【多模态大模型】LLaMA in arXiv 2023
一、引言
论文: LLaMA: Open and Efficient Foundation Language Models
作者: Meta AI
代码: LLaMA
特点: 该方法在Transformer的基础上增加了Pre-normalization (RMSNorm)、SwiGLU activation function (SwiGLU)、Rotary Embeddings (RoPE)、FlashAttention。
⚠️ 在学习该方法前,建议补充BatchNorm、LayerNorm、位置编码、Attention的相关知识。
二、详情
Transformer和LLaMA的结构图如下:

可见,其结构差异主要体现在如下方面:
- Transformer采用了左编码器+右解码器(Encoder+Decoder)的结构,LLaMA采用了仅解码器(Decoder-only)的结构。由于仅包含解码器不需要与编码器输出交互,故LLaMA去掉了Transformer中Decoder中间的交叉Multi-Head Attention和Add & Norm。
- LLaMA采用了归一化前置(Pre-normalization)的策略,将归一化操作放在了注意力、FFN前并在线性映射前增加了一个归一化。此外,LLaMA还将LayerNorm替换为了
RMSNorm。- LLaMA将绝对位置编码替换为了旋转位置编码,即
RoPE,这是一种只对Q和K进行位置编码的方式。- 为加速训练,LLaMA引入了
FlashAttention。- LLaMA将ReLU替换为了
SwiGLU。
2.1 RMSNorm
均方根归一化RMSNorm简化了LayerNorm的计算。
要了解RMSNorm,首先需回顾LayerNorm的公式:

其中, x \boldsymbol{x} x为输入的token序列, E [ x ] = 1 n ∑ i = 1 n x i {\bf E}\boldsymbol{[x]}=\frac{1}{n}\sum_{i=1}^{n}\boldsymbol{x}_i E[x]=n1∑i=1nxi和 V a r [ x ] = 1 n ∑ i = 1 n ( x i − E [ x ] ) 2 {\bf Var}\boldsymbol{[x]}=\sqrt{\frac{1}{n}\sum_{i=1}^n(\boldsymbol{x}_i-{\bf E}\boldsymbol{[x]})^2} Var[x]=n1∑i=1n(xi−E[x])2为 x \boldsymbol{x} x的均值和有偏方差, ϵ \boldsymbol{\epsilon} ϵ用来防止分母为0, γ \boldsymbol{\gamma} γ和 β \boldsymbol{\beta} β是可学习的参数用来缩放和平移。
RMSNorm简化了LayerNorm的计算,其公式如下:

其中, R M S [ x ] = 1 n ∑ i = 1 n x i 2 {\bf RMS}\boldsymbol{[x]}=\sqrt{\frac{1}{n}\sum_{i=1}^{n}\boldsymbol{x}_i^2} RMS[x]=n1∑i=1nxi2是均方根。
可见,RMSNorm与LayerNorm主要有如下差别:
RMSNorm无需计算均值 E [ x ] {\bf E}[\boldsymbol{x}] E[x]。RMSNorm将有偏方差 V a r [ x ] {\bf Var[\boldsymbol{x}]} Var[x]替换为了均方根 R M S [ x ] {\bf RMS[\boldsymbol{x}]} RMS[x]。RMSNorm无需平移项 γ \boldsymbol{\gamma} γ。
与LayerNorm一样,RMSNorm也能以句子或单词(token)为单位进行归一化,如下给出了以token为单位的代码示例。
import torch
import torch.nn as nnclass MyRMSNorm(nn.Module):def __init__(self, hidden_dim, eps=1e-8):super().__init__()# 防止分母计算为0self._eps = eps# 仿射变换参数,缩放norm后的数据分布self._gamma = nn.Parameter(torch.ones(hidden_dim))def forward(self, input):# input(N,L,C)ms = input.pow(2).mean(dim=-1, keepdim=True) # 计算均方,token-wiseinput = input / torch.sqrt(ms + self._eps) # 执行标准化return input * self._gamma # 仿射变换if __name__ == '__main__':batch_size = 4length = 2hidden_dim = 3input = torch.rand(4, 2, 3)myRMSN = MyRMSNorm(hidden_dim=hidden_dim)MyO = myRMSN(input)pytorchRMSN = nn.RMSNorm(normalized_shape=hidden_dim, elementwise_affine=False) # 不使用可学习的gamma和betapytorchO = pytorchRMSN(input)print(MyO == pytorchO)
2.2 RoPE
旋转位置编码RoPE使用绝对位置信息设计旋转规则,使旋转后的数据能够表达相对位置信息。
要了解RoPE,首先我们来了解一下二维空间的旋转。如下图:

其中, X = [ ρ cos ϕ , ρ sin ϕ ] X=[\rho\cos\phi,\rho\sin\phi] X=[ρcosϕ,ρsinϕ]是一个二维向量,逆时针旋转 θ \theta θ度变成 X R ( θ ) XR(\theta) XR(θ)。此时 R ( θ ) = [ cos θ , sin θ − sin θ , cos θ ] R(\theta)=\left[\begin{matrix}\cos\theta,~\sin\theta\\-\sin\theta,~\cos\theta\end{matrix}\right] R(θ)=[cosθ, sinθ−sinθ, cosθ],证明如下:
X R ( θ ) = [ ρ cos ϕ , ρ sin ϕ ] [ cos θ , sin θ − sin θ , cos θ ] = ρ [ cos ϕ cos θ − sin ϕ sin θ , cos ϕ sin θ + sin ϕ cos θ ] = [ ρ cos ( ϕ + θ ) , ρ sin ( ϕ + θ ) ] XR(\theta)=[\rho\cos\phi,\rho\sin\phi]\left[\begin{matrix}\cos\theta,~\sin\theta\\-\sin\theta,~\cos\theta\end{matrix}\right]\\=\rho[\cos\phi\cos\theta-\sin\phi\sin\theta,\cos\phi\sin\theta+\sin\phi\cos\theta]=[\rho\cos(\phi+\theta),\rho\sin(\phi+\theta)] XR(θ)=[ρcosϕ,ρsinϕ][cosθ, sinθ−sinθ, cosθ]=ρ[cosϕcosθ−sinϕsinθ,cosϕsinθ+sinϕcosθ]=[ρcos(ϕ+θ),ρsin(ϕ+θ)]
可见, X X X与 X R ( θ ) XR(\theta) XR(θ)仅差一个 θ \theta θ,所以二维空间逆时针旋转 θ \theta θ度可通过 R ( θ ) R(\theta) R(θ)实现。
旋转只改变角度,不改变长度。
RoPE将旋转应用在了注意力模块的查询 Q Q Q和 K K K上。它将第 i i i个查询 Q i Q_i Qi旋转 i θ i\theta iθ的角度,再将第 j j j个键 K j K_j Kj旋转 j θ j\theta jθ的角度,那么 Q i K j T Q_iK_j^T QiKjT就会变成一个与相对位置 i − j i-j i−j相关的值。推导过程如下:

i i i和 j j j是查询 Q i Q_i Qi和 K j K_j Kj的绝对位置, i − j i-j i−j是它们的相对位置。
然而, Q i Q_i Qi和 K j K_j Kj的维度通常都是大于2的,我们假设它是 D D D且 D D D是2的整数倍,于是我们可以将 Q i Q_i Qi和 K j K_j Kj分别划分为 d = D 2 d=\frac{D}{2} d=2D个子空间,每个子空间都是二维的。
下图给出了一个 D = 10 D=10 D=10的例子,我们将 Q i Q_i Qi和 K j K_j Kj分为5个子空间并分配1个包括5个角度的旋转序列 Θ = ( θ 1 , θ 2 , ⋯ , θ 5 ) \Theta=(\theta_1,\theta_2,\cdots,\theta_5) Θ=(θ1,θ2,⋯,θ5),每个子空间的旋转角度是在对应旋转序列的基础上乘以 i i i或 j j j。

将其扩展到 d d d个子空间,可以得到如下信息:

其中, X i X_i Xi代指 Q i Q_i Qi或 K j K_j Kj。此时,这种旋转仍然具有相对位置的表达能力,证明如下:

显然,上面的 R ( i Θ ) R(i\Theta) R(iΘ)过于稀疏,为了提升计算效率,通常 d d d个子空间的旋转使用下式表达:

为避免token数过多, i θ k i\theta_k iθk和 j θ k j\theta_k jθk重叠导致相对位置得不到表达(同一个子空间 k k k,绝对位置 i i i和 j j j不同, i θ k − j θ k = 2 m π i\theta_k-j\theta_k=2m\pi iθk−jθk=2mπ时重叠, m m m是一个整数),RoPE使用了一个递减的等比数列作为 θ \theta θ序列,如下:

θ k \theta_k θk是递减的,这表示token中前几个子空间的旋转角度较大,越往后旋转角度越小。
事实上,为了方便我们通常不是将相邻的两个值划分至同一子空间,而是将D分为前后两个部分,前后各取一个依次组成子空间,例如[q0,q1,q2,q3]被划分为[q0,q2], [q1,q3]而不是[q0,q1], [q2,q3]。以下为使用这种方式进行子空间划分的RoPE代码:
from torch.nn import functional as F
import torch.nn as nn
import torch
import mathclass Rotator:"""根据hidden_dim,和position_ids 生成对应的旋转位置编码, 和论文中定义略有不同,一个个二维的子空间被分割到了前后两部分,分别进行旋转,然后拼接起来"""def __init__(self, D, position_ids):""" position_ids: [seq_len], D 和单个头的hidden_dim对应 """base = 10000d = D / 2B = base ** (1/d)theta_base = 1.0 / (B ** (torch.arange(0, d))) # 等比数列, $\Theta$thetas = position_ids.outer(theta_base) # [seq_len, D/2]# 这里的子空间划分与讲解不同,[q0,q1,q2,q3] -> [q0,q2],[q1,q3]是两个子空间而不是[q0,q1],[q2,q3]full_thetas = torch.cat((thetas, thetas), dim=-1) # [seq_len, D]self.cos = full_thetas.cos()self.sin = full_thetas.sin()def rotate(self, x):"""x: [bs, num_attention_heads, seq_len, D]q: [bs, num_attention_heads, seq_len, D]cos: [seq_len, D][x,y] @ [[cos, sin], [-sin, cos]] = [x*cos-y*sin, ycos+x*sin] =[x,y]*cos+[-y, x]*sin"""return x * self.cos + Rotator.reverse_half(x) * self.sin@staticmethoddef reverse_half(q):""" q: [bs, num_attention_heads, seq_len, D] trick2 """u = q[..., :q.shape[-1] // 2] # 认为是各个二维子空间的第一维的向量集结v = q[..., q.shape[-1] // 2:] # 认为是各个二维子空间的第二维的向量集结return torch.cat((-v, u), dim=-1)if __name__ == "__main__":batch_size = 2num_heads = 3D = 6 # 单个头的token向量长度hidden_dim = D * num_headsseq_len = 4position_ids = torch.arange(seq_len)rotator = Rotator(D, position_ids)x = torch.randn((batch_size, seq_len, hidden_dim))# 对每个头分别进行旋转,[batch_size,seq_len,hidden_dim] -> [batch_size,seq_len,num_heads,D] -> [batch_size,num_heads,seq_len,D]x = x.view(batch_size, seq_len, num_heads, D).transpose(1, 2)x = rotator.rotate(x)
2.3 FlashAttention
FlashAttention以分块的形式进行注意力计算,避免了SRAM和HBM之间频繁读写导致的时间浪费。
详情请参考我之前的博客FlashAttention in NeurIPS 2022。
2.4 SwiGLU
激活函数SwiGLU是门控线性单元(Gated Linear Units, GLU)的变体,下图红框中表达了GLU的计算过程:

可见,GLU会先使用两个带偏执的线性层映射输入 x \boldsymbol{x} x,分别记为 x W 1 + b 1 \boldsymbol{xW_1+b_1} xW1+b1和 x W 2 + b 2 \boldsymbol{xW_2+b_2} xW2+b2;其中一个线性映射后会跟一个非线性激活函数sigmoid,记为 σ ( x W 1 + b 1 ) \sigma(\boldsymbol{xW_1+b_1}) σ(xW1+b1);然后将左右两边的结果对应元素相乘即完成了GLU,记为 σ ( x W 1 + b 1 ) ⊗ ( x W 2 + b 2 ) \sigma(\boldsymbol{xW_1+b_1})\otimes(\boldsymbol{xW_2+b_2}) σ(xW1+b1)⊗(xW2+b2)。
SwiGLU对GLU做了两点改进:
- 去掉了两个线性映射的偏执项,此时公式变成 σ ( x W 1 ) ⊗ ( x W 2 ) \sigma(\boldsymbol{xW_1})\otimes(\boldsymbol{xW_2}) σ(xW1)⊗(xW2)。
- 将
sigmoid替换为了Swish,此时公式变成 Swish β ( x W 1 ) ⊗ ( x W 2 ) \text{Swish}_{\beta}(\boldsymbol{xW_1})\otimes(\boldsymbol{xW_2}) Swishβ(xW1)⊗(xW2)。
Swish的公式为 Swish β ( a ) = a σ ( β a ) = a 1 + e − β a \text{Swish}_{\beta}(a)=a\sigma(\beta a)=\frac{a}{1+e^{-\beta a}} Swishβ(a)=aσ(βa)=1+e−βaa,在不同的 β \beta β下该非线性激活函数的曲线如下:

可见,当 β \beta β较大时,该曲线与ReLU十分接近;当 β = 1 \beta=1 β=1时,小于0但接近0的曲线变得更光滑且非单调。
SwiGLU则选用了 β = 1 \beta=1 β=1的Swish,于是我们得到SwiGLU的公式如下:
Swish ( x W 1 ) ⊗ ( x W 2 ) = x W 1 1 + e − x W 1 ⊗ x W 2 \text{Swish}(\boldsymbol{xW_1})\otimes(\boldsymbol{xW_2})=\frac{\boldsymbol{xW_1}}{1+e^{-\boldsymbol{xW_1}}}\otimes\boldsymbol{xW_2} Swish(xW1)⊗(xW2)=1+e−xW1xW1⊗xW2
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
解密旋转位置编码:数学基础、代码实现与绝对编码一体化探索
一文为你深度解析 LLaMA2 模型架构
Llama改进之——SwiGLU激活函数
相关文章:
【多模态大模型】LLaMA in arXiv 2023
一、引言 论文: LLaMA: Open and Efficient Foundation Language Models 作者: Meta AI 代码: LLaMA 特点: 该方法在Transformer的基础上增加了Pre-normalization (RMSNorm)、SwiGLU activation function (SwiGLU)、Rotary Embed…...
java中restful接口和普通接口的区别)
(转)java中restful接口和普通接口的区别
RESTful接口是一种遵循REST(Representational State Transfer)架构风格的网络接口,设计上更倾向于资源的表述,通过HTTP方法(如GET、POST、PUT、DELETE)直接操作资源,使得接口更简洁、易于理解和维护。 与普通接口相比…...
灵办AI免费ChatGPT4人工智能浏览器插件快速便捷(多功能)
灵办AI就是您所需的最佳助手!我们为您带来了一款多功能AI工具,不仅能为您提供精准翻译,还能满足您的对话需求、智能续写、AI搜索、文档阅读、代码生成与修正等多种需求。灵办 AI,真正让工作和学习变得轻松高效! 推荐使…...

VulnHub:BlueMoon
准备工作 靶机下载地址,下载完成后使用virtualbox打开虚拟机,网络设置修改为桥接。 信息收集 主机发现 攻击机ip:192.168.31.218,nmap扫描攻击机同网段存活主机。 nmap 192.168.31.0/24 -Pn -T4 目标靶机ip为:192…...

处理filter里抛出的异常
Filter 的异常是在 org.apache.catalina.core.ApplicationFilterChain.internalDoFilter()这里扔出来的。Filter是tomcat负责调用执行的,所以会比 servlet(尤其是SpringMVC 的dispatcherServlet )先执行,所以 Filter 里的错误&…...

IndexedDB深度解析:JavaScript的客户端数据库
IndexedDB是一个在用户浏览器中运行的低等级API,用于存储大量结构化数据。作为NoSQL数据库,IndexedDB为Web应用程序提供了丰富的数据存储能力,支持键值对存储、索引、事务和复杂查询等功能。本文将详细介绍IndexedDB的基本概念、工作原理、使…...

C语言中的函数指针和返回值为数组的函数指针对比
函数指针 //定义一个函数指针,函数的参数是int型,返回值为int typedef int (*func)(int);//定义一个函数指针,函数的参数是int*型,返回值为int* typedef int* (*func)(int *);定义一个返回值为数组指针的函数 //定义…...

根据字符串的长度和字符值的大小来对字符串切片进行排序
在 Go 语言中,根据字符串的长度和字符值的大小来对字符串切片进行排序。示例如下: package mainimport ("fmt""sort" )// 自定义类型,以实现排序接口 type byLengthAndValue []string// 实现 sort.Interface 的 Len 方法 func (s b…...

RabbitMQ 的工作原理
下面是rabbitmq 的工作原理图解 1、客户端连接到消息队列服务器,打开一个channel。 2、客户端声明一个exchange,并设置相关属性。 3、客户端声明一个queue,并设置相关属性。 4、客户端使用routing key, 在exchange和queue 之间…...

WPF 资源、引用命名空间格式、FrameworkElement、Binding、数据绑定
资源 对象级别独立文件 静态资源使用(StaticResource)指的是在程序载入内存时对资源的一次性使用,之后就不再去访问这个资源了。 动态资源使用(DynamicResource)使用指的是在程序运行过程中仍然会去访问资源。 显然,如果你确定…...

vue3-03-创建响应式数据的几种方法
响应式数据 一、 ref 创建:响应式数据1)ref 创建:基本类型的响应式数据2)ref 创建:对象类型的响应式数据3)volar 插件自动添加 .value4)customRef 自定义 ref 二、 reactive 创建:响…...

stm32智能颜色送餐小车(openmv二维码识别+颜色识别+oled显示)
大家好啊,我是情谊,今天我们来介绍一下我最近设计的stm32产品,我们在今年七月份的时候参加了光电设计大赛,我们小队使用的就是stm32的智能送餐小车,虽然止步于省赛,但是还是一次成长的经验吧,那…...

对接的广告平台越多,APP广告变现的收益越高?
无论是游戏、社交、工具应用类APP还是泛娱乐类APP,流量变现的方式主要有广告、内购、订阅三种方式。其中,广告变现是门槛最低、适用最广的变现方式。 只要APP有流量,就可以进行广告变现,让APP的流量快速转化为商业价值。作为最常…...

LINUX原始机安装JDK
文章目录 下载 JDK压缩包创建jdk文件夹sftp 远程上传解压缩 tar -zxvf 包名配置环境变量刷新 环境变量验证是否安装成功安装JAVA 依赖yum更新及替换镜像curl 命令下载更新更新yum依赖判断repo文件是否存在生成缓存、启用阿里云镜像 重新下载java依赖再次验证hello world 下载 J…...

MR400D工业级带网口4G DTU:RS232/RS485 TO LTE深度测评
在物联网技术日新月异的今天,数据传输的效率和稳定性成为了各行各业关注的焦点。作为一款集先进性与实用性于一身的物联网设备,工业级带网口的4G DTU(数据传输单元)以其强大的功能特性和广泛的应用场景,赢得了市场的广…...

第四范式发布AI+5G视频营销产品 助力精准获客与高效转化
产品上新 Product Release 今天,第四范式AI5G视频电话互动营销产品全新发布。 相较于以往销效率低、互动差、转化差的传统电话外呼和短信营销方式,视频电话互动营销基于AI、5G等技术,可让用户接听电话时观看个性化视频广告并实时互动…...
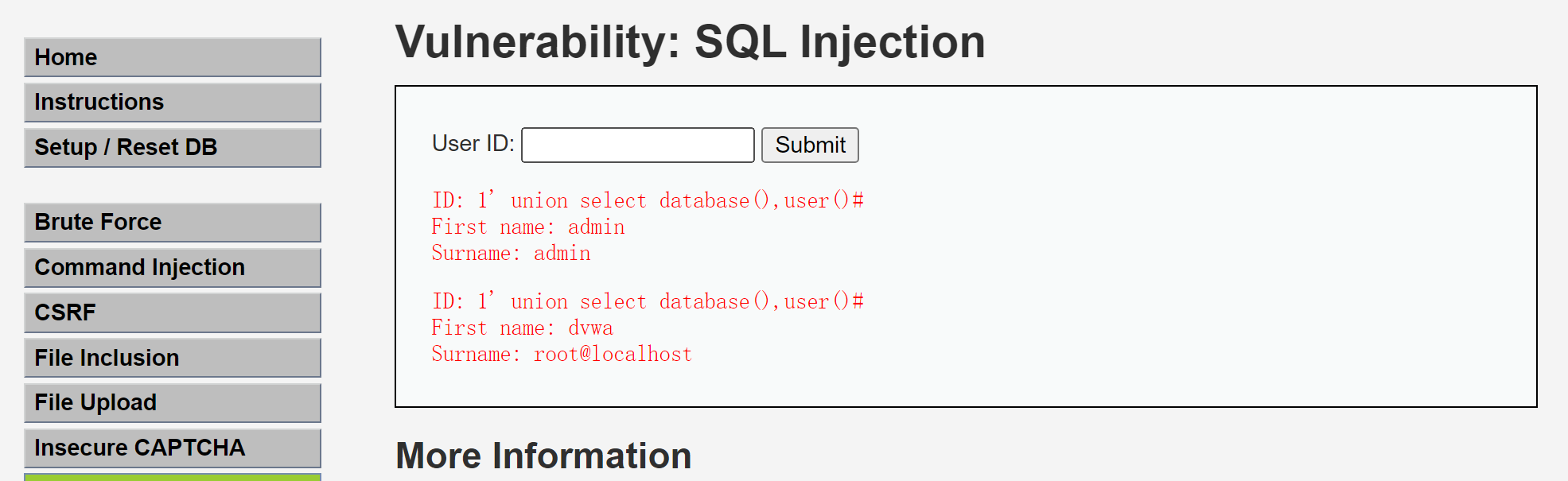
DVWA-IDS测试(特殊版本)
起因 浏览DVWA历史更新记录发现有版本带有IDS插件,可以用于平时没有相关设备等场景演示用,所以开启本次测试。 下载 官方最新版本是移除了IDS插件,原因是“从不使用”,所以需要下载移除该插件之前的版本。 https://github.com/…...

轻度自闭症的温柔启航:星启帆的康复之旅
在儿童成长的道路上,自闭症作为一种复杂的神经发展障碍,给许多家庭带来了挑战与困扰。轻度自闭症,作为自闭症谱系中的一个类型,其症状表现相对较轻,但同样需要我们的关注与科学的干预。星启帆自闭症儿童康复机构&#…...

一、OpenTK简介
文章目录 一、历史和发展二、功能和优势(一)强大的图形渲染功能(二)跨平台支持(三)与 C# 的紧密集成(四)开源和活跃的社区(五)性能优化三、适用场景(一)游戏开发(二)科学计算可视化(三)虚拟现实和增强现实应用(四)图形用户界面开发(五)教育和培训应用(六)…...

Dom4j详细介绍
Dom4j 1.1 解析概览 将数据存储为XML格式后,程序化地访问这些数据变得至关重要。虽然Java基础的IO操作能够实现这一目标,但这一过程往往既复杂又繁琐,尤其是在处理大型文件或需要频繁读写操作的场景下。为了解决这些问题,开发者…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...