第N5周:Pytorch文本分类入门
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊
任务:
●1. 了解文本分类的基本流程
●2. 学习常用数据清洗方法
●3. 学习如何使用jieba实现英文分词
●4. 学习如何构建文本向量

一、前期准备
- 环境安装
这是一个使用PyTorch实现的简单文本分类实战案例。在这个例子中,将使用AG News数据集进行文本分类。
AG News(AG’s News Topic Classification Dataset)是一个广泛用于文本分类任务的数据集,尤其是在新闻领域。该数据集是由AG’s Corpus of News Articles收集整理而来,包含了四个主要的类别:世界、体育、商业和科技。
首先,确保已经安装了torchtext与portalocker库
我的版本号是:

python版本是3.10.14:

python版本与要安装的torch、torchdata、torchvision、torchtext、portalocker库的版本是存在关联的,如果版本不对,代码在运行时会发生冲突,发生诸如“OSError: [WinError 127] 找不到指定的程序”这样的问题。
这些问题可以参考下面的文章来解决:
OSError: [WinError 127] 找不到指定的程序。
PyTorch中torch、torchvision、torchaudio、torchtext版本对应关系
Installing previous versions of PyTorch
torchtext 安装版本参考
通过参考上面的文章,我的做法是先检查虚拟环境的torch、torchvision、torchaudio、torchtext的版本是否冲突,是否与python的版本冲突。
如果有冲突,把torch、torchvision、torchaudio、torchtext卸载:
pip uninstall torch、torchvision、torchaudio、torchtext
因为虚拟环境的pyhon版本为3.10.14,我选择安装的torch、torchvision、torchaudio、torchtext的版本如下:
pip install torchvision == 0.15.0
pip install torchaudio == 2.0.1
pip install torch==2.0.0
最好是按照上面的顺序来安装,因为,当安装完torch,然后安装torchvision时,系统会自动下载cpu版本的torch。我的电脑是只有cpu,这个问题无所谓的。
还有一个问题,就是安装完torchvision时,可能也会同时自动安装torch,但自动安装的torch有可能不是我们自己想要安装的版本,这时就要把自动安装的torch卸载,等安装完torchaudio,再安装自己想要的torch版本。
还要安装下面的库:
pip insall torchtext == 0.15.1
pip insall torchdata==0.6.0
pip install portalocker ==2.7.0
pip install tornado
tornado是自动寻找对应的版本安装的。
注:相近版本也可,不必完全一致。
- 加载数据
import torchvision
from torchvision import transforms, datasetsimport torch
import torch.nn as nnimport os,PIL,pathlib,warningswarnings.filterwarnings("ignore") #忽略警告信息# win10系统,调用GPU运行
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device# 苹果系统,调用M2芯片
# device = torch.device('mps')
# device
代码输出
device(type='cpu')
from torchtext.datasets import AG_NEWStrain_iter = AG_NEWS(split='train') # 加载 AG News 数据集
torchtext.datasets.AG_NEWS()是一个用于加载 AG News 数据集的 TorchText 数据集类。AG News 数据集是一个用于文本分类任务的常见数据集,其中包含四个类别的新闻文章:世界、科技、体育和商业。torchtext.datasets.AG_NEWS() 类加载的数据集是一个列表,其中每个条目都是一个元组,包含以下两个元素:
●一条新闻文章的文本内容。
●新闻文章所属的类别(一个整数,从1到4,分别对应世界、科技、体育和商业)。
更详细的介绍可参考其他来源的NLP基础知识。
- 构建词典
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iteratortokenizer = get_tokenizer('basic_english') # 返回分词器函数,训练营内“get_tokenizer函数详解”一文def yield_tokens(data_iter):for _, text in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"]) # 设置默认索引,如果找不到单词,则会选择默认索引
vocab(['here', 'is', 'an', 'example'])
代码输出
[475, 21, 30, 5297]
torchtext.data.utils.get_tokenizer() 是一个用于将文本数据分词的函数。它返回一个分词器(tokenizer)函数,可以将一个字符串转换成一个单词的列表。这个函数可以接受两个参数:tokenizer 和 language,tokenizer参数指定要使用的分词器的名称。
label_pipeline('10')
代码输出
9
- 生成数据批次和迭代器
from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_label, _text) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即语句的总词汇量offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) #返回维度dim中输入元素的累计和return label_list.to(device), text_list.to(device), offsets.to(device)# 数据加载器
dataloader = DataLoader(train_iter,batch_size=8,shuffle =False,collate_fn=collate_batch)
二、准备模型
- 定义模型
这里定义TextClassificationModel模型,首先对文本进行嵌入,然后对句子嵌入之后的结果进行均值聚合。

from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, # 词典大小embed_dim, # 嵌入的维度sparse=False) # self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
self.embedding.weight.data.uniform_(-initrange, initrange)这段代码是在 PyTorch 框架下用于初始化神经网络的词嵌入层(embedding layer)权重的一种方法。这里使用了均匀分布的随机值来初始化权重,具体来说,其作用如下:
- self.embedding: 这是神经网络中的词嵌入层(embedding layer)。词嵌入层的作用是将离散的单词表示(通常为整数索引)映射为固定大小的连续向量。这些向量捕捉了单词之间的语义关系,并作为网络的输入。
- self.embedding.weight: 这是词嵌入层的权重矩阵,它的形状为 (vocab_size, embedding_dim),其中 vocab_size 是词汇表的大小,embedding_dim 是嵌入向量的维度。
- self.embedding.weight.data: 这是权重矩阵的数据部分,我们可以在这里直接操作其底层的张量。
- .uniform_(-initrange, initrange): 这是一个原地操作(in-place operation),用于将权重矩阵的值用一个均匀分布进行初始化。均匀分布的范围为 [-initrange, initrange],其中
initrange 是一个正数。
通过这种方式初始化词嵌入层的权重,可以使得模型在训练开始时具有一定的随机性,有助于避免梯度消失或梯度爆炸等问题。在训练过程中,这些权重将通过优化算法不断更新,以捕捉到更好的单词表示。
- 定义实例
num_class = len(set([label for (label, text) in train_iter]))
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)
- 定义训练函数与评估函数
import timedef train(dataloader):model.train() # 切换为训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 500start_time = time.time()for idx, (label, text, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # grad属性归零loss = criterion(predicted_label, label) # 计算网络输出和真实值之间的差距,label为真实值loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:1d} | {:4d}/{:4d} batches ''| train_acc {:4.3f} train_loss {:4.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换为测试模式total_acc, train_loss, total_count = 0, 0, 0with torch.no_grad():for idx, (label, text, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算loss值# 记录测试数据total_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)return total_acc/total_count, train_loss/total_count
三、训练模型
- 拆分数据集并运行模型
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 超参数
EPOCHS = 10 # epoch
LR = 5 # 学习率
BATCH_SIZE = 64 # batch size for trainingcriterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = Nonetrain_iter, test_iter = AG_NEWS() # 加载数据
train_dataset = to_map_style_dataset(train_iter)
test_dataset = to_map_style_dataset(test_iter)
num_train = int(len(train_dataset) * 0.95)split_train_, split_valid_ = random_split(train_dataset,[num_train, len(train_dataset)-num_train])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| epoch {:1d} | time: {:4.2f}s | ''valid_acc {:4.3f} valid_loss {:4.3f}'.format(epoch,time.time() - epoch_start_time,val_acc,val_loss))print('-' * 69)
代码运行结果
| epoch 1 | 500/1782 batches | train_acc 0.711 train_loss 0.01138
| epoch 1 | 1000/1782 batches | train_acc 0.866 train_loss 0.00614
| epoch 1 | 1500/1782 batches | train_acc 0.880 train_loss 0.00553
---------------------------------------------------------------------
| epoch 1 | time: 41.89s | valid_acc 0.893 valid_loss 0.005
---------------------------------------------------------------------
| epoch 2 | 500/1782 batches | train_acc 0.901 train_loss 0.00453
| epoch 2 | 1000/1782 batches | train_acc 0.904 train_loss 0.00444
| epoch 2 | 1500/1782 batches | train_acc 0.908 train_loss 0.00434
---------------------------------------------------------------------
| epoch 2 | time: 40.36s | valid_acc 0.894 valid_loss 0.005
---------------------------------------------------------------------
| epoch 3 | 500/1782 batches | train_acc 0.919 train_loss 0.00378
| epoch 3 | 1000/1782 batches | train_acc 0.921 train_loss 0.00376
| epoch 3 | 1500/1782 batches | train_acc 0.912 train_loss 0.00398
---------------------------------------------------------------------
| epoch 3 | time: 39.92s | valid_acc 0.905 valid_loss 0.005
---------------------------------------------------------------------
| epoch 4 | 500/1782 batches | train_acc 0.927 train_loss 0.00335
| epoch 4 | 1000/1782 batches | train_acc 0.926 train_loss 0.00347
| epoch 4 | 1500/1782 batches | train_acc 0.927 train_loss 0.00345
---------------------------------------------------------------------
| epoch 4 | time: 40.08s | valid_acc 0.882 valid_loss 0.005
---------------------------------------------------------------------
| epoch 5 | 500/1782 batches | train_acc 0.943 train_loss 0.00273
| epoch 5 | 1000/1782 batches | train_acc 0.943 train_loss 0.00272
| epoch 5 | 1500/1782 batches | train_acc 0.945 train_loss 0.00265
---------------------------------------------------------------------
| epoch 5 | time: 40.49s | valid_acc 0.912 valid_loss 0.004
---------------------------------------------------------------------
| epoch 6 | 500/1782 batches | train_acc 0.948 train_loss 0.00256
| epoch 6 | 1000/1782 batches | train_acc 0.945 train_loss 0.00265
| epoch 6 | 1500/1782 batches | train_acc 0.946 train_loss 0.00266
---------------------------------------------------------------------
| epoch 6 | time: 40.07s | valid_acc 0.913 valid_loss 0.004
---------------------------------------------------------------------
| epoch 7 | 500/1782 batches | train_acc 0.945 train_loss 0.00260
| epoch 7 | 1000/1782 batches | train_acc 0.947 train_loss 0.00255
| epoch 7 | 1500/1782 batches | train_acc 0.948 train_loss 0.00254
---------------------------------------------------------------------
| epoch 7 | time: 40.79s | valid_acc 0.913 valid_loss 0.004
---------------------------------------------------------------------
| epoch 8 | 500/1782 batches | train_acc 0.948 train_loss 0.00253
| epoch 8 | 1000/1782 batches | train_acc 0.948 train_loss 0.00247
| epoch 8 | 1500/1782 batches | train_acc 0.948 train_loss 0.00253
---------------------------------------------------------------------
| epoch 8 | time: 40.05s | valid_acc 0.915 valid_loss 0.004
---------------------------------------------------------------------
| epoch 9 | 500/1782 batches | train_acc 0.949 train_loss 0.00249
| epoch 9 | 1000/1782 batches | train_acc 0.950 train_loss 0.00243
| epoch 9 | 1500/1782 batches | train_acc 0.949 train_loss 0.00248
---------------------------------------------------------------------
| epoch 9 | time: 40.00s | valid_acc 0.914 valid_loss 0.004
---------------------------------------------------------------------
| epoch 10 | 500/1782 batches | train_acc 0.950 train_loss 0.00238
| epoch 10 | 1000/1782 batches | train_acc 0.950 train_loss 0.00243
| epoch 10 | 1500/1782 batches | train_acc 0.951 train_loss 0.00238
---------------------------------------------------------------------
| epoch 10 | time: 40.05s | valid_acc 0.915 valid_loss 0.004
---------------------------------------------------------------------
torchtext.data.functional.to_map_style_dataset 函数的作用是将一个迭代式的数据集(Iterable-style dataset)转换为映射式的数据集(Map-style dataset)。这个转换使得我们可以通过索引(例如:整数)更方便地访问数据集中的元素。
在 PyTorch 中,数据集可以分为两种类型:Iterable-style 和 Map-style。Iterable-style 数据集实现了 __ iter__() 方法,可以迭代访问数据集中的元素,但不支持通过索引访问。而 Map-style 数据集实现了 __ getitem__() 和 __ len__() 方法,可以直接通过索引访问特定元素,并能获取数据集的大小。
TorchText 是 PyTorch 的一个扩展库,专注于处理文本数据。torchtext.data.functional 中的 to_map_style_dataset 函数可以帮助我们将一个 Iterable-style 数据集转换为一个易于操作的 Map-style 数据集。这样,我们可以通过索引直接访问数据集中的特定样本,从而简化了训练、验证和测试过程中的数据处理。
- 使用测试数据集评估模型
print('Checking the results of test dataset.')
test_acc, test_loss = evaluate(test_dataloader)
print('test accuracy {:8.3f}'.format(test_acc))
代码运行结果
Checking the results of test dataset.
test accuracy 0.912
相关文章:
第N5周:Pytorch文本分类入门
本文为365天深度学习训练营 中的学习记录博客原作者:K同学啊 任务: ●1. 了解文本分类的基本流程 ●2. 学习常用数据清洗方法 ●3. 学习如何使用jieba实现英文分词 ●4. 学习如何构建文本向量 一、前期准备 环境安装 这是一个使用PyTorch实现的简单文…...

SpringBoot 自定义 starter
1. 官方文档 SpringBoot 版本 2.6.13,相关链接 Developing with Spring Boot 1.1 什么是 Starter Starters are a set of convenient dependency descriptors that you can include in your application. You get a one-stop shop for all the Spring and relate…...

TDengine Invalid data format 问题定位
Invalid data format 看语义是数据类型不符,通常这个报错出现在使用行协议写入时。 如果是批量数据写入,想定位是哪条语句的问题,需要查看客户端日志。 如何确定使用的是哪个日志 lsof -p pidof taosadapter | grep taoslog如果没有安装lso…...

Spring Boot 使用 MongoDB 教程
🍁 作者:知识浅谈,CSDN签约讲师,CSDN博客专家,华为云云享专家,阿里云专家博主 📌 擅长领域:全栈工程师、爬虫、ACM算法 🔥 微信:zsqtcyw 联系我领取学习资料 …...

Python办公自动化:使用openpyxl 创建与保存 Excel 工作簿
1 创建新的工作簿 在开始任何 Excel 操作之前,首先需要创建一个工作簿。openpyxl 提供了简单的接口来创建新的工作簿。 创建一个空白的工作簿 我们可以使用 openpyxl.Workbook() 来创建一个新的空白工作簿。以下是一个简单的示例: import openpyxl# …...

【张】#11 Union 共用体
Union 共用体可以存储不同的数据类型,但只能同时存储其中的一种类型。 #include <iostream> using namespace std;struct Product {char productName[20];int type;//1 int ,else charunion{int id_int;char id_chars[20];}; };int main(){Product product; …...
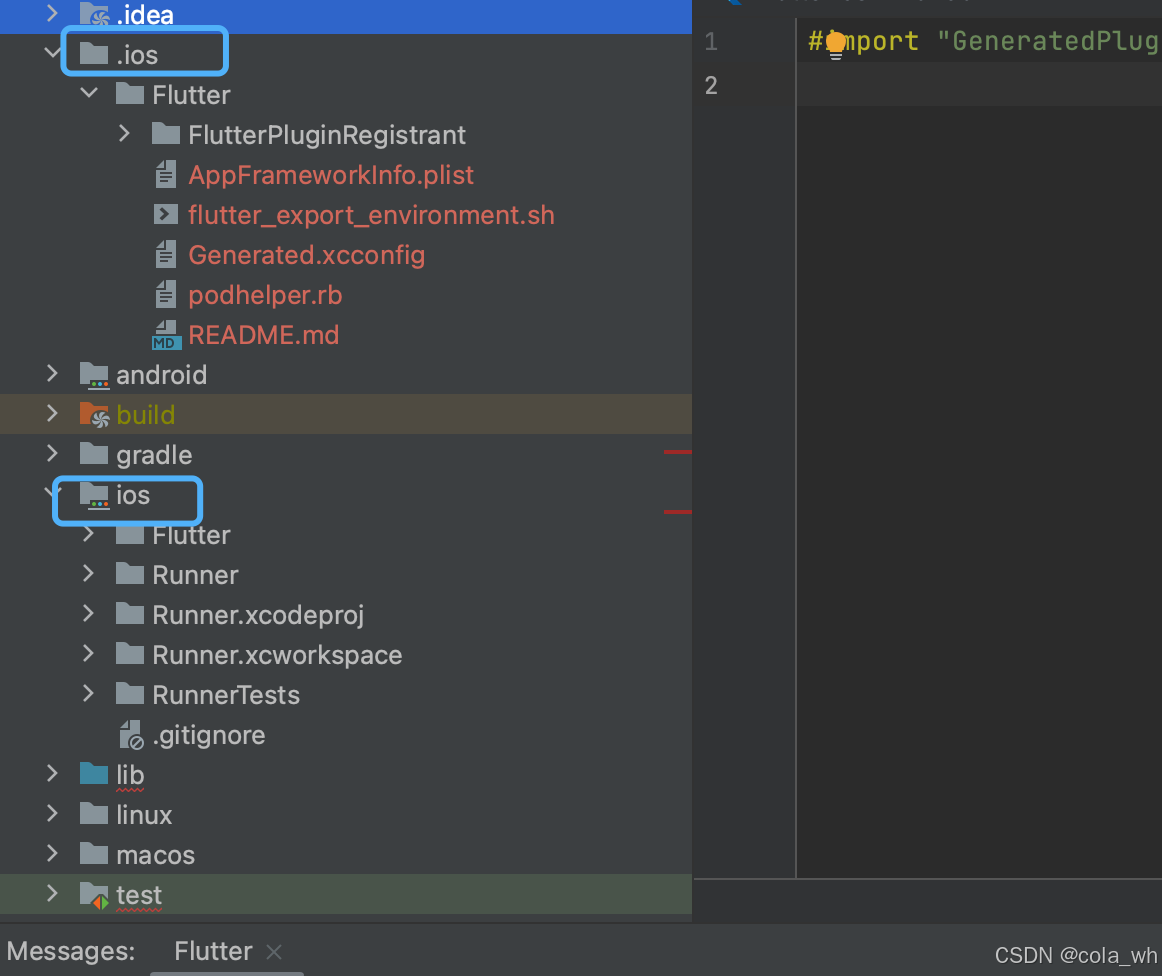
Xcode 在原生集成flutter项目
笔者公司有一个从2017年就开始开发的iOS和安卓原生项目,现在计划从外到内开始进行项目迁徙。 1》从gitee拉取flutter端的代码;(Android报错Exception: Podfile missing) 2》替换Xcode里的cocopods里Podfile的路径 然后报警 然后…...

ES6的promise
Promise是什么 1、Promise是js中的一个原生对象,是一种异步编程的解决方案。可以替换掉传统的回调函数解决方案,将异步操作以同步的流程表达出来。 2、Promise有三种状态:pending(初始化)、fulfilled(成功)、rejected(失败) 可以通过resolve(…...

轻松找回:如何在PostgreSQL 16中重置忘记的数据库密码
目录 1. 引言2. PostgreSQL 16的新特性简介3. 解决方法概述4. 方法一:通过修改pg_hba.conf文件重置密码5. 方法二:通过命令行进入单用户模式6. 方法三:使用pgAdmin工具重置密码7. 总结与最佳实践写在以后 1. 引言 你有没有过这样的经历&…...
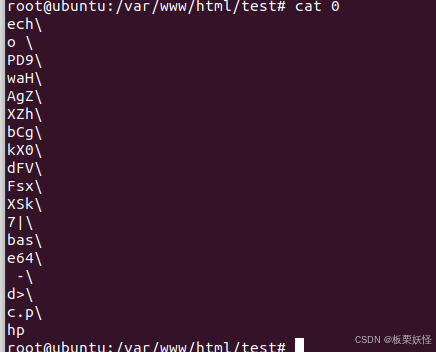
EVAL长度突破限制
目录 突破15位限制 代码 绕过方式 第一种(使用echo执行) 第二种(使用file_get_content追加文件后进行问件包含) 第三种(使用usort可变长参数) 突破7位限制 第一种(可以使用>创建文件…...

如何判断树上一个点是否在直径上
# 旅游规划 ## 题目描述 W市的交通规划出现了重大问题,市政府下定决心在全市各大交通路口安排疏导员来疏导密集的车流。但由于人员不足,W市市长决定只在最需要安排人员的路口安排人员。 具体来说,W市的交通网络十分简单,由n个…...

docker 部署 RabbitMQ
命令 docker run -d --namerabbitmq \ -p 5671:5671 -p 5672:5672 -p 4369:4369 \ -p 15671:15671 -p 15672:15672 -p 25672:25672 \ -e RABBITMQ_DEFAULT_USERusername\ -e RABBITMQ_DEFAULT_PASSpassword\ -v /usr/local/rabbitmq/data:/var/lib/rabbitmq \ -v /usr/local/r…...

设计模式 - 过滤器模式
💝💝💝首先,欢迎各位来到我的博客!本文深入理解设计模式原理、应用技巧、强调实战操作,提供代码示例和解决方案,适合有一定编程基础并希望提升设计能力的开发者,帮助读者快速掌握并灵活运用设计模式。 💝💝💝如有需要请大家订阅我的专栏【设计模式】哟!我会定…...

使用 Locust 进行本地压力测试
在应用开发和运维过程中,了解应用在高负载情况下的表现至关重要。压力测试可以帮助你识别性能瓶颈和潜在问题。本文将介绍如何使用 Locust 工具进行本地压力测试,模拟高并发场景,并分析测试结果。 1. 什么是 Locust? Locust 是一…...

【图形学】TA之路-矩阵应用平移-旋转-大小
矩阵应用:在 Unity 中,Transform 和矩阵之间的关系非常密切。Transform 组件主要用于描述和控制一个物体在三维空间中的位置、旋转和缩放,而这些操作背后实际上都是通过矩阵来实现的 1. Transform 组件与矩阵的关系 Transform 组件包含以下…...

Spring 循环依赖解决方案
文章目录 1. 循环依赖的产生2. 循环依赖的解决模型3. 基于setter/Autowired 的循环依赖1_编写测试代码2_初始化 Cat3_初始化 Person4_ 回到 Cat 的创建流程5_小结 4. 基于构造方法的循环依赖5. 基于原型 Bean 的循环依赖6. 引人AOP的额外设计7. 总结 IOC 容器初始化bean对象的逻…...
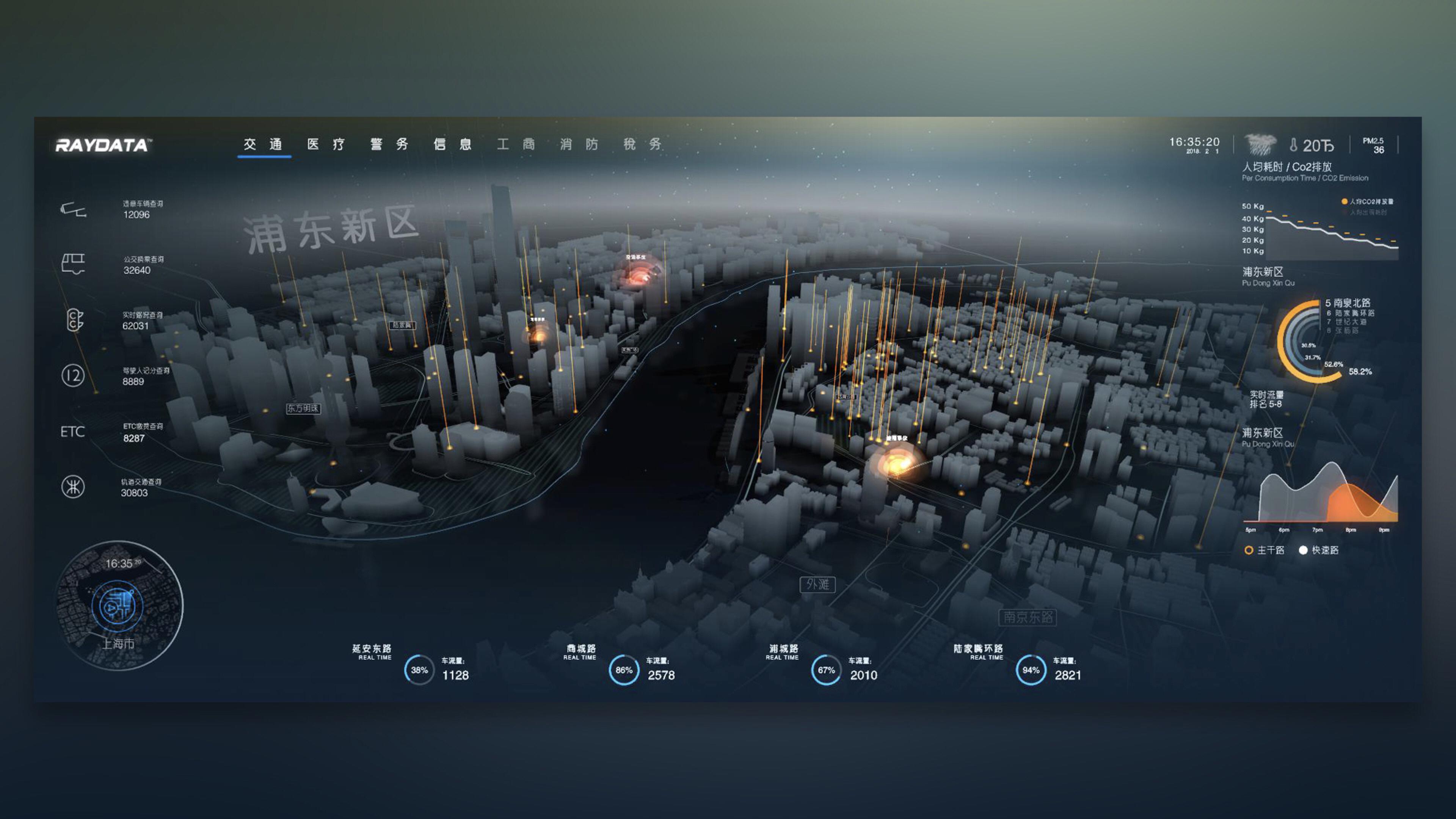
可视化大屏:如何get到领导心目中的“科技感”?
你如果问领导可视化大屏需要什么风格的,领导大概率说科技感的,然后你就去做了,结果被劈了一顿,什么原因?因为你没有get到领导心目中描述的科技感。 一、为什么都喜欢科技感 科技感在可视化大屏设计中具有以下好处&am…...

基于Python的金融数据采集与分析的设计与实现
基于Python的金融数据采集与分析的设计与实现 “Design and Implementation of Financial Data Collection and Analysis based on Python” 完整下载链接:基于Python的金融数据采集与分析的设计与实现 文章目录 基于Python的金融数据采集与分析的设计与实现摘要第一章 绪论1…...

使用Sanic和SSE实现实时股票行情推送
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storm…...

redis散列若干记录
字典 redis本身使用字典结构管理数据 redis使用hash表实现字典结构 使用了什么hash算法 使用SipHash算法,该算法能有效防止Hash表碰撞,并有不错的性能 hash冲突怎么解决 使用链表法解决hash冲突 hash表如何扩容 渐进式扩容,不会引起线程长期阻…...

射频PA中的ICC和ICQ电流是什么?
射频 PA 的 ICC 与 ICQ 深度解析 核心关联:ICQ(静态偏置)与 ICC(工作电流)直接决定 DLCA / ENDC / SRS / RX Desense 的系统稳定性。 一、拍板级定义:ICQ vs ICC 术语 全称 工作状态 核心关注点 ICQ Quiescent Current 静态(无信号或极小信号) 线性度、稳定性、瞬态响应…...

README智能生成工具:从项目分析到自动化文档的工程实践
1. 项目概述:一个为README注入灵魂的智能工具在开源社区和日常开发中,README文件的重要性不言而喻。它不仅是项目的门面,更是连接开发者与用户、贡献者之间的第一座桥梁。然而,有多少次,我们面对一个功能强大但文档寥寥…...

通过Taotoken为OpenClaw配置自定义模型供应商的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken为OpenClaw配置自定义模型供应商的详细步骤 OpenClaw是一个流行的AI智能体开发框架,它允许开发者灵活地配…...

9D传感器融合技术:原理、优化与应用
1. 9D传感器融合技术概述在当今的智能设备领域,精确的姿态感知已成为标配功能。从智能手机的自动旋转屏幕到VR头显的动作追踪,背后都离不开多传感器数据的融合处理。9D传感器融合技术通过整合加速度计、陀螺仪和磁力计的数据(各提供3轴测量&a…...

ToDesk、向日葵、UU远程横评:谁才是2026国产远控首
ToDesk、向日葵、UU远程横评:谁才是2026国产远控首选一、前言:国产远控崛起,2026 怎么选?远程控制早已从 “小众工具” 变成个人、办公、游戏、运维的刚需。2026 年国产远控阵营已全面崛起,ToDesk、向日葵、UU 远程成为…...

长期使用taotoken聚合api在项目中的稳定性主观体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合API在项目中的稳定性主观体验分享 1. 项目背景与接入简述 我们团队负责一个面向内部的知识管理与智能问答系…...

从零到跑通:Windows下OTB100数据集与Matlab评测环境保姆级避坑指南
从零到跑通:Windows下OTB100数据集与Matlab评测环境保姆级避坑指南 刚接触目标跟踪领域的研究者,往往需要从经典数据集评测开始。OTB(Object Tracking Benchmark)作为目标跟踪领域的基石数据集,包含100个具有挑战性的视…...

MediaCreationTool.bat:Windows部署自动化脚本封装架构深度解析
MediaCreationTool.bat:Windows部署自动化脚本封装架构深度解析 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

边缘AI技术原理与实战:从模型轻量化到医疗零售场景落地
1. 项目概述:为什么“边缘AI”正在重塑我们的世界最近几年,我身边越来越多的工程师朋友,从云端AI的狂热转向了“边缘AI”的务实探索。这不仅仅是技术潮流的转向,更像是一场静悄悄的革命。简单来说,边缘AI就是把原本需要…...
)
【限时公开】ElevenLabs企业级有声书工作台搭建指南:Webhook自动触发+Notion项目看板+音频质量AI评分模型(含开源评估脚本)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs企业级有声书工作台全景概览 ElevenLabs 企业级有声书工作台(Enterprise Audiobook Studio)是一套面向出版机构、教育平台与内容工厂的端到端语音生成协同平台&#x…...