HAProxy 全解析:驾驭网络负载均衡与高可用的强大引擎
一、什么是HAproxy
HAProxy是一个免费、开源的高性能TCP/HTTP负载均衡器和代理服务器软件,主要用于实现以下功能
一、负载均衡
-
多种负载均衡算法支持:
- 轮询(Round Robin):它依次将请求均匀分配到后端的各个服务器。例如有服务器A、B、C,第一个请求会被分配到服务器A,第二个请求分配到服务器B,第三个请求分配到服务器C,然后再按照这个顺序循环。这样可以确保每个服务器都有机会处理请求,平均分担负载。
- 加权轮询(Weighted Round Robin):根据服务器的性能差异为每台服务器分配不同的权重。性能好的服务器权重高,会被分配更多请求。比如服务器A性能较强,权重设为3;服务器B性能中等,权重设为2;服务器C性能较弱,权重设为1。那么在一轮分配中,服务器A会分配到3个请求,服务器B会分配到2个请求,服务器C会分配到1个请求,然后再按照这个比例循环分配。这样可以更合理地利用服务器资源,让高性能服务器处理更多任务。
- 最少连接(Least Connections):该算法将新的请求分配给当前连接数最少的服务器。HAProxy会实时监测每台后端服务器的连接数,当有新的请求到来时,选择连接数最少的服务器进行分配。例如在某一时刻,服务器A当前连接数为10,服务器B当前连接数为8,服务器C当前连接数为12,当有一个新请求时,HAProxy会将请求分配给服务器B。这种算法适用于服务器处理请求的时间差异较大的情况,能够更有效地平衡服务器负载,避免某些服务器因连接过多而响应缓慢,同时充分利用连接数较少的服务器资源。
-
七层负载均衡(基于应用层):
- HAProxy能够分析应用层协议(如HTTP)的内容,根据不同的请求特征进行更精细的负载均衡。例如,它可以根据请求的URL路径将不同类型的请求分发到不同的后端服务器组。比如,对于网站的静态资源(如图片、CSS文件、JavaScript文件等)请求,可以将其分配到专门优化过处理静态资源的服务器组;而对于动态网页(如.php、.jsp等后缀的网页请求),可以分配到处理动态内容的服务器组。这样可以根据不同的应用需求进行更高效的资源分配,提高整个系统的性能和响应速度。
- 还可以根据HTTP请求头中的信息进行负载均衡。比如,根据用户的地理位置信息(通常在请求头中包含),将来自不同地区的用户请求分配到距离他们较近的数据中心的服务器上,减少网络延迟,提高用户体验。或者根据用户的浏览器类型、设备类型等信息进行针对性的负载均衡,为不同类型的客户端提供最佳的服务。
二、代理服务
-
正向代理:
- 在企业网络中,HAProxy可以作为正向代理服务器,为内部客户端访问外部网络提供代理服务。它可以缓存经常访问的外部网页内容,当内部客户端再次请求相同内容时,直接从缓存中返回,提高访问速度,减少网络带宽占用。同时,它可以对内部客户端的访问进行过滤和控制,例如限制访问某些不安全或不适当的网站,提高企业网络的安全性和合规性。
- 对于一些移动应用开发者,他们可以使用HAProxy作为正向代理来模拟不同的网络环境和测试应用在各种网络条件下的性能。通过配置HAProxy,可以模拟低速网络、高延迟网络等情况,以便在应用发布前发现和解决潜在的网络相关问题。
-
反向代理:
- 当用户访问一个网站时,他们实际上是与HAProxy进行通信,HAProxy再将请求转发到后端的真实Web服务器。对于用户来说,他们只看到HAProxy的IP地址,不知道后端具体有哪些服务器在处理请求。这样可以隐藏后端服务器的真实IP地址和架构,提高服务器的安全性,防止直接针对后端服务器的攻击。同时,HAProxy可以对后端服务器进行负载均衡,如前面所述的各种负载均衡算法,确保每个服务器都能合理分担用户请求,提高网站的整体性能和可靠性。
- HAProxy还可以对后端服务器返回的响应进行优化和处理。例如,对响应数据进行压缩,减少网络传输的数据量,提高响应速度;或者对响应内容进行修改,如添加统一的版权信息、错误处理页面等,提高网站的一致性和用户体验。
三、高可用性和可靠性
-
健康检查:
- HAProxy会定期对后端服务器进行健康检查,以确保它们能够正常处理请求。它可以通过多种方式进行检查,如发送简单的TCP连接请求或HTTP请求来验证服务器的可用性。如果发现某台服务器出现故障,如无法建立连接、响应超时或返回错误状态码等,HAProxy会自动将其从负载均衡池中移除,不再向其发送新的请求,直到该服务器恢复正常。这样可以避免将用户请求发送到故障服务器,保证用户能够始终得到正常的服务响应。
- 例如在一个电商网站的服务器集群中,HAProxy每隔5秒对后端的Web服务器进行一次健康检查。如果某台服务器在连续三次检查中都没有正常响应,HAProxy就会将其标记为故障服务器,并停止向其分配请求。当该服务器恢复正常并通过后续的健康检查时,HAProxy会再次将其加入到负载均衡池中,重新开始接收请求。
-
故障切换:
- 在配置了多个HAProxy实例的高可用架构中,如果主HAProxy实例出现故障,备用实例会自动接管服务,实现无缝的故障切换。例如,通过使用Keepalived等工具,可以实现HAProxy的高可用。当主HAProxy所在的服务器出现硬件故障、软件崩溃或网络问题时,Keepalived会检测到故障,并迅速将虚拟IP地址切换到备用HAProxy实例所在的服务器上,用户的请求会自动被导向备用HAProxy,从而保证负载均衡服务的不间断运行。
- 在后端服务器层面,如果一台服务器出现故障,HAProxy不仅会将其从负载均衡池中移除,还会在该服务器恢复正常后自动尝试重新将其加入到池中,实现故障服务器的自动恢复和重新纳入负载均衡体系,确保整个系统在面对服务器故障时具有良好的弹性和恢复能力
四、四层负载均衡和七层负载均衡的区别
一、工作层次
-
四层负载均衡:
- 工作在OSI模型的第四层,即传输层。它主要通过分析IP地址和端口号来决定如何分发网络流量。
- 例如,当一个客户端向服务器发起TCP连接请求时,四层负载均衡器会根据预先配置的策略,如轮询、加权轮询等,将请求转发到不同的后端服务器。它只关心数据包中的源IP地址、目标IP地址、源端口号和目标端口号这些信息,而不关心数据包的具体内容。
- 以一个简单的Web应用场景为例,假设有多个Web服务器提供相同的服务,客户端通过浏览器访问网站,四层负载均衡器接收到请求后,只根据TCP连接的相关信息将请求分发到不同的Web服务器,而不考虑请求是要获取具体哪个网页等更上层的信息。
-
七层负载均衡:
- 工作在OSI模型的第七层,即应用层。它能够深入分析应用层协议(如HTTP、HTTPS、FTP等)的内容,理解用户的具体请求。
- 例如,在HTTP协议中,七层负载均衡器可以根据请求的URL、HTTP方法(GET、POST等)、HTTP头部信息等进行更加精细的负载均衡。如果一个电商网站使用七层负载均衡,它可以根据用户请求的不同URL,将请求商品列表页面的请求分发到一组专门优化处理商品列表的服务器,将请求购物车页面的请求分发到另一组针对购物车操作优化的服务器。
- 七层负载均衡器还可以根据用户的会话信息进行负载均衡。比如,对于需要保持用户会话一致性的应用,它可以将属于同一个用户的连续请求都转发到同一台后端服务器,以确保用户会话状态的正确维护。
二、负载均衡策略
-
四层负载均衡策略:
- 主要基于网络层和传输层的信息制定策略。常见的策略有:
- 轮询(Round Robin):依次将客户端的连接请求均匀地分配到后端的不同服务器。例如,有三台服务器A、B、C,第一个连接请求分配给服务器A,第二个分配给服务器B,第三个分配给服务器C,然后第四个又重新分配给服务器A,如此循环。
- 加权轮询(Weighted Round Robin):根据服务器的性能差异为每台服务器分配不同的权重。性能好的服务器权重高,会分配到更多的连接请求。例如,服务器A权重为3,服务器B权重为2,服务器C权重为1,那么在一轮分配中,服务器A会分配到3个连接请求,服务器B会分配到2个连接请求,服务器C会分配到1个连接请求,然后再按照这个比例循环分配。
- 最少连接(Least Connections):将新的连接请求分配给当前连接数最少的服务器。负载均衡器会实时监测每台服务器的连接数,当有新的连接请求到来时,选择连接数最少的服务器进行分配。例如,服务器A当前连接数为10,服务器B当前连接数为8,服务器C当前连接数为12,当有一个新连接请求时,负载均衡器会将请求分配给服务器B。
- 主要基于网络层和传输层的信息制定策略。常见的策略有:
-
七层负载均衡策略:
- 由于可以分析应用层协议的内容,其策略更加丰富和灵活。除了类似四层的一些基本策略外,还有:
- 基于URL的负载均衡:根据请求的URL路径将不同类型的请求分发到不同的后端服务器组。比如,对于网站的静态资源(如图片、CSS文件、JavaScript文件等)请求,可以将其分配到专门优化过处理静态资源的服务器组;而对于动态网页(如.php、.jsp等后缀的网页请求),可以分配到处理动态内容的服务器组。
- 基于HTTP方法的负载均衡:对于不同的HTTP方法(如GET、POST、PUT、DELETE等)进行不同的负载均衡处理。例如,对于频繁的GET请求(如获取网页内容)可以分配到一组性能较好的缓存服务器,而对于相对较少但可能涉及数据更新的POST请求(如提交表单数据)可以分配到专门的数据库更新服务器组。
- 基于HTTP头部信息的负载均衡:根据HTTP请求头部中的信息进行负载均衡。比如,根据用户的地理位置信息(通常在请求头中包含),将来自不同地区的用户请求分配到距离他们较近的数据中心的服务器上,减少网络延迟,提高用户体验。或者根据用户的浏览器类型、设备类型等信息进行针对性的负载均衡,为不同类型的客户端提供最佳的服务。
- 由于可以分析应用层协议的内容,其策略更加丰富和灵活。除了类似四层的一些基本策略外,还有:
三、对应用的影响
-
四层负载均衡对应用的透明性:
- 四层负载均衡对应用是相对透明的。它不需要对应用程序本身进行修改,只需要将应用服务器的IP地址和端口配置到负载均衡器上,负载均衡器就可以根据策略将请求分发到不同的服务器。
- 例如,对于一个已经部署好的Web应用,无论它是使用Java开发的Tomcat服务器,还是使用Python开发的Flask服务器,只要将这些服务器的IP地址和端口告知四层负载均衡器,负载均衡器就可以正常工作,应用程序无需做任何关于负载均衡的代码修改。
- 这种透明性使得四层负载均衡在一些对应用程序改动有限制或希望快速部署负载均衡的场景下非常方便,不会因为引入负载均衡而对应用程序的开发和维护带来过多的复杂性。
-
七层负载均衡对应用的定制性:
- 七层负载均衡可以根据应用层的具体信息进行更精细的控制和优化,因此它可以更好地适应应用的需求,但同时也可能需要对应用程序进行一定的配合和调整。
- 例如,为了实现基于用户会话的负载均衡(即将同一个用户的请求始终分发到同一台服务器),应用程序可能需要在HTTP请求中添加一些特定的标识信息,以便七层负载均衡器能够识别和跟踪用户会话。或者在某些复杂的负载均衡策略下,应用程序可能需要按照负载均衡器的要求返回特定的状态码或响应头信息,以便负载均衡器进行更准确的决策。
- 虽然这种对应用程序的调整增加了一些复杂性,但它也为应用提供了更多的优化和定制空间。比如通过七层负载均衡可以更好地实现应用的高可用性、优化资源分配以及针对不同用户群体提供个性化的服务等。
四、性能和资源消耗
-
四层负载均衡的性能优势和资源消耗情况:
- 四层负载均衡通常具有较高的性能,因为它的工作在相对较低的层次,只需要分析和处理较少的网络数据包信息,对数据包的处理相对简单和快速。
- 它的资源消耗相对较低,因为不需要像七层负载均衡那样深入解析应用层协议的内容。这使得四层负载均衡器能够处理大量的并发连接请求,适用于对性能要求较高、网络流量较大的场景。例如,在一些大型的在线游戏服务器集群中,四层负载均衡器可以快速地将玩家的连接请求分发到不同的游戏服务器,保证游戏的低延迟和高并发处理能力。
- 然而,四层负载均衡的简单性也导致了它在某些功能上的局限性,无法像七层负载均衡那样提供丰富的负载均衡策略和对应用的精细控制。
-
七层负载均衡的性能和资源消耗特点:
- 七层负载均衡由于需要深入分析应用层协议的内容,对数据包的处理更加复杂,因此相对四层负载均衡来说性能会稍低一些,并且资源消耗也会相对较高。
- 当处理大量并发请求时,七层负载均衡器可能需要更多的计算资源和内存来解析和处理应用层协议。例如,在一个繁忙的电商网站中,七层负载均衡器在分析大量的HTTP请求的URL、头部信息等内容时,可能会占用较多的CPU和内存资源。
- 但是,七层负载均衡的这种性能和资源消耗是为了换取更丰富的功能和对应用的更精细控制。在一些对应用层功能和策略要求较高的场景下,如前面提到的根据用户请求内容进行智能分发、优化用户体验等,七层负载均衡的这些特性是非常有价值的。
五、HAproyx实验环境的部署
企业版网站:HAProxy Technologies | World's Fastest Load Balancer
社区版网站:HAProxy - 可靠、高性能。TCP/HTTP 负载均衡器
github: HAProxy · GitHub
四台虚拟机
测试:172.25.254.128
haproxy:172.25.254.129
webserver1:172.25.254.160
webserver2:172.25.254.161
两台webserver安装nginx

写入发布文件并测试
[root@localhost ~]# echo webserver1 - 172.25.254.160> /usr/share/nginx/html/index.html
[root@localhost ~]# echo webserver2 - 172.25.254.161 >/usr/share/nginx/html/index.html

安装软件

六、HAproxy基本配置信息
HAProxy的配置文件haproxy.cfg由两大部分组成,分别是:
global:全局配置段
进程及安全配置相关的参数
性能调整相关参数
Debug参数proxies:代理配置段
defaults:为frontend, backend,listen提供默认配置
frontend:前端,相当于nginx中的server{}
backend:后端,相当于nginx中的upstream 0
listen:同时拥有前端和后端配置,配置简单,生产推荐使用
前端和后端分开写
[root@localhost ~]# vim /etc/haproxy/haproxy.cfg

[root@localhost ~]# systemctl enable haproxy.service --now
检测

后端检测
[root@localhost ~]# systemctl stop nginx.service

前端和后端合并

检测

七、HAproxy的全局配置及日志分离
一、daemon
-
参数说明:
- 这个参数用于设置HAProxy是否以守护进程(Daemon)模式运行。
- 在守护进程模式下,HAProxy会在后台运行,不会与终端关联。这意味着即使启动HAProxy的终端关闭,HAProxy也会继续运行,不会受到影响。
-
示例配置:
daemon:- 当设置为
true时,HAProxy将以守护进程模式运行。默认情况下,它是false,即不以守护进程模式运行。
二、maxconn
-
参数说明:
- 用于定义HAProxy能够处理的最大并发连接数。
- 它限制了同时连接到HAProxy的客户端数量,包括所有的前端(frontend)监听端口的连接总和。
-
示例配置:
maxconn 65535:- 这里将最大并发连接数设置为65535。这个值需要根据服务器的硬件资源(如内存、CPU等)以及预期的负载情况来合理调整。如果设置得过高,可能会导致服务器资源耗尽;如果设置得过低,可能会限制系统的处理能力,导致客户端连接被拒绝。
三、pidfile
-
参数说明:
- 指定HAProxy进程的PID(进程ID)文件的路径。
- PID文件用于记录HAProxy运行时的进程ID,方便其他程序或脚本对HAProxy进程进行管理和监控。
-
示例配置:
pidfile /var/run/haproxy.pid:- 这里指定了PID文件的路径为
/var/run/haproxy.pid。当HAProxy启动时,它会将自己的进程ID写入这个文件,当需要停止、重启或查询HAProxy进程状态时,可以通过读取这个文件获取进程ID。
四、user和group
-
参数说明:
user用于指定运行HAProxy进程的用户。group用于指定运行HAProxy进程的用户组。- 这两个参数主要用于安全和权限管理。通过将HAProxy运行在一个特定的用户和用户组下,可以限制HAProxy对系统资源的访问权限,提高系统的安全性。
-
示例配置:
user haproxy:group haproxy:- 这里将HAProxy进程的运行用户和用户组都设置为
haproxy(假设系统中存在这个用户和用户组)。如果不进行这样的设置,HAProxy可能会以默认的较高权限用户运行,可能会带来安全风险。
五、log
-
参数说明:
- 用于配置HAProxy的日志相关设置。
- 它可以指定日志的输出位置、日志级别等。
-
示例配置:
log 127.0.0.1 local0 info:- 这里指定将日志发送到IP地址为127.0.0.1(本地)的
local0日志设备,日志级别为info。日志级别可以根据需要调整,常见的日志级别还有debug(调试,最详细)、warning(警告)、error(错误)等。不同的日志级别会记录不同详细程度的信息,info级别通常会记录一些重要的运行状态和事件信息。
六、stats socket
-
参数说明:
- 用于设置HAProxy的统计信息套接字(socket)路径。
- 通过这个套接字,可以获取HAProxy的实时运行状态和统计信息,如当前的连接数、吞吐量、后端服务器的健康状态等。
-
示例配置:
stats socket /var/lib/haproxy/stats:- 这里指定了统计信息套接字的路径为
/var/lib/haproxy/stats。可以通过相应的工具或脚本连接到这个套接字来获取HAProxy的统计信息,以便进行监控和分析。
七、nbproc
-
参数说明:
- 用于指定HAProxy启动的进程数量。
- 在一些高负载的场景下,通过启动多个HAProxy进程可以提高系统的处理能力和性能。每个进程可以独立地处理连接请求。
-
示例配置:
nbproc 2:- 这里设置启动2个HAProxy进程。可以根据服务器的硬件资源(如CPU核心数等)和负载情况来调整这个值。但需要注意的是,启动多个进程也会消耗更多的系统资源,所以需要合理平衡。
多进程





多线程(多进程和多线程不能同时出现)


日志定义
[root@localhost ~]# vim /etc/haproxy/haproxy.cfg

[root@localhost ~]# vim /etc/rsyslog.conf
开启UDP协议


[root@localhost ~]# systemctl restart rsyslog.service
[root@localhost ~]# systemctl restart haproxy.service

八、HAproxy-proxies中的常用配置参数
| 参数 | 类型 | 作用 |
| defaults[] | proxies | 默认配置项,针对以下的frontend、backend和listen生效,可以多个name也可以没有name |
| frontend | proxies | 前端servername,类似于nginx的一个虚拟主机server和LVS服务集群 |
| listen | proxies | #将frontend和backend合并在一起配置,相对于frontend和backend配置更简洁,生产常用 |
proxies配置-defaults
| 参数 | 功能 |
| option abortonclose | 当服务器负载很高时,目自动结束掉当前队列处理比较久的连接,针对业务情况选择开启 |
| option redispatch | 当server ld对应的服务器挂掉后,强制定向到其他健康的服务器,重新派发 |
| option http-keep-alive | 开启与客户端的会话保持 |
| option forwardfor | 透传客户端真实IP至后端web服务器(在apache配置文件中加入:%{X-Forwarded-For}i 后在webserer中看日志即可看到地址透传信息) |
| mode http | tcp | 设置默认工作类型,使用TCP服务器性能更好,减少压力 |
| timeout http-keep-alive 120s | session 会话保持超时时间,此时间段内会转发到相同的后端服务器 |
| timeout connect 120s | 客户端请求从haproxy到后端server最长连接等待时间(TCP连接之前)默认单位ms |
| timeout server 600s | 客户端请求从haproxy到后端服务端的请求处理超时时长(TCP连接之后),默认单位ms,如果超时,会出现502错误,此值建议设置较大些,访止502错误 |
| timeout client 600s | 设置haproxy与客户端的最长非活动时间,默认单位ms,建议和timeout server相同 |
| timeout check 5s | 对后端服务器的默认检测超时时间 |
| default-server inter 1000 weight 3 | 指定后端服务器的默认设置 |
proxies配置-frontend
frontend配置参数:
proxies配置backend
定义一组后端服务器,backend服务器将被frontend进行调用。注意: backend 的名称必须唯一,并且必须在listen或frontend中事先定义才可以使用,否则服务无法启动mode http|tcp #指定负载协议类型,和对应的frontend必须一致option #配置选项server #定义后端real server,必须指定IP和端口
注意:option后面加 httpchk,smtpchk,mysql-check,pgsql-check,ssl-hello-chk方法,可用于实现更多应用层检测功能。server配置#针对一个server配置check #对指定real进行健康状态检查,如果不加此设置,默认不开启检查,只有check后面没有其它配置也可以启用检查功能#默认对相应的后端服务器IP和端口,利用TCP连接进行周期性健康性检查,注意必须指定端口才能实现健康性检查addr <IP> #可指定的健康状态监测IP,可以是专门的数据网段,减少业务网络的流量port <num> #指定的健康状态监测端口inter <num> #健康状态检查间隔时间,默认2000 msfall <num> #后端服务器从线上转为线下的检查的连续失效次数,默认为3rise <num> #后端服务器从下线恢复上线的检查的连续有效次数,默认为2weight <weight> #默认为1,最大值为256,0(状态为蓝色)表示不参与负载均衡,但仍接受持久连接backup #将后端服务器标记为备份状态,只在所有非备份主机down机时提供服务,类似SorryServerdisabled #将后端服务器标记为不可用状态,即维护状态,除了持久模式#将不再接受连接,状态为深黄色,优雅下线,不再接受新用户的请求redirect prefix http://www.baidu.com/ #将请求临时(302)重定向至其它URL,只适用于http模式maxconn <maxconn> #当前后端server的最大并发连接数
 [root@localhost ~]# vim /etc/httpd/conf/httpd.conf
[root@localhost ~]# vim /etc/httpd/conf/httpd.conf



[root@localhost ~]# vim /etc/haproxy/haproxy.cfg

[root@localhost ~]# systemctl restart haproxy.service

[root@localhost ~]# systemctl restart nginx.service

下线维护

[root@localhost ~]# systemctl restart haproxy.service
测试

上线

将请求临时(302)重定向至其它URL

[root@localhost ~]# systemctl restart haproxy.service

maxconn <maxconn> #当前后端server的最大并发连接数

九、HAproxy热处理

















十、HAproxy算法
静态算法
static-rr:基于权重的轮询调度


first


动态算法
roundrobin



leastconn


其他算法
source


map-base 取模法


一致性hash
- 哈希环首先依赖于一个哈希函数。这个哈希函数能够将任意的键(例如服务器的名称或标识符、数据的特征值等)映射为一个数值。然后,将这些数值看作是一个环上的点。
- 例如,使用一致性哈希算法时,通常将这个数值空间视为一个 0 到 2^32 - 1 的整数环(当然也可以是其他范围,但这个范围比较常见)。假设有服务器 A、B、C,通过哈希函数计算出它们对应的哈希值分别为 100、200、300,那么就在这个整数环上相应的位置标记这三个点,这样就构建了一个简单的哈希环。



URL(Uniform Resource Locator)、URI(Uniform Resource Identifier)和URN(Uniform Resource Name)是用于标识和定位网络资源的概念,它们之间有联系也有区别。
URL(统一资源定位符)
-
定义与组成:
- URL是一种具体的URI,用于描述网络上资源的位置。它包含了访问资源所需的所有信息,如协议、服务器地址、端口号、路径等。
- 例如,“Example Domain”就是一个典型的URL。其中,“https”是协议,表明使用的是安全超文本传输协议;“www.example.com”是服务器地址,用于定位资源所在的服务器;“/index.html”是路径,指示服务器上资源的具体位置。
-
作用与用途:
- 主要用于在网络上准确地定位和访问资源。通过URL,浏览器能够向服务器请求特定的网页、文件或其他数据资源。当用户在浏览器中输入一个URL时,浏览器会根据URL中的信息与相应的服务器建立连接,并请求指定的资源。
- 例如,当你在浏览器中输入上述URL时,浏览器会通过HTTPS协议与“www.example.com”服务器建立连接,然后请求获取“index.html”这个网页文件,服务器会将该文件的内容返回给浏览器,浏览器再将其展示给用户。
URI(统一资源标识符)
-
定义与范围:
- URI是一个更通用的概念,它是用来标识资源的字符串。URL是URI的一种具体形式,而URN是另一种形式的URI。URI的目的是为了唯一地标识一个资源,无论该资源位于何处,以及如何访问它。
- 例如,一个图书的ISBN号(国际标准书号)可以作为一个URI来标识一本书,即使这本书可能在不同的图书馆、书店或在线平台有不同的存储位置和获取方式,但通过ISBN这个URI可以唯一地确定这本书的身份。
-
结构与特点:
- URI通常由多个部分组成,尽管具体的结构可能因不同类型的URI而有所差异。一般来说,它至少包含一个用于标识资源类型的方案(scheme)部分。例如,在URL中,“https”就是方案部分,用于表明资源是通过超文本传输协议(HTTP)且是安全版本(S)来访问的。
- URI强调的是资源的标识,它不一定提供关于如何实际访问资源的详细信息(这与URL不同)。它更侧重于资源的唯一性和抽象标识,使得不同的系统和应用能够通过统一的方式来识别资源。
URN(统一资源名称)
-
定义与特点:
- URN也是URI的一种形式,它通过名称来标识资源,而不是通过资源的位置或访问方式(这与URL不同)。URN的设计目标是提供一种持久的、与位置无关的资源标识方法。
- 例如,“urn:isbn:978-3-16-148410-0”是一个URN,它使用“urn”方案来标识这是一个URN,“isbn”表示这是基于国际标准书号的资源标识,后面的字符串是具体的ISBN号码。无论这本书在网络上的存储位置如何变化,或者通过何种方式获取,这个URN都始终唯一地标识这本书。
-
用途与优势:
- URN的主要用途是在分布式系统中提供一种稳定的、长期有效的资源标识。在一些情况下,资源的实际位置可能会发生变化,但是通过URN可以始终准确地识别资源,而不需要依赖于具体的位置信息。这对于资源的管理、引用和长期保存非常重要。
- 例如,在数字图书馆系统中,对于一些珍贵的文献资源,使用URN可以确保即使资源的存储位置或访问方式发生改变,仍然可以通过URN准确地找到和引用该资源,而不会因为位置的变化导致资源无法被正确识别和访问。
uri



url_param


hdr



#静态static-rr--------->tcp/httpfirst------------->tcp/http#动态roundrobin-------->tcp/httpleastconn--------->tcp/http#以下静态和动态取决于hash_type是否consistentsource------------>tcp/httpUri--------------->httpurl_param--------->httphdr--------------->http
十一、HAproxy状态页
stats enable #基于默认的参数启用stats pagestats hide-version #将状态页中haproxy版本隐藏stats refresh <delay> #设定自动刷新时间间隔,默认不自动刷新stats uri <prefix> #自定义stats page uri,默认值:/haproxy?statsstats auth <user>:<passwd> #认证时的账号和密码,可定义多个用户,每行指定一个用户#默认:no authenticationstats admin { if | unless } <cond> #启用stats page中的管理功能



随便down掉一台服务器
[root@localhost ~]# systemctl stop nginx.service


十二、HAproxy基于cookie的会话保持
当客户端首次访问后端服务器时,后端服务器会在响应中设置一个特定的 cookie。HAProxy 会识别这个 cookie,并在后续的请求中,根据这个 cookie 的值将客户端的请求始终转发到同一台后端服务器上。这样就保证了属于同一个会话的请求都能被发送到同一台服务器处理,从而保持会话的一致性。

cookie name [ rewrite | insert | prefix ][ indirect ] [ nocache ][ postonly ] [preserve ][ httponly ] [ secure ][ domain ]* [ maxidle <idle> ][ maxlife ]name: #cookie 的 key名称,用于实现持久连接insert: #插入新的cookie,默认不插入cookieindirect: #如果客户端已经有cookie,则不会再发送cookie信息nocache: #当client和hapoxy之间有缓存服务器(如:CDN)时,不允许中间缓存器缓存cookie,#因为这会导致很多经过同一个CDN的请求都发送到同一台后端服务器



十三、HAproxy的ip透传
HAProxy 的 IP 透传(也称为 IP 地址传递或源 IP 保持)是一种重要的功能,它主要用于在负载均衡场景下确保后端服务器能够获取到客户端的真实 IP 地址。以下是关于 HAProxy IP 透传的详细内容:
一、为什么需要 IP 透传
在一些应用场景中,后端服务器需要知道客户端的真实 IP 地址,例如:
- 访问日志记录:准确记录客户端的 IP 以便进行分析和安全监控等。
- 基于 IP 的访问控制:某些应用可能根据客户端 IP 来限制或允许访问。
- 地理位置定位:根据 IP 确定客户端的地理位置,提供个性化的服务。
二、HAProxy 实现 IP 透传的原理
HAProxy 通常通过在 HTTP 头或 TCP 选项中传递客户端的 IP 地址信息到后端服务器来实现 IP 透传。具体有以下几种常见方式:
-
X-Forwarded-For方式:- HAProxy 在将客户端请求转发到后端服务器时,会在 HTTP 请求头中添加
X-Forwarded-For字段。 - 这个字段的值包含了客户端的 IP 地址,以及可能存在的经过的代理服务器的 IP 地址列表(按照顺序)。例如,如果客户端的 IP 是 192.168.1.100,经过了一个代理服务器 10.0.0.1,那么
X-Forwarded-For的值可能是“192.168.1.100, 10.0.0.1”。 - 后端服务器可以通过读取这个 HTTP 头字段来获取客户端的真实 IP 地址。
- HAProxy 在将客户端请求转发到后端服务器时,会在 HTTP 请求头中添加
-
PROXY Protocol方式(适用于 TCP 负载均衡):PROXY Protocol是一种专门用于在代理服务器和后端服务器之间传递连接信息(包括源 IP 和源端口、目标 IP 和目标端口)的协议。- HAProxy 支持发送和接收
PROXY Protocol信息。当 HAProxy 作为负载均衡器时,它可以在与后端服务器建立连接时,先发送PROXY Protocol头,将客户端的连接信息传递给后端服务器。 - 后端服务器需要支持
PROXY Protocol才能正确解析和处理这个信息,获取到客户端的真实 IP 地址和端口。
七层IP透传



[root@localhost ~]# cat /var/log/nginx/access.log


Apache默认没有设定

这里因为之前做过设定,所以直接出效果了

但是要在http的配置文件里加入%{X-Forwarded-For}i
[root@localhost ~]# vim /etc/httpd/conf/httpd.conf

四层IP透传




[root@localhost ~]# vim /etc/nginx/nginx.conf


十四、HAproxy访问控制列表
HAProxy 的访问控制列表(ACL,Access Control List)是一种强大的机制,用于根据不同的条件来控制对后端服务器的访问
- 基于 IP 地址的访问控制:可以限制或允许特定 IP 地址或 IP 地址范围的客户端访问。例如,只允许公司内部 IP 段的用户访问某些关键服务,而阻止外部未授权 IP 的访问。
- 基于 HTTP 请求特征的访问控制:根据 HTTP 方法(如 GET、POST 等)、请求的 URL 路径、HTTP 头部等条件来控制访问。比如,只允许特定的 HTTP 方法访问某个 API 端点,或者限制对某些敏感路径的访问。
- 流量管理和路由:结合 HAProxy 的其他功能,如负载均衡策略,可以根据 ACL 的结果将请求路由到不同的后端服务器群组。例如,将来自不同地区的用户请求路由到相应地区的服务器上。
#用acl来定义或声明一个aclacl <aclname> <criterion> [flags] [operator] [<value>]acl 名称 匹配规范 匹配模式 具体操作符 操作对象类型
























十五、HAproxy利用acl做动静分离等访问控制
基于域名访问



基于IP访问

拒绝访问

匹配浏览器类型

基于文件后缀名

十六、自定义错误页面内容
[root@localhost ~]# systemctl stop httpd.service
[root@localhost ~]# systemctl stop nginx.service




十七、HAproxy https

[root@localhost ~]# cat /etc/haproxy/certs/timingtc.pem



相关文章:
HAProxy 全解析:驾驭网络负载均衡与高可用的强大引擎
一、什么是HAproxy HAProxy是一个免费、开源的高性能TCP/HTTP负载均衡器和代理服务器软件,主要用于实现以下功能 一、负载均衡 多种负载均衡算法支持: 轮询(Round Robin):它依次将请求均匀分配到后端的各个服务器。例…...

陶瓷材质的防静电架空地板越来越受欢迎的原因
目前市面上的陶瓷防静电架空地板主要分为两种:钢基和硫酸钙基。前者是以全钢冲孔裸板作为板基,经粘接、固定整型和灌浆的方式加工而成,后者是以复合硫酸钙板为基材,表面粘接防静电陶瓷砖,四周导电PVC边条封边。近年来陶…...

Mariadb数据库本机无密码登录的问题解决
Mariadb数据库本机无密码登录的问题解决 安装了mariadb后,发现Mariadb本机无密码才能登录 百度了很多文章,发现很多人是因为root的plugin设置的值不正确导致的,unix_socket可以不需要密码,mysql_native_password 是正常的。 解…...
校园外卖平台小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,商家管理,菜品信息管理,菜品分类管理,购买菜品管理,订单信息管理,系统管理 微信端账号功能包括:系统首页&a…...

Python3 第八十一课 -- urllib
目录 一. 前言 二. urllib.request 三. urllib.error 四. urllib.parse 五. urllib.robotparser 一. 前言 Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。 本文主要介绍 Python3 的 urllib。 urllib 包 包含以下几个模块: url…...

Vue 3+Vite+Eectron从入门到实战系列之(五)一后台管理登录页
前面已经讲了不少基础知识,这篇开始,我们进行实操,做个后台管理系统,打包成多端的,可安装的桌面app!!其中,登录,退出的提示信息用系统的提示,不使用elemengplus的弹窗提示!ÿ…...

Docker 网络代理配置及防火墙设置指南
Docker 网络代理配置及防火墙设置指南 背景 在某些环境中,服务器无法直接访问外网,需要通过网络代理进行连接。虽然我们通常会在 /etc/environment 或 /etc/profile 等系统配置文件中直接配置代理,但 Docker 命令无法使用这些配置。例如&am…...

基于PostGIS(Postgres)+Node.js实现的xyz瓦片地图服务器
背景介绍 前两天研究GeoServer发布存储在PostGIS中栅格数据,最终目的是想在PostGIS中存储金字塔瓦片,用GeoServer发布,但是最后经过研究不改GeoServer源码的情况下,好像只支持将大图tif存在PostGIS数据库中进行发布,金…...

浙大数据结构慕课课后题(06-图3 六度空间)
题目要求: 输入格式: 输入第1行给出两个正整数,分别表示社交网络图的结点数N(1<N≤103,表示人数)、边数M(≤33N,表示社交关系数)。随后的M行对应M条边,每行给出一对正…...

Windows File Recovery卡在99%怎么解决?实用指南!
为什么会出现“Windows File Recovery卡在99%”的问题? Windows File Recovery(Windows文件恢复)是微软设计的命令行应用程序。它可以帮助用户从健康/损坏/格式化的存储设备中恢复已删除/丢失的文件。 通过输入相关命令,设置源/…...

数据结构之数组
写在前面 看下数组。 1:巴拉巴拉 数组是一种线性数据结构,使用连续的内存空间来存储数据,存储的数据要求有相同的数据类型,并且每个元素占用的内存空间相同。获取元素速度非常快,为O(1)常量时间复杂度,所…...

springboot集成sensitive-word实现敏感词过滤
文章目录 敏感词过滤方案一:正则表达式方案二:基于DFA算法的敏感词过滤工具框架-sensitive-wordspringboot集成sensitive-word步骤一:引入pom步骤二:自定义配置步骤三:自定义敏感词白名单步骤四:核心方法测…...

C++ 之动手写 Reactor 服务器模型(一):网络编程基础复习总结
基础 IP 地址可以在网络环境中唯一标识一台主机。 端口号可以在主机中唯一标识一个进程。 所以在网络环境中唯一标识一个进程可以使用 IP 地址与端口号 Port 。 字节序 TCP/IP协议规定,网络数据流应采用大端字节序。 大端:低地址存高位,…...

qt 在vs2022 报错记录
1,qt.network.ssl: QSslSocket::connectToHostEncrypted: TLS initialization failed 需要把SSL 相关的库加入进去,如ssleay32.dll,libeay32.dll。 2,在一个文件中已定义,编译器在链接时,在多处报 已在.*…...

【人工智能】TensorFlow和机器学习概述
一、TensorFlow概述 TensorFlow是由Google Brain团队开发的开源机器学习库,用于各种复杂的数学计算,特别是在深度学习领域。以下是对TensorFlow的详细概述: 1. 核心概念 张量(Tensor):TensorFlow中的基本…...

SQLALchemy 的介绍
SQLALchemy 的介绍 基本概述主要特点使用场景安装与配置安装 SQLAlchemy配置 SQLAlchemy示例:使用 SQLite 数据库连接到其他数据库 结论 总结 SQLAlchemy是Python编程语言下的一款开源软件,它提供了SQL工具包及对象关系映射(ORM)工…...
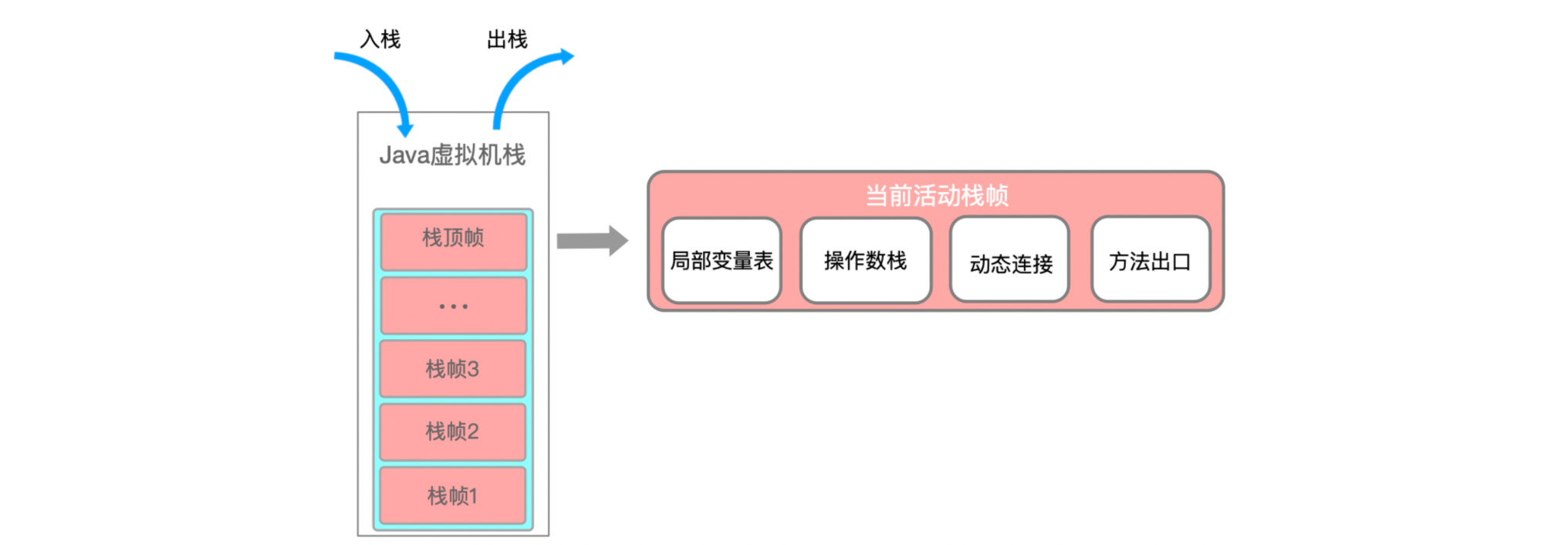
Java虚拟机:运行时内存结构
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 035 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...

微信小程序子组件调用父组件的方法
来源:通义千文2.5 步骤 1: 定义父组件中的方法 首先,在父组件中定义一个方法(如 handleClick),并准备一个用于接收子组件传来的数据的方法。 父组件(Parent.wxml) html<!-- parent.wxml …...

【数据结构】TreeMap和TreeSet
目录 前言TreeMap实现的接口内部类常用方法 TreeSet实现的接口常用方法 前言 Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。 一般把搜索的数据称为关键字(Key), 和关键字对应的称为…...

前端react集成OIDC
文章目录 OpenID Connect (OIDC)3种 授权模式 【服务端】express 集成OIDC【前端】react 集成OIDCoidc-client-js库 原生集成react-oidc-context 库非组件获取user信息 OAuth 2.0 协议主要用于资源授权。 OpenID Connect (OIDC) https://openid.net/specs/openid-connect-core…...

为什么92%的AI团队Serverless化失败?奇点大会披露的4个反直觉架构断点与实时熔断方案
更多请点击: https://intelliparadigm.com 第一章:AI原生Serverless实践:2026奇点智能技术大会无服务器架构 在2026奇点智能技术大会上,AI原生Serverless成为核心范式——它不再将模型推理简单托管于函数即服务(FaaS&…...

程序员转智能体开发,从入门到落地,看这一篇就够了
文章目录前言一、为什么2026年是转智能体开发的最佳时机1.1 市场需求爆炸式增长,薪资再创新高1.2 传统程序员转型有三大天然优势二、智能体开发到底是什么?和传统开发有什么区别?2.1 从"命令式"到"声明式"的思维转变2.2 …...

AI编程提效:用系统提示词实现测试驱动开发与可靠交付
1. 项目概述:一个为AI编程工作流设计的“系统指令集”如果你经常用Claude、Cursor或者ChatGPT来辅助写代码,大概率遇到过这种情况:AI助手给出的代码片段看起来能跑,但一放到项目里就各种报错;或者它自作主张地“优化”…...

泉盛UV-K5/K6固件深度定制指南:解锁专业级无线电功能
泉盛UV-K5/K6固件深度定制指南:解锁专业级无线电功能 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 你是否对原厂固件的功能限制感到…...

从干扰三要素到实战:辐射发射的工程化抑制与诊断方法
1. 项目概述:从一道周五小测题聊起辐射发射那天在EE Times上翻到一篇2014年的老文章,标题叫“Friday Quiz: Radiated Emissions”,作者是Martin Rowe。文章开头就抛出了一个非常基础,但又直击电磁兼容(EMC)…...

C++ 入门核心语法|从 Hello World 到基础特性一次性吃透
文章目录前言一、C 第一个程序:Hello World二、命名空间 namespace1. 为什么需要命名空间?2. 命名空间定义规则3. 三种使用方式三、C 输入 & 输出1. 核心对象2. 最大优势四、缺省参数(默认参数)1. 定义2. 使用方式3. 声明与定…...

开源数字白板the-board:基于React+Fabric.js的实时协作技术解析
1. 项目概述:一个开源的“数字白板”能做什么?最近在GitHub上看到一个挺有意思的项目,叫the-board。乍一看名字,可能觉得平平无奇,但点进去你会发现,它其实是一个功能相当完整的在线白板应用。简单来说&…...

电力系统网络安全:从风险认知到威胁建模的实战指南
1. 从日常运维到风险认知:重新审视大容量电力系统的安全基线在能源行业干了十几年,我见过太多同行把大容量电力系统(Bulk Energy System, BES)的运维简化为“确保别停电”。日常的告警处理、设备巡检、工单流转构成了工作的全部叙…...

非确定有限自动机—计算机等级考试—软件设计师考前备忘录—东方仙盟
1. 先明确:圆圈里的数字是什么?圆圈里的 0,1,2,3,4,5 是状态编号,不是输入符号,也不是要识别的字符串内容。比如 状态0 是起始状态,状态5 是终止(接受)状态。箭头边上的 0,1,ε 才是输入符号&am…...

独立语音AI创业必读,ElevenLabs Independent计划全链路解析:从白名单内测→额度扩容→月度用量审计→续期失败预警
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Independent计划的战略定位与生态价值 ElevenLabs Independent 计划并非单纯的技术授权项目,而是面向独立开发者、开源创作者与小型 AI 应用团队构建的可持续协作基础设施。其核…...