Python爬虫开发:BeautifulSoup、Scrapy入门

在现代网络开发中,网络爬虫是一个非常重要的工具。它可以自动化地从网页中提取数据,并且可以用于各种用途,如数据收集、信息聚合和内容监控等。在Python中,有多个库可以用于爬虫开发,其中BeautifulSoup和Scrapy是两个非常流行的选择。本篇文章将详细介绍这两个库,并提供一个综合详细的例子,展示如何使用它们来进行网页数据爬取。
一、BeautifulSoup入门
1. BeautifulSoup简介
BeautifulSoup是一个Python库,用于从HTML或XML文档中提取数据。它能够通过标签和属性来定位和提取数据,非常适合进行小规模的网页抓取任务。
2. 安装BeautifulSoup
在使用BeautifulSoup之前,需要安装它和一个HTML解析器,如lxml或html5lib。可以使用以下命令进行安装:
pip install beautifulsoup4 lxml3. BeautifulSoup基础用法
以下是BeautifulSoup的基本用法,包括如何解析HTML文档,查找标签和属性,以及提取数据。
from bs4 import BeautifulSouphtml_doc = """
<html>
<head><title>示例页面</title></head>
<body>
<p class="title"><b>示例段落</b></p>
<p class="content">这是一个示例页面。</p>
<a href="http://example.com/one" class="link">第一个链接</a>
<a href="http://example.com/two" class="link">第二个链接</a>
</body>
</html>
"""soup = BeautifulSoup(html_doc, 'lxml')# 查找标题标签
title = soup.title
print(title.string)# 查找所有段落标签
paragraphs = soup.find_all('p')
for p in paragraphs:print(p.text)# 查找所有链接标签
links = soup.find_all('a')
for link in links:print(link.get('href'))二、Scrapy入门
1. Scrapy简介
Scrapy是一个用于爬取网站并提取结构化数据的应用框架。它提供了强大的功能,如处理请求、解析HTML、管理爬取的数据等,适合进行大规模的爬虫开发。
2. 安装Scrapy
可以使用以下命令安装Scrapy:
pip install scrapy3. Scrapy基础用法
以下是Scrapy的基本用法,包括如何创建项目、定义爬虫和解析数据。
# 创建Scrapy项目
scrapy startproject example_project
cd example_project# 创建爬虫
scrapy genspider example example.com在example_project/spiders/example.py中定义爬虫:
import scrapyclass ExampleSpider(scrapy.Spider):name = "example"allowed_domains = ["example.com"]start_urls = ['http://example.com/',]def parse(self, response):for title in response.css('title'):yield {'title': title.get()}for link in response.css('a::attr(href)').getall():yield response.follow(link, self.parse)运行爬虫:
scrapy crawl example三、综合示例:爬取博客文章
以下是一个综合示例,展示如何使用BeautifulSoup和Scrapy来爬取博客文章并提取文章标题和链接。
1. 使用BeautifulSoup爬取博客文章
import requests
from bs4 import BeautifulSoupurl = 'https://example-blog.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'lxml')# 提取文章标题和链接
articles = soup.find_all('article')
for article in articles:title = article.find('h2').textlink = article.find('a')['href']print(f"标题: {title}, 链接: {link}")2. 使用Scrapy爬取博客文章
首先,创建Scrapy项目并生成爬虫:
scrapy startproject blog_crawler
cd blog_crawler
scrapy genspider blog_spider example-blog.com在blog_crawler/spiders/blog_spider.py中定义爬虫:
import scrapyclass BlogSpider(scrapy.Spider):name = "blog_spider"allowed_domains = ["example-blog.com"]start_urls = ['https://example-blog.com/',]def parse(self, response):for article in response.css('article'):title = article.css('h2::text').get()link = article.css('a::attr(href)').get()yield {'title': title, 'link': link}next_page = response.css('a.next::attr(href)').get()if next_page:yield response.follow(next_page, self.parse)运行爬虫并保存结果到JSON文件:
scrapy crawl blog_spider -o articles.json四、深入理解BeautifulSoup
1. BeautifulSoup的解析器
BeautifulSoup支持多种解析器,包括Python标准库的html.parser、第三方库lxml和html5lib。不同解析器的性能和功能有所不同,选择适合的解析器可以提升解析效率。
from bs4 import BeautifulSoup# 使用html.parser解析器
soup = BeautifulSoup(html_doc, 'html.parser')# 使用lxml解析器
soup = BeautifulSoup(html_doc, 'lxml')# 使用html5lib解析器
soup = BeautifulSoup(html_doc, 'html5lib')2. BeautifulSoup的常用功能
- 查找标签:使用
find和find_all方法查找单个或多个标签。 - CSS选择器:使用
select方法通过CSS选择器查找标签。 - 遍历文档树:使用
parent、children、siblings等方法遍历文档树。
# 查找单个标签
title_tag = soup.find('title')# 查找所有特定标签
links = soup.find_all('a')# 使用CSS选择器
links = soup.select('a')# 遍历文档树
parent = title_tag.parent
siblings = title_tag.next_siblings3. BeautifulSoup的应用实例
以下是一个完整的实例,展示如何使用BeautifulSoup爬取一个新闻网站的标题和链接。
import requests
from bs4 import BeautifulSoupurl = 'https://news.ycombinator.com/'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'lxml')articles = soup.find_all('a', class_='storylink')
for article in articles:title = article.textlink = article['href']print(f"标题: {title}, 链接: {link}")五、深入理解Scrapy
1. Scrapy的组件
Scrapy有多个重要的组件,每个组件都有特定的功能。
- Spider:定义爬取逻辑,发送请求并处理响应。
- Item:定义数据结构,用于存储爬取的数据。
- Pipeline:处理爬取的数据,如清洗、验证和存储。
- Middleware:处理请求和响应,如添加请求头和处理错误。
2. Scrapy的配置
Scrapy提供了丰富的配置选项,可以在settings.py中配置。
# 设置用户代理
USER_AGENT = 'my-crawler (http://example.com)'# 设置并发请求数量
CONCURRENT_REQUESTS = 16# 设置下载延迟
DOWNLOAD_DELAY = 1# 启用或禁用中间件
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.CustomMiddleware': 543,
}3. Scrapy的应用实例
以下是一个完整的Scrapy爬虫实例,展示如何爬取一个新闻网站的标题和链接,并将数据存储到JSON文件中。
首先,创建项目和爬虫:
scrapy startproject news_crawler
cd news_crawler
scrapy genspider news_spider news.ycombinator.com在news_crawler/items.py中定义Item:
import scrapyclass NewsItem(scrapy.Item):title = scrapy.Field()link = scrapy.Field()在news_crawler/spiders/news_spider.py中定义爬虫:
import scrapy
from news_crawler.items import NewsItemclass NewsSpider(scrapy.Spider):name = 'news_spider'allowed_domains = ['news.ycombinator.com']start_urls = ['https://news.ycombinator.com/']def parse(self, response):articles = response.css('a.storylink')for article in articles:item = NewsItem()item['title'] = article.css('::text').get()item['link'] = article.css('::attr(href)').get()yield itemnext_page = response.css('a.morelink::attr(href)').get()if next_page:yield response.follow(next_page, self.parse)在news_crawler/pipelines.py中定义Pipeline:
import jsonclass NewsCrawlerPipeline:def open_spider(self, spider):self.file = open('items.json', 'w')def close_spider(self, spider):self.file.close()def process_item(self, item, spider):line = json.dumps(dict(item)) + "\n"self.file.write(line)return item在news_crawler/settings.py中启用Pipeline:
ITEM_PIPELINES = {'news_crawler.pipelines.NewsCrawlerPipeline': 300,
}运行爬虫并保存结果到JSON文件:
scrapy crawl news_spider六、总结
通过本文,我们详细介绍了Python中的两个流行的爬虫开发库:BeautifulSoup和Scrapy。我们不仅介绍了它们的基本用法,还深入探讨了它们的高级功能和应用场景。通过综合实例,我们展示了如何使用这两个库来爬取新闻网站的标题和链接,并将数据存储到文件中。
希望本文对你理解和使用BeautifulSoup和Scrapy有所帮助,无论是进行小规模的网页抓取任务,还是开发大规模的爬虫项目。未来可以根据具体需求选择合适的工具,提高开发效率和数据处理能力。
作者:Rjdeng
链接:https://juejin.cn/post/7400255677804232716
相关文章:
Python爬虫开发:BeautifulSoup、Scrapy入门
在现代网络开发中,网络爬虫是一个非常重要的工具。它可以自动化地从网页中提取数据,并且可以用于各种用途,如数据收集、信息聚合和内容监控等。在Python中,有多个库可以用于爬虫开发,其中BeautifulSoup和Scrapy是两个非…...
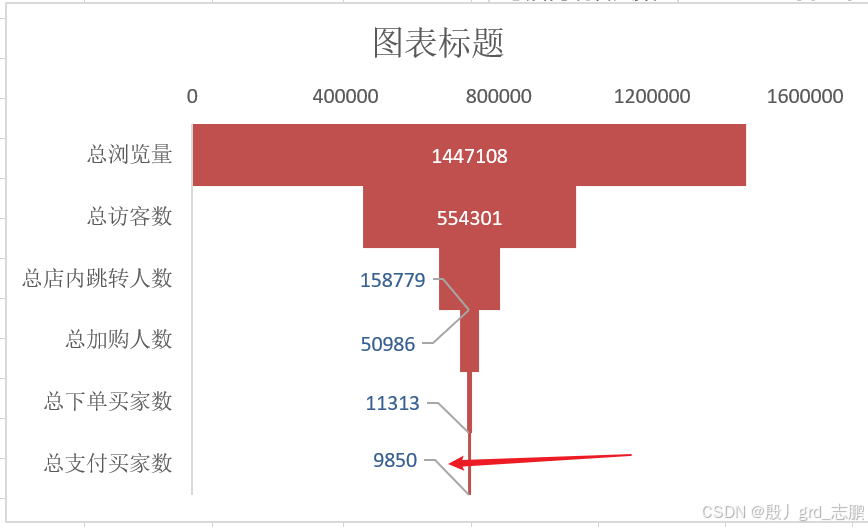
数据科学、数据分析、人工智能必备知识汇总-----常用数据分析方法-----持续更新
数据科学、数据分析、人工智能必备知识汇总-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/140174015 文章目录 一、对比分析法1. 按时间和地区2. 同比和环比 二、分组分析法三、结构分析法四、交叉分析法五、矩阵分…...

学习vue Router 一 起步,编程式导航,历史记录,路由传参
目录 起步,安装 1. 安装 2. 使用 命名路由 编程式导航 1. 字符串模式 2. 对象模式 3. 命名路由模式 历史记录 replace的使用 横跨历史 路由传参 1. query路由传参 2. 动态路由传参 3. 二者的区别 起步,安装 router 路由 因为vue是单页应用…...

Qt/C++最新地图组件发布/历时半年重构/同时支持各种地图内核/包括百度高德腾讯天地图
一、前言说明 最近花了半年时间,专门重构了整个地图组件,之前写的比较粗糙,有点为了完成功能而做的,没有考虑太多拓展性和易用性。这套地图自检这几年大量的实际项目和用户使用下来,反馈了不少很好的建议和意见&#…...

Laravel + Thinkphp 生成二维码
安装依赖 composer require endroid/qr-code 编写ThinkPhP代码 public function index() {// 创建二维码内容$qrCode new QrCode(Hello World);// 设置二维码的配置$qrCode->setSize(300);$qrCode->setMargin(10);// 获取二维码图像$writer new PngWriter();$result…...

2408C++,C++20的无侵入式反射
原文 C17基于结构绑定的编译期反射 事实上不需要宏的编译期反射在C17中已用得很多了,比如struct_pack的编译期反射就不需要宏,因为C17结构绑定可直接得到一个聚集类的成员的引用. struct person {int id;std::string name;int age; }; int main() {person p{1, "tom&qu…...
- python实现)
抽象工厂模式(Abstract factory pattern)- python实现
抽象工厂模式的通俗示例 想象一下,你正在经营一家家具店,你需要从不同的供应商那里采购不同的家具系列。有的供应商提供的是现代风格家具,包括现代沙发、现代椅子和现代桌子;而有的供应商提供的是古典风格家具,包括古…...

adb Connection reset by peer的解决方法
本文同步发于:https://www.cnblogs.com/yeshen-org/p/18350232 最近在编译一个老项目,项目中依赖了很多第三方库,用gradle编译要20-30分钟,而且内存开销很大。 公司配的15G内存的电脑,一次编译能用到14G。 编译的时候&…...

111111111
1111111111111111111...

搜维尔科技:Varjo XR-4使用UE5 打造最具沉浸感的混合现实环境
Varjo XR-4使用UE5打造最具沉浸感的混合现实环境 搜维尔科技:Varjo XR-4使用UE5 打造最具沉浸感的混合现实环境...
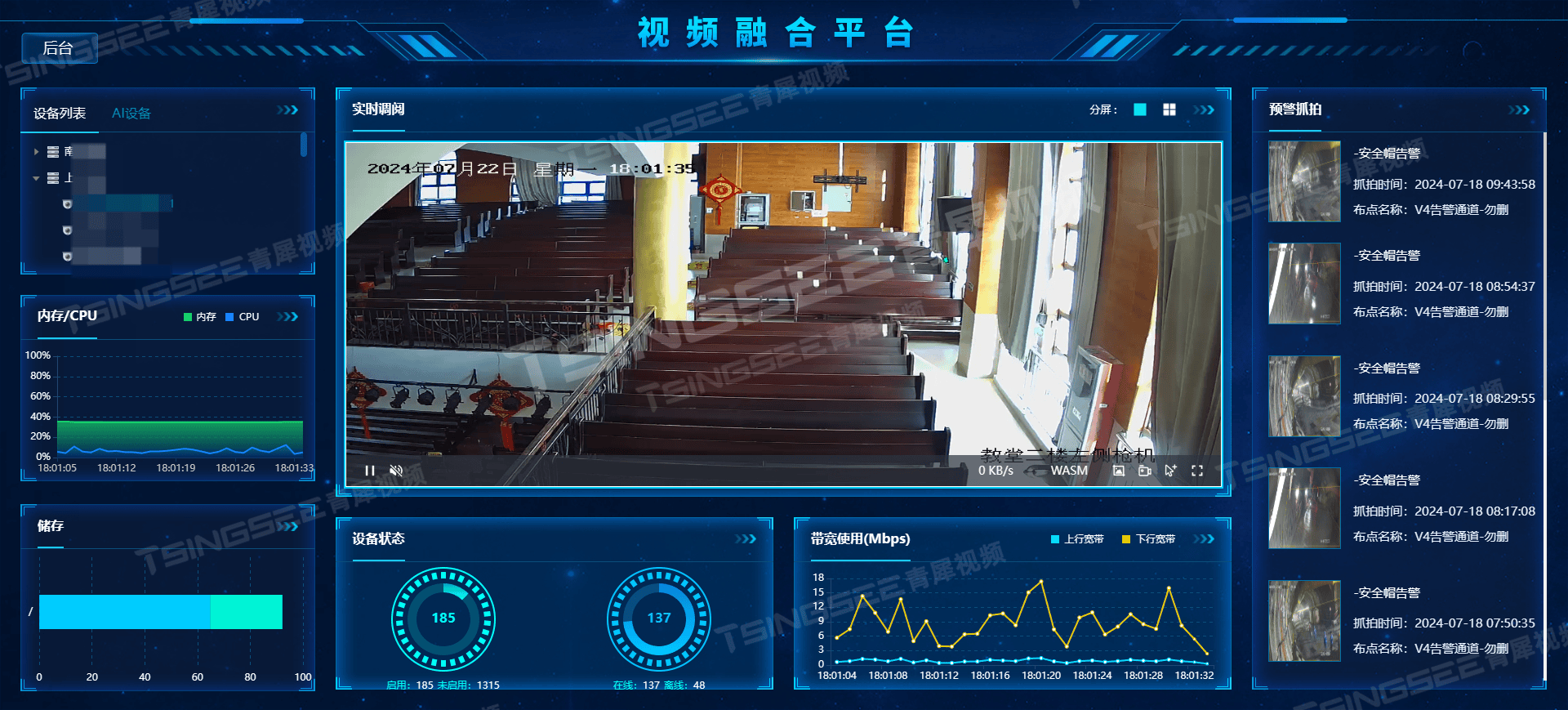
从分散到集中:TSINGSEE青犀EasyCVR视频汇聚网关在视频整体监控解决方案中的整合作用
边缘计算视频汇聚网关是基于开放式、大融合、全兼容、标准化的设计架构理念,依据《安全防范视频监控联网系统信息传输、交换、控制技术要求》(GB/T28181-2011)标准开发,集流媒体转发、视频编码、视频管理、标准通信协议、网络穿透…...

React学习-jsx语法
jsx语法,浏览器不认识,需要经过babel编译 https://babeljs.io/ 面试题:jsx的作用? 普通回答:可以在js中返回dom,经过babel编译成js认识的代码import { jsx as _jsx, jsxs as _jsxs } from "react/j…...

uniapp多图上传uni.chooseImage上传照片uni.uploadFile
uniapp多图上传uni.chooseImage上传照片uni.uploadFile 代码示例: /**上传照片 多图*/getImage() {uni.chooseImage({count: 9, //默认9sizeType: [original, compressed], //可以指定是原图还是压缩图,默认二者都有sourceType: [album], //从相册选择/…...

鸿蒙(API 12 Beta2版)媒体开发【处理音频焦点事件】
音频打断策略 多音频并发,即多个音频流同时播放。此场景下,如果系统不加管控,会造成多个音频流混音播放,容易让用户感到嘈杂,造成不好的用户体验。为了解决这个问题,系统预设了音频打断策略,对…...
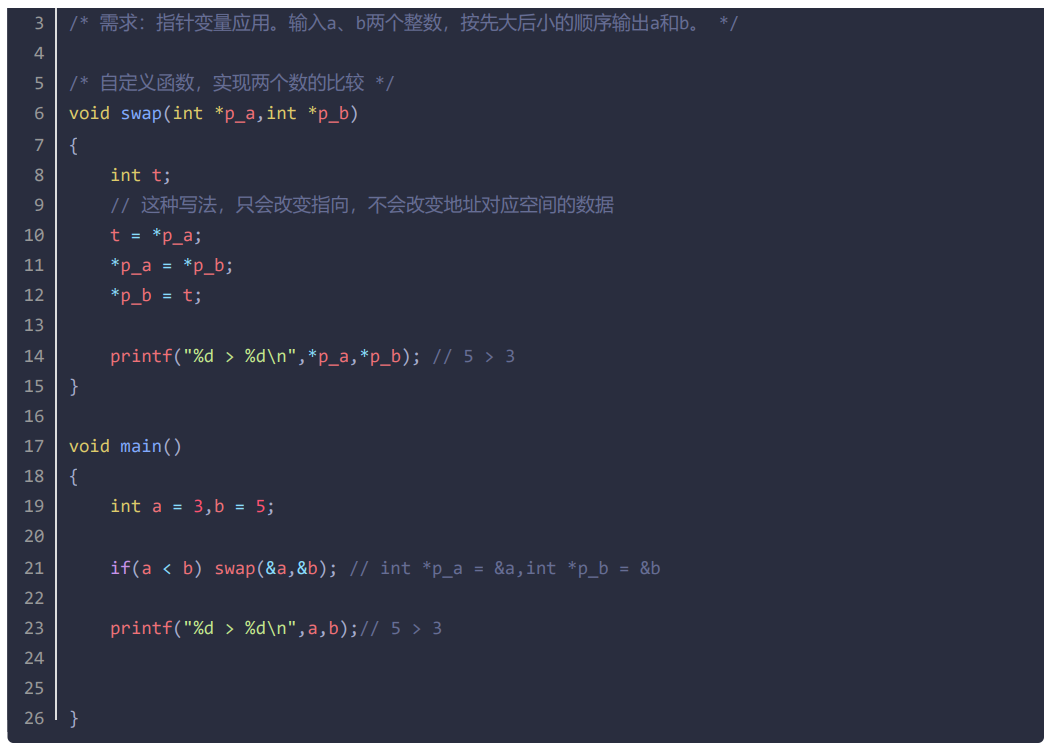
c语言第12天
指针的引入 为函数修改实参提供支持。 为动态内存管理提供支持。 为动态数据结构提供支持。 为内存访问提供另一种途径。 指针概述 内存地址:系统为了内存管理的方便,将内存划分为一个个的内存单元(1个内存单元占1个字 节)&…...

回归预测|一种多输入多输出的粒子群优化支持向量机数据回归预测Matlab程序PSO-MSVR非for循环实现 原理上进行修改多输出
回归预测|一种多输入多输出的粒子群优化支持向量机数据回归预测Matlab程序PSO-MSVR非for循环实现 原理上进行修改多输出 文章目录 前言回归预测|一种多输入多输出的粒子群优化支持向量机数据回归预测Matlab程序PSO-MSVR非for循环实现 原理上进行修改多输出 一、PSO-MSVR模型1. …...

《花100块做个摸鱼小网站! 》第二篇—后端应用搭建和完成第一个爬虫
一、前言 大家好呀,我是summo,前面已经教会大家怎么去阿里云买服务器(链接在这,需要自取:https://developer.aliyun.com/huodong/dashiblogger?userCodemtbtcjr1),以及怎么搭建JDK、Redis、My…...

Mapreduce_csv_averageCSV文件计算平均值
csv文件求某个平均数据 查询每个部门的平均工资,最后输出 数据处理过程 employee_noheader.csv(没做关于首行的处理,运行时请自行删除) EmployeeID,EmployeeName,DepartmentID,Salary 1,ZhangSan,101,5000 2,LiSi,102,6000…...

将UEC++项目转码成UTF-8
方法一 如果文件不多的话,可以手动一个一个进行修改。添加 “高级保存选项” 手动改为UTF-8 方法二 使用editorconfig文件,统一编码问题。通过:“工具” > “选项”>"文本编辑器" > "C/C" > "代码样式…...

深入探索MySQL C API:使用C语言操作MySQL数据库
目录 引言 一. MySQL C API简介 二. MySQL C API核心函数 2.1 初始化和连接 2.2 配置和执行 2.3 处理结果 2.4 清理和关闭 2.5 错误处理 三. MySQL使用过程 四. 实现CRUD操作 4.1 创建数据库并建立表 编辑 4.2 添加数据(Create) 编辑 …...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...