数据加载工具pg_bulkload插件的介绍
瀚高数据库
目录
环境
文档用途
详细信息
环境
系统平台:Linux x86-64 Red Hat Enterprise Linux 7
版本:12
文档用途
本文档主要介绍pg_bulkload插件的安装与使用。
详细信息
研发公司:NTT OSS Center DBMS Development and Support Team,与pg_rman出自相同开发者
license协议:BSD
一、pg_bulkload安装
有从源码安装和rpm安装两种方式,这里仅采用README.md中给出的源码安装。
1.安装前提:提前安装好pg数据库并初始化数据目录。
此外,官方文档还给出了需求库:
PostgreSQL devel package : postgresqlxx-devel(RHEL), postgresql-server-dev-x.x(Ubuntu)PAM devel package : pam-devel(RHEL), libpam-devel(Ubuntu)Readline devel or libedit devel package : readline-devel or libedit-devel(RHEL), libreadline-dev or libedit-dev(Ubuntu)C compiler and build utility : "Development Tools" (RHEL), build-essential(Ubuntu)
2.安装步骤:
1)下载安装包:
git clone https://github.com/ossc-db/pg_bulkload.git[postgres@pg-bulkload opt]$ lltotal 19896drwxr-xr-x 11 postgres postgres 4096 Oct 27 15:28 pg_bulkload
2)进入目录并编译安装:
cd pg_bulkloadmakemake install
注意:编译时需要读取pg_config来获取pg的环境变量,使用root编译时需要环境变量里配上能找到pg_config的路径,也可以将目录的所有者更改为postgres再进行安装。
3)创建extension:
[postgres@pg-bulkload pg_bulkload]$ psql
psql (12.2)Type "help" for help.postgres=# CREATE EXTENSION pg_bulkload;CREATE EXTENSION
二、pg_bulkload使用
pg_bulkload有两种导入数据的方法,通过参数导入和通过控制文件导入。
创建要导入的测试数据
seq 100000| awk '{print $0"|postgres"}' > tbl_test_output.txt
文件内容
[postgres@pg-bulkload pg_bulkload]$ cat tbl_test_output.txt1|postgres2|postgres3|postgres4|postgres......99998|postgres99999|postgres100000|postgres
1.使用参数方式导入
1)创建测试表
postgres=# create table tbl_test(id int,name text);CREATE TABLE
2)导入命令语法
pg_bulkload -i [源数据] -O [目标表] -l [输出日志] -o [控制文件中的选项] -o [控制文件中的选项]-i 输入从中加载数据的源。与控制文件中的“ INPUT ”相同。-O 输出将数据加载到的目标。与控制文件中的“ OUTPUT ”相同。-l日志文件写入结果日志的路径。与控制文件中的“ LOGFILE ”相同。-P PARSE_BADFILE写入无法正确解析的坏记录的路径。与控制文件中的“ PARSE_BADFILE ”相同。-u DUPLICATE_BADFILE在索引重建期间写入与唯一约束冲突的坏记录的路径。与控制文件中的“ DUPLICATE_BADFILE ”相同。-o "key=val"控制文件中可用的任何选项,可传递多个选项。-d 数据库名指定要连接的数据库的名称。如果未指定,则从环境变量PGDATABASE中读取数据库名称。如果未设置,则使用为连接指定的用户名。-h 主机指定运行服务器的机器的主机名。如果该值以斜杠开头,则它用作Unix域套接字的目录。-p 端口指定服务器正在侦听连接的TCP端口或本地Unix域套接字文件扩展名。-U 用户名要连接的用户名。-W 密码强制pg_bulkload在连接到数据库之前提示输入密码。这个选项不是必需的,因为如果服务器要求密码认证,pg_bulkload会自动提示输入密码。但是,vacuumdb会浪费一次连接尝试服务器是否需要密码。在某些情况下,输入-W可以避免额外的连接尝试。-e发送到服务器的回显命令。-E从 DEBUG、INFO、NOTICE、WARNING、ERROR、LOG、FATAL 和PANIC中选择输出消息级别。默认值为INFO。
3)执行导入命令
[postgres@pg-bulkload pg_bulkload]$ pg_bulkload -i /usr/local/pgsql/data/pg_bulkload/tbl_test_output.txt -O tbl_test -l /usr/local/pgsql/data/pg_bulkload/tbl_test_output.log -o "TYPE=CSV" -o "DELIMITER=|"NOTICE: BULK LOAD STARTNOTICE: BULK LOAD END0 Rows skipped.100000 Rows successfully loaded.0 Rows not loaded due to parse errors.0 Rows not loaded due to duplicate errors.0 Rows replaced with new rows.
4)查看日志文件
[postgres@pg-bulkload pg_bulkload]$ cat tbl_test_output.logpg_bulkload 3.1.19 on 2021-10-27 16:25:42.045267+08INPUT = /usr/local/pgsql/data/pg_bulkload/tbl_test_output.txtPARSE_BADFILE = /usr/local/pgsql/data/pg_bulkload/20211027162542_postgres_public_tbl_test.prs.txtLOGFILE = /usr/local/pgsql/data/pg_bulkload/tbl_test_output.logLIMIT = INFINITEPARSE_ERRORS = 0CHECK_CONSTRAINTS = NOTYPE = CSVSKIP = 0DELIMITER = |QUOTE = "\""ESCAPE = "\""NULL =OUTPUT = public.tbl_testMULTI_PROCESS = NOVERBOSE = NOWRITER = DIRECTDUPLICATE_BADFILE = /usr/local/pgsql/data/pg_bulkload/20211027162542_postgres_public_tbl_test.dup.csvDUPLICATE_ERRORS = 0ON_DUPLICATE_KEEP = NEWTRUNCATE = NO0 Rows skipped.100000 Rows successfully loaded.0 Rows not loaded due to parse errors.0 Rows not loaded due to duplicate errors.0 Rows replaced with new rows.Run began on 2021-10-27 16:25:42.045267+08Run ended on 2021-10-27 16:25:42.098395+08CPU 0.00s/0.04u sec elapsed 0.05 sec
2.使用控制文件方式导入(csv格式)
1)创建控制文件
[postgres@pg-bulkload pg_bulkload]$ touch test1.ctl
2)控制文件内容
INPUT = /usr/local/pgsql/data/pg_bulkload/tbl_test_output.txt#要从中加载数据的源PARSE_BADFILE = /usr/local/pgsql/data/pg_bulkload/test1_bad.txt#写入无法正确解析的坏记录的路径LOGFILE = /usr/local/pgsql/data/pg_bulkload/test1_output.log#写入结果日志的路径LIMIT = INFINITE#要加载的行数PARSE_ERRORS = 0#在分析、编码检查、编码转换、筛选函数、检查约束检查、非空检查或数据类型转换期间引发错误的传入元组数。CHECK_CONSTRAINTS = NO#指定在加载过程中是否检查CHECK约束TYPE = CSV#输入数据的类型SKIP = 1000#跳过的输入行数DELIMITER = |#分隔文件每行中的列的单ASCII字符QUOTE = "\""#指定ASCII引号字符ESCAPE = "\""#指定应出现在QUOTE数据字符值之前的ASCII字符OUTPUT = public.tbl_test1#要将数据加载到的目标MULTI_PROCESS = NO#是否使用多线程并行对数据进行读取、解析和写入WRITER = DIRECT#加载数据的方法DUPLICATE_BADFILE = /usr/local/pgsql/data/pg_bulkload/test1.dup.csv#在索引重建期间写入与唯一约束冲突的坏记录的路径DUPLICATE_ERRORS = 0#违反唯一约束的传入元组数ON_DUPLICATE_KEEP = NEW#指定如何处理违反唯一约束的元组TRUNCATE = YES#指定是否清除目标表中的所有行
3)导入命令语法
pg_bulkload + 控制文件名称
4)新建表并插入一条数据
[postgres@pg-bulkload pg_bulkload]$ psql
psql (12.2)Type "help" for help.postgres=# create table tbl_test1(id int,name text);CREATE TABLEpostgres=# insert into tbl_test1 values (2021,'test');INSERT 0 1postgres=# select * from tbl_test1 ;id | name------+------2021 | test(1 row)
5)执行控制文件
[postgres@pg-bulkload pg_bulkload]$ vim test1.ctl
[postgres@pg-bulkload pg_bulkload]$ pg_bulkload ./test1.ctlNOTICE: BULK LOAD STARTNOTICE: BULK LOAD END1000 Rows skipped.99000 Rows successfully loaded.0 Rows not loaded due to parse errors.0 Rows not loaded due to duplicate errors.0 Rows replaced with new rows.
6)查询验证
postgres=# select * from tbl_test1 ;id | name--------+----------1001 | postgres1002 | postgres1003 | postgres1004 | postgres1005 | postgres1006 | postgres......postgres=# select * from tbl_test1 where id = 2021;id | name------+----------2021 | postgres(1 row)
通过上述结果可以看到,在控制文件中配置参数跳过前1000行并对表先进行truncate操作,导入数据时执行了文件中的配置。
有关具体的参数信息和控制文件可配内容选项,查阅官方文档
http://ossc-db.github.io/pg_bulkload/pg_bulkload.html
相关文章:

数据加载工具pg_bulkload插件的介绍
瀚高数据库 目录 环境 文档用途 详细信息 环境 系统平台:Linux x86-64 Red Hat Enterprise Linux 7 版本:12 文档用途 本文档主要介绍pg_bulkload插件的安装与使用。 详细信息 研发公司:NTT OSS Center DBMS Development and Support Team&…...

Windows禁止应用联网
转自两种方法阻止电脑上的软件彻底联网! - 知乎 (zhihu.com) 但为了稳妥,自己还是稍微记录一下 1、创建bat脚本文件 创建文本-将下面的代码填入-保存为.bat文件 Echo Off SetLocal:beginecho: echo ****** 禁止文件夹联网 ****** echo:set /p folder…...

zabbix邮件告警配置
一、报警 触发器的通知信息显示在web管理界面, 运维工程师仍然没办法24小时盯着它。所以我们希望它能自动地 通知工程师们,这就是报警。 zabbix的报警媒介支持email,jabber,sms(短信),微信,电话语音等。 报警过程原理 配置报警信息可以通过邮箱来实现 1、本地邮箱…...

代码随想录算法训练营第 35 天 | LeetCode 416. 分割等和子集
代码随想录算法训练营 Day35 代码随想录算法训练营第 35 天 | LeetCode 416. 分割等和子集 目录 代码随想录算法训练营前言LeetCode416. 分割等和子集 一、LeetCode416. 分割等和子集1.题目链接2.思路3.题解 前言 LeetCode416. 分割等和子集 讲解文档 一、LeetCode416. 分割…...

伪国企是指的什么?
伪国企,也称为虚假国企,主要指的是那些通过不正当手段,如伪造文件、虚假宣传等,误导公众或第三方,使其误认为该企业具有国有企业背景或实际控制权的非国有企业。 一、伪国企类型 具体来说,伪国企可能包括…...

Transformer在量化投资中的应用
开篇 深度学习的发展为我们创建下一代时间序列预测模型提供了强大的工具。深度人工神经网络,作为一种完全以数据驱动的方式学习时间动态的方法,特别适合寻找输入和输出之间复杂的非线性关系的挑战。最初,循环神经网络及其扩展的LSTM网络被设…...
a++ 和 ++a
由于后缀递增/递减运算符需要返回原始值,这可能导致编译器生成额外的代码来保存原始值,因此在某些情况下,前缀递增/递减可能更高效。在不涉及表达式结果的上下文中(例如,在单独的语句中),a和a的…...

Python配置文件格式——INI、JSON、YAML、XML、TOML
文章目录 对比INIJSONYAMLXMLTOML参考文献 对比 格式优点缺点是否支持注释INI简单易懂语言内置支持不支持复杂数据结构✓JSON支持复杂数据结构阅读起来不够直观YAML简洁有序支持复杂数据结构灵活但有歧义不同实现有兼容性问题✓XML支持复杂数据结构和命名空间语法冗长体积较大…...

The First项目报告:Web3人生模拟器,DegenReborn带你重开币圈
2023年6月14日,ReadON APP的首页上,一篇引人注目的文章《黑客马拉松奖:‘Degenreborn’——Meme与GameFi的梦幻交汇》跃然眼前,该文章巧妙融合了NFT、GameFi及Ethereum等热门话题,为读者带来了一场科技与娱乐的盛宴。 …...

燃气经营企业从业人员考试真题及答案
燃气经营企业从业人员考试真题及答案 11.《城镇燃气设计规范》中规定:当穿过卫生间、阁楼或壁柜时,燃气管道应采用()连接(金属软管不得有接头),并应设在钢套管内。 A.法兰 B.软管 C.焊接 D.丝扣 答案:…...

白骑士的Matlab教学进阶篇 2.1 数据可视化
系列目录 上一篇:白骑士的Matlab教学基础篇 1.5 数据输入与输出 数据可视化是MATLAB的一个强大功能,它能够将数据以图形的形式展示出来,便于理解和分析。本文将介绍MATLAB中的基本绘图函数、绘制2D图形、绘制3D图形以及高级图形属性与定制的…...

2024年8月 | 涉及侵权、抄袭洗稿违规行为公示
为护社区良好氛围,守护清朗网络空间,CSDN持续对侵害他人权益、抄袭洗稿违规内容进行治理。 今年7月,CSDN共计删除涉及抄袭洗稿内容xx篇,下架侵权资源xx个,封禁违规账号42个。 部分违规账号公示 账号昵称处置结果封禁创…...

操作系统快速入门(四)
😀前言 本篇博文是关于操作系统的,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以帮助到大家,您的满意是我的动力😉&…...

前缀异或优化
前言:这个题目其实就是考察前缀和,正常情况下开二维数组来记录,但是也可以优化成一位的位运算 我们顺便可以学习一下如何进行查询二进制串中1的个数 class Solution { public:vector<bool> canMakePaliQueries(string s, vector<vec…...

AI学习指南深度学习篇-卷积神经网络中的正则化和优化
AI学习指南深度学习篇-卷积神经网络中的正则化和优化 在深度学习领域,卷积神经网络(Convolutional Neural Networks,CNN)是一类非常重要的模型,被广泛应用于图像识别、目标检测等任务中。然而,在训练CNN时…...

AutoGen Studio 本地源码构建
目录 一、环境配置 1.1 创建本地环境 1.2 下载 autogen 源码 1.3 安装依赖 2. 构建 3. 运行 本文主要介绍 AutoGen Studio 本地源码构建过程。 一、环境配置 1.1 创建本地环境 通过 conda 创建一个环境,Python 3.10+,Node.js 14.15.0+。 conda create -n autogen p…...

医疗陪诊系统源码详解:在线问诊APP开发的技术要点
如今,开发一款高效、可靠的在线问诊APP则成为了许多企业的目标。本篇文章,小编将详细解析医疗陪诊系统的源码,并探讨在线问诊APP开发的关键技术要点。 一、医疗陪诊系统的基本功能 在开始开发之前,首先需要明确医疗陪诊系统的基本…...
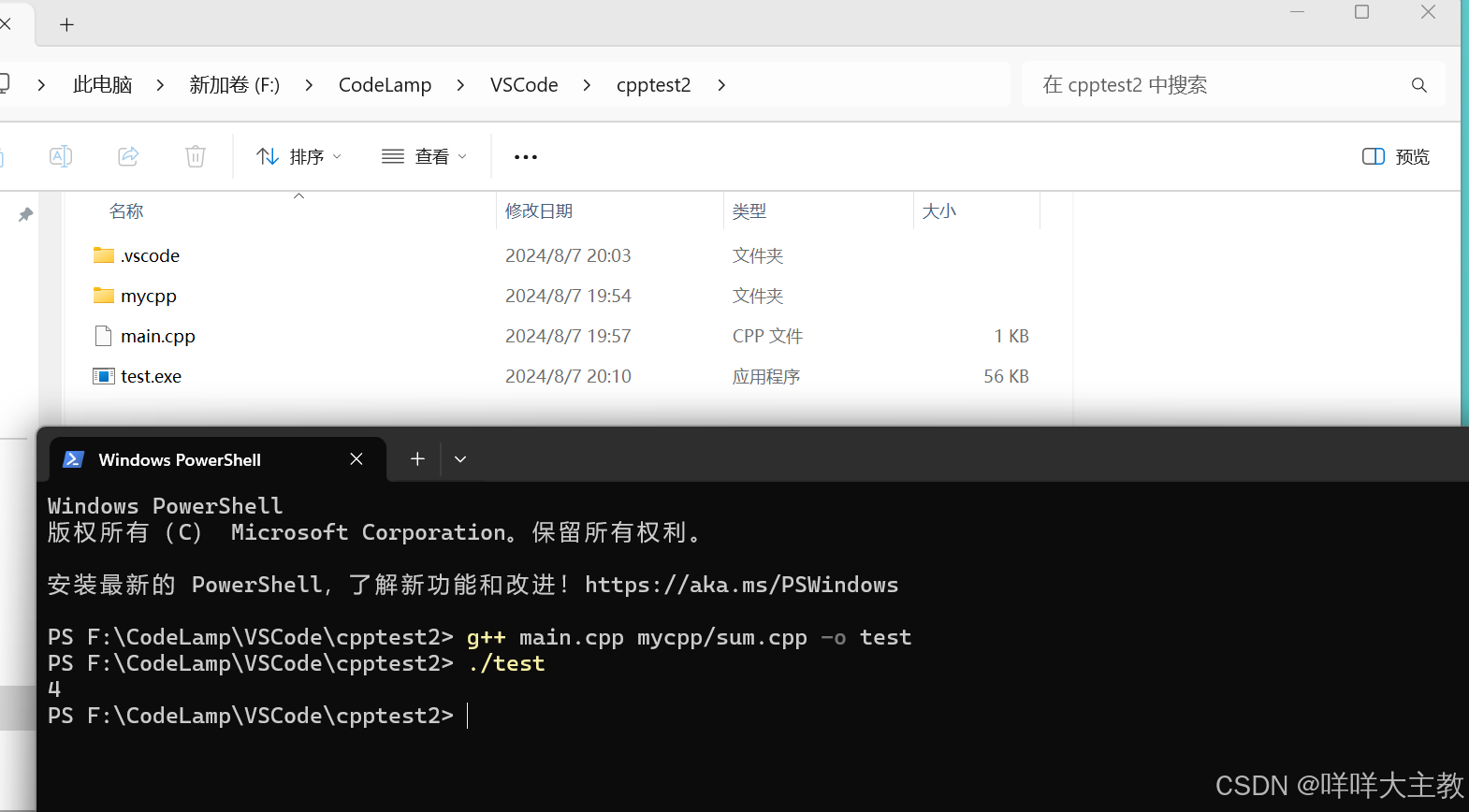
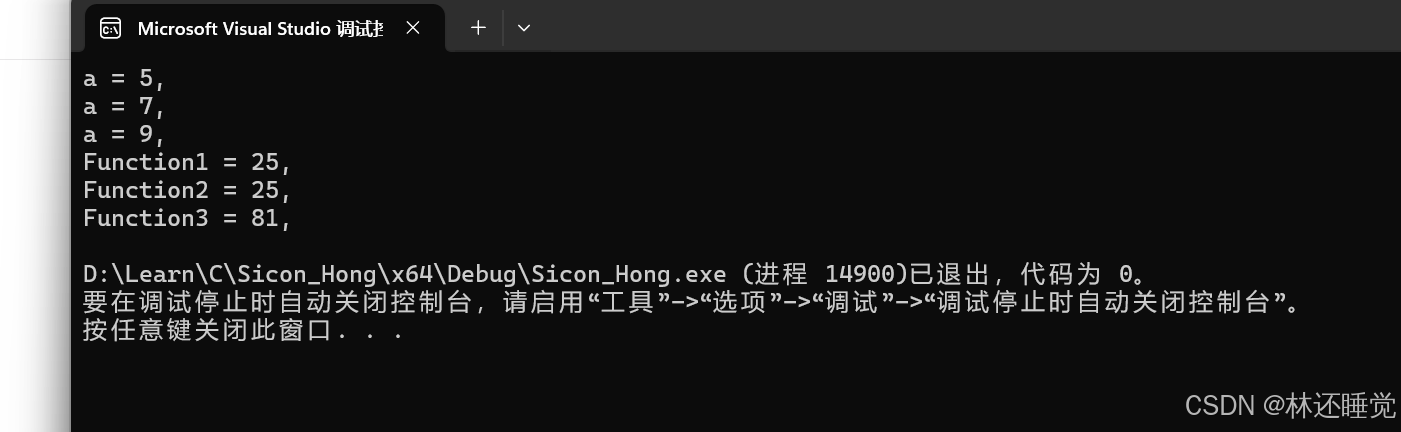
VSCode编译多个不同文件夹下的C++文件
实际上VSCode编译C文件就是通过向g传递参数实现的,因此即使是不同包下面的cpp文件或者.h文件都是可以通过修改g的编译参数实现,而在VSCode中,task.json文件其实就是在配置g的编译参数,因此我们可以通过修改task.json里面的参数&am…...
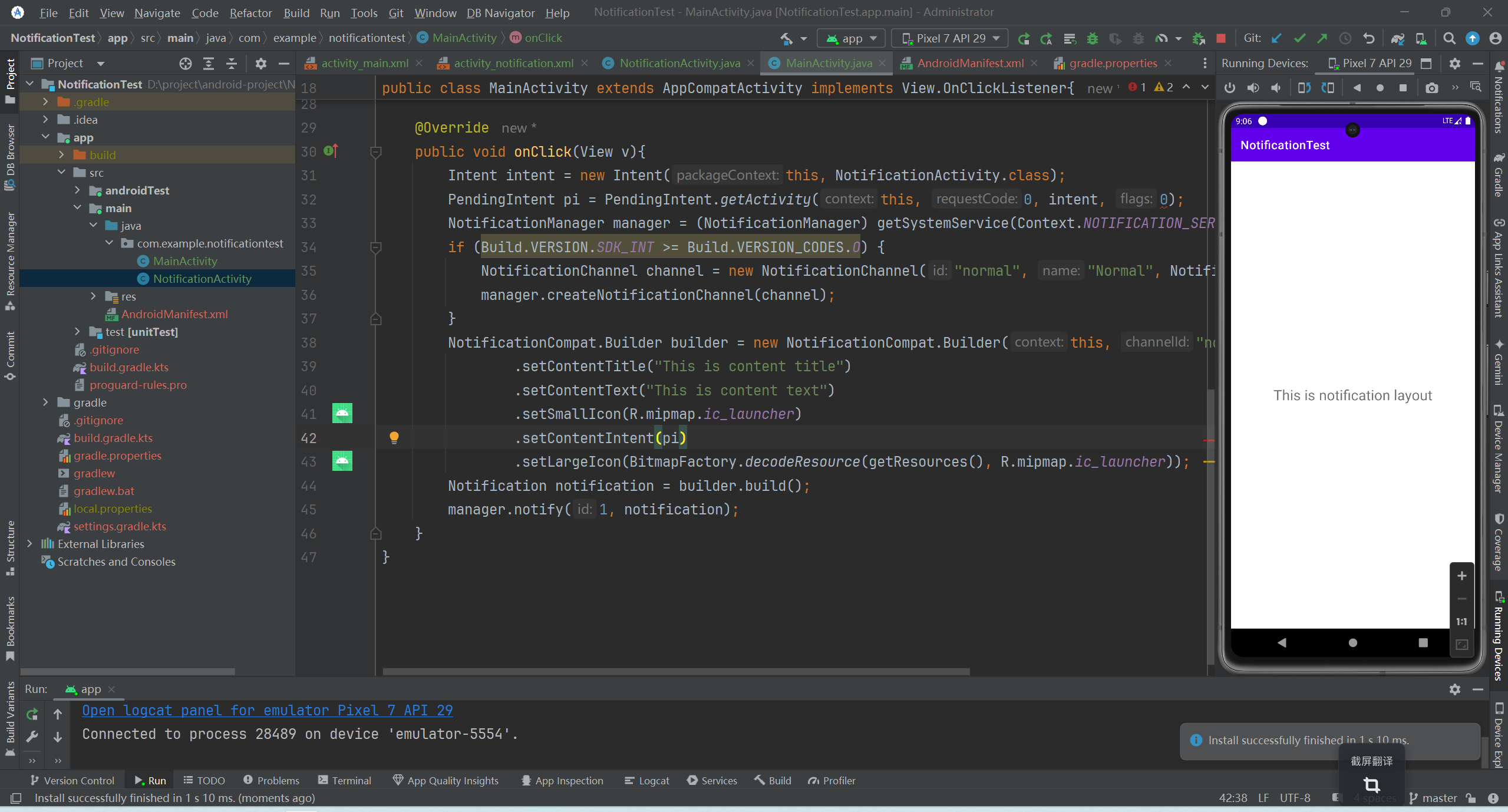
【安卓】连接真机和使用通知
文章目录 连接到真机使用通知通知的简单使用通知的详细信息 连接到真机 先用USB线将手机与电脑连接。 打开手机的设置,找到关于手机,点开之后,找到开发者选项界面。或者找到软件版本号,连续点击,系统会提示你点击几次能…...

CSS3下拉菜单实现
导航菜单: <nav class"multi_drop_menu"><!-- 一级开始 --><ul><li><a href"#">Power</a></li><li><a href"#">Money</a></li><li><a href"#"…...

2026年深圳冷冻食品包装盒代理,其中商机你知道多少?
在深圳这个充满活力与机遇的城市,冷冻食品市场一直呈现出稳步增长的态势。随着消费者对冷冻食品需求的不断增加,冷冻食品包装盒的市场需求也随之水涨船高。2026 年,深圳冷冻食品包装盒代理蕴含着巨大的商机。下面就为你详细剖析其中的商机以及…...

单线程 Redis 的高性能之道
引言Redis 以单线程模型处理网络请求与命令操作,却能在高并发场景下保持惊人的吞吐能力。这背后离不开三大基石:全内存存储、高效数据结构(哈希表、跳表等)以及 epoll 多路复用机制,让单线程能够高效处理海量连接。 随…...

ISO-SLAM-seq:全长 RNA代谢测序服务
ISO-SLAM-seq 技术,是 SLAM-seq 与 ISO-seq 的结合,通过研发成熟的核苷类似物 4-硫尿苷 (S4U) 代谢 RNA 标记方法和基于 Oxford Nanopore Technology 纳米孔测序平台或者 PacBio 的三代全长转录组测序方法,ISO-SLAM-seq 能检测整合到总 RNA 中…...

如何利用 SEO 工具提取网站的外部链接
如何利用 SEO 工具提取网站的外部链接 在当今竞争激烈的网络环境中,外部链接(即指向你网站的其他网站的链接)已经成为提升网站搜索引擎排名的重要因素。利用 SEO 工具提取网站的外部链接,不仅能帮助你更好地了解你的网站链接情况…...

终极指南:使用android-advancedrecyclerview实现状态保存的拖拽列表
终极指南:使用android-advancedrecyclerview实现状态保存的拖拽列表 【免费下载链接】android-advancedrecyclerview RecyclerView extension library which provides advanced features. (ex. Googles Inbox app like swiping, Play Music app like drag and drop …...

高校AIGC检测越来越严格背后的原因:政策趋势和学生应对建议
高校AIGC检测越来越严格背后的原因:政策趋势和学生应对建议 超过六成高校已经把AIGC检测纳入论文审查流程。但真正了解检测原理的人不到一成。 我判断:高校AIGC检测趋严这件事,大多数人的恐慌来自不了解。搞清楚原理,应对起来没…...
)
最好用的服务器文件传输工具:SSHFerry(下载见结尾)
为了 AutoDL 传文件更快更省心,我自己做了个 SSH 工作区:SSHFerry(下载见结尾) 之前我写过一篇和 AutoDL 上传有关的文章,没想到后面慢慢有了 1 万多阅读。 但那篇文章现在回头看,我觉得还是有点不够负责。…...

BetterGI:原神智能辅助系统 重新定义游戏体验
BetterGI:原神智能辅助系统 重新定义游戏体验 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音游 - UI Automa…...

口碑好的3D动画源头厂家哪家专业
咱做3D动画的时候,都想找个专业靠谱的源头厂家。毕竟质量有保障,价格也会更实惠。那么现在市场上口碑好的3D动画源头厂家都有哪些呢?今天就带大家好好分析一下,顺便给大家推荐一家我觉得超棒的厂家——玄熠数字视觉科技࿰…...

Graphormer模型架构深度解析:Positional Encoding如何编码分子图拓扑结构?
Graphormer模型架构深度解析:Positional Encoding如何编码分子图拓扑结构? 1. Graphormer模型概述 Graphormer是微软研究院开发的一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建…...