Python爬虫使用实例
IDE:大部分是在PyCharm上面写的
解释器装的多 → 环境错乱 → error:没有配置,no model
- 爬虫可以做什么?
下载数据【文本/二进制数据(视频、音频、图片)】、自动化脚本【自动抢票、答题、采数据、评论、点赞】
- 爬虫的原理?
通过模拟/控制浏览器(客户端)批量的向服务器请求数据
- 完成一个完整的爬虫需要的步骤?
获取资源 – 发送请求 – 数据解析 – 保存数据
- 开发者工具 抓包

Headers 头部信息、数据包请求地址、请求方法、响应头、请求头
| Cookie | 用户身份标识 |
| Host | 客户端指定想访问的域名地址 |
| Origin | 资源在服务器的起始位置 |
| Pragma | 请求地址的查看参数 |
| Referer | 防盗链告诉服务器我是从哪个网页跳转过来的 |
| User-agent | 浏览器身份标识 |
| Payload | 查看参数、请求参数 |
| Preview | 预览服务器数据 |
| Response | 响应/回答 |
有花括号{}的 半结构化数据 json数据 前后端数据交互常用
驼峰命名法 AaBb大驼峰 a_b小驼峰
以下是几个爬虫实例:
1. 豆瓣电影
BV1NY411b7PR
🥝 实现步骤
step: 明确需求 → 发送请求 → 获取数据 → 解析数据(re正则表达式、css选择器、xpath) → 保存数据
🥝 实现代码
实现代码:
import requests # 数据请求模块
import parsel # 数据解析模块
import csv # 保存表格数据# f=open('douban.csv',mode='w',encoding='utf-8',newline='') # 中文乱码
f=open('douban.csv',mode='w',encoding='utf-8-sig',newline='')csv_writer =csv.DictWriter(f,fieldnames=['电影名字','详情页',#'导演',#'主演','演员','年份','国家','电影类型','评分','评论人数','概述',
])
csv_writer.writeheader()
for page in range(0,250,25):# url = 'https://movie.douban.com/top250'url =f'https://movie.douban.com/top250?start={page}&filter='headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}response = requests.get(url=url, headers=headers)# print(response.text)selector = parsel.Selector(response.text)lis = selector.css('.grid_view li') # css选择器# selector.xpath('//*[@class="grid_view"]/li') # xpathfor li in lis:# span:nth-child(1) 组合选择器,选择第几个span标签# text 获取标签的文本数据title = li.css('.hd a span:nth-child(1)::text').get() # 标题href = li.css('.hd a::attr(href)').get() # 详情页# li.xpath('//*[@class="hd"]/a/span(1)/text()').get()info = li.css('.bd p::text').getall()actor = info[0].strip().split('主演:') # strip()去字符串两端的空格,split字符串分割# director=actor[0].replace('导演:','').strip()# performer=actor[0].replace('...','').replace('/','').strip()actors = actor[0].replace('...', '').replace('/', '').strip() # 演员,导演+主演others = info[1].strip().split('/')year = others[0].strip() # 年份country = others[1].strip() # 城市type = others[2].strip() # 类型scores = li.css('.star span:nth-child(2)::text').get() # 评分#comment = li.css('.star span:nth-child(4)::text').get() # 评价人数comment = li.css('.star span:nth-child(4)::text').get().replace('人评价', '') # 评价人数overview = li.css('.inq::text').get() # 概述# print(title,actor,others)# print(director,performer,year,country,type)dit={'电影名字':title,'详情页':href,'演员':actors,#'导演':director,#'主演':performer,'年份':year,'国家':country,'电影类型':type,'评分':scores,'评论人数':comment,'概述':overview,}csv_writer.writerow(dit)print(title, href, actors, year, country, type, scores, comment, overview, sep=' | ')
🥝 部分参数
部分参数来源:


🥝 运行效果
部分效果:



🥝 乱码问题
中文乱码问题的解决:
乱码的效果就是它除了数字就全是问号???,哈哈哈哈。🤣
# f=open('douban.csv',mode='w',encoding='utf-8',newline='') # 中文乱码
f=open('douban.csv',mode='w',encoding='utf-8-sig',newline='')
2. 酷狗榜单
BV1ZU4y1B7yY
🥝 实现步骤
step: 发送请求 → 获取数据 → 解析数据
🥝 单个榜单
# pip Install requests
# 导入数据请求模块
import requests
# 导入正则模块,re是内置的,不需要安装
# 在Python中需要通过正则表达式对字符串进⾏匹配的时候,可以使⽤⼀个python自带的模块,名字为re。
import re
# 确定请求地址
url='https://www.kugou.com/yy/html/rank.html'
# 模拟伪装 headers 请求头 <-- 开发者工具里面进行复制粘贴
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
# 发送请求
response = requests.get(url=url,headers=headers)
# print(response)
# <Response [200]> //整体是一个响应对象,200 状态码表示请求成功
#(仅仅表示请求成功,不一定得到想要的数据)
# 获取数据,获取服务器返回响应数据 response.text 获取响应文本数据
# print(response.text)
# 解析数据
Hash_list = re.findall('"Hash":"(.*?)",', response.text)
album_id_list = re.findall('"album_id":(.*?),', response.text)
#print(Hash_list)
#print(album_id_list)
# for循环遍历 把列表里面元素一个一个提取出来
for Hash, album_id in zip(Hash_list, album_id_list):# print(Hash,album_id)link = 'https://wwwapi.kugou.com/yy/index.php'# 请求参数data = {'r': 'play/getdata',# 'callback':'jQuery191022953264396493434_1663671714341','hash': Hash,'dfid': '4FII5w3ArJSc0dPjmR1DFIit','appid': '1014','mid': ' 8c6815fe99744abfea7f557377764693','platid': '4','album_id': album_id,# 'album_audio_id': '39933554','_': '1663671714343',}music_data = requests.get(url=link, params=data, headers=headers).json()# music_data = requests.get(url=link, params=data, headers=headers).textaudio_name=music_data['data']['audio_name']audio_url = music_data['data']['play_url']# print(music_data)print(audio_name,':',audio_url)# 保存数据audio_content = requests.get(url=audio_url, headers=headers).contentwith open('music\\'+audio_name+'.mp3',mode='wb') as f:f.write(audio_content)
获取请求地址:

请求头:
‘user-agent’: ’ Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36’ 表示浏览器基本身份标识
第九行代码要注意,如果引号写错了可能报错:
AttributeError: ‘set’ object has no attribute ‘items’
错误写法一:
headers={'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
headers是字典数据类型,不是集合set。{' '}是集合;{' ':' '}是字典
InvalidHeader: Invalid leading whitespace, reserved character(s), or returncharacter(s) in header value: ’ Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36’
错误写法二:
headers={'user-agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
多了个空格,小错误要注意。
re模块findall方法
re.findall() →找到所有我们想要的数据内容
解析的时候,hash、album
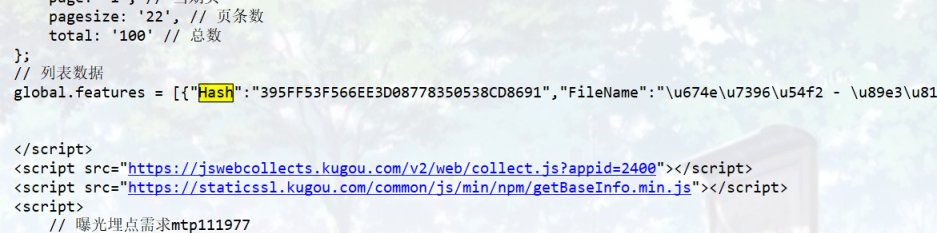
比较长,一次不好截,



错位❌写法:
music_data = requests.get(url=link, params=data, headers=headers).json()
requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)

不是json格式,多了一部分,把callback删掉可以,或者用text
response.json →获取json字典数据
取歌曲名字和url


with open('music\\'+audio_name+'.mp3') as f:
FileNotFoundError: [Errno 2] No such file or directory: ‘music\李玖哲 - 解脱.mp3’
文件夹不存在(music),即使music文件夹已在,仍报错,可以改成:
with open('music\\'+audio_name+'.mp3',mode='wb') as f:
效果
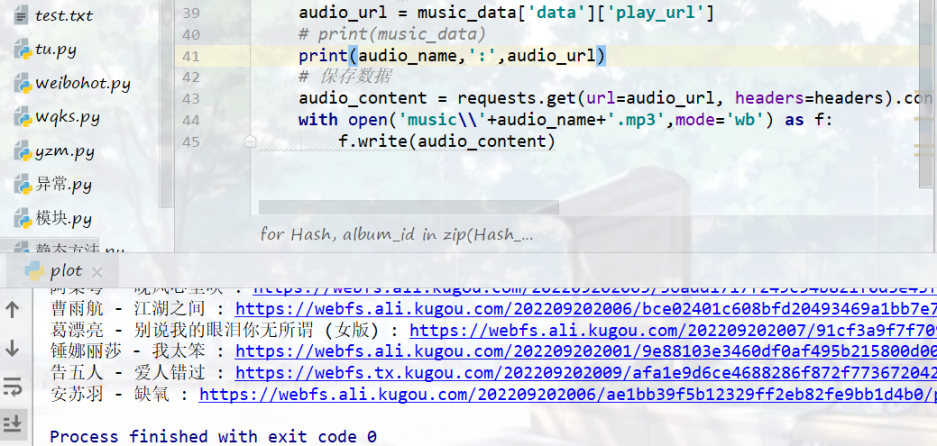

🥝 多个榜单
import requests
import reurl='https://www.kugou.com/yy/html/rank.html'
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
response = requests.get(url=url,headers=headers)
#print(response.text)
music_list = re.findall('<a title="(.*?)" .*? hidefocus="true" href="(.*?)">', response.text)[1:]# print(music_list)
# 从第几个开始爬,3(切片)
# for title,index in music_list[3:]:
for title,index in music_list:print(title)# url = 'https://www.kugou.com/yy/html/rank.html'# 模拟伪装 headers 请求头 <-- 开发者工具里面进行复制粘贴headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}# 发送请求response = requests.get(url=index, headers=headers)# print(response)# <Response [200]> //整体是一个响应对象,200 状态码表示请求成功# (仅仅表示请求成功,不一定得到想要的数据)# 获取数据,获取服务器返回响应数据 response.text 获取响应文本数据Hash_list = re.findall('"Hash":"(.*?)",', response.text)album_id_list = re.findall('"album_id":(.*?),', response.text)# print(Hash_list)# print(album_id_list)# for循环遍历 把列表里面元素一个一个提取出来for Hash, album_id in zip(Hash_list, album_id_list):# print(Hash,album_id)link = 'https://wwwapi.kugou.com/yy/index.php'# 请求参数data = {'r': 'play/getdata',# 'callback':'jQuery191022953264396493434_1663671714341','hash': Hash,'dfid': '4FII5w3ArJSc0dPjmR1DFIit','appid': '1014','mid': ' 8c6815fe99744abfea7f557377764693','platid': '4','album_id': album_id,# 'album_audio_id': '39933554','_': '1663671714343',}music_data = requests.get(url=link, params=data, headers=headers).json()# music_data = requests.get(url=link, params=data, headers=headers).textaudio_name = music_data['data']['audio_name']audio_name = re.sub(r'[\/:*?"<>|]','',audio_name)audio_url = music_data['data']['play_url']if audio_url:# print(music_data)print(audio_name, ':', audio_url)# 保存数据audio_content = requests.get(url=audio_url, headers=headers).contentwith open('music\\' + audio_name + '.mp3', mode='wb') as f:f.write(audio_content)


第一个不要,做个切片
第一个网址打开是这样的
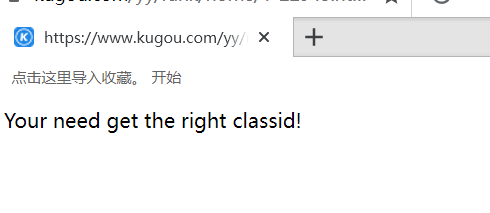
music_list = re.findall('<a title="(.*?)" hidefocus="true" href="(.*?)"', response.text)[1:]
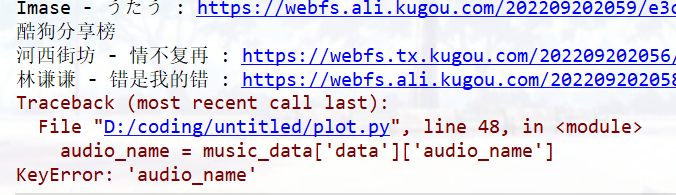
requests.exceptions.MissingSchema: Invalid URL ‘’: No scheme supplied. Perhaps you meant http://?
报错位置
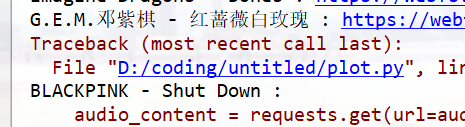
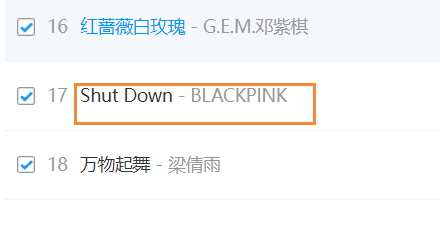
请求链接🔗不对,无法下载,改代码,让他直接跳过

OSError: [Errno 22] Invalid argument: ‘music\Stingray、Backstreet Boys - I Want It That Way (In the Style of Backstreet Boys|Karaoke Version).mp3’
特殊字符 → windows系统文件名不能包含

re.sub(r'[\/:*?"<>|]','',audio_name)
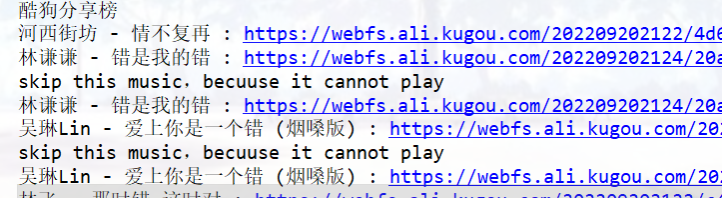
能跳过,但是有重复,就很怪
import requests
import reurl='https://www.kugou.com/yy/html/rank.html'
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
response = requests.get(url=url,headers=headers)
#print(response.text)
music_list = re.findall('<a title="(.*?)" .*? hidefocus="true" href="(.*?)">', response.text)[1:]# print(music_list)
# 从第4个开始爬,3(切片),0开始
# for title,index in music_list[3:]:
for title,index in music_list:print(title)# url = 'https://www.kugou.com/yy/html/rank.html'# 模拟伪装 headers 请求头 <-- 开发者工具里面进行复制粘贴headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}# 发送请求response = requests.get(url=index, headers=headers)# print(response)# <Response [200]> //整体是一个响应对象,200 状态码表示请求成功# (仅仅表示请求成功,不一定得到想要的数据)# 获取数据,获取服务器返回响应数据 response.text 获取响应文本数据Hash_list = re.findall('"Hash":"(.*?)",', response.text)album_id_list = re.findall('"album_id":(.*?),', response.text)# print(Hash_list)# print(album_id_list)# for循环遍历 把列表里面元素一个一个提取出来for Hash, album_id in zip(Hash_list, album_id_list):# print(Hash,album_id)link = 'https://wwwapi.kugou.com/yy/index.php'# 请求参数data = {'r': 'play/getdata',# 'callback':'jQuery191022953264396493434_1663671714341','hash': Hash,'dfid': '4FII5w3ArJSc0dPjmR1DFIit','appid': '1014','mid': ' 8c6815fe99744abfea7f557377764693','platid': '4','album_id': album_id,# 'album_audio_id': '39933554','_': '1663671714343',}music_data = requests.get(url=link, params=data, headers=headers).json()# music_data = requests.get(url=link, params=data, headers=headers).texttry:audio_name = music_data['data']['audio_name']audio_name = re.sub(r'[\/:*?"<>|]', '', audio_name)audio_url = music_data['data']['play_url']except Exception as KeyError:print("skip this music,becuuse it cannot play")if audio_url:print(audio_name, ':', audio_url)# 保存数据audio_content = requests.get(url=audio_url, headers=headers).contentwith open('music\\' + audio_name + '.mp3', mode='wb') as f:f.write(audio_content)
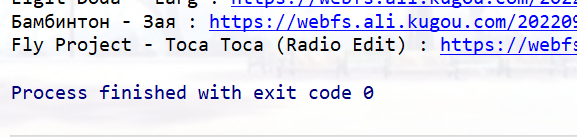
🥝 完善版本
import requests
import reurl='https://www.kugou.com/yy/html/rank.html'
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
response = requests.get(url=url,headers=headers)
#print(response.text)
music_list = re.findall('<a title="(.*?)" .*? hidefocus="true" href="(.*?)">', response.text)[1:]# print(music_list)
# 从第4个开始爬,3(切片),0开始
# for title,index in music_list[3:]:
for title,index in music_list:print(title)# url = 'https://www.kugou.com/yy/html/rank.html'# 模拟伪装 headers 请求头 <-- 开发者工具里面进行复制粘贴headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}# 发送请求response = requests.get(url=index, headers=headers)# print(response)# <Response [200]> //整体是一个响应对象,200 状态码表示请求成功# (仅仅表示请求成功,不一定得到想要的数据)# 获取数据,获取服务器返回响应数据 response.text 获取响应文本数据Hash_list = re.findall('"Hash":"(.*?)",', response.text)album_id_list = re.findall('"album_id":(.*?),', response.text)# print(Hash_list)# print(album_id_list)# for循环遍历 把列表里面元素一个一个提取出来for Hash, album_id in zip(Hash_list, album_id_list):# print(Hash,album_id)link = 'https://wwwapi.kugou.com/yy/index.php'# 请求参数data = {'r': 'play/getdata',# 'callback':'jQuery191022953264396493434_1663671714341','hash': Hash,'dfid': '4FII5w3ArJSc0dPjmR1DFIit','appid': '1014','mid': ' 8c6815fe99744abfea7f557377764693','platid': '4','album_id': album_id,# 'album_audio_id': '39933554','_': '1663671714343',}music_data = requests.get(url=link, params=data, headers=headers).json()# music_data = requests.get(url=link, params=data, headers=headers).texttry:audio_name = music_data['data']['audio_name']audio_name = re.sub(r'[\/:*?"<>|]', '', audio_name)audio_url = music_data['data']['play_url']if audio_url:print(audio_name, ':', audio_url)# 保存数据audio_content = requests.get(url=audio_url, headers=headers).contentwith open('music\\' + audio_name + '.mp3', mode='wb') as f:f.write(audio_content)except Exception as KeyError:pass
try-except的妙用,直接跳过一些错误/null的歌曲,比之前的多榜代码好一些。
3. 千千音乐
查单曲的params

# 千千音乐
import requests
import time
import hashliburl='https://music.91q.com/v1/song/tracklink'# 要其他歌曲修改这个params就可以了
params={
'sign': 'aeb1fc52109d5dd518d02f4548936a0b',
'TSID': 'T10045980539',
'appid': 16073360,# 不变
'timestamp':1658711978,
}headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}response=requests.get(url=url,params=params,headers=headers)music_url=response.json()['data']['path']
music_title=response.json()['data']['title']
music_singer=response.json()['data']['artist'][0]['name']
print(music_title,music_singer,music_url)
4. 微博热搜
# pip install lxml
# 微博热搜
import requests
from lxml import etree
import time
url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr='
header={'cookie':"SINAGLOBAL=7254774839451.836.1628626364688; SUB=_2AkMWR_ROf8NxqwJRmf8cymjraIt-ygDEieKgGwWVJRMxHRl-yT9jqmUgtRB6PcfaoQpx1lJ1uirGAtLgm7UgNIYfEEnw; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWEs5v92H1qMCCxQX.d-5iG; UOR=,,www.baidu.com; _s_tentry=-; Apache=1090953026415.7019.1632559647541; ULV=1632559647546:8:4:2:1090953026415.7019.1632559647541:1632110419050; WBtopGlobal_register_version=2021092517; WBStorage=6ff1c79b|undefined",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
resp = requests.get (url,headers=header)
resp1 = resp.content.decode(encoding='utf-8',errors='ignore')
resp2=etree.HTML(resp1)
title = resp2.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td/a/text()')
print(time.strftime("%F,%R")+'微博热搜:')
for i in range(51):print (f'{i} '+''.join([title[i]]))
time.sleep(1)

后面还有很多,截图未完,但效果大概就是这样子的
5. 当当榜单
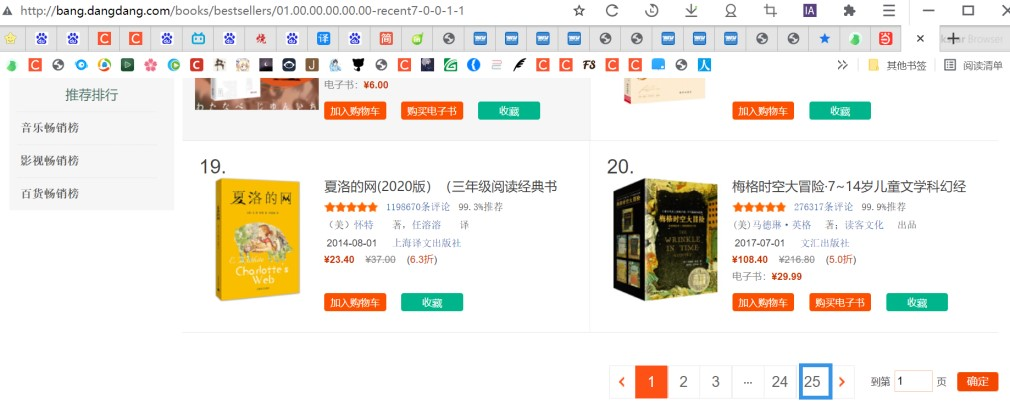
🥝 书籍数据
# 导入数据请求模块
import requests
# 导入数据解析模块
import parsel
# 导入csv模块 ---> 内置模块 不需要安装
import csv# 创建文件
f = open('书籍data25页.csv', mode='a', encoding='utf-8', newline='')
# f文件对象 fieldnames 字段名 ---> 表格第一行 作为表头
csv_writer = csv.DictWriter(f, fieldnames=['标题','评论','推荐',\'作者','日期','出版社','售价',\'原价','折扣','电子书','详情页',])
# 写入表头
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url发送请求- 等号左边是定义变量名- 模拟浏览器 ---> 请求头headers ---> 在开发者工具里面复制粘贴 字典数据类型一种简单反反爬手段, 防止被服务器识别出来是爬虫程序- 使用什么请求方式, 根据开发者工具来的
"""
for page in range(1, 26): # 1,26 是取1-25的数字, 不包含26# 确定请求网址url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-{page}'# 模拟浏览器 ---> 请求头headers = {# User-Agent 用户代理 表示浏览器基本身份标识'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}# 发送请求 返回的响应对象 ---> <Response [200]>: <> 表示对象 response 响应回复 200状态码 表示请求成功response = requests.get(url=url, headers=headers)print(response)# 2. 获取数据, 获取服务器返回响应数据 ---> 开发者工具里面 response print(response.text)"""3. 解析数据, 提取我们想要数据内容, 书籍基本信息根据得到数据类型以及我们想要数据内容, 选择最适合解析方法:- re正则表达式- css选择器- xpathxpath ---> 根据标签节点提取数据css选择器 ---> 根据标签属性提取数据内容css语法匹配 不会 1 会的 2复制粘贴会不会 ---> ctrl + C ctrl + v"""# 转数据类型 <Selector xpath=None data='<html xmlns="http://www.w3.org/1999/x...'>selector = parsel.Selector(response.text)# 第一次提取 提取所有li标签 --> 返回列表, 元素Selector对象lis = selector.css('.bang_list_mode li')# for循环遍历 之后进行二次提取 我们想要内容for li in lis:"""attr() 属性选择器 a::attr(title) ---> 获取a标签里面title属性get() 获取一个 第一个 """title = li.css('.name a::attr(title)').get() # 标题star = li.css('.star a::text').get().replace('条评论', '') # 评论recommend = li.css('.tuijian::text').get().replace('推荐', '') # 推荐author = li.css('.publisher_info a::attr(title)').get() # 作者date = li.css('.publisher_info span::text').get() # 日期press = li.css('div:nth-child(6) a::text').get() # 出版社price_n = li.css('.price .price_n::text').get() # 售价price_r = li.css('.price .price_r::text').get() # 原价price_s = li.css('.price .price_s::text').get().replace('折', '') # 折扣price_e = li.css('.price .price_e .price_n::text').get() # 电子书href = li.css('.name a::attr(href)').get() # 详情页# 保存数据#源码、解答、教程加Q裙:261823976dit = {'标题': title,'评论': star,'推荐': recommend,'作者': author,\'日期': date,'出版社': press,'售价': price_n,'原价': price_r,\'折扣': price_s,'电子书': price_e,'详情页': href,}# 写入数据csv_writer.writerow(dit)print(title, star, recommend, author, date, press, price_n, price_r, price_s, price_e, href, sep=' | ')
🥝 获取评论
短评

长评

一开始能用,后来报错,就用扣钉重新运行了一下,可以。
raise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
# 导入数据请求模块
import time
import requests
import re
for page in range(1, 11): # 第1-第10页的评论time.sleep(1.5)# 确定网址url = 'http://product.dangdang.com/index.php'# 请求参数data = {'r': 'comment/list','productId': '27898031',#'productId': '25201859', # 《钝感力》'categoryPath': '01.43.77.07.00.00','mainProductId': '27898031',#'mainProductId': '25201859','mediumId': '0','pageIndex': page,'sortType': '1','filterType': '1','isSystem': '1','tagId': '0','tagFilterCount': '0','template': 'publish','long_or_short': 'short',# 短评}headers = {'Cookie': '__permanent_id=20220526142043051185927786403737954; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; ddscreen=2; secret_key=f4022441400c500aa79d59edd8918a6e; __visit_id=20220723213635653213297242210260506; __out_refer=; pos_6_start=1658583812022; pos_6_end=1658583812593; __trace_id=20220723214559176959858324136999851; __rpm=p_27898031.comment_body..1658583937494%7Cp_27898031.comment_body..1658583997600','Host': 'product.dangdang.com','Referer': 'http://product.dangdang.com/27898031.html',#'Referer': 'http://product.dangdang.com/25201859.html','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',}response = requests.get(url=url, params=data, headers=headers)html_data = response.json()['data']['list']['html']content_list = re.findall("<span><a href='.*?' target='_blank'>(.*?)</a></span>", html_data)for content in content_list:with open('评论.txt', mode='a', encoding='utf-8') as f:f.write(content)f.write('\n')print(content)
对一下最后一句评论,对的上。# 《钝感力》最后一句评论是质量挺好,印刷纸质都很好,内容上觉得有道理,又不是很能说服人,个人感受
🥝 词云显示

import jieba
import wordcloud
#import imageio
import imageio.v2 as imageio
# 读取图片
py = imageio.imread('python.gif')
# 打开文件
f = open('评论.txt', encoding='utf-8')
# 读取内容
txt = f.read()
# jieba模块进行分词 ---> 列表
txt_list = jieba.lcut(txt)
print(txt_list)
# join把列表合成字符串
string = ' '.join(txt_list)
# 使用词云库
wc = wordcloud.WordCloud(height=300, # 高度width=500, # 宽度background_color='white', # 背景颜色font_path='msyh.ttc', # 字体scale=15, # 轮廓stopwords={'的', '了', '很', '也'}, # 停用词mask=py # 自定义词云图样式
)
wc.generate(string) # 需要做词云数据传入进去
wc.to_file('1.png') # 输入图片
🥝 关于词云
词云:wordcloud
安装:
pip install wordcloud
实现步骤:
读取词云的文本文件 → WordCloud().generate(txt) → to_image()建立词云图像文件 → show()显示词云
用法:

# pip install wordcloud
# pip install jieba # 中文-jieba
import wordcloud
import jieba# 注意把字体导进去,如果用到要写中文要把能显示中文的字体(很多都行)导进去
wd = wordcloud.WordCloud(font_path="A73方正行黑简体.ttf") # 配置对象参数
txt=' '.join(jieba.cut("wordcloud python 猫咪 但是"))
wd.generate(txt) # 加载词云文本
wd.to_file("wd.png")

text.txt
text
dog dog dog
dog dog dog
fish
cat
cat
# pip install wordcloud
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
# 读取文本文件
with open('text.txt') as f:txt=f.read()
wd=wordcloud.WordCloud().generate(txt)
wd.to_image().show() # 建立词云图像文件并显示
wd.to_file("wd.png")
或者,不从外面读,写成字符串
# pip install wordcloud
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
# 文本
txt="text dog dog dog dog dog dog fish cat cat"
wd=wordcloud.WordCloud().generate(txt)
wd.to_image().show() # 建立词云图像文件并显示
wd.to_file("wd.png")
乱码问题
词云中文乱码问题
中文词云失败的解决方法jieba
文本文件中有中文,在扣钉中会变框框,在PyCharm中报错。

UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xab in position 53: incomplete multibyte sequence
解决方法:

# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf").generate(txt)
wd.to_image().show() # 建立词云图像文件并显示
wd.to_file("wd.png") # 输出到文件

jieba模块
jieba模块
安装模块:
pip install jieba
分词模式:
jieba 是Python中的中文分词库,提供以下三种分词模式:
- 精确模式
jieba.lcut(str) - 全模式
jieba.lcut(str,cut_all=True) - 搜索引擎模式
jieba.lcut_for_search(str)
import jieba
s = "中国是一个伟大的国家"
print(jieba.lcut(s)) # 精准模式
# 输出结果: ['中国', '是', '一个', '伟大', '的', '国家']
print(jieba.lcut(s,cut_all=True)) # 全模式
# 输出结果:['中国', '国是', '一个', '伟大', '的', '国家']
s1 = "中华人民共和国是伟大的"
print(jieba.lcut_for_search(s1)) # 搜索引擎模式
# 输出结果 :
# ['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']
jieba模块的cut()方法
import jieba
txt="我的妹妹是一只猫"
words=jieba.cut(txt)
for word in words:print(word)
Building prefix dict from the default dictionary …
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.952 seconds.
Prefix dict has been built succesfully.
我 的 妹妹 是 一只 猫
jieba猫猫Python猫猫jieba Matplotlib jieba,Python

# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
cut_text=' '.join(jieba.cut(txt))
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf").generate(cut_text)
wd.to_image().show() # 建立词云图像文件并显示
wd.to_file("wd.png") # 输出到文件
词云参数


与matplotlib联用

text
dog dog dog
dog dog dog
fish
cat
cat
狗
# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf",background_color="lightblue",width=800,height=600).generate(txt)
plt.imshow(wd)
plt.savefig("wd.png") # 输出到文件
plt.show()
plt.axis("off") # 关闭轴线

# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf",background_color="lightblue",width=800,height=600).generate(txt)
plt.imshow(wd)
plt.axis("off") # 关闭轴线
plt.savefig("wd.png") # 输出到文件
plt.show()
词云形状
WordCloud(mask=)
一般的图片可能要先进行去底再使用
在线去底 https://www.aigei.com/bgremover/

# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
cut_text=' '.join(jieba.cut(txt))
bgimage=np.array(Image.open('python(已去底).gif'))
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf",\background_color="white",mask=bgimage).generate(cut_text)
plt.imshow(wd)
plt.axis("off")
plt.savefig("wd.png") # 输出到文件
plt.show()
用 imageio 则不去底
# pip install wordcloud
# pip install jieba
# pip install imageio
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
import imageio
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
cut_text=' '.join(jieba.cut(txt))
bgimage=imageio.imread('python.gif')
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf",\background_color="white",mask=bgimage).generate(cut_text)
plt.imshow(wd)
plt.axis("off")
plt.savefig("wd.png") # 输出到文件
plt.show()
可视化词云包-Stylecloud
https://github.com/minimaxir/stylecloud
https://fontawesome.com/
https://fontawesome.dashgame.com/
https://fa5.dashgame.com/#/

import pandas as pd
import jieba.analyse
from stylecloud import gen_stylecloud
with open('text.txt',encoding='utf-8') as f:txt=f.read()
cut_text=' '.join(jieba.cut(txt))
gen_stylecloud(text=cut_text,icon_name='fas fa-comment-dots',font_path="A73方正行黑简体.ttf",background_color='white',output_name='wd.jpg')
print('绘图成功!')



import stylecloud
stylecloud.gen_stylecloud(file_path='text.txt', icon_name= 'fas fa-dog',font_path="A73方正行黑简体.ttf",palette='colorbrewer.diverging.Spectral_11', background_color='black', gradient='horizontal')
# palette:调色板(通过 palettable 实现)[默认值:cartocolors.qualitative.Bold_5]
字体颜色color

import stylecloud
stylecloud.gen_stylecloud(file_path='text.txt', icon_name= 'fas fa-dog',font_path="A73方正行黑简体.ttf",palette='colorbrewer.diverging.Spectral_11', background_color='black', # 背景色colors='white',# 字体颜色gradient='horizontal'# 梯度)
反向遮罩invert_mask

import stylecloud
stylecloud.gen_stylecloud(file_path='text.txt', icon_name= 'fas fa-dog',font_path="A73方正行黑简体.ttf",palette='colorbrewer.diverging.Spectral_11', background_color='black', # 背景色colors='white',# 字体颜色invert_mask=True, # 反向遮罩gradient='horizontal')
调色板palette
palettable 网站: https://jiffyclub.github.io/palettable/

import stylecloud
stylecloud.gen_stylecloud(file_path='text.txt', icon_name= 'fab fa-twitter',font_path="A73方正行黑简体.ttf",palette='cartocolors.diverging.TealRose_7', background_color='white', # 背景色gradient='horizontal')

import stylecloud
stylecloud.gen_stylecloud(file_path='评论.txt', icon_name= 'fab fa-qq',font_path="A73方正行黑简体.ttf",palette='tableau.BlueRed_6', background_color='white', # 背景色gradient='horizontal',size=400,output_name='书评.png')
相关文章:
Python爬虫使用实例
IDE:大部分是在PyCharm上面写的 解释器装的多 → 环境错乱 → error:没有配置,no model 爬虫可以做什么? 下载数据【文本/二进制数据(视频、音频、图片)】、自动化脚本【自动抢票、答题、采数据、评论、点…...
主成分分析(PCA)
1 主成分分析简介 主成分分析(Principal Component Analysis,PCA), 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法。主成分分析是由卡尔皮尔逊(Karl Pearson)于1901年发明的。通过维度约减的方式将高维度…...

python实现生命游戏
“生命游戏”(Conway’s Game of Life)是由数学家约翰康威提出的一种零玩家游戏。它是一个细胞自动机,由一组简单的规则决定每个细胞的状态。以下是用Python实现“生命游戏”的代码示例: Python代码实现 import numpy as np imp…...

基于vue框架的CIA报价平台的设计与实现1xv02(程序+源码+数据库+调试部署+开发环境)系统界面在最后面。
系统程序文件列表 项目功能:用户,供应商,产品分类,产品信息,在线咨询,资质申请 开题报告内容 基于Vue框架的CIA报价平台的设计与实现 开题报告 一、选题背景 随着市场竞争的日益激烈,企业对于成本控制与效率提升的需求愈发迫切。在采购与供应链管理…...

【Kubernetes】k8s集群Pod控制器
目录 一.Pod控制器作用 二.Pod控制器类型 1.Deployment(简称deploy) ReplicaSet(简称rs) 2.StatefulSet(简称sts) 创建SatefulSet控制器 3.DaemonSet(简称ds) 4.Job 5.Cron…...

什么是NLP实体识别?
目录 1. 实体识别的基本概念 1.1 什么是实体识别? 1.2 实体识别的应用场景 2. 实体识别的常用方法 2.1 基于规则的方法 2.1.1 规则定义与模式匹配 2.2 基于机器学习的方法 2.2.1 特征工程与传统机器学习模型 2.3 基于深度学习的方法 2.3.1 神经网络模型 …...

掌握Jenkins自动化部署:从代码提交到自动上线的全流程揭秘
Jenkins自动化部署是现代软件开发中不可或缺的一部分,它不仅简化了代码的发布过程,还为整个团队带来了无与伦比的效率和协作力。想象一下,开发者们可以专注于编写高质量的代码,而不是为繁琐的手动部署所烦恼;测试人员能…...

糟糕界面集锦-控件篇09
目前我们还无法确定该把这个问题划到哪个类别中,但是如图所示,在一个列表框中只显示3 个项目无疑是愚蠢的。 这是微软的文件管理器提供的文件关联界面,用户需要把某一个特定类型的文件与一个应用程序关联时会弹出该对话框。如示例:…...

喵喵蓝牙热敏打印机(下)
目录 前言一、电量、温度、缺纸检测1.电量检测2.针头温度检测3.缺纸检测 二、蓝牙APP通信打印1.蓝牙初始化2.APP通信打印 三、FreeRTOS任务整合 前言 喵喵蓝牙热敏打印机(上) 内容有点多,就分为了上下两篇。 一、电量、温度、缺纸检测 先启…...

软件测试第1章 软件测试是什么
目录 内容说明 一、软件测试与质量概览需要熟悉什么 二、如何理解质量保证 三、软件测试的误区-程序员和测试的关系 四、软件测试是什么? 五、软件测试的目的 六、软件测试与软件质量保证 七、软件测试的必要性 八、软件测试的基本概念分析 …...

【技术分享】 hysteria2从服务端到客户端部署教程
hysteria2从服务端到客户端部署教程 前言 在如今的网络环境中,尤其是涉及跨国访问的场景中,hysteria2作为一个新兴的传输协议工具,凭借其高效的传输能力和灵活的配置方式,受到了越来越多用户的青睐。本教程将带您一步步完成hyst…...

C++入门基础知识16
C 的关键字(接上一篇博文!!!) 54. typeid 指出指针或引用指向的对象的实际派生类型。 55. typename typename(类型名字)关键字告诉编译器把一个特殊的名字解释成一个类型。在下列情况下必须对一…...

浏览器调试工具-Chrome Dev Tools
浏览器调试模式下的各个调试工具是常用的工具集,能够帮助开发者理解、调试和优化网页。 1.打开方式 直接在浏览器中按下F12键右键点击页面上的任一元素,选择“检查”(Inspect)在浏览器右上角点击菜单按钮,选择“更多…...

基于车联网大数据平台的用户驾驶习惯行为画像分析
近年来,新能源汽车行业的迅速发展推动了汽车智能化的趋势。新能源汽车上配备了成千上万的传感器,这些传感器采集了大量的行车数据被用于车辆运行状况的监控与分析。另一方面,采集到的大量行车数据,也能很好地体现用户的驾驶习惯。…...

Ubuntu24.04搭建maxkb开发环境
接上文:windows10搭建maxkb开发环境(劝退指南) 上文在windows10环境搭建maxkb开发环境遇到各种坑,后面就转战ubuntu平台,果然比较顺利的完成开发环境搭建。当然遇到相关的问题还是可以参考上文《windows10搭建maxkb开发…...

C++ 指针和引用的区别
1.引用在定义时必须初始化,而指针没有要求 2.引用一旦引用了一个实体就不能在引用其它实体,指针可以在任何时候指向同一类型的指针 3.没有空引用,但是有空指针 4.在sizeof中含义不同:引用结果为引用类型的大小,但指…...

python绘制蕨菜叶分形
一花一叶一世界,一草一木一浮生. 使用了四个不同的线性变换,根据概率选择其中一个变换并更新 x 和 y 坐标。然后将生成的绿色点绘制出来,形成一片蕨菜叶。 import numpy as np import matplotlib.pyplot as pltdef fern_fractal(num_points):# 初始化坐…...

1分钟了解pandas
Pandas 是一个强大的 Python 库,用于数据分析和数据处理。它为 Python 提供了高效的数据结构和数据分析工具,使得数据操作变得简单而直观。Pandas 由 Wes McKinney 在 2008 年创建,并迅速成为数据科学领域中最受欢迎的库之一。 安装 Pandas …...

django-celery应用-定时执行测试cases
1、celery周期性任务 简介-----celery beat 是一个调度程序,它定期启动任务,然后由集群中的可用工作节点执行这些任务。 django-celery-beat celery默认的调度程序是 celery.beat.PersistentScheduler ,它简单地跟踪本地 shelve 数据库文件中…...

【C++深度探索】unordered_set、unordered_map封装
🔥 个人主页:大耳朵土土垚 🔥 所属专栏:C从入门至进阶 这里将会不定期更新有关C/C的内容,欢迎大家点赞,收藏,评论🥳🥳🎉🎉🎉 文章目录…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

NanaZip:现代Windows文件压缩问题的终极解决方案
NanaZip:现代Windows文件压缩问题的终极解决方案 【免费下载链接】NanaZip The 7-Zip derivative intended for the modern Windows experience 项目地址: https://gitcode.com/gh_mirrors/na/NanaZip 还在为Windows文件压缩工具界面老旧、功能单一而烦恼吗&…...

应对Claude Code访问不稳定,快速切换至Taotoken的应急方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对Claude Code访问不稳定,快速切换至Taotoken的应急方案 对于依赖Claude Code进行日常开发或自动化任务的用户来说&a…...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

JMeter实现RSA签名验签全流程实战
1. 为什么RSA加密接口测试总卡在“连通但失败”这一步? 你有没有遇到过这种情况:接口文档写得清清楚楚,Postman里填好URL、Header、Body,一发请求——返回 {"code":4001,"msg":"签名验证失败"} …...

为什么你的霓虹总像“塑料灯带”?Midjourney光子散射模拟缺陷曝光:3个被官方隐瞒的--sref调参禁区
更多请点击: https://kaifayun.com 第一章:为什么你的霓虹总像“塑料灯带”? 霓虹效果在现代 UI 设计中无处不在——按钮悬停、加载指示器、焦点高亮……但多数实现却流于表面:生硬的 box-shadow、固定色值的渐变边框、缺乏物理感…...

第5章 薪资重构——AI时代的程序员价值重估
第5章 薪资重构——AI时代的程序员价值重估 核心问题:AI时代,程序员的薪资会发生怎样的变化?哪些人在涨薪?哪些人在降薪? 5.1 问题定义:薪资分化的真相是什么? 5.1.1 一个令人震惊的数据 2026年第一季度,一个对比让整个技术圈哗然: 同一家公司内部: - 一个AI方向…...

为什么你的辉光总像P图?——拆解Adobe Stock Top 10辉光作品的MJ底层prompt结构,含--v 6.2专属glow injection指令
更多请点击: https://intelliparadigm.com 第一章:辉光效果的视觉认知误区与本质解构 辉光(Glow)常被误认为是“发光物体自身辐射出的光”,实则是一种典型的后处理视觉错觉——它不改变光源物理属性,也不增…...