「Pytorch」BF16 Mixed Precision Training
在深度学习领域,神经网络的训练性能瓶颈常常出现在 GPU显存的使用上。主要表现为两方面:
- 单卡上可容纳的模型和数据量有限;
- 显存与计算单元之间的带宽和延迟限制了运算速度;
为了解决显卡瓶颈的问题,涌现了不同的解决方法。
模型参数量估计
为了更好地估算模型所要占用的显存,首先需要分析模型训练过程中有哪些部分需要消耗存储空间。在 “ZeRO: Memory Optimizations Toward Training Trillion Parameter Model” 中提出,模型在训练时,主要有两大部分的空间占用。
- 对于大模型来说,主要的空间占用是模型状态,包括优化器状态(eg:Adam优化器的动量和方差)、模型参数和模型参数的梯度;
- 剩余的空间主要被模型训练中间激活值、临时缓冲区和不可用的内存碎片占用,统称为剩余状态。
以 3.5B 大模型为例。①35亿个参数,如果使用 FP16进行存储的话,即 70亿个字节,约7GB左右;②前向传播的激活值和反向传播的梯度大小跟模型参数保持一致,约 7GB;③以 Adam优化器为例,包括三部分,分别为 FP32格式模型参数的备份,FP32的动量和方差,加起来约28GB;因此,从理论上,要微调此模型的话,至少需要 49GB的空间。
1、BF16 半精度浮点数
双精度浮点 Float64;单浮点精度 Float32;半浮点精度 Float16,被广泛应用于model推理
为了进一步降低计算量和显存占用,可以考虑整数int4和int8量化推理
之前深度学习模型的训练通常都采用 Float32(FP32)的精度,而作者发现,使用较低的精度来进行模型的训练也是可行的,并且能够显著提升速度。通过采用混合精度训练,一般可以实现 2~3 倍的速度提升,极大的优化了模型的训练流程。
- FP32 整体长度为4个字节,即32位,其中有8位的指数位宽,23位的尾数精度和1位的符号位,能够表示的数值范围是 1 × 2 − 126 ∼ ( 2 − ϵ ) × 2 127 1\times 2^{-126} \sim (2-\epsilon)\times 2^{127} 1×2−126∼(2−ϵ)×2127 ;
- 在一些不太需要高精度计算的应用中,eg:图像处理和神经网络中,32位的空间其实有一些浪费,因此又出现了新的数据类型,半精度浮点数 FP16,使用16位(2个字节)来存储浮点值,有5位的指数位宽,10位的尾数精度和1位的符号位,能够表示的数值范围是 1 × 2 − 14 ∼ ( 2 − ϵ ) × 2 15 1\times 2^{-14} \sim (2-\epsilon)\times 2^{15} 1×2−14∼(2−ϵ)×215;
| 格式 | 位数/位 | 指数位宽/位 | 尾数精度/位 | 符号位/位 | 数值范围 |
|---|---|---|---|---|---|
| FP32 | 32 | 8 | 23 | 1 | 1 × 2 − 126 ∼ ( 2 − ϵ ) × 2 127 1\times 2^{-126} \sim (2-\epsilon)\times 2^{127} 1×2−126∼(2−ϵ)×2127 |
| FP16 | 16 | 5 | 10 | 1 | 1 × 2 − 14 ∼ ( 2 − ϵ ) × 2 15 1\times 2^{-14} \sim (2-\epsilon)\times 2^{15} 1×2−14∼(2−ϵ)×215 |
| BP32 | 16 | 8 | 7 | 1 | 1 × 2 − 126 ∼ ( 2 − ϵ ) × 2 127 1\times 2^{-126} \sim (2-\epsilon)\times 2^{127} 1×2−126∼(2−ϵ)×2127 |
混合精度训练,即在模型训练时同时采用 FP32 和 FP16 两种精度。在实践过程中,研究人员发现在大语言模型的训练中直接使用 FP16会有一些问题,在训练过程中 loss 会非常不稳定,因此使用 FP16 训练大模型非常困难。问题在于 FP16的指数位宽只有 5位,能表示的最大整数为 65504,一旦权重超过这个值就会发生溢出,因此只能进行较小数的乘法,eg:可以计算 250 × 250 = 62500 250\times250=62500 250×250=62500,但如果计算 255 × 255 = 65025 255\times 255=65025 255×255=65025 就会溢出,这是导致训练出现问题的主要原因。这也意味着模型权重必须保持很小。一种成为损失缩放的技术可以缓解这个问题,但是当模型变得非常大时,FP16 较小的数值范围依旧是一个问题。
- 为了更好地解决 FP16的问题,谷歌开发了一种新的浮点数格式 BF16(Brain Floating Point, 2个字节),用于降低存储需求,提高机器学习算法的计算速度。BF16 的指数位宽为8位,于 FP32相同,尾数精度采用7位,因此当使用 BF16时,精度非常差。然而,在训练模型时一般采用随机梯度下降法及其变体,其过程像蹒跚而行,即使某一步没有找到最优方向也没关系,模型会在后续调整纠正。
将模型参数类型从 FP16换为 BF16,训练的大模型 loss值的下降也会变得更加稳定。
这种低精度和 混合精度训练的方法逐渐被广泛接受和应用,深度学习框架、GPU以及 神经网络加速器的设计也因此受到了深渊的影响。可以说,混合精度训练的提出,对深度学习领域起到了关键的推动作用,有效地解决了 GPU显存的使用问题,提升了模型训练的效率。
2、混合精度训练
paper:Mixed Precision Training
- 维护一个权重的单精度副本,在每个优化器步骤后累计梯度(对于前向和反向传播,此副本四舍五入到半精度);
- 提出了损失缩放来保持小幅度的梯度值;
- 使用半精度算法,该算法累积为单精度输出,在存储到内存之前将其转化为半精度;

FP32 为主副本权重,
在混合精度训练时,权重、激活函数、梯度被保存为 FP16,为了与 FP32模型的精度相匹配,在optimizer step时,维持 FP32权重为主线,并使用权重梯度进行更新。在每次迭代时,主权重的 FP16副本用于前向和反向传播,将 FP32训练所需的存储和带宽减半,如上图所示。
虽然对 FP32住权重的需求并不普遍,但许多模型还需要 FP32的两个可能原因是:
- 权重更新变得太小,无法在 FP16中表示,任何大小小于 2 − 24 2^{-24} 2−24 的值在 FP16中都将变为 零,当与学习率相乘时,这些小值梯度在优化器中都会变为零,并对模型的准确性产生不利影响。使用单精度进行更新可以解决这一问题;
- 权重值 与 权重更新的比例非常大。在这种情况下,即使权重更新可以在 FP16中表示,当加法操作将其右移以使二进制点与权重对齐时,它仍然可能变为零。当归一化权重值的幅度比权重更新的新幅度大 至少2048倍,就会发生这种情况。由于 FP16有10位尾数,隐式位必须右移11位或更多位置,才能潜在地创建一个零。在比例大于2048时,隐式比特将右移12位或更多位。这将导致权重更新变得无法恢复的零。更大的比例将导致非标注化数字的效果。同样,可以通过计算 FP32中的更新来抵消这种影响。
图2-a所示,在 FP16前后传播更新 FP32权重主线时,匹配FP32训练结果,而更新FP16权重会导致 80%的相对精度损失。
由于更大的 batch-size 和每层的激活被保存以在反向传播过程中重复使用,因此训练内存消耗主要由激活决定。由于激活也以半精度格式存储,因此训练深度神经网络的整体内存消耗大约减半。
2.1 损失缩放
FP16指数偏差将归一化指数的范围集中到 [-14,15],而实践中的梯度值往往由小幅度(负指数)主导,如图3所示,显示了Multibox SSD模型的 FP32训练期间在所有层上的急活梯度值的直方图,FP16 可表示范围的大部分未必使用,而许多值低于最小可表示范围 变为指数为0。放大梯度将使它们占据更多的可表示范围,并保留否则会丢失为0的值。当梯度未被缩放时,这个特定的网络会发散,但将其压缩8倍(指数为3)就足以匹配 FP32训练所达到的精度。这说明激活


2.2运算精度
神经网络模型分为三类:vector dot-products, reductions, point-wise operations。当涉及到降低精度的算法时,这些类别受益于不同的处理,为了保持模型的准确性,发现一些模型要求 FP16矢量点积将部分累加成 FP32,在写入内存之前将其转换为 FP16。如果 FP32中没有这种积累,一些 FP16模型与基线模型的精度不匹配。
之前的GPU只支持 FP16 乘/加法运算,而 NVIDIA Volta GPU引入了 Tensor Core,可以将 FP16输入矩阵相乘,并将乘积累加到 FP16或 FP32输出中。
FP32中应进行大幅缩减(向量各元素之和)。在累积统计数据和 softmax层时,这种建好主要出现在 batch-normalization 层中。在两种层类型种,仍然从内存中读取和写入FP16张量,在 FP32中执行算术运算,这并没有减缓训练过程,因为这些层的内存带宽有限,对算术速度不敏感。
逐点操作,如非线性和逐像素矩阵运算,是内存带宽有限,由于算术精度不影响这些运算的速度,因此可以使用FP16 或 FP32.
相关文章:
「Pytorch」BF16 Mixed Precision Training
在深度学习领域,神经网络的训练性能瓶颈常常出现在 GPU显存的使用上。主要表现为两方面: 单卡上可容纳的模型和数据量有限;显存与计算单元之间的带宽和延迟限制了运算速度; 为了解决显卡瓶颈的问题,涌现了不同的解决…...

论文阅读:Efficient Core Maintenance in Large Bipartite Graphs | SIGMOD 2024
还记得我们昨天讨论的《Querying Historical Cohesive Subgraphs over Temporal Bipartite Graphs》这篇论文吗? https://blog.csdn.net/m0_62361730/article/details/141003301 这篇(还没看的快去看) 这篇论文主要研究如何在时间双向图上查询历史凝聚子图,而《E…...
LLMOps — 使用 BentoML 为 Llama-3 模型提供服务
使用 BentoML 和 Runpod 快速设置 LLM API 经常看到数据科学家对 LLM 的开发感兴趣,包括模型架构、训练技术或数据收集。然而,我注意到,很多时候,除了理论方面,许多人在以用户实际使用的方式提供这些模型时遇到了问题…...

微软蓝屏事件揭秘:有问题的数据引发内存读取越界
讲动人的故事,写懂人的代码 CrowdStrike前一阵在官网上发布了上周爆发的全球企业微软蓝屏事件的官方初步复盘结果。其中谈到了这次事件的根本原因: 2024年7月19日,我们部署了两个额外的IPC模板实例。由于内容验证器中的一个bug,使…...

NASA:北极ARCTAS差分吸收激光雷达(DIAL)遥感数据
ARCTAS Differential Absorption Lidar (DIAL) Remotely Sensed Data ARCTAS差分吸收激光雷达(DIAL)遥感数据 简介 ARCTAS差分吸收激光雷达(DIAL)遥感数据是一种远程感测技术,用于测量大气中不同波长的激光辐射被大…...

Android 文件上传与下载
在实际开发涉及文件上传不会自己写上传代码,一般 会集成第三网络库来做图片上传,比如android-async-http,okhttp等,另外还有七牛也提供 了下载和上传的API。 1.项目用到的图片上传的关键方法: 这里用到一个第三方的库…...

Java语言的充电桩系统Charging station system
介绍 SpringBoot 框架,充电桩平台充电桩系统充电平台充电桩互联互通协议云快充协议1.5-1.6协议新能源汽车二轮车公交车二轮车充电-四轮车充电充电源代码充电平台源码Java源码-共享充电桩-充电桩软件 软件介绍 小程序端:城市切换、附近电站、电桩详情页…...

RCE之无参数读取文件
什么是无参数? 顾名思义,就是只使用函数,且函数不能带有参数,这里有种种限制:比如我们选择的函数必须能接受其括号内函数的返回值;使用的函数规定必须参数为空或者为一个参数等 例题: <?…...

Python GUI开发必看:Tkinter Button控件使用详解
Button(按钮)组件用于实现各种各样的按钮。 Button组件可以包含文本或图像,你可以将一个Python的函数或方法与之相关联,当按钮被按下时,对应的函数或方法将被自动执行。 Button组件仅能显示单一字体的文本,…...

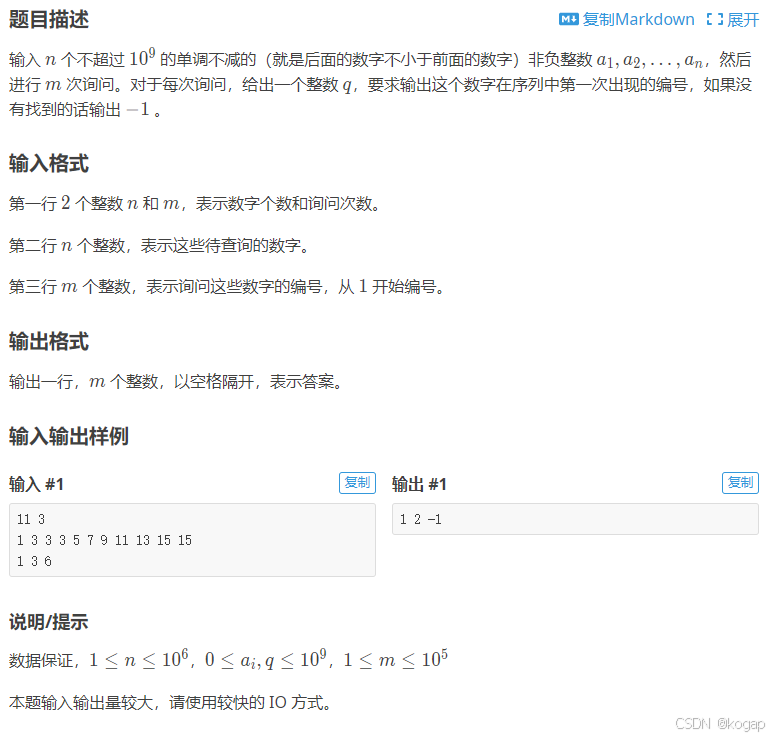
上海市计算机学会竞赛平台2024年7月月赛丙组得分排名
题目描述 给定 nn 名学生的考试得分,这些学生的学号为 11 到 nn,其第 ii 号学生的得分为 aiai,请将这些学生按照分数从大到小的顺序排列并输出学号序列。 若两个学生得分相同,则先输出较小的学号。 输入格式 第一行…...

Can GPT-3 Perform Statutory Reasoning?
文章目录 题目摘要相关工作SARAGPT-3 对美国法典的了解GPT-3 在对合成法规进行简单推理时遇到困难结论 题目 GPT-3 可以进行法定推理吗? 论文地址:https://arxiv.org/abs/2302.06100 摘要 法定推理是用事实和法规进行推理的任务,法规是立法机…...

redis面试(十一)锁超时
boolean res lock.tryLock(100, 10, TimeUnit.SECONDS); RedissonLock里面有这样一个方法tryLock(),意思是尝试获取锁的结果。 最大等待时间100s,并且获取到锁之后,10s之内没有释放的话,锁会自动失效。 尝试获取锁超时 time …...

C代码做底层及Matlab_SimuLink做应用层设计单片机程序
前言:SimuLink工具极其强大,但是能直接支持单片机自主开发的很少,造成这个问题的原因主要是我们使用的芯片底层多是C代码工程,芯片厂家也只提供C代码库,很少能提供SimuLink的支持库,即使提供也不是很不完善,如NXP的一些芯片提供的SimuLink库不含盖高级应用,再比如意法半…...

Cloud Kernel SIG 月度动态:ANCK OOT 驱动基线更新,发布 2 个 ANCK 版本
Cloud Kernel SIG(Special Interest Group):支撑龙蜥内核版本的研发、发布和服务,提供生产可用的高性价比内核产品。 01 SIG 整体进展 1. 发布 ANCK 5.10-016.4 小版本。 2. 发布 ANCK 5.10-017.1 小版本。 3. ANCK 新增海光平…...

vue3仿飞书头像,根据不同名称生成不同的头像背景色
效果展示: 传递三个参数: name:要显示的名称;size:头像的大小;cutNum:分割当前名称的最后几位数; 代码如下: <template><div:style"{color: #fff,borde…...

SpringBoot整合三方
SpringBoot整合redis 引入redis依赖包 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>redis.clients</groupId&g…...

React之组件的使用
Vue、React和Angular是三个流行的前端框架,采用组件化的开发方式。支持虚拟DOM(Virtual DOM)技术,有丰富的生态系统、大量的插件和工具可以使用。Vue的语法是传统的HTML和JavaScript,React使用JSX语法,Angu…...

深度学习--长短期记忆网络
1.引入 RNN 可以将以前的信息与当前的信息进行连接。例如,在视频中,可以用前面的帧来 帮助理解当前帧的内容;在文本中,可以用前面半句话的内容来预测后面的内容。但是, RNN 存在一个记忆消失的问题。例如,…...
研0 冲刺算法竞赛 day29 P2249 【深基13.例1】查找
P2249 【深基13.例1】查找 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 思路: ①二分查找 ②stl函数:lower_bound(a.begin(),a.end(),x) 返回第一个大于等于 x的数的地址 代码: #include<iostream> #include<algorithm> …...

基于vue框架的CKD电子病历系统nfa2e(程序+源码+数据库+调试部署+开发环境)系统界面在最后面。
系统程序文件列表 项目功能:患者,医生,药品信息,电子病历,临时医嘱,长期医嘱,健康科普 开题报告内容 基于Vue框架的CKD电子病历系统 开题报告 一、选题背景 随着信息技术的飞速发展和医疗信息化的深入推进,电子病历系统(Electronic Medic…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...