proxy负载均衡
endpoint : 终点、终端 看service服务器的ip kubectl get ep
backend -> real server :真正提供web服务的服务器
负载均衡器 load balancer --》LB
USER -->LB --->BACKEND(real server)
nginx
SERVICE --->很多的endpoint--》pod
user -->node--->service --->pod
LB
IPVS-->LVS
删除service(相当于负载均衡器) 不会删除pod
service类型:ClusterIP(集群内部自动分配虚拟ip,只能在集群内部访问)
NodePort (使用nat,可以外网) 端口号30000-32767 在集群中每个选定的node的相同端口上公开service 用nodeport和nodeip从集群外部访问
LoadBalancer 通过外部的负载均衡来访问 ExternalName
headless service: 定义cluster的值为“none” 不会有ip 使用域名访问 集群内布

[root@k8s-master-1 ~]# top
top - 15:09:18 up 5:37, 2 users, load average: 0.84, 1.34, 1.51
Tasks: 166 total, 1 running, 165 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3.4 us, 3.4 sy, 0.0 ni, 89.7 id, 0.0 wa, 0.0 hi, 3.4 si, 0.0 st
KiB Mem : 3861300 total, 395440 free, 1161244 used, 2304616 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2447520 avail Mem
us --》user processes 用户态进程消耗的cpu的资源的比例
sy --》system processes(内核态的进程消耗的cpu的资源的比例)
id -->idle 空闲
hi --》hard interrupt --》硬件导致的程序中断
si --》soft interrupt --》软件导致的程序中断
用户态的进程会在以下几种情况下进入内核态:
1.系统调用:
主动请求:这是处于用户态的进程主动请求切换到内核态的一种方式。用户态的进程通过系统调用申请使用操作系统提供的系统调用服务例程来处理任务。系统调用的机制核心是使用了操作系统为用户特别开发的一个中断机制,即软中断。在UNIX系统上,内核对外的接口就是系统调用,这些系统调用以C函数的形式出现,因此内核外的程序都必须经由系统调用才能获得操作系统的服务。
过程:当应用程序使用系统调用时,会先将系统调用名称转换为系统调用号,然后将系统调用号和请求参数放到寄存器里,接着执行中断指令(如Linux中的int $0x80指令),产生一个中断,使CPU陷入到内核态。之后,CPU会跳转到中断处理程序,执行内核态逻辑,并在完成后通过中断返回指令(如iret指令)恢复到用户态。
2.异常:
被动触发:当CPU执行运行在用户态下的程序时,如果发生了某些事先不可知的异常(如缺页异常),这时会触发由当前运行的进程切换到处理此异常的内核相关程序中,也就是转到了内核态。
处理:异常发生时,CPU会暂停执行下一条即将要执行的指令,转而执行与异常信号对应的处理程序。如果先前执行的指令是用户态下的程序,那么这个转换的过程就发生了由用户态到内核态的切换。
3.外设中断:
外部事件:当外围设备(如硬盘、网卡等)完成用户请求的操作后,会向CPU发出相应的中断信号。
处理流程:这时CPU会暂停执行下一条即将要执行的指令,转而去执行与中断信号对应的处理程序。如果先前执行的指令是用户态下的程序,那么这个转换的过程也就发生了由用户态到内核态的切换。例如,硬盘读写操作完成后,系统会切换到硬盘读写的中断处理程序中执行后续操作。
综上,用户态的进程会在系统调用、异常处理和外设中断发生时进入内核态。在这些情况下,CPU会暂停当前的用户态执行流程,转而执行内核态的相关程序或处理逻辑。需要注意的是,在这些转换过程中,会涉及到CPU上下文(如寄存器、程序计数器等)的保存和恢复,以确保进程在执行完内核态任务后能够正确地恢复到用户态继续执行。
iptables(用户态) ---》netfilter内核态 过滤防火墙 传递参数--》linux内核里的模块 性能损耗 只是防火墙,大规模场景下性能大打折扣
ipvs--》LVS -->负载均衡器--》 四层
- iptables和ipvs做负载均衡的时候,哪些性能好? ipvs好 iptables里的规则越多,查找的时候,消耗的时间就会越长,效率就会越低--》不适合大的集群规模 iptables规则是顺序表的存放在一个表里 --》顺序表 ipvs是采用哈希表来存放负载均衡策略,查找的时候,效率比较高,消耗的时间比较短--》适合大的集群规模 ipvs的规则存放在哈希表里 哈希表 当表越来越大的时候,传统的表和哈希表在查找和插入、删除方面有什么区别?哪个优势更加大? iptables和ipvs使用了不同的数据结构存放规则,在查找速度上和扩展性上有差异 哈希表查询为什么比较快?底层原理(哈希表由链表和数组构成 查询效率高 增删效率也高)
lvs有几种模式 :
- NAT(Network Address Translation):lvs中只改目的ip,而nginx改源和目的ip
- 客户端的请求被转发到后端的真实服务器上,同时返回的数据包经过LVS集群的前端节点进行源地址转换,以便客户端能够接收到回复。
- NAT 模式下,LVS 节点必须能够直接与所有后端服务器通信,且所有服务器都必须与LVS节点在一个私有网络内。 支持的real service比较少:10
- 易于实现,不需要更改后端服务器的配置,但所有返回的流量都要经过LVS节点,可能成为瓶颈。
- DR(Direct Routing)模式:直接路由
- LVS 节点将客户端的请求以二层广播的方式发送到后端服务器,后端服务器直接回复给客户端,不经过 LVS 节点。
- 这要求所有的服务器和 LVS 节点都在同一个物理网络上,且后端服务器的网卡必须配置为混杂模式。网速快 效率高 好 支持更多real service 100
- DR 模式可以有效避免 LVS 成为流量瓶颈,因为它只处理出站流量。
- TUN(IP Tunneling)(IPIP)模式:隧道
- LVS 节点将客户端请求封装到新的 IP 数据包中,然后以三层隧道的方式发送到后端服务器。后端服务器(real service 上面也有vip,所以可以直接回复)解封装请求,处理后直接回复给客户端。
- 这种模式允许后端服务器和 LVS 节点不在同一物理网络,甚至可以在不同的地理位置。不常用 公网网络不稳定
- TUN 模式增加了额外的网络开销,因需要进行封装和解封装,但它提供了更好的灵活性和可扩展性。
为什么k8s选择ipvs:

僵尸进程: 子进程退出,父进程没有使用wait()系统调用去回收子进程的pcb,导致子进程的信息任然在内核空间里,消耗了内存空间,死而不化像僵尸一样存在。 把父进程删掉 交由进程号为1的init进程处理 会反复wait
fork() --》创建子进程的--》linux、unix系统
系统调用-》操作系统里的一个功能
wait() -->回收子进程的pcb-->释放子进程的空间
exit() -->结束进程,释放内存空间
把父进程下面的子进程的空间都释放
[root@k8s-master-1 nginx]# cat lu.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <linux/wait.h>
int main(int argc,char **argv)
{
int i=0;
pid_t pid=fork();
if(pid==-1) return 0;
else if(pid==0)
{
printf("son pid is %d\n",getpid());
while(1)
{
printf("son---i=%d\n",i);
i++;
//子进程运行的时间是10秒
sleep(1);
if(i==10)
break;
}
printf("son is over!\n");
}else if(pid>0)
{
printf("parent pid is %d\n",getpid());
while(1)
{ // 设置父进程运行的时间为20秒,看20秒后,父进程退出,操作系统是否回收僵尸进程的pcb
sleep(1);
i++;
if(i==30)
// break;
exit(0); //退出程序
} }
return 0; }
[root@k8s-master-1 nginx]# gcc -o lu lu.c
service类型:
clusterIP: pod这能在k8s集群内部访问
NodePort : 允许外面的机器可以通过访问node节点服务器的ip和端口,在映射到pod
ipvs有规则链chain(对数据包进行过滤处理): input,output,forward(处理转发数据包),postrouting(在进行路由选择后处理数据包),prerouting 不指定的话默认所有链
如果转发数据(充当路由器),路径为prerouting->forword->postrouting
规则表:raw表,mangle表,nat表(网络地址转换),filter表(数据过滤 默认) 表存放链,链放规则
哈希函数:任意个字符的输入经过哈希函数处理后得到固定长度长度字符串的输出
输出的字符串称呼hash值(摘要值),ipvs采用了所以支持大规模,查找速度快
iptables [-t 表名] 管理选项 [链名] [条件匹配] [-j 目标动作或跳转] -A INPUT
[root@localhost ~]# iptables -t filter -A(在末尾加apppend) INPUT -p(协议) tcp -j ACCEPT (放行)DROP(丢弃数据包)REJECT(拒绝)
[root@localhost ~]# iptables -I INPUT -p udp -j ACCEPT
[root@localhost ~]# iptables -I INPUT 2 -p icmp -j ACCEPT
[root@localhost ~]# iptables -P INPUT DROP
iptables -L -n -v 看全部详细
[root@localhost ~]# iptables -L(list) INPUT --line-numbers(--line显示编号)-v
Chain INPUT (policy DROP)
num target prot opt source destination
1 ACCEPT udp -- anywhere anywhere
2 ACCEPT icmp -- anywhere anywhere
3 ACCEPT tcp -- anywhere anywhere
-F 清楚filter表所有规则
-i(在开始insert) INPUT --dport --sport
端口匹配
使用“--sport 源端口”、“--dport 目标端口”的形式
采用“端口1:端口2”的形式可以指定一个范围的端口
iptables中dnat和snat: 改变数据包的目标地址或源地址。这两种技术广泛应用于路由器和防火墙中,以实现私有网络访问公共网络、负载均衡、隐藏内部网络结构等功能。
DNAT(Destination NAT)改变数据包的目标地址:让外面的服务器可以访问内部的相当于k8s 的service
- 将对外公开的IP地址和端口映射到内部网络中的一台或多台服务器上。
- 实现负载均衡,将请求分发到不同的后端服务器。
实现方式: 在PREROUTING链中,使用-j DNAT跳转目标,指定需要转换的目标地址和端口。将所有对192.168.1.1:80的HTTP请求重定向到192.168.2.2:8080:
iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to-destination 192.168.2.2:8080
SNAT(Source NAT)局域网里的机器访问外网 改变数据包的源地址
- 允许私有网络中的设备通过公共IP地址访问互联网。
- 隐藏内部网络结构,对外部网络屏蔽内部IP地址。
实现方式: 在POSTROUTING链中,使用-j SNAT跳转目标,指定需要转换的源地址。例如,将所有从192.168.1.0/24网络发出的数据包的源地址改为192.168.1.1:
iptables -t nat -A POSTROUTING -s 192.168.1.0/24
iptables实现负载均衡原理
1.DNAT:通过在 iptables 的 nat 表的 PREROUTING 链中使用 DNAT 规则,可以修改进入的数据包的目标 IP 地址,将其重定向到集群中的某台后端服务器。
2.连接跟踪:确保 iptables 的 mangle 表中有相应的规则来标记新的连接,并且 nat 表的 POSTROUTING 链中也有相应的 SNAT 规则,以确保响应数据包能够正确返回到客户端。
[root@k8s-master-1 nginx]# echo $RANDOM |md5sum
6475adbb760c4cc8689ce972d66ea2fb -
[root@k8s-master-1 nginx]# echo $RANDOM |md5sum
0eff3102013e7f484d1d7bbe32b70f17 -
[root@k8s-master-1 nginx]# iptables -L --line|more
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 cali-INPUT all -- anywhere anywhere /* cali:Cz_u1IQiXIMmKD4c */
2 KUBE-NODE-PORT all -- anywhere anywhere /* kubernetes health check rules */
3 KUBE-FIREWALL all -- anywhere anywhere
Chain FORWARD (policy ACCEPT)
num target prot opt source destination
1 cali-FORWARD all -- anywhere anywhere /* cali:wUHhoiAYhphO9Mso */
2 KUBE-FORWARD all -- anywhere anywhere /* kubernetes forwarding rules */
3 DOCKER-USER all -- anywhere anywhere
4 DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere
5 ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED
6 DOCKER all -- anywhere anywhere
7 ACCEPT all -- anywhere anywhere /* cali:S93hcgKJrXEqnTfs */ /* Policy explicitly accepted packet. */ mark match 0x10000/0x10000
Chain OUTPUT (policy ACCEPT)
num target prot opt source destination
1 cali-OUTPUT all -- anywhere anywhere /* cali:tVnHkvAo15HuiPy0 */
2 KUBE-FIREWALL all -- anywhere anywhere
- kube-proxy (创建service.将pod发布出去)可以使用 iptables 或 ipvs 模式来实现服务的网络代理。
- iptables (使用链表,数据过滤,防火墙功能)模式较为成熟,但在大规模集群中可能因规则数量过多而影响性能。
- ipvs (Hash表)模式在大型集群中提供了更好的可扩展性和性能,尤其是在高并发和大量服务的情况下,它利用更高效的数据结构和负载均衡算法来优化服务的响应时间和资源利用率(有健康检查机制,检测后端服务器可用性)
相关文章:
proxy负载均衡
endpoint : 终点、终端 看service服务器的ip kubectl get ep backend -> real server :真正提供web服务的服务器 负载均衡器 load balancer --》LB USER -->LB --->BACKEND(real server) nginx SERVICE --->很多的endpoint--》po…...

两个若依系统,不能同时登录问题解决方案
原因: 问题根源在于两个独立的系统(A系统与B系统)共享了同一cookie键名来存储各自用户的认证令牌(token)。这种设计导致了以下情形: 当用户在A系统登录后,一个token被存储在cookie中࿰…...

Unity Render Streaming项目实践经验
UnityRenderStreaming项目 项目github地址见上,我使用项目的3.1.0-exp.7版本、Unity 2023.1.0版本、windows11运行。 1下载项目包 2在Unity Hub中打开RenderStreaming~文件夹 3在package manager中导入com.unity.renderstreaming package 因为已经下载过了就选择install pa…...
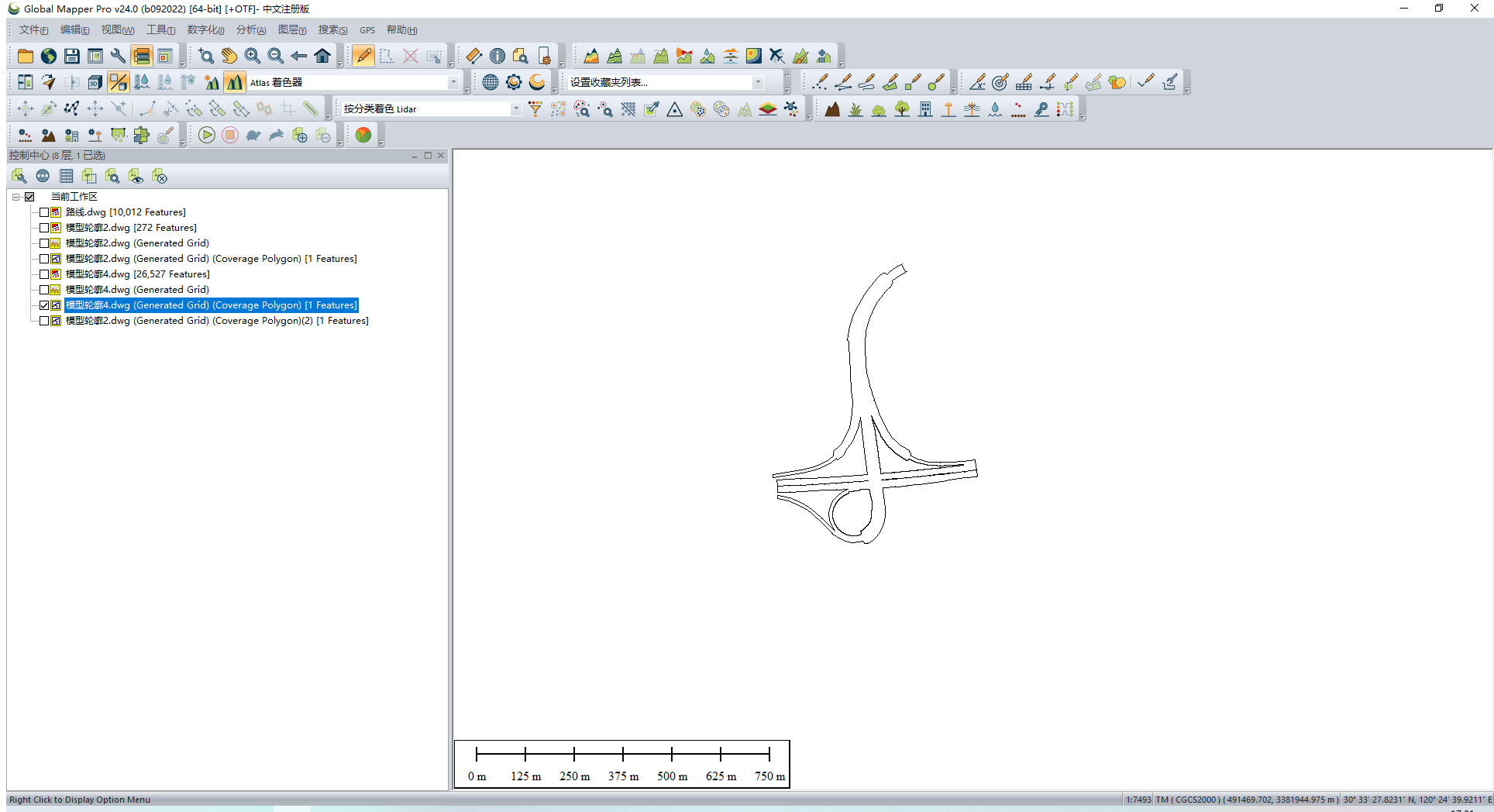
Rvt/dgn格式的模型如何提取外轮廓,用于压平倾斜模型或者地形,进行BIM+GIS融合
0序 很多设计院、施工单位都需要做BIMGIS的融合,把设计成果或者施工方案和现状实景做叠加。 BIM作为设计模型和现状的实景是不吻合的,多数都需要在现状的基础上进行改造,穿过村落的桥梁,已有立交的跨域等。为了更好的展示设计方案…...

sqli-labs-master靶场通关
目录 一、sqli-labs第一关 1.判断是否存在sql注入 (1)提示输入数字值的ID作为参数,输入?id1 (2)通过数字值不同返回的内容也不同,所以我们输入的内容是带入到数据库里面查询了 (3࿰…...

hive sql 处理多层 json 数组
1. 背景 json 字符串值数据示例: {"score": 1,"submitTime": 1712491933,"answerFlag": 1,"groupId": 1755547960,"answers": [{"value": "[1, 2, 3]","ids": [4,5,6],"is…...
)
Dom 元素转换 Image 图片 (截图)
Dom 元素转换 Image 图片 (截图) dom-to-image dom-to-image NPM 官网文档 参考文章码上行舟 dom-to-image 是如何将 html 转换成图片的(文章参考) 安装 npm install dom-to-image --save 使用 /* in ES 6 */ import domtoimage from "dom-to-image"; /* in ES 5 *…...
)
零售业务产品系统应用架构设计(二)
ETC信用结算系统根据《加快推进高速公路电子不停车快捷收费应用服务实施方案》(发改基础〔2019〕935号),拓宽ETC发行服务渠道。推动建立全网协同服务模式,完善服务规则,鼓励银行业金融机构、非银行支付机构和互联网企业等服务机构紧密合作。允许ETC绑定既有银行账户和支付…...

Linux速成入门教程——从零基础开始快速入门,一文了解Linux用户管理与权限
2.1 用户与组管理 用户与组的基本概念 在Linux系统中,用户和组是管理权限和资源访问的基本单元。每个用户都有一个唯一的用户ID(UID),每个组都有一个唯一的组ID(GID)。用户可以属于一个或多个组ÿ…...

网工内推 | 宁德时代IT运维,晋升空间大,带薪年假,包吃包住
01 宁德时代 🔷招聘岗位:IT运维服务 🔷任职要求 1、大专及以上学历专业不限,应届毕业生或计算机、网络维护等相关专业优先; 2、具备较强的服务意识和良好的语言表达能力、沟通能力、记忆能力、心理承受能力和学习能力…...

Linux---系统安全
文章目录 系统安全系统账号清理密码安全控制命令历史限制终端自动注销如设置时间短的处理方式 使用su命令切换用户用途及用法密码验证限制使用su命令的用户查看su操作记录限制使用su命令的用户查看su操作记录su命令的安全隐患 PAM(Pluggable Authentication Modules)可插拔式认…...

手写数字识别实战
全部代码: import matplotlib.pyplot import torch from torch import nn # nn是完成神经网络相关的一些工作 from torch.nn import functional as F # functional是常用的一些函数 from torch import optim # 优化的工具包import torchvision from matplotlib …...

二叉树遍历
二叉树的遍历是二叉树操作中的一个基本且重要的概念,它指的是按照一定的规则访问二叉树中的每个节点,并且每个节点仅被访问一次。常见的二叉树遍历方式有四种:前序遍历(Pre-order Traversal)、中序遍历(In-…...

uni app 调用前置摄像头
uniapp开发app并没有相关Api调用前置摄像头。只能使用5app的api 调用前置摄像头拍照 plus.camera.getCamera(index) 获取需要操作的摄像头对象,如果要进行拍照或摄像操作,需先通过此方法获取摄像头对象 index指定要获取摄像头的索引值,1表…...

哈工大李治军老师OS课程笔记(4)——内存管理
一 内存使用与分段(实验六) 内存是如何用起来的? 内存使用:将程序放在内存中,PC指向开始地址 重定位:修改程序中的地址(是相对地址) 什么时候完成重定位? 编译时加基址…...

代码随想录算法训练营第43天:动态规划part10:子序列问题
300.最长递增子序列 力扣题目链接(opens new window) 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2…...

传智教育引通义灵码进课堂,为技术人才教育学习提效
7 月 17 日,阿里云与传智教育在阿里巴巴云谷园区签署合作协议,双方将基于阿里云智能编程助手通义灵码在课程共建、品牌合作及产教融合等多个领域展开合作,共同推进 AI 教育及相关业务的发展,致力于培养适应未来社会需求的高素质技…...
企业信息化建设搞得好了叫系统工程,搞不好叫面子工程
2024-06-13 09:26贝格前端工场...

程序员如何平衡日常编码工作与提升式学习?
在快速变化的编程领域中,平衡日常编码工作与个人成长确实是一个重要且富有挑战性的议题。以下是我对这一问题的看法和建议: 1. 认识到平衡的重要性 首先,理解两者之间的平衡并非零和游戏,而是相辅相成的。高效的编码工作能够为个…...

Linux---文件系统和日志分析
文章目录 文件系统和日志分析inode和block概述inode包含文件的元信息用stat命令可以查看某个文件的inode信息Linux系统文件三个主要的时间属性 目录文件的结构用户通过文件名打开文件时,系统内部的过程查看inode号码的方法硬盘分区后的结构访问文件的简单流程inode的…...

设计程序统计行业淡季旺季,职场工作量数据,合理调配人力,解决忙闲不均,人力资源浪费职场现状。
一、实际应用场景描述在许多行业(如零售、旅游、物流、电商、教育培训等)中,普遍存在明显的季节性波动:- 旺季:订单/任务激增,员工超负荷加班- 淡季:业务量骤减,人员闲置、工时不足-…...

MediaCreationTool.bat:Windows部署自动化脚本封装架构深度解析
MediaCreationTool.bat:Windows部署自动化脚本封装架构深度解析 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

从‘一片蓝’到‘五彩斑斓’:手把手教你美化Matlab三维柱状图,让论文图表脱颖而出
从‘一片蓝’到‘五彩斑斓’:科研级Matlab三维柱状图视觉优化全攻略 当审稿人翻开一篇论文时,图表往往是他们最先注意到的元素。我曾参与过多次学术期刊的评审工作,那些配色考究、细节精致的图表总能在第一时间抓住眼球——这不仅仅是审美问题…...

收藏!小白也能看懂大模型:从入门到实战的AI学习指南
2026年春招中,AI岗位激增12倍,平均月薪超6万元,成为企业争夺焦点。大模型算法、多模态技术等前沿领域人才需求暴涨,AI已从实验室概念进入规模化落地阶段。教育体系面临挑战,需提前培养AI启蒙能力,打破传统专…...

Altium Designer 系统偏好设置全解析:从新手到高手的效率跃迁
1. Altium Designer系统偏好设置的重要性 刚接触Altium Designer时,我和大多数新手一样,只关注画原理图、布局布线这些核心功能。直到有次看到同事操作,同样的操作他只用我三分之一的时间完成,我才意识到系统偏好设置的重要性。这…...

网络安全协议验证不求人:手把手教你用VirtualBox导入SPAN虚拟机跑AVISPA
网络安全协议验证实战:VirtualBoxSPAN虚拟机快速搭建AVISPA实验环境 在网络安全研究领域,协议验证是确保通信安全性的关键环节。AVISPA(Automated Validation of Internet Security Protocols and Applications)作为自动化验证工…...

WarcraftHelper:免费终极指南,让魔兽争霸III在现代系统上流畅运行
WarcraftHelper:免费终极指南,让魔兽争霸III在现代系统上流畅运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHel…...

JPlag:源代码相似性检测与抄袭识别的核心技术解析
JPlag:源代码相似性检测与抄袭识别的核心技术解析 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag JPlag是一…...
)
老笔记本焕发第二春:微星GT60升级GTX1060保姆级避坑指南(含硬件ID修改)
微星GT60笔记本升级GTX1060全流程实战:从硬件改造到驱动破解 当手头的微星GT60笔记本逐渐跟不上现代游戏需求时,许多玩家会考虑升级显卡来延续它的使用寿命。MXM接口的GTX1060显卡因其性价比和性能表现成为热门选择,但整个升级过程充满技术陷…...

use Hyperf\View\View;的生命周期的庖丁解牛
它的本质是:Hyperf\View\View 不是一个简单的工具类,而是一个由 Hyperf DI 容器管理的 服务实例 (Service Instance)。它的生命周期始于 容器启动时的元数据注册,经历 请求触发时的懒加载/实例化,执行 模板解析与渲染,…...