复现、并改进open-mmlab的mmpose详细细节
复现open-mmlab的mmpose详细细节
- 1.配置环境
- 2.数据处理
- 3.训练
- 4.改进mmpose
- 4.1 快速调试技巧
- 4.2 快速定位
- 4.3 改进backbone
- 4.3.1 使用说明
- 4.3.2 改进案例
- 4.3.2.1 复现mmpose原配置文件
- 4.3.2.2 复现开源项目
- 4.3.2.3 修改配置文件
- 4.3.2.4 修改新模型
- 4.4 添加auxiliary_head
- 4.4.1 添加auxiliary_head配置
- 4.4.2 注意事项
1.配置环境
stage1:创建python环境
conda create --name openmmlab python=3.8 -y
conda activate openmmlab
stage2:安装pytorch(这里我是以torch1.10.0为例)
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
stage3:安装MMCV,全部都可以加上清华源,-i https://pypi.tuna.tsinghua.edu.cn/simple
pip install openmim
pip install mmengine
pip install "mmcv>=2.0.1"
pip install "mmdet>=3.1.0"
但是,这里在安装mmcv的时候,容易出错,比如:ImportError: DLL load failed while importing _ext: 找不到指定的程序。
很大就是mmcv版本装的有问题。
我们定位到mmcv的安装文档
https://mmcv.readthedocs.io/en/latest/get_started/installation.html#install-mmcv
会有根据操作系统、cuda版本,以及torch的版本后,确定自己选择的mmcv版本,进而生成最终的安装指令。

stage4:安装MMPose:
方式1:
git clone https://github.com/open-mmlab/mmpose.git
cd mmpose
pip install -r requirements.txt
pip install -v -e .
方式2:
pip install "mmpose>=1.1.0"
2.数据处理
这里我们以 CrowdPose 数据集为例,下载链接为:
https://github.com/MVIG-SJTU/AlphaPose/blob/pytorch/doc/CrowdPose.md
这里我们任意选取configs/body_2d_keypoint文件中的文件,以:topdown_heatmap/crowdpose/td-hm_res50_8xb64-210e_crowdpose-256x192.py为例。
新建文件夹CrowdPose,并将下载下来的数据集文件夹存放进去:

我们首先更改选好的配置文件td-hm_res50_8xb64-210e_crowdpose-256x192.py中的data_root,路径就是刚才我们新建好的文件夹。

接着,还是同一份配置文件,我们更改标注文件,这里文件的默认为:'annotations/mmpose_crowdpose_train.json',我们可以根据这个来修改我们下载下来的数据集文件夹名称,也可以将这里反过来改成我们自己的数据集文件夹名,都可以的。

3.训练
4.改进mmpose
MMPose中,所有与模型结构实现相关的代码都存放在 models目录下:

4.1 快速调试技巧
mmpose是基于pytorch开发的,所以在数据预处理以及前向传播的调用,都在底层环境的mmengine中:/mmengine/model/base_model/base_model.py。

我们这里可以打断点过来,可以看到,image的维度是[batch_szie, 3, 256, 192];

随后,我们可以在我们选用的backbone,或者自己新加的backbone中,在前向传播forward函数中打上断点,会发现这里的x就是上述的image,与此同时,也能看到每一层网络结构后feature map的变化。

这里,给推荐另一个小技巧,因为每次从整个框架的train开始断点,耗时麻烦。
我们直接在backbone的py文件中,进行调试,这样就大大减少了我们改进或者调试模型的复杂度,我们只要添加如下代码,将config配置文件中模型的extra 字典复制过来,然后在当前py文件进行debug就省事省力了。
if __name__ == '__main__':extra = dict(stage1=dict(num_modules=1,num_branches=1,block='BOTTLENECK',num_blocks=(4,),num_channels=(64,)),stage2=dict(num_modules=1,num_branches=2,block='BASIC',num_blocks=(4, 4),num_channels=(32, 64)),stage3=dict(num_modules=4,num_branches=3,block='BASIC',num_blocks=(4, 4, 4),num_channels=(32, 64, 128)),stage4=dict(num_modules=3,num_branches=4,block='BASIC',num_blocks=(4, 4, 4, 4),num_channels=(32, 64, 128, 256)))model = HRNet(extra, in_channels=3)model.eval()x = torch.randn((2, 3, 256, 192))outputs = model(x)
4.2 快速定位
将backbone、neck、head各结构实例化的接口位于mmpose/models/pose_estimators/base.py中。

4.3 改进backbone
4.3.1 使用说明
如果希望实现一个新的backbone,你需要在目录 backbones下新建一个文件进行定义。

新建的骨干网络需要继承BaseBackbone 类,其他方面与你继承 nn.Module 来创建没有任何不同。
在完成骨干网络的实现后,你需要使用 MODELS来对其进行注册:
from mmpose.registry import MODELS
from .base_backbone import BaseBackbone
@MODELS.register_module()
class YourNewBackbone(BaseBackbone):

最后,请记得在backbones/__init__.py 中导入你的新骨干网络。

4.3.2 改进案例
以复现mmpose配置文件:configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py为例,该配置文件的backbone对应的配置文件为:‘HRNet’,我们比如想替换:
https://github.com/xzz777/SCTNet
中的开源项目中的分割backbone。
4.3.2.1 复现mmpose原配置文件
为了确保替换的backbone能跑通,最好是跑一遍原始配置文件,这样清楚知道模型的backbone、neck、head各结构输出的维度,这样方便在新模型中进行调整。
我们首先复现官方提供的原配置文件:configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py。
配置文件中:input_size表示dataloder预处理后图片的size(也就是模型的输入图像大小),heatmap_size表示最后输出的key points热图的size,这里可以更改为指定的size,比如:640,相应的热图size相应缩放4倍。

backbone输入:[2, 3, 640, 640],backbone的输出为:[batch_size, 32, 160, 160]。

Head表示输出头,in_channels为32,表示backbone的输出通道数(如果没有设置neck结构的话),out_channels为17,表示Head的输出通道数,结合上述的heatmap_size最终的输出为:[batch_size, 17, 160, 160]。

4.3.2.2 复现开源项目
我们想用:
https://github.com/xzz777/SCTNet
中的开源项目中的分割backbone,那复现一下看一下底层的feature map的变化对于我们快速改完模型是帮助很大的。
输入:[2, 3, 640, 640],输出如下:

4.3.2.3 修改配置文件
我们参照4.3.1 使用说明新建好开源项目中的backbone后,我们对配置文件中的model字典文件进行更改:
# model settings
model = dict(type='TopdownPoseEstimator',data_preprocessor=dict(type='PoseDataPreprocessor',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],bgr_to_rgb=True),# backbone=dict(# type='HRNet',# in_channels=3,# extra=dict(# stage1=dict(# num_modules=1,# num_branches=1,# block='BOTTLENECK',# num_blocks=(4, ),# num_channels=(64, )),# stage2=dict(# num_modules=1,# num_branches=2,# block='BASIC',# num_blocks=(4, 4),# num_channels=(32, 64)),# stage3=dict(# num_modules=4,# num_branches=3,# block='BASIC',# num_blocks=(4, 4, 4),# num_channels=(32, 64, 128)),# stage4=dict(# num_modules=3,# num_branches=4,# block='BASIC',# num_blocks=(4, 4, 4, 4),# num_channels=(32, 64, 128, 256))),# init_cfg=dict(# type='Pretrained',# checkpoint='https://download.openmmlab.com/mmpose/'# 'pretrain_models/hrnet_w32-36af842e.pth'),# ),backbone=dict(type='SCTNet',init_cfg=dict(type='Pretrained',checkpoint=checkpoint_backbone),base_channels=64,spp_channels=128),head=dict(type='HeatmapHead',#in_channels=32,in_channels=256,out_channels=17,deconv_out_channels=None,loss=dict(type='KeypointMSELoss', use_target_weight=True),decoder=codec),test_cfg=dict(flip_test=True,flip_mode='heatmap',shift_heatmap=True,))
4.3.2.4 修改新模型
上述我们分别在复现mmpose框架和我们想要采用的分割开源项目后,可以发现即使统一输入图像为640x640,两个项目的backbone的输出都是不一样的。这里因为基于mmpose框架来改,所以我们肯定是将分割开源项目backbone的输出尽量调整和我们上述复现mmpose中hrnet的输出一致,这样在框架后续中求loss等也就不会报错了。
这是分割开源项目的backbone的输出:

这是mmpose中hrnet的输出:

两个backbone输出的通道数不一致,这会导致Head报错,这里我们对配置文件的Head接受输入的通道数进行修改,将32更改为我们的新backbone的输出通道数256。

所以,现在两个backbone的输出还差宽高不一致,我们这个时候来进一步看一下,Head部分的代码,Head采用’HeatmapHead’,我们定位到mmpose/models/heads/heatmap_heads/heatmap_head.py,发现前向传播forward中代码不多,所以我们选择在Head部分调整backbone的输出。

因为我们的backbone中输出的是list,这里我们要对原始的forward进行修改,我们选用backbone最后层的输出,也就是list[0],同时我们采用双线性插值调整输出的宽高。
def forward(self, feats: Tuple[Tensor]) -> Tensor:"""Forward the network. The input is multi scale feature maps and theoutput is the heatmap.Args:feats (Tuple[Tensor]): Multi scale feature maps.Returns:Tensor: output heatmap."""# x = feats[-1]x = feats[0]x = self.deconv_layers(x)x = self.conv_layers(x)x = self.final_layer(x)x = F.interpolate(input=x, scale_factor=2, mode='bilinear')return x
4.4 添加auxiliary_head
4.4.1 添加auxiliary_head配置
上述git中使用了Transformer Block作为辅助head,这里我们也尝试在我们的mmpose框架中进行改进。
https://github.com/xzz777/SCTNet
我们参照这个git,添加auxiliary_head的配置文件。

# model settings
model = dict(type='TopdownPoseEstimator',data_preprocessor=dict(type='PoseDataPreprocessor',mean=[123.675, 116.28, 103.53],std=[58.395, 57.12, 57.375],bgr_to_rgb=True),backbone=dict(type='SCTNet',init_cfg=dict(type='Pretrained',checkpoint=checkpoint_backbone),base_channels=64,spp_channels=128),head=dict(type='HeatmapHead_Revise',# in_channels=32,in_channels=256,out_channels=17,deconv_out_channels=None,loss=dict(type='KeypointMSELoss', use_target_weight=True),decoder=codec),auxiliary_head=[dict(type='VitGuidanceHead',init_cfg=dict(type='Pretrained',checkpoint= checkpoint_teacher),in_channels=256,channels=256,base_channels=64,in_index=2,num_classes=171,loss_decode=dict(type='AlignmentLoss', loss_weight=[3, 15, 15, 15]))],test_cfg=dict(flip_test=True,flip_mode='heatmap',shift_heatmap=True,))但是,发生了报错:
TypeError: init() got an unexpected keyword argument ‘auxiliary_head’
我们在进入底层环境(这里就是我们对应配置的Anaconda环境)后,我的是:D:\Anaconda3\envs\SCTNet\Lib\site-packages\mmengine\registry\build_functions.py,定位到报错的位置,发现是在:mmpose/models/pose_estimators/topdown.py中

在TopdownPoseEstimator类中,添加缺少了‘auxiliary_head’字典的键。

随后,我们得在mmpose框架中注册一个新的head,你需要在目录 mmpose/models/heads/heatmap_heads下新建一个文件进行定义。

新建的head网络需要继承BaseHead类,其他方面与你继承 nn.Module 来创建没有任何不同。
在完成骨干网络的实现后,你需要使用 MODELS来对其进行注册:
from mmpose.registry import MODELS
from ..base_head import BaseHead
@MODELS.register_module()
class YourNewHead(BaseHead):

最后,请记得在heatmap_heads/__init__.py 中导入你的新nead网络。

4.4.2 注意事项
可能会报错:
No module named ‘mmcv.cnn.utils.weight_init’
改成:
from mmengine.model import BaseModule, constant_init, kaiming_init, trunc_normal_init, trunc_normal_init, normal_init
由于,继承了BaseHead,

BaseHead里有3个abstractmethod,抽象方法在基类中没有实现,子类必须实现这些方法,否则子类也会被视为抽象类,无法实例化。

如果我们暂时没有使用到这3个方法,可以重写出来,用pass带过:

相关文章:
复现、并改进open-mmlab的mmpose详细细节
复现open-mmlab的mmpose详细细节 1.配置环境2.数据处理3.训练4.改进mmpose4.1 快速调试技巧4.2 快速定位4.3 改进backbone4.3.1 使用说明4.3.2 改进案例4.3.2.1 复现mmpose原配置文件4.3.2.2 复现开源项目4.3.2.3 修改配置文件4.3.2.4 修改新模型 4.4 添加auxiliary_head4.4.1 …...

编写兼容Python2.x与3.x代码
编写兼容Python2.x与3.x代码 当我们正处于Python2.x到Python3.x的过渡期时,你可能想过是否可以在不修改任何代码的前提下能同时运行在Python2和3中。这看起来还真是一个合理的诉求,但如何开始呢?哪些Python2代码在3.x解释器执行时容易出状况…...

比特币8.12学习问题
疑问:什么是过滤,什么是offset 没有投钱的情况下,怎么用api 公式:单币分配金额 总资金 / 2/ offset/选币数量,其中2 表示多空 买入滑点(Slippage)是指在执行交易订单时,实际成交…...

解析 Vue 中的app.version、 app.provide 与 app.runWithContext :原理、应用与实例剖析
目录 app.provide app.runWithContext app.version 非 VIP 用户能够通过积分下载博文资源 app.provide 在 Vue 3.0 中,app.provide充当着在应用层级提供全局共享数据或者服务的关键角色。 app.provide(key, value) 这一方法接收两个关键参数,其中 …...

Ubuntu server 命令行跑selenium
背景 自动化测试都是在本机win上使用selenium 跑自动化脚本,但是服务器都是命令行的没有web界面 依赖包部署 apt-get install zlib1g-dev zlib1g## 安装谷歌浏览器 ## 跳到底部,选择其他平台 https://www.google.com/chrome/## ubuntu # dpkg -i google-chrome-stable_…...

刚刚,模糊测试平台SFuzz受到行业认可
近日,中国网络安全产业联盟(CCIA)正式发布了“2024年网络安全优秀创新成果大赛-安全严选专题赛”评选结果,开源网安模糊测试平台SFuzz凭借重大创新能力,得到组委会认可,获本次大赛创新产品优胜奖。 2024年网…...
数据结构与算法——DFS(深度优先搜索)
算法介绍: 深度优先搜索(Depth-First Search,简称DFS)是一种用于遍历或搜索树或图的算法。这种算法会尽可能深地搜索图的分支,直到找到目标节点或达到叶节点(没有子节点的节点),然后…...

基于lambda简化设计模式
写在文章开头 本文将演示基于函数式编程的理念,优化设计模式中繁琐的模板化编码开发,以保证用尽可能少的代码做尽可能多的事,希望对你有帮助。 Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ÿ…...

揭秘! 经纬恒润“车路云一体化”方案研发服务背后的科技驱动力
随着高级别智能驾驶技术的飞速发展,自动驾驶与路侧基础设施协同合作已成为行业内的又一热点。我国率先提出以“车路云一体化”为核心的战略布局,国家政策密集出台,地方试点积极推进,行业标准日趋完善,智能网联汽车“车…...

Redis操作--RedisTemplate(二)StringRedisTemplate
一、介绍 1、简介 由于存储在 Redis 中的 key 和 value 通常是很常见的 String 类型,Redis模块提供了 RedisConnection 和 RedisTemplate 的扩展,分是 StringRedisConnection 和 StringRedisTemplate,作为字符串操作的解决方案。 通过源码…...

【自动驾驶】ROS中自定义格式的服务通信,含命令行动态传参(c++)
目录 通信流程创建服务器端及客户端新建服务通讯文件修改service的xml及cmakelistCMakeLists.txt编辑 msg 相关配置编译消息相关头文件在cmakelist中包含头文件的路径在service包下编写service.cpp在client包下编写client.cpp测试运行查询服务的相关指令列出目前的所有服务&…...

优思学院|PDCA和DMAIC之间如何选择?
在现代组织中,提升方法、质量和效率是企业追求卓越、保持竞争力的核心目标。在这条道路上,DMAIC(定义、测量、分析、改进、控制)和PDCA(计划、执行、检查、行动)被广泛应用于持续改进和问题解决。这两者虽然…...

5 款最佳 Micro SD 卡恢复软件,助您恢复文件
您是否对数据恢复存在某些疑问,并想知道如何恢复 Micro SD 卡上的文件?如果是,那么在本文中您将找到答案。网上有许多专门用于从 Micro SD 卡或格式化的 Micro 卡恢复已删除文件而设计的软件。因此,在本文中,我们将向您…...

【使用教程】CiA402中的“原点回归模式”和“轮廓位置模式”搭配使用操作实例
使用“原点回归模式”配合“轮廓位置模式”是步进或伺服电机使用过程中最常用的方法,其对于提高自动化生产线的准确性和效率具有重要意义,本文将对正常使用控制电机中发送的命令及顺序进行简要说明。 说明:“原点回归”以“堵转回原点”的方式…...

服务器网络不通排查方案
服务器网络不通排查方案 最近遇到了服务器上服务已经启动,但是在浏览器上无法访问的问题,记录一下排查流程 文章目录 服务器网络不通排查方案netstart排查网络连接信息netstat 命令netstat -aptn 命令 iptables总结 netstart排查网络连接信息 netstat …...
问题解决历程)
Spring Boot + Vue 跨域配置(CORS)问题解决历程
在使用 Spring Boot 和 Vue 开发前后端分离的项目时,跨域资源共享(CORS)问题是一个常见的挑战。接下来,我将分享我是如何一步步解决这个问题的,包括中间的一些试错过程,希望能够帮助到正在经历类似问题的你…...
Think | 大模型迈向AGI的探索和对齐
注:节选自我于24年初所写的「融合RL与LLM思想探寻世界模型以迈向AGI」散文式风格文章,感兴趣的小伙伴儿可以访问我的主页置顶或专栏收录,并制作了电子书供大家参考,有需要的小伙伴可以关注私信我,因为属于技术散文风格…...
为什么选择在Facebook投放广告?
2024年了你还没对 Facebook 广告产生兴趣?那你可就亏大了! 今天这篇文章,我们会分享它对你扩大业务的好处。要知道,Facebook 广告凭借它庞大的用户群和先进的定位选项,已经是企业主们有效接触目标受众的必备神器。接下…...
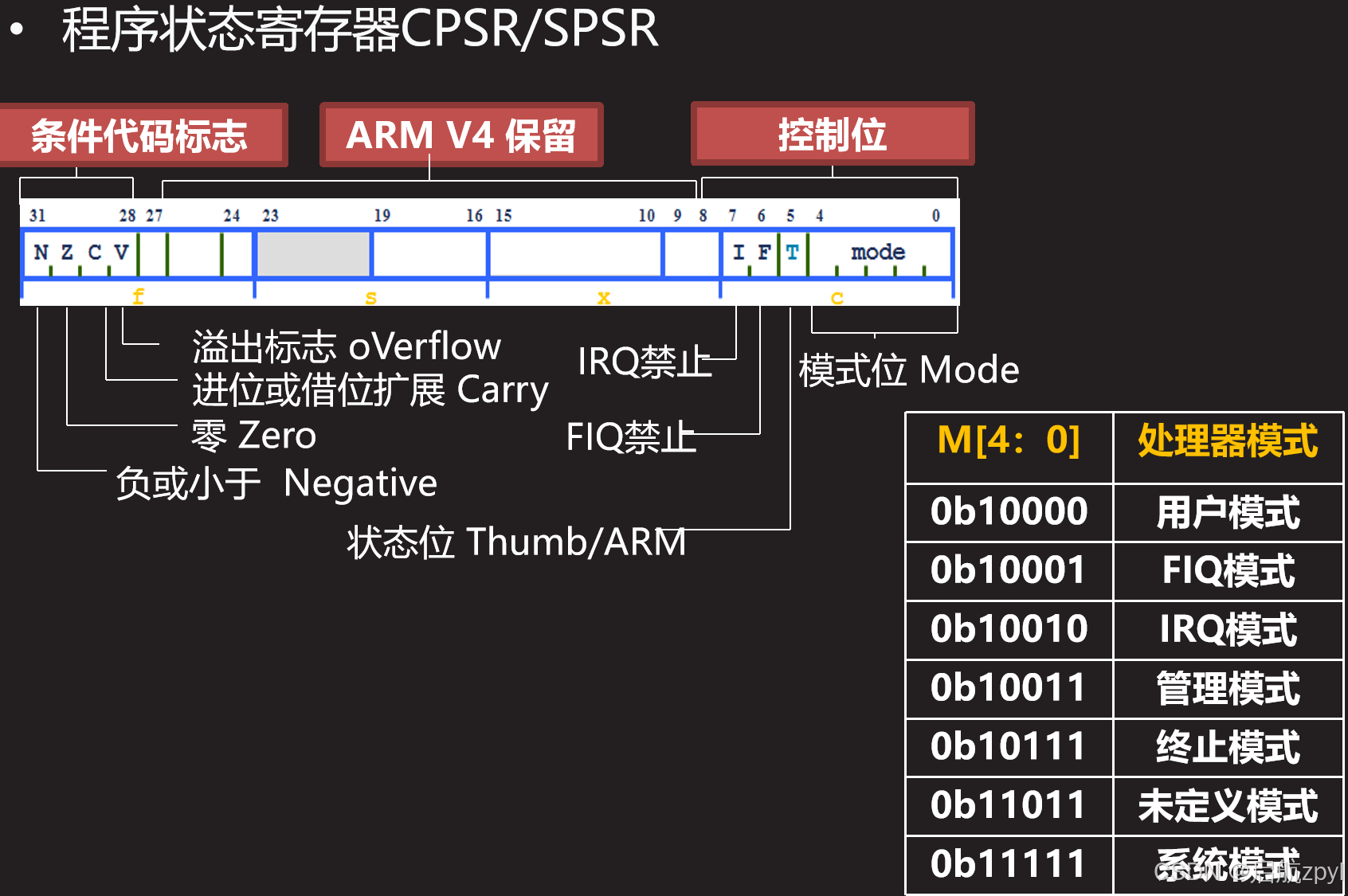
10 ARM 体系
10 ARM 体系 ARM体系1、基本概念1.1 常见的处理器1.2 ARM7三级指令流水线1.3 初识PC寄存器 2、 ARM核的七种工作模式3、ARM核七种异常 ARM体系 1、基本概念 1.1 常见的处理器 PowerPC处理器:飞思卡尔MPC系列 DSP:TI达芬奇系列 FPGA:Xilinx赛灵思的ZYN…...
指令)
ubuntu中设置开机自动运行的(sudo)指令
ubuntu版本:22.04.4 在Ubuntu中设置开机自动运行某一条(需要sudo权限的)指令,我们可以通过编辑系统的启动脚本来实现: 创建一个新的启动脚本:创建一个新的脚本文件,并将其放置在 /etc/init.d/ 目…...

千里科技“AI+车”加速度:2025年营收增长42%、净利翻倍、新业务突破
A股上市公司重庆千里科技股份有限公司(以下简称“千里科技”)今日发布2025年年度报告,公司收入、利润双增长,“AI车”商业化实现突破。报告期内,全年实现营业收入99.99亿元,同比增长42.13%;归母…...

健康赛道又一个爆款玩法:华一拼团+公排返利,到底怎么做?
大家好,我一家电商软件开发公司的负责人。现在健康赛道那可真是遍地黄金,躺赚的机会说来就来啦!你是不是一直苦于找不到能落地、还能高盈利的模式系统?今天我就给大家分享2026爆火的模式——华一健康模式系统,它直接照…...
核心知识点)
Elasticsearch(ES)核心知识点
Elasticsearch(ES)核心知识点1. 核心概念 Document:文档,一条数据(JSON)Field:字段,文档里的属性Index:索引,相当于数据库的“库/表”Type:类型&a…...

RC4算法逆向实战:从特征识别到魔改对抗
1. RC4算法基础与逆向特征识别 RC4算法作为经典的流加密算法,在CTF竞赛和恶意软件分析中频繁出现。我第一次逆向分析RC4加密的样本时,花了整整三天才确认算法类型——因为当时的我还不熟悉它的特征指纹。现在回头看,识别标准RC4其实有明确的规…...

10:2026 AI变现实战总览:内容、工具、信息差三种变现闭环
作者: HOS(安全风信子) 日期: 2026-04-01 主要来源平台: GitHub 摘要: 提前剧透12大模块如何串联成3条可复制的赚钱路径。本文构建内容变现2.0闭环全图(Agentic生成)、工具/SaaS变现闭环全图(Ag…...

3款轻量级替代方案:华硕笔记本硬件控制工具深度解析
3款轻量级替代方案:华硕笔记本硬件控制工具深度解析 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar…...
)
苍穹外卖day10(黑马程序员)
苍穹外卖 day10 笔记 WebSocket 什么是 WebSocket WebSocket 是一种全双工的网络通信方式:客户端和服务器建立连接之后,双方都可以随时主动给对方发消息,不必像传统网页那样「每次都要重新发起一次请求」。 可以把它理解成: HTTP&…...

WaveTools:解决鸣潮玩家性能优化与数据管理痛点的开源工具
WaveTools:解决鸣潮玩家性能优化与数据管理痛点的开源工具 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools是一款专为《鸣潮》PC玩家设计的开源辅助工具,集成性能优化、账…...

覆盖更远、组网更稳:基于 EFR32BG21 的智能家居与物联网 BLE Mesh 无线模块方案
智能家居与物联网设备越来越多,但真正决定体验上限的往往不是“有没有连上网”,而是信号能不能到、掉线后能不能自愈、多设备同时在线是否还稳定。单靠点对点蓝牙,很容易在隔墙、远距离、多节点场景里碰到瓶颈;而把低功耗蓝牙与 M…...

ESP-01s固件烧录与Arduino编程:从接线玄学到一键下载的避坑指南
1. ESP-01s模块入门:为什么你的接线总是出错? 第一次接触ESP-01s的朋友,十有八九会在烧录固件或上传程序时遇到各种莫名其妙的失败。我见过太多人把模块插上CH340就以为万事大吉,结果在电脑前折腾一整天都搞不定下载。这其实是因为…...