如何用sql在1分钟从1T数据中精准定位查询?Hive离线数仓 Spark分析
最近在一个群里,从群友哪里了解到这样一个业务需求:如何在 hdfs 1 T源数据库中,1分钟内从其中抓取自己想要的数据?
我的理解是 : 在hdfs数据库中为拥有 尽1T数据的表创建索引,并对其进行性能优化,以实现1分钟精准查询数据的目的
想要实现其实有点繁杂,可以使用多种工具和技术。如下:
假设使用的是Apache Hive和HDFS存储数据:
有些大数据的朋友可能会疑惑,为什么优先假设hive spark不是更擅长?
因为我是走大数据运维方向的,运维的话数据库sql语句接触的多,离线数仓hive中的语句和sql基本大差不差,作为运维我上手更快一点,学的比较扎实。
如果你也是运维,建议在拓宽技术池的时候优先考虑hive而不是spark;但是,如果你是开发,那么我建议在拓宽技术池的时候优先考虑spark而不是hive,因为spark中定义了一种属于它自己的语言
其实,我spark也会,但是,也只是会,比起各种大牛,只是班门弄斧。不过在最下面三,和四,我会假设spark举例子,并对spark做一下简短介绍。后续的话我会出一期关于大数据所有主流组件搭载在一个集群实验环境的运维配置文档。
注意:在大数据-Hadoop体系中 ,spark批处理和hive离线数仓可以说是对立并行的两个大分支技术栈,,,建议主攻其一,另一个灵活使用就行。他们是2015出现在国内,2017年之后国外各大公司纷纷采用,国内2020采用的,目前属于很前沿,并且很主流,很顶层的技术。(注:19年国内云计算开始起势,大数据的发展与云计算和人工智能等密切相关,更离不开芯片,硬件存储技术等相关支撑,它们之间相辅相成)
一,hive进行数据查询优化,以实现1分钟内精准查询数据的目标。
1. 数据准备:假设使用的是Apache Hive和HDFS存储数据
确保数据已经存储在HDFS中,且数据格式适合索引和查询操作。常见的数据格式包括Parquet和ORC等。
2. 选择合适的工具
在Hadoop生态系统中,有多种工具可以用于索引和优化查询性能,如Apache Hive、Apache HBase、Apache Kudu、Apache Impala等。这里假设使用的是Apache Hive。
其实HBase也能用,它提供了快速的随机读写能力,但对于大规模数据的复杂查询,相较于使用Hive,使用 HBase 可能会面临很多问题如下:
2.1
HBase 中实现类似 SQL 的复杂查询,通常需要额外的设计和开发工作,例如使用二级索引、扫描和过滤器等。
2.3
HBase 可以通过预先分区、压缩和缓存等优化措施提高性能,但是对于 1TB 数据规模的复杂查询, 在一分钟内可能难以完成。
大规模的扫描操作在 HBase 中可能会导致性能瓶颈,会引起大数据集群瞬时宕机,尤其是在没有合适索引的情况下
2.4
HBase 与其他查询优化工具(如 Apache Phoenix)结合可以提供 SQL 查询功能,但整体复杂度较高。
总之,与 Hive 相比,HBase 的查询优化和性能调优复杂度更大。查询小数据 优先hbase 实时性很快反应迅速,但稍微数据量一上来,就要考虑hive了
3. 创建表和索引
3.1 创建表
确保表已经存在并且数据已经加载。
CREATE EXTERNAL TABLE IF NOT EXISTS my_table ( id INT, name STRING, value DOUBLE, timestamp TIMESTAMP ) STORED AS PARQUET LOCATION 'hdfs:///path/to/my_table';
3.2 使用分区和桶
分区和桶化可以显著提高查询性能。
3.2.1 分区表
按时间戳对表进行分区:
CREATE EXTERNAL TABLE IF NOT EXISTS my_partitioned_table ( id INT, name STRING, value DOUBLE ) PARTITIONED BY (timestamp STRING) STORED AS PARQUET LOCATION 'hdfs:///path/to/my_partitioned_table';
3.2.2 加载数据到分区表
将数据加载到分区表中:
INSERT OVERWRITE TABLE my_partitioned_table PARTITION (timestamp) SELECT id, name, value, DATE_FORMAT(timestamp, 'yyyy-MM-dd') as timestamp FROM my_table;
3.2.3 桶化表
按ID对表进行桶化:
CopyCREATE EXTERNAL TABLE IF NOT EXISTS my_bucketed_table (id INT,name STRING,value DOUBLE,timestamp STRING
)
CLUSTERED BY (id) INTO 256 BUCKETS
STORED AS PARQUET
LOCATION 'hdfs:///path/to/my_bucketed_table';
4. 创建Hive索引
Hive支持两种类型的索引:紧凑索引和位图索引。选择合适的索引类型。
CopyCREATE INDEX my_index ON TABLE my_partitioned_table (id)
AS 'COMPACT' WITH DEFERRED REBUILD;
然后重建索引:
CopyALTER INDEX my_index ON my_partitioned_table REBUILD;
5. 优化查询
使用适当的查询优化技术:
- 使用索引:确保查询使用索引字段。
- 限制扫描范围:通过WHERE子句限制扫描范围。
- 使用合适的文件格式:如Parquet、ORC,以提高I/O效率。
- 适当的资源分配:配置YARN和Hive的资源分配,以确保查询有足够的资源。
6. 测试和调整
运行查询并监控其性能,根据结果进行调整。
SELECT * FROM my_partitioned_table WHERE id = 123 AND timestamp = '2023-10-01';
7. 监控和维护
定期监控查询性能和系统资源使用情况,进行必要的维护和调整。
8. 使用Apache Impala进行实时查询(可选)
注:这个我只是了解,听说还可以,我主要在用hbase和Hive,有需要的我们可以共同研究。
如果需要更快的查询,可以考虑使用Apache Impala进行实时查询。Impala提供了实时SQL查询功能,可以显著提升查询效率。
8.1 创建表
在Impala中创建表:
CREATE EXTERNAL TABLE IF NOT EXISTS my_table (id INT,name STRING,value DOUBLE,timestamp TIMESTAMP ) STORED AS PARQUET LOCATION 'hdfs:///path/to/my_table';
8.2 执行查询
在Impala中执行查询:
SELECT * FROM my_table WHERE id = 123 AND timestamp = '2023-10-01';
通过以上步骤,可以在HDFS源数据库中为1TB数据的表创建索引并进行性能优化,以实现1分钟内精准查询数据的目标。具体实现可能需要根据实际环境和需求进行调整。
9. 使用Spark进行处理(可选)
如果需要更复杂的查询和处理,可以考虑使用Apache Spark进行数据处理和查询。
9.1 加载数据
使用Spark加载数据:
val df = spark.read.parquet("hdfs:///path/to/my_table")
9.2 创建索引
使用DataFrame API创建索引:
df.createOrReplaceTempView("my_table") spark.sql("CREATE INDEX my_index ON TABLE my_table (id)")
9.3 查询数据
使用Spark SQL查询数据:
val result = spark.sql("SELECT * FROM my_table WHERE id = 123 AND timestamp = '2023-10-01'") result.show()
通过以上步骤,可以在HDFS源数据库中为1TB数据的表创建索引并进行性能优化,以实现1分钟内精准查询数据的目标。具体实现可能需要根据实际环境和需求进行调整。
二,对于昨天发表的文章我进行了补充:
后续我会出一期关于大数据所有主流组件搭载在一个集群实验环境的运维配置文档。
我先科普一下:
在大数据体系中,目前主要以Hadoop为基础,进而进行延申扩展, 因此有时也称为大数据-Hadoop体系 很多分支虽然相互 功能重合,相互不调用,但是Hadoop作为基础架构平台容器却完美的把这些容纳在一起。
2005-2011,那时候大数据概念刚刚兴起,hadoop1.0和2.0称王,
2013之后形势变了即使有了Hadoop3.0,但是
Spark(2010年出世2013成型)Kafka(2011年出世后来合并到3.0,但单独也使用于各种开发场景不再拘泥于大数据)
Flink(2014年出道即巅峰与spark,hive并立)
TensorFlow(2015年神经网络框架 人工智能,python必学)等等这些先是在国外纷纷分割天下,
在2014-2016年先后进入国内也成为主流前沿技术,至今仍在向前发展,
当然由于很多技术栈的灵感来源于Hadoop,
而Hadoop作为先行者,虽然目前不能独霸江湖,但基本上作为一个基础的大数据平台架构托底,目前在很多公司都在沿用,
它的地位,大概类似于少林武当,是前行者,也是监察者,更是补救者。
其他新兴大分支技术栈也许是嵩山,也许是华山,也许是蜀山,也许是丐帮,
他们的确在某一个时间段独霸天下,但是有时候不是越前沿越好,有些技术需要不断试错,等到这个大版本快过去才被银行国企采纳,其实这是明智的选择。
银行国企等要考虑安全稳定性,要考虑代码全开源,要考虑是否有无后门,坐看花开花落一直云淡风轻才是最好的选择。
所以大家有时还是理解一下吧。国家也不容易的。大数据,人工智能等已经落后国外一点了,但凡国内能开发诸如flink这种大框架,很多,其实也不会再三考虑,坐看花开花落了。
三,Spark进行数据查询优化,以实现1分钟内精准查询数据的目标。
1. 环境准备
确保你的环境中已经安装和配置好了以下组件:
- Hadoop HDFS
- Apache Spark
- 适当的存储格式(如Parquet、ORC等)
2. 数据准备
假设数据已经存储在HDFS中,并且采用高效的存储格式(如Parquet或ORC),这将有助于提高查询性能。
3. 读取数据
使用Spark读取HDFS中的数据。这里我们假设数据存储在Parquet格式的文件中。
Copyimport org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("Query1TBData").getOrCreate()val df = spark.read.parquet("hdfs:///path/to/your/data")
4. 数据分区和索引
4.1 分区
在读取数据时,尽量利用数据的自然分区(如基于时间戳的分区)。这可以显著减少查询扫描的数据量。
假设数据按日期进行了分区:
Copyval partitionedDF = spark.read.parquet("hdfs:///path/to/your/data/partitioned_by_date")
4.2 索引(可选)
虽然Spark本身不支持索引,但是你可以通过将数据写入支持索引的外部存储系统(如HBase或Elasticsearch)来实现索引功能。不过,这里假设我们只使用Spark和HDFS。
5. 优化查询
利用Spark的各种优化技术来提高查询性能。
5.1 缓存数据
如果数据量较大,可以选择性地缓存部分数据以提高查询速度。
Copydf.cache()
5.2 使用合适的数据格式和压缩
Parquet和ORC等列式存储格式可以显著提高查询性能。
Copyval df = spark.read.option("compression", "snappy").parquet("hdfs:///path/to/your/data")
5.3 过滤和投影
尽量在读取数据时进行过滤和投影,缩小数据处理范围。
Copyval filteredDF = df.filter("your_filter_condition").select("needed_columns")
6. 执行查询
执行你的查询操作,并进行性能调优。
Copyval resultDF = filteredDF.filter("another_filter_condition")
resultDF.show()
7. 性能调优
7.1 调整Spark配置
调整Spark配置参数,以提高性能。例如,增加执行器内存和核数。
Copyspark-submit --class your.main.Class \--master yarn \--deploy-mode cluster \--num-executors 50 \--executor-memory 4G \--executor-cores 4 \path/to/your/jarfile.jar
7.2 使用Broadcast Join
对于小表和大表的连接操作,可以使用广播变量(Broadcast Variable)来优化。
Copyimport org.apache.spark.sql.functions.broadcastval smallDF = spark.read.parquet("hdfs:///path/to/small/table")
val joinedDF = df.join(broadcast(smallDF), "join_key")
7.3 使用Spark SQL和数据框操作
使用Spark SQL和数据框操作可以充分利用Catalyst优化器,提高查询性能。
Copyval resultDF = spark.sql("SELECT your_columns FROM your_table WHERE your_conditions")
resultDF.show()
8. 测试和调整
通过实际运行查询,监控性能,并进行必要的调整。使用Spark UI和日志来分析性能瓶颈,并进行优化。
总结
通过使用Spark,你可以在HDFS 1TB数据规模下进行高效的查询和数据处理。通过合理的数据分区、缓存、过滤、投影以及Spark配置优化,可以实现1分钟内精准查询数据的目的
四,Spark小白入门看
Apache Spark 是一个快速、通用的分布式数据处理引擎,设计用于大规模数据处理。它提供了一个统一的编程模型,可以处理批处理、流处理和交互式查询。以下是对 Spark 的详细介绍:
1. 核心组件
1.1 Spark Core
Spark Core 是 Spark 的基础,提供了内存计算和弹性分布式数据集(RDD)的功能。RDD 是不可变、分布式的数据集合,可以在集群的多个节点上并行处理。
内存计算:Spark 的主要设计目标之一是提高计算速度,尤其是迭代计算。通过在内存中缓存数据,可以避免重复的磁盘 I/O 操作。
弹性分布式数据集(RDD):RDD 是 Spark 的核心抽象,代表一个不可变的、分布式的数据集合。RDD 支持两类操作:转换(如 map、filter)和行动(如 count、collect)。
1.2 Spark SQL
Spark SQL 提供了结构化数据处理的能力。它引入了 DataFrame 和 Dataset 这两种高层次的抽象,允许用户使用 SQL 查询数据。
DataFrame:类似于关系数据库中的数据表,支持丰富的 SQL 查询和数据操作。
Dataset:结合了 RDD 的强类型和 DataFrame 的优化优势,提供了类型安全的 API。
1.3 Spark Streaming
Spark Streaming 能够实时处理数据流。它把实时数据流分成小的批次,然后使用 Spark 引擎处理这些批次数据。
DStream:代表一个离散化的数据流,由一系列连续的 RDD 组成。
窗口操作:支持基于时间窗口的操作,可以进行滑动窗口、滚动窗口等操作。
1.4 MLlib
MLlib 是 Spark 的机器学习库,提供了丰富的机器学习算法和实用工具。
机器学习算法:包括分类、回归、聚类、协同过滤等。
数据处理工具:包括特征提取、转换等。
1.5 GraphX
GraphX 是 Spark 的图计算库,提供了图和并行图操作的 API,适用于图数据的分析和处理。
图抽象:提供了点(Vertex)和边(Edge)的抽象。
图算法:包括 PageRank、Connected Components、Shortest Path 等常见的图算法。
2. 编程模型
2.1 RDD
RDD 是 Spark 的核心抽象,代表一个不可变、分布式的数据集合。RDD 支持两类操作:转换和行动。
转换(Transformation):如
map、filter、flatMap等,返回一个新的 RDD。行动(Action):如
count、collect、reduce等,返回一个值或把结果保存到存储系统中。
2.2 DataFrame
DataFrame 是类似于关系数据库中的数据表,支持丰富的 SQL 查询和数据操作。
Copyval spark = SparkSession.builder.appName("Example").getOrCreate()
val df = spark.read.json("path/to/json/file")
df.show()
df.select("name", "age").filter($"age" > 21).show()
2.3 Dataset
Dataset 提供了类型安全的 API,结合了 RDD 的强类型和 DataFrame 的优化优势。
Copycase class Person(name: String, age: Int)
val ds = spark.read.json("path/to/json/file").as[Person]
ds.filter(_.age > 21).show()
3. 性能优化
3.1 内存缓存
通过在内存中缓存数据,可以显著提高计算速度,特别是对于迭代计算。
Copyval rdd = spark.sparkContext.textFile("path/to/file")
rdd.cache()
3.2 数据分区
合理的数据分区可以提高并行度和计算效率。可以使用 repartition 和 coalesce 方法调整数据分区。
Copyval repartitionedRDD = rdd.repartition(10)
3.3 广播变量
对于需要在所有节点上共享的较小数据集,可以使用广播变量。
Copyval broadcastVar = spark.sparkContext.broadcast(Array(1, 2, 3))
3.4 使用合适的数据格式
使用 Parquet 或 ORC 等列式存储格式可以显著提高查询性能。
Copyval df = spark.read.parquet("path/to/parquet/file")
4. 部署和操作
4.1 集群管理
Spark 支持多种集群管理器,包括:
- Standalone:Spark 自带的简单集群管理器。
- YARN:Hadoop 的资源管理器。
- Mesos:分布式系统内核,适用于大规模集群。
4.2 任务提交
可以使用 spark-submit 命令提交 Spark 任务。
Copyspark-submit --class your.main.Class --master yarn --deploy-mode cluster path/to/your/jarfile.jar
4.3 调优
可以通过调整 Spark 配置参数来进行性能调优,例如:
- executor-memory:执行器内存。
- executor-cores:执行器核数。
- num-executors:执行器数量。
5. 应用场景
- 批处理:大规模数据的批处理任务。
- 流处理:实时数据流处理。
- 交互式查询:对大数据的快速交互式查询。
- 机器学习:大规模机器学习任务。
- 图处理:图数据的分析和处理。
6. 总结
spark (其实全称Apache Spark,不过国内直接称呼spark )是一个功能强大且灵活的分布式数据处理引擎,适用于各种大规模数据处理任务。通过内存计算、高效的编程模型和丰富的库支持,Spark 提供了高性能的数据处理能力。选择合适的数据格式、合理配置资源和利用 Spark 的优化机制,可以实现高效的数据查询和处理。
相关文章:

如何用sql在1分钟从1T数据中精准定位查询?Hive离线数仓 Spark分析
最近在一个群里,从群友哪里了解到这样一个业务需求:如何在 hdfs 1 T源数据库中,1分钟内从其中抓取自己想要的数据? 我的理解是 : 在hdfs数据库中为拥有 尽1T数据的表创建索引,并对其进行性能优化,以实现…...

acpi 主板布局需要 efi
今天在折腾 ESXI 的时候,启动虚拟机跳出了 acpi 主板布局需要 efi 然后我就将 ESXI 的启动方式改为了 EFI 但是虚拟机有莫名的启动不了,网上也没有找到办法,最后,我将虚拟机类型有原本的 ubuntu 换成了 debian 最后启动成功&…...

月之暗面对谈 Zilliz:长文本和 RAG 如何选择?
01 长文本与RAG通用对比 准确率:通常情况下长文本优于RAG 长文本:可更加综合的去分析所有相关的内容,提取相关数字,生成图表,效果尚可。RAG:更适合找到一段或者是几段可能相关的段落。如果希望大模型能够…...

高级java每日一道面试题-2024年8月12日-设计模式篇-请列举出在JDK中几个常用的设计模式?
如果有遗漏,评论区告诉我进行补充 面试官: 请列举出在JDK中几个常用的设计模式? 我回答: 在Java Development Kit (JDK) 中,许多设计模式被广泛使用,以帮助实现软件的结构、行为和复用。下面是一些在JDK中常见的设计模式及其简要说明: 工…...

mysql workbench8.0如何导出mysql5.7格式的sql定义
碰到的问题 mac上安装mysql workbech6.0后不能运行,但安装workbench8.0后,导出的数据库sql文件默认是msyql 8.0的语法和格式。比如生成索引的语句后面会有visible关键字,当把mysql8.0的sql文件导入到mysql5.7时就会报错。 如何解决 点击my…...

数据结构(学习)2024.8.6(顺序表)
今天开始学习数据结构的相关知识,大概分为了解数据结构、算法;学习线性表:顺序表、链表、栈、队列的相关知识和树:二叉树、遍历、创建,查询方法、排序方式等。 目录 一、数据结构 数据 逻辑结构 1.线性结构 2.树…...
MyBatis全解
目录 一, MyBatis 概述 1.1-介绍 MyBatis 的历史和发展 1.2-MyBatis 的特点和优势 1.3-MyBatis 与 JDBC 的对比 1.4-MyBatis 与其他 ORM 框架的对比 二, 快速入门 2.1-环境搭建 2.2-第一个 MyBatis 应用程序 2.3-配置文件详解 (mybatis-config.…...

【Redis进阶】Redis集群
目录 Redis集群的诞生 单节点Redis的局限性 1.存储容量限制 2.性能瓶颈 3.单点故障 4.扩展性能差 分布式系统发展的需要 1.海量数据处理 2.高性能要求 3.弹性扩展能力 Redis集群(cluster) 如图所示案例 Redis集群设计 什么是数据分片&…...

JVM运行时数据区之虚拟机栈
【1】概述 Java虚拟机栈(Java Virtual Machine Stack),早期也叫Java栈。每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个的栈帧(Stack Frame),对应着一次次的Java方法调用。 栈是运行…...

Python 机器学习求解 PDE 学习项目 基础知识(4)PyTorch 库函数使用详细案例
PyTorch 库函数使用详细案例 前言 在深度学习中,PyTorch 是一个广泛使用的开源机器学习库。它提供了强大的功能,用于构建、训练和评估深度学习模型。本文档将详细介绍如何使用以下 PyTorch 相关库函数,并提供相应的案例示例: to…...

SpringBoot-enjoy模板引擎
主要用于Web开发,前后端不分离时的页面渲染 SpringBoot整合enjoy模板引擎步骤: 1.将页面保存在templates目录下 2.添加enjoy的坐标 <dependency> <groupId>com.jfinal</groupId> <artifactId>enjoy</artifactId&g…...
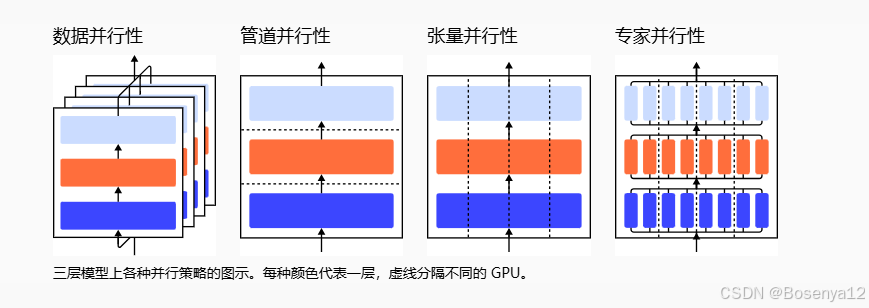
【学习笔记】如何训练大模型
如何在许多 GPU 上训练真正的大型模型? 单个 GPU 工作线程的内存有限,并且许多大型模型的大小已经超出了单个 GPU 的范围。有几种并行范式可以跨多个 GPU 进行模型训练,还可以使用各种模型架构和内存节省设计来帮助训练超大型神经网络。 并…...
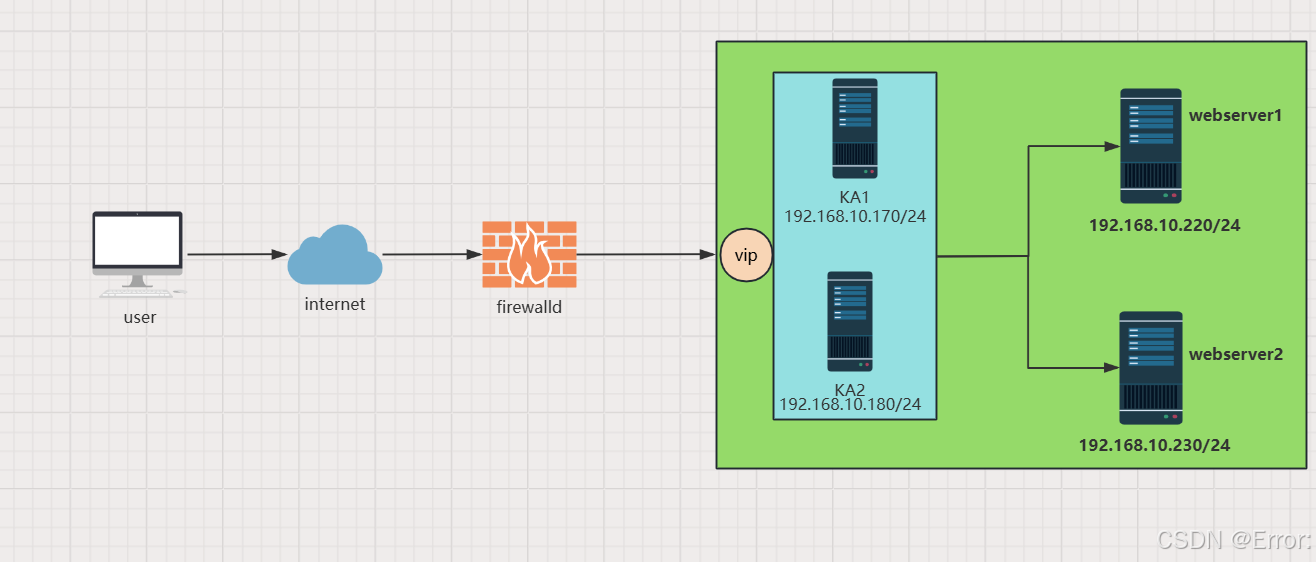
高可用集群KEEPALIVED
一、集群相关概念简述 HA是High Available缩写,是双机集群系统简称,指高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。 1、集群的分类 LB:负载均衡…...

Linux shell编程学习笔记69: curl 命令行网络数据传输工具 选项数量雷人(中)
0 前言 curl是Linux中的一款综合性网络传输工具,既可以上传也可以下载,支持HTTP、HTTPS、FTP等30余种常见协议。 该命令选项超多,在学习笔记68中,我们列举了该命令的部分实例,今天继续通过实例来研究curl命令的功能…...

怎么在网站底部添加站点地图?
在优化网站 SEO 时,站点地图(Sitemap)是一个非常重要的工具。它帮助搜索引擎更好地理解和抓取您的网站内容。幸运的是,从 WordPress 5.5 开始,WordPress 自带了站点地图生成功能,无需额外插件。下面将介绍如…...

bash和sh的区别
Bash和sh的主要区别在于它们的交互性、兼容性、默认shell以及脚本执行方式。 首先,Bash提供了更丰富的交互功能,使得它在终端中的使用更加舒适和方便。相比之下,sh由于其最小化的功能集,提供了更广泛的兼容性。然而ÿ…...
基于LSTM的锂电池剩余寿命预测 [电池容量提取+锂电池寿命预测] Matlab代码
基于LSTM的锂电池剩余寿命预测 [电池容量提取锂电池寿命预测] Matlab代码 无需更改代码,双击main直接运行!!! 1、内含“电池容量提取”和“锂电池寿命预测”两个部分完整代码和NASA的电池数据 2、提取NASA数据集的电池容量&am…...
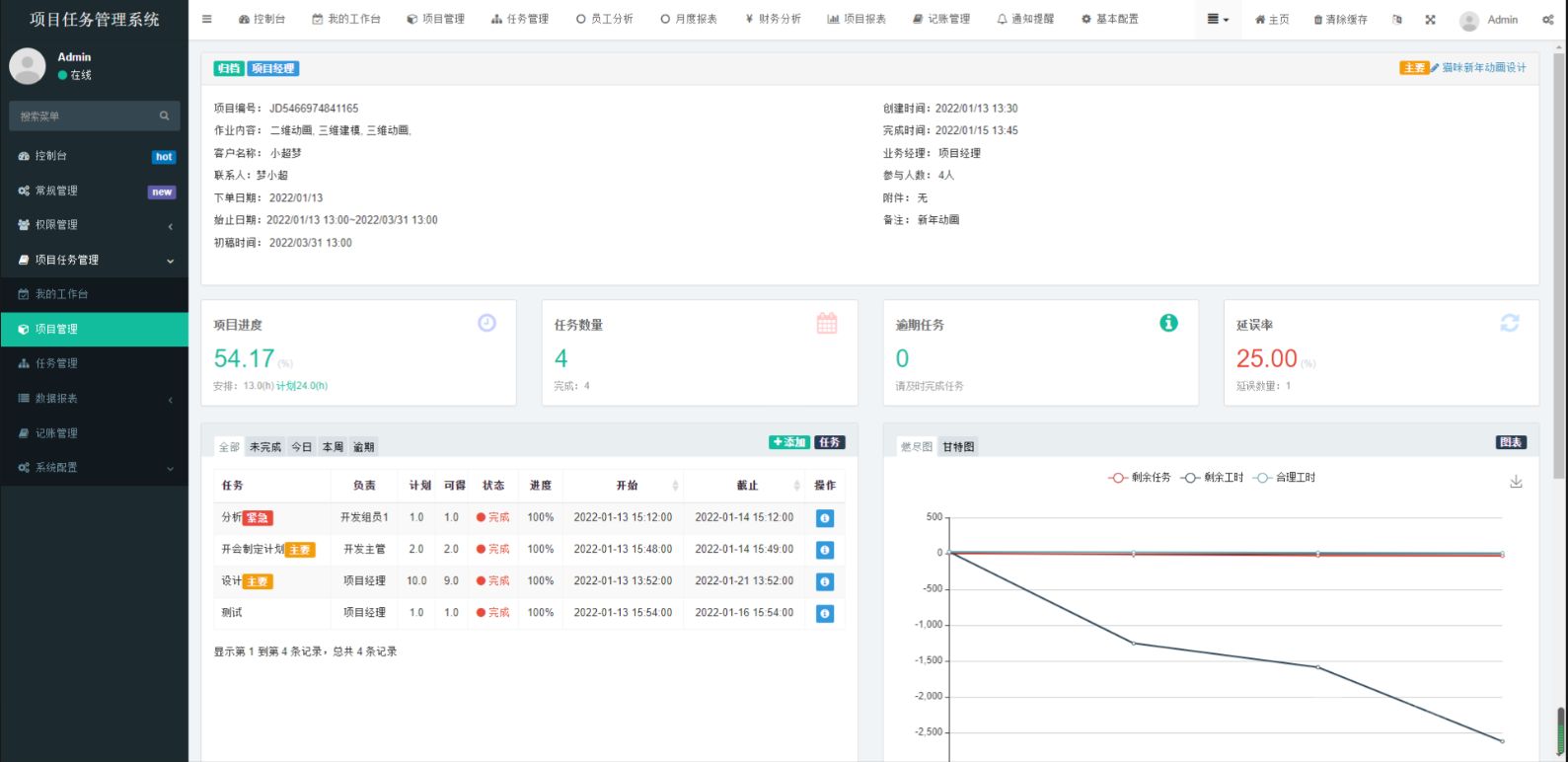
PHP项目任务系统小程序源码
🚀解锁高效新境界!我的项目任务系统大揭秘🔍 🌟 段落一:引言 - 为什么需要项目任务系统? Hey小伙伴们!你是否曾为了杂乱的待办事项焦头烂额?🤯 或是项目截止日逼近&…...
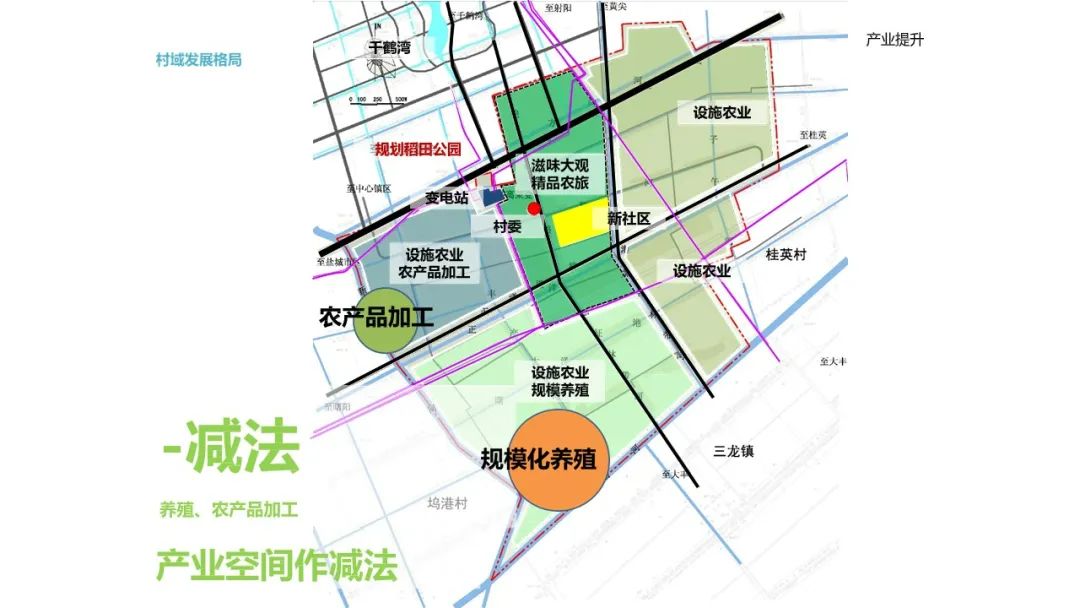
乡村振兴旅游休闲景观解决方案
乡村振兴旅游休闲景观解决方案摘要 2. 规划方案概览 规划核心:PPT展示了乡村振兴建设规划的核心区平面图及鸟瞰图,涵盖景观小品、设施农业、自行车道、新社区等设计元素。 规划策略:方案注重打造大开大合的空间感受,特色农产大观…...

【大数据】重塑时代的核心技术及其发展历程
🐇明明跟你说过:个人主页 🏅个人专栏:《大数据前沿:技术与应用并进》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是大数据 2、大数据技术诞生的背景 二、大…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

从Gamma函数到泊松分布:一个概率论中的含参量积分实用案例解析
Gamma函数与泊松分布:概率论中的数学之美 在数据科学和机器学习的实践中,概率分布构成了建模的基石。当我们深入探究这些分布背后的数学原理时,Gamma函数以其优雅的性质和广泛的应用脱颖而出。它不仅连接了离散与连续概率世界,更在…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...