Redis:查询是否包含某个字符/字符串之二
上一篇:Redis:查询是否包含某个字符/字符串之一-CSDN博客
下一篇:Redis:查询是否包含某个字符/字符串之三-CSDN博客
摘要:
要查询数据,就需要遍历key,遍历value,其中包含存储等辅助功能
正文:
一、Python 遍历Redis所有key,并判断value中是否包涵每个字符串
在Python中遍历Redis的所有key,并检查每个key对应的value是否包含特定的字符串,可以使用redis-py库来完成。但是,需要注意的是,直接遍历Redis中的所有key(使用KEYS *)在key数量非常多的情况下可能会导致Redis服务阻塞,因此推荐使用SCAN命令来迭代地遍历key。
以下是一个使用redis-py库和SCAN命令来遍历Redis中所有key,并检查每个key的value是否包含特定字符串的示例代码:
import redis # 连接到Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True) # 要搜索的字符串列表
search_strings = ['example1', 'example2', 'another_string'] # 使用SCAN命令迭代遍历Redis中的所有key
cursor = '0'
while cursor != 0: cursor, keys = r.scan(cursor=cursor, match='*', count=100) for key in keys: # 获取key对应的value value = r.get(key) if value: # 确保value不是None # 检查value是否包含任何一个search_strings中的字符串 for search_string in search_strings: if search_string in value: print(f"Key: {key}, Value: {value}, contains: {search_string}") break # 如果已经找到一个匹配的字符串,可以跳出内层循环 # 注意:上面的代码假设所有value都是字符串。如果value是其他类型(如列表、集合等),则需要相应地调整检查逻辑。请注意以下几点:
-
连接Redis:确保你已经安装了
redis-py库,并且正确配置了Redis服务器的连接信息。 -
SCAN命令:这里使用了SCAN命令来迭代地遍历key,而不是KEYS *。count参数指定了每次迭代返回的key的最大数量,但实际返回的key数量可能会更少。 -
检查value:示例代码假设所有的value都是字符串类型。如果value是其他类型(如列表、集合、哈希等),则需要使用相应的Redis命令来获取和检查这些类型的数据。
-
性能考虑:遍历Redis中的所有key并检查它们的value是一个资源密集型操作,特别是在key数量很多的情况下。请确保这种操作不会在生产环境中对Redis性能造成不利影响。
-
错误处理:示例代码中没有包含错误处理逻辑。在实际应用中,你可能需要添加适当的错误处理来捕获和处理可能发生的异常,如网络问题、Redis服务器不可用等。
二、需要区分Redis返回的不同数据结构进行后续的遍历查询
在Redis中,不同的数据结构(如字符串、列表、集合、有序集合、哈希表)需要使用不同的命令来遍历或查询。当你从Redis获取数据时,首先你需要知道这个数据是以什么数据结构存储的,然后才能使用相应的命令来进行遍历或查询。
以下是一些基本的数据结构和它们对应的遍历/查询方法:
- 字符串(String):
- 字符串是Redis中最基本的数据类型,但它本身不支持遍历,因为它只存储一个值。但是,你可以使用
GET命令来获取这个值,然后根据值的类型(如果它是JSON、XML或其他可解析的格式)在客户端进行解析和遍历。
- 字符串是Redis中最基本的数据类型,但它本身不支持遍历,因为它只存储一个值。但是,你可以使用
- 列表(List):
- 使用
LRANGE key start stop命令可以遍历列表中的元素。start和stop是索引值,其中0表示列表的第一个元素。
- 使用
- 集合(Set):
- 使用
SMEMBERS key命令可以获取集合中的所有元素,然后你可以在客户端遍历这些元素。
- 使用
- 有序集合(Sorted Set):
- 使用
ZRANGE key start stop [WITHSCORES]命令可以遍历有序集合中的元素及其分数。如果你只关心元素,可以省略WITHSCORES选项。
- 使用
- 哈希表(Hash):
- 哈希表存储键值对,但你不能直接遍历哈希表中的所有值或键。你需要使用
HGETALL key来获取哈希表中的所有字段和值,然后在客户端遍历这个返回的列表(通常是一个字段名-值对的列表)。
- 哈希表存储键值对,但你不能直接遍历哈希表中的所有值或键。你需要使用
在Python中,你可以使用redis-py库来与Redis进行交互,并根据返回的数据类型进行相应的处理。以下是一个简单的示例,展示了如何根据Redis返回的不同数据结构进行遍历查询:
import redis # 连接到Redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True) # 假设我们知道key的数据类型 # 列表
list_key = 'mylist'
for item in r.lrange(list_key, 0, -1): # 遍历整个列表,-1 表示最后一个元素 print(item) # 集合
set_key = 'myset'
for item in r.smembers(set_key): print(item) # 有序集合
zset_key = 'myzset'
for item, score in r.zrange(zset_key, 0, -1, withscores=True): print(f"Item: {item}, Score: {score}") # 哈希表
hash_key = 'myhash'
for key, value in r.hgetall(hash_key).items(): print(f"Field: {key}, Value: {value}") # 注意:对于字符串,你通常不会遍历它,而是直接获取并使用它
string_key = 'mystring'
value = r.get(string_key)
print(value) # 或者根据值的类型进行解析和遍历请注意,上述代码中的decode_responses=True参数确保从Redis返回的数据被解码为Python字符串(而不是字节对象)。这对于处理文本数据非常有用。如果你的数据是二进制数据,你可能需要省略这个参数或相应地处理返回的数据。
在Redis中,常见的数据结构包括字符串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)、哈希表(Hash)等。当从Redis获取数据时,你首先需要知道存储该数据的key对应的数据类型,然后才能使用适当的方法来遍历或查询该数据。
以下是一个Python示例,该示例使用redis-py库连接到Redis服务器,并根据不同的数据类型执行不同的遍历或查询操作:
import redis # 连接到Redis服务器
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True) # 假设我们有以下key和它们对应的数据类型
# key1: 字符串
# key2: 列表
# key3: 集合
# key4: 有序集合
# key5: 哈希表 # 函数:根据key的数据类型执行不同的操作
def handle_data_by_type(key): # 获取key的类型 data_type = r.type(key) if data_type == 'string': # 对于字符串,直接获取并打印 value = r.get(key) print(f"String: {value}") elif data_type == 'list': # 对于列表,遍历并打印每个元素 values = r.lrange(key, 0, -1) # 获取列表中的所有元素 for value in values: print(f"List Element: {value}") elif data_type == 'set': # 对于集合,遍历并打印每个元素(注意集合是无序的) members = r.smembers(key) for member in members: print(f"Set Member: {member}") elif data_type == 'zset': # 对于有序集合,遍历并打印每个元素及其分数 for member, score in r.zscan_iter(key): print(f"Sorted Set Member: {member}, Score: {score}") elif data_type == 'hash': # 对于哈希表,遍历并打印每个字段及其值 for field in r.hkeys(key): value = r.hget(key, field) print(f"Hash Field: {field}, Value: {value}") else: print(f"Unknown data type for key: {key}") # 示例:处理不同的key
handle_data_by_type('key1') # 假设key1是字符串
handle_data_by_type('key2') # 假设key2是列表
handle_data_by_type('key3') # 假设key3是集合
handle_data_by_type('key4') # 假设key4是有序集合
handle_data_by_type('key5') # 假设key5是哈希表 # 注意:上面的'key1'到'key5'及其数据类型只是示例,你需要根据实际情况替换它们请注意以下几点:
- 我使用了
r.type(key)来获取key的数据类型。 - 对于列表(List),我使用了
r.lrange(key, 0, -1)来获取所有元素。 - 对于集合(Set),我使用了
r.smembers(key)来获取所有成员。 - 对于有序集合(Sorted Set),我使用了
r.zscan_iter(key)来迭代成员和它们的分数。这是因为zscan_iter比zrange更高效,特别是当有序集合包含大量元素时。但是,请注意zscan_iter返回的是元组的迭代器,其中每个元组包含(成员,分数)。 - 对于哈希表(Hash),我使用了
r.hkeys(key)来获取所有字段,然后对每个字段使用r.hget(key, field)来获取其值。
请根据你的实际需求调整key和数据结构。
三、将打印结果追加打印到txt
在Python中,如果你想要将打印结果(通常是输出到控制台的文本)追加到txt文件中,你可以使用文件操作来实现这一点。以下是一个简单的示例,展示了如何将打印结果追加到txt文件中:
# 打开(或创建)一个文件用于追加内容,如果文件不存在则创建
with open('output.txt', 'a') as file: # 假设这是你想要打印到控制台的文本 text_to_print = "Hello, World!\n" # 首先,你可以将文本打印到控制台 print(text_to_print, end='') # 注意end=''是为了避免在控制台输出额外的换行符 # 然后,将相同的文本写入(追加)到文件中 file.write(text_to_print) # 注意:使用with语句可以确保文件在操作完成后正确关闭在这个例子中,open函数以追加模式('a')打开(或创建)了一个名为output.txt的文件。这意味着如果文件已经存在,新的内容将被追加到文件的末尾;如果文件不存在,将创建一个新文件。
print函数用于将文本输出到控制台,而file.write方法则用于将文本写入文件。注意,print函数默认会在文本末尾添加一个换行符,但在这个例子中,我们通过设置end=''来避免在控制台输出中添加额外的换行符,以保持与控制台输出的一致性(如果你希望控制台输出和文件输出完全一致,包括换行符的话,可以省略end='')。
另外,使用with语句可以确保文件在操作完成后被正确关闭,即使在写入文件时发生异常也是如此。这是一种处理文件时推荐的做法。
四、redis r.scan 自动跳过非utf-8的数据
在 Python 中使用 Redis 时,r.scan() 方法通常用于迭代地遍历 Redis 数据库中的键,但它本身并不直接处理数据的编码问题。r.scan() 返回的是键的列表,这些键是字节串(bytes)类型,而不是直接解码为字符串。因此,当你遇到非 UTF-8 编码的数据时,问题通常发生在尝试将这些字节串解码为字符串时。
要自动跳过非 UTF-8 编码的数据,你需要在迭代 r.scan() 返回的键时,对每个键进行解码尝试,并捕获可能发生的 UnicodeDecodeError 异常。如果捕获到该异常,则可以跳过该键或采取其他适当的措施。
以下是一个示例代码,展示了如何在迭代 Redis 键时跳过非 UTF-8 编码的键:
import redis # 连接到 Redis
r = redis.Redis(host='localhost', port=6379, db=0) # 使用 scan 迭代键
cursor = '0'
while cursor != 0: cursor, keys = r.scan(cursor=cursor, match='*', count=10) for key in keys: try: # 尝试将键解码为 UTF-8 字符串 decoded_key = key.decode('utf-8') # 如果成功解码,则处理该键(这里只是打印出来) print(decoded_key) except UnicodeDecodeError: # 如果解码失败(即不是 UTF-8 编码),则跳过该键 print(f"跳过非 UTF-8 编码的键: {key}") # 此时,所有非 UTF-8 编码的键都已被跳过,程序继续执行在这个示例中,r.scan() 方法用于迭代 Redis 中的键。对于每个键,我们都尝试使用 .decode('utf-8') 方法将其从字节串解码为字符串。如果解码成功,我们就处理该键(在这个例子中是打印出来)。如果解码失败(即捕获到 UnicodeDecodeError 异常),我们就打印一条消息表示跳过了该键,并继续迭代下一个键。
请注意,这种方法假设你只对 UTF-8 编码的键感兴趣。如果你的 Redis 数据库中存储了多种编码的键,并且你需要根据键的编码来执行不同的操作,你可能需要更复杂的逻辑来确定每个键的编码并相应地处理它们。然而,在大多数情况下,将 Redis 中的键统一为 UTF-8 编码是一个好主意,这可以避免在处理数据时遇到编码问题。
小结
这里面我还有一个问题没有解决,欢迎大家交流
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xac in position 0: invalid start byte--end---
相关文章:

Redis:查询是否包含某个字符/字符串之二
上一篇:Redis:查询是否包含某个字符/字符串之一-CSDN博客 下一篇:Redis:查询是否包含某个字符/字符串之三-CSDN博客 摘要: 要查询数据,就需要遍历key,遍历value,其中包含存储等辅助…...

算法笔记|Day23贪心算法
算法笔记|Day23贪心算法 ☆☆☆☆☆leetcode 455.分发饼干题目分析代码 ☆☆☆☆☆leetcode 376. 摆动序列题目分析代码 ☆☆☆☆☆leetcode 53. 最大子序和题目分析代码 ☆☆☆☆☆leetcode 455.分发饼干 题目链接:leetcode 455.分发饼干 题目分析 优先考虑饼干…...
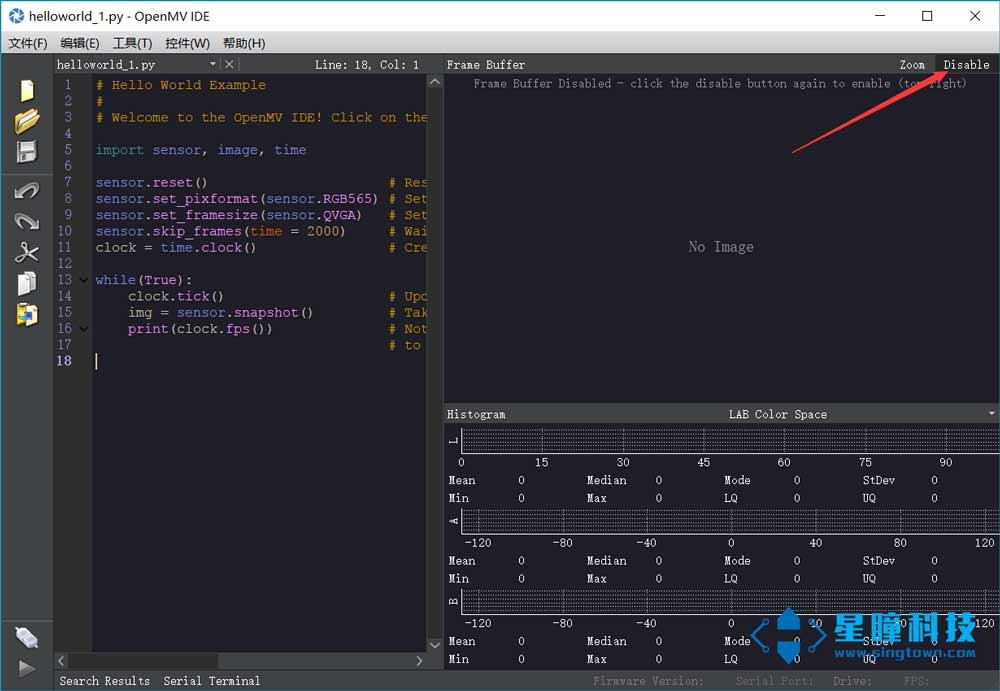
[星瞳科技]OpenMV使用时有哪些常见错误和解决办法?
常见代码错误 ImportError:no module named xxx 这个错误是Import错误,没有stepper这个模块。 原因: 你没有把stepper.py这个文件拖到你的板子里。见:模块的使用 拖过去之后,需要重启,使模块生效 MemoryError:FB …...
:PyTorch使用-张量的类型转换,拼接操作,索引操作,形状操作)
深度学习入门(二):PyTorch使用-张量的类型转换,拼接操作,索引操作,形状操作
目录 1. 张量类型转换 1.1 张量转换为 numpy 数组 1.2 numpy 转换为张量 1.3 标量张量和数字的转换 1.4 小节 2. 张量拼接操作 2.1 torch.cat 函数的使用 2.2 torch.stack 函数的使用 2.3 小节 3. 张量索引操作 3.1 简单行、列索引 3.2 列表索引 3.3 范围索引 3.…...

使用C#禁止Windows系统插入U盘(除鼠标键盘以外的USB设备)
试用网上成品的禁用U盘的相关软件,发现使用固态硬盘改装的U盘以及手机等设备,无法被禁止,无奈下,自己使用C#手搓了一个。 基本逻辑: 开机自启;启动时,修改注册表,禁止系统插入USB存…...

18. 基于ES实战海量数据检索
18. 基于ES实战海量数据检索 一. 概述二. Elasticsearch 全文检索1. 分布式搜索引擎2. 搜索引擎种类3. 倒排索引三. elastic使用1. 官网介绍2. docker安装3. elasticsearch-head工具4. 分词与内置分词4.1 内置分词器(了解即可)4.2 `IK`中文分词器三. 整合SpringCloud1. 基础配置…...

SpringBoot和Redis的交互数据操作以及Redis的持久化/删除策略和缓存问题
目录 一、SpringBoot和Redis/MySQL的数据交互 二、Redis的持久化 1、持久化过程保存什么 2、RDB方式 (1)RDB手动 (2)RDB自动 (3)RDB的优点 (4)RDB缺点 3、AOF方式 &#…...

Butterworth filter的运行原理
想象一下,你正在录制一个舞蹈表演的视频,但在录制过程中,摄像机由于风的影响稍微晃动了一下。现在,录像中的舞者看起来不再那么流畅,动作变得有点颤抖。你希望能让舞者的动作重新看起来平滑和优雅,这时你就…...

掌握SQL的威力:批量更新与删除的艺术
标题:掌握SQL的威力:批量更新与删除的艺术 在数据库管理中,批量更新(UPDATE)和删除(DELETE)操作是常见的需求,特别是在处理大量数据时。SQL作为数据库查询和操作的标准语言…...

《新一代数据可视化分析工具应用指南》正式开放下载
2024年8月12日,由DataEase开源项目组编写的《新一代数据可视化分析工具应用指南》白皮书正式面向广大用户开放下载。 《新一代数据可视化分析工具应用指南》是DataEase开源项目组为了支持企业落地并推广BI工具、推进企业数据可视化建设而编著的指导手册。通过本白皮…...
数据结构与算法——BFS(广度优先搜索)
算法介绍: 广度优先搜索(Breadth-First Search,简称BFS)是一种遍历或搜索树和图的算法,也称为宽度优先搜索,BFS算法从图的某个节点开始,依次对其所有相邻节点进行探索和遍历,然后再…...
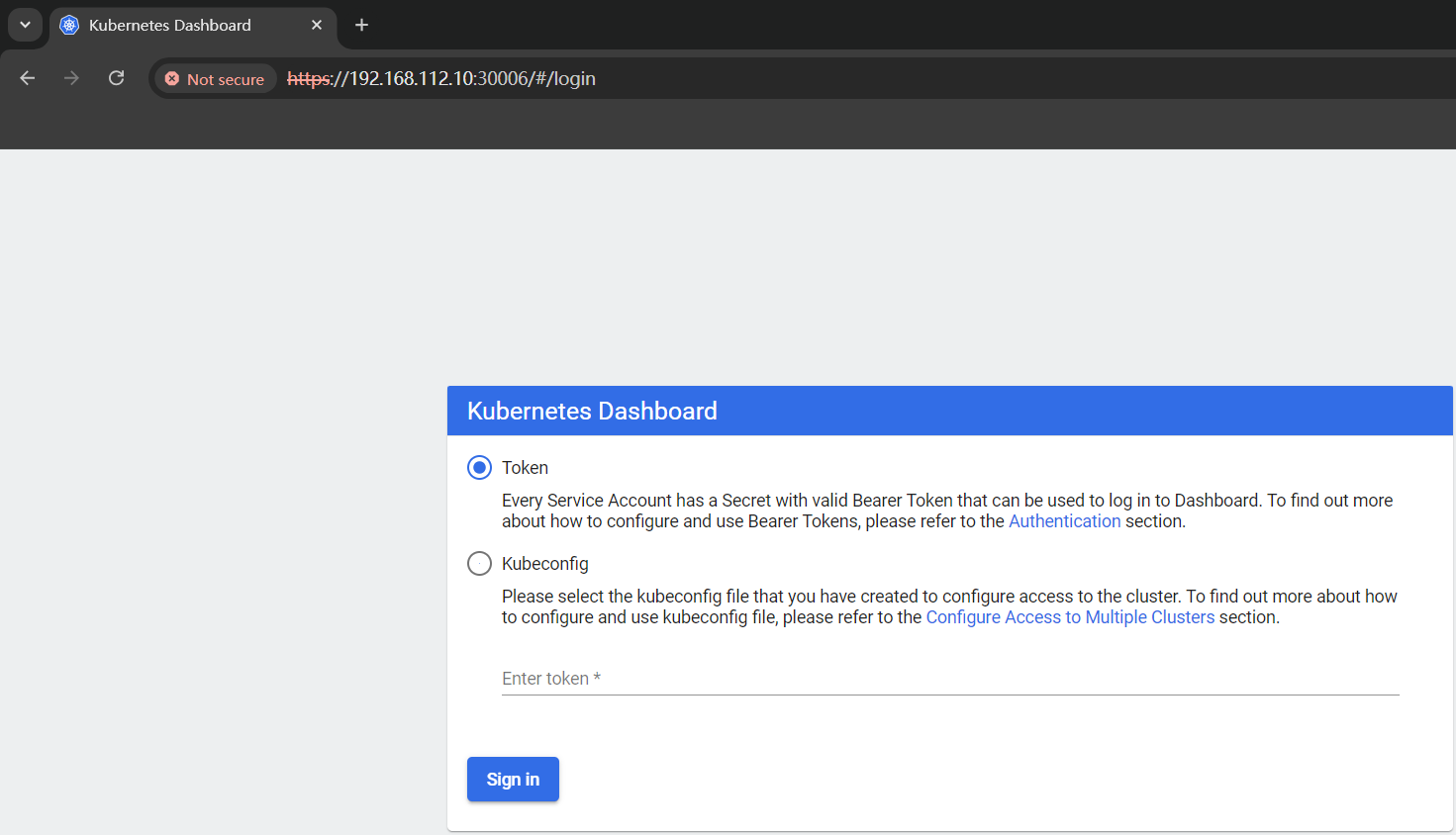
登录 k8s-Dashboard 显示 Your connection is not private
文章目录 一、背景二、解决方案 一、背景 部署好 kubernetes-Dashboard 后使用 master节点的 ipport 登录 Dashboard 显示 Your connection is not private 无论是 Edge 还是 Google Chrome 都是这样的情况 二、解决方案 点击网页空白处,英文输入法输入…...

【Bifrost】ubuntu24.04 远程构建及clion设置编码风格google
Bifrost 构建通过clion 远程到ubuntu24.04 构建感觉是不认识这种写法,这种至少是c++11 fix : 修改absl 的构建cmakelist,明确c++17 好像还是不行error: ‘uint8_t’ was not declared in this scope加入:#include <stdint.h>可以解决一部分。那么,这种呢?/home/zha…...
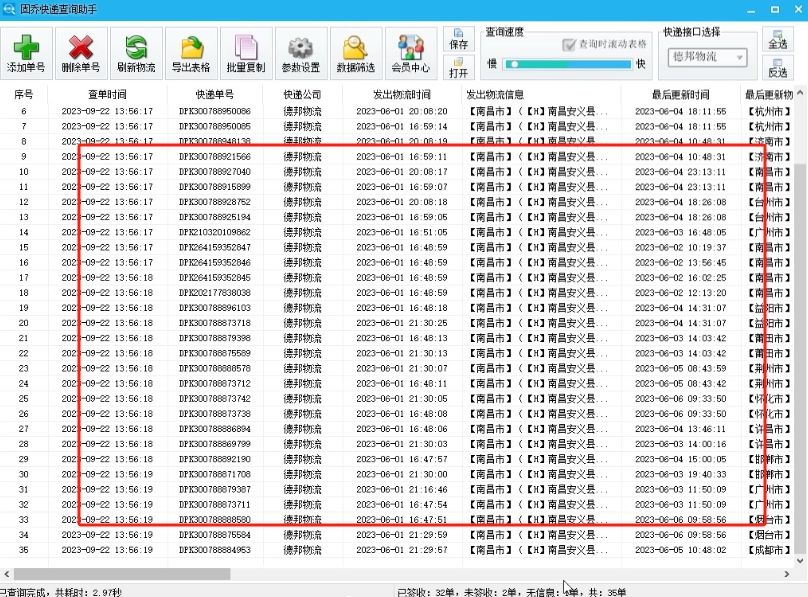
批量查询全国快递单号:高效追踪物流信息
在日常生活和工作中,我们经常会遇到需要查询多个快递单号物流信息的情况。如果手动逐一查询,不仅效率低下,而且容易出错。为了解决这个问题,我们可以借助固乔科技推出的【固乔快递查询助手】软件,轻松实现全国快递的批…...

DVWA | CSRF(LowMedium)攻击的渗透实践
目录 概述 Low Medium 概述 CSRF(Cross-Site Request Forgery,跨站请求伪造) 是一种网络攻击方式。 通过伪造当前用户的行为,让目标服务器误以为请求由当前用户发起,并利用当前用户权限实现业务请求伪造。 例如&a…...

Tmagic-editor低代码底层拖拽库Moveable示例学习
在前面咱们的自研低代码海报制作平台学习分享计划中分享了自己开发的基本拖拽组件,也只是做了最简单的基本实现。真要写产品,更多还是依赖相关的开源优秀库。 文章目录 参考基本拖拽基本缩放基本Scalable基本旋转基于原点的拖拽和旋转关于练习源码 参考 …...

公开测评:文件防泄密系统哪家好|4款文件防泄密软件推荐
在文件防泄密系统领域,有多款软件以其高效、安全和全面的功能脱颖而出,为企业数据保护提供了有力支持。以下是四款值得推荐的文件防泄密软件,它们各具特色,能够满足不同企业的数据安全需求。 1. 安企神软件 7天试用版https://wor…...

【wiki知识库】09.欢迎页面添加(统计浏览量)Vue修改
目录 编辑 一、今日目标 二、新增the-welcome组件 2.1 template 2.2 script 2.2.1 getStatistic 2.2.2 get30DayStatistic 一、今日目标 上篇文章链接:【wiki知识库】08.添加用户登录功能--前端Vue部分修改-CSDN博客 今天就要实现最后的东西了,…...

ui自动化难点
位置坐标:可以通过滑动等方式实现 颜色显示:UIAuto.DEV (devsleep.com) --此工具可以解决很多属性上无法解决的问题 原理: 对系统控件的选择和点击实现该方法...

静态路由与默认路由和实验以及ARP工作原理
目录 1.静态路由和默认路由 1.1 静态路由 1.2 默认路由 1.3 主要区别总结 2.实验 2.1 实验 2.1.1 实验top 2.1.2 实验要求 2.2 实验配置 2.2.1 ip信息配置 2.2.2 配置静态 2.2.3配置默认 2.3 实验结果查看 3.为什么第一个ping会显示丢包? 3.1 ARP 工…...

智慧树自动刷课插件:3步告别手动点击,让在线学习效率提升200%
智慧树自动刷课插件:3步告别手动点击,让在线学习效率提升200% 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的繁琐操作而烦恼…...

为AI编码代理构建确定性安全层:开源安全网关ai-sec实战指南
1. 项目概述:为AI编码代理构建确定性安全层如果你正在使用Claude Code、Cursor、Codex这类AI编码助手,或者正在开发基于LLM的自动化工作流,那么一个核心的痛点你一定深有体会:如何确保AI不会执行危险命令?当AI助手建议…...

解锁MapleStory游戏资源编辑的终极指南:Harepacker-resurrected深度解析
解锁MapleStory游戏资源编辑的终极指南:Harepacker-resurrected深度解析 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾…...

量子噪声控制与FIR滤波器应用解析
1. 量子噪声控制基础与FIR滤波器原理量子计算的核心挑战之一是如何在噪声环境中保持量子态的相干性。量子比特极易受到环境噪声的影响,导致量子门操作精度下降。在众多噪声类型中,1/f噪声(低频噪声)因其普遍存在于固态量子系统中而…...
)
别再踩坑了!Ubuntu 20.04下用Docker一键编译OLLVM 4.0(附完整Dockerfile)
基于Docker的OLLVM 4.0高效编译指南:Ubuntu 20.04最佳实践 在移动安全与逆向工程领域,OLLVM作为代码混淆的黄金标准工具链,其环境搭建一直是开发者面临的痛点。传统源码编译方式需要处理复杂的依赖关系、版本冲突和系统污染风险,而…...

如何快速获取学术文献:SciDownl高效科研工具完全指南
如何快速获取学术文献:SciDownl高效科研工具完全指南 【免费下载链接】SciDownl An unofficial api for downloading papers from SciHub via DOI, PMID, title 项目地址: https://gitcode.com/gh_mirrors/sc/SciDownl 在当今的科研工作中,获取学…...

建议科技部与教育部聘请耿同学做学术打假工作
目前,学术界和社会公众正在热议的有一个核心话题:学术打假。“耿同学”(B站科普博主“耿同学讲故事”)近期在学术打假领域的表现确实堪称“降维打击”。作为一名退学博士,他仅凭个人力量和一些开源AI工具,在…...

从协同过滤到深度学习:Spark机器学习实战三部曲
1. 协同过滤:Spark推荐系统的基石 推荐系统是机器学习最接地气的应用场景之一。我在电商平台做算法优化时,发现协同过滤(CF)始终是新手最容易上手的推荐算法。Spark MLlib提供了两种经典实现:基于物品的协同过滤(Item CF)和基于用户的协同过滤…...

构建AI模型API桥接器:实现OpenAI格式与私有模型服务的无缝对接
1. 项目概述:连接两个世界的桥梁最近在折腾一些AI相关的项目时,遇到了一个挺有意思的“桥接”需求。简单来说,我手头有一套基于OpenAI API的成熟应用逻辑,但出于性能、成本或者特定环境限制的考虑,我希望后端能无缝切换…...

打破物理限制:如何用ParsecVDisplay创建多达16个虚拟显示器?
打破物理限制:如何用ParsecVDisplay创建多达16个虚拟显示器? 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一款基于Parsec虚拟显示驱动…...