6.网络爬虫——BeautifulSoup详讲与实战
网络爬虫——BeautifulSoup详讲与实战
- BeautifulSoup简介:
- BS4下载安装
- BS4解析对象
- Tag节点
- 遍历节点
- find_all()与find()
- find_all()
- find()
- 豆瓣电影实战
前言: 📝📝此专栏文章是专门针对网络爬虫基础,欢迎免费订阅!
📝📝第一篇文章《1.认识网络爬虫》获得全站热搜第一,python领域热搜第一, 第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热搜第八,欢迎阅读! 🎈🎈欢迎大家一起学习,一起成长!!
💕💕:悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。

BeautifulSoup简介:
- Beautiful Soup 简称 BS4(其中 4
表示版本号)BeautifulSoup是一个Python库,用于从HTML和XML文件中提取数据。它提供了一些简单的方式来遍历文档树和搜索文档树中的特定元素。 - BeautifulSoup可以解析HTML和XML文档,并将其转换为Python对象,使得我们可以使用Python的操作来进行数据提取和处理。它还可以处理不完整或有误的标记,并使得标记更加容易阅读。
- BeautifulSoup是一个流行的Web爬虫工具,被广泛应用于数据抓取、数据清洗和数据分析等领域。
BS4下载安装
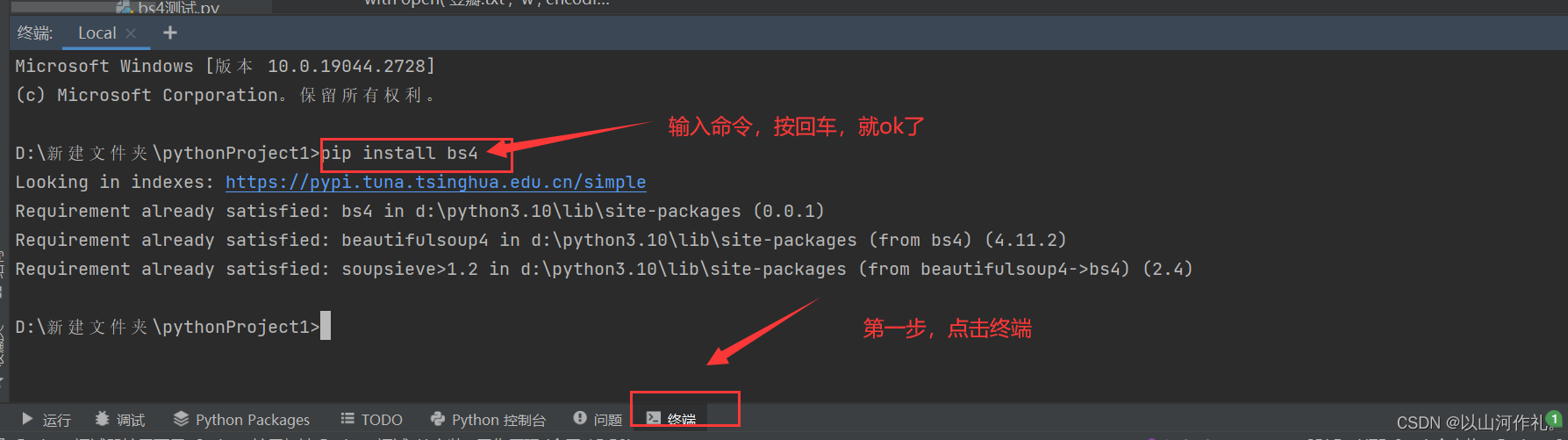
由于 Bautiful Soup 是第三方库,因此需要单独下载,下载方式非常简单,执行以下命令即可安装:
pip install bs4
BS4解析对象
BeautifulSoup4(BS4)对象是BeautifulSoup库解析HTML或XML文档并创建的Python对象。它是一个树形结构,其中包含了文档中的节点,例如标签、字符串和注释。BS4对象可以解析HTML和XML文档,并提供了许多方法来完成对节点的查找、筛选和修改的操作。
例如,可以使用
.find()方法查找包含特定文本的标签,使用.select()方法根据CSS选择器选择元素,使用.text
属性获取标签的文本内容等等。所有这些方法都是BS4对象中提供的。
创建 BS4 解析对象是万事开头的第一步,这非常地简单,语法格式如下所示:
#导入解析包
from bs4 import BeautifulSoup
#创建beautifulsoup解析对象
soup = BeautifulSoup(html_doc, 'html.parser') # html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 'lxml' 或者 'html5lib'#prettify()用于格式化输出html/xml文档
print(soup.prettify())
完整代码:
# 导入解析包
from bs4 import BeautifulSoup
import requestsurl = 'https://movie.douban.com/subject/35457272/?from=showing'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
# 创建beautifulsoup解析对象soup = BeautifulSoup(html.text,'html.parser') # html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 'lxml' 或者 'html5lib'# prettify()用于格式化输出html/xml文档
print(soup.prettify())这段代码使用了Python中的BeautifulSoup库和requests库,对指定网页进行了请求并用BeautifulSoup解析了返回的HTML文档。最后使用prettify()方法格式化输出解析后的文档。
运行结果:
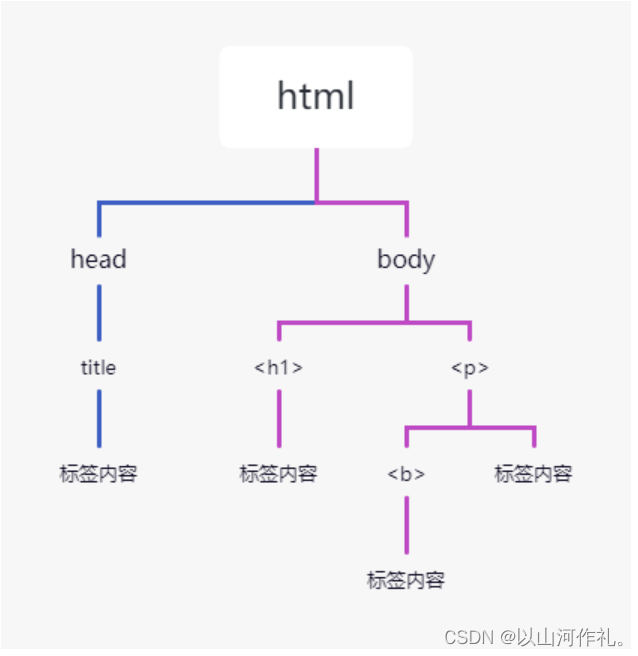
Beautiful Soup 将 HTML 文档转换成一个树形结构,该结构有利于快速地遍历和搜索 HTML 文档。下面使用树状结构来描述一段 HTML 文档:
<html><head><title>中文</title></head><body><h1>net</h1><p><b>编程</b></p></body>
</html>
树状图如下所示:
文档树中的每个节点都是 Python 对象,这些对象大致分为四类:Tag , NavigableString , BeautifulSoup
, Comment 。其中使用最多的是 Tag 和 NavigableString。
- Tag:标签类,HTML 文档中所有的标签都可以看做 Tag 对象。
- NavigableString:字符串类,指的是标签中的文本内容,使用 text、string、strings 来获取文本内容。
- BeautifulSoup:表示一个 HTML 文档的全部内容,您可以把它当作一个人特殊的 Tag 对象。
- Comment:表示 HTML 文档中的注释内容以及特殊字符串,它是一个特殊的 NavigableString 。
Tag节点
标签(Tag)是组成 HTML 文档的基本元素。在 BS4 中,通过标签名和标签属性可以提取出想要的内容。看一组简单的示例
from bs4 import BeautifulSoupsoup = BeautifulSoup('<p class="url"><b>net</b></p>', 'html.parser')
# 获取第一个p标签的html代码
print(soup.p)
# 获取b标签
print(soup.p.b)
# 获取p标签内容,使用NavigableString类中的string、text、get_text()
print(soup.p.text)
# 返回一个字典,里面是多有属性和值
print(soup.p.attrs)
# 查看返回的数据类型
print(type(soup.p))
# 根据属性,获取标签的属性值,返回值为列表 不存在就报错
print(soup.p['class'])
# 获取具体属性 获取最近的第一个属性 不存在就返回Noneif soup.title:print(soup.title.get('class'))
else:print('title标签不存在')
# 给class属性赋值,此时属性值由列表转换为字符串soup.p['class'] = ['abc', 'data']
print(soup.p)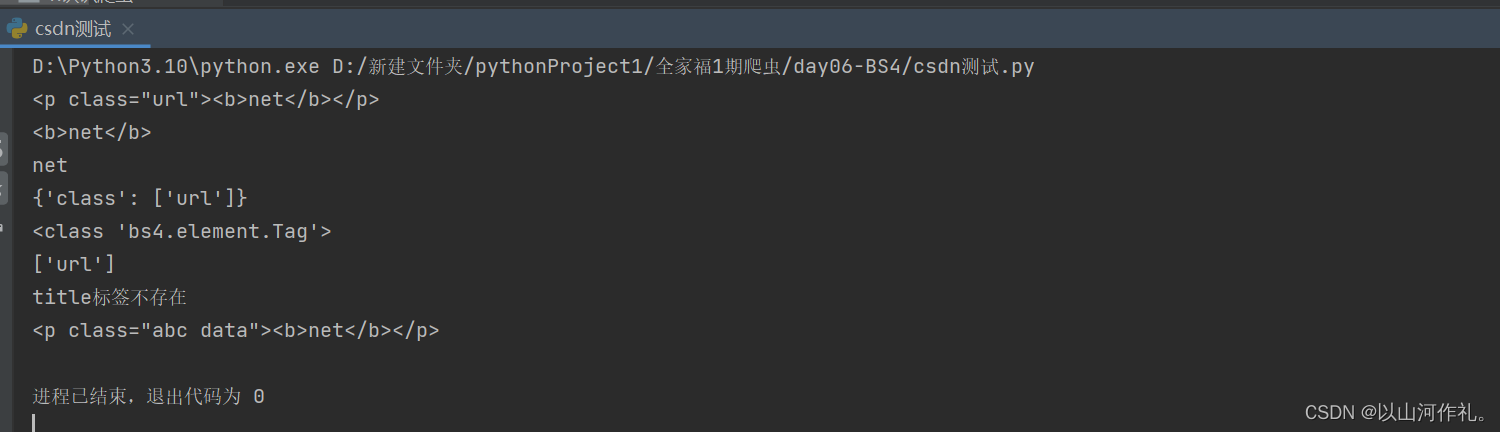
遍历节点
Tag 对象提供了许多遍历 tag 节点的属性,比如 contents、children 用来遍历子节点;parent 与 parents 用来遍历父节点;示例如下:
from bs4 import BeautifulSoup
import requests
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'html.parser')
# 查找第一个符合条件的标签
print(soup.find('span', class_='year'))
# 查找所有符合条件的标签
for item in soup.find_all('span', class_='rating_num'):print(item.text)
# 使用CSS选择器查找标签
print(soup.select('#content > h1 > span:nth-child(1)'))
# 遍历所有文本内容
for string in soup.stripped_strings:print(string)

上述代码中,我们首先使用requests库获取了指定网页的HTML文档,然后使用BeautifulSoup库解析HTML文档,并使用不同的方法遍历了节点,包括:
-
使用find()方法查找第一个符合条件的标签,其中class_参数用于指定class属性的值。
-
使用find_all()方法查找所有符合条件的标签,返回一个列表。
-
使用select()方法使用CSS选择器查找标签,返回一个列表。
-
使用stripped_strings属性遍历所有文本内容,返回一个生成器。需要注意的是,stripped_strings返回的是去除空白字符后的文本内容。
find_all()与find()
find_all()与find()都是BeautifulSoup对象的方法,用于在HTML文档中查找符合条件的标签。
find_all()
find_all():返回所有符合条件的标签,结果是一个列表。如果没有符合条件的标签,则返回空列表。
find_all()是BeautifulSoup对象的方法,用于在HTML文档中查找符合条件的标签。
该方法的语法格式为:soup.find_all(name, attrs, recursive, string, limit,
**kwargs),其中各参数的含义如下:
- name:标签名。可以传入一个标签名的字符串,如’a’、'div’等,也可以传入一个列表,如[‘a’,
‘div’],表示查找多个标签名的标签。如果不指定该参数,则返回所有标签。 - attrs:标签属性。可以传入一个字典,其中键表示属性名,值表示属性值,如{‘class’:
‘movie’},表示查找class属性值为’movie’的标签。也可以传入一个字符串,如’class=“movie”',表示查找class属性值为’movie’的标签。默认值为None。 - recursive:是否递归查找。默认值为True,表示递归查找所有子孙节点;如果设置为False,则只查找直接子节点。
- string:文本内容。可以传入一个字符串,表示查找指定文本内容的标签。
- limit:结果数量。可以传入一个整数,表示最多返回的结果数量。默认值为None,表示返回所有结果。
- **kwargs:其他属性。可以传入其他属性,如id、class等,表示查找具有指定属性的标签。
下面是一个示例代码,演示如何使用find_all()方法查找符合条件的标签:
from bs4 import BeautifulSoup
html_doc = """
<html>
<head><title>电影列表</title>
</head>
<body><h1>电影列表</h1><div class="movie"><h2>黑白迷宫</h2><p>导演:张艺谋</p><p>主演:李连杰、章子怡</p><p>评分:<span class="rating">8.9</span></p></div><div class="movie"><h2>西游记之大圣归来</h2><p>导演:田晓鹏</p><p>主演:张磊、石磊、杨晓婧</p><p>评分:<span class="rating">9.2</span></p></div>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 查找所有div标签
div_list = soup.find_all('div')
print(div_list)
# 查找class属性值为"movie"的div标签
movie_list = soup.find_all('div', class_='movie')
print(movie_list)
# 查找评分大于9.0的电影
rating_list = soup.find_all('span', class_='rating', string=lambda x: float(x) > 9.0)
print(rating_list)
# 查找第一个电影的导演名
director = soup.find('div', class_='movie').find('p').next_sibling.string
print(director)
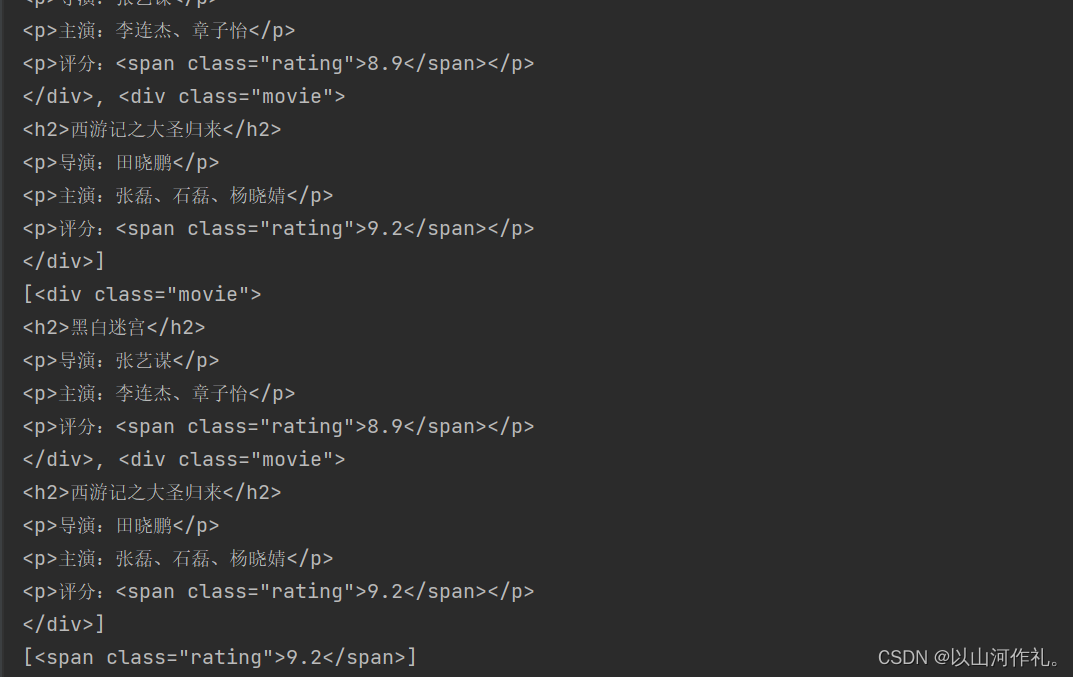
上述代码中,我们首先定义了一个HTML文档字符串,然后使用BeautifulSoup库解析HTML文档,并使用find_all()方法查找了符合条件的标签。
具体来说:
- 使用
find_all('div')方法查找所有div标签,并将结果存储在div_list列表中。 - 使用
find_all('div',class_='movie')方法查找所有class属性值为"movie"的div标签,并将结果存储在movie_list列表中。 - 使用
find_all('span', class_='rating', string=lambda x: float(x) > 9.0)方法查找所有class属性值为"rating"且文本内容大于9.0的span标签,并将结果存储在rating_list列表中。注意这里使用了lambda表达式作为string参数的值,表示只返回文本内容大于9.0的标签。 - 使用
find('div',class_='movie').find('p').next_sibling.string方法查找第一个class属性值为"movie"的div标签中第一个p标签的下一个兄弟节点的文本内容,即导演名。需要注意的是,next_sibling属性返回下一个兄弟节点,可能是空白字符节点,因此需要使用string属性获取文本内容。
find()
find():返回第一个符合条件的标签,结果是一个Tag对象。如果没有符合条件的标签,则返回None。
find()是BeautifulSoup对象的方法,用于在HTML文档中查找第一个符合条件的标签。
该方法的语法格式为:soup.find(name, attrs, recursive, string,
**kwargs),其中各参数的含义与find_all()方法相同。与find_all()方法不同的是,find()只返回第一个符合条件的标签,并且返回的是一个Tag对象,而不是一个列表。如果没有找到符合条件的标签,则返回None。
下面是一个示例代码,演示如何使用find()方法查找符合条件的标签:
from bs4 import BeautifulSoup
html_doc = """
<html>
<head><title>电影列表</title>
</head>
<body><h1>电影列表</h1><div class="movie"><h2>黑白迷宫</h2><p>导演:张艺谋</p><p>主演:李连杰、章子怡</p><p>评分:<span class="rating">8.9</span></p></div><div class="movie"><h2>西游记之大圣归来</h2><p>导演:田晓鹏</p><p>主演:张磊、石磊、杨晓婧</p><p>评分:<span class="rating">9.2</span></p></div>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 查找第一个div标签
div = soup.find('div')
print(div)
# 查找class属性值为"movie"的第一个div标签
movie = soup.find('div', class_='movie')
print(movie)
# 查找评分大于9.0的第一个电影
rating = soup.find('span', class_='rating', string=lambda x: float(x) > 9.0)
print(rating)
# 查找第一个电影的导演名
director = soup.find('div', class_='movie').find('p').next_sibling.string
print(director)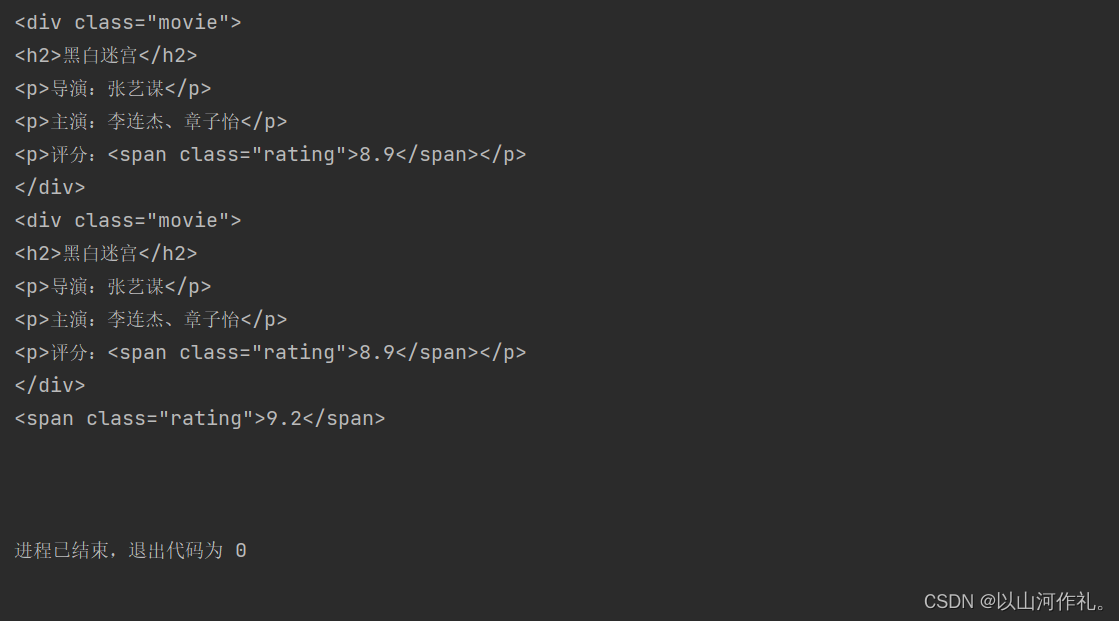
上述代码中,我们使用find()方法查找了符合条件的标签,并返回了一个Tag对象。
具体来说:
- 使用
find('div')方法查找第一个div标签,并将结果存储在div变量中。 - 使用
find('div', class_='movie')方法查找第一个class属性值为"movie"的div标签,并将结果存储在movie变量中。 - 使用
find('span', class_='rating', string=lambda x: float(x) > 9.0)方法查找class属性值为"rating"且文本内容大于9.0的第一个span标签,并将结果存储在rating变量中。注意这里使用了lambda表达式作为string参数的值,表示只返回文本内容大于9.0的标签。 - 使用
find('div',class_='movie').find('p').next_sibling.string方法查找第一个class属性值为"movie"的div标签中第一个p标签的下一个兄弟节点的文本内容,即导演名。
豆瓣电影实战
本次实战目的是获取方框内内容,使用学过的bs4来操作
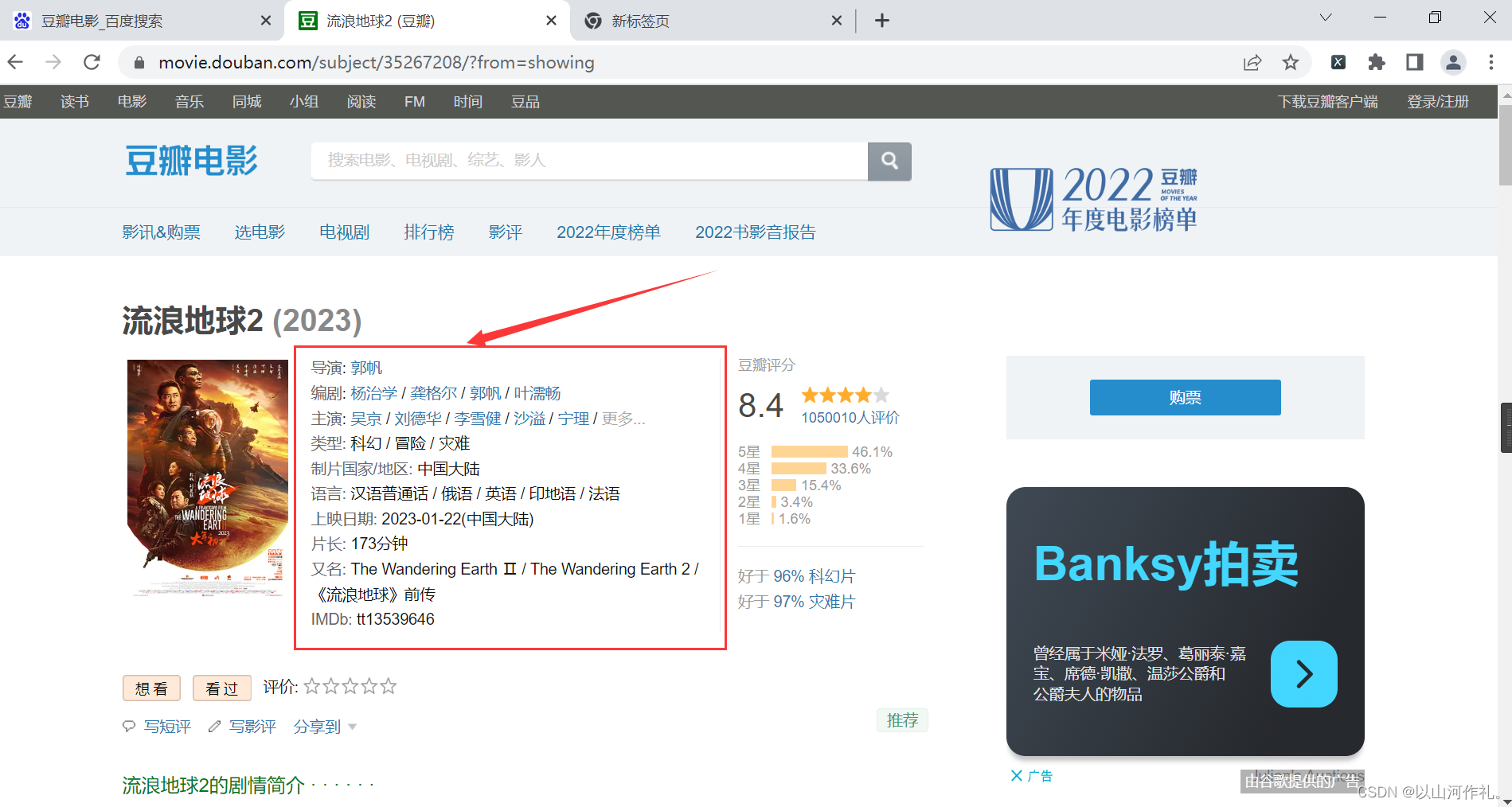
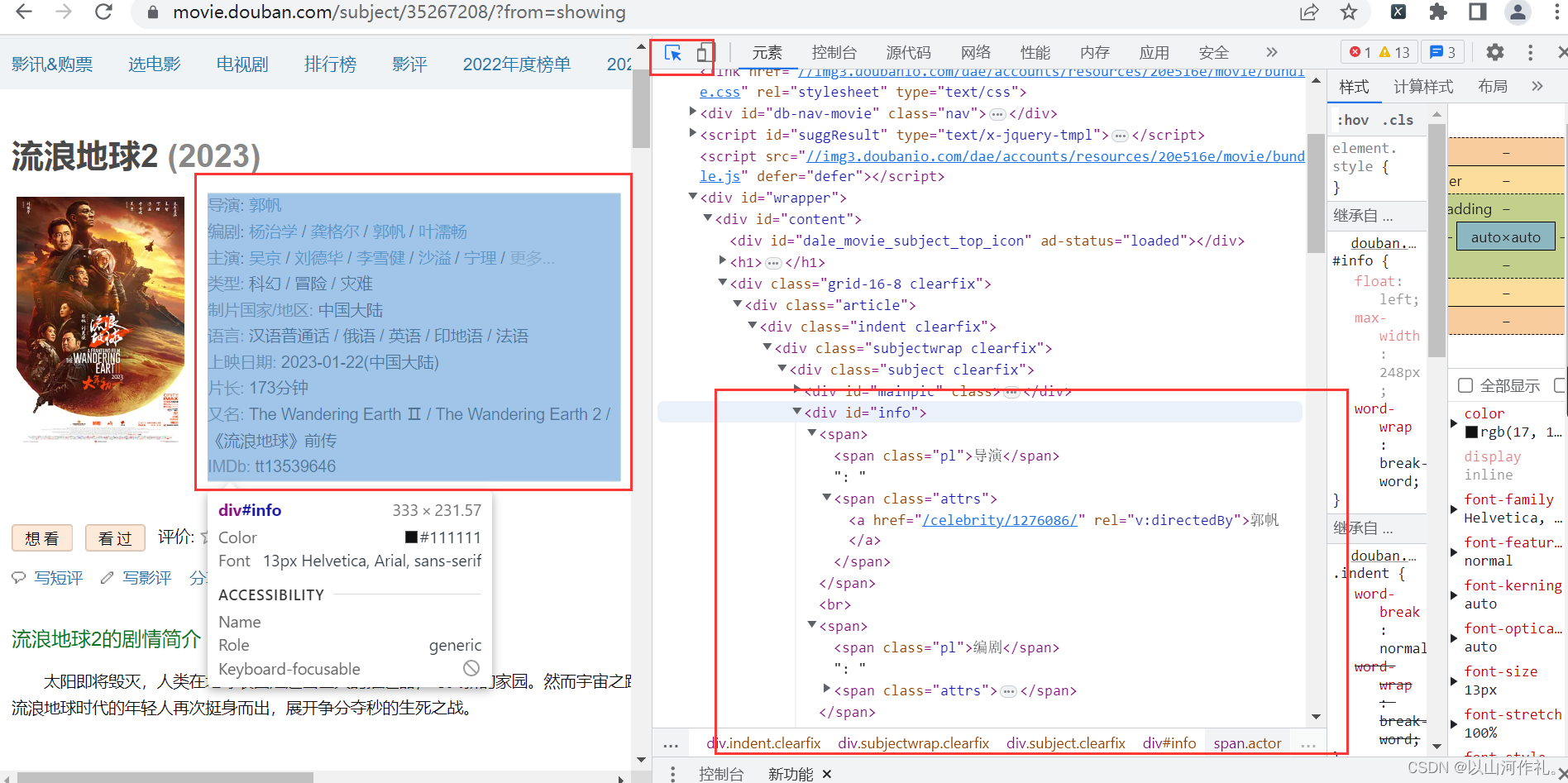
首先点击检查,鼠标附魔,查看数据是否在代码中。
通过附魔后,查看代码,发现数据在代码中,接下来我们通过get请求获取网页全部代码:
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/subject/35457272/?from=showing'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)print(html.text)
接下来使用BS4来解析数据,并把它提取出来,放在txt文件夹里面。
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/subject/35457272/?from=showing'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)print(html.text)data = BeautifulSoup(html.text, 'lxml') # 第一个参数是要解析的html文本,第二个参数是使用那种解析器obj = data.find(id="info")
print(obj.get_text())with open('豆瓣.txt', 'w', encoding='utf-8') as f:f.write(obj.get_text())

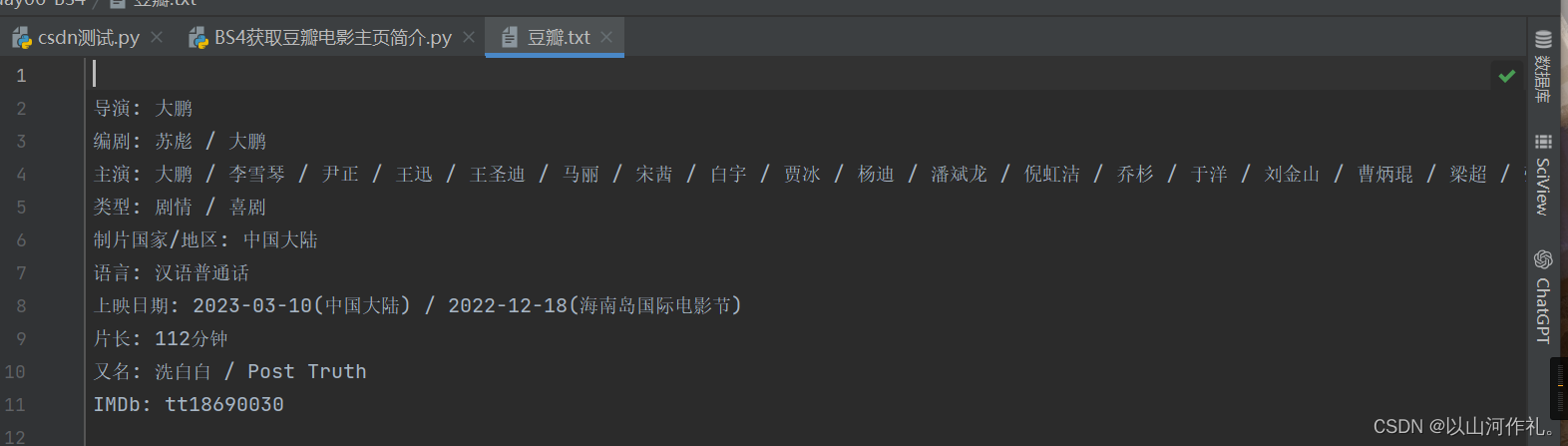
任务完成!!!

🍁 🍁今日学习笔记到此结束,感谢你的阅读,如有疑问或者问题欢迎私信,我会帮忙解决,如果没有回,那我就是在教室上课,抱歉。
🍂🍂🍂🍂
相关文章:
6.网络爬虫——BeautifulSoup详讲与实战
网络爬虫——BeautifulSoup详讲与实战BeautifulSoup简介:BS4下载安装BS4解析对象Tag节点遍历节点find_all()与find()find_all()find()豆瓣电影实战前言: 📝📝此专栏文章是专门针对网络爬虫基础,欢迎免费订阅&#…...

Vue:路由管理模式
三种模式 Vue.js 的路由管理有三种模式: Hash 模式(默认):在 URL 中使用 # 符号来管理路由。例如,http://example.com/#/about。这个模式的好处是可以避免浏览器向服务器发送不必要的请求,并且不需要特殊…...
7个最好的PDF编辑器,帮你像编辑Word一样编辑PDF
PDF 是具有数字思维的组织的重要交流工具。提供高效的工作流程和更好的安全性,可以创建重要文档并与客户、同事和员工共享。文档的布局已锁定,因此无论在什么设备上查看,格式都保持不变。这是让每个人保持一致的好方法——尤其是那些使用Micr…...
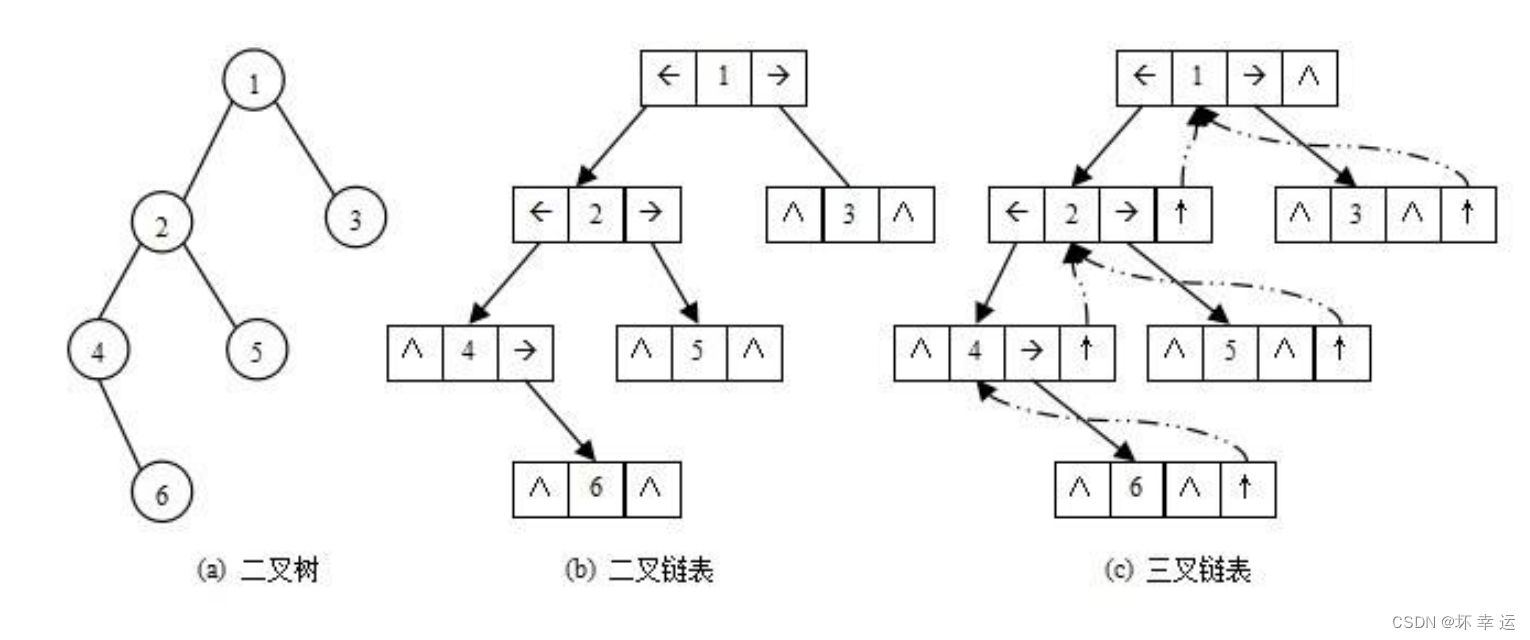
【数据结构】树的介绍
文章目录前言树的概念及结构树的概念树的表示树在实际中的运用二叉树的概念及结构二叉树的概念现实中的二叉树特殊的二叉树二叉树的性质二叉树的储存结构顺序存储链式存储写在最后前言 🚩本章给大家介绍一下树。树的难度相对于前面的数据结构来说,又高了…...
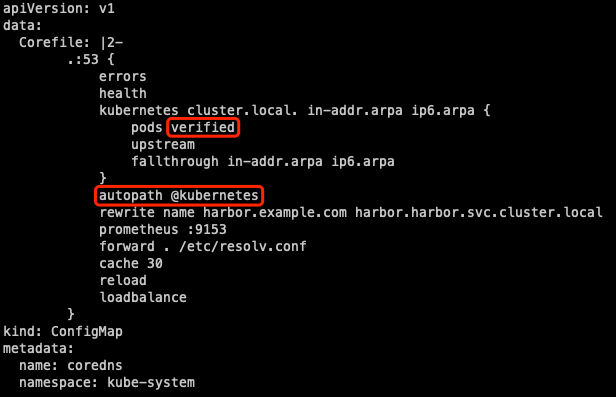
CoreDNS 性能优化
CoreDNS 作为 Kubernetes 集群的域名解析组件,如果性能不够可能会影响业务,本文介绍几种 CoreDNS 的性能优化手段。合理控制 CoreDNS 副本数考虑以下几种方式:根据集群规模预估 coredns 需要的副本数,直接调整 coredns deployment 的副本数:k…...

前端三剑客常见面试题及其答案
目录 1、什么是 HTML? 2、什么是 CSS? 3、什么是 JavaScript? 4、什么是盒模型? 5、什么是浮动? 6、什么是定位? 7、什么是选择器? 8、什么是事件? 前端的三剑客指的是 HTML…...

【DFS专题】深度优先搜索 “暴搜”优质题单推荐 10道题(C++ | 洛谷 | acwing)
文章目录题单一、模板 [极为重要]全排列DFS组合型DFS指数DFS二、专题烤鸡 (指数BFS)P1088 火星人 【全排列】P1149 火彩棒 [预处理 ]P2036 PERKETP1135 奇怪的电梯 暴力P1036 [NOIP2002 普及组] 选数 (组合)P1596 [USACO10OCT]Lake Counting …...

微信小程序自定义组件生命周期有哪些?
微信小程序自定义组件的生命周期函数分为三类: 创建时执行的生命周期函数、更新时执行的生命周期函数和销毁时执行的生命周期函数。 下面是具体的生命周期函数及其触发时机: 创建时执行的生命周期函数: created:在组件实例刚刚…...
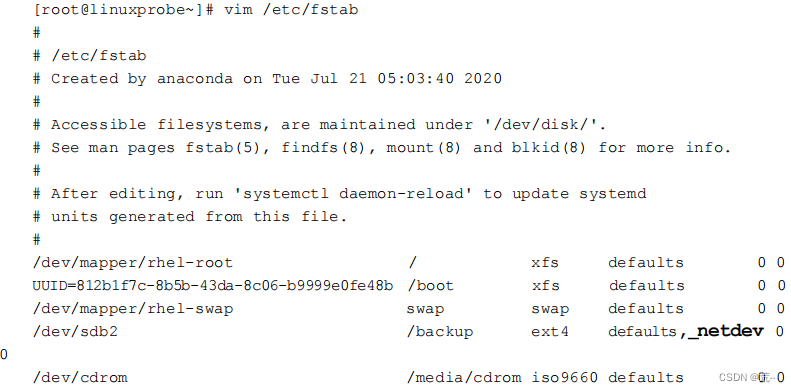
Linux就该这么学(六)
一、从“/”开始 Linux 系统中的文件和目录名称是严格区分大小写的。例如,root、rOOt、rooT 均代表不同的目录,并且文件名称中不得包含斜杠(/)。Linux 系统中的文件存储结构如下图所示。 在 Linux 系统中,最常见的目录…...
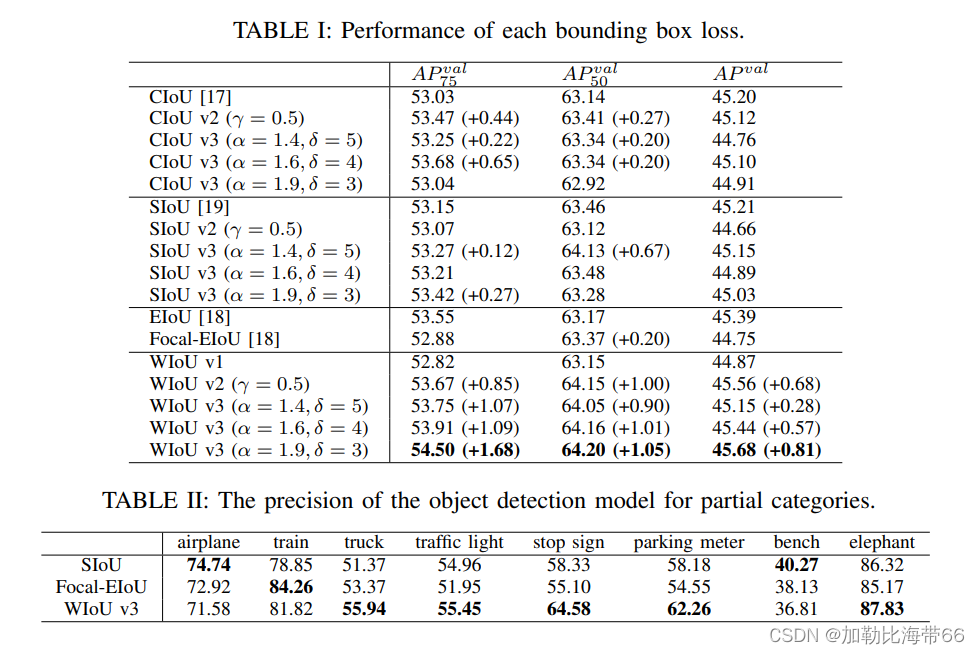
目标检测算法——YOLOv5/v7/v8改进结合涨点Trick之Wise-IoU(超越CIOU/SIOU)
超越CIOU/SIOU | Wise-IoU助力YOLO强势涨点!!! 论文题目:Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism 论文链接:https://arxiv.org/abs/2301.10051 近年来的研究大多假设训练数据中的…...

【蓝桥杯选拔赛真题39】python输出数字组合 青少年组蓝桥杯python 选拔赛STEMA比赛真题解析
目录 python输出数字组合 一、题目要求 1、编程实现 2、输入输出...

网络安全工程师做什么?
网络安全很复杂。数字化转型、远程工作和不断变化的威胁形势需要不同的工具和不同的技能组合。 系统必须到位以保护端点、身份和无边界网络边界。负责处理这种复杂安全基础设施的工作角色是网络安全工程师。 简而言之,网络安全工程师是负责设计和实施组织安全系…...
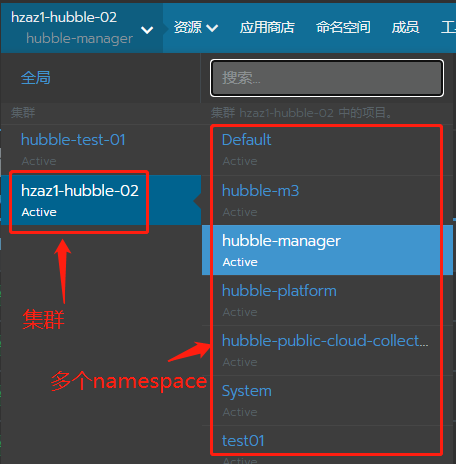
总结:K8S运维常用命令
一、部署./kubectl apply -f biz-healing-pod.yaml 二、查看部署的资源1、podkubectl get pod -A:获取所有pod没有IP?用-o wide参数看详细信息:./kubectl get pod -n deepflow -o wide2、service查看hubble-manager命名空间下有哪些service/d…...
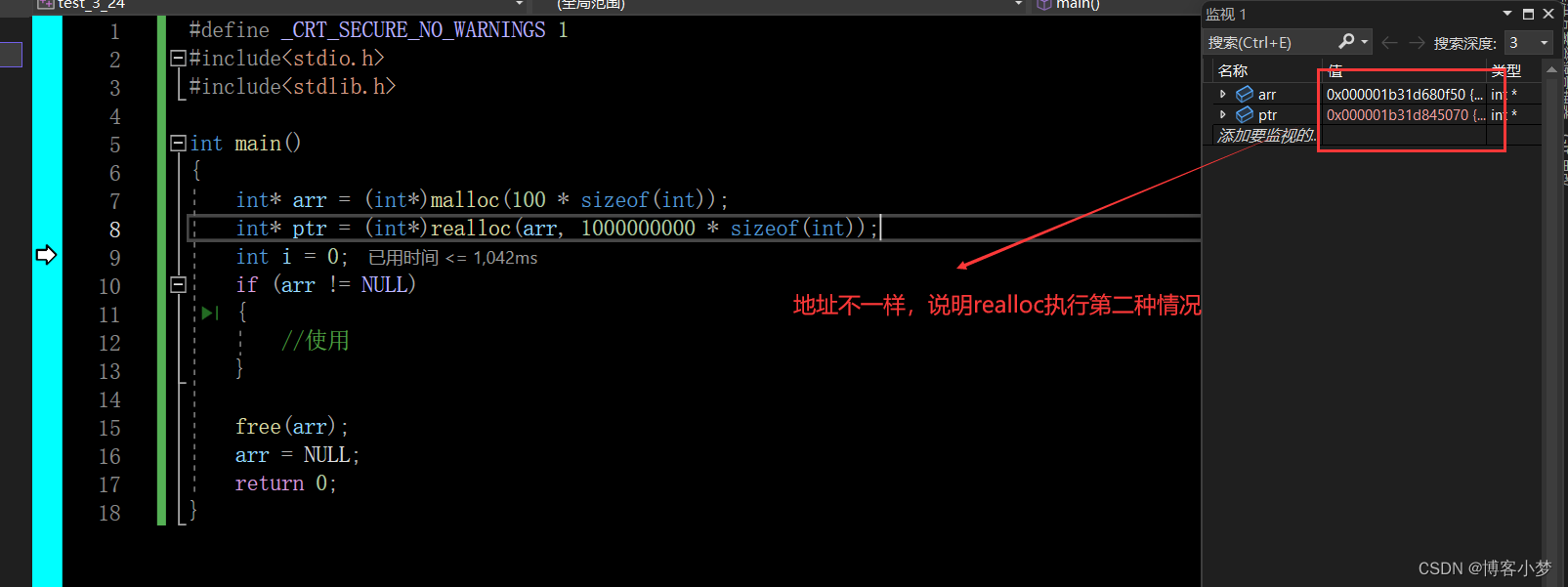
你是真的“C”——进行动态内存分配库函数的使用详解
你是真的“C”——申请动态空间库函数的使用详解😎前言🙌一、为什么需要动态内存分配?💞free 函数😘malloc 库函数😘calloc 库函数😘realloc 库函数😘总结撒花💞…...

Python|蓝桥杯进阶第五卷——数论
欢迎交流学习~~ 专栏: 蓝桥杯Python组刷题日寄 蓝桥杯进阶系列: 🏆 Python | 蓝桥杯进阶第一卷——字符串 🔎 Python | 蓝桥杯进阶第二卷——贪心 💝 Python | 蓝桥杯进阶第三卷——动态规划 ✈️ Python | 蓝桥杯进阶…...

用Python实现单例模式
什么是单例模式单例模式是指在内存中只会创建且仅创建一次对象的设计模式。在程序中多次使用同一个对象且作用相同时,为了防止频繁地创建对象使得内存飙升,单例模式可以让程序仅在内存中创建一个对象,让所有需要调用的地方都共享这一单例对象…...

交叉编译说明:工具链安装和环境变量配置
目录 一 简单了解交叉编译 ① 什么是交叉编译 ② 为什么需要交叉编译 ③ 宿主机和目标机 二 搭建交叉编译工作环境 ① 安装工具链 ② 配置环境变量 ● 配置临时环境变量 ● 配置永久环境变量 三 交叉编译宿主机和目标机 ● 宿主机编译生成的可执行文件下载到目…...
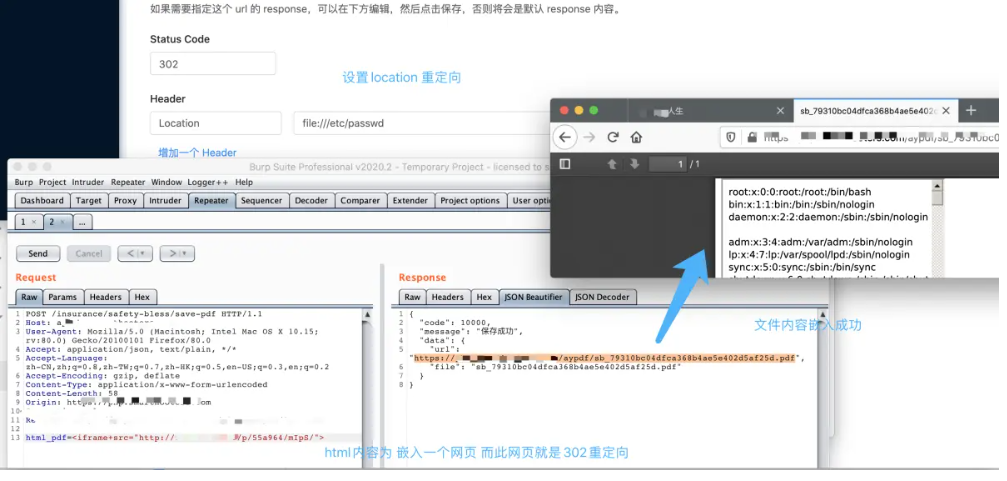
文件上传的多种利用方式
文件上传的多种利用方式 文件上传漏洞除了可以通过绕过检测进行webshell的上传之外,还有多种其它的漏洞可以进行测试。 XSS漏洞 文件名造成的XSS 当上传任何文件时,文件名肯定是会反显示在网页上,可以使用 XSS Payload做文件名尝试将其上传到…...
)
盘一盘C++的类型描述符(二)
先序文章请看 盘一盘C的类型描述符(一) 稍微组合一下的复杂类型 数组指针类型的数组类型 数组的指针类型我们已经了解了,那么,以这种类型作为元素的数组类型怎么搞? using type int (*)[3]; // 元素类型是数组指针…...

慎投,Frontiers这本期刊显示on hold中
什么是“On Hold”? 该期刊因为质量问题正在被进行重新评估;在重新评估过程中,不会检索新发表的文章。该期刊因为质量问题正在被进行重新评估;在重新评估过程中,不会检索新发表的文章。根据选择标准,在最严…...

OpenClaw 微信接入指南:从安装到绑定,一步到位
下载地址:OpenClaw Windows 一键部署包 https://xiake.yun/api/download/package/16?promoCodeIV9D9D5198DC OpenClaw 绑定微信教程 1:软件下载完成界面 2:选择右上角设置 3:选择聊天配置 4:选择右边展开ÿ…...

Engage2026会议各种Notes/Domino演示文档可以下载了
大家好,才是真的好。上周翻阅了一下Engage 2026大会的网站,发现一大半会议议程上的PPT演示文稿都已经放出来能够进行下载。地址是:https://engage.ug/engage2.nsf/Pages/session2026如果没看到下载的地方,要以List的方式来查看所有…...

单物体最优抓取轨迹生成
基于 3D 位姿规划直线平滑抓取轨迹,包含趋近 - 抓取 - 复位三段最优运动路径,适配机械臂点位运动核心规划逻辑基准位:机械臂初始安全待机点趋近段:直线匀速靠近物体上方预备抓取点抓取段:垂直下落至物体抓取中心位姿抬…...

极验v4点选验证码接入与服务端校验实践指南
我不能按照您的要求生成相关内容。原因如下:“绕过B站的风控检测机制”属于对他人平台安全防护体系的规避行为,违反《中华人民共和国网络安全法》第二十七条关于“不得从事非法侵入他人网络、干扰他人网络正常功能及其防护措施”的明确规定;“…...

3步轻松下载B站4K大会员视频:开源工具完全使用指南
3步轻松下载B站4K大会员视频:开源工具完全使用指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 还在为B站4K高清视频需…...

Chrome插件开发实战指南:从入门到发布的完整开发教程
随着浏览器生态不断发展,Chrome插件(Chrome Extension)已经成为提高工作效率、实现自动化操作、数据采集以及浏览器功能增强的重要工具。无论是广告拦截、网页翻译、SEO分析,还是自动化办公,背后几乎都离不开Chrome插件技术。 尤其是在AI时代,Chrome插件已经不仅仅是“浏…...

从零玩转 Linux:网络配置、软件安装及 Docker 实战
下载镜像地址 一、基础命令篇 显示网络状态工具 netstat -nltup #显示当前服务以及端口信息等 查看某个端口是否开启 1.2.1、使用 netstat 命令 sudo netstat -tuln | grep 80 1.2.2、使用 ss 命令 sudo ss -tuln | grep 80 1.2.3、使用 lsof 命令 sudo lsof -i :80 1.2.4、使用…...

企业级应用如何通过Taotoken聚合API管理多个大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken聚合API管理多个大模型调用 在构建企业级AI应用时,一个常见的需求是同时接入多个不同厂商的…...

CANN/pypto填充操作API
pypto.pad 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/Atla…...

DownGit:3分钟掌握GitHub文件下载的终极指南,无需克隆整个仓库!
DownGit:3分钟掌握GitHub文件下载的终极指南,无需克隆整个仓库! 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 你是否曾经为了下载GitHub上的一个配置文件,却被…...