FastAPI部署大模型Llama 3.1
项目地址:[self-llm/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md at master · datawhalechina/self-llm (github.com)](https://github.com/datawhalechina/self-llm/blob/master/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md)
目的:使用AutoDL的深度学习环境,简单部署大模型
## 环境准备
考虑到部分同学配置环境可能会遇到一些问题,我们在AutoDL平台准备了LLaMA3-1的环境镜像,点击下方链接并直接创建Autodl示例即可。 ***https://www.codewithgpu.com/i/datawhalechina/self-llm/self-llm-llama3.1***
首先 `pip` 换源加速下载并安装依赖包
```
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.111.1
pip install uvicorn==0.30.3
pip install modelscope==1.16.1
pip install transformers==4.42.4
pip install accelerate==0.32.1
```
## 模型下载
模型下载社区有魔塔和huggingface(被墙,可能不能使用),所以同意使用魔塔社区的方式下载模型
新建 `model_download.py` 文件并在其中输入以下内容,粘贴代码后请及时保存文件,如下图所示。并运行 `python model_download.py` 执行下载,模型大小为 15GB,下载模型大概需要15 分钟。
```python
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3.1-8B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
```

> 注意:如果模型下载失败,可以多试几次:运行 `python model_download.py`
## API部署代码
新建 `api.py` 文件并在其中输入以下内容,粘贴代码后请及时保存文件(Ctrl+`s`)。以下代码有很详细的注释
```
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM
import uvicorn
import json
import datetime
import torch
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
prompt = json_post_list.get('prompt') # 获取请求中的提示
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
# 调用模型进行对话生成
input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"status": 200,
"time": time
}
# 构建日志信息
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/LLM-Research/Meta-Llama-3___1-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16)
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用
```
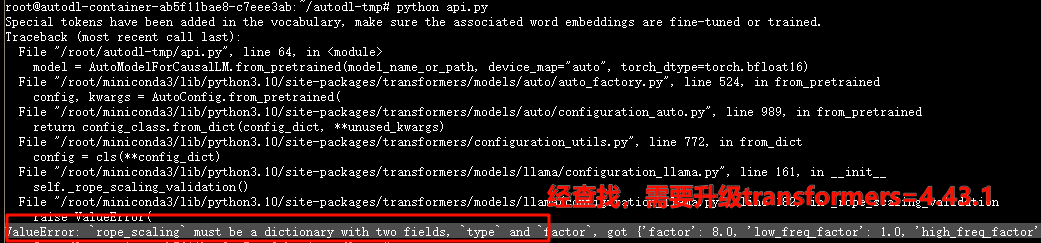
运行以上代码 `python api.py`
> 如果遇到以下bug:需要`pip install transformers==4.43.1`
## 部署测试
在终端输入以下命令启动api服务:
```
python api.py
```
加载完毕后出现如下信息说明成功。
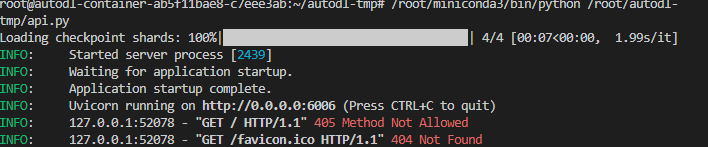
默认部署在 6006 端口,通过 POST 方法进行调用,可以使用 curl 调用,如下所示:

- `curl`: 这是命令行工具的名字,用于从服务器获取或发送数据。
- `-X POST`: 这个选项指定了请求类型为 `POST`。`POST` 请求通常用于向服务器发送数据。
- `"http://127.0.0.1:6006"`: 这是请求的目标 URL。`127.0.0.1` 是本地回环地址,意味着请求将被发送到同一台计算机上运行的服务。`6006` 是服务监听的端口号。
- `-H 'Content-Type: application/json'`: 这个选项设置了请求头 (`Header`) 中的 `Content-Type` 字段为 `application/json`。这告诉服务器发送的数据是 JSON 格式。
- `-d '{"prompt": "你好"}'`: 这个选项指定了要发送的数据体 (`Body`)。在这里,数据是一个 JSON 对象,其中包含一个键值对,键是 `"prompt"`,值是 `"你好"`。这个数据体将作为请求的一部分发送给服务器。
也可以使用 python 中的 requests 库进行调用,我们新建一个test.ibynb文件,复制如下代码,按`Enter+Shift`运行代码。
```
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
if __name__ == '__main__':
print(get_completion('我写了一篇文章:FastAPI部署大模型Llama3.1。你帮我写一段总结,100字以内'))
```
输出结果如下:

**部署大模型Llama 3.1 到 FastAPI**
本文介绍了如何将大模型Llama 3.1 部署到 FastAPI,一个现代、快速、强大的 Python web 框架。通过本教程,你将学习如何将 Llama 3.1 集成到 FastAPI 中,并利用其强大的自然语言处理能力来构建智能应用。
本文涵盖了以下内容:
* 安装和设置 FastAPI
* 下载和部署 Llama 3.1 模型
* 使用 FastAPI 与 Llama 3.1 进行交互
本教程适合任何对 AI 和机器学习感兴趣的开发者。
相关文章:

FastAPI部署大模型Llama 3.1
项目地址:[self-llm/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md at master datawhalechina/self-llm (github.com)](https://github.com/datawhalechina/self-llm/blob/master/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md) …...

C++拾趣——编译器预处理宏__COUNTER__的应用场景
大纲 生成唯一标识符调试信息宏展开模板元编程代码 在C中,__COUNTER__是一个特殊的预处理宏,它主要被用来生成唯一的整数标识符。这个宏是由一些编译器(如GCC和Visual Studio)内置支持的,而不是C标准的一部分。它的主要…...

使用HTML和cgi实现网页登录功能
0.HTML文件结构 一.HTML文件 1.test.html <!DOCTYPE html> <html><head><meta charset"utf-8"><title>菜鸟教程(runoob.com)</title></head><body><!-- 将结果提交给/cgi-bin/test.cgi下 --><form actio…...
Java流程控制01:用户交互Scanner
本节教学视频链接:https://www.bilibili.com/video/BV12J41137hu?p33&vd_sourceb5775c3a4ea16a5306db9c7c1c1486b5https://www.bilibili.com/video/BV12J41137hu?p33&vd_sourceb5775c3a4ea16a5306db9c7c1c1486b5 Scanner 类用于扫描输入文本从字符串中提…...

什么是回滚
回滚(Rollback)是指当程序或数据出现错误时,将程序或数据恢复到最近一个正确版本或上一次正确状态的行为。回滚机制在软件开发、数据库管理、系统部署等多个领域都有广泛应用,旨在保证系统的稳定性和数据的完整性。以下是关于回滚…...

Java项目通过IDEA远程debug调试
前言 在我们真实项目开发过程中,又是经常会发现一种问题,就是我们在开发环境功能是正常的,在测试环境可能也不太容易发现问题。 结果到了生产环境,由于数据量大,且数据类型变多后,就产生了一些比较难复现…...

Python 绘图入门
数据可视化的概念及意义 数据可视化有着久远的历史,最早可以追溯至10世纪,至今已经应用和发展了数百年。不知名的天文学家是已知的最早尝试以图形方式显示全年当中太阳,月亮和行星的位置变化的图。 图1 数据可视化的发展历程 什么是数据可视…...
RK3568平台(背光篇)背光驱动代码分析
一.背光驱动设备树DTS backlight: backlight {compatible "pwm-backlight";pwms <&pwm1 0 5555555 1>;brightness-levels <77 77 78 78 79 79 80 8182 83 84 85 86 87 87 8888 89 90 90 91 91 92 9394 94 95 95 96 96 9…...

华为od统一考试B卷【比赛】python实现
def split_params(param_str): return list(map(int, param_str.split(,))) def main(): # 获取输入 target_str input().strip() # 输入验证,拆分并转换为整数 try: m, n split_params(target_str) except ValueError: print(-1) return # 检查 M 和 …...

Prometheus 监控接入规范
目录 一、目的 二、自定义监控指标定义规范 2.1 基本命名规范 2.1.1 指标命名规范 2.1.2 标签名称 2.2 控制基数 2.2.1 避免高基数标签 2.2.2 预定义标签集 2.2.3 动态数据的处理 2.2.4 评估与监控基数 2.2.5 降低历史数据的保留 2.2.6 适当使用 Histogram 和 Summa…...

优化 SQL 查询性能:深入理解 EXPLAIN 命令
优化 SQL 查询性能:深入理解 EXPLAIN 命令 在 MySQL 数据库管理中,优化 SQL 查询性能是确保高效数据处理的关键。EXPLAIN 命令是分析和优化 SQL 查询的强大工具,它帮助我们理解查询执行计划,从而找到性能瓶颈并进行优化。本文将详细解释 EXPLAIN 命令返回的各个列的含义,…...

@Mapper报红
检查pom.xml,导入 org.mybatis.spring.boot 依赖: <dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency…...

shell综合小实验1-----查看系统硬件信息
echo命令的使用 1:echo -n 不换行 echo -n “我是个大聪明” #不换行输入我是大聪明 2:echo -e 开启颜色 echo -e "\03335m我是大聪明\033[0m" #用35m这种颜色输出我是大聪明然后关闭颜色显示, 30多是字体颜色,40多是…...

【过程管理】项目需求管理规程(Word原件)
在软件开发的过程中,开发人员与用户之间往往忽视有效的信息沟通,这常常导致开发出的软件无法满足用户的实际需求,进而引发不必要的返工。返工不仅为开发人员带来技术上的困扰,增加了人力和物力的消耗,还会对软件的整体…...

C# 不使用 `async` 和 `await` 的常见场景
虽然 async 和 await 是强大的异步编程工具,但在某些情况下,不使用它们可能更合适。以下是一些不使用 async 和 await 的常见场景: 方法是完全同步的: 如果方法中的所有操作都是同步的,并且没有异步调用,则…...

adb目录笔记《adb更新、进入开发者模式,adb查询packages、adb开启应用,查询进程、强制删除进程》
1.sideload模式 在需要安卓没有root权限的时候,可以使用adb reboot sideload命令进入sideload模式,之后运行对应文件 adb reboot sideload adb sideload <root.zip> 2.packages包查询、运行、删除 在需要查看安卓中packages包的名称时…...

VS2022 C++ EasyX EGE 吃豆人升级版
我是可爱的C小盆友(不要脸了),嘻嘻,等了这么久,吃豆人终于升级啦! 更新日志: 1.修复奇奇怪怪的bug 2.把敌人AI增强了一(hen)点(duo) 3.加入了…...

计算机图形学 | 动画模拟
动画模拟 布料模拟 质点弹簧系统: 红色部分很弱地阻挡对折 Steep connection FEM:有限元方法 粒子系统 粒子系统本质上就是在定义个体和群体的关系。 动画帧率 VR游戏要不晕需要达到90fps Forward Kinematics Inverse Kinematics 只告诉末端p点,中间…...

B2.3 Arm 内存模型定义
B2.3 Arm 内存模型定义 Arm 内存模型引入了以下几种关系: 内在关系 :例如,内在数据/控制/顺序依赖关系和内在翻译之前的关系,这些是源自指令语义的硬件要求。 之后关系 :例如,之后的连贯性和 TLB 之后的关系,这些关系在特定执行中发生这种方式,但在不同的执行中可以以…...

(javaweb)SpringBootWeb案例(毕业设计)案例--部门管理
目录 1.准备工作 2.部门管理--查询功能 3.前后端联调 3.部门管理--新增功能 1.准备工作 mapper数据访问层相当于dao层 根据页面原型和需求分析出接口文档--前后端必须遵循这种规范 大部分情况下 接口文档由后端人员来编写 前后端进行交互基于restful风格接口 http的请求方式…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...