四十、大数据技术之Kafka3.x(3)
🌻🌻 目录
- 一、Kafka Broker
- 1.1 Kafka Broker工作流程
- 1.1.1 Zookeeper 存储的Kafka信息
- 1.1.2 Kafka Broker 总体工作流程
- 1.1.3 Broker 重要参数
- 1.2 生产经验——节点服役和退役
- 1.2.1 服役新节点
- 1.2.2 退役旧节点
- 1.3 Kafka 副本
- 1.3.1 副本基本信息
- 1.3.2 Leader 选举流程
- 1.3.3 Leader 和 Follower 故障处理细节
- 1.3.4 分区副本分配
- 1.3.5 生产经验——手动调整分区副本存储
- 1.3.6 生产经验——Leader Partition负载平衡
- 1.3.7 生产经验——增加副本因子
- 1.4 文件存储
- 1.4.1 文件存储机制
- 1.4.2 文件清理策略
- 1.5 高效读写数据
一、Kafka Broker
1.1 Kafka Broker工作流程
1.1.1 Zookeeper 存储的Kafka信息
(1)启动Zookeeper客户端。
cd /usr/local/zookeeper/bin/ls./zkCli.sh

(2)通过ls命令可以查看kafka相关信息。
ls /ls /kafka/ls /kafka/brokers/ls /kafka/brokers/ids

zookeerper 可视化工具 PrettyZoo:
- 下载
- 使用参考
①

②


1.1.2 Kafka Broker 总体工作流程

1)模拟Kafka上下线,Zookeeper中数据变化
(1)查看/kafka/brokers/ids路径上的节点。
./kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties./kafka-server-stop.sh


1.1.3 Broker 重要参数

1.2 生产经验——节点服役和退役
1.2.1 服役新节点
1)新节点准备
(1)关闭linux-102(已经装了hadoop,jdk,zookeeper,kafka),并右键执行克隆操作,linux-103,linux-104(注:之前若有直接可以删掉重新克隆)
(2)开启linux-103,linux-104 并修改IP地址。
①

②

③

④ 修改ip,将192.168.10.102修改为 192.168.10.103,保存,并重启网络


⑤ 修改 主机名


⑥ 重启进行远程连接

⑦ 删除日志,并分别修改linux-103与linux-102 的节点 id 和服务器 ip,并开启集群配置


开启集群配置(linux-102,linux-103,linux-104都需修改)

(3) 先启动linux-102,再启动linux-103,再次启动 linux-104(脚本启动后期更新)
cd /usr/local/zookeeper/bin/./zkServer.sh start./zkServer.sh statuscd /usr/local/kafka/bin./kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties



(4) 查看 linux-102 上有哪些主题,并分配了分区(生产环境建议至少分两个副区,如果不小心删除一个,则还有一个类似备份的)
./kafka-topics.sh --bootstrap-server linux-102:9092 --list./kafka-topics.sh --bootstrap-server linux-102:9092 --topic first --describe

思考:如何将
linux-102上面的一些分到linux-103达到负载均衡呢?看下面 2)
2)执行负载均衡操作
(1)创建一个要均衡的主题(在 linux-102 服务器的 kafka下面创建)。
cd /usr/local/kafkavi topics-to-move.json

{"topics": [{"topic": "first"}],"version": 1
}

(2)生成一个负载均衡的计划(在 linux-102 服务器的 kafka下面生成)。
# 0,1,2 代表三台服务器
bin/kafka-reassign-partitions.sh --bootstrap-server linux-102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
遇到错误:java.io.IOException: Unable to read file topics-to-move.json

解决:直接切换到kafka 根目录进行生成即可:

(3)创建副本存储计划(所有副本存储在broker2、broker3、broker4)。
vi increase-replication-factor.json

输入如下内容:
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2],"log_dirs":["any"]},{"topic":"first","partition":1,"replicas":[2],"log_dirs":["any"]},{"topic":"first","partition":2,"replicas":[2],"log_dirs":["any"]},{"topic":"first","partition":3,"replicas":[2],"log_dirs":["any"]}]}

(4)执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server linux-102:9092 --reassignment-json-file increase-replication-factor.json --execute

(5)验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server linux-102:9092 --reassignment-json-file increase-replication-factor.json --verify

上述操作都是在linux-102上操作的。
1.2.2 退役旧节点
1)执行负载均衡操作
先按照退役一台节点,
生成执行计划,然后按照服役时操作流程执行负载均衡。
(1)创建一个要均衡的主题。
与上面(1)创建一个要均衡的主题(在 linux-102 服务器的 kafka下面创建)。一样无需再创建。
(2)创建执行计划。
#上面是分配到了三台机器 2,3,4,现在移除 4即服务器 linux-104
bin/kafka-reassign-partitions.sh --bootstrap-server linux-102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "2,3" --generate

(3)创建副本存储计划(所有副本存储在broker2、broker3)。
vi increase-replication-factor.json

删除前面的,将上面复制的粘贴里面保存即可。

粘贴上面复制的如下内容:
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2],"log_dirs":["any"]},{"topic":"first","partition":1,"replicas":[2],"log_dirs":["any"]},{"topic":"first","partition":2,"replicas":[2],"log_dirs":["any"]},{"topic":"first","partition":3,"replicas":[2],"log_dirs":["any"]}]}
(4)执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server linux-102:9092 --reassignment-json-file increase-replication-factor.json --execute

(5)验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server linux-102:9092 --reassignment-json-file increase-replication-factor.json --verify

2)执行停止命令
在linux-104上执行停止命令即可
./kafka-server-stop.sh

1.3 Kafka 副本
下面的所有后期会详细更新(可跳过直接看 👉👉
大数据技术之Kafka3.x(4))
1.3.1 副本基本信息
- (1)Kafka 副本作用:
提高数据可靠性。- (2)Kafka默认副本1个,生产环境一般配置为2个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
- (3)Kafka中副本分为:Leader和Follower。Kafka生产者只会把数据发往Leader,然后Follower找Leader进行同步数据。
(4)Kafka分区中的所有副本统称为AR(Assigned Repllicas)。
AR = ISR + OSR
ISR,表示和Leader保持同步的Follower集合。如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。Leader发生故障之后,就会从ISR中选举新的Leader。
OSR,表示Follower与Leader副本同步时,延迟过多的副本。
1.3.2 Leader 选举流程
(
跳过后期更新)
Kafka 集群中有一个
broker的Controller会被选举为Controller Leader,负责管理集群 broker 的上下线,所有topic的分区副本分配和Leader选举等工作。
Controller的信息同步工作是依赖于Zookeeper的。

开启
linux-102,linux-103,linux-104,进行如下操作:
(1)创建一个新的topic,4个分区,4个副本(因为我是单节点,所以设置了 1)
bin/kafka-topics.sh --bootstrap-server linux-102:9092 --create --topic Daniel1 --partitions 1 --replication-factor 1

(2)查看Leader分布情况
bin/kafka-topics.sh --bootstrap-server linux-102:9092 --describe --topic Daniel1

(3)停止掉linux-103的kafka进程,并查看Leader分区情况

(4)停止掉linux-104的kafka进程,并查看Leader分区情况
(5)启动linux-104的kafka进程,并查看Leader分区情况
(6)启动linux-104的kafka进程,并查看Leader分区情况
(7)停止掉linux-103的kafka进程,并查看Leader分区情况
1.3.3 Leader 和 Follower 故障处理细节

1.3.4 分区副本分配
(
跳过后期更新)
如果kafka服务器只有4个节点,那么设置kafka的分区数大于服务器台数,在kafka底层如何分配存储副本呢?
1)创建16分区,3个副本
(1)创建一个新的topic,名称为second。
bin/kafka-topics.sh --bootstrap-server linux-102:9092 --create --topic second --partitions 16 --replication-factor 3

(2)查看分区和副本情况。


1.3.5 生产经验——手动调整分区副本存储

手动调整分区副本存储的步骤如下:
(1)创建一个新的topic,名称为three。

(2)查看分区副本存储情况。

(3)创建副本存储计划(所有副本都指定存储在broker0、broker1中)。
(4)执行副本存储计划。
(5)验证副本存储计划。
(6)查看分区副本存储情况。
1.3.6 生产经验——Leader Partition负载平衡


1.3.7 生产经验——增加副本因子
在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的增加需要先制定计划,然后根据计划执行。
1)创建topic
2)手动增加副本存储
(1)创建副本存储计划(所有副本都指定存储在broker0、broker1、broker2中)。
(2)执行副本存储计划。
1.4 文件存储
1.4.1 文件存储机制
1)Topic数据的存储机制

2)思考:Topic数据到底存储在什么位置?
(1)启动生产者,并发送消息。
(2)查看linux-102(或者linux-103、linux-104)的/usr/local/kafka/datas/first-1(first-0、first-2)路径上的文件。
(3)直接查看log日志,发现是乱码。
(4)通过工具查看index和log信息。
3)index文件和log文件详解

说明:日志存储参数配置

1.4.2 文件清理策略
Kafka中默认的日志保存时间为7天,可以通过调整如下参数修改保存时间。
Kafka中默认的日志保存时间为7天,可以通过调整如下参数修改保存时间。
- log.retention.hours,最低优先级小时,默认7天。
- log.retention.minutes,分钟。
- log.retention.ms,最高优先级毫秒。
- log.retention.check.interval.ms,负责设置检查周期,默认5分钟。
那么日志一旦超过了设置的时间,怎么处理呢?
Kafka中提供的日志清理策略有delete和compact两种。
1)delete日志删除:将过期数据删除
- log.cleanup.policy = delete 所有数据启用删除策略
(1)基于时间:默认打开。以segment中所有记录中的最大时间戳作为该文件时间戳。
(2)基于大小:默认关闭。超过设置的所有日志总大小,删除最早的segment。
log.retention.bytes,默认等于-1,表示无穷大。
思考:如果一个segment中有一部分数据过期,一部分没有过期,怎么处理?

2)compact日志压缩

1.5 高效读写数据
- 1)Kafka本身是分布式集群,可以采用分区技术,并行度高
- 2)读数据采用稀疏索引,可以快速定位要消费的数据
- 3)顺序写磁盘
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。

4)页缓存 + 零拷贝技术

相关文章:
四十、大数据技术之Kafka3.x(3)
🌻🌻 目录 一、Kafka Broker1.1 Kafka Broker工作流程1.1.1 Zookeeper 存储的Kafka信息1.1.2 Kafka Broker 总体工作流程1.1.3 Broker 重要参数 1.2 生产经验——节点服役和退役1.2.1 服役新节点1.2.2 退役旧节点 1.3 Kafka 副本1.3.1 副本基本信息1.3.2…...

redis——基本命令
什么是Reids(REmote Dictionary Server) Redis是现在主流的数据库之一,是一个使用ANSI C编写的开源、包含多种数据结构、支持网络的、基于内存、可选持久性的键值对存储数据。 特性 1.速度快 :Redis的数据全部存储瑜内存中。 …...

pytorch实现单层线性回归模型
文章目录 简述代码重构要点 数学模型、运行结果数据构建与分批模型封装运行测试 简述 python使用 数值微分法 求梯度,实现单层线性回归-CSDN博客 python使用 计算图(forward与backward) 求梯度,实现单层线性回归-CSDN博客 数值微分…...

智能小家电能否利用亚马逊VC搭上跨境快车?——WAYLI威利跨境助力商家
智能小家电行业在全球化背景下,正迎来前所未有的发展机遇。亚马逊为品牌商和制造商提供的一站式服务平台,为智能小家电企业提供了搭乘跨境快车、拓展国际市场的绝佳机会。 首先,亚马逊VC平台能够帮助智能小家电企业简化与亚马逊的合作流程&am…...
顺丰科技25届秋季校园招聘常见问题答疑及校招网申测评笔试题型分析SHL题库Verify测评
Q:顺丰科技2025届校园招聘面向对象是? A:2025届应届毕业生,毕业时间段为2024年10月1日至2025年9月30日(不满足以上毕业时间的同学可以关注顺丰科技社会招聘或实习生招聘)。 Q:我可以投递几个岗…...

深入理解 Kibana 配置文件:一份详尽的指南
Kibana 是一个强大的数据可视化平台,它允许用户通过 Elasticsearch 轻松地探索和分析数据。Kibana 的配置文件 kibana.yml 是定制和优化 Kibana 行为的关键。在这篇博客中,我们将深入探讨 kibana.yml 文件中的各个配置项,并提供示例说明。 服…...

算法的学习笔记—链表中倒数第 K 个结点(牛客JZ22)
😀前言 在编程过程中,链表是一种常见的数据结构,它能够高效地进行插入和删除操作。然而,遍历链表并找到特定节点是一个典型的挑战,尤其是当我们需要找到链表中倒数第 K 个节点时。本文将详细介绍如何使用双指针技术来解…...
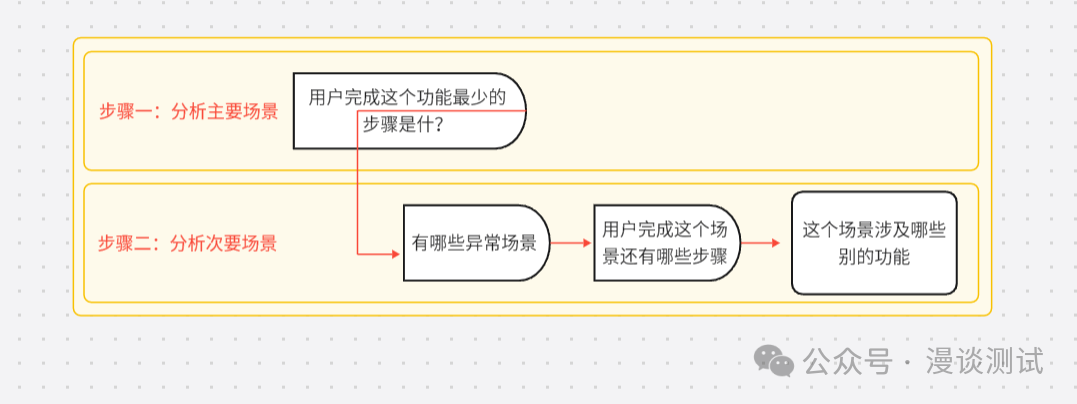
聊聊场景及场景测试
在我们进行测试过程中,有一种黑盒测试叫场景测试,我们完全是从用户的角度去理解系统,从而可以挖掘用户的隐含需求。 场景是指用户会使用这个系统来完成预定目标的所有情况的集合。 场景本身也代表了用户的需求,所以我们可以认为…...

Spring Web MVC入门(中)
1. 请求 访问不同的路径, 就是发送不同的请求. 在发送请求时, 可能会带⼀些参数, 所以学习Spring的请求, 主要 是学习如何传递参数到后端以及后端如何接收. 传递参数, 咱们主要是使⽤浏览器和Postman来模拟; 1.1 传递单个参数 接收单个参数,在Spring MV…...

Django后端架构开发:后台管理与会话技术详解
🌟 Django后端架构开发:后台管理与会话技术详解 🔹 后台管理:自定义模型类 Django的后台管理系统提供了强大的模型管理功能,你可以通过自定义模型类来控制模型在后台管理界面的显示和操作。自定义模型类通过继承admin…...
)
挑战Infiniband, 爆改Ethernet(2)
挑战Infiniband, 爆改Ethernet之物理层 前面说过UE为了挑战Infiniband在AI集群和HPC领域的优势地位,计划爆改以太网技术,以适应AI和HPC集群对高性能、可扩展网络的需求。正如UE联盟关于愿景的说明中宣称的:”提供一个完整的架构,通…...
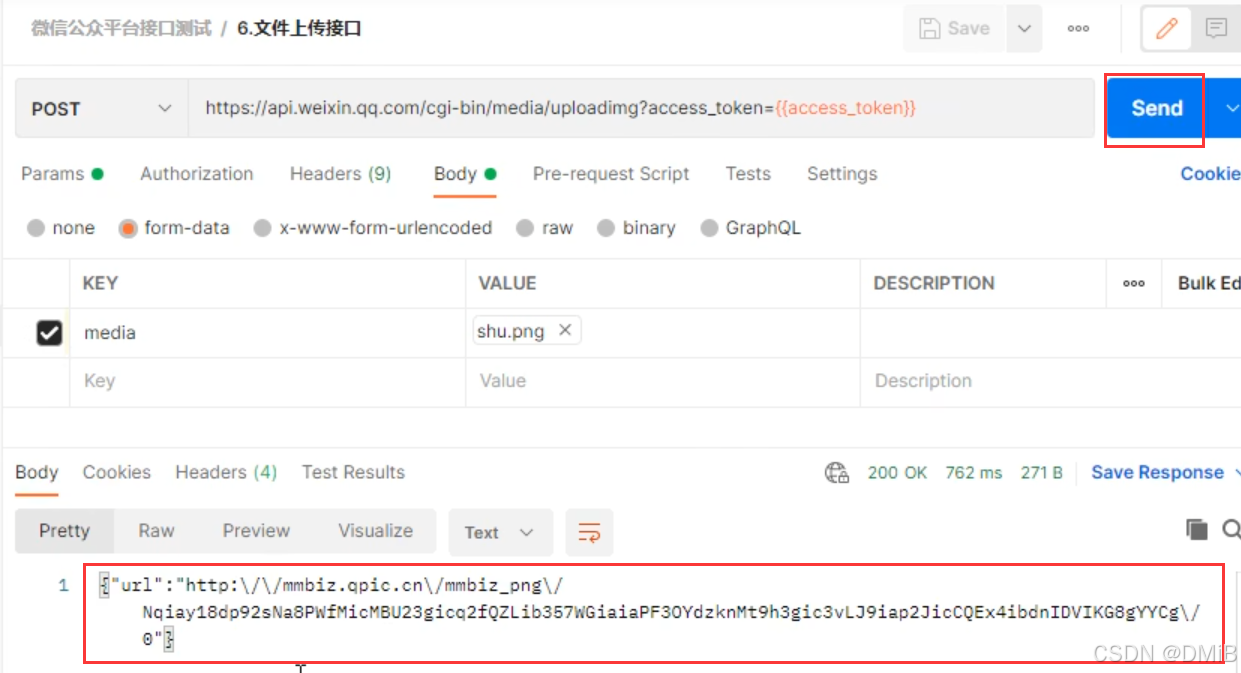
Postman文件上传接口测试
接口介绍 返回示例 测试步骤 1.添加一个新请求,修改请求名,填写URL,选择请求方式 2.将剩下的media参数放在请求body里,选择form-data,选择key右边的类型为file类型,就会出现选择文件的按钮Select Files&a…...

stm32入门学习14-电源控制
有时候我们的程序中有些触发执行条件,有时这些触发频率很少,我们的程序就一直在循环,这样就很浪费电,我们可以通过PWR电源控制来实现低功耗模式,即只有在触发时才执行程序,其余时间可以关闭一些没必要的设备…...

[C++][opencv]基于opencv实现photoshop算法色相和饱和度调整
【测试环境】 vs2019 opencv4.8.0 【效果演示】 【核心实现代码】 HSL.hpp #ifndef OPENCV2_PS_HSL_HPP_ #define OPENCV2_PS_HSL_HPP_#include "opencv2/core.hpp" using namespace cv;namespace cv {enum HSL_COLOR {HSL_ALL,HSL_RED,HSL_YELLOW,HSL_GREEN,HS…...

Github 2024-08-16Java开源项目日报 Top10
根据Github Trendings的统计,今日(2024-08-16统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Java项目10TypeScript项目1Ruby项目1Apache Dubbo: 高性能的Java开源RPC框架 创建周期:4441 天开发语言:Java协议类型:Apache License 2.0St…...

AI学习记录 - torch 的 matmul和dot的关联,也就是点乘和点积的联系
有用大佬们点点赞 1、两个一维向量点积 ,求 词A 与 词A 之间的关联度 2、两个词向量之间求关联度,求 : 词A 与 词A 的关联度 5 词A 与 词B 的关联度 11 词B 与 词A 的关联度 11 词B 与 词B 的关联度 25 刚刚好和矩阵乘法符合: 3、什么是…...

leetcode 885. Spiral Matrix III
题目链接 You start at the cell (rStart, cStart) of an rows x cols grid facing east. The northwest corner is at the first row and column in the grid, and the southeast corner is at the last row and column. You will walk in a clockwise spiral shape to visi…...

mysql windows安装与远程连接配置
安装包在主页资源中 一、安装(此安装教程为“mysql-installer-community-5.7.41.0.msi”安装教程,安装到win10环境) 保持默认选项,点击”Next“。 点开第一行加号展开一路展开找到“MySQL Server 5,7,41 - X64”点击选中点击一下中间只想右侧的箭头看到…...

子网掩码是什么以及子网掩码相关计算
子网掩码 (Subnet Mask) 又称网络掩码 (Netmask),告知主机或路由设备,地址的哪一部分是网络号,包括子网的网络号部分,哪一部分是主机号部分。 子网掩码使用与IP地址相同的编址格式,即32 bit—4个8位组的32位长格式。…...

仿RabbitMQ实现消息队列
前言:本项目是仿照RabbitMQ并基于SpringBoot Mybatis SQLite3实现的消息队列,该项目实现了MQ的核心功能:生产者、消费者、中间人、发布、订阅等。 源码链接:仿Rabbit MQ实现消息队列 目录 前言:本项目是仿照Rabbi…...

HashMap 源码解析 底层原理 面试如何回答
HashMap 源码解析 底层原理 面试如何回答 一、参考资料 【Java视频教程,java入门神器(附300道Java面试题剖析)】 https://www.bilibili.com/video/BV1PY411e7J6/?p172&share_sourcecopy_web&vd_source855891859b2dc554eace9de3f28b4…...

ppt模板_0041_十一国庆主题3
PPT模板分享...

深度解析Windows运行库兼容性:VisualCppRedist AIO完整技术方案
深度解析Windows运行库兼容性:VisualCppRedist AIO完整技术方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库缺失问题是Windows系统…...

【VibeCoding系列教程05】AI编程工具别瞎选!我用过一遍后,把它们分成了3个段位
我刚用AI做出了人生第一个网页应用,正沉浸在"原来我也能当程序员"的幻觉中。结果第二天我就遇到了一个更头疼的问题——市面上的AI编程工具,多得像超市里的酸奶,看着都差不多,拿起来才发现有的过期了有的加糖太多。有人…...

Taotoken在多模型API聚合中的稳定性与低延迟体验观测
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken在多模型API聚合中的稳定性与低延迟体验观测 在项目开发中,尤其是那些重度依赖大模型能力的应用,A…...

5分钟解锁Cursor Pro:免费使用AI编程助手的终极指南
5分钟解锁Cursor Pro:免费使用AI编程助手的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

使用TaotokenCLI工具一键配置开发环境与密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境与密钥 在接入多个大模型服务时,开发者通常需要为不同的工具和项目手动配置API密…...

告别电脑休眠烦恼:MouseJiggler鼠标抖动工具完全指南
告别电脑休眠烦恼:MouseJiggler鼠标抖动工具完全指南 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and forth. 项目…...

Ubuntu 24.04 SSH密钥登录失效原因与实战修复全指南
1. 为什么24.04的SSH配置不能照搬22.04的经验?Ubuntu 24.04 LTS(Noble Numbat)发布后,我第一时间在三台生产边缘节点上做了迁移测试——结果两台在SSH密钥登录环节直接卡死,ssh -v输出停在debug1: Next authentication…...

软件可维护性评估工具对比:从代码行数到AI模型,谁更懂开发者?
1. 项目概述:为什么我们需要重新审视可维护性评估?在软件开发的日常里,我们总在和时间赛跑。新功能要上线,Bug要修复,架构要优化,而代码库就在这日复一日的迭代中悄然生长。直到某一天,你发现修…...