论文分享|MLLMs中多种模态(图像/视频/音频/语音)的tokenizer梳理
本文旨在对任意模态输入-任意模态输出 (X2X) 的LLM的编解码方式进行简单梳理,同时总结一些代表性工作。
注:图像代表Image,视频代表Video(不含声音),音频代表 Audio/Music,语音代表Speech
各种模态编解码方式梳理
文本
- 编码:和LLM一样,使用tokenizer与位置嵌入转换为输入Embedding,选择性利用Transformer Encoder进行处理
- 解码:和LLM一致,使用Transformer Decoder解码获取输出文本
图像
- 编码:使用Vision Transformer (ViT) 将图像分割为patch序列,利用Transformer处理得到编码。之后选择MLP/QFormer/VQ-VAE中一个合适的connector得到表征
- 解码:使用Diffusion模型利用LLM生成的语义token得到图像
视频
- 编码:从视频中抽出若干帧图像代表视频,利用图像编码方式得到每个帧的表征,并按照相对顺序拼接在一起放进输入序列中
- 解码:使用Diffusion模型利用LLM生成的语义token得到视频
音频/语音
- 编码:使用声学采样技术将音频/语音转换为离散的序列,利用Encoder编码,再利用RVQ量化技术得到最终的输入表征。
- 常用编码器:C-Former、HuBERT、BEATs 或 Whisper
- 解码:使用音频/语音Decoder或Diffusion模型解码LLM生成的语义token得到音频/语音
1.AnyGPT:文本,图像,语音,音频
论文标题:AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
来源:Arxiv2024/复旦
开源地址:https://github.com/OpenMOSS/AnyGPT
注:此部分参考了 老刘说NLP:多模态数据的tokenizer
编码:将各种模态的原始数据使用不同编码器编码,输入LLM得到语义token
解码:利用每个模态对应解码器将语义token解码为各种模态的原始数据。
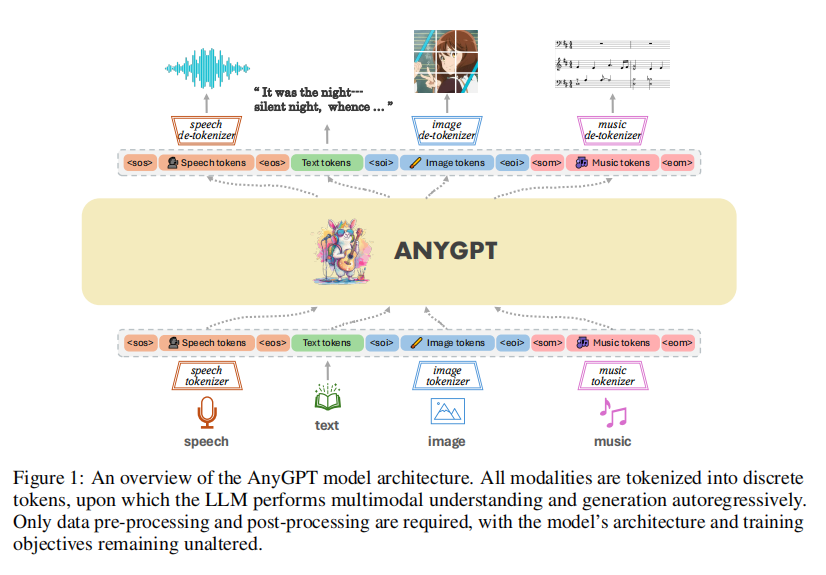
图像
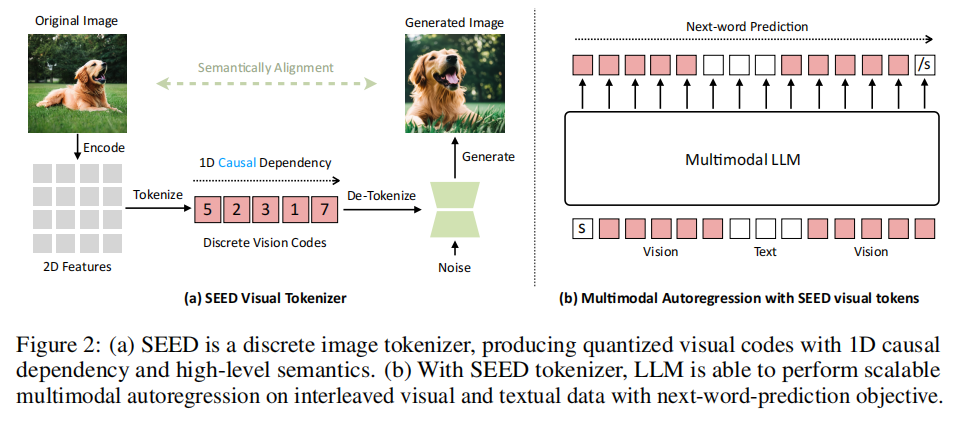
使用 seed-tokenizer (ICLR2024’腾讯)
图像编码:SEED分词器以224×224RGB图像作为输入;经过ViT转成16×16的Patches;再经过CausalQ-Former把Patch的特征转化成32个causal embeddings;再通过一个大小为8192的codebook将特征转化成量化代码序列;再通过MLP解码成生成嵌入。
图像解码:经过UNetdecoder变回原始图像。
ViT编码器和UNet解码器直接源自预训练的BLIP-2和unCLIP Stable Diffusion(unCLIP-SD)
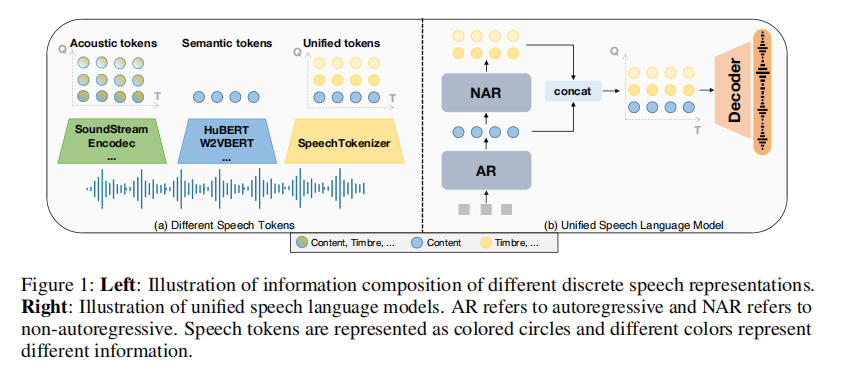
语音
使用 SpeechTokenizer (ICLR2024’复旦)
语音编码:使用8个分层量化器将单通道音频序列压缩为离散矩阵,每个量化器有1,024个条目,并实现50Hz的帧速率。第1个量化器层捕获语义内容,而第2层到第8层编码副语言细节,将10秒的音频转换为500×8的矩阵。
语音解码:使用专门训练的SoundStorm (Arxiv2023’Google)。将从SpeechTokenizer得到的语义 (semantic) tokens 转换为声学 (acoustic) tokens。 再利用SpeechTokenizer的Decoder将声学token转换为声音音频。
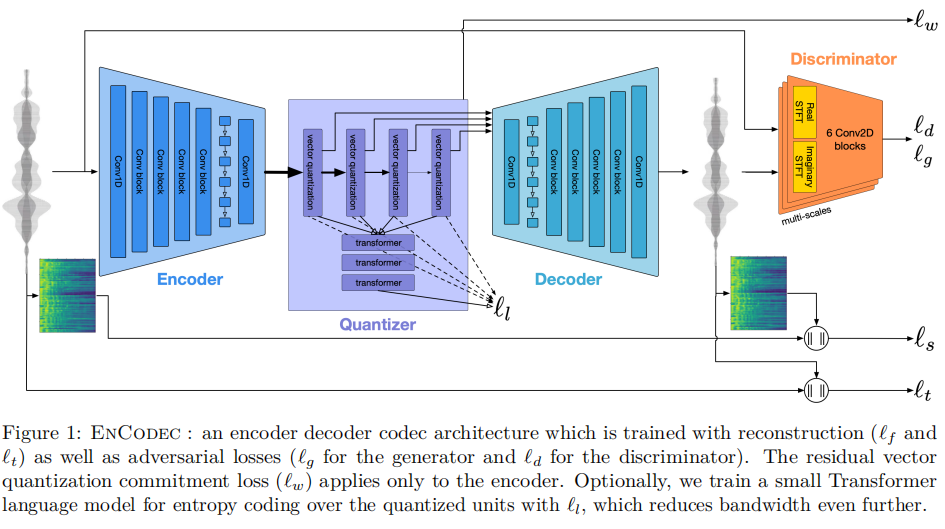
音频
使用 EnCodec (Arxiv2023’Meta)
音频编码:使用Encodec处理32kHz单音音频,实现50Hz的帧速率。生成的嵌入使用具有4个量化器的RVQ进行量化,每个量化器codebook的大小为2048,最终形成8192个组合音乐词表大小。
音频解码:使用Encodec token来过滤掉人类感知之外的高频音频细节,然后使用Encodec的解码器将这些token重建为高保真的音频数据。
2.NextGPT:文本,图像,视频,音频
论文标题:NExT-GPT: Any-to-Any Multimodal LLM
来源:ICML2024’Oral/NUS
开源地址:https://github.com/NExT-GPT/NExT-GPT
编码:使用ImageBind (CVPR2023’Meta) 对多种模态进行编码,经过一个统一的映射头转换为表征输入LLM。其中音频使用 AST (Interspeech2021’Google) 编码,再将2D编码视为图像用ViT进行处理.
解码:每种模态的语义表征先经过各自的映射头转换为新的表征,再利用不同模态的Diffusion模型进行解码得到生成的不同模态数据。其中图像使用 Stable Diffusion,视频使用 Zeroscope,音频使用 AudioLDM。
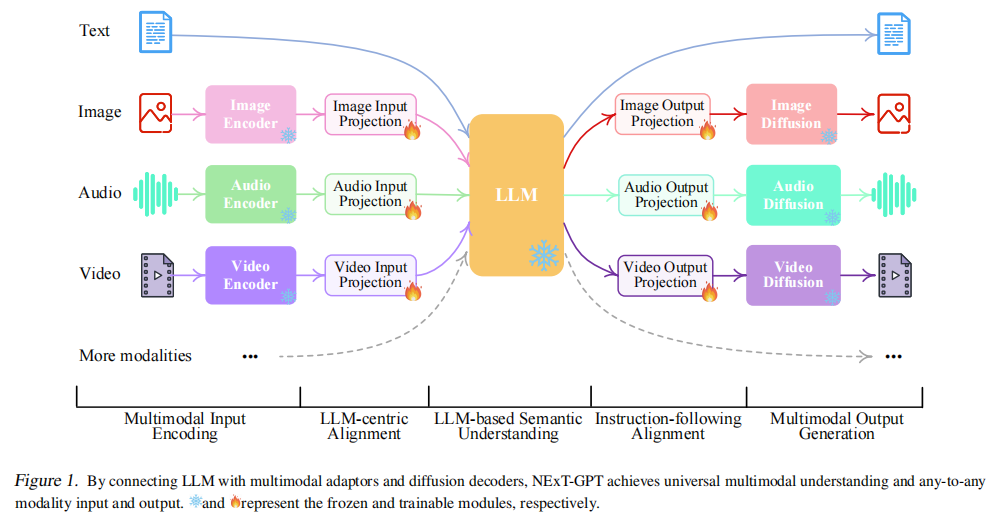

3.X-LLM:文本,图像,视频,语音
论文标题:X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
来源:Arxiv2023/中科院
开源地址:https://github.com/phellonchen/X-LLM
编码:利用Q-Former和Adapter将多种模态的Encoder得到的表征与LLM对齐。其中音频使用C-Former,即利用CIF模块将语音压缩采样,再经过Transformer得到表征。
解码:最后直接由LLM输出文本
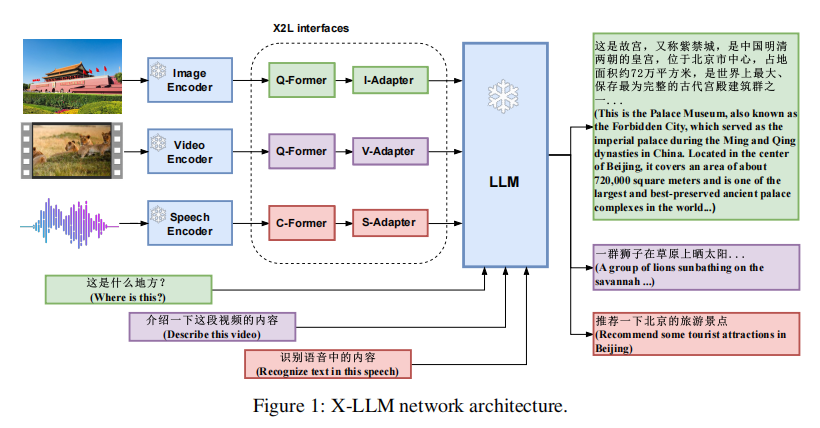
4.Audio-Video LLM:文本,视频,音频
论文标题:Audio-visual training for improved grounding in video-text LLMs
来源:PhroneticAI/Arxiv2024
编码:音频使用Whisper,视频使用sigLIP,分别过投射层转换为表征再拼接在一起
解码:LLM Decoder解码得到文本
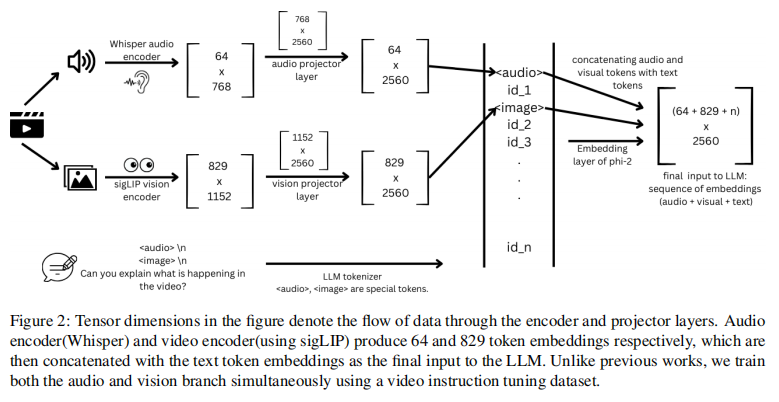
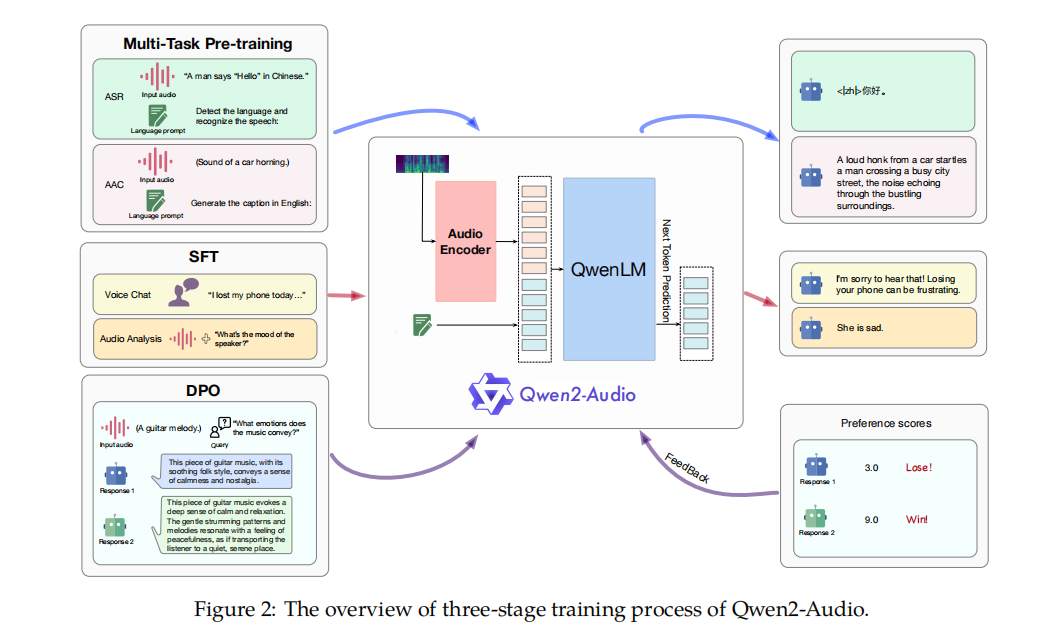
5.Qwen2-Audio: 文本,音频
论文标题:Qwen2-Audio Technical Report
来源:Arxiv2024/阿里
开源地址:https://github.com/QwenLM/Qwen2-Audio
编码:使用Whisper-large-v3进行编码
解码:生成文本
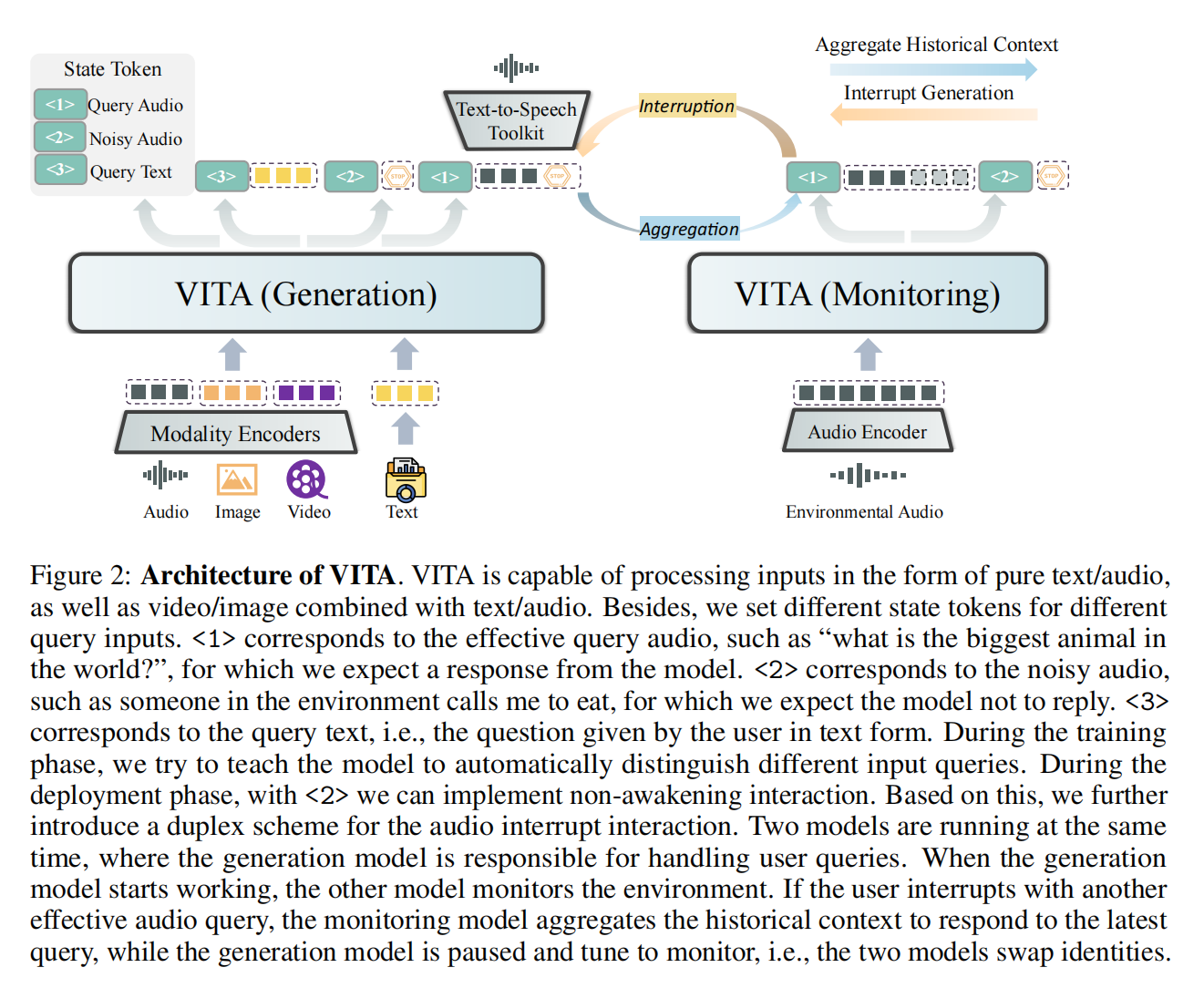
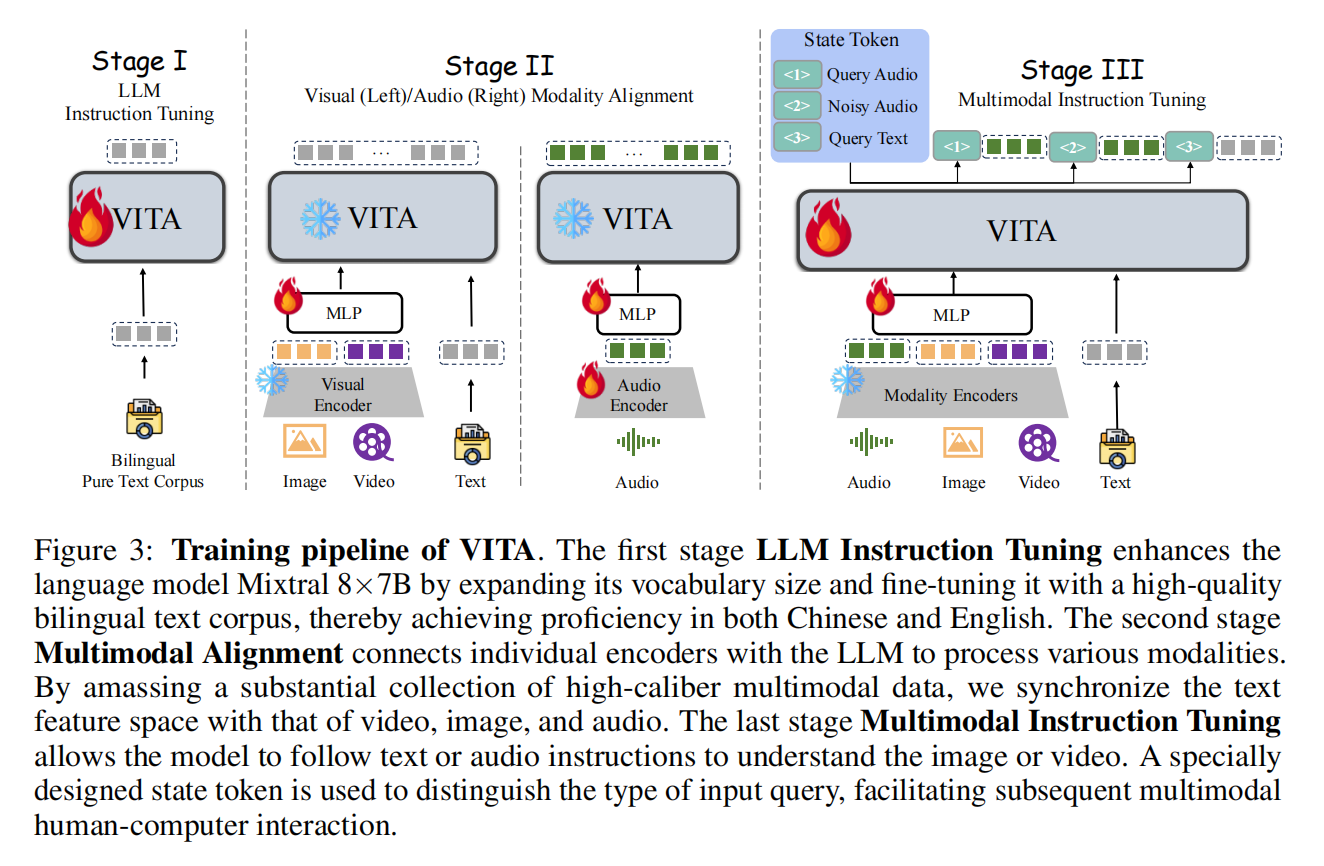
6.VITA:文本,图像,视频,音频
论文标题:VITA: Towards Open-Source Interactive Omni Multimodal LLM
来源:Arxiv2024/腾讯
开源地址:https://github.com/VITA-MLLM/VITA
注:参考了博客 VITA : 首个开源支持自然人机交互的全能多模态大语言模型
编码:图像使用 InternViT-300M-448px 编码。音频首先通过 Mel 频率滤波器块处理,该块将音频信号分解为 Mel 频率尺度上的各个频带,模拟人类对声音的非线性感知;之后使用 4 层 CNN 下采样层和 24 层的Transformer,共计 341M 参数,处理输入特征;再采用简单的两层 MLP 作为音频-文本模态连接器,最终,每 2 秒的音频输入被编码为 25 个词元。
解码:生成文本。再根据需求用TTS转换为语音。
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞或收藏支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索的知识,记得关注我!
相关文章:
论文分享|MLLMs中多种模态(图像/视频/音频/语音)的tokenizer梳理
本文旨在对任意模态输入-任意模态输出 (X2X) 的LLM的编解码方式进行简单梳理,同时总结一些代表性工作。 注:图像代表Image,视频代表Video(不含声音),音频代表 Audio/Music,语音代表Speech 各种…...

如何使用 Puppeteer 和 Node.JS 进行 Web 抓取?
什么是 Headlesschrome? Headless?是的,这意味着这个浏览器没有图形用户界面 (GUI)。不用鼠标或触摸设备与视觉元素交互,你需要使用命令行界面 (CLI) 来执行自动化操作。 Headlesschrome 和 Puppeteer 很多网页抓取工具都可适用…...

JDK 8 有哪些新特性?
JDK 8 引入了一系列新特性,主要包括: 1. 元空间替代了永久代 解决了永久代的内存管理、性能问题。提高了类加载器的隔离性。增强了可扩展性和跨平台性。提升了与垃圾收集器的兼容性。 因为 JDK8 要把 JRockit 虚拟机和 Hotspot 虚拟机融合,…...
C++ Win32API 贪吃蛇游戏
程序代码: #include <windows.h> #include <list> #include <ctime>// 定义游戏区域大小 const int width 20; const int height 20;// 定义贪吃蛇的方向 enum Direction { UP, DOWN, LEFT, RIGHT };// 定义贪吃蛇的节点 struct SnakeNode {in…...

【Python实现代码视频/视频转字符画/代码风格视频】
该程序改良自GitHub开源项目VideoCharDraw 在源程序CharDraw_thread.py 带压缩和多线程版本字符画的基础上使用Tkinter库添加了图形化的操作,使用户操作体验更方便。 什么是视频字符画? 视频转字符画是一种将视频中的每一帧图像转换为由字符组成的图…...
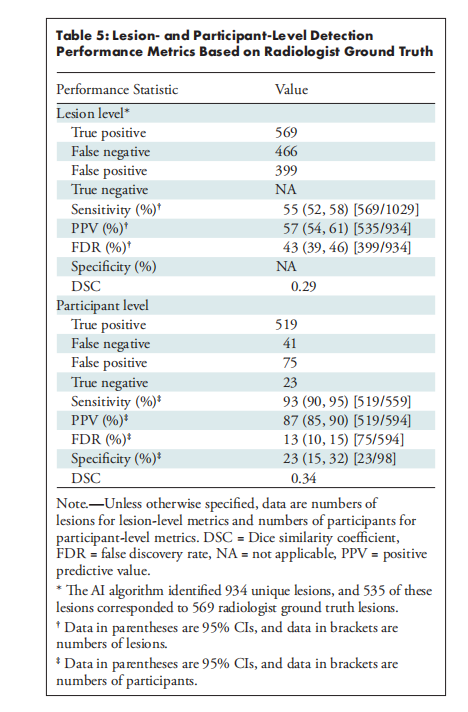
基于级联深度学习算法的前列腺病灶检测在双参数MRI中的评估| 文献速递-基于深度学习的乳房、前列腺疾病诊断系统
Title 题目 Evaluation of a Cascaded Deep Learning–based Algorithm for Prostate Lesion Detection at Biparametric MRI 基于级联深度学习算法的前列腺病灶检测在双参数MRI中的评估 Background 背景 Multiparametric MRI (mpMRI) improves prostate cancer (PCa) de…...
基于STM32开发的智能门铃系统
目录 引言环境准备工作 硬件准备软件安装与配置系统设计 系统架构硬件连接代码实现 初始化代码控制代码应用场景 家庭门铃系统智能社区门禁管理常见问题及解决方案 常见问题解决方案结论 1. 引言 智能门铃系统结合了传统门铃功能与现代技术,通过摄像头、麦克风、…...

【WebRTC指南】远程视频流
远程视频流使用入门 RTCPeerConnection 连接到远程对等设备后,就可以在它们之间流式传输音频和视频。此时,我们会将从 getUserMedia() 收到的数据流连接到 RTCPeerConnection。媒体流包含至少一个媒体轨道,当我们想将媒体传输到远程对等设备时,它们会分别添加到 RTCPeerCo…...

前端构建URL的几种方法比对,以及函数实现
当我们在前端开发中处理 URL 时,可能会用到字符串拼接、ES6 模板语法 (template literals) 或者使用 new URL() 构造函数。这三者各有优劣,适用于不同的场景。 1. 字符串拼接与 ES6 模板语法 字符串拼接 和 ES6 模板语法 都是将不同的字符串片段组合在…...

场外个股期权如何发出行权指令?
场外期权行权指令也就是平仓指令的意思,一般场外个股期权交易有三种方式开仓和行权平仓指令,分别是市价,限价和半小时询价,跟普通股票的买卖和交易方式类似,唯一区别是手动发出场外个股期权的行权指令,下文…...

AH8681锂电升压3.7升5V升12V 2A可支持QC2.0 3.0
135.3806.7573在探讨AH8681这款专为3.7V升压5V至12V,并具备2A输出能力,同时兼容QC2.0与QC3.0快充协议的升压芯片时,我们不得不深入其技术细节、应用场景、设计优势以及市场定位等多个维度,以全面理解其在现代电子设备中的重要作用…...
那些年我们一起遇到过的奇技淫巧
EVAL长度限制突破技巧 PHP Eval函数参数限制在16个字符的情况下 ,如何拿到Webshell? 写一段限制长度在小于17位的字符,拿下webshell <?php highlight_file(__FILE__); $param $_REQUEST[param]; if (strlen($param) < 17 &&am…...
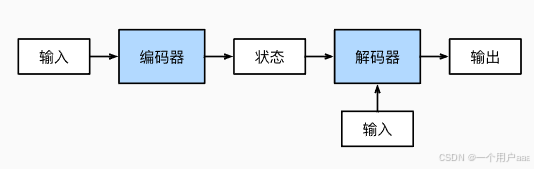
机器学习笔记:编码器与解码器
目录 介绍 组成结构 代码实现 编码器 解码器 合并编码器-解码器 思考 介绍 在机器翻译中,输入的序列与输出的序列经常是长度不相等的序列,此时,像自然语言处理这种直接使用循环神经网络或是门控循环单元的方法就行不通了。因此&#x…...

加密狗创新解决方案助力工业自动化
面临的挑战 早在1991年,COPA-DATA就认识到需要一个既能提供长期保护又能灵活应对的解决方案,以防止软件盗版并确保客户在各种复杂的工业环境下能够顺利使用其产品。这一解决方案不仅要兼容Windows系统,还必须在网络连接受限的情况下ÿ…...
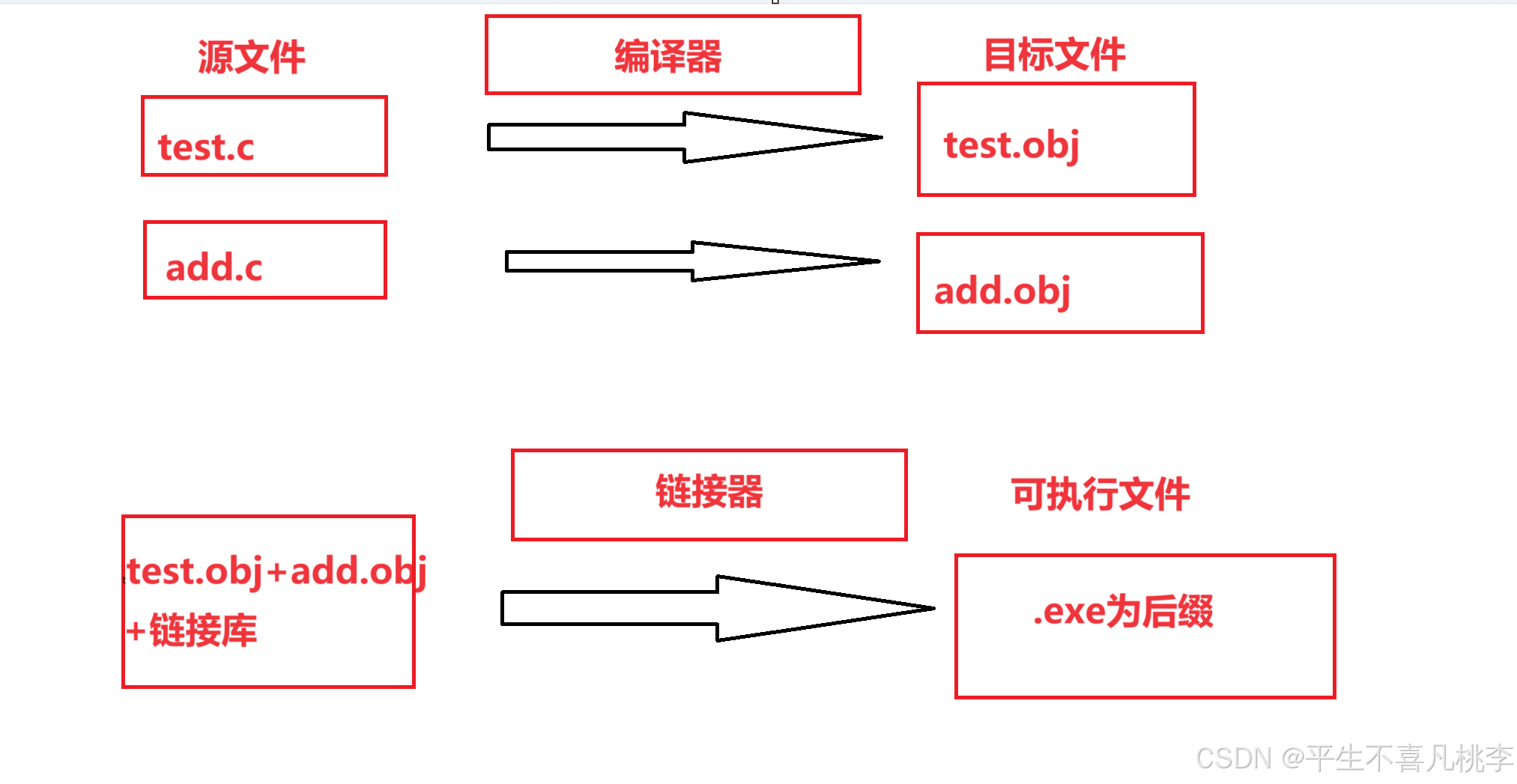
浅谈文件缓冲区和翻译环境
文章目录 1、文件缓冲区2、程序环境A、翻译过程概述B、详解编译和链接a、编译b、链接 1、文件缓冲区 ANSIC 标准采用”文件缓冲系统“处理数据文件,即在文件的读写过程中会使用到文件缓冲区,而文件缓冲区分为输入缓冲区和输出缓冲区。 读写文件 写文件…...
《腾讯NCNN框架的模型转换x86/mips交叉编译推理》详细教程
NCNN的编译运行交叉编译 1.在Ubuntu上编译运行ncnn1)编译ncnn x86 linux2)测试ncnn x86 linux 2. 模型转换1)onnx2)pnnx 3.在x86上加载推理模型1)准备工作2)编写C推理代码3)编写Cmakelist编译 4.在MIPS上进行交叉编译推理1&#x…...

关于近期安卓开发书籍阅读观后感
概述 由于笔者是Java转Android,对于安卓相关知识欠缺,故找一些入门和进阶书籍观看。笔者搜到的相关的安卓推荐博客:【Android – 学习】学习资料汇总_android书籍强烈推荐-CSDN博客相对来说比较全面。 阅读历程 笔者先阅读的是郭霖老师的…...
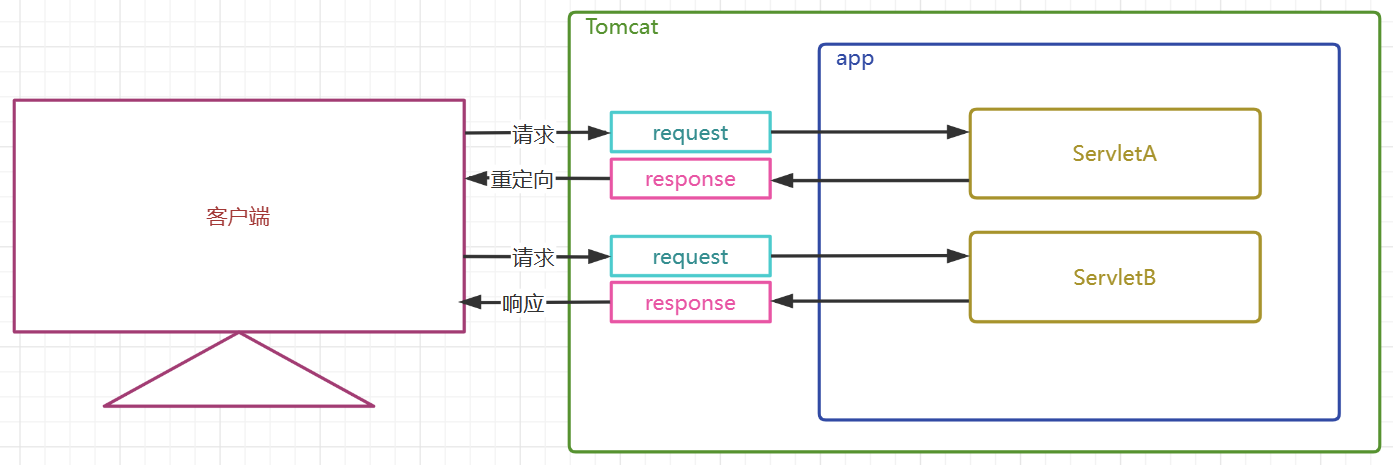
Servlet——个人笔记
Servlet——个人笔记 文章目录 [toc]Servlet简介Servlet命名Servlet由来实现过程 Servlet 相对 CGI 的优势简要说说什么是CGI Servlet 在IDEA中开发流程Servlet注解方式配置WebServlet注解源码WebServlet注解使用 Servlet常见容器Servlet 生命周期简介测试 Servlet 方法init()…...

富格林:戳穿虚假交易保证安全
富格林指出,虚假交易亏损骗局一直以来都是投资者的诟病。不少投资者来到这个赛道的目的铁定是为了安全盈利增值财富,因此如何去杜绝虚假交易便成了当务之急。实际上,有不少投资技巧可以为保障我们的交易安全带来一些庇护。下面富格林就给大家…...
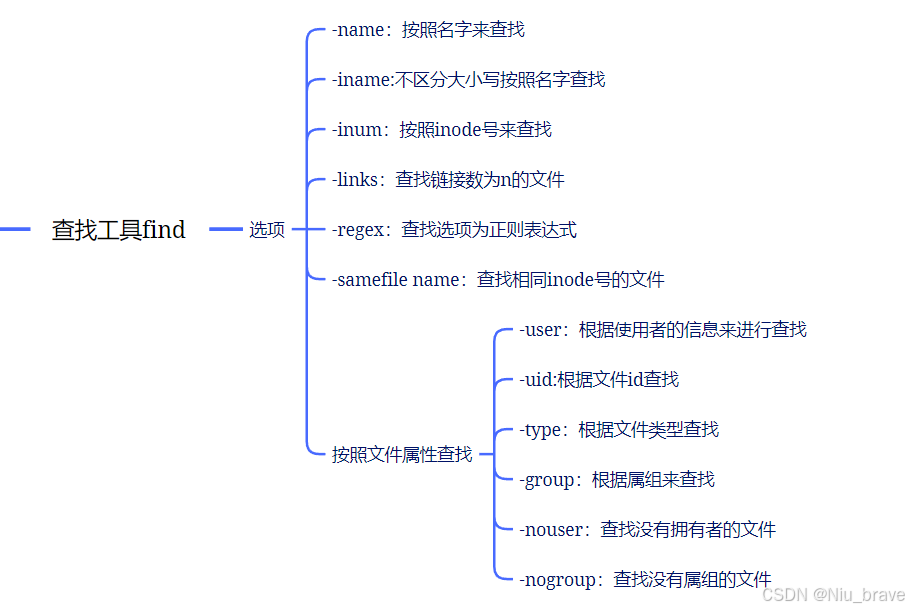
Linux学习——文本处理工具与正则表达式
目录 一,grep 1,grep介绍 2,grep的常用选项 3,grep使用演示 1,基本使用 直接查找字符串: 使用选项 2,使用正则表达式进行匹配 1,正则表达式介绍 2,使用范例 二&…...

AI智能体容器化开发实践:基于AgentBox构建安全可复现的沙盒环境
1. 项目概述:AgentBox,一个为AI智能体打造的“沙盒”开发环境最近在折腾AI智能体(Agent)的开发,发现一个挺有意思的现象:很多开发者,包括我自己在内,在初期搭建智能体应用时…...

从TPM到机密计算:远程证明技术原理与zap1项目实践指南
1. 项目概述与核心价值最近在整理一些零散的学习笔记时,发现了一个挺有意思的项目,叫Frontier-Compute/zap1-learning-attestation。乍一看这个标题,可能有点让人摸不着头脑,尤其是对于刚接触可信计算或者硬件安全领域的朋友来说。…...
)
中文长文本语音崩溃?ElevenLabs API超时/截断/静音突变?20年语音架构师紧急发布的6行容错重试+分段重对齐代码(已验证10万+字符稳定输出)
更多请点击: https://intelliparadigm.com 第一章:中文长文本语音崩溃的根因诊断与现象复现 中文长文本语音合成(TTS)在处理超长段落(如 >3000 字)时频繁出现进程中断、内存溢出或静音输出,…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

企业级后端四层架构实战:从理论到代码的清晰落地
1. 项目概述:一个四层架构的实战蓝图最近在GitHub上看到一个挺有意思的项目,叫BTawaifi/four-layer-system。光看名字,你可能会觉得这又是一个老生常谈的“四层架构”理论教程,无非是Controller、Service、Repository那套东西。但…...

ESP32-S2 Reverse TFT Feather开发板深度解析:从核心硬件到物联网项目实战
1. 项目概述:为什么选择ESP32-S2 Reverse TFT Feather?如果你正在寻找一款能让你快速搭建物联网设备原型,尤其是那些需要一块漂亮屏幕来交互或显示信息的项目,那么ESP32-S2 Reverse TFT Feather绝对是一个值得你花时间研究的开发板…...

基于Feather微控制器的智能灯光系统:颜色感应与BLE遥控实现
1. 项目概述与核心价值又到了折腾点节日氛围的时候了。往年都是买现成的彩灯串,总觉得少了点意思,今年决定自己动手,做个能“听懂”指令、甚至能“看见”颜色的智能灯光系统。这个项目的核心,就是用一块小小的微控制器,…...

ASPICE汽车软件开发标准:V模型、能力等级与核心过程实战解析
1. 项目概述:为什么我们需要ASPICE这张“汽车软件地图”如果你在汽车行业,尤其是涉及软件、电子电气或系统开发的岗位待过一阵子,大概率会频繁听到一个词:ASPICE。它可能出现在项目启动会上,出现在供应商审核清单里&am…...

2026年冰袋吸水粉厂家大揭秘:选择指南与行业趋势题
随着冷链物流行业的快速发展,冰袋吸水粉作为冷链运输中不可或缺的保冷材料,其市场需求持续增长。然而,市场上冰袋吸水粉的质量参差不齐,如何选择一家值得信赖的厂家成为许多采购商关注的重点。本文将从行业背景、技术特点及市场趋…...

量子优化算法在组合优化问题中的应用与性能分析
1. 量子优化算法与组合优化问题概述组合优化问题广泛存在于物流调度、网络设计、芯片布局等工业场景中,其核心挑战在于从离散解空间中高效寻找最优解。传统经典算法在面对NP难问题时往往面临计算复杂度爆炸的困境。量子优化算法通过量子叠加和纠缠等特性,…...