YOLO-V1~V3经典物体检测算法介绍
大名鼎鼎的YOLO物体检测算法如今已经出现了V8版本,我们先来了解一下它前几代版本都做了什么吧。
本篇文章介绍v1-v3,后续会继续更新。
一、节深度学习经典检测方法概述
1.1 检测任务中阶段的意义
我们所学的深度学习经典检测方法 ,有些是单阶段的,有些是两阶段的:
one-stage(单阶段):YOLO系列
two-stage(两阶段):Faster-rcnn、Mask-Rcnn系列
单阶段:
我们进行物体检测,简单来说,只需要的到四个值就可以了(图片中某个物体的左上x1y1、右下x2y2角的坐标),这四个值x1、y1、x2、y2我们通过回归任务就可完成。
只通过一个CNN网络提取特征,不去做其它的映衬,然后通过回归获得预测结果。

两阶段:
同样对于输入的图片通过CNN提取特征,最终结果依旧是获取猫的位置,只不过这里多了一个RPN区域建议网络,生成了多个预选框,我们最后在这些预选框里选择出所需要的结果。

1.2 不同阶段算法优缺点分析
one-stage:
最核心的优势:速度非常快,适合做实时检测任务!
但是缺点也是有的,效果通常情况下不会太好!

two-stage:
速度通常较慢(5FPS),但是效果通常还是不错的!
非常实用的通用框架MaskRcnn,建议熟悉下!
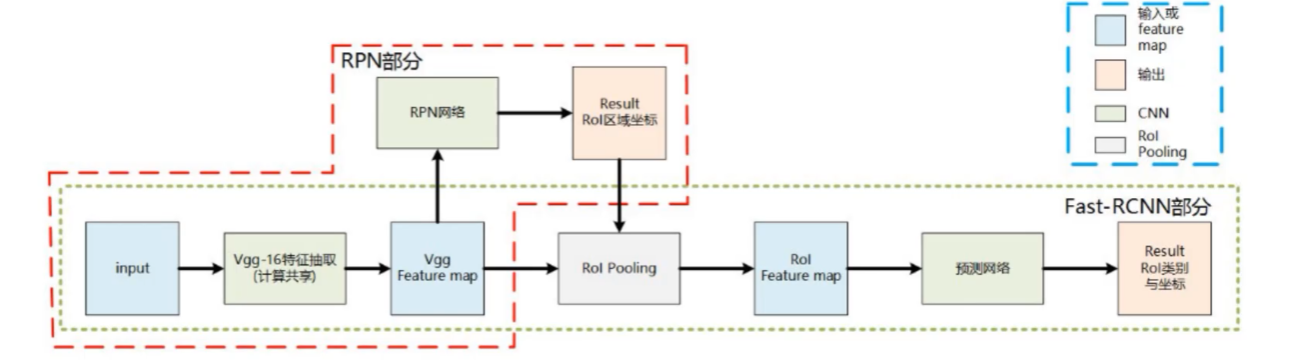
前面说到过了,像是YOLO特征提取后直接回归,步骤单一所以速度会比较快但是效果稍差,而像是Mask-Rcnn多了一步预选处理,效果不错但是速度会比较慢。一般视频任务中,我们要求实时监测,所以应该选用YOLO,当然FPS也是不固定的,总之网络越复杂,效果越好,速度越慢,反之那就反之。
1.3 YOLO指标计算
map指标:综合衡量检测效果;单看精度或recall不行吗?
精度:检测出来的框与实际是否吻合
召回率:有没有一些框没有检测到
二者一般相互矛盾,一个高了另一个就会低,所以单看某一个指标无法判断效果的好坏。
我们通常用mAP指标进行衡量。
IOU:交集和并集的比值

如图蓝色的是真实值/标记值,橙色是预测值,IOU越高,越接近1,效果越好,说明越“重合”。
我们希望橙色的预测框与蓝色的标记框越接近越重合越好(精度越高越好),同时我们希望把图片中需要检测出来的东西全部检测出来(召回率越高越好),比如上图如果还需要检测窗户等。
1.4 MAP指标计算

基于置信度阈值来计算,例如分别计算0.9;0.8;0.7
置信度:如检测的是人脸,置信度表示这是一个人脸的可能性。比所选置信度小的框就不要了。
如置信度选0.9时,对于上面三张图片:TP=1 FP=0 FN=2则Precision=1/1;Recall=1/3 ,即对于第一张图片是人脸也被检测出来了TP=1,第二三张图片是人脸没被检测出来(漏检)FN=2。
如何计算AP呢?需要把所有阈值0-1都考虑进来;MAP就是所有类别的平均。
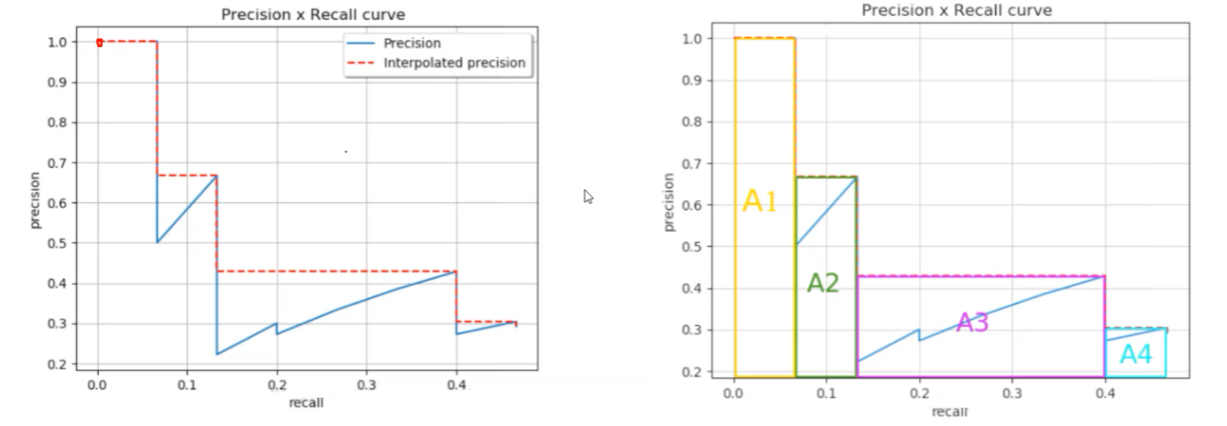
上图纵坐标是精度,横坐标是召回率,可见精度高的时候召回率比较低,召回率高的时候精度比较低。
MAP即红线下方所围成的面积(取的最大值),即右侧A1+A2+A3+A4
当然,我们希望MAP越接近1(一个大矩形)越好。
二、YOLO-V1整体思想与网络架构
2.1 YOLO算法整体思路解读
YOLO-V1:
经典的one-stage方法
You Only Look Once,你只看一次,名字就已经说明了一切!
把检测问题转化成回归问题,一个CNN就搞定了!
可以对视频进行实时检测,应用领域非常广!

核心思想:
预测一张图片上有哪些个物体,比如下图,有狗、自行车、汽车。假设这张图片大小为7x7,一共49个格子,我们要求这49个格子自己预测在自己这个格子上的是什么物体。
比如图片左侧的狗落在图片的一个区域之中,但我们只关心它的中心点落在哪里,如图红色的格子它就负责预测这条狗,有一个物体落在红色格子上面了并且红色格子还是中心点。
49个格子预测自己所代表的是什么,或者说物体落到了以这个格子为中心点的话,这个格子需要把这个物体给预测出来。

如图红色的格子去做预测,但它也不知道狗长什么样子,但是有一些经验值比如一些物体是长方形的一些物体是正放心的h1w1,h2w2(如上图黄色的框),显然对于上图长方形的框更好一点(有真实值,长方形的IOU更高,派他上场),我们把候选框进行微调,即回归任务,找出最合适的h和w,并找出起始位置(v1:xy,hw)。
由于有很多个格子,就会产生很多个中心点坐标和候选框,但有一些框起来的不是一个物体(背景),所以我们还需要一个置信度confidence,来确定框起来的是不是物体,不是(小于)那就去掉。
简单来说V1版本关键词:
四个偏移量:中心点、两种候选框(选其一),x、y和h、w。
一个置信度的值:判断是否一个物体,是的话进行回归微调四个偏移量
2.2 网络架构解读
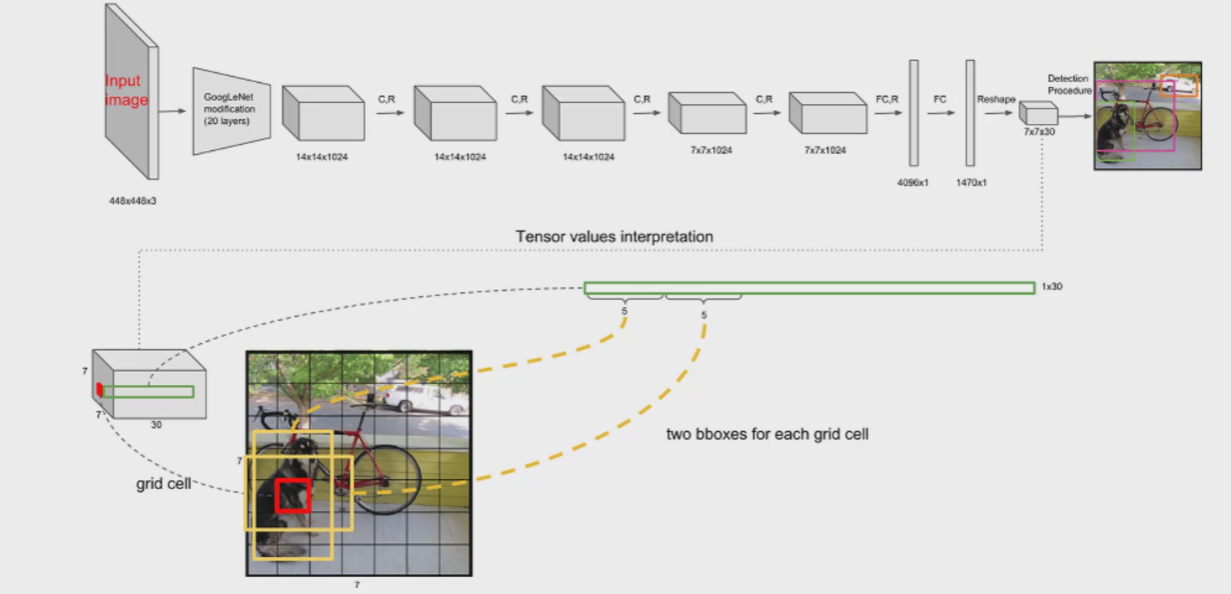
V1版本中,测试时输入大小为448*448*3,(训练时用224*224 当时计算机性能可能比较差,V2后进行改进。)相对来说是个固定值,进行特征提取,得到7*7*1024的特征图,进行全连接再reshape后,得到7*7*30。
其中,7*7就是前面说的那个“格子”,实际上一个格子代表这部分感受野的信息/特征等。
前面提到V1版本有两个候选框,h1w1x1y1和c1,h2w2x2y2和c2,这样就有了5+5=10个值,7*7*30这30里除了这10个值,剩下的20则是20分类,20个概率值。

这里B是框的个数=2,C是类别个数=20
(7*7) * (2*5+20)
2.3 位置损失计算

位置损失:
对于每个格子的每两个候选框,选择IOU最大的那个,计算真实值的预测值之间的差异(xywh)。
有些物体比较大,wh差不太多就可以,但对于小的物体,wh相差一定的值就会不好,因此这里将wh进行了开根号处理(数值较小的时候相对敏感一些)。
置信度误差:
一张图片的背景要多于前景,我们要分类讨论它预测的是前景还是背景。
我们让真实值前景置信度为1,背景为0。
如果一个候选框和真实框的IOU大于一定阈值如0.5,我们认为它是一个前景,希望它的confidence接近1(它毕竟不是一个真实框,有自己的IOU),IOU越大越好。
小于0.5或者没有的时候,便是背景,置信度为0。
(自己的置信度-真实置信度)²,前景直接算背景加权重参数。
分类误差:
交叉熵计算。
2.4 NMS非极大值抑制
即我们最后会得到好多个框(经过IOU大于一定阈值筛选后),先按置信度进行排序,选置信度最大的,别的就不要了。
2.5 优缺点分析
优点:
快速,简单!
缺点:
每个Cell只预测一个类别,如果重叠无法解决
小物体检测效果一般,长宽比可选的但单一
小物体一般检测不到,B1,B2候选框经验值一般是大的。假如多个物体重合在一起,如狗和猫前后在一起,一个格子预测结果出来是狗就预测不到猫了。多标签处理也不好做,如狗、斑点狗哈士奇等。
三、YOLO-V2改进细节

整体的网络架构和思想相较于V1没有变化,改进了网络在实现过程中的小细节。
加入上表那些细节后,mAP由63.4提升到了78.6。
3.1 YOLO-V2-Batch Normalization
V2版本舍弃Dropout,卷积后全部加入Batch Normalization
网络的每一层的输入都做了归一化,收敛相对更容易
经过Batch Normalization处理后的网络会提升2%的mAP
从现在的角度来看,Batch Normalization已经成网络必备处理
3.2 YOLO-V2-更大的分辨率
V1训练时用的是224*224,测试时使用448*448
可能导致模型水土不服,V2训练时额外又进行了10次448*448 的微调
使用高分辨率分类器后,YOLOv2的mAP提升了约4%
3.3 YOLO-V2-网络结构
DarkNet网络结构(借鉴了VGG Restnet),实际输入为416*416(为什么不是448?要被32整除才行,希望结果是奇数有实际中心点。)。
没有FC(全连接)层(容易过拟合、参数多训练慢),5次降采样(2*2池化,共缩小了32倍),最后得到13*13(416/32)的特征图(第一代版本7*7小了点,先验框也是。)。
3*3的卷积借鉴了VGG参数比较少感受野比较大。1*1卷积节省了很多参数,在1*1卷积这步只改变了特征图的个数。 ps:1*1卷积可以用来降维/升维,增加非线性特征(激活函数)等
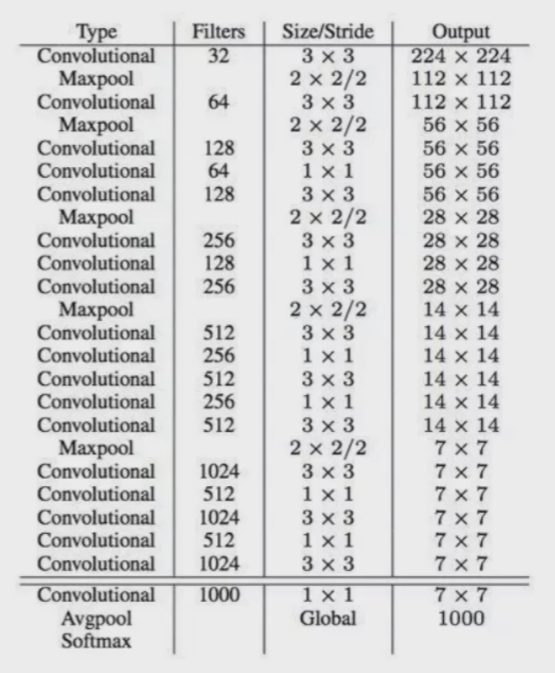
注:上图output那一列仅供参考,实际上输入416输出13。
之前要全连接全连接reshape:

3.4 YOLO-V2-聚类提取先验框
faster-rcnn系列选择的先验比例都是常规的,但是不一定完全适合数据集
K-means聚类中的距离:
 ,有的框大有的框小,使用欧氏距离的话大的框产生差异的情况也会比较大,所以使用IOU进行距离度量,IOU=1时效果越好d=0。
,有的框大有的框小,使用欧氏距离的话大的框产生差异的情况也会比较大,所以使用IOU进行距离度量,IOU=1时效果越好d=0。
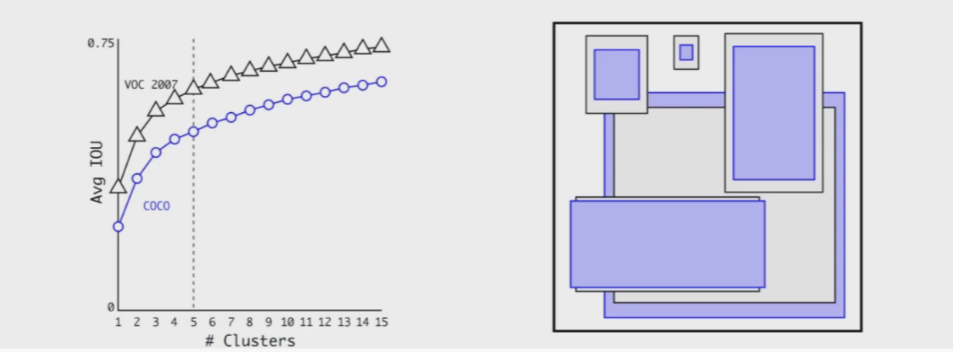
之前学的YOLO-V1里面B=2,但正常的物体不就是什么长方形正方形这两种形状,faster-rcnn这种2-stage的方法用了9种先验框,YOLO-V2版本一想自己也多加几种吧。
faster-rcnn里使用如1:1 1:2 2:1三种比例的框,每种比例分不同大小各3个,共9个框。YOLO-V2中使用聚类在某数据集如COCO中进行先验框提取,比如Kmean中的K=5那就分出5堆长宽比不同的先验框,每堆长宽相近,比如300:200一堆,316:271一堆,110:115一堆...。这样更加合适一些。
上图左边横坐标是Kmeans中k的取值,纵坐标是平均IOU。K越小,堆之间差异越大,K越大,堆之间差异越小越“细腻”,一般选K=5。右边就是那5个堆。
V1版本B=2,V2版本K=5,从两种框提升到了5种框。
3.5 YOLO-V2-Anchor Box
通过引入anchor boxes,使得预测的box数量更多(13*13*n)
跟faster-rcnn系列不同的是先验框并不是直接按照长宽固定比给定

上图可见有无先验框对mAP没怎么变(略微下降)。因为先验框多了也就是说框起来的虽然多了,但不一定框的都对。
但是召回率上升了,也就是查全率提升,图像中但凡有真实值标记出来的被检测出的可能性更大一点,毕竟框多了。
3.6 YOLO-V2-Directed Location Predictio
bbox:中心为(xp,yp);宽和高为(wp,hp),则
 。如tx=1,则将bbox在x轴向右移动wp;tx=−1则将其向左移动wp
。如tx=1,则将bbox在x轴向右移动wp;tx=−1则将其向左移动wp
这样会导致收敛问题(乱移动),模型不稳定,尤其是刚开始进行训练的时候。V2中并没有直接使用上面的偏移量,而是选择相对grid cell的偏移量(这样无论怎么偏移都不会偏移出中心点这个格子)

计算公式为:



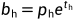
其中 为sigmoid函数,这里用sigmoid函数是为了让预测框的中心位置位于grid中,这种对偏移量的约束一定程度上保证了训练时间减少,加快收敛。
为sigmoid函数,这里用sigmoid函数是为了让预测框的中心位置位于grid中,这种对偏移量的约束一定程度上保证了训练时间减少,加快收敛。
相对grid cell左上角那个点的距离,用sigmoid压缩到了0-1之间,因为一个格子就是一个单位不能超过1;Cx、Cy是指这个左上角的点在13*13格子里的坐标,这里是1,1。
例如预测值(σtx,σty,tw,th)=(0.2, 0.1, 0.2, 0.32),anchor框为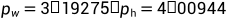 (注:这都是特征图grid cell的不是原始图像)
(注:这都是特征图grid cell的不是原始图像)


3.7 YOLO-V2-Fine-Grained Features
到最后一层,感受野太大了,小目标可能会丢失,需要融合之前的特征。
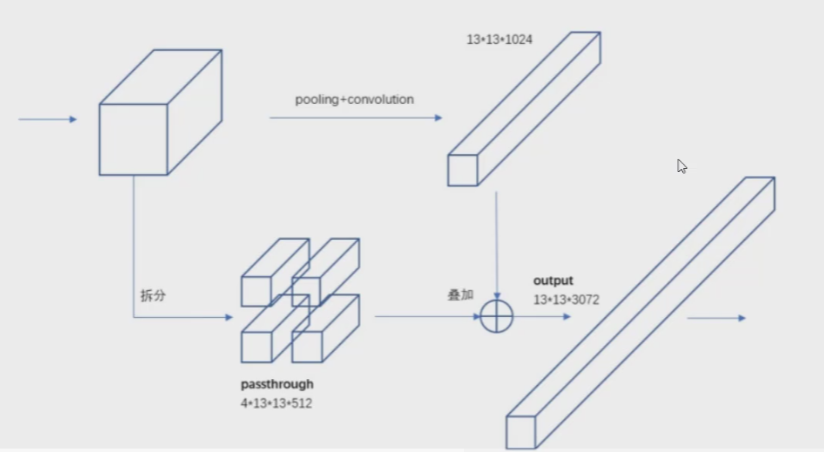
以YOLO-V2的DarkNet19为例,不光光要最后一层的13*13*1024,还要把中间层的特征图拿出来,比如中间的26*26*512,可以把它改写成4*13*13*512,这样和13*13*1024一进行叠加,就能得到既有大小目标通吃的13*13*3072的特征图了。
3.8 YOLO-V2-Multi-Scale
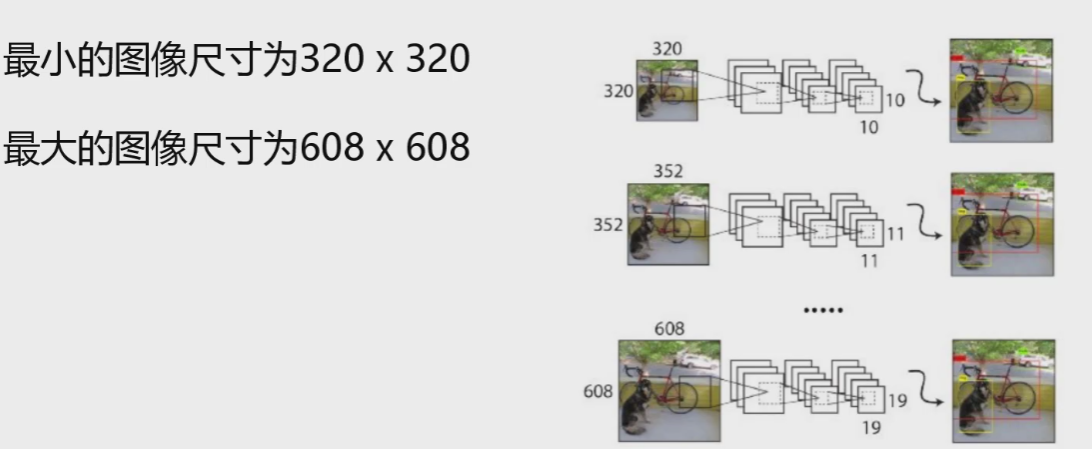
因为都是卷积没有全连接,所以输入大小可以不固定。一般照一张图片进行检测,如果把它resize成一定大小,效果没有以下方法好一些:一定iterations之后改变输入图片大小,即多尺度。
这样就让网络有了一定的适应能力,既能在大的分辨率检测到,也能在小的分辨率检测到。
3.9 总结
以上各点结合在一起就是YOLO-V2进行的细节改进,整体的结构相较于V1思想还是没有变的,都是one-stage方法,最后经过回归得到结果。
四、YOLO-V3核心网络模型
不像V2改进了许多细节,V3版本主要针对一点:网络架构的升级,即特征提取得更好一些。

上图横坐标表示预测时间,纵坐标表示mAP值。
YOLO-V3最大的改进就是网络结构,使其更适合小目标检测
特征做的更细致,融入多持续特征图信息来预测不同规格物体
先验框更丰富了,3种scale,每种3个规格,一共9种
softmax改进,预测多标签任务
4.1 多scale
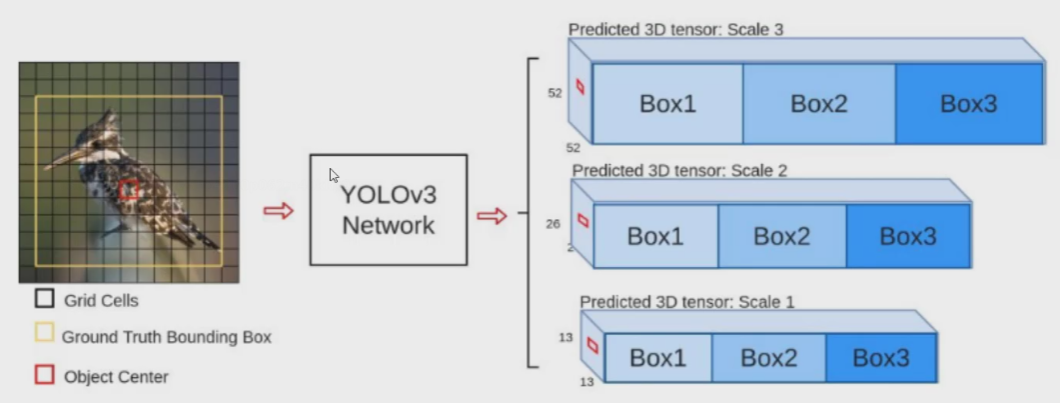
为了能检测到不同大小的物体,设计了3个scale。
之前我们在V2中提到特征融合,比如把中间某层的特整图和最后的特征图整合到一起,达到“大小目标通吃”的效果,但是这样直接融合可能会把一些“擅长的东西淹没”。现在我们来想一想,由于感受野的存在,不同层的特征图虽都是特征提取,但实际细分做的工作还是不同的,比如前几次卷积更注重纹理轮廓颜色等,中间注重其它特征,后面的注重整体特征(感受野大)。
我们把负责不同工作的特征图放到一起,不如把它们分开来,如提取轮廓的都放到一起,注重整体的放到一起... 这样“分工明确”,效果会更好一些。
比如上图13*13的特征图感受野大,那就去预测大物体;26*26的特征图,感受野中等,去预测中等目标;52*52的特征图,感受野小,去预测小目标。只不过不是把这些大小的特征图单拿出来,在预测中目标时要参考大特征图;在预测小目标时要参考中特征图。
至于BOX1、BOX2、BOX3则是三种比例,共9种都不一样,下面会讲解。
scale变换经典方法
这里简单介绍3种:
法1. 图像金字塔

resize输入图片的大小,通过改变分辨率来得到不同大小的结果,13*13、26*26、52*52...
该方法可行,但在注重速度的YOLO上还是差了点。
法2.对不同的特征图分别利用
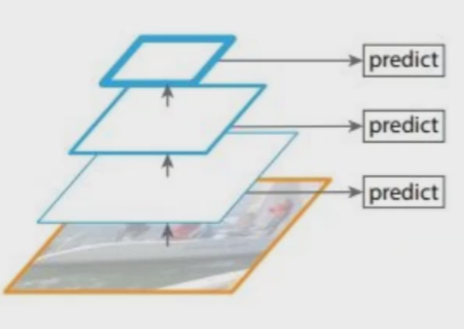
该方法也可行,但不如下面的好。
法3. 不同特征图融合后进行预测(YOLO-V3核心思想)
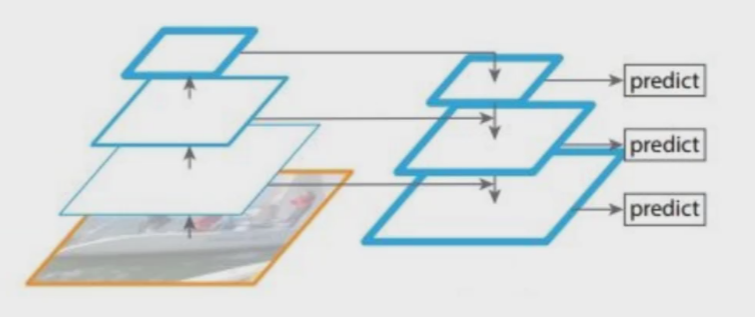
因为13*13的感受野大,可以把大目标识别好,但中等的“眼界”不如大的,小的“眼界”也不如中等的,因此不如让“老年人”帮帮中年人,让“中年人”帮帮小孩。这里,进行了特征融合。
把13*13的特征图通过上采样变成26*26的,与原本26*26的进行融合。“中年人”帮小孩同理。
4.2 残差连接
从今天的角度来看,基本上所有的网络架构都用上了残差连接的方法。V3中也用了resnet的思想,堆叠更多的层来进行特征提取。
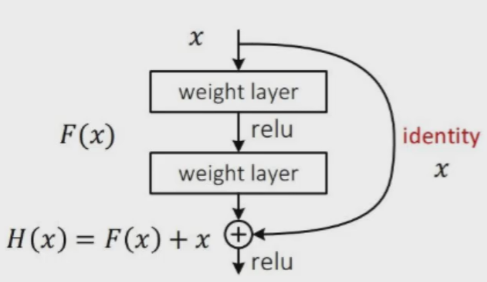
在过去14年VGG出现,人们以为卷积层数越多越好,但实际上通过测试发现发现越学越差,比如16层的时候要比30的好。因为无法保证卷积的时候,在某特征图之上继续提取特征效果会更好。
后来15还是16年诞生Resnet 残差网络,如果新加进来的这层效果不好,我把它的权重设为0 不用这一层。 即好的我们要不好的不要。
4.3 核心网络架构-DarkNet53

可以看到里面加入了残差块。
没有池化和全连接,全部卷积。
下采样通过stride为2实现。
3中scale,更多先验框。
看上图右下角部分,得到13*13*75结果,(这里75根据不同任务设置的,我们主要看前面的),它前面13*13*1024特征图还进行了26*26*256的上采样与26*26*512的特征图进行融合,得到26*26*768的融合特征图,在经过卷积变换->26*26*256->输出26*26*75。完成“老人给中年人提建议”。"中年人给小孩提建议"同理,小孩融合了中年人和老年人的建议。
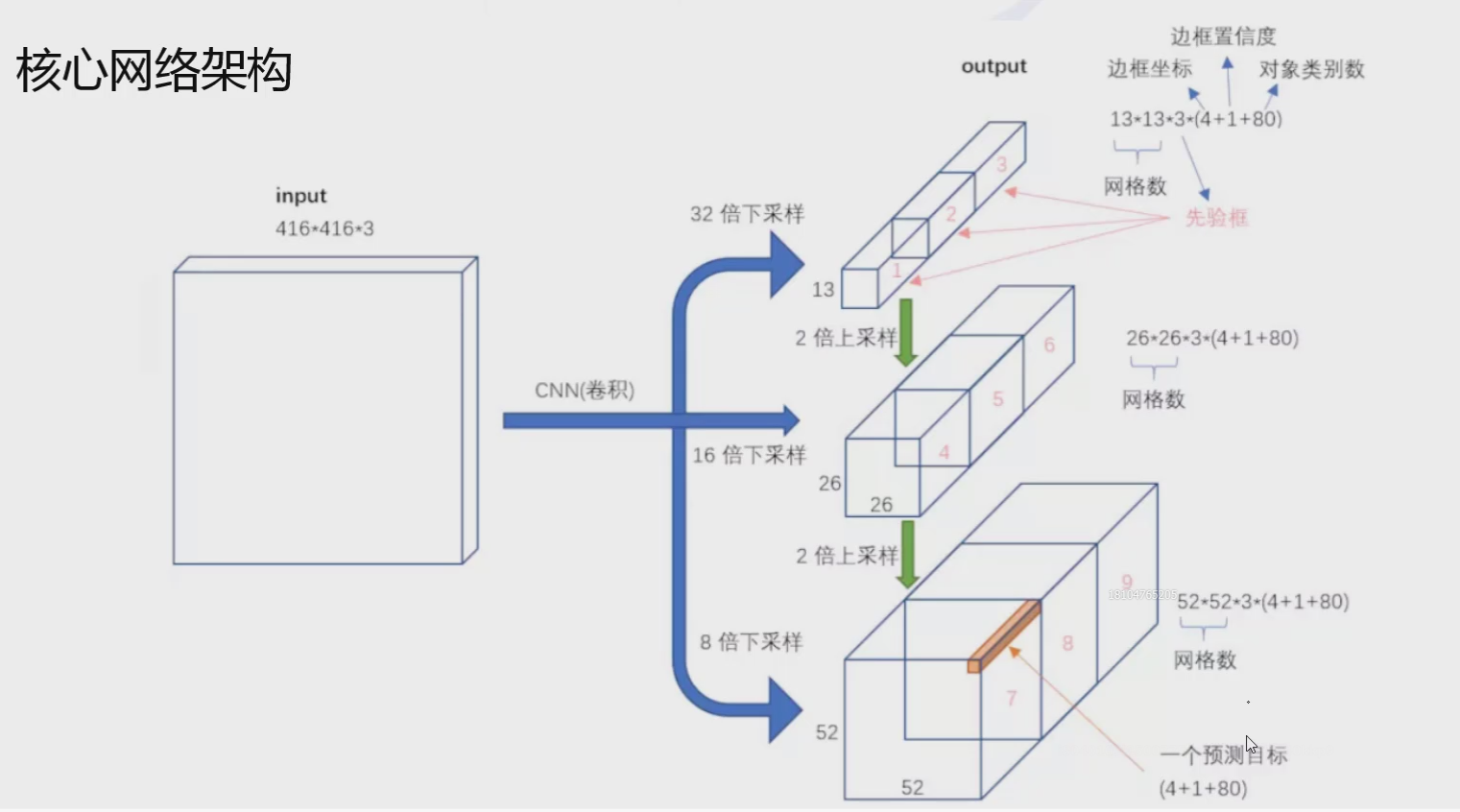
在V1中网格7*7,V2中网格为13*13,V3则是有3种:13*13、26*26、52*52
以13*13为例,输出结果13*13*3*85,其中13是网格数,3是3种比例的先验框BOX123,85里分为4个xywh坐标值、1个置信度(前景还是背景),剩下的80则是任务的类别数量。
26*26、52*52同理。
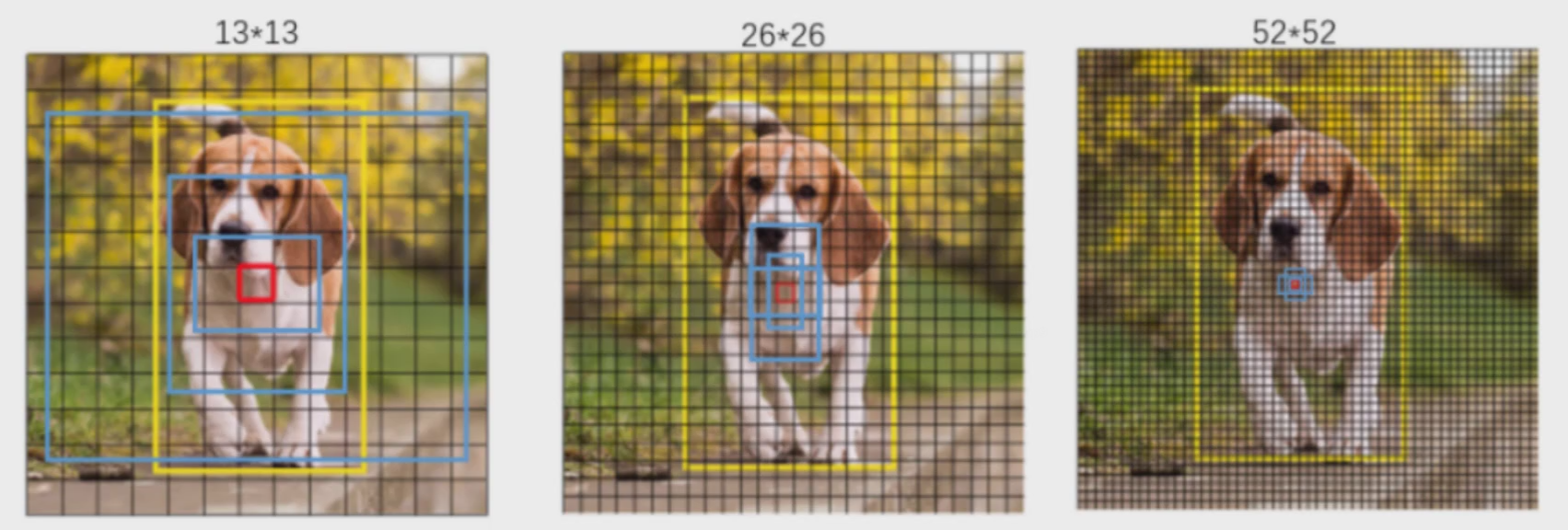
4.4 先验框设计
V1中2(B=2)个,V2中5(K=5)个,V3中9(3*3)个。
3种scale,每种3个规格,一共9种

如下图:黄色表示标签 蓝色表示先验框的大小
4.5 softmax层改进
物体检测任务中可能一个物体有多个标签
logistic激活函数来完成,这样就能预测每一个类别是/不是,即概率越接近1,损失越接近0,概率越接近0损失越无穷大。
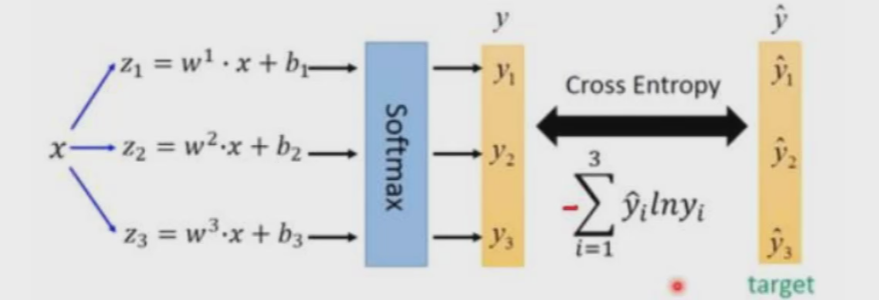
这样比如检测猫输出结果的数组中,猫的概率0.7,狗的概率0.3,加菲猫的概率0.8,幼年猫的概率0.7... 我们可以设置一个阈值来进行筛选。
4.6 总结
YOLO-V3最大的改进就是网络结构,使其更适合小目标检测
特征做的更细致,融入多持续特征图信息来预测不同规格物体
先验框更丰富了,3种scale,每种3个规格,一共9种
softmax改进,预测多标签任务
相关文章:
YOLO-V1~V3经典物体检测算法介绍
大名鼎鼎的YOLO物体检测算法如今已经出现了V8版本,我们先来了解一下它前几代版本都做了什么吧。本篇文章介绍v1-v3,后续会继续更新。一、节深度学习经典检测方法概述1.1 检测任务中阶段的意义我们所学的深度学习经典检测方法 ,有些是单阶段的…...
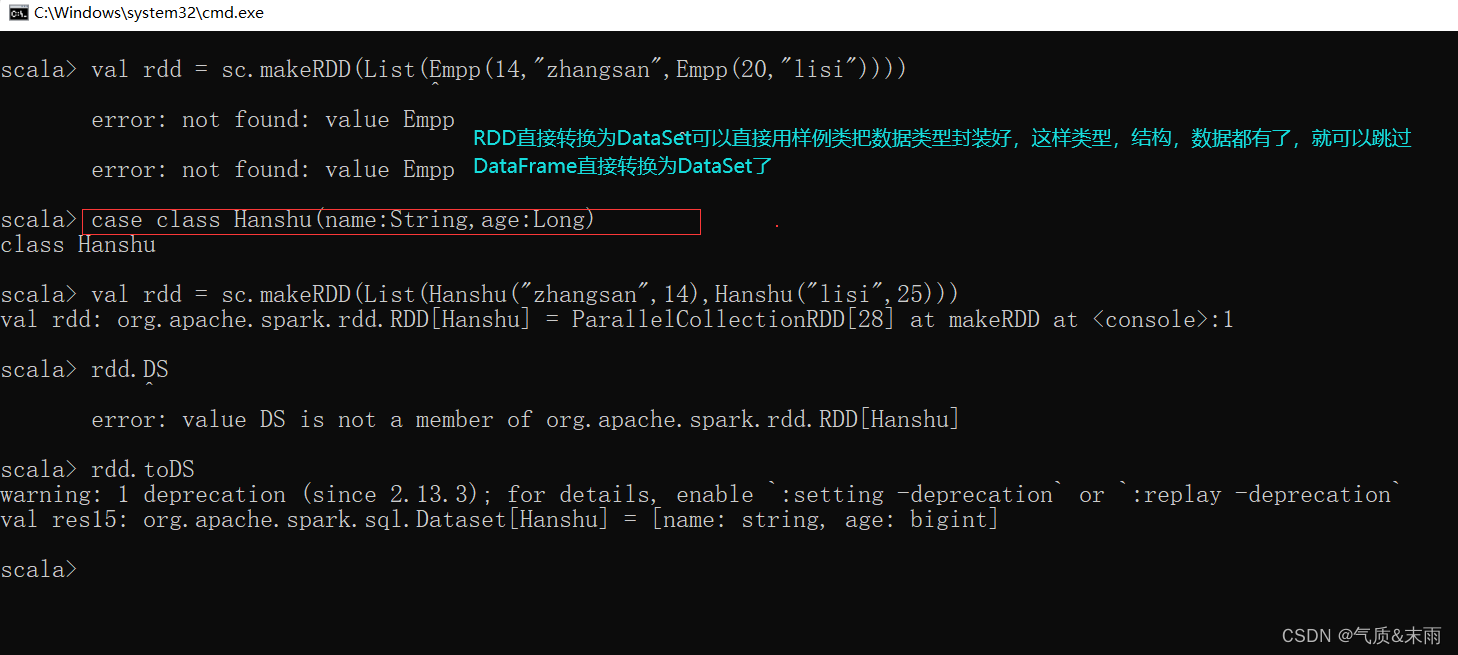
SparkSQL 核心编程
文章目录SparkSQL 核心编程1、新的起点2、SQL 语法1) 读取 json 文件创建 DataFrame2) 对 DataFrame 创建一个临时表3) 通过SQL语句实现查询全表3、DSL 语法1) 创建一个DataFrame2) 查看DataFrame的Schema信息3) 只查看"username"列数据4) 查看"username"列…...
Android核心开发【UI绘制流程解析+原理】
一、UI如何进行具体绘制 UI从数据加载到具体展现的过程: 进程间的启动协作: 二、如何加载到数据 应用从启动到onCreate的过程: Activity生产过程详解: 核心对象 绘制流程源码路径 1、Activity加载ViewRootImpl ActivityThread…...
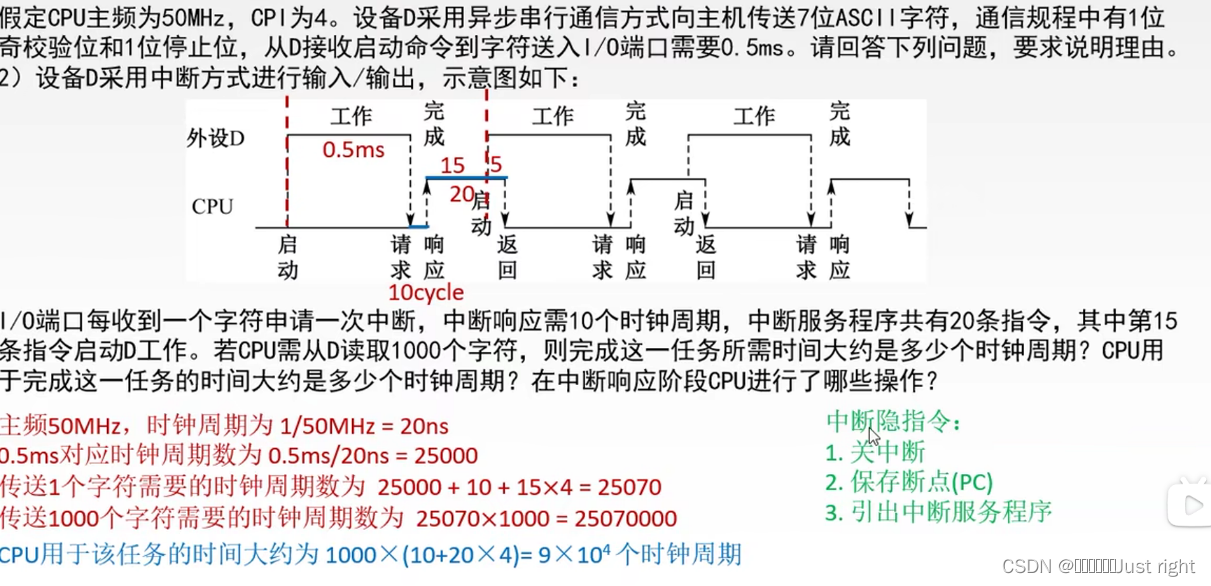
计算机组成原理第七章笔记记录
仅仅作为笔记记录,B站视频链接,若有错误请指出,谢谢 基本概念 演变过程 I/O系统基本组成 I/O软件 包括驱动程序、用户程序、管理程序、升级补丁等 下面的两种方式是用来实现CPU和I/O设备的信息交换的 I/O指令 CPU指令的一部分,由操作码,命令码,设备…...
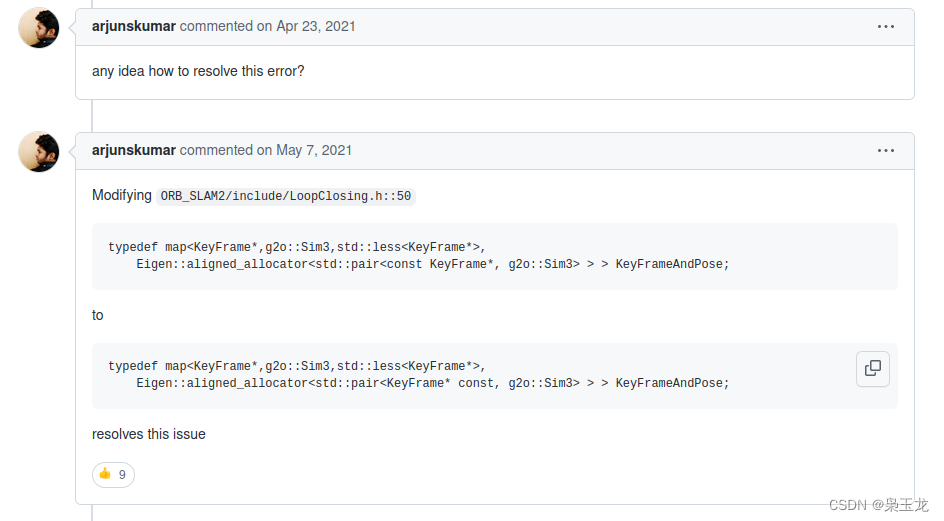
ORB-SLAM2编译、安装等问题汇总大全(Ubuntu20.04、eigen3、pangolin0.5、opencv3.4.10)
ORB-SLAM2编译、安装等问题汇总大全(Ubuntu20.04、eigen3、pangolin0.5、opencv3.4.10) 1:环境说明: 使用的Linux发行版本为Ubuntu 20.04 SLAM2下载地址为:git clone https://github.com/raulmur/ORB_SLAM2.git ORB_SLAM2 2&a…...

QuickBuck:一款专为安全研究人员设计的勒索软件模拟器
关于QuickBuck QuickBuck是一款基于Golang开发的勒索软件模拟工具,在该工具的帮助下,广大研究人员可以通过更简单的方法来判断反病毒保护方案是否能够有效地预防勒索软件的攻击。 功能介绍 该工具能够模拟下列勒索软件典型行为,其中包括&a…...

【八大数据排序法】堆积树排序法的图形理解和案例实现 | C++
第二十一章 堆积树排序法 目录 第二十一章 堆积树排序法 ●前言 ●认识排序 1.简要介绍 2.图形理解 3.算法分析 ●二、案例实现 1.案例一 ● 总结 前言 排序算法是我们在程序设计中经常见到和使用的一种算法,它主要是将一堆不规则的数据按照递增…...

低代码开发平台|生产管理-生产加工搭建指南
1、简介1.1、案例简介本文将介绍,如何搭建生产管理-生产加工。1.2、应用场景在主生产计划列表中下达加工后,在加工单列表可操作领料、质检。2、设置方法2.1、表单搭建1)新建表单【产品结构清单(BOM)】,字段…...
Python类型-语句-函数
文章目录类型动态类型:变量类型会随着程序的运行发生改变注释控制台控制台输入input()运算符算术关系逻辑赋值总结语句判断语句while循环for循环函数链式调用和嵌套调用递归关键字传参在C/java中,整数除以整数结果还是整数,并不会将小数部分舍弃…...

真兰仪表在创业板开启申购:募资约20亿元,IPO市值约为78亿元
2月9日,上海真兰仪表科技股份有限公司(下称“真兰仪表”,SZ:301303)开启申购,将在深圳证券交易所创业板上市。本次上市,真兰仪表的发行价为26.80元/股,市盈率43.06倍。 据贝多财经了解…...
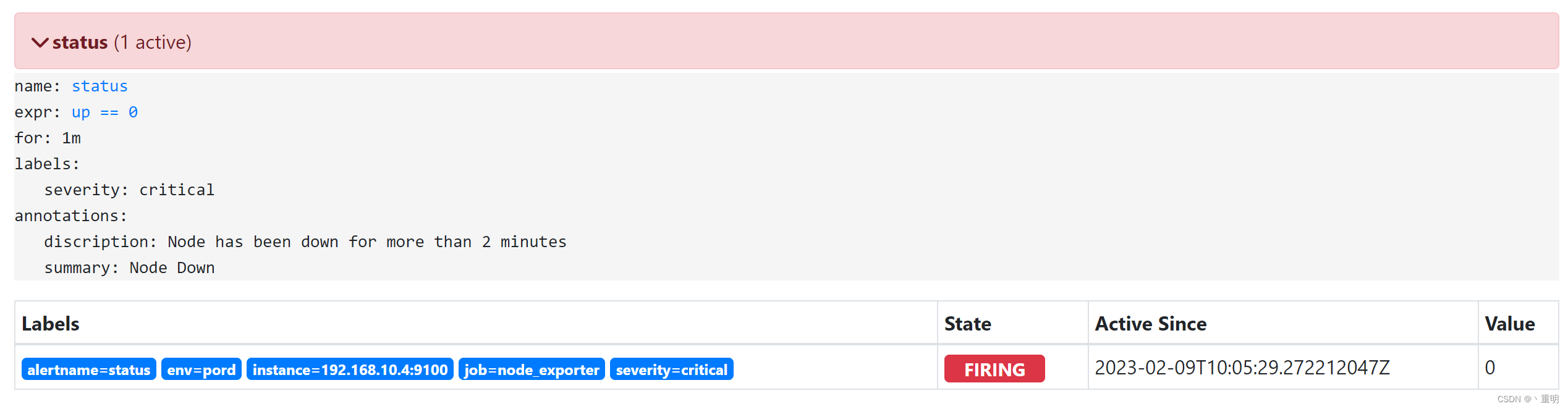
【2023】Prometheus-Prometheus与Alertmanager配置详解
记录一下Prometheus与Alertmanager的配置参数等内容 目录1.Prometheus1.1.prometheus.yml1.2.告警规则定义2.alertmanager2.1.alertmanager.yml2.1.1.global:全局配置2.1.1.1.以email方式作为告警发送方2.1.1.2.以wechat方式作为告警发送方2.1.1.3.以webhook方式作为…...

华为HCIE学习之openstack基础
文章目录一、Openstack各种文件位置二、Openstack命令操作1.使用帮助三、用命令发放云主机1、创建租户2、创建用户并与租户绑定3、注册镜像4、创建规格5、创建公有网络及其子网(做弹性IP用)6、创建私有网络及其子网7、创建路由并设置网关与端口8、创建安…...
Python实现贝叶斯优化器(Bayes_opt)优化BP神经网络分类模型(BP神经网络分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。1.项目背景贝叶斯优化器(BayesianOptimization) 是一种黑盒子优化器,用来寻找最优参数。贝叶斯优化器是基…...
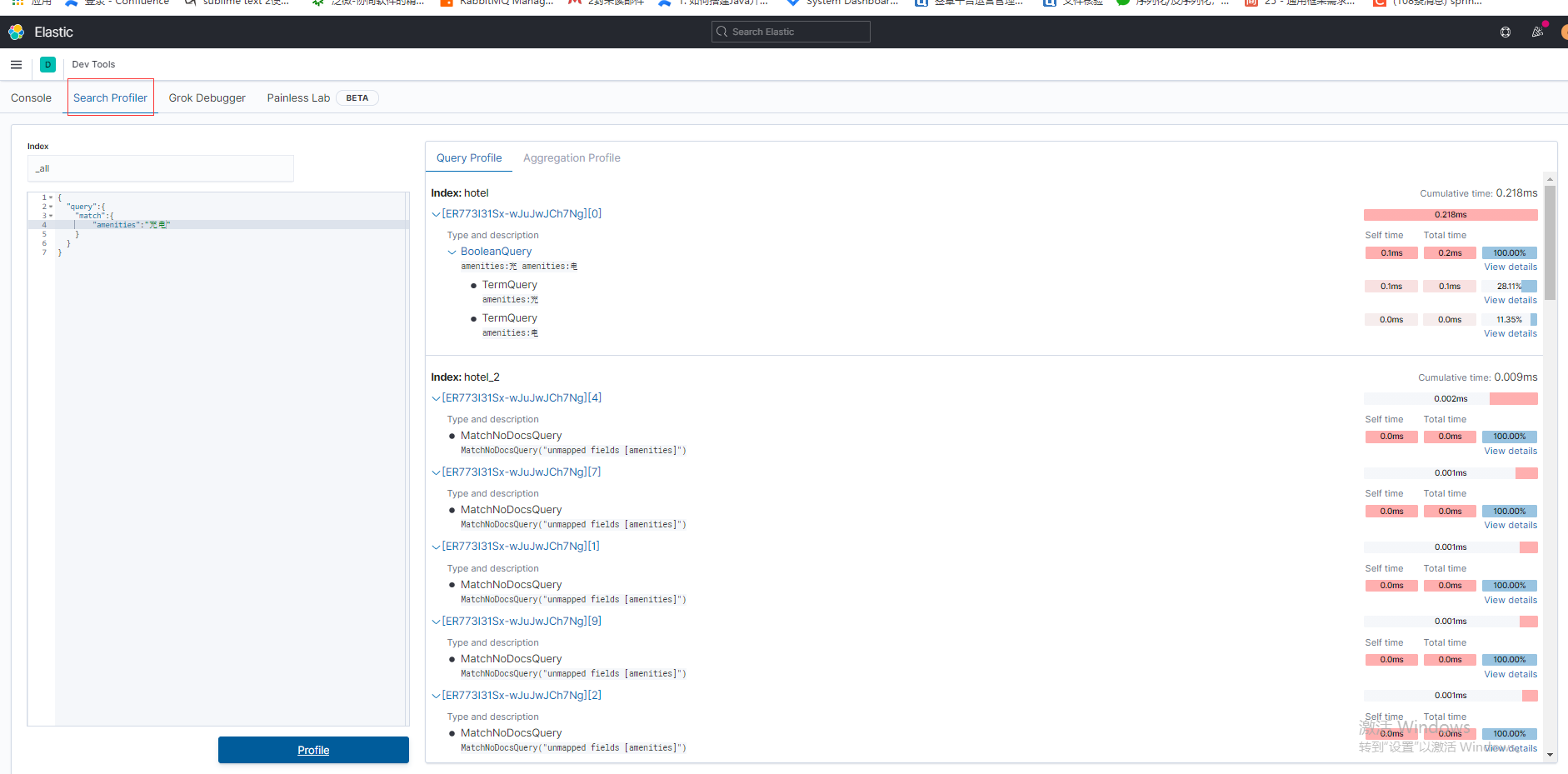
Elasticsearch(九)搜索---搜索辅助功能(下)--搜索性能分析
一、前言 上篇文章我们学习了ES的搜索辅助功能的一部分–分别是指定搜索返回的字段,搜索结果计数,分页,那么本次我们来学习一下ES的性能分析相关功能。 二、ES性能分析 在使用ES的过程中,有的搜索请求的响应比较慢,…...
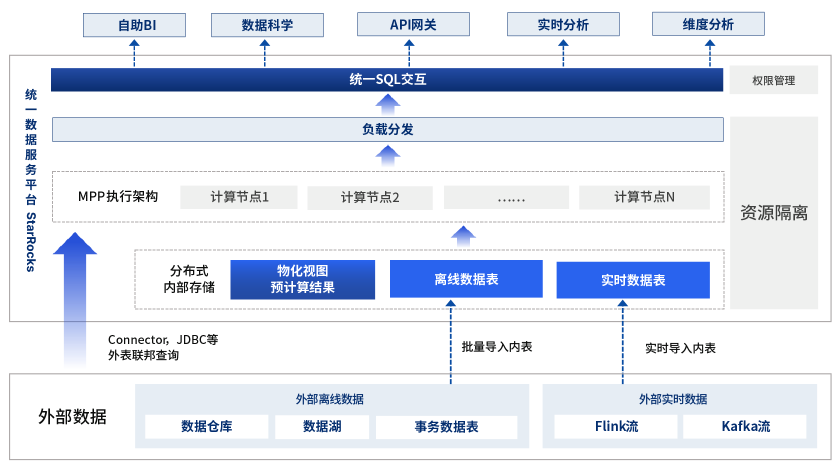
化繁为简|中信建投基于StarRocks构建统一查询服务平台
近年来,在证券服务逐渐互联网化,以及券商牌照红利逐渐消退的行业背景下,中信建投不断加大对数字化的投入,尤其重视数据基础设施的建设,期望在客户服务、经营管理等多方面由经验依赖向数据驱动转变,从而提高…...

2023数字中国创新大赛·数据开发赛道首批赛题启动报名
由数字中国建设峰会组委会主办的2023数字中国创新大赛(DCIC 2023)已正式启幕,本届大赛结合当下数字技术发展的热点和业界关注的焦点,面向产业实际需求设置了九大赛道。其中,数据开发赛道2月8日正式上线首批赛题&#x…...

MySQL数据库
1.MySQL的MyISAM与InnoDB两种存储引擎在,事务、锁级别,各自的适用场景? 1.1事务处理上方面 MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。 InnoDB:提供事务…...

鸿蒙设备学习|快速上手BearPi-HM Micro开发板
系列文章目录 第一章 鸿蒙设备学习|初识BearPi-HM Micro开发板 第二章 鸿蒙设备学习|快速上手BearPi-HM Micro开发板 文章目录系列文章目录前言一、环境要求1.硬件要求2.软件要求3.Linux构建工具要求4.Windows开发工具要求5.工具下载地址二、安装编译基础环境1.安装Linux编译环…...

软件测试标准流程
软件测试的基本流程大概要经历四个阶段,分别是制定测试计划、测试需求分析、测试用例设计与编写以及测试用例评审。因此软件测试的工作内容,远远没有许多人想象的只是找出bug那么简单。准确的说,从一个项目立项以后,软件测试从业者…...

Python身份运算符
Python身份运算符身份运算符用于比较两个对象的存储单元运算符描述实例isis 是判断两个标识符是不是引用自一个对象x is y, 类似 id(x) id(y) , 如果引用的是同一个对象则返回 True,否则返回 Falseis notis not 是判断两个标识符是不是引用自不同对象x is not y &a…...
)
告别手搓测试平台:用Synopsys SVT APB VIP快速搭建你的SoC验证环境(附完整配置流程)
告别手搓测试平台:用Synopsys SVT APB VIP快速搭建你的SoC验证环境(附完整配置流程) 在SoC验证领域,APB总线作为AMBA协议家族中最基础的外设连接标准,几乎出现在每一个现代芯片设计中。然而,许多验证工程师…...
的安全与应用)
别再只复制粘贴了!深入理解阿里云IoT设备三元组(ProductKey/DeviceName/DeviceSecret)的安全与应用
阿里云IoT设备三元组安全实践指南:从基础认知到高级防护策略 在物联网项目开发中,设备身份认证是保障系统安全的第一道防线。许多开发者虽然能够快速完成设备接入,但对认证核心——设备三元组(ProductKey/DeviceName/DeviceSecret…...

STM32+EMMC+GL3227E固件调试:从扇区偏移到数据同步的实战解析
1. 问题现象与背景分析 最近在调试一个嵌入式存储系统时遇到了奇怪的现象:STM32主控将数据写入EMMC存储后,通过GL3227E桥接芯片连接电脑却无法识别。更诡异的是,电脑格式化后的EMMC,STM32写入的数据在电脑端又"消失"了。…...

eFuse 的核心作用
它触及了设备安全性的核心机制——eFuse。 简而言之:一台已经烧录(blown)了 eFuse 的设备,其安全机制与未烧录 eFuse 的设备有本质区别,你之前在非 eFuse 设备上成功的代码修改(强制 check_key 返回 0)很可能在烧录了 eFuse 的设备上无效。 以下是详细解释: eFuse 的…...
)
告别砖头:GD32 BootLoader设计中的Flash分区与地址规划实战指南(含IAR/Keil工程配置)
GD32 BootLoader架构设计与Flash分区策略实战 1. 理解GD32 Flash存储特性与IAP基础架构 GD32系列MCU的Flash存储结构呈现出典型的非均匀扇区分布特征——前4个扇区为16KB,后续扇区则扩展为64KB。这种物理特性直接影响了BootLoader设计的核心逻辑。不同于传统均匀分…...

手把手复现1G通话:用Python模拟FM调制、FSK信令与FDMA多用户通信
手把手复现1G通话:用Python模拟FM调制、FSK信令与FDMA多用户通信 在移动通信的演进史中,1G系统如同数字时代的罗塞塔石碑,用模拟信号承载了人类首次无线对话的自由。今天我们将穿越回1983年摩托罗拉DynaTAC 8000X面世的年代,用Py…...

跨平台桌面待办工具My-TODOs:本地存储的极简任务管理终极指南
跨平台桌面待办工具My-TODOs:本地存储的极简任务管理终极指南 【免费下载链接】My-TODOs A cross-platform desktop To-Do list. 跨平台桌面待办小工具 项目地址: https://gitcode.com/gh_mirrors/my/My-TODOs 你是否厌倦了云端任务管理工具的复杂界面和隐私…...
)
从VGG到ResNet:手把手教你用PyTorch复现DeepLabV2的ASPP模块(附代码)
从VGG到ResNet:手把手教你用PyTorch复现DeepLabV2的ASPP模块(附代码) 在计算机视觉领域,语义分割一直是极具挑战性的任务之一。不同于简单的图像分类,语义分割需要在像素级别上对图像进行理解和标注,这要求…...

谷歌排名算法有哪些? 解决AI生成内容不收录的3个操作方案
2024年3月5日,谷歌启动了一场持续45天的核心算法更新。这次调整导致互联网上超过40%的低质量内容被清除。许多依靠软件大批量产出文章的站点,网页收录量在短时间内缩减了九成。单纯依靠算法堆砌出来的文字,在目前的搜索环境下很难获得生存空间…...

【开发实战】【memtester】嵌入式系统内存稳定性保障:从工具原理到压力测试场景全解析
1. 为什么嵌入式系统需要内存稳定性测试 在嵌入式产品量产前,内存稳定性测试是硬件验证中最容易被忽视却至关重要的环节。我曾参与过一个智能家居网关项目,设备在实验室运行一切正常,但批量部署后却频繁出现随机重启。经过两周的排查…...