Redis中Big Key该如何解决?
目录
1、Big Key的产生
2、BigKey场景分析
3、Big Key的危害
4、检测 BigKey
5、解决 BigKey 问题
Big Key拆分
(1)按时间/业务拆分
(2)按哈希(Hash)拆分
(3)按前缀树拆分
Big Key定期清理
Big key压缩
Big Key批处理
优化持久化配置
6、总结
Big Key 问题是指某个键(key)的值(value)过大,这会导致 Redis 的性能下降
1、Big Key的产生
- 业务设计不合理
在设计应用时,如果对数据结构的设计不够精细,可能会导致单个 key 存储的数据量过大,没有合理地拆分成多个较小的 key
如:存储了大量数据的字符串、哈希表(hash)、列表(list)等,这会导致在执行涉及该键的操作时消耗更多的时间和资源。
- 未及时清理无用数据
如:忘记设置过期时间,没有定期删除过期或不再需要的数据,List结构中数据持续增加而没有弹出数据的机制,那么数据会越来越多
- 数据类型选择不当
不同的数据类型有不同的内存使用特点。例如,使用字符串类型存储大量数据可能不如使用哈希(HASH)类型来得高效。
选择不适合的数据类型可能导致内存使用效率低下,进而产生 Big Key
如:文件二进制数据不使用 String 保存、使用 HyperLogLog 统计页面 UV、Bitmap 保存状态信息(0/1)
- 动态增长管理不当
某些数据结构可能随着时间和用户行为的变化而不断增长,如果没有适当的管理机制来控制其增长,就可能导致 Big Key 的出现。
如:日志记录、历史数据存储、某个明星热点粉丝列表或者评论的列表等功能如果没有合理的清理策略,可能会导致 key 的数据量逐渐增大
2、BigKey场景分析
以以下常见的场景分析Big Key的问题以及解决方案:
1. 用户行为日志记录
场景描述:应用程序记录用户的行为日志,如点击事件、浏览历史等,通常会将这些数据存储在一个用户的键中。
问题产生:随着用户行为的增多,单一用户的日志数据量会逐渐增大,形成 BigKey。
解决方案:分割日志数据到多个键中,例如按照日期分割。定期归档或清理旧的日志数据
2. 产品目录或商品信息
场景描述:电商平台或零售系统中,每个商品可能包含大量的属性信息,如规格、价格、库存等。
问题产生:如果将所有商品信息都存储在一个键中,随着商品数量的增加,键的大小也会增加。
解决方案:将商品信息拆分为多个键,例如按类别或品牌存储。使用更高效的数据结构,如使用哈希表存储商品的属性
3. 社交网络的好友关系
场景描述:社交应用中,每个用户都有自己的好友列表。
问题产生:当用户的好友数量非常多时,存储好友列表的键可能会变得非常大。
解决方案:将好友列表拆分为多个键,例如按照字母顺序或好友活跃度进行分组。使用有序集合(Sorted Set)存储好友列表,便于快速查找和排序
4. 会话状态存储
场景描述:Web 应用程序中,会话状态通常需要在服务器端存储。
问题产生:如果每个用户的会话状态包含了大量数据,如购物车、登录信息等,会话状态键可能会变得非常大。
解决方案:将会话状态拆分为多个键,例如将购物车和其他状态分开。定期清理过期的会话状态。
3、Big Key的危害
- 性能下降
对 BigKey 执行批量操作,如 HGETALL 或 HSETALL,这些命令的时间复杂度通常是 O(N),其中 N 是键中元素的数量。当 N 很大时,这些操作会变得非常耗时,尤其是在 Redis 的单线程模型下
- 内存占用
BigKey 占用过多的内存,可能导致 Redis 的整体内存使用过高,从而触发内存淘汰策略,影响其他键的性能
- 网络拥塞
BigKey 在网络上传输时会占用较多带宽,特别是当客户端频繁读取或写入 BigKey 时,可能会导致网络拥塞。
- 超时阻塞
Redis 的主要命令执行是在单线程中完成的,这意味着在执行 BigKey 相关操作时,其他客户端的请求会被阻塞,直到该操作完成
- 备份和恢复时间增加
Big Key 会使 RDB 快照文件或 AOF 日志文件增大,从而增加备份和恢复所需的时间。
大量的 Big Key 存在时,可能会导致备份和恢复过程变得非常缓慢
- 复制延迟/删除异常
在主从复制场景中,Big Key 的复制会消耗更多的时间,导致从节点的延迟增加
当Big Key 过期需要删除时,由于数据量过大,可能发生主库较响应时间过长,主从数据同步异常(删除掉的数据,从库还在使用)
4、检测 BigKey
- 使用 redis-cli 工具:可以通过 redis-cli 工具来检测 BigKey
- 使用 Redis 自带的命令:Redis 提供了 BIGKEYS 命令来查询当前 Redis 中所有 key 的信息,帮助统计分析键值对的大小情况
使用以下命令扫描Redis中所有的键,并返回前1000个Big Key
redis-cli --scan --pattern '*' --count 1000redis-cli -a "password" -- bigkeys5、解决 BigKey 问题
-
Big Key拆分
将大键拆分成多个小键,使用更合适的数据结构来存储数据
拆分方式:
(1)按时间/业务拆分
如果 Big Key 包含的是按时间顺序排列的数据,可以考虑按时间范围拆分
(2)按哈希(Hash)拆分
使用哈希函数将大 Key 拆分成多个小 Key,并将其存储在不同的 Redis 实例中
(3)按前缀树拆分
使用前缀树将大 Key 拆分成多个层级结构,每个层级的 Key 都更小
前缀树是一种树形数据结构,用于高效地存储和检索字符串集合
🌰:假设有一个 Big Key 用于存储每天的用户登录记录按照Hash拆分
按照Hash拆分:
HashExample中- 使用 HashMap 来存储键值对。
- insert 方法用于插入以 user: 开头的键值对。
- get 方法用于查找特定键的值。
- printKeysWithPrefix 方法用于打印所有以特定前缀开头的键
public class HashExample {private Map<String, String> hashTable;public HashExample() {hashTable = new HashMap<>();}// 插入键值对public void insert(String key, String value) {if (key.startsWith("user:")) {hashTable.put(key, value);} else {System.out.println("只允许以 'user:' 开头的键。");}}// 查找键public String get(String key) {return hashTable.get(key);}// 查找以特定前缀开头的所有键public void printKeysWithPrefix(String prefix) {System.out.println("以 '" + prefix + "' 开头的键:");for (String key : hashTable.keySet()) {if (key.startsWith(prefix)) {System.out.println(key + ": " + hashTable.get(key));}}}public static void main(String[] args) {HashExample hashExample = new HashExample();hashExample.insert("user:123", "User 123 Data");hashExample.insert("user:456", "User 456 Data");hashExample.insert("admin:001", "Admin Data"); // 不会插入// 查找以 "user:" 开头的所有键hashExample.printKeysWithPrefix("user:");}
}按照前缀树拆分
那么按照前缀树实现来存储和查询以 "user:" 开头的键,该如何实现呢?
首先,需要定义一个前缀树节点的类
TrieNode类中每个节点包含一个字符的子节点映射( children )和一个布尔值( isEndOfKey ),指示该节点是否为一个完整的键
class TrieNode {Map<Character, TrieNode> children;boolean isEndOfKey;public TrieNode() {children = new HashMap<>();isEndOfKey = false;}
}接下来,定义一个前缀树类:
Trie 类: - insert 方法用于插入一个键
- collectKeysWithPrefix 方法用于查找以特定前缀开头的所有键
- collectKeys 方法使用深度优先搜索(DFS)遍历节点,收集所有完整的键
class Trie {private TrieNode root;public Trie() {root = new TrieNode();}// 插入键public void insert(String key) {TrieNode node = root;for (char ch : key.toCharArray()) {node.children.putIfAbsent(ch, new TrieNode());node = node.children.get(ch);}node.isEndOfKey = true;}// 查找以特定前缀开头的所有键public List<String> collectKeysWithPrefix(String prefix) {TrieNode node = root;for (char ch : prefix.toCharArray()) {if (!node.children.containsKey(ch)) {return new ArrayList<>(); // 如果前缀不存在,返回空列表}node = node.children.get(ch);}List<String> keys = new ArrayList<>();collectKeys(node, prefix, keys);return keys;}// 深度优先搜索,收集所有以特定前缀开头的键private void collectKeys(TrieNode node, String currentPrefix, List<String> keys) {if (node.isEndOfKey) {keys.add(currentPrefix);}for (Map.Entry<Character, TrieNode> entry : node.children.entrySet()) {collectKeys(entry.getValue(), currentPrefix + entry.getKey(), keys);}}
}最后,使用前缀树来存储和查询以 "user:" 开头的键:
public class Main {public static void main(String[] args) {Trie trie = new Trie();trie.insert("user:1", "value1");trie.insert("user:2", "value2");trie.insert("user:3", "value3");trie.insert("admin:1", "value4");// 查找以 "user:" 开头的所有键List<String> userKeys = trie.collectKeysWithPrefix("user:");System.out.println("以 'user:' 开头的键: " + userKeys);}
}
Big Key定期清理
异步删除:定期清理不再使用的 BigKey,以释放内存空间
Redis 4.0+ 可以使用 UNLINK 命令来异步删除一个或多个指定的 key。Redis 4.0 以下可以考虑使用 SCAN 命令结合 DEL 命令来分批次删除
设置TTL:对于经常访问的大键,可以考虑使用缓存策略LRU(最近最少使用)来减轻 Redis 的负担
关于缓存策略可以看这篇文章:Redis的过期策略以及内存淘汰机制-CSDN博客
Big key压缩
对于文本数据,可以考虑使用压缩算法来减小存储空间
Redis 支持使用 LZF、QUICKLZ 和 GZIP 算法进行压缩
Big Key批处理
如果 Big Key 不能避免,可以考虑使用分批处理的方式来读取和更新数据,比如使用 SCAN 命令
优化持久化配置
RDB:调整 RDB 的备份频率和条件,减少 Big Key 对 RDB 文件大小的影响。
AOF:启用 AOF 的压缩功能,减少 AOF 文件的大小
🔴建议:
- 避免使用非常长的 Key:理想情况下,Key 的长度应小于 100 字节。
- 使用复合键:使用多个字段(例如,用户 ID 和帖子 ID)组合成一个键,可以减少单个键的长度。
- 使用子列表:将大列表拆分成多个子列表,每个子列表的元素较少。
- 使用 HyperLogLog:HyperLogLog 是一种概率数据结构,可以近似计算大集合中的唯一元素数量,它占用的空间非常小,例如统计页面 UV、网站访问者的唯一 IP 地址、用户的唯一 ID等
6、总结
Redis的Big Key会给Redis带来的意想不到的危害,需要监控、及时发现和处理Big Key。在开发过程中需要选用适当的Redis数据结构开发业务,尽量避免big key
相关文章:

Redis中Big Key该如何解决?
目录 1、Big Key的产生 2、BigKey场景分析 3、Big Key的危害 4、检测 BigKey 5、解决 BigKey 问题 Big Key拆分 (1)按时间/业务拆分 (2)按哈希(Hash)拆分 (3)按前缀树拆分…...

基于springboot的实习管理系统
TOC springboot207基于springboot的实习管理系统 绪论 1.1研究背景与意义 信息化管理模式是将行业中的工作流程由人工服务,逐渐转换为使用计算机技术的信息化管理服务。这种管理模式发展迅速,使用起来非常简单容易,用户甚至不用掌握相关的…...
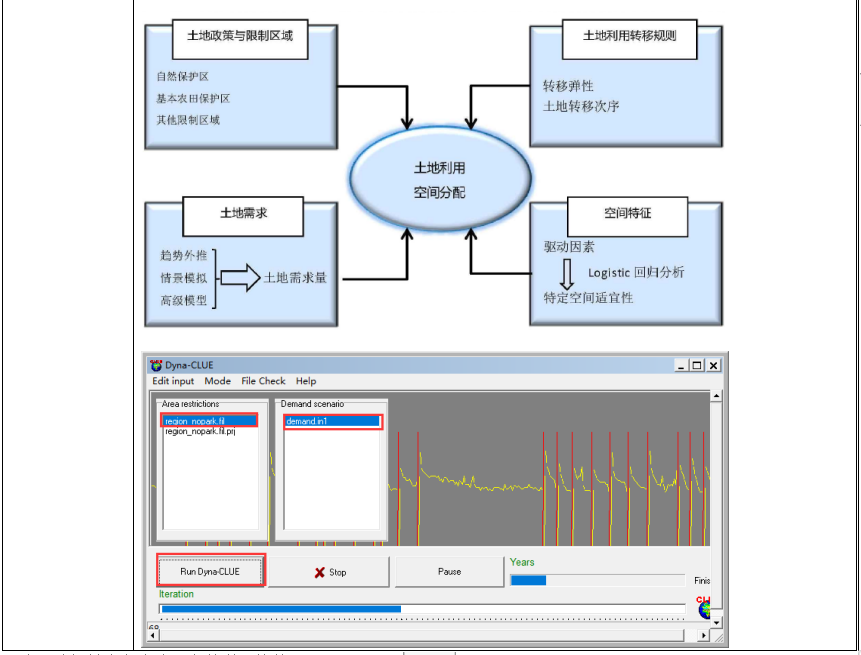
土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测
土地利用/土地覆盖数据是生态、环境和气象等领域众多模型的重要输入参数之一。基于遥感影像解译,可获取历史或当前任何一个区域的土地利用/土地覆盖数据,用于评估区域的生态环境变化、评价重大生态工程建设成效等。借助CLUE模型,实现对未来土…...

Rust 之环境搭建
前言 Rust 是一种现代的系统级编程语言,以其内存安全性、高性能和简洁的语法而著称。本文将介绍如何在不同操作系统上搭建 Rust 开发环境,并配置好基础工具,使您能够快速开始 Rust 编程。 1. 安装 Rust Rust 官方推荐使用 rustup 工具来管…...

基于微信小程序地图实现点位标注、覆盖物、地图聊天
目录 小程序部分map标签的使用获取用户经纬度并转换地址地图点击事件覆盖物标注点击并实现弹窗交互数据库及接口部分数据库表结构设计API搭建小程序接口使用注意事项wx.getLocation深入控制地图小程序部分 map标签的使用 创建小程序的步骤这里不再重复赘述,在wxml页面中放一个…...

xxl-job的分片广播+单播
1 介绍一下xxl-job XXL-JOB 是一个分布式任务调度平台,旨在为分布式应用系统提供开箱即用的调度解决方案。它非常易于使用,并具有很高的可扩展性。以下是 XXL-JOB 的详细介绍,包括其核心功能、架构设计、主要组件及其应用场景。 核心功能 简…...

情感分类代码
在进行自然语言处理中的情感分类时,通常需要准备以下几方面的内容: 1. **数据集**:高质量的标注数据集是关键,包括正面、负面和中性情感标记的文本。 2. **情感词典**:可用的情感词典,如SentiWordNet&…...

WPF—常用控件、属性、事件、详细介绍
WPF—常用控件、属性、事件、详细介绍 WPF(Windows Presentation Foundation)是微软推出的基于Windows 的用户界面框架,属于.NET Framework 3.0的一部分。它提供了统一的编程模型、语言和框架,真正做到了分离界面设计人员与开发人…...

Oracle遭遇bug导致共享内存无法分配报ORA-04031错误
1.故障描述 在7月17日上午11时左右,收到告警短信,提示集群节点2宕机,当即登陆该节点进行查看,发现数据库状态正常。但日志里出现大量的ORA-04031报错,提示无法分配shared_pool,当时手动执行shared pool刷新…...

SAP BRIM用于应收账款AR收入中台
SAP BRIM(Billing and Revenue Innovation Management)是SAP提供的一个综合性解决方案,旨在帮助企业高效管理计费和收入流程。它与SAP ERP系统集成,提供端到端的功能,简化计费流程,自动化收入确认ÿ…...

LVS原理简介
LVS是Linux virtual server的缩写,为linux虚拟服务器,是一个虚拟的服务器集群系统。LVS简单工作原理为用户请求LVS VIP,LVS根据转发方式和算法,将请求转发给后端服务器,后端服务器接收到请求,返回给用户。对…...

Qt五大核心特性之元对象系统
前言 Qt 的元对象系统(Meta-Object System)是 Qt 框架的核心之一,提供了一些 C 原生不具备的功能(因为在C它们是静态的),如反射、信号槽机制、属性系统等。通过这个系统,Qt 实现了许多强大的功能,这使得它…...

开放式耳机伤耳朵吗?开放式耳机在一定程度上保护我们的耳朵
开放式耳机通常被认为对耳朵的伤害较小,因为它们不需要插入耳道,从而减少了耳道内的压力和潜在的感染风险。与传统入耳式耳机相比,开放式耳机允许耳朵自然通风,减少耳道内的湿气和热量积聚,这有助于保持耳朵的健康。 然…...
JAVA打车小程序APP打车顺风车滴滴车跑腿源码微信小程序打车系统源码
🚗💨打车、顺风车、滴滴车&跑腿系统,一键解决出行生活难题! 一、出行新选择,打车从此不再难 忙碌的生活节奏,让我们常常需要快速、便捷的出行方式。打车、顺风车、滴滴车系统,正是为了满足…...

批量智慧:揭秘机器学习中的批量大小
标题:批量智慧:揭秘机器学习中的批量大小 机器学习是人工智能的一个分支,它使得计算机能够从数据中学习并做出决策或预测。在机器学习的过程中,批量大小(Batch Size)是一个至关重要的超参数,它…...

苹果Vision Pro生态发展:现状、挑战与未来展望
苹果公司以其创新技术和强大的生态系统闻名于世。在最近的财报会议上,CEO蒂姆库克分享了Vision Pro平台的最新进展,引发了业界的广泛关注。本文将深入探讨Vision Pro生态的现状、面临的挑战以及与其他XR平台的对比分析。 一、Vision Pro生态现状 据库克介绍,Vision Pro平台…...

湖南第一师范学院来访炼石,推动密码与数据安全合作
2024年8月11日,为进一步加强交流与合作,深入探讨校企产学研合作,湖南第一师范学院计算机学院院长杨恒伏一行莅临炼石调研指导。湖南第一师范学院计算机学院院长杨恒伏、网络空间安全系主任周聪等专家领导出席。炼石网络创始人兼CEO白小勇对湖…...

全面解析ETL:数据仓库架构中的关键处理过程
目录 一、数据仓库架构中的ETL 二、数据抽取 (1)逻辑抽取 (2)物理抽取 (3)变化数据捕获 三、数据转换 四、数据装载 (1)提高装载效率 (2)处理装载失败 五、ET…...

keepalived的介绍与配置
Keepalived是一个轻量级别的高可用解决方案,同时也是一个免费开源的、用C编写的类似于layer3, 4 & 7(也有说法认为是layer3, 4 & 5)交换机制的软件,主要提供负载均衡和高可用服务。它自动完成检测服务器的状态、故障隔离和…...

二叉树概念与使用
文章目录 一、作用二、二叉树概念特征2.1二叉树概念补充2.1.1度2.1.2深度2.1.3若规定根节点的层数为1,则深度为h的二叉树的最大结点数是2^h-1个结点 三、使用2.1二叉树存储,检索,插入项目 四、 二叉树检索的时间复杂度1. 普通二叉树2. 二叉搜…...

HoRain云--Ollama 安装
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

从零开始,在Hermes Agent项目中接入Taotoken服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始,在Hermes Agent项目中接入Taotoken服务 基础教程类,引导使用Hermes Agent框架的开发者完成接入&a…...

Redis Bitmap的隐藏用法:从“优惠券防超领”到“大数据去重”的实战避坑指南
Redis Bitmap的隐藏用法:从“优惠券防超领”到“大数据去重”的实战避坑指南 在数据密集型的现代应用中,如何高效处理海量数据的唯一性校验和状态标记,一直是开发者面临的挑战。Redis的Bitmap数据结构以其极低的内存消耗和O(1)时间复杂度的位…...
)
跟着 MDN 学CSS day_17:(深入理解溢出机制与容器控制艺术)
在CSS的世界里,一切皆为盒子。当我们精心设定盒子的宽度和高度,试图构建完美的布局时,一个不可避免的问题就会悄然出现:**如果内容超出了盒子的承载能力,会发生什么?**这就是CSS中一个至关重要的概念——溢…...

基于堆叠集成学习的脑膜炎早期预警模型:从EHR数据挖掘到临床决策支持
1. 项目概述与核心价值在急诊室(ER)和重症监护室(ICU)里,时间就是生命,而脑膜炎的诊断恰恰是和时间赛跑。这种包裹着大脑和脊髓的脑膜炎症,起病急、进展快,一旦延误,神经…...

为什么你的Mac鼠标和触控板总在“打架“?Scroll Reverser终结滚动方向混乱
为什么你的Mac鼠标和触控板总在"打架"?Scroll Reverser终结滚动方向混乱 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 在Mac生态系统中,有一…...

智慧树自动刷课插件终极指南:3步安装教程,彻底告别手动刷课烦恼!
智慧树自动刷课插件终极指南:3步安装教程,彻底告别手动刷课烦恼! 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的…...

告别无效编程!Cursor + 高德地图实战,解锁AI开发效率密码
当GitHub Copilot还在逐行补全代码时,Cursor已经让开发者用"聊天"的方式写项目了。从Cursor的四大快捷键到AI幻觉的实战应对,从Vibe Coding的前沿理念到高德地图的AI落地实践,本文将带你深度理解AI编程的现在与未来。 目录 一、Cur…...

MAPED技术:电子衍射材料表征的创新方法
1. MAPED技术概述:电子衍射领域的革新方法多角度进动电子衍射(Multi-angle Precession Electron Diffraction, MAPED)是近年来在材料表征领域兴起的一项创新技术。这项技术通过采集不同入射角度的4D-STEM扫描数据,并在后期处理中进…...

OllyDbg与Cheat Engine协同分析恶意软件动态行为
1. 这不是游戏外挂工具,而是逆向工程师的听诊器与显微镜很多人第一次听说OllyDbg或Cheat Engine,是在游戏论坛里看到“修改血量”“无限金币”的教程;也有人在安全群聊中听到老手随口一句:“这壳用OD下断点一跟就破”。但真相是&a…...