慢SQL优化

1、避免使用select *
select * 不会走覆盖索引,会出现大量的回表操作,从而导致查询sql的性能很低。
--反例
select * from user where id = 1;
--正例
select name,age from user where id = 1;
2、union all 代替 union
union:去重后的数据,union all:所有数据包含重复数据
排重的过程需要遍历、排序和比较,它更耗时,更消耗cpu资源。
除非是有些特殊的场景,比如union all之后,结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这时可以使用union。
--反例
(select * from user where id = 1)
union
(select * from user where id = 2);--正例
(select * from user where id = 1)
union all
(select * from user where id = 2);3、小表驱动大表
小表驱动大表:小表的数据集驱动大表的数据集。
假如有order和user两张表,其中order表有10000条数据,而user表有100条数据。
有效的用户下过的订单列表,in关键字去实现业务需求,更加合适。
因为如果SQL语句中包含了in关键字,则它会优先执行in里面的子查询语句,然后再执行in外面的语句。如果in里面的数据量很少,作为条件查询速度更快。
如果SQL语句中包含了exists关键字,它优先执行exists左边的语句(即主查询语句)。然后把它作为条件,去跟右边的语句匹配。如果匹配上,则可以查询出数据。如果匹配不上,数据就被过滤掉了。
--IN
select * from order
where user_id in (select id from user where status=1)--exists
select * from order
where exists (select 1 from user where order.user_id = user.id and status=1)
in适用于左边大表,右边小表。
exists适用于左边小表,右边大表。
4、批量新增
下面操作需要多次请求数据库,才能完成这批数据的插入。
每次远程请求数据库,是会消耗一定性能的。而如果我们的代码需要请求多次数据库,才能完成本次业务功能,势必会消耗更多的性能。
--反例
for(Order order: list){orderMapper.insert(order):
}在循环中逐条插入
insert into order(id,code,user_id)
values(123,'001',100);批量插入只需要远程请求一次数据库,SQL性能会得到提升,数据量越多,提升越大。
但需要注意的是,不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在500以内。如果数据多于500,则分多批次处理。
--正例
orderMapper.insertBatch(list);insert into order(id,code,user_id)
values(123,'001',100),(124,'002',100),(125,'003',101);
5、多用limit
查询数据创建时间最新的一条数据
--反例
select id,create_date
from order
where user_id=123
order by create_date asc;List<Order> list = orderMapper.getOrderList();
Order order = list.get(0);--正例
select id,create_date
from order
where user_id=123
order by create_date asc
limit 1;6、in中值太多
我们不做任何限制,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。
select id,name from category
where id in (1,2,3...100000000);可以在SQL中对数据用limit做限制,不过我们更多的是要在业务代码中加限制
select id,name from category
where id in (1,2,3...100)
limit 500;如果ids超过500条记录,可以分批用多线程去查询数据。每批只查500条记录,最后把查询到的数据汇总到一起返回。
public List<Category> getCategory(List<Long> ids) {if(CollectionUtils.isEmpty(ids)) {return null;}if(ids.size() > 500) {throw new BusinessException("一次最多允许查询500条记录")}return mapper.getCategoryList(ids);
}7、增量同步
远程接口查询数据,然后同步到另外一个数据库。
--反例
--数据很多的话,查询性能会非常差。
select * from user;
按ID和时间升序,每次只同步一批数据,这一批数据只有100条记录。
每次同步完成之后,保存这100条数据中最大的ID和时间,给同步下一批数据的时候用。
通过这种增量查询的方式,能够提升单次查询的效率。
select * from user
where id > #{lastId} and create_time >= #{lastCreateTime}
limit 100;全量同步:每天9点全量执行一次,目标表记录同步时间
增量同步:每15分钟定时执行任务同步数据,如果源数据表修改时间 > 目标表的同步时间 ,作为新增数据同步
8、高效的分页
列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。
select id,name,age
from user limit 10,20;如果表中数据量少,用limit关键字做分页,没啥问题。但如果表中数据量很多,用它就会出现性能问题。mysql会查到1000020条数据,然后丢弃前面的1000000条,只查后面的20条数据,这个是非常浪费资源的。
select id,name,age
from user limit 1000000,20;先找到上次分页最大的id,然后利用id上的索引查询。不过该方案,要求id是连续的,并且有序的。
select id,name,age
from user where id > 1000000 limit 20;9、用连接查询代替子查询
mysql中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。
--子查询
select * from order
where user_id in (select id from user where status=1)子查询语句可以通过in关键字实现,一个查询语句的条件是在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。
子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。
但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。
select o.* from order o
inner join user u on o.user_id = u.id
where u.status=110、join的表不宜过多
阿里巴巴开发者手册的规定,join表的数量不应该超过
3个。
如果join太多,mysql在选择索引的时候会非常复杂,很容易选错索引。
并且如果没有命中中,nested loop join 就是分别从两个表读一行数据进行两两对比,复杂度是 n^2。所以我们应该尽量控制join表的数量。
--反例
select a.name,b.name.c.name,d.name
from a
inner join b on a.id = b.a_id
inner join c on c.b_id = b.id
inner join d on d.c_id = c.id
inner join e on e.d_id = d.id
inner join f on f.e_id = e.id
inner join g on g.f_id = f.id如果实现业务场景中需要查询出另外几张表中的数据,可以在a、b、c表中冗余专门的字段,比如:在表a中冗余d_name字段,保存需要查询出的数据。
不过我之前也见过有些ERP系统,并发量不大,但业务比较复杂,需要join十几张表才能查询出数据。所以join表的数量要根据系统的实际情况决定,不能一概而论,尽量越少越好。
--正例
select a.name,b.name.c.name,a.d_name
from a
inner join b on a.id = b.a_id
inner join c on c.b_id = b.id11、 join时要注意
left join:求两个表的交集外加左表剩下的数据。inner join:求两个表交集的数据。
两张表使用inner join关联,mysql会自动选择两张表中的小表,去驱动大表,所以性能上不会有太大的问题。
--inner join
select o.id,o.code,u.name
from order o
inner join user u on o.user_id = u.id
where u.status=1;两张表使用left join关联,mysql会默认用left join关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。
select o.id,o.code,u.name
from order o
left join user u on o.user_id = u.id
where u.status=1;left join关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。
12、控制索引数量
众所周知,索引能够显著的提升查询sql的性能,但索引数量并非越多越好。
因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。
阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。
mysql使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。
那么,问题来了,如果表中的索引太多,超过了5个该怎么办?
这个问题要辩证的看,如果你的系统并发量不高,表中的数据量也不多,其实超过5个也可以,只要不要超过太多就行。
但对于一些高并发的系统,请务必遵守单表索引数量不要超过5的限制。
那么,高并发系统如何优化索引数量?
能够建联合索引,就别建单个索引,可以删除无用的单个索引。
将部分查询功能迁移到其他类型的数据库中,比如:Elastic Seach、HBase等,在业务表中只需要建几个关键索引即可。
13、选择合理的字段类型
char表示固定字符串类型,该类型的字段存储空间的固定的,会浪费存储空间。
alter table order
add column code char(20) NOT NULL;varchar表示变长字符串类型,该类型的字段存储空间会根据实际数据的长度调整,不会浪费存储空间。
alter table order
add column code varchar(20) NOT NULL;如果是长度固定的字段,比如用户手机号,一般都是11位的,可以定义成char类型,长度是11字节。
但如果是企业名称字段,假如定义成char类型,就有问题了。
如果长度定义得太长,比如定义成了200字节,而实际企业长度只有50字节,则会浪费150字节的存储空间。
如果长度定义得太短,比如定义成了50字节,但实际企业名称有100字节,就会存储不下,而抛出异常。
所以建议将企业名称改成varchar类型,变长字段存储空间小,可以节省存储空间,而且对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
我们在选择字段类型时,应该遵循这样的原则:
- 能用数字类型,就不用字符串,因为字符的处理往往比数字要慢。
- 尽可能使用小的类型,比如:用bit存布尔值,用tinyint存枚举值等。
- 长度固定的字符串字段,用char类型。
- 长度可变的字符串字段,用varchar类型。
- 金额字段用decimal,避免精度丢失问题。
14、 提升group by的效率
我们有很多业务场景需要使用group by关键字,它主要的功能是去重和分组。
通常它会跟having一起配合使用,表示分组后再根据一定的条件过滤数据。
--反例
select user_id,user_name from order
group by user_id
having user_id <= 200;这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?
--正例
select user_id,user_name from order
where user_id <= 200
group by user_id使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。
其实这是一种思路,不仅限于group by的优化。我们的sql语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升sql整体的性能。
15、索引优化
索引优化的第一步是:检查sql语句有没有走索引。
可以使用explain命令,查看mysql的执行计划。
explain select * from `order` where code='002';

通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:

下面说说索引失效的常见原因:

相关文章:
慢SQL优化
1、避免使用select * select * 不会走覆盖索引,会出现大量的回表操作,从而导致查询sql的性能很低。 --反例 select * from user where id 1;--正例 select name,age from user where id 1;2、union all 代替 union union:去重后的数据…...

MES生产执行系统源码,支持 SaaS 多租户,技术架构:springboot + vue-element-plus-admin
MES的定义与功能 MES是制造业中一种重要的管理信息系统,用于协调和监控整个生产过程。它通过收集、分析和处理各种生产数据,实现对生产流程的实时跟踪和监控,并为决策者提供准确的数据支持。MES涵盖了工厂运营、计划排程、质量管理、设备维护…...

【Linux】分析hung_panic生成的vmcore
简介 1、遇到一个问题: 上述日志是oom_kill,下述日志是hung_panic 2、分别解释两层含义,全部日志如下: [75834.243209] kodo invoked oom-killer: gfp_mask0x600040(GFP_NOFS), order0, oom_score_adj968 [75834.245657] CPU: 0…...

unity 画线写字
效果 1.界面设置 2.涉及两个脚本UIDraw.cs和UIDrawLine.cs UIDraw.cs using System; using System.Collections.Generic; using UnityEngine; using UnityEngine.EventSystems; using UnityEngine.UI;public class UIDraw : MonoBehaviour, IPointerEnterHandler, IPointerEx…...

GitHub的详细介绍
GitHub是一个面向开源及私有软件项目的托管平台,它建立在Git这个分布式版本控制系统之上,为开发者提供了在云端存储、管理和共享代码的便捷方式。以下是对GitHub的详细介绍: ### 一、GitHub的基本功能 1. **代码托管**:GitHub允…...

【鸿蒙学习】HarmonyOS应用开发者基础 - 构建更加丰富的页面之Tabs(三)
学完时间:2024年8月14日 一、前言叨叨 学习HarmonyOS的第六课,人数又成功的降了500名左右,到了3575人了。 本文接上一文章【鸿蒙学习】HarmonyOS应用开发者基础 - 构建更加丰富的页面(一),继续记录构建更…...

Detectron2 安装指南
文章目录 前言Detectron2官方文档官方指南 安装 Detectron2虚拟环境安装 PyTorch安装 Detectron2 总结 前言 Detectron2 是 Meta AI 的一个机器视觉相关的库,建立在 Detectron 和 maskrcnn-benchmark 基础之上,可以进行目标检测、语义分割、全景分割&am…...

亚马逊 Linux mysql5.7 安装纪录
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz cp /home/admin/mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz /usr/local/mysql #解压压缩包 tar -zxvf mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz 重命名mysql-…...

ZLMediaKit编译webrtc
ZLMediaKit官方文档写的挺详细的,但是也不算特别详细。 按照上面的文档,执行到cmake的时候,会提示“srtp 未找到, WebRTC 相关功能打开失败”,但是cmke还是可以继续啊。此时看文档说webrtc比较复杂,默认是不编译的&am…...

KEEPALIVED高可用集群最详解
目录 一、高可用集群 1.1 集群的类型 1.2 实现高可用 1.3 VRRP:Virtual Router Redundancy Protocol 1.3.1 VRRP相关术语 1.5.2 VRRP 相关技术 二、部署KEEPALIVED 2.1 keepalived 简介 2.2 Keepalived 架构 2.3 Keepalived 环境准备 2.3.1 实验环境 2…...

【大模型】llama-factory基础学习
前言:LLaMA-Factory项目的目标是整合主流的各种高效训练微调技术,适配市场主流开源模型,形成一个功能丰富,适配性好的训练框架。 目录 1. 前期准备2. 原始模型直接推理3. 自定义数据集4. 模型训练5. 模型合并并导出 1. 前期准备 …...

【Java】如何使用jdbc连接并操作MySQL,一文读懂不迷路,小白也能轻松学会
JDBC的原理 JDBC(Java Database Connectivity)是Java提供的用于连接和操作数据库的API。它允许Java应用程序与各种数据库进行交互,以下是JDBC的基本原理: 驱动程序管理:JDBC使用不同的数据库驱动程序来连接不同类型的…...

新手学习VR全景需要知道的几个问题
1.什么是720云 720云是一家专注于VR全景内容制作与展示的技术平台,提供从拍摄、编辑到发布的一站式解决方案。它的核心功能包括全景图像的制作和编辑工具,以及VR全景内容的在线展示和分享服务。720云的技术广泛应用于房地产、旅游、教育、文化展示等多个…...

上海知名泌尿外科专家常态化坐诊黄山新晨医院,让前列腺癌看得更早、更准!
继7月28日上海第四人民医院泌尿外科专家在黄山新晨医院开展义诊之后,8月9日和10日,该团队领头人周铁教授又完成了合作以来的首次坐诊,标志着双方合作从此进入常态化阶段。 周铁主任在查看患者的检查报告 周铁主任曾任中华医学会泌尿外科分会…...

Elasticsearch: 非结构化的数据搜索
r很多大数据组件在快速原型时期都是Java实现,后来因为GC不可控、内存或者向量化等等各种各样的问题换到了C,比如zookeeper->nuraft(https://www.yuque.com/treblez/qksu6c/hu1fuu71hgwanq8o?singleDoc# 《olap/clickhouse keeper 一致性协调服务》)&…...

44 个 React 前端面试问题
1.你知道哪些React hooks? useState:用于管理功能组件中的状态。useEffect:用于在功能组件中执行副作用,例如获取数据或订阅事件。useContext:用于访问功能组件内的 React 上下文的值。useRef:用于创建对跨…...

LLMs之Framework:Hugging Face Accelerate后端框架之FSDP和DeepSpeed的对比与分析
LLMs之Framework:Hugging Face Accelerate后端框架之FSDP和DeepSpeed的对比与分析 导读:该文章阐述了FSDP和DeepSpeed在实现上的差异,Accelerate如何统一它们的行为,并提供指导帮助用户在两种后端之间切换。同时也讨论了低精度优化…...

HarmonyOS应用开发学习-ArkTs声明式UI描述
ArkTs声明式UI描述 1 创建组件 声明式UI描述 ArKTS以声明方式组合和扩展组件来描述应用程序的UI,同时还提供了基本的属性、事件和子组件配置方法,帮助开发者实现应用交互逻辑 创建组件 根据组件构造方法的不同,创建组件包含有参数和无参…...

Redis20-通信协议
目录 RESP协议 概述 数据类型 模拟Redis客户端 RESP协议 概述 Redis是一个CS架构的软件,通信一般分两步(不包括pipeline和PubSub): 客户端(client)向服务端(server)发送一条命…...
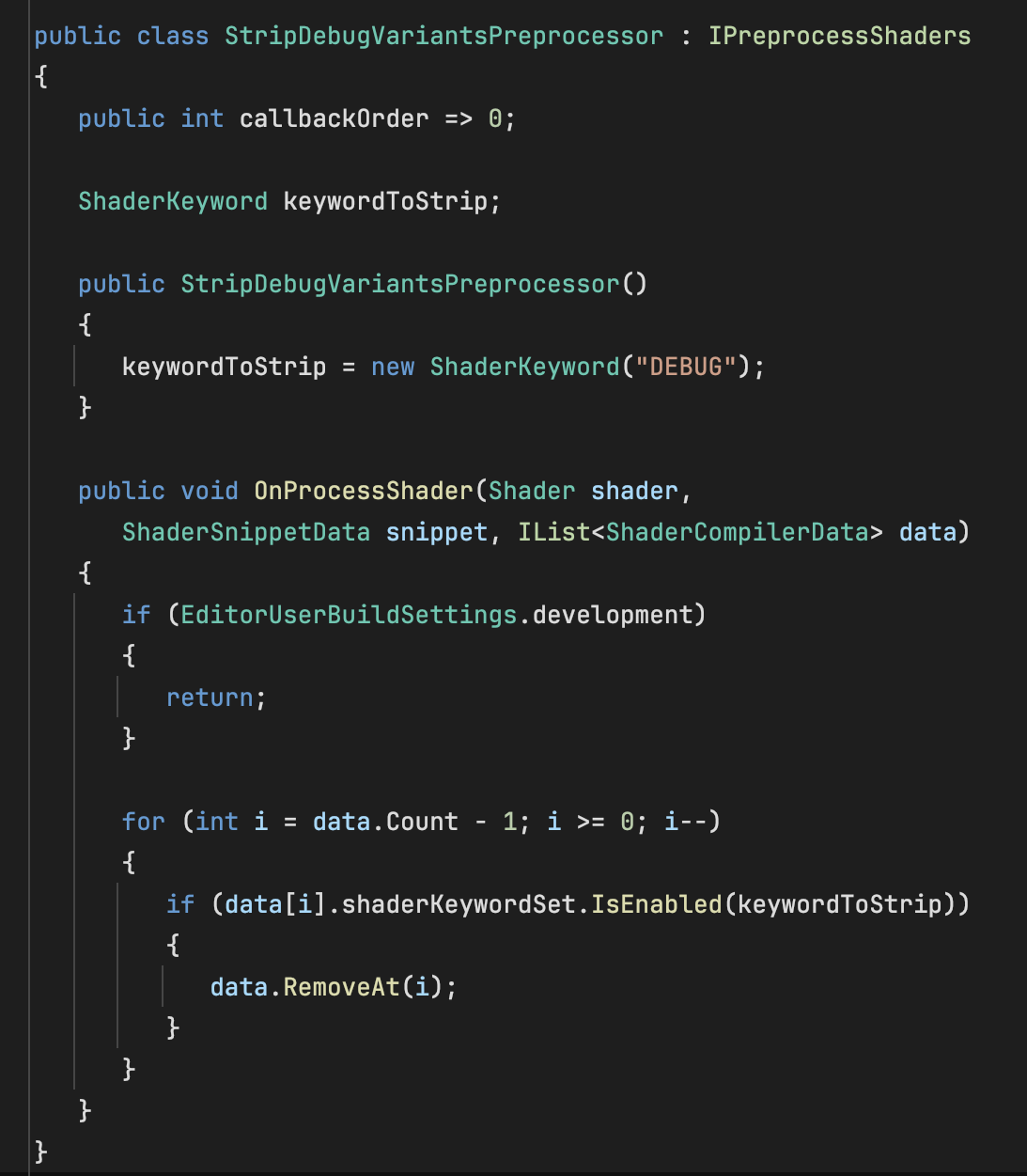
Unity Shader变体优化与故障排除技巧
在 Unity 中编写着色器时,我们可以方便地在一个源文件中包含多个特性、通道和分支逻辑。在构建时,着色器源文件会被编译成着色器程序,这些程序包含一个或多个变体。变体是该着色器在满足一组条件后生成的版本,这通常会导致线性执行…...

Worldquant研究顾问速通
几天时间速通拿了金牌,中间停了一两周,然后仔细研究了下,学了相关知识,搭建自己ai驱动的工作流后每天大约10分钟设置好任务,可探索到10来个可以提交的alpha,目前产出比大约在1/100,simulate100个…...

Windows与Linux跨系统数据传输:从SCP、Rsync到自动化脚本的完整指南
1. 项目概述:为什么我们需要跨系统传输数据?在混合IT环境成为常态的今天,一个典型的开发或运维场景是:你的主力工作机运行着Windows,而你的代码、应用或数据处理任务则部署在远端的Linux服务器上。无论是将本地的配置文…...

避坑指南:Ubuntu 20.04上VINS-Fusion环境搭建,从源码修改到手机数据实测的完整流程
Ubuntu 20.04下VINS-Fusion环境搭建全流程避坑手册 当你在Ubuntu 20.04上尝试搭建VINS-Fusion环境时,可能会遇到各种令人头疼的问题。从依赖项安装到源码修改,再到手机摄像头数据的适配,每一步都可能隐藏着意想不到的"坑"。本文将带…...

你的 FlashAttention 真的在跑吗?几个简单方法确认
之前有个朋友在昇腾 NPU 上部署模型,按文档开了 --enable-flash-attn,跑起来也没报错。但他总觉得延迟不对——跟之前没开的时候差不多。他问我:怎么确认 FlashAttention 真的生效了?不会是静默降级了吧? 这个问题问得…...

美股软件股反弹:AI 重塑软件未来,谁能成为时代赢家?
美股软件股遭遇“集体误杀”去年 10 月底开始,美股软件股经历罕见“集体误杀”。以软件 ETF——IGV 为代表,软件板块从高位显著回撤,跌幅接近 40%。曾经的高质量成长资产软件公司,沦为 AI 浪潮下的“旧世界遗产”。恐慌源于 DeepS…...

保姆级教程:SAP资产折旧调错了怎么办?手把手教你用AB08和反向事务类型回退操作
SAP资产折旧纠错实战:AB08与反向事务类型的精准回退方案 资产折旧调整是SAP系统中高频操作之一,但误操作后的修正往往让使用者手足无措。当ABAA或ABMA执行后发现金额错误时,如何安全撤回操作而不影响历史数据?本文将深入解析两种主…...
为9.2%)
2026-2032期间,全球半导体设备零部件PVD和ALD熔射服务市场年复合增长率(CAGR)为9.2%
QYResearch调研显示,2025年全球半导体设备零部件PVD和ALD熔射服务市场规模大约为0.58亿美元,预计2032年将达到1.07亿美元,2026-2032期间年复合增长率(CAGR)为9.2%。行业竞争格局与细分市场市场分析全球半导体设备零部件…...

开源架构企业管理软件适合哪些类型的公司
开源架构企业管理软件适合哪些类型的公司 很多人一听到“开源架构”,第一反应是技术人员、开发者、极客项目。放到企业管理软件里,其实开源架构更像一种长期可控的建设方式:企业能看见系统如何运行,也能在需要时改造它。 对中小…...

告别检测卡点,okbiye 智能双优化破解毕业论文查重与 AI 识别难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 一、引言:论文定稿阶段两大检测难题普遍困扰学子 论文撰写收尾阶段,绝大多数毕业生都会直面两道审核关卡&#x…...
的电动汽车充电行为场景生成研究( Python + PyTorch实现))
【顶级EI复现】基于去噪概率扩散模型(DDPM)的电动汽车充电行为场景生成研究( Python + PyTorch实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...