深度学习 Day28——利用Pytorch实现好莱坞明星识别
深度学习 Day28——利用Pytorch实现好莱坞明星识别
文章目录
- 深度学习 Day28——利用Pytorch实现好莱坞明星识别
- 一、前言
- 二、我的环境
- 三、前期工作
- 1、导入依赖项设置GPU
- 2、导入数据集
- 3、划分数据集
- 四、调用官方的VGG16模型
- 五、训练模型
- 1、编写训练函数
- 2、编写测试函数
- 3、设置动态学习率
- 4、正式训练
- 5、保存模型
- 六、结果可视化
- 1、Loss与Accuracy图
- 2、图片预测
- 3、模型评估
- 七、动态学习率
- 八、最后我想说
一、前言
🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍦 参考文章:Pytorch实战 | 第P6周:好莱坞明星识别
🍖 原作者:K同学啊|接辅导、项目定制

本期博客主要学习动态学习率的学习以及调用VGG16网络框架。
二、我的环境
- 电脑系统:Windows 11
- 语言环境:Python 3.8.5
- 编译器:Datalore
- 深度学习环境:
- torch 1.12.1+cu113
- torchvision 0.13.1+cu113
- 显卡及显存:RTX 3070 8G
三、前期工作
1、导入依赖项设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warningswarnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
2、导入数据集
data_dir = 'E:\深度学习\data\Day15'
data_dir = pathlib.Path(data_dir) # 转换为pathlib对象
data_paths = list(data_dir.glob('*')) # 获取所有子目录
classeNames = [str(path).split('\\')[4] for path in data_paths] # 获取所有子目录的名称
classeNames
['Angelina Jolie','Brad Pitt','Denzel Washington','Hugh Jackman','Jennifer Lawrence','Johnny Depp','Kate Winslet','Leonardo DiCaprio','Megan Fox','Natalie Portman','Nicole Kidman','Robert Downey Jr','Sandra Bullock','Scarlett Johansson','Tom Cruise','Tom Hanks','Will Smith']
data_transforms = transforms.Compose([ # 数据预处理transforms.Resize([224, 224]), # 缩放图片(Image),保持长宽比不变,最短边为224像素# transforms.CenterCrop(224),transforms.ToTensor(), # 将图片(Image)转成Tensor,归一化至[0, 1]transforms.Normalize(mean=[0.485, 0.456, 0.406], # 标准化至[-1, 1],规定均值和标准差std=[0.229, 0.224, 0.225]) # [0.485, 0.456, 0.406]是ImageNet数据集的均值,[0.229, 0.224, 0.225]是ImageNet数据集的标准差
])
total_data = datasets.ImageFolder(data_dir, transform=data_transforms)
total_data
Dataset ImageFolderNumber of datapoints: 1800Root location: E:\深度学习\data\Day15StandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
total_data.class_to_idx # 类别索引
{'Angelina Jolie': 0,'Brad Pitt': 1,'Denzel Washington': 2,'Hugh Jackman': 3,'Jennifer Lawrence': 4,'Johnny Depp': 5,'Kate Winslet': 6,'Leonardo DiCaprio': 7,'Megan Fox': 8,'Natalie Portman': 9,'Nicole Kidman': 10,'Robert Downey Jr': 11,'Sandra Bullock': 12,'Scarlett Johansson': 13,'Tom Cruise': 14,'Tom Hanks': 15,'Will Smith': 16}
total_data.transform # 用于训练的数据预处理
Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
3、划分数据集
train_size = int(0.8 * len(total_data)) # 训练集大小
val_size = len(total_data) - train_size # 验证集大小
train_data, val_data = torch.utils.data.random_split(total_data, [train_size, val_size]) # 随机划分训练集和验证集
train_data, val_data
(<torch.utils.data.dataset.Subset at 0x2a9f997a7c0>,<torch.utils.data.dataset.Subset at 0x2a9f997a070>)
batch_size = 32 # 批次大小
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=1) # 训练集
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=True, num_workers=1) # 验证集
for X, y in train_loader: # 获取一个batch的数据print('X:', X.shape, 'type:', X.dtype) # X为图片数据,y为标签print('y:', y.shape, 'type:', y.dtype)break
X: torch.Size([32, 3, 224, 224]) type: torch.float32
y: torch.Size([32]) type: torch.int64
四、调用官方的VGG16模型
from torchvision.models import vgg16 # 加载预训练模型
device = 'cuda' if torch.cuda.is_available() else 'cpu' # 判断是否有GPU
print("Using {} device".format(device)) # 输出使用的设备
model = vgg16(pretrained=True) # 加载预训练模型
for param in model.parameters(): # 冻结参数param.requires_grad = False # 不需要计算梯度model.classifier[6] = nn.Linear(4096, len(classeNames)) # 修改最后一层全连接层
model
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=17, bias=True))
)
五、训练模型
1、编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
2、编写测试函数
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
3、设置动态学习率
learning_rate = 1e-4
lambda1 = lambda epoch: 0.95 ** (epoch // 4)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
或者
from torch.nn.parameter import Parameter
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR
from torch.utils.data import Dataset
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, lr=0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(20):for batch_idx in range(3):optimizer.zero_grad()loss = torch.randn(1, requires_grad=True)loss.backward()optimizer.step()
4、正式训练
import copy
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数
epochs = 40 # 训练次数train_loss, val_loss = [], [] # 记录训练集和验证集的损失
train_acc, val_acc = [], [] # 记录训练集和验证集的准确率
best_acc = 0 # 记录最佳准确率for epoch in range(epochs): # 训练循环for epoch in range(epochs): # 更新学习率(使用自定义学习率时使用)# adjust_learning_rate(optimizer, epoch, learn_rate)model.train() # 训练模式epoch_train_acc, epoch_train_loss = train(train_loader, model, loss_fn, optimizer) # 训练scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)model.eval() # 验证模式epoch_test_acc, epoch_test_loss = test(val_loader, model, loss_fn) # 验证# 保存最佳模型到 best_modelif epoch_test_acc > best_acc: # 如果当前模型的准确率大于之前的最佳准确率best_acc = epoch_test_acc # 更新最佳准确率best_model = copy.deepcopy(model) # 保存最佳模型train_acc.append(epoch_train_acc) # 记录训练集和验证集的准确率train_loss.append(epoch_train_loss) # 记录训练集和验证集的损失val_acc.append(epoch_test_acc) # 记录训练集和验证集的准确率val_loss.append(epoch_test_loss) # 记录训练集和验证集的损失# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,epoch_test_acc*100, epoch_test_loss, lr))
5、保存模型
PATH = './cifar_net.pth'
torch.save(model.state_dict(), PATH) # 保存模型
print("Model saved")
六、结果可视化
1、Loss与Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2、图片预测
from PIL import Imageclasses = list(total_data.class_to_idx) # 获取类别名称def predict_one_image(image_path, model, transform, classes): # 预测单张图片test_img = Image.open(image_path).convert('RGB') # 读取图片plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img) # 图片预处理img = test_img.to(device).unsqueeze(0) # 增加一个维度model.eval() # 模型评估模式output = model(img) # 预测_,pred = torch.max(output,1) # 获取预测结果pred_class = classes[pred] # 获取预测类别print(f'预测结果是:{pred_class}') # 打印预测结果
# 预测训练集中的某张照片
predict_one_image(image_path='E:\\深度学习\\data\\Day15\\Leonardo DiCaprio\\002_86e8aa58.jpg',model=model,transform=data_transforms,classes=classes)
3、模型评估
best_model.eval() # 模型评估模式
epoch_test_acc, epoch_test_loss = test(train_loader, best_model, loss_fn) # 测试集准确率
print(f'最佳模型的测试集准确率为:{epoch_test_acc*100:.2f}%')
七、动态学习率
在 PyTorch 中,我们可以通过调整学习率来优化神经网络的训练。动态学习率是指在训练过程中,根据当前的迭代轮数或其他条件来动态调整学习率。以下是几种常用的设置动态学习率的方法:
-
学习率衰减:学习率随着训练轮数的增加而逐渐减小。例如,可以使用 PyTorch 中的
torch.optim.lr_scheduler模块来实现学习率衰减,其中包括了很多种学习率调度器。下面是一个例子:import torch.optim as optim from torch.optim.lr_scheduler import StepLR# 创建一个优化器和一个学习率调度器 optimizer = optim.SGD(model.parameters(), lr=0.1) scheduler = StepLR(optimizer, step_size=10, gamma=0.1)for epoch in range(100):# 在每个 epoch 结束时更新学习率scheduler.step()# 训练代码train(...)这个例子中,使用了
StepLR学习率调度器,它会在每个step_size轮训练之后,将学习率乘以gamma。也就是说,每经过step_size轮训练,学习率就会降低一个数量级。 -
基于损失值的学习率调整:学习率随着损失值的变化而调整。当损失值开始变化缓慢时,就可以适当减小学习率。例如,可以使用 PyTorch 中的
torch.optim.lr_scheduler.ReduceLROnPlateau学习率调度器来实现基于损失值的学习率调整。下面是一个例子:import torch.optim as optim from torch.optim.lr_scheduler import ReduceLROnPlateau# 创建一个优化器和一个学习率调度器 optimizer = optim.SGD(model.parameters(), lr=0.1) scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=True)for epoch in range(100):# 训练代码train(...)# 在每个 epoch 结束时计算验证集的损失值,并更新学习率val_loss = validate(...)scheduler.step(val_loss)这个例子中,使用了
ReduceLROnPlateau学习率调度器,它会在损失值不再明显下降时,适当减小学习率。具体来说,如果在patience个 epoch 中,损失值没有下降,则将学习率乘以factor。 -
循环学习率:学习率在一个区间内来回循环变化,以帮助模型跳出局部最优解。例如,可以使用 PyTorch 中的
torch.optim.lr_scheduler.CyclicLR学习率调度器来实现循环学习率。下面是一个例子:import torch.optim as optim from torch.optim.lr_scheduler import CyclicLR# 创建一个优化器和一个学习率调度器 optimizer = optim.SGD(model.parameters(), lr=0.1) scheduler = CyclicLR(optimizer, base_lr=0.001, max_lr=0.1, step_size_up=100, cycle_momentum=False)for epoch in range(100):# 训练代码train(...)# 在每个 epoch 结束时更新学习率scheduler.step()这个例子中,使用了
CyclicLR学习率调度器,它会在一个区间内来回循环变化学习率。具体来说,学习率会从base_lr增加到max_lr,然后又降回base_lr,如此往复。其中,step_size_up指定了每个循环中学习率从base_lr增加到max_lr的轮数。cycle_momentum参数可以选择是否在循环中改变动量的大小。
八、最后我想说
本期博客出现了一些问题,在训练的时候报错:AttributeError: 'list' object has no attribute 'train',目前还没有解决,一开始是我自己重新写的一份代码,然后报这个错误,然后我使用K老师的源码跑也不行,就很迷茫。目前还不知道如何解决。
相关文章:
深度学习 Day28——利用Pytorch实现好莱坞明星识别
深度学习 Day28——利用Pytorch实现好莱坞明星识别 文章目录深度学习 Day28——利用Pytorch实现好莱坞明星识别一、前言二、我的环境三、前期工作1、导入依赖项设置GPU2、导入数据集3、划分数据集四、调用官方的VGG16模型五、训练模型1、编写训练函数2、编写测试函数3、设置动态…...

Android中使用FCM进行消息推送
Firebase Cloud Message 的介绍 Firebase Cloud Message(FCM)是由Google推出的一种云端消息推送服务,它是由Google推出的Google Cloud Messaging(GCM)服务的升级版。在2016年5月,Google宣布将Google Cloud Messaging重命名为Firebase Cloud Message,作为Firebase的一部…...
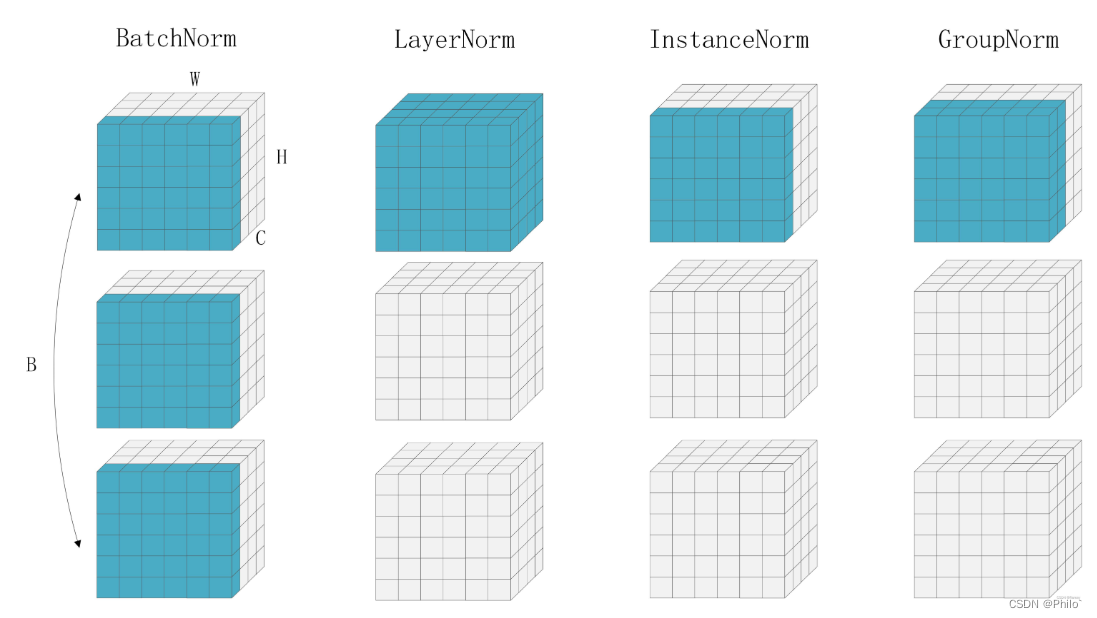
从 X 入门Pytorch——BN、LN、IN、GN 四种归一化层的代码使用和原理
Pytorch中四种归一化层的原理和代码使用前言1 Batch Normalization(2015年提出)Pytorch官网解释原理Pytorch代码示例2 Layer Normalization(2016年提出)Pytorch官网解释原理Pytorch代码示例3 Instance Normalization(2…...

Windows环境下实施域名访问的一些小知识
文章目录 前言一、windows域名访问流程二、网络域名访问配置设置DNS未正确设置DNS的结果三、本地hosts设置本地hosts本地hosts的优先机制本地hosts的内部访问次序示例一示例二总结前言 作为一种常见的操作系统,windows系统具有其特殊的域名访问管理机制。了解其访问机制,将有…...

78.qt QCustomPlot介绍
参考https://www.qcustomplot.com/index.php/tutorials/settingup 下载地址: https://www.qcustomplot.com/index.php/download 1.添加帮助文档 在QtCreator ——>工具——>选项——>帮助——>文档——>添加,选择qcustomplot.qch文件,确定,以后按F1就能跳转到…...
win32api之文件系统管理(七)
什么是文件系统 文件系统是一种用于管理计算机存储设备上文件和目录的机制。文件系统为文件和目录分配磁盘空间,管理文件和目录的存储和检索,以及提供对它们的访问和共享,以下是常见的两种文件系统: NTFSFAT32磁盘分区容量2T32G…...

点云规则格网化,且保存原始的点云索引
点云规则格网化,且保存原始的点云索引 点云深度学习Voxelize规则,参考PTV2:https://github.com/Gofinge/PointTransformerV2 1总执行文件 import numpy as np import torch from pcr.utils.registry import Registry TRANSFORMS Registry…...
入职第一天就被迫离职,找工作多月已读不回,面试拿不到offer我该怎么办?
大多数情况下,测试员的个人技能成长速度,远远大于公司规模或业务的成长速度。所以,跳槽成为了这个行业里最常见的一个词汇。 前言 前几天,我们一个粉丝跟我说,正常入职一家外包,什么都准备好了࿰…...
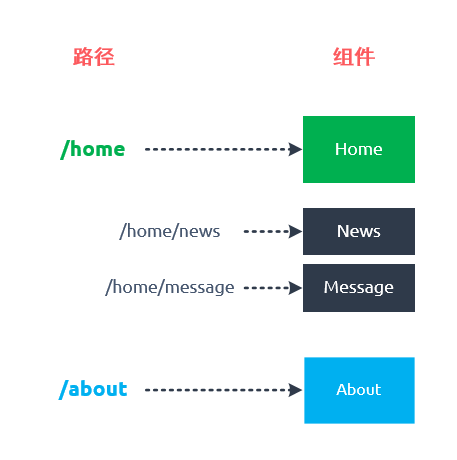
走进Vue【三】vue-router详解
目录🌟前言🌟路由🌟什么是前端路由?🌟前端路由优点缺点🌟vue-router🌟安装🌟路由初体验1.路由组件router-linkrouter-view2.步骤1. 定义路由组件2. 定义路由3. 创建 router 实例4. 挂…...

html+css制作
<!DOCTYPE html> <html><head><meta charset"utf-8"><title>校园官网</title><style type"text/css">*{padding: 0;margin: 0;}#logo{width:30%;float: left;}.nav{width: 100%;height: 100px;background-color…...

Python实现rar、zip和7z文件的压缩和解压
一、7z压缩文件的压缩和解压 1、安装py7zr 我们要先安装py7zr第三方库: pip install py7zr如果python环境有问题,执行上面那一条安装语句老是安装在默认的python环境的话,我们可以执行下面这条语句,将第三方库安装在项目的虚拟…...

从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala
从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala 前言 【本文适合有一定计算机基础/半年工作经验的读者食用。立个Flg,愿天下不再有肤浅的SQL Boy】 谈到大数据开发,占据绝大多数人口的就是SQL Boy,不接受反驳,毕竟大…...
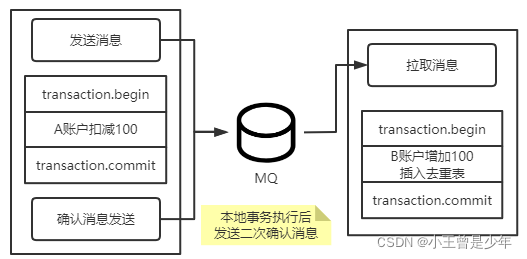
RocketMQ 事务消息 原理及使用方法解析
🍊 Java学习:Java从入门到精通总结 🍊 深入浅出RocketMQ设计思想:深入浅出RocketMQ设计思想 🍊 绝对不一样的职场干货:大厂最佳实践经验指南 📆 最近更新:2023年3月24日 &#x…...

为什么 ChatGPT 输出时经常会中断,需要输入“继续” 才可以继续输出?
作者:明明如月学长, CSDN 博客专家,蚂蚁集团高级 Java 工程师,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《EffectiveJava》独家解析》专栏作者。 热门文章推荐…...

PyTorch 之 基于经典网络架构训练图像分类模型
文章目录一、 模块简单介绍1. 数据预处理部分2. 网络模块设置3. 网络模型保存与测试二、数据读取与预处理操作1. 制作数据源2. 读取标签对应的实际名字3. 展示数据三、模型构建与实现1. 加载 models 中提供的模型,并且直接用训练的好权重当做初始化参数2. 参考 pyto…...

Scrapy的callback进入不了回调方法
一、前言 有的时候,Scrapy的callback方法直接被略过了,不去执行其中的回调方法,可能排查好久都排查不出来,我来教大家集中解决方法。 yield Request(urlurl, callbackself.parse_detail, cb_kwargs{item: item})二、解决方法 1…...

第二十一天 数据库开发-MySQL
目录 数据库开发-MySQL 前言 1. MySQL概述 1.1 安装 1.2 数据模型 1.3 SQL介绍 1.4 项目开发流程 2. 数据库设计-DDL 2.1 数据库操作 2.2 图形化工具 2.3 表操作 3. 数据库操作-DML 3.1 增加(insert) 3.2 修改(update) 3.3 删除(delete) 数据库开发-MySQL 前言 …...

蓝桥杯每日一真题—— [蓝桥杯 2021 省 AB2] 完全平方数(数论,质因数分解)
文章目录[蓝桥杯 2021 省 AB2] 完全平方数题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1样例 #2样例输入 #2样例输出 #2提示思路:理论补充:完全平方数的一个性质:完全平方数的质因子的指数一定为偶数最终思路:小插曲&am…...
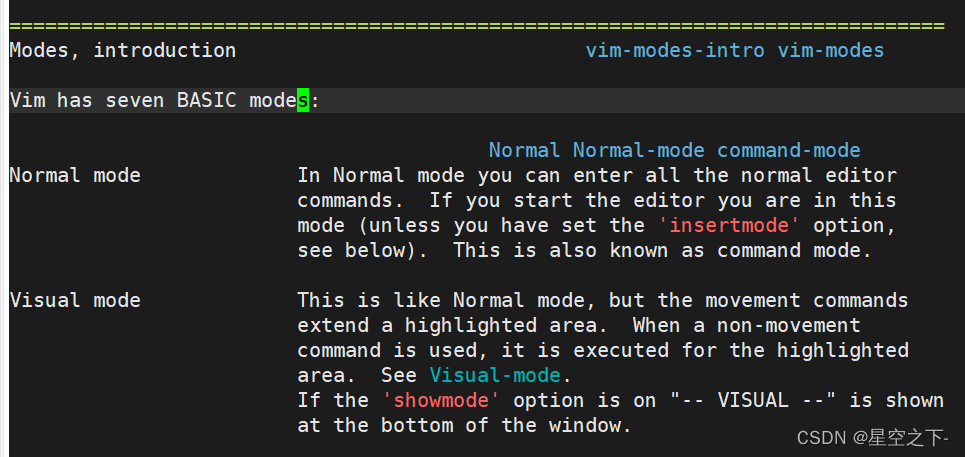
Linux编辑器-vim
一、vim简述1)vi/vim2)检查vim是否安装2)如何用vim打开文件3)vim的几种模式命令模式插入模式末行模式可视化模式二、vim的基本操作1)进入vim(命令行模式)2)[命令行模式]切换至[插入模式]3)[插入模式]切换至[命令行模式]4)[命令行模…...
5G将在五方面彻底改变制造业
想象一下这样一个未来,智能机器人通过在工厂车间重新配置自己,从多条生产线上组装产品。安全无人机处理着从监视入侵者到确认员工停车等繁琐的任务。自动驾驶汽车不仅可以在建筑物之间运输零部件,还可以在全国各地运输。工厂检查可以在千里之…...

深入理解VideoCrafter:DDPM3D和DDIM采样算法在高质量视频生成中的应用
深入理解VideoCrafter:DDPM3D和DDIM采样算法在高质量视频生成中的应用 【免费下载链接】VideoCrafter VideoCrafter1: Open Diffusion Models for High-Quality Video Generation 项目地址: https://gitcode.com/gh_mirrors/vi/VideoCrafter VideoCrafter是一…...

团队知识协作平台:构建高效智能的文档管理系统
团队知识协作平台:构建高效智能的文档管理系统 【免费下载链接】outline Outline 是一个基于 React 和 Node.js 打造的快速、协作式团队知识库。它可以让团队方便地存储和管理知识信息。你可以直接使用其托管版本,也可以自己运行或参与开发。源项目地址&…...

AI 大模型绘图日常使用教程|零门槛上手,快速出图不踩坑
摘要日常办公、学习中,我们经常需要各类图片 ——PPT 配图、工作流程图、活动海报、课件插画等,手动绘制耗时费力,专业设计软件又难上手。本文整合目前最实用、免费 / 低成本的 AI 绘图大模型,从工具选择、基础操作到进阶技巧&…...
)
微信850协议实战:泡泡玛特小程序授权不掉线全流程解析(附源码)
微信850协议深度应用:构建高稳定小程序授权体系的技术实践 在移动互联网生态中,微信小程序已成为连接用户与服务的重要桥梁。对于开发者而言,如何确保授权流程的稳定性,特别是在需要长期维持登录状态的场景下,成为技术…...

理论框架总搭不起来?资深导师力荐这几个AI写作辅助平台
写论文时,理论框架总是理不顺、逻辑不清晰?很多同学都遇到过这样的问题。其实,关键在于用对工具、走对流程——资深教授普遍建议,结合AI写作辅助平台能大幅提升效率。我们实测发现,千笔AI(中文全流程首选&a…...

终极指南:5分钟为群晖Audio Station添加QQ音乐歌词插件
终极指南:5分钟为群晖Audio Station添加QQ音乐歌词插件 【免费下载链接】qq_music_aum Synology LRC Plugin. 群晖 Audio Station 歌词插件,歌词来自QQ音乐。 项目地址: https://gitcode.com/gh_mirrors/qq/qq_music_aum 还在为群晖Audio Station…...

低成本AI方案:OpenClaw对接本地Qwen3.5-9B替代ChatGPT API
低成本AI方案:OpenClaw对接本地Qwen3.5-9B替代ChatGPT API 1. 为什么选择本地部署Qwen3.5-9B? 作为一名长期使用OpenAI API的开发者,我最近开始尝试将OpenClaw与本地部署的Qwen3.5-9B模型对接。这个转变源于一个简单但痛苦的事实࿱…...

Jira替代工具如何选?2026年推荐十款适合小团队且容易上手项目管理平台
在数字化转型浪潮席卷全球的背景下,企业尤其是科技驱动型组织正加速将敏捷与精益理念融入核心运营流程。根据Gartner发布的报告,到2025年,超过80%的软件项目将采用敏捷或混合开发模式,这使得能够支撑高效协作与透明化管理的项目管…...

MSG文件高效提取工具:解放双手的Outlook邮件解析方案
MSG文件高效提取工具:解放双手的Outlook邮件解析方案 【免费下载链接】msg-extractor Extracts emails and attachments saved in Microsoft Outlooks .msg files 项目地址: https://gitcode.com/gh_mirrors/ms/msg-extractor 副标题:你是否还在为…...

挖到宝!PFC2D 流固耦合常用案例合集,科研人速进
该模型是“PFC2D流固耦合常用案例合集”: 其中包括水力压裂、达西渗流等多个案例。 有需要学习和交流的伙伴可按需选取。 干货满满,是运用pfc5.0做流固耦合必不可少的科研学习资料性价比绝对超高 内容可编辑,觉得运行通畅 代码真实有效。最近…...