分析SQL的count(*)并优化
最近优化过几个慢查询接口的性能,总结了一些心得体会拿出来跟大家一起分享一下,希望对你会有所帮助。
我们使用的数据库是Mysql8,使用的存储引擎是Innodb。这次优化除了优化索引之外,更多的是在优化count(*)。
通常情况下,分页接口一般会查询两次数据库,第一次是获取具体数据,第二次是获取总的记录行数,然后把结果整合之后,再返回。
查询具体数据的sql,比如是这样的:`
select id,name from user limit 1,20;
它没有性能问题。
但另外一条使用count(*)查询总记录行数的sql,例如:
select count(*) from user;
却存在性能差的问题。
为什么会出现这种情况呢?
1 count(*)为什么性能差?
在Mysql中,count(*)的作用是统计表中记录的总行数。
而count(*)的性能跟存储引擎有直接关系,并非所有的存储引擎,count(*)的性能都很差。
在Mysql中使用最多的存储引擎是:innodb和myisam。
在myisam中会把总行数保存到磁盘上,使用count(*)时,只需要返回那个数据即可,无需额外的计算,所以执行效率很高。
而innodb则不同,由于它支持事务,有MVCC(即多版本并发控制)的存在,在同一个时间点的不同事务中,同一条查询sql,返回的记录行数可能是不确定的。
在innodb使用count(*)时,需要从存储引擎中一行行的读出数据,然后累加起来,所以执行效率很低。
如果表中数据量小还好,一旦表中数据量很大,innodb存储引擎使用count(*)统计数据时,性能就会很差。
2 如何优化count(*)性能?
从上面得知,既然count(*)存在性能问题,那么我们该如何优化呢?
我们可以从以下几个方面着手。
2.1 增加redis缓存
对于简单的count(*),比如:统计浏览总次数或者浏览总人数,我们可以直接将接口使用redis缓存起来,没必要实时统计。
当用户打开指定页面时,在缓存中每次都设置成count = count+1即可。
用户第一次访问页面时,redis中的count值设置成1。用户以后每访问一次页面,都让count加1,最后重新设置到redis中。
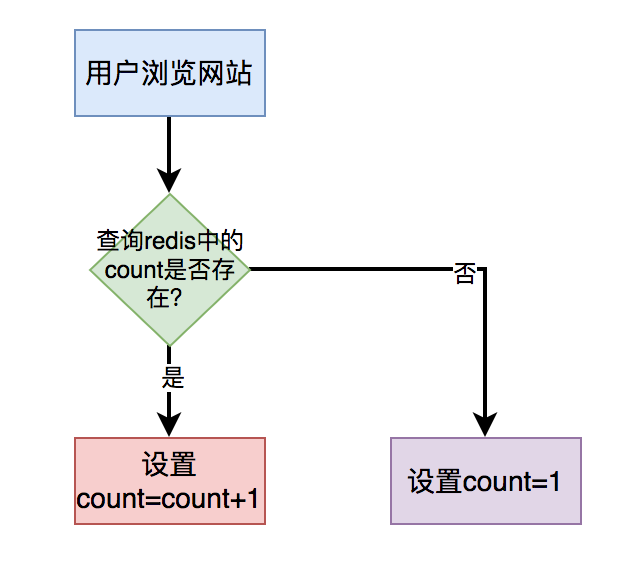
这样在需要展示数量的地方,从redis中查出count值返回即可。
该场景无需从数据埋点表中使用count(*)实时统计数据,性能将会得到极大的提升。
不过在高并发的情况下,可能会存在缓存和数据库的数据不一致的问题。
但对于统计浏览总次数或者浏览总人数这种业务场景,对数据的准确性要求并不高,容忍数据不一致的情况存在。
2.2 加二级缓存
对于有些业务场景,新增数据很少,大部分是统计数量操作,而且查询条件很多。这时候使用传统的count(*)实时统计数据,性能肯定不会好。
假如在页面中可以通过id、name、状态、时间、来源等,一个或多个条件,统计品牌数量。
这种情况下用户的组合条件比较多,增加联合索引也没用,用户可以选择其中一个或者多个查询条件,有时候联合索引也会失效,只能尽量满足用户使用频率最高的条件增加索引。
也就是有些组合条件可以走索引,有些组合条件没法走索引,这些没法走索引的场景,该如何优化呢?
答:使用二级缓存。
二级缓存其实就是内存缓存。
我们可以使用caffine或者guava实现二级缓存的功能。
目前SpringBoot已经集成了caffine,使用起来非常方便。
只需在需要增加二级缓存的查询方法中,使用@Cacheable注解即可。
@Cacheable(value = "brand", , keyGenerator = "cacheKeyGenerator")public BrandModel getBrand(Condition condition) {return getBrandByCondition(condition);}
然后自定义cacheKeyGenerator,用于指定缓存的key。
public class CacheKeyGenerator implements KeyGenerator {@Overridepublic Object generate(Object target, Method method, Object... params) {return target.getClass().getSimpleName() + UNDERLINE+ method.getName() + ","+ StringUtils.arrayToDelimitedString(params, ",");}
}
这个key是由各个条件组合而成。
这样通过某个条件组合查询出品牌的数据之后,会把结果缓存到内存中,设置过期时间为5分钟。
后面用户在5分钟内,使用相同的条件,重新查询数据时,可以直接从二级缓存中查出数据,直接返回了。
这样能够极大的提示count(*)的查询效率。
但是如果使用二级缓存,可能存在不同的服务器上,数据不一样的情况。我们需要根据实际业务场景来选择,没法适用于所有业务场景。
2.3 多线程执行
不知道你有没有做过这样的需求:统计有效订单有多少,无效订单有多少。
这种情况一般需要写两条sql,统计有效订单的sql如下:
select count(*) from order where status=1;
统计无效订单的sql如下:
select count(*) from order where status=0;
但如果在一个接口中,同步执行这两条sql效率会非常低。
这时候,可以改成成一条sql:
select count(*),status from order
group by status;
使用group by关键字分组统计相同status的数量,只会产生两条记录,一条记录是有效订单数量,另外一条记录是无效订单数量。
但有个问题:status字段只有1和0两个值,重复度很高,区分度非常低,不能走索引,会全表扫描,效率也不高。
还有其他的解决方案不?
答:使用多线程处理。
我们可以使用CompleteFuture使用两个线程异步调用统计有效订单的sql和统计无效订单的sql,最后汇总数据,这样能够提升查询接口的性能。
2.4 减少join的表
大部分的情况下,使用count(*)是为了实时统计总数量的。
但如果表本身的数据量不多,但join的表太多,也可能会影响count(*)的效率。
比如在查询商品信息时,需要根据商品名称、单位、品牌、分类等信息查询数据。
这时候写一条sql可以查出想要的数据,比如下面这样的:
select count(*)
from product p
inner join unit u on p.unit_id = u.id
inner join brand b on p.brand_id = b.id
inner join category c on p.category_id = c.id
where p.name='测试商品' and u.id=123 and b.id=124 and c.id=125;
使用product表去join了unit、brand和category这三张表。
其实这些查询条件,在product表中都能查询出数据,没必要join额外的表。
我们可以把sql改成这样:
select count(*)
from product
where name='测试商品' and unit_id=123 and brand_id=124 and category_id=125;
在count(*)时只查product单表即可,去掉多余的表join,让查询效率可以提升不少。
2.5 改成ClickHouse
有些时候,join的表实在太多,没法去掉多余的join,该怎么办呢?
比如上面的例子中,查询商品信息时,需要根据商品名称、单位名称、品牌名称、分类名称等信息查询数据。
这时候根据product单表是没法查询出数据的,必须要去join:unit、brand和category这三张表,这时候该如何优化呢?
答:可以将数据保存到ClickHouse。
ClickHouse是基于列存储的数据库,不支持事务,查询性能非常高,号称查询十几亿的数据,能够秒级返回。
为了避免对业务代码的嵌入性,可以使用Canal监听Mysql的binlog日志。当product表有数据新增时,需要同时查询出单位、品牌和分类的数据,生成一个新的结果集,保存到ClickHouse当中。
查询数据时,从ClickHouse当中查询,这样使用count(*)的查询效率能够提升N倍。
需要特别提醒一下:使用ClickHouse时,新增数据不要太频繁,尽量批量插入数据。
其实如果查询条件非常多,使用ClickHouse也不是特别合适,这时候可以改成ElasticSearch,不过它跟Mysql一样,存在深分页问题。
3 count的各种用法性能对比
既然说到count(*),就不能不说一下count家族的其他成员,比如:count(1)、count(id)、count(普通索引列)、count(未加索引列)。
那么它们有什么区别呢?
-
count(*) :它会获取所有行的数据,不做任何处理,行数加1。
-
count(1):它会获取所有行的数据,每行固定值1,也是行数加1。
-
count(id):id代表主键,它需要从所有行的数据中解析出id字段,其中id肯定都不为NULL,行数加1。
-
count(普通索引列):它需要从所有行的数据中解析出普通索引列,然后判断是否为NULL,如果不是NULL,则行数+1。
-
count(未加索引列):它会全表扫描获取所有数据,解析中未加索引列,然后判断是否为NULL,如果不是NULL,则行数+1。
由此,最后count的性能从高到低是:
count(*) ≈ count(1) > count(id) > count(普通索引列) > count(未加索引列)
所以,其实count(*)是最快的。
意不意外,惊不惊喜?S
相关文章:
分析SQL的count(*)并优化
最近优化过几个慢查询接口的性能,总结了一些心得体会拿出来跟大家一起分享一下,希望对你会有所帮助。 我们使用的数据库是Mysql8,使用的存储引擎是Innodb。这次优化除了优化索引之外,更多的是在优化count(*)。 通常情况下&#…...

Java学习日记(day18)
一、软件的结构 C/S (Client - Server 客户端-服务器端) 典型应用:QQ软件 ,飞秋,印象笔记。 特点: 必须下载特定的客户端程序。服务器端升级,客户端升级。 B/S (Broswer -Server 浏览器端- 服务器端&a…...
什么是外部表(External Table)?)
Oracle(61)什么是外部表(External Table)?
外部表(External Table)是Oracle数据库中的一种特殊表类型,用于访问存储在外部文件系统中的数据,而不需要将数据实际加载到数据库内部。外部表的主要优势在于允许数据库用户在不移动或复制数据的情况下,直接查询和处理…...
物联网HMI/网关搭载ARM+CODESYS实现软PLC+HMI一体化
物联网HMI/网关搭载CODESYS实现软PLCHMI一体化 硬件:ARM平台,支持STM32/全志T3/RK3568/树莓派等平台 软件:CODESYS V3.5、JMobile Studio CODESYS是一款功能强大的PLC软件编程工具,它支持IEC61131-3标准IL、ST、FBD、LD、CFC、…...

Java中Stream流
Java中Stream流 Stream 使用flatMap处理嵌套集合: 有一个对象列表,每个对象又包含一个列表,可以使用flatMap来“展平”这个结构。 List<List<String>> listOfLists Arrays.asList(Arrays.asList("a", "b"),Arrays.a…...

纯css实现多行文本右下角最后一行展示全部按钮
未展开全部: 展开全部: 综上演示按钮始终保持在最下方 css代码如下: <div class"info-content"><div class"info-text" :class"!showAll ? mle-hidden : "><span class"show-all"…...

WPF篇(17)-ListBox列表控件+ListView数据列表控件
ListBox列表控件 ListBox是一个列表控件,用于显示条目类的数据,默认每行只能显示一个内容项,当然,我们可以通过修改它的数据模板,来自定义每一行(元素)的数据外观,达到显示更多数据…...

HAProxy 全解析:驾驭网络负载均衡与高可用的强大引擎
一、什么是HAproxy HAProxy是一个免费、开源的高性能TCP/HTTP负载均衡器和代理服务器软件,主要用于实现以下功能 一、负载均衡 多种负载均衡算法支持: 轮询(Round Robin):它依次将请求均匀分配到后端的各个服务器。例…...

陶瓷材质的防静电架空地板越来越受欢迎的原因
目前市面上的陶瓷防静电架空地板主要分为两种:钢基和硫酸钙基。前者是以全钢冲孔裸板作为板基,经粘接、固定整型和灌浆的方式加工而成,后者是以复合硫酸钙板为基材,表面粘接防静电陶瓷砖,四周导电PVC边条封边。近年来陶…...

Mariadb数据库本机无密码登录的问题解决
Mariadb数据库本机无密码登录的问题解决 安装了mariadb后,发现Mariadb本机无密码才能登录 百度了很多文章,发现很多人是因为root的plugin设置的值不正确导致的,unix_socket可以不需要密码,mysql_native_password 是正常的。 解…...
校园外卖平台小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,商家管理,菜品信息管理,菜品分类管理,购买菜品管理,订单信息管理,系统管理 微信端账号功能包括:系统首页&a…...

Python3 第八十一课 -- urllib
目录 一. 前言 二. urllib.request 三. urllib.error 四. urllib.parse 五. urllib.robotparser 一. 前言 Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。 本文主要介绍 Python3 的 urllib。 urllib 包 包含以下几个模块: url…...

Vue 3+Vite+Eectron从入门到实战系列之(五)一后台管理登录页
前面已经讲了不少基础知识,这篇开始,我们进行实操,做个后台管理系统,打包成多端的,可安装的桌面app!!其中,登录,退出的提示信息用系统的提示,不使用elemengplus的弹窗提示!ÿ…...

Docker 网络代理配置及防火墙设置指南
Docker 网络代理配置及防火墙设置指南 背景 在某些环境中,服务器无法直接访问外网,需要通过网络代理进行连接。虽然我们通常会在 /etc/environment 或 /etc/profile 等系统配置文件中直接配置代理,但 Docker 命令无法使用这些配置。例如&am…...

基于PostGIS(Postgres)+Node.js实现的xyz瓦片地图服务器
背景介绍 前两天研究GeoServer发布存储在PostGIS中栅格数据,最终目的是想在PostGIS中存储金字塔瓦片,用GeoServer发布,但是最后经过研究不改GeoServer源码的情况下,好像只支持将大图tif存在PostGIS数据库中进行发布,金…...

浙大数据结构慕课课后题(06-图3 六度空间)
题目要求: 输入格式: 输入第1行给出两个正整数,分别表示社交网络图的结点数N(1<N≤103,表示人数)、边数M(≤33N,表示社交关系数)。随后的M行对应M条边,每行给出一对正…...

Windows File Recovery卡在99%怎么解决?实用指南!
为什么会出现“Windows File Recovery卡在99%”的问题? Windows File Recovery(Windows文件恢复)是微软设计的命令行应用程序。它可以帮助用户从健康/损坏/格式化的存储设备中恢复已删除/丢失的文件。 通过输入相关命令,设置源/…...

数据结构之数组
写在前面 看下数组。 1:巴拉巴拉 数组是一种线性数据结构,使用连续的内存空间来存储数据,存储的数据要求有相同的数据类型,并且每个元素占用的内存空间相同。获取元素速度非常快,为O(1)常量时间复杂度,所…...

springboot集成sensitive-word实现敏感词过滤
文章目录 敏感词过滤方案一:正则表达式方案二:基于DFA算法的敏感词过滤工具框架-sensitive-wordspringboot集成sensitive-word步骤一:引入pom步骤二:自定义配置步骤三:自定义敏感词白名单步骤四:核心方法测…...

C++ 之动手写 Reactor 服务器模型(一):网络编程基础复习总结
基础 IP 地址可以在网络环境中唯一标识一台主机。 端口号可以在主机中唯一标识一个进程。 所以在网络环境中唯一标识一个进程可以使用 IP 地址与端口号 Port 。 字节序 TCP/IP协议规定,网络数据流应采用大端字节序。 大端:低地址存高位,…...
)
新手也能看懂的TCAD入门:用Sentaurus和Silvaco分别跑一个NPN三极管(附完整代码)
TCAD新手实战指南:从零开始仿真NPN三极管 1. 初识TCAD:半导体仿真的利器 在微电子领域,TCAD(Technology Computer-Aided Design)工具如同设计师的"数字实验室",让我们能在计算机上模拟半导体器件…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...

JVM调优实战:让你的服务性能提升50%
一、背景 线上一个核心订单服务,QPS 3000左右,经常出现接口超时告警。监控显示: 平均RT: 180ms(要求<100ms)Full GC频率: 每天20次,每次STW 1.5sCPU使用率: 峰值85%服务规格: 8C16G,堆内存…...

百度网盘直链解析工具:突破下载限速的Python解决方案
百度网盘直链解析工具:突破下载限速的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经为百度网盘的下载速度而烦恼?作为国内最…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

Thorium浏览器深度解析:5个核心优势与进阶配置实战
Thorium浏览器深度解析:5个核心优势与进阶配置实战 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top of the RE…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题
CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/…...

基于LLM的游戏AI智能体:从感知到决策的框架构建与实践
1. 项目概述:一个能“玩”游戏的AI智能体最近在GitHub上看到一个挺有意思的项目,叫ChattyPlay-Agent。光看名字,你可能会觉得这又是一个基于大语言模型的聊天机器人。但点进去仔细研究后,我发现它的定位非常独特:这是一…...