颠覆传统 北大新型MoM架构挑战Transformer模型,显著提升计算效率
 挑战传统的Transformer模型设计
挑战传统的Transformer模型设计
在深度学习和自然语言处理领域,Transformer模型已经成为一种标准的架构,广泛应用于各种任务中。传统的Transformer模型依赖于一个固定的、按深度排序的层次结构,每一层的输出都作为下一层的输入。这种设计虽然简单有效,但也存在参数冗余和计算效率低下的问题。
最近,一项新的研究提出了一种名为“Mixture-of-Modules”(MoM)的新架构,旨在打破这种固定层次的传统,通过动态组装不同的模块来计算每个token,从而提高模型的灵活性和计算效率。这种设计允许模型在不同层之间自由地“移动”计算,而不是严格遵循从浅层到深层的顺序。MoM通过引入两个路由器动态选择不同的注意力模块和前馈网络模块,组合成一个完整的计算图,实现了对传统Transformer的一种创新性改进。
这项研究不仅挑战了Transformer的传统设计,还展示了在保持相当性能的同时,如何显著减少计算资源的消耗。通过这种新的架构设计,MoM在多个基准测试中展示了其优越性,包括GLUE和XSUM,证明了其在处理深度和参数数量上的灵活性。
先看结论
1. 主要优势
MoM架构的主要优势包括:
- 提供了一个统一的框架,将多种Transformer变体(如混合专家、提前退出和混合深度等)纳入其中,为未来的架构设计提供了新的思路。
- 在前向计算中引入了前所未有的灵活性,使得“深度”和“参数数量”不再像传统方式那样紧密耦合,用户可以通过扩大模块池或增加深度来构建更强大的架构。
- 通过合理配置模块和压缩模型深度,实现了与传统Transformer相当的性能,同时显著降低了计算资源的消耗。
2. 实验结果
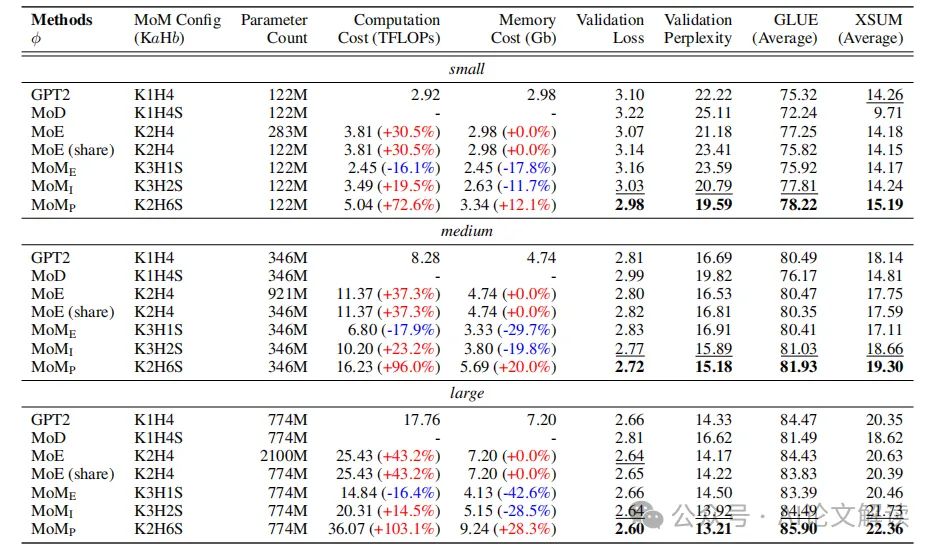
通过在不同的参数规模上预训练MoM模型,并在GLUE和XSUM基准测试中进行评估,实验结果显示:
- 在所有参数规模上,MoM模型一致地超越了传统的GPT-2模型。
- MoM架构能够在保持性能的同时,显著减少计算资源的消耗,特别是在大规模模型上,资源节约更为显著。
论文标题: MIXTURE-OF-MODULES: REINVENTING TRANSFORMERS AS DYNAMIC ASSEMBLIES OF MODULES
机构: Peking University, Renmin University, Tsinghua University, Ant Group
论文链接: https://arxiv.org/pdf/2407.06677.pdf。
MoM架构概述
Mixture-of-Modules (MoM) 是一种新颖的架构,旨在打破传统的 Transformer 模型中深度有序的层次结构。MoM的核心思想是将神经网络定义为由传统 Transformer 派生的模块的动态组装。这些模块包括多头注意力(MHA)、前馈网络(FFN)和特殊的“SKIP”模块,每个模块都具有独特的参数化。
在 MoM 中,每个令牌的计算图是通过两个路由器动态选择注意力模块和前馈模块并在前向传递中组装这些模块来形成的。这种机制不仅提供了一个统一的框架,将各种 Transformer 变体纳入其中,还引入了一种灵活且可学习的方法来减少 Transformer 参数化中的冗余。
MoM的设计允许在不同的层之间自由地移动令牌的计算,这一点与传统的从浅层到深层的顺序不同。这种设计使得深度和参数数量不再像传统架构中那样紧密耦合,从而为构建更强大的架构提供了更大的灵活性。
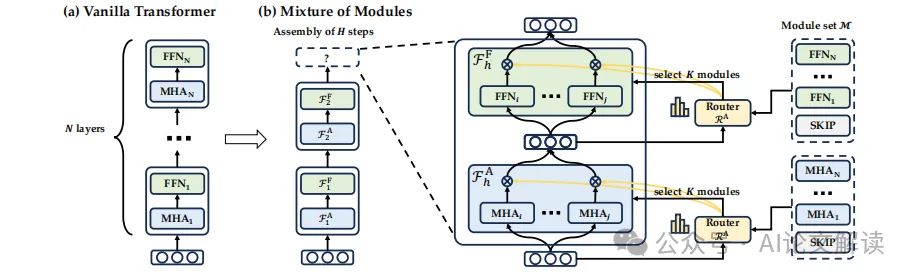
模块动态组装机制
在 MoM 中,模块的动态组装是通过一个迭代过程实现的,每个令牌在每一步都可能被分配到不同的模块。这一过程由两个专门的路由器控制,分别用于选择 MHA 和 FFN 模块。每个路由器输出一个分布,指示每个模块被选中的权重。
在每一步中,根据路由器的输出,选择权重最大的 K 个模块进行组装。这些模块通过一个组装函数联合起来,形成该步骤的输出。这个过程不仅仅是简单的层叠,而是一个根据令牌的需求动态调整的过程,使得每个令牌都可以在最适合它的模块中被处理。
此外,MoM 采用了一种两阶段训练方法来优化这一动态组装过程。首先,在大规模语料库上预训练一个标准的 Transformer,然后将其分解为模块,并用这些模块初始化 MoM,同时随机初始化路由器。在第二阶段,继续在相同的数据和目标上训练模块和路由器,以此来加速模型的收敛并提高参数的利用率。
通过这种动态组装机制,MoM 能够在保持与传统 Transformer 相当的性能的同时,显著减少前向计算中的 FLOPs 和内存使用。
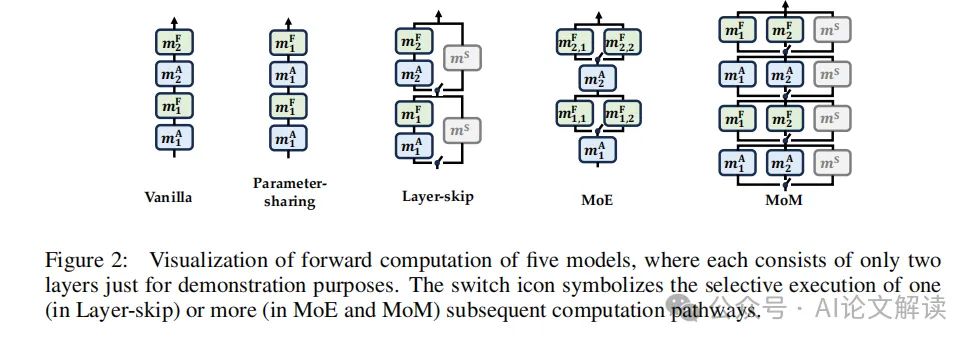
训练策略与实验设置
1. 实验模型与配置
实验中,我们采用了三种不同规模的MoM模型:MoM-small、MoM-medium和MoM-large,分别包含122M、346M和774M参数。在训练过程中,我们使用了官方的GPT-2模型作为MoM的初始化基础,这些模型从HuggingFace平台下载。
2. 训练数据与预处理
我们使用OpenWebText作为预训练数据集,该数据集经过标记后包含约9亿个token。从中随机抽取400万token作为验证集。所有模型的输入序列长度设置为1024。我们设置学习率为1e-3,并在两个训练阶段中均采用0.1的预热比例,不使用dropout。所有模型均在8×A100 GPU上训练,总批量大小为8×64。
3. 训练策略
我们采用了两阶段训练策略。在第一阶段,我们在大规模语料库上预训练一个标准的Transformer模型,以此来初始化MoM的模块集合。第二阶段,我们从头开始初始化路由器,继续使用相同的数据和目标训练模块和路由器。这种方法不仅增强了模块功能的专业化,还加速了模型的收敛。
实验结果与分析
1. 主要结果
实验结果表明,MoM在保持参数数量不变的情况下,通过更深的计算图(H)在GLUE和XSUM基准测试中一致地超越了所有基线模型。MoM的增强性能验证了我们的初衷:传统的深度有序层组织是次优的,可以通过动态模块组织和改进参数利用率来实现改进。
MoM的不同实例在资源成本上也显示出显著差异。例如,MoME-medium和MoME-large在资源成本上的减少比MoME-small更为显著。这些观察结果进一步强化了我们之前的动机:Transformer的过度参数化在模型规模增大时变得更加明显。
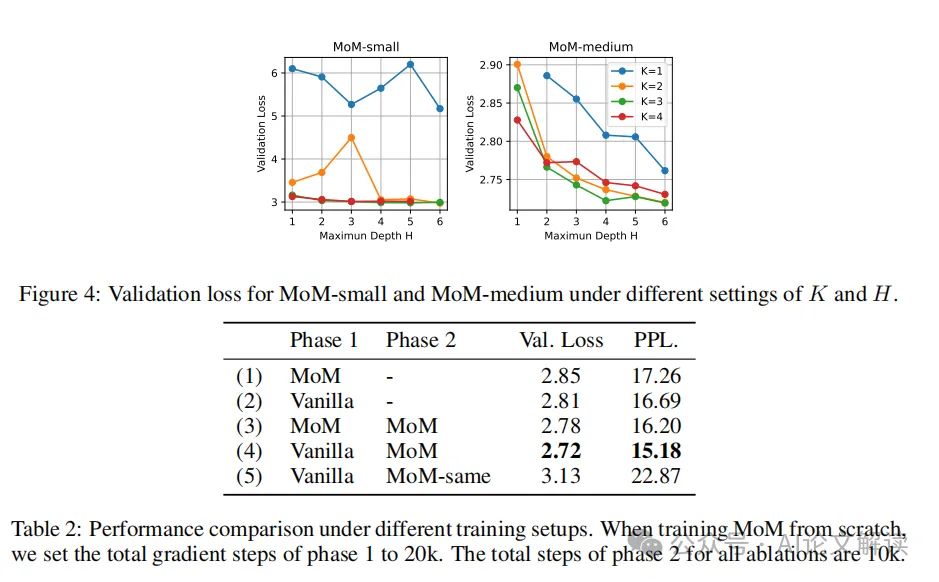
2. 训练策略的影响
我们研究了两阶段训练策略对模型性能的影响。结果显示,与从头开始训练MoM相比,使用预训练的Transformer模型初始化模块权重的两阶段策略具有更好的性能。这一发现强调了使用良好训练的Transformer模型为MoM初始化模块权重的重要性。
此外,我们还观察到,当减少MHA模块的数量时,损失的显著增加并不会立即出现,这表明Transformer中的MHA模块存在相当的冗余。相比之下,当逐渐减少FFN模块的数量时,每次移除一个FFN都会导致明显的损失增加,表明FFN模块的参数化较少冗余。
相关文章:
颠覆传统 北大新型MoM架构挑战Transformer模型,显著提升计算效率
挑战传统的Transformer模型设计 在深度学习和自然语言处理领域,Transformer模型已经成为一种标准的架构,广泛应用于各种任务中。传统的Transformer模型依赖于一个固定的、按深度排序的层次结构,每一层的输出都作为下一层的输入。这种设计虽然…...

接口优化笔记
索引 添加索引 where条件的关键自动或者order by后面的排序字段可以添加索引加速查询 索引只能通过删除新增进行修改,无法直接修改。 # 查看表的索引 show index from table_name; show create table table_name; # 添加索引 alter table table_name add index …...

pandas 科学计数法显示
我注意到pandas中有一个问题, 默认情况下,就是其中的数据的小数位不能超过6位,比如0.0000007就会被显示为0,这个结果如下 全部以科学技术显示 import pandas as pd import numpy as np# 设置显示格式为科学计数法 pd.options.d…...

PHP正则替换字符串中的图片地址
在PHP中,可以使用preg_replace()函数来实现正则表达式的替换功能。以下是一个简单的例子,演示如何替换字符串中的图片地址。 double $str 图片地址1:<img src"http://example.com/image1.jpg"> 图片地址2:<i…...

基于多商户AI智能名片商城小程序的粉丝忠诚度提升策略:深度融合足额法则与多维度激励体系
摘要:在数字化浪潮的推动下,多商户AI智能名片商城小程序以其独特的商业模式和技术优势,正逐步成为连接商家与消费者,特别是粉丝群体的重要平台。本文深入探讨了如何通过深度融合足额法则与多维度激励体系,有效提升多商…...

BigDecimal高精度运算
1. BigDecimal是什么类型,为什么可以转为double BigDecimal 是 Java 中用于表示任意精度的十进制数的类。它主要用于金融和商业计算,能够提供比 double 类型更高精度的运算,特别是在处理货币等需要精确计算的场景中。 1.1 BigDecimal 的基…...

C/C++实现蓝屏2.0
🚀欢迎互三👉:程序猿方梓燚 💎💎 🚀关注博主,后期持续更新系列文章 🚀如果有错误感谢请大家批评指出,及时修改 🚀感谢大家点赞👍收藏⭐评论✍ 前…...

Unity音频管理器插件AudioToolKit
Unity音频管理器插件AudioToolKit 介绍AudioToolKit介绍具体用法总结 介绍 最近在自己写音频管理器的时候在网上发现了一款比较好用并且功能很全的一个音频管理插件,叫做AudioToolKit的插件。 如果需要的可以直接从我资源中找AudioToolKit。 AudioToolKit介绍 A…...
搜维尔科技:驾驶模拟器背后的技术: Varjo的虚拟/混合现实 (VR/XR)提供独特的优势,最终加快汽车开发创新的步伐
专业驾驶模拟器广泛应用于车辆开发,帮助汽车行业在开发过程的早期做出更好的设计决策。总体目标是为测试驾驶员提供最真实的驾驶体验,包括动态动作和声音,并测试控制算法或辅助系统等功能。环境越真实,驾驶员的体验就越接近最终车…...

OSL 冠名赞助Web3峰会 “FORESIGHT2024”圆满收官
OSL 望为香港数字资产市场发展建设添砖加瓦 (香港,2024 年 8 月 13 日)- 8 月 11 日至 12 日, 由 香港唯一专注数字资产的上市公司 OSL 集团(863.HK)冠名赞助,Foresight News、 Foresight Ventu…...

LeetCode 3148.矩阵中的最大得分:每个元素与其左或上元素之差的最大值(原地修改O(1)空间)
【LetMeFly】3148.矩阵中的最大得分:每个元素与其左或上元素之差的最大值(原地修改O(1)空间) 力扣题目链接:https://leetcode.cn/problems/maximum-difference-score-in-a-grid/ 给你一个由 正整数 组成、大小为 m x n 的矩阵 g…...

主流的开源大型语言模型
本期我们来聊聊目前主流的开源大型语言模型。这些模型就像是AI界的超级英雄,各具特色,为我们的研究和开发提供了强大的力量。🚀 GPT-Neo:这是EleutherAI的杰作,它模仿了OpenAI的GPT-3。GPT-Neo虽然规模小一些…...

【自动驾驶】话题通信
目录 构建发布者构建订阅者编写lanch文件自动启动节点测试运行ROS的目录结构 切换到工作空间的src目录下: 构建发布者 catkin_create_pkg publisher std_msgs rospy roscpp编写发布者程序: // 1.包含头文件 #include "ros/ros.h" #include &…...

【Linux】中的软件安装:深入探索RPM、SRPM与YUM
🐇明明跟你说过:个人主页 🏅个人专栏:《Linux :从菜鸟到飞鸟的逆袭》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、Linux的起源与发展 2、RPM、SRPM与YUM的简要介…...

uniapp自定义请求头信息header
添加请求头:uniapp自定义请求头信息header,如下:添加tenant-id参数 代码...
SpringBoot整合Liquibase
1、是什么? Liquibase官网 Liquibase是一个开源的数据库管理工具,可以帮助开发人员管理和跟踪数据库变更。它可以与各种关系型数据库和NoSQL数据库一起使用,并提供多种数据库任务自动化功能,例如数据库迁移、版本控制和监控。Li…...

虚幻5|给武器添加碰撞检测与伤害
本章内容衔接上两章,需要完成上两章才能用本章内容 虚幻5|角色武器装备的数据库学习(不只是用来装备武器,甚至是角色切换也很可能用到)-CSDN博客虚幻5|普通攻击,使用接口更方便-CSDN博客 如有疑问,可访问…...

RESTful API设计指南:构建高效、可扩展的Web服务
目录 引言 一.RESTful API概述 二.设计原则 2.1. 资源导向 2.2. 使用标准的HTTP方法 2.3. 无状态通信 2.4. 可缓存响应 2.5. 分层系统 2.6. 按需加载代码(可选) 2.7. HATEOAS 三.最佳实践 3.1. 明确资源和子资源 3.2. 使用合适的HTTP状态码 …...

黑马头条vue2.0项目实战(九)——编辑用户资料
目录 1. 创建组件并配置路由 2. 页面布局 3. 展示用户信息 4. 修改昵称 5. 修改性别 6. 修改生日 7. 修改头像 7.1 图片上传预览 7.2 使用纯客户端的方式处理用户头像上传预览 7.3 头像裁切 7.4 纯客户端的图片裁切上传流程 7.5 Cropper.js 图片裁剪器的基本使用 …...

43.【C语言】指针(重难点)(F)
目录 15.二级指针 *定义 *演示 16.三级以及多级指针 *三级指针的定义 *多级指针的定义 17.指针数组 *定义 *代码 18.指针数组模拟二维数组 往期推荐 15.二级指针 *定义 之前讲的指针全是一级指针 int a 1; int *pa &a;//一级指针 如果写成 int a 1; int *pa &a…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 [特殊字符]
LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 🎯 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为复盘找不到关键点而烦恼吗?想提升棋力却…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

为什么92%的数据库重构失败?Claude设计辅助如何在48小时内规避反范式陷阱?
更多请点击: https://codechina.net 第一章:为什么92%的数据库重构失败?——反范式陷阱的本质溯源 数据库重构失败率高达92%,其核心症结并非技术能力不足,而是对“反范式”这一设计策略的误读与滥用。许多团队在性能压…...

终极Windows风扇控制指南:FanControl让你的电脑安静又高效
终极Windows风扇控制指南:FanControl让你的电脑安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

NBT数据可视化编辑解决方案:NBTExplorer技术解析与应用指南
NBT数据可视化编辑解决方案:NBTExplorer技术解析与应用指南 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer NBTExplorer是一款面向Minecraft数据管理的…...

YOLO训练前数据检查必备:一个脚本批量转换LabelImg的txt标签并可视化核对
YOLO训练前数据检查实战:批量转换与可视化核验脚本开发指南 在计算机视觉项目的实际落地过程中,数据质量往往比模型架构更能决定最终效果的上限。许多团队花费大量时间调整超参数和网络结构,却忽略了最基础的标注数据验证环节。当使用LabelIm…...