用爬虫技术探索石墨文档:数据自动化处理与个性化应用的创新实践
用爬虫技术探索石墨文档:数据自动化处理与个性化应用的创新实践
在当今这个信息爆炸的时代,文档管理与协作成为了企业运营和个人工作中不可或缺的一部分。石墨文档,作为一款轻量级的云端Office套件,凭借其强大的在线协作、实时同步以及丰富的文档格式支持功能,在众多用户中赢得了良好的口碑。然而,当我们面对大量存储在石墨文档中的数据时,如何高效地提取、整理并进行分析,便成为了一个值得探讨的问题。本文将深入探讨如何利用爬虫技术玩转石墨文档,实现数据的自动化处理与个性化应用,从而开启一段不同寻常的数据探索之旅。
一、引言:石墨文档与爬虫技术的结合点
石墨文档,本质上是一个基于云端的文档管理系统,用户可以在其中创建、编辑、分享和协作处理各种文档。然而,当这些文档中的数据积累到一定程度时,如何高效地提取并利用这些数据,便成为了用户面临的一大挑战。此时,爬虫技术便显得尤为重要。
爬虫技术,又称为网络爬虫或网页蜘蛛,是一种自动从互联网中抓取信息的程序。它模拟人类浏览网页的行为,自动访问网页、提取数据并保存到本地或数据库中。将爬虫技术应用于石墨文档,可以实现对文档中数据的自动化提取和整理,为后续的数据分析、报表生成等提供强有力的支持。
二、石墨文档爬虫技术的基础架构
要实现石墨文档的爬虫技术,我们需要构建一个基本的爬虫系统。这个系统通常包括以下几个部分:
-
目标分析:首先,需要对目标石墨文档进行分析,了解其URL结构、文档格式、数据布局等信息。这一步是后续编写爬虫代码的基础。
-
爬虫引擎:选择或开发适合的爬虫引擎。Python中的Scrapy、BeautifulSoup等库是处理网页数据的常用工具。对于石墨文档这样的云端服务,可能需要通过API接口或模拟浏览器行为(如使用Selenium)来获取数据。
-
数据解析:根据目标文档的格式和结构,编写相应的数据解析代码。这包括从HTML、JSON等格式中提取文本、图片、表格等数据。
-
数据存储:将解析后的数据存储到本地文件、数据库或云存储服务中。MySQL、MongoDB、Redis等都是常用的数据存储方案。
-
异常处理与日志记录:在爬虫运行过程中,可能会遇到各种异常情况(如网络问题、权限限制等)。因此,需要编写异常处理代码,并记录详细的日志信息以便后续调试和优化。
三、石墨文档爬虫技术的实现案例
以下是一个基于Python和Selenium的石墨文档爬虫实现案例,用于提取文档中的表格数据:
1. 环境准备
- 安装Python环境
- 安装Selenium库及对应的WebDriver(如ChromeDriver)
- 配置石墨文档账号及权限
2. 编写爬虫代码
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import pandas as pd# 启动浏览器驱动
driver = webdriver.Chrome(executable_path='path_to_chromedriver')# 打开石墨文档登录页面
driver.get('https://shimo.im/login')# 填写登录信息(这里以用户名和密码为例)
driver.find_element(By.ID, 'username').send_keys('your_username')
driver.find_element(By.ID, 'password').send_keys('your_password')
driver.find_element(By.ID, 'login-button').click()# 跳转到目标文档页面
driver.get('https://shimo.im/docs/your_document_id')# 等待文档加载完成(这里可能需要根据实际情况调整等待时间)
# 假设文档中有一个表格,并且我们知道其DOM结构
# 以下代码为示例,实际情况需根据DOM结构进行调整
table_elements = driver.find_elements(By.TAG_NAME, 'table')
if table_elements:table_html = table_elements[0].get_attribute('outerHTML')# 将HTML表格转换为Pandas DataFramedf = pd.read_html(table_html)[0]print(df)# 关闭浏览器
driver.quit()
3. 注意事项
- 上述代码仅为示例,实际开发中需要根据石墨文档的DOM结构进行调整。
- 由于石墨文档可能采用JavaScript动态加载数据,因此可能需要使用Selenium的等待机制(如WebDriverWait)来确保数据完全加载后再进行提取。
- 考虑到安全性和隐私性,不建议直接在爬虫中存储敏感信息(如用户名和密码)。可以考虑使用环境变量或加密存储等方式来保护这些信息。
四、石墨文档爬虫技术的进阶应用
1. 数据自动化处理
通过爬虫技术,我们可以实现石墨文档中数据的自动化处理。例如,可以定期运行爬虫脚本,自动从指定的石墨文档中抓取数据,并进行清洗、转换和加载(ETL)处理,最终将数据存储在数据库中供后续分析使用。这种方式可以极大地提高数据处理的效率,减少人工干预,降低出错率。
2. 数据分析与报表生成
在获取到数据后,可以利用Python的Pandas、NumPy等数据分析库,以及Matplotlib、Seaborn等可视化工具,对数据进行深入的分析和挖掘。通过分析,可以发现数据中的规律、趋势和异常,为决策提供有力的支持。同时,还可以根据分析结果,自动生成各种报表和图表,便于向上级汇报或向团队成员展示。
3. 个性化应用与自动化工作流
结合爬虫技术,我们还可以开发出各种个性化应用,以满足特定场景下的需求。例如,可以开发一个自动化工作流系统,该系统能够根据预设的规则和条件,自动触发爬虫任务,抓取特定石墨文档中的数据,并基于这些数据执行一系列后续操作,如发送邮件通知、更新项目状态、触发其他系统任务等。这种自动化工作流可以极大地提高工作效率,减少人工操作的繁琐和错误。
4. 跨平台与多源数据整合
石墨文档只是众多数据源中的一个。在实际应用中,我们往往需要处理来自多个平台、多种格式的数据。因此,可以将爬虫技术与其他数据处理技术相结合,实现跨平台、多源数据的整合。例如,可以使用API接口从其他云服务(如阿里云、腾讯云等)获取数据,然后使用爬虫技术从本地文件或网页中抓取数据,最后将所有数据统一存储在数据库中,以便进行综合分析。
五、挑战与应对策略
尽管爬虫技术在石墨文档数据处理中展现出巨大的潜力,但在实际应用过程中仍面临一些挑战:
-
反爬虫机制:石墨文档等网站可能会设置反爬虫机制,限制爬虫的访问频率或完全阻止爬虫的访问。针对这一问题,可以采取降低访问频率、模拟真实用户行为、使用代理IP等策略来规避反爬虫机制。
-
数据格式与结构变化:石墨文档的格式和结构可能会随着版本的更新而发生变化,导致原有的爬虫代码无法正常工作。因此,需要定期更新和维护爬虫代码,以适应数据格式和结构的变化。
-
安全与隐私:在爬取石墨文档等数据时,需要特别注意安全和隐私问题。避免未经授权地访问和存储敏感信息,遵守相关法律法规和道德准则。
-
性能与稳定性:对于大规模数据的爬取和处理,需要关注爬虫的性能和稳定性。优化爬虫代码、使用高性能的硬件和存储设备、设置合理的并发数和重试机制等,都是提高爬虫性能和稳定性的有效手段。
六、结论
通过将爬虫技术应用于石墨文档,我们可以实现数据的自动化处理与个性化应用,为数据分析和决策支持提供强有力的支持。然而,在实际应用过程中也需要注意反爬虫机制、数据格式与结构变化、安全与隐私以及性能与稳定性等挑战。只有不断学习和探索新的技术和方法,才能更好地发挥爬虫技术在石墨文档数据处理中的优势。
未来,随着技术的不断发展和进步,我们有理由相信爬虫技术在石墨文档及其他领域的应用将会越来越广泛和深入。无论是企业还是个人用户都将从中受益匪浅,实现更高效、更智能的数据管理和利用。
相关文章:

用爬虫技术探索石墨文档:数据自动化处理与个性化应用的创新实践
用爬虫技术探索石墨文档:数据自动化处理与个性化应用的创新实践 在当今这个信息爆炸的时代,文档管理与协作成为了企业运营和个人工作中不可或缺的一部分。石墨文档,作为一款轻量级的云端Office套件,凭借其强大的在线协作、实时同…...

【JavaEE初阶】线程池
目录 📕 引言 🌳 概念 🍀ThreadPoolExecutor 类 🚩 int corePoolSize与int maximumPoolSize: 🚩 long keepAliveTime与TimeUnit nuit: 🚩 BlockingQueue workQueue:…...

zdpgo_cobra_req 新增解析请求体内容
zdpgo_cobra_req 使用Go语言开发的,类似于curl的HTTP客户端请求工具,用于便捷的测试各种HTTP地址 特性 1、帮助文档都是中文的2、支持常见的HTTP请求,比如GET、POST、PUT、DELETE等 下载 git clone https://github.com/zhangdapeng520/z…...
Java聚合快递对接云洋系统快递小程序源码
🌟【一键聚合,高效便捷】快递对接云洋系统小程序全攻略🚀 引言:告别繁琐,拥抱智能快递新时代🔍 在这个快节奏的时代,每一分每一秒都弥足珍贵。你是否还在为手动输入多个快递单号、频繁切换不同…...

陕西西安培华学院计算机软件工程毕业设计课题选题参考目录
陕西西安培华学院计算机软件工程毕业设计课题选题 博主介绍:✌️大厂码农|毕设布道师,阿里云开发社区乘风者计划专家博主,CSDN平台,✌️Java领域优质创作者,博客之星、掘金/华为云/阿里云等平台优质作者、专注于大学生项目实战开发…...

如何用sql在1分钟从1T数据中精准定位查询?Hive离线数仓 Spark分析
最近在一个群里,从群友哪里了解到这样一个业务需求:如何在 hdfs 1 T源数据库中,1分钟内从其中抓取自己想要的数据? 我的理解是 : 在hdfs数据库中为拥有 尽1T数据的表创建索引,并对其进行性能优化,以实现…...

acpi 主板布局需要 efi
今天在折腾 ESXI 的时候,启动虚拟机跳出了 acpi 主板布局需要 efi 然后我就将 ESXI 的启动方式改为了 EFI 但是虚拟机有莫名的启动不了,网上也没有找到办法,最后,我将虚拟机类型有原本的 ubuntu 换成了 debian 最后启动成功&…...

月之暗面对谈 Zilliz:长文本和 RAG 如何选择?
01 长文本与RAG通用对比 准确率:通常情况下长文本优于RAG 长文本:可更加综合的去分析所有相关的内容,提取相关数字,生成图表,效果尚可。RAG:更适合找到一段或者是几段可能相关的段落。如果希望大模型能够…...

高级java每日一道面试题-2024年8月12日-设计模式篇-请列举出在JDK中几个常用的设计模式?
如果有遗漏,评论区告诉我进行补充 面试官: 请列举出在JDK中几个常用的设计模式? 我回答: 在Java Development Kit (JDK) 中,许多设计模式被广泛使用,以帮助实现软件的结构、行为和复用。下面是一些在JDK中常见的设计模式及其简要说明: 工…...

mysql workbench8.0如何导出mysql5.7格式的sql定义
碰到的问题 mac上安装mysql workbech6.0后不能运行,但安装workbench8.0后,导出的数据库sql文件默认是msyql 8.0的语法和格式。比如生成索引的语句后面会有visible关键字,当把mysql8.0的sql文件导入到mysql5.7时就会报错。 如何解决 点击my…...

数据结构(学习)2024.8.6(顺序表)
今天开始学习数据结构的相关知识,大概分为了解数据结构、算法;学习线性表:顺序表、链表、栈、队列的相关知识和树:二叉树、遍历、创建,查询方法、排序方式等。 目录 一、数据结构 数据 逻辑结构 1.线性结构 2.树…...
MyBatis全解
目录 一, MyBatis 概述 1.1-介绍 MyBatis 的历史和发展 1.2-MyBatis 的特点和优势 1.3-MyBatis 与 JDBC 的对比 1.4-MyBatis 与其他 ORM 框架的对比 二, 快速入门 2.1-环境搭建 2.2-第一个 MyBatis 应用程序 2.3-配置文件详解 (mybatis-config.…...

【Redis进阶】Redis集群
目录 Redis集群的诞生 单节点Redis的局限性 1.存储容量限制 2.性能瓶颈 3.单点故障 4.扩展性能差 分布式系统发展的需要 1.海量数据处理 2.高性能要求 3.弹性扩展能力 Redis集群(cluster) 如图所示案例 Redis集群设计 什么是数据分片&…...

JVM运行时数据区之虚拟机栈
【1】概述 Java虚拟机栈(Java Virtual Machine Stack),早期也叫Java栈。每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个的栈帧(Stack Frame),对应着一次次的Java方法调用。 栈是运行…...

Python 机器学习求解 PDE 学习项目 基础知识(4)PyTorch 库函数使用详细案例
PyTorch 库函数使用详细案例 前言 在深度学习中,PyTorch 是一个广泛使用的开源机器学习库。它提供了强大的功能,用于构建、训练和评估深度学习模型。本文档将详细介绍如何使用以下 PyTorch 相关库函数,并提供相应的案例示例: to…...

SpringBoot-enjoy模板引擎
主要用于Web开发,前后端不分离时的页面渲染 SpringBoot整合enjoy模板引擎步骤: 1.将页面保存在templates目录下 2.添加enjoy的坐标 <dependency> <groupId>com.jfinal</groupId> <artifactId>enjoy</artifactId&g…...
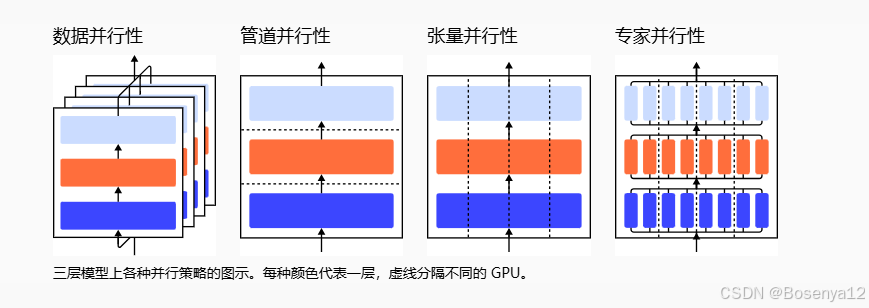
【学习笔记】如何训练大模型
如何在许多 GPU 上训练真正的大型模型? 单个 GPU 工作线程的内存有限,并且许多大型模型的大小已经超出了单个 GPU 的范围。有几种并行范式可以跨多个 GPU 进行模型训练,还可以使用各种模型架构和内存节省设计来帮助训练超大型神经网络。 并…...
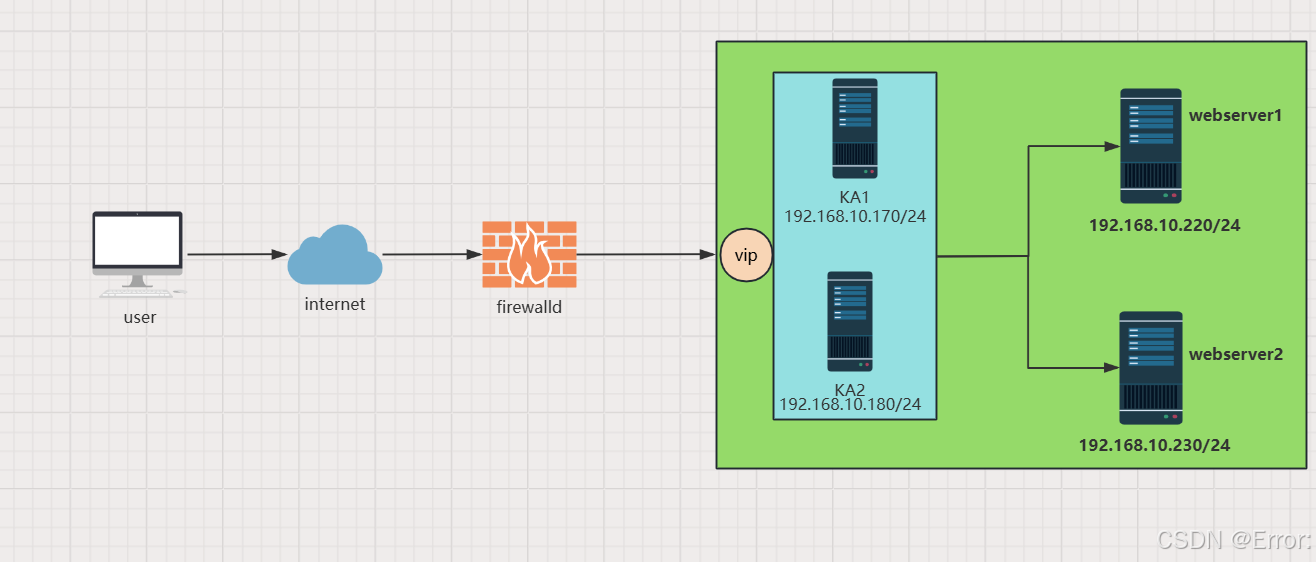
高可用集群KEEPALIVED
一、集群相关概念简述 HA是High Available缩写,是双机集群系统简称,指高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。 1、集群的分类 LB:负载均衡…...

Linux shell编程学习笔记69: curl 命令行网络数据传输工具 选项数量雷人(中)
0 前言 curl是Linux中的一款综合性网络传输工具,既可以上传也可以下载,支持HTTP、HTTPS、FTP等30余种常见协议。 该命令选项超多,在学习笔记68中,我们列举了该命令的部分实例,今天继续通过实例来研究curl命令的功能…...

怎么在网站底部添加站点地图?
在优化网站 SEO 时,站点地图(Sitemap)是一个非常重要的工具。它帮助搜索引擎更好地理解和抓取您的网站内容。幸运的是,从 WordPress 5.5 开始,WordPress 自带了站点地图生成功能,无需额外插件。下面将介绍如…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

“--glow”并不存在?!深度逆向Midjourney 6.1源码级辉光模拟协议,曝光官方刻意隐藏的4个隐式辉光增强开关
更多请点击: https://kaifayun.com 第一章:辉光效果的视觉本质与Midjourney 6.1协议悖论 辉光(Glow)并非物理光源的直接投射,而是人眼视网膜对高对比度边缘与饱和色域交界处产生的神经光学响应——一种由局部亮度梯度…...

ESP32搭建TFT_LCD中文字库,附常用字库
(一)简介 在使用ESP32的时候,我们知道OLED屏幕是有中文库的,里面有非常多的常用字,但是LCD屏幕只有取模才能得到中文字体,那我们本期教程就来教大家如何搭建自己的字体库,使用中文字体更加方便快…...