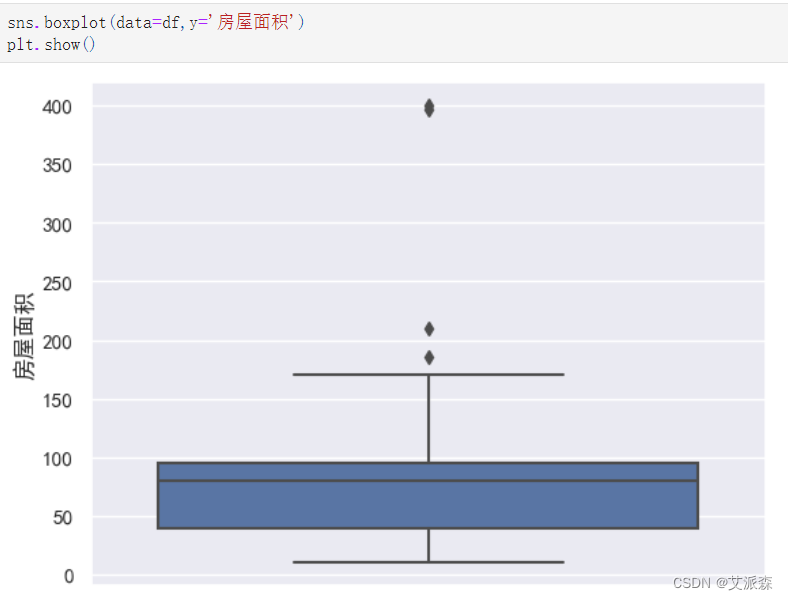
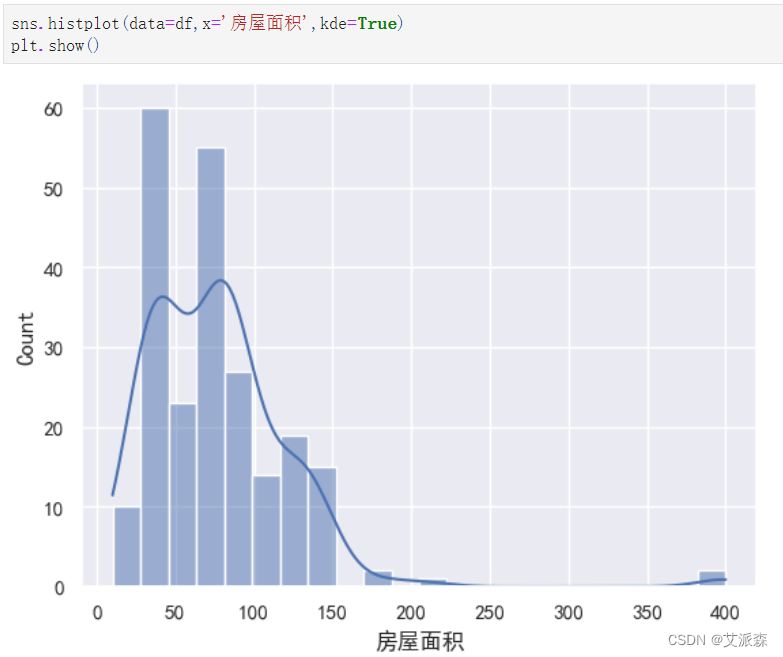
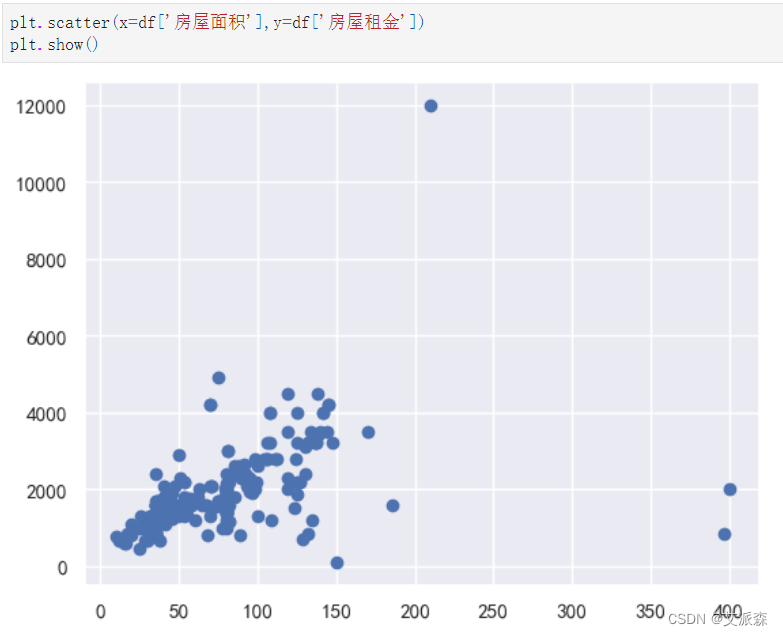
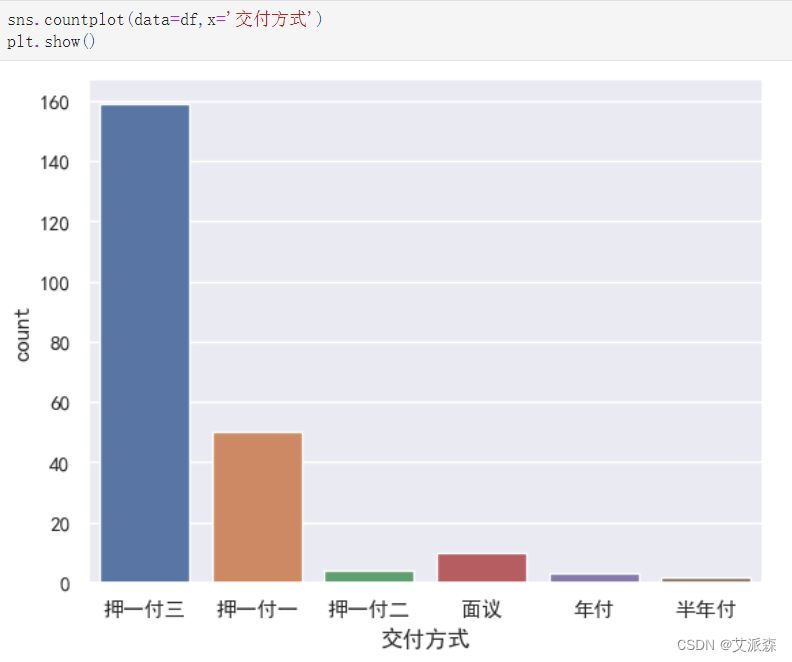

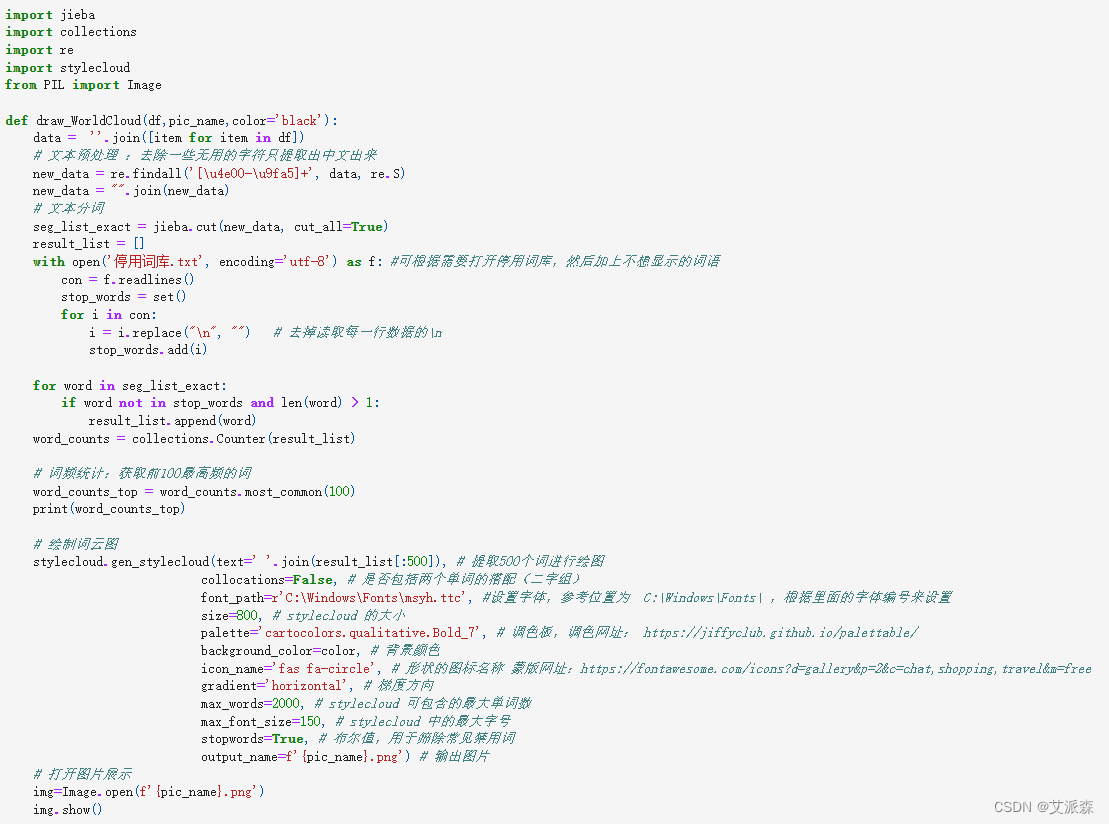
自定义一个画词云图的函数
做出房源亮点词云图


做出配套设施词云图


4.4特征工程
筛选特征
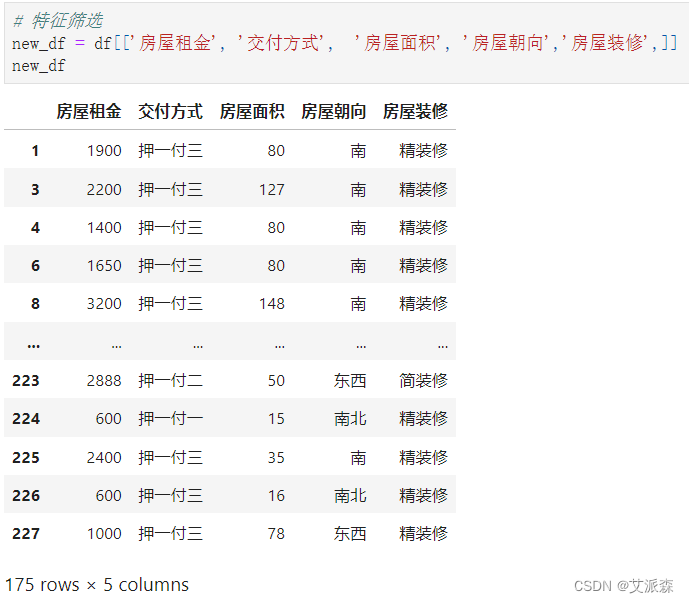
对非数值变量进行编码处理
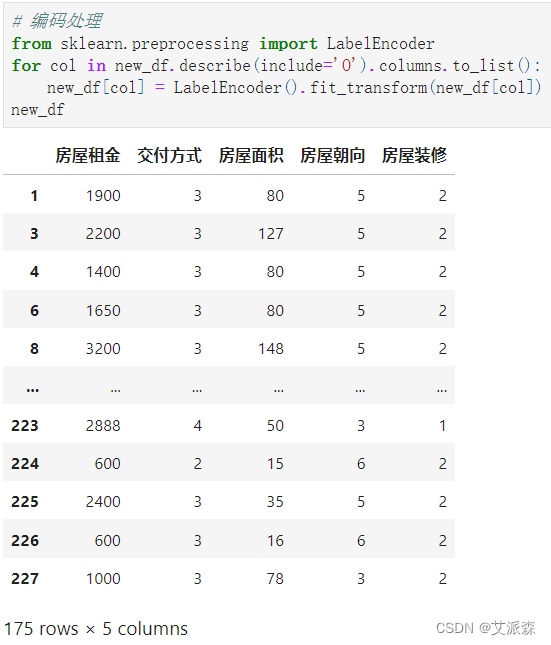
准备建模所需数据,即特征变量X和目标变量y,接着拆分数据集为训练集和测试集,其中测试集比例为0.2

4.5构建模型
定义一个训练模型并输出模型的评估指标

构建多元回归模型
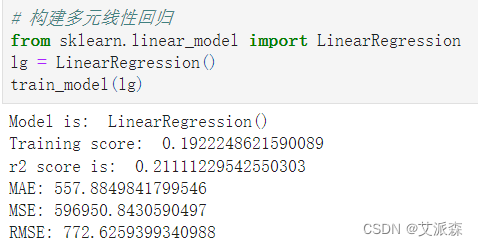
构建KNN模型


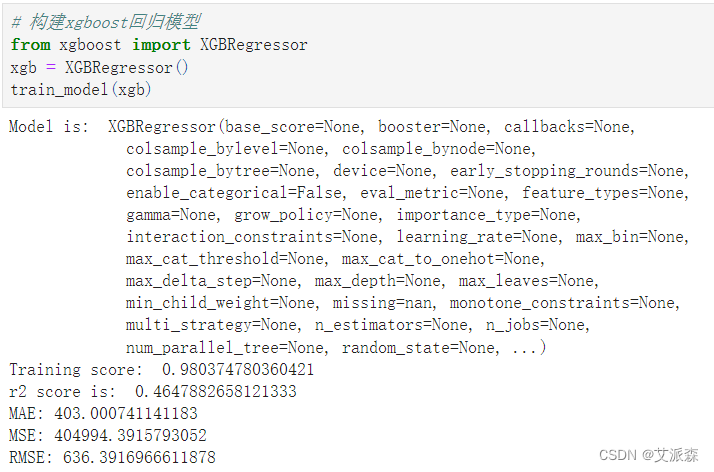
从上面构建的模型中,XGBoost模型的准确率最高,为0.98 ,故我们选择其作为最终模型。
4.6特征重要性
获取模型特征重要性并排序打印输出,最后进行可视化展示
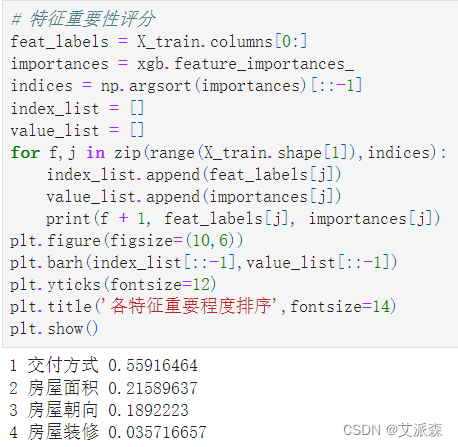
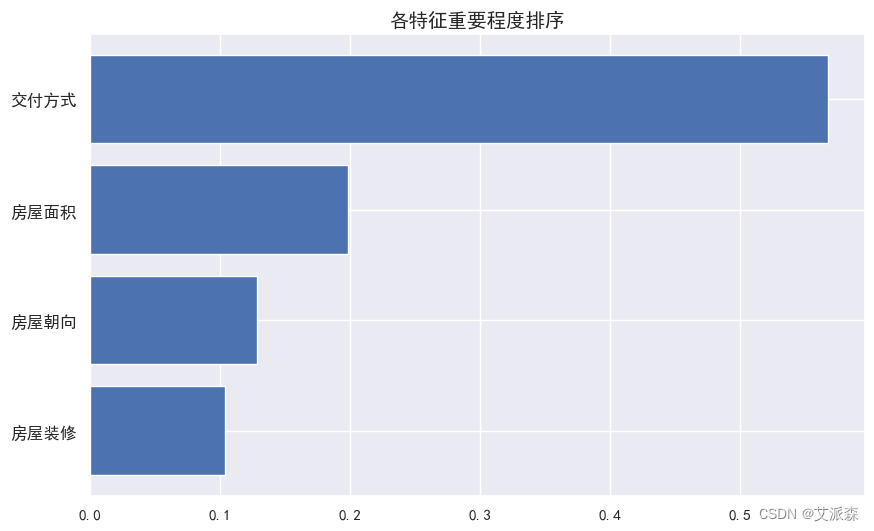
4.7模型预测
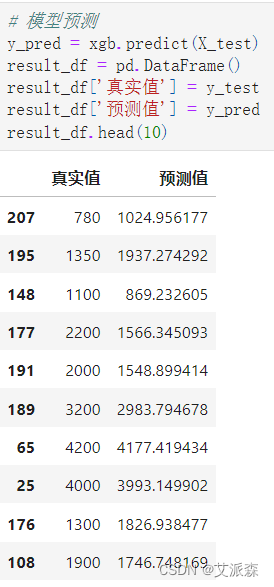
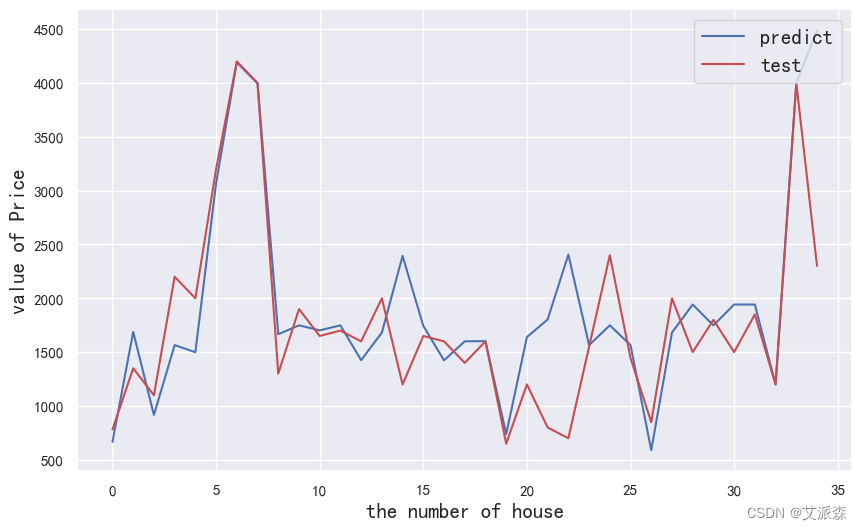
将预测结果可视化展示

源代码
import matplotlib.pylab as plt
import numpy as np
import seaborn as sns
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
sns.set(font='SimHei')
import warnings
warnings.filterwarnings('ignore')df = pd.read_csv('长沙租房数据.csv') # 导入数据
df.head() # 查看数据前五行
df.shape # 查看数据大小
df.info() # 查看数据基本信息
df.describe().T # 查看数据描述性统计
df.isnull().sum() # 统计缺失值情况
df.drop(['距地铁距离','楼层'],axis=1,inplace=True)
df.dropna(inplace=True)
df['房屋租金'] = df['房屋租金'].apply(lambda x:int(x.split('元')[0]))
df['房屋租金']
df['房屋面积'] = df['房屋面积'].apply(lambda x:int(x[:-2]))
df['房屋面积']
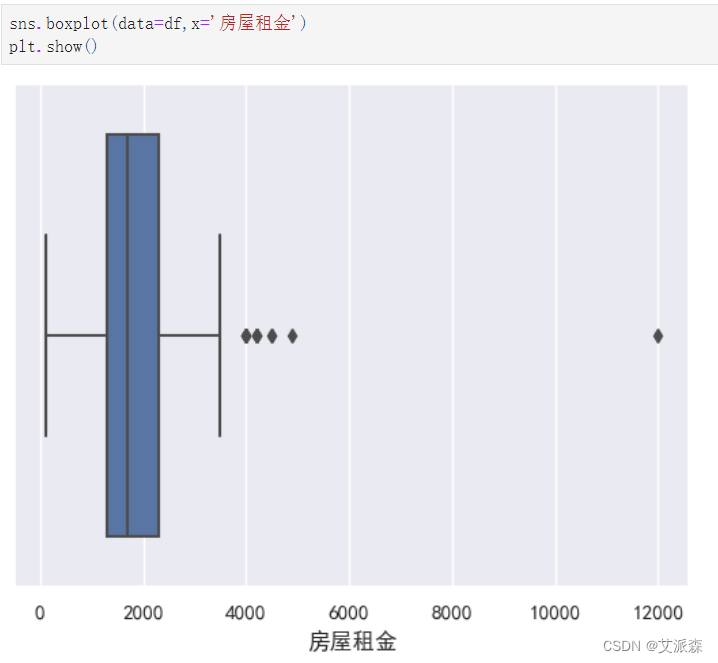
sns.boxplot(data=df,x='房屋租金')
plt.show()
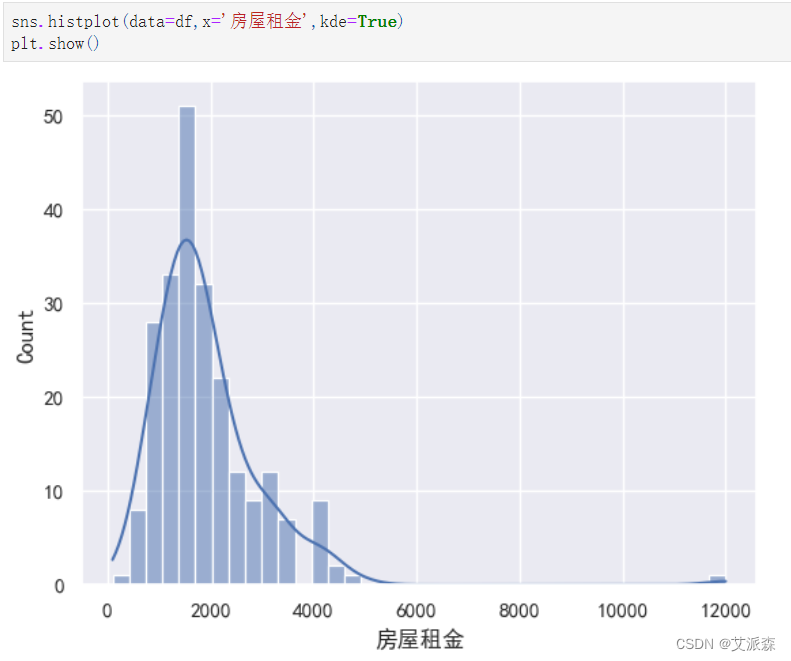
sns.histplot(data=df,x='房屋租金',kde=True)
plt.show()
sns.boxplot(data=df,y='房屋面积')
plt.show()
sns.histplot(data=df,x='房屋面积',kde=True)
plt.show()
plt.scatter(x=df['房屋面积'],y=df['房屋租金'])
plt.show()
sns.countplot(data=df,x='交付方式')
plt.show()
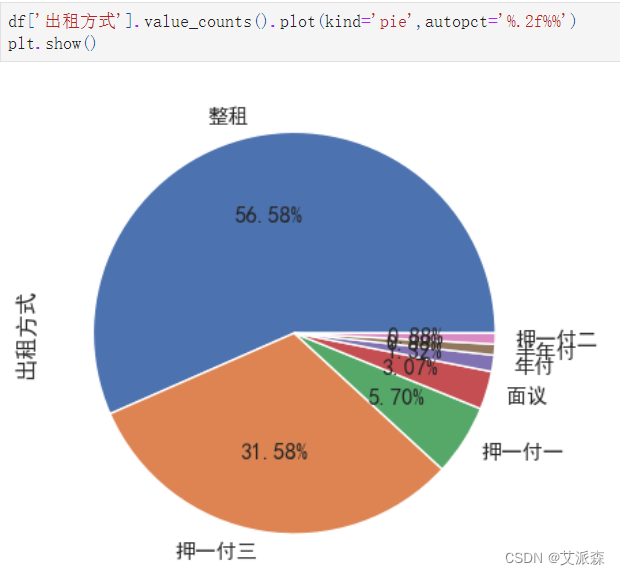
df['出租方式'].value_counts().plot(kind='pie',autopct='%.2f%%')
plt.show()
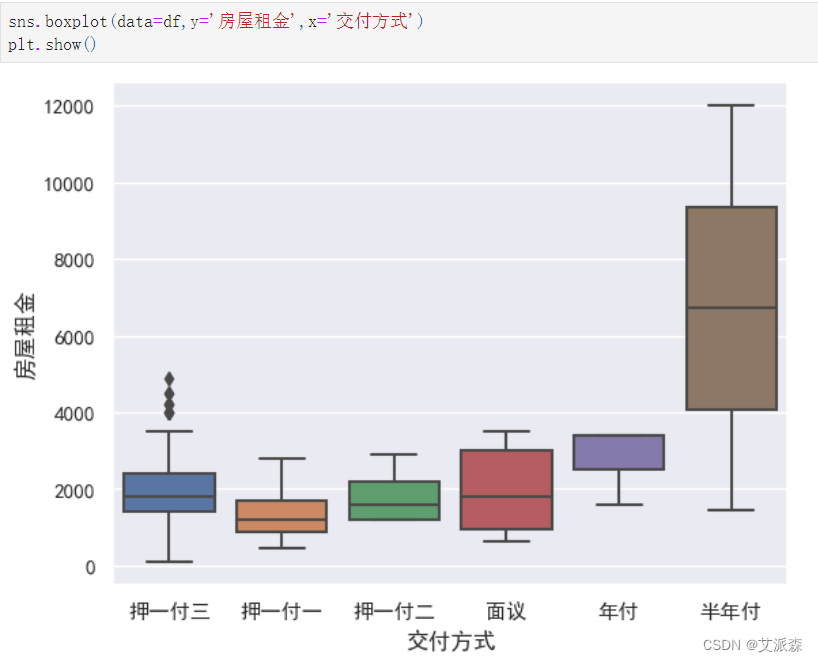
sns.boxplot(data=df,y='房屋租金',x='交付方式')
plt.show()
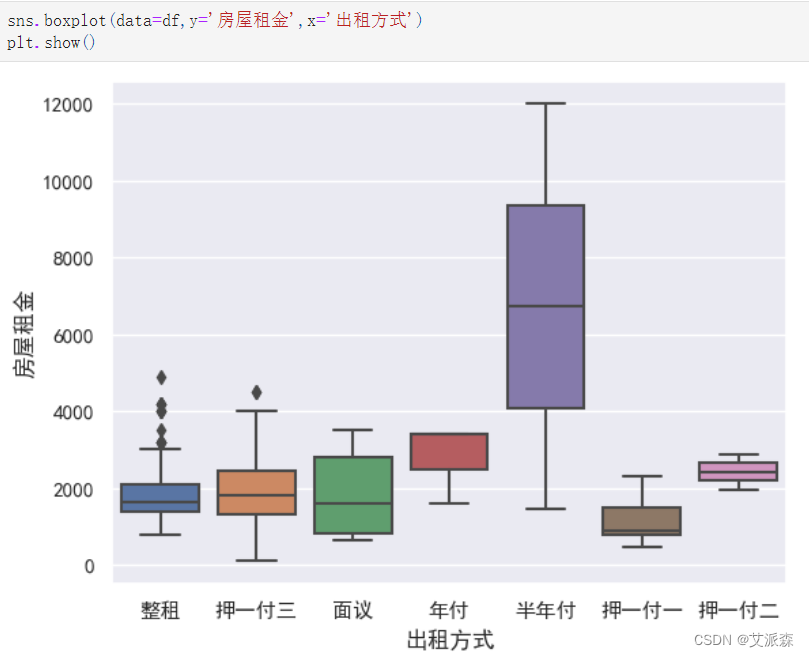
sns.boxplot(data=df,y='房屋租金',x='出租方式')
plt.show()
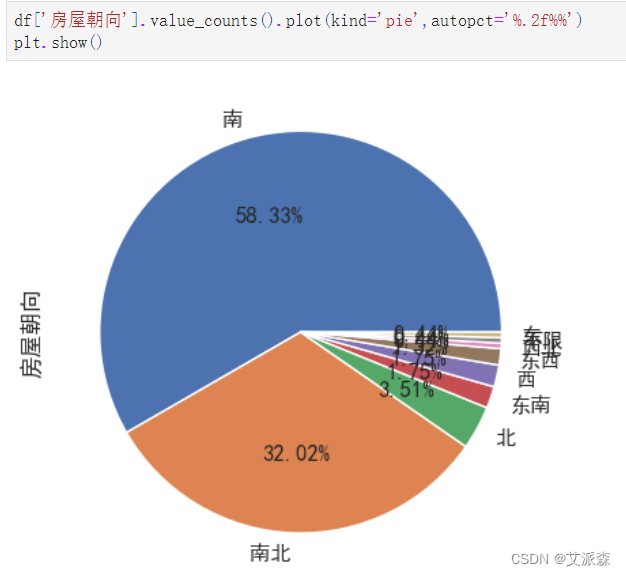
df['房屋朝向'].value_counts().plot(kind='pie',autopct='%.2f%%')
plt.show()
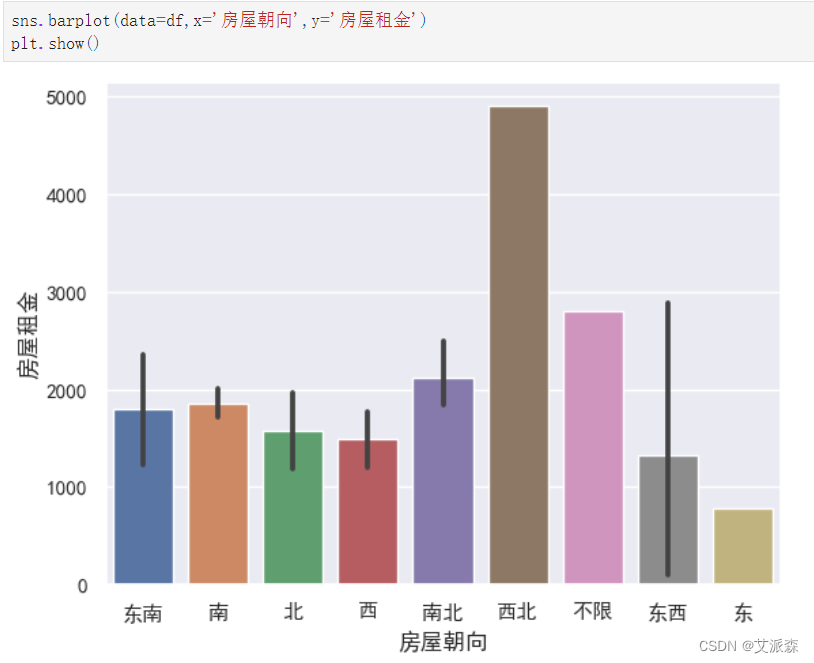
sns.barplot(data=df,x='房屋朝向',y='房屋租金')
plt.show()
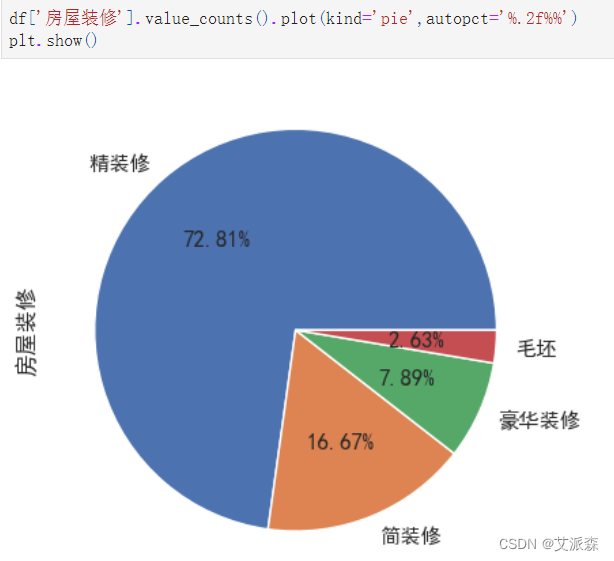
df['房屋装修'].value_counts().plot(kind='pie',autopct='%.2f%%')
plt.show()
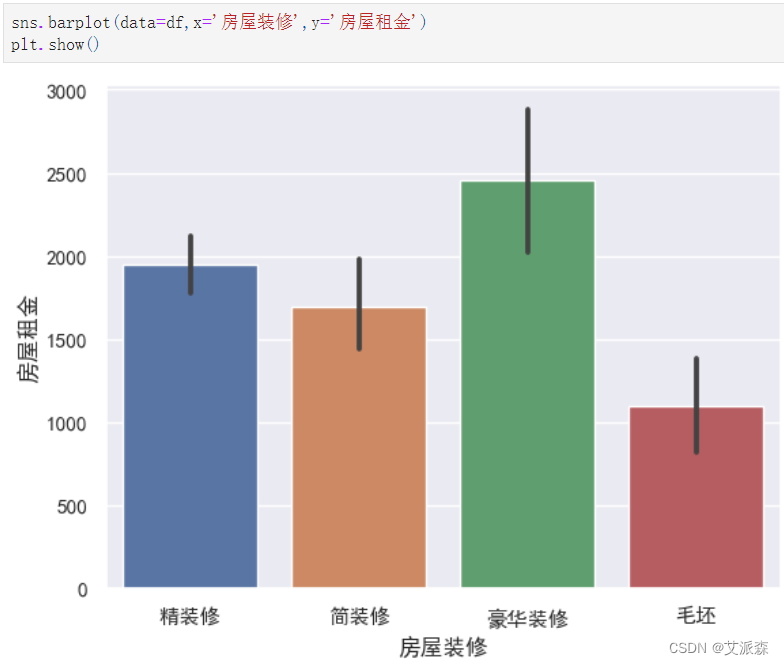
sns.barplot(data=df,x='房屋装修',y='房屋租金')
plt.show()
# 相关性分析
sns.heatmap(df.corr(),vmax=1,annot=True,linewidths=0.5,cbar=False,cmap='YlGnBu',annot_kws={'fontsize':18})
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
plt.title('各个因素之间的相关系数',fontsize=20)
plt.show()
import jieba
import collections
import re
import stylecloud
from PIL import Imagedef draw_WorldCloud(df,pic_name,color='black'):data = ''.join([item for item in df])# 文本预处理 :去除一些无用的字符只提取出中文出来new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)new_data = "".join(new_data)# 文本分词seg_list_exact = jieba.cut(new_data, cut_all=True)result_list = []with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语con = f.readlines()stop_words = set()for i in con:i = i.replace("\n", "") # 去掉读取每一行数据的\nstop_words.add(i)for word in seg_list_exact:if word not in stop_words and len(word) > 1:result_list.append(word)word_counts = collections.Counter(result_list)# 词频统计:获取前100最高频的词word_counts_top = word_counts.most_common(100)print(word_counts_top)# 绘制词云图stylecloud.gen_stylecloud(text=' '.join(result_list[:500]), # 提取500个词进行绘图collocations=False, # 是否包括两个单词的搭配(二字组)font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体,参考位置为 C:\Windows\Fonts\ ,根据里面的字体编号来设置size=800, # stylecloud 的大小palette='cartocolors.qualitative.Bold_7', # 调色板,调色网址: https://jiffyclub.github.io/palettable/background_color=color, # 背景颜色icon_name='fas fa-circle', # 形状的图标名称 蒙版网址:https://fontawesome.com/icons?d=gallery&p=2&c=chat,shopping,travel&m=freegradient='horizontal', # 梯度方向max_words=2000, # stylecloud 可包含的最大单词数max_font_size=150, # stylecloud 中的最大字号stopwords=True, # 布尔值,用于筛除常见禁用词output_name=f'{pic_name}.png') # 输出图片# 打开图片展示img=Image.open(f'{pic_name}.png')img.show()
draw_WorldCloud(df['房源亮点'],'房源亮点词云图') # 词云图可视化
draw_WorldCloud(df['配套设施'],'配套设施词云图') # 词云图可视化
# 编码处理
df['交付方式'].replace({'押一付三':0,'押一付一':1,'面议':2,'押一付二':3,'年付':4,'半年付':5},inplace=True)
df['房屋朝向'].replace({'东':0,'南':1,'西':2,'北':3,'南北':4,'东南':5,'东西':6,'西北':7,'不限':8},inplace=True)
df['房屋装修'].replace({'毛坯':0,'简装修':1,'精装修':2,'豪华装修':3},inplace=True)
# 特征筛选
new_df = df[['房屋租金', '交付方式', '房屋面积', '房屋朝向','房屋装修',]]
new_df
from sklearn.model_selection import train_test_split
# 准备数据
X = new_df.drop('房屋租金',axis=1)
y = new_df['房屋租金']
# 划分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
print('训练集大小:',X_train.shape[0])
print('测试集大小:',X_test.shape[0])
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
# 定义一个训练模型并输出模型的评估指标
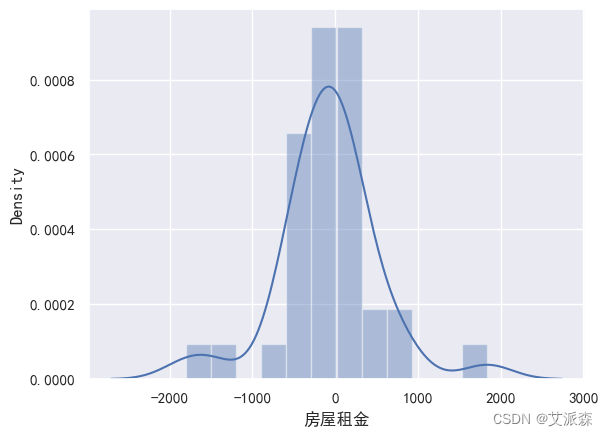
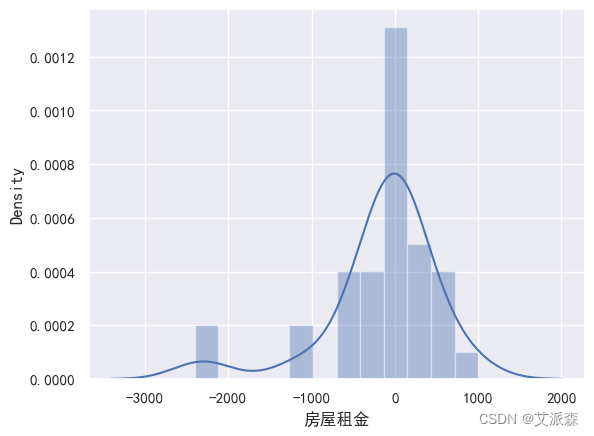
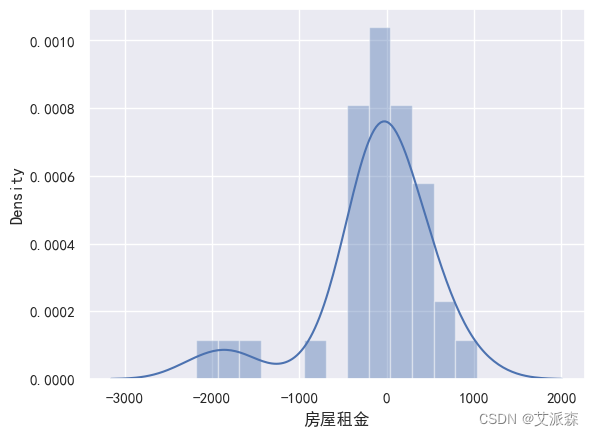
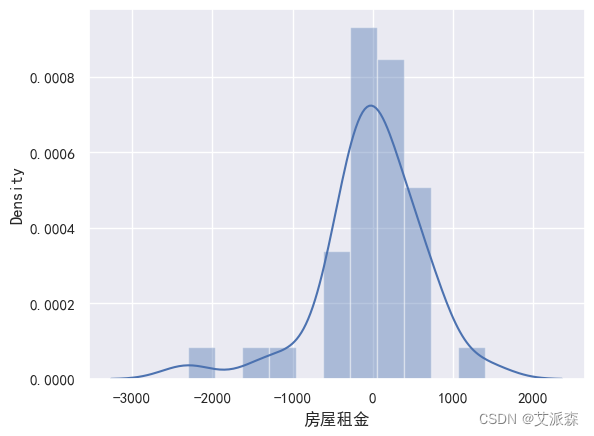
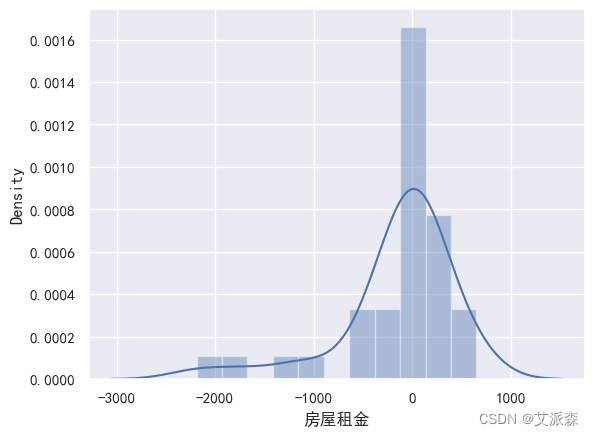
def train_model(ml_model):print("Model is: ", ml_model)model = ml_model.fit(X_train, y_train)print("Training score: ", model.score(X_train,y_train))predictions = model.predict(X_test)r2score = r2_score(y_test, predictions)print("r2 score is: ", r2score)print('MAE:', mean_absolute_error(y_test,predictions))print('MSE:', mean_squared_error(y_test,predictions))print('RMSE:', np.sqrt(mean_squared_error(y_test,predictions)))# 真实值和预测值的差值sns.distplot(y_test - predictions)
# 构建多元线性回归
from sklearn.linear_model import LinearRegression
lg = LinearRegression()
train_model(lg)
# 构建knn回归
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor()
train_model(knn)
# 构建决策树回归
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor()
train_model(tree)
# 构建随机森林回归
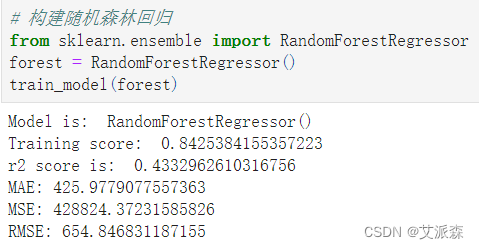
from sklearn.ensemble import RandomForestRegressor
forest = RandomForestRegressor()
train_model(forest)
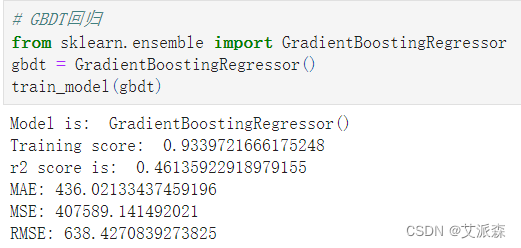
# GBDT回归
from sklearn.ensemble import GradientBoostingRegressor
gbdt = GradientBoostingRegressor()
train_model(gbdt)
# 构建xgboost回归模型
from xgboost import XGBRegressor
xgb = XGBRegressor()
train_model(xgb)
# 特征重要性评分
feat_labels = X_train.columns[0:]
importances = xgb.feature_importances_
indices = np.argsort(importances)[::-1]
index_list = []
value_list = []
for f,j in zip(range(X_train.shape[1]),indices):index_list.append(feat_labels[j])value_list.append(importances[j])print(f + 1, feat_labels[j], importances[j])
plt.figure(figsize=(10,6))
plt.barh(index_list[::-1],value_list[::-1])
plt.yticks(fontsize=12)
plt.title('各特征重要程度排序',fontsize=14)
plt.show()
# 模型预测
y_pred = xgb.predict(X_test)
result_df = pd.DataFrame()
result_df['真实值'] = y_test
result_df['预测值'] = y_pred
result_df.head(10)
# 模型预测可视化
plt.figure(figsize=(10,6))
plt.plot(range(len(y_test))[:200],y_pred[:200],'b',label='predict')
plt.plot(range(len(y_test))[:200],y_test[:200],'r',label='test')
plt.legend(loc='upper right',fontsize=15)
plt.xlabel('the number of house',fontdict={'weight': 'normal', 'size': 15})
plt.ylabel('value of Price',fontdict={'weight': 'normal', 'size': 15})
plt.show()
import joblib
joblib.dump(xgb,'model.pkl')
new_df
x_data = pd.DataFrame(data=[['面议',141,'南','简装修']],columns=['交付方式','房屋面积','房屋朝向','房屋装修'])
x_data
# 编码处理
x_data['交付方式'].replace({'押一付三':0,'押一付一':1,'面议':2,'押一付二':3,'年付':4,'半年付':5},inplace=True)
x_data['房屋朝向'].replace({'东':0,'南':1,'西':2,'北':3,'南北':4,'东南':5,'东西':6,'西北':7,'不限':8},inplace=True)
x_data['房屋装修'].replace({'毛坯':0,'简装修':1,'精装修':2,'豪华装修':3},inplace=True)
x_data
model = joblib.load('model.pkl')
result = model.predict(x_data)[0]
result
资料获取,更多粉丝福利,关注下方公众号获取

相关文章:
基于Python爬虫+机器学习的长沙市租房价格预测研究
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
开发效率翻倍攻略!大学生电脑小白管理秘籍,资料秒搜技巧大公开!C盘满了怎么办?如何快速安全的清理C盘?烦人的电脑问题?一键解决!
如何正确管理自己的第一台电脑?大一新生如何管理自己的电脑?老鸟如何追求快捷操作电脑? 文章目录 如何正确管理自己的第一台电脑?大一新生如何管理自己的电脑?老鸟如何追求快捷操作电脑?前言初级基础分区操…...

[C#数据加密]——MD5、SHA、AES、RSA
一、C#数据加密介绍 数据加密是信息安全领域的一个重要组成部分,它用于保护数据不被未授权访问。以下是一些常见的加密算法和方法: 1、MD5 (Message Digest Algorithm 5): 一种广泛使用的哈希函数,可以产生128位的哈希值。通常用于验证文件完…...

QT不阻塞UI的方式
方法1:QtConcurrent #include <QtConcurrent> #include <QFuture> #include <QFutureWatcher> #include <QDebug>void longRunningTask() {// 模拟耗时操作QThread::sleep(5); }void startTask() {QFuture<void> future QtConcurre…...

鸿蒙HarmonyOS开发:常用布局及实用技巧
文章目录 一、概述二、盒子模型三、线性布局(Column/Row)1、space属性2、justifyContent属性3、alignItems属性 四、实用技巧1、Blank组件的使用2、layoutWeight属性的使用 一、概述 布局是指对页面组件进行排列和定位的过程,其目的是有效地…...

【解答】洛必达法则的使用条件及常见错误,洛必达法则的适用条件,常见的易错点,2022数一第一题例题
目录 洛必达法则的使用条件及常见错误 洛必达法则的适用条件 常见的易错点 举例说明(见D选项) 总结 🌈 嗨,我是命运之光! 🌌 2024,每日百字,记录时光,感谢有你&…...

使用Python下载飞书共享表格数据教程
写在前面 随着企业协作办公软件的流行,飞书以其高效的协作能力和便捷的共享功能,成为了许多公司必备的工具之一。在日常工作中,我们经常需要从飞书中下载共享的表格数据进行分析。本文将详细介绍如何使用Python下载飞书共享表格数据。 前置…...

【C++】protobuf的简单使用(通讯录例子)
protobuf的简单使用(通讯录例子) .proto文件的编写保留字段字段唯一编号protobuf的类型enum类型Any类型oneof类型map类型完整通讯录代码.proto文件write文件read文件运行结果 .proto文件的编写 syntax用于指定protobuf的语法;package当.prot…...

Apple 智能基础语言模型
Introducing Apple’s On-Device and Server Foundation Models technical details June 10, 2024 在2024年的全球开发者大会上,苹果推出了Apple Intelligence,这是一个深度集成到iOS 18、iPadOS 18和macOS Sequoia中的个人智能系统。Apple Intelligen…...

GreptimeDB融资数百万美元; Oracle提供免费长期MySQL; 谷歌大模型支持云数据库问题洞察
重要更新 1. 开源时序数据库 GreptimeDB宣布完成数百万美元的新一轮融资。GreptimeDB是一款Rust 语言编写的时序数据库,具有分布式,开源,云原生,兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时࿰…...

Java中的抽象类与接口
1. 抽象类 1.1 抽象类概念 在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的, 如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。 比如&…...

云计算概念以及与云服务的区别
目录 1.云的概念 1.1 什么是云? 1.2 云计算的类型 1.3 云计算的服务模式 1.4 云计算的优势 2.云计算和云服务的区别 2.1 定义 2.2 范围 2.3 角色 2.5 举例 2.6使用者 3.总结 1.云的概念 1.1 什么是云? “云”在计算机科学和信息技术领域通常…...

Netty技术全解析:LengthFieldBaseFrameDecoder类深度解析
❃博主首页 : 「码到三十五」 ,同名公众号 :「码到三十五」,wx号 : 「liwu0213」 ☠博主专栏 : <mysql高手> <elasticsearch高手> <源码解读> <java核心> <面试攻关> ♝博主的话 :…...
深入InnoDB核心:揭秘B+树在数据库索引中的高效应用
目录 一、索引页与数据行的紧密关联 (一)数据页的双向链表结构 (二)记录行的单向链表结构 二、未创建索引情况 (一)无索引下的单页查找过程 以主键为搜索条件 以非主键列为搜索条件 (二…...

c++(面向对象的性质:抽象,封装,继承,多态)
ctrla全选,ctrli对齐 ctrl/ 一起注释 ctrlz 退回上一步 一些基础的内容: cout:输出流对象 cin:输入流对象 输入一个i和一个j,然后输出ij的和: 值不变的原因: 值传递,a和i是…...

java基础学习笔记1
Java编程规范 命名风格 1. 【强制】代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。 反例:_name / __name / $name / name_ / name$ / name__ 2. 【强制】代码中的命名严禁使用拼音与英文混合的方式,更不允许直…...

[VBA]使用VBA在Excel中 操作 形状shape 对象
excel已关闭地图插件,对于想做 地图可视化 的,用形状来操作是一种办法,就是要自行找到合适的 地图形状,修改形状颜色等就可以用于 可视化展示不同省市销量、人口等数据。 引言 在Excel中,通过VBA(Visual Basic for Applications)可以极大地增强数据可视化和报告自动化…...

Apache POI 实现 Excel 表格下载
这里以苍穹外卖中数据导出功能为例,记录下 Apache POI 导出 Excel 表格的过程。 首先在 pom.xml 中导入相关依赖 <!-- poi 用于操作 excel 表格--> <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId&…...
)
大华嵌入式面试题大全及参考答案(2万字长文)
目录 在C语言中,static 关键字有哪些主要用途? static 修饰的全局变量与普通全局变量有什么区别? 为什么要在嵌入式系统中使用 static 修饰函数? 虚函数与纯虚函数了解么? strcpy 给你加结束符吗,还是要自己加? select 的作用是什么,它和 epoll 的区别? map 与…...

C语言——查漏补缺
前言 本篇博客主要记录一些C语言的遗漏点,完成查漏补缺的工作,如果读者感兴趣,可以看看下面的内容。都是一些小点,下面进入正文部分。 1. 字符汇聚 编写代码,演示多个字符从两端移动,向中间汇聚 #inclu…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

XML 服务器
XML 服务器 引言 XML(可扩展标记语言)服务器在现代互联网技术中扮演着至关重要的角色。它为数据的传输和处理提供了灵活且高效的方式。本文将深入探讨XML服务器的概念、工作原理、应用场景及其在软件开发中的重要性。 什么是XML服务器? XML服务器是一种用于存储、处理和…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...