【Pytorch】利用PyTorch实现图像识别

本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
这是目录
- 使用torchvision库的datasets类加载常用的数据集或自定义数据集
- 使用torchvision库进行数据增强和变换,自定义自己的图像分类数据集并使用torchvision库加载它们
- 使用torchvision库的models类加载预训练模型或自定义模型
- forward方法
- 进行模型训练和测试,使用matplotlib.pyplot库可视化结果
使用torchvision库的datasets类加载常用的数据集或自定义数据集
图像识别是计算机视觉中的一个基础任务,它的目标是让计算机能够识别图像中的物体、场景或者概念,并将它们分配到预定义的类别中。例如,给定一张猫的图片,图像识别系统应该能够输出“猫”这个类别。
为了训练和评估图像识别系统,我们需要有大量的带有标注的图像数据集。常用的图像分类数据集有:
- ImageNet:一个包含超过1400万张图片和2万多个类别的大型数据库,是目前最流行和最具挑战性的图像分类基准之一。
- CIFAR-10/CIFAR-100:一个包含6万张32×32大小的彩色图片和10或100个类别的小型数据库,适合入门级和快速实验。
- MNIST:一个包含7万张28×28大小的灰度手写数字图片和10个类别的经典数据库,是深度学习中最常用的测试集之一。
- Fashion-MNIST:一个包含7万张28×28大小的灰度服装图片和10个类别的数据库,是MNIST数据库在时尚领域上更加复杂和现代化版本。
使用torchvision库可以方便地加载这些常用数据集或者自定义数据集。torchvision.datasets提供了一些加载数据集或者下载数据集到本地缓存文件夹(默认为./data)并返回Dataset对象(torch.utils.data.Dataset) 的函数。Dataset对象可以存储样本及其对应标签,并提供索引方式(dataset[i])来获取第i个样本。例如,要加载CIFAR-10训练集并进行随机打乱,可以使用以下代码:
import torchvision
import torchvision.transforms as transformstransform = transforms.Compose([transforms.ToTensor()]) # 定义转换函数,将PIL.Image转换为torch.Tensor
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) # 加载CIFAR-10训练集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True) # 定义DataLoader对象,用于批量加载数据
使用torchvision库进行数据增强和变换,自定义自己的图像分类数据集并使用torchvision库加载它们
- 数据增强和变换:为了提高模型的泛化能力和数据利用率,我们通常会对图像数据进行一些随机的变换,例如裁剪、旋转、翻转、缩放、亮度调整等。这些变换可以在一定程度上模拟真实场景中的图像变化,增加模型对不同视角和光照条件下的物体识别能力。torchvision.transforms提供了一些常用的图像变换函数,可以组合成一个transform对象,并传入datasets类中作为参数。例如,要对CIFAR-10训练集进行随机水平翻转和随机裁剪,并将图像归一化到[-1, 1]范围内,可以使用以下代码:
import torchvision
import torchvision.transforms as transformstransform = transforms.Compose([transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomCrop(32, padding=4), # 随机裁剪到32×32大小,并在边缘填充4个像素transforms.ToTensor(), # 将PIL.Image转换为torch.Tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 将RGB三个通道的值归一化到[-1, 1]范围内
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) # 加载CIFAR-10训练集,并应用上述变换
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True) # 定义DataLoader对象,用于批量加载数据
- 自定义图像分类数据集:如果我们有自己的图像分类数据集,我们可以通过继承torch.utils.data.Dataset类来自定义一个Dataset对象,并实现__len__和__getitem__两个方法。__len__方法返回数据集中样本的数量,__getitem__方法根据给定的索引返回一个样本及其标签。例如,假设我们有一个文件夹结构如下:
my_dataset/
├── class_0/
│ ├── image_000.jpg
│ ├── image_001.jpg
│ └── ...
├── class_1/
│ ├── image_000.jpg
│ ├── image_001.jpg
│ └── ...
└── ...
其中每个子文件夹代表一个类别,每个子文件夹中包含该类别对应的图像文件。我们可以使用以下代码来自定义一个Dataset对象,并加载这个数据集:
import torch.utils.data as data
from PIL import Image
import osclass MyDataset(data.Dataset):def __init__(self, root_dir, transform=None):self.root_dir = root_dir # 根目录路径self.transform = transform # 变换函数self.classes = sorted(os.listdir(root_dir)) # 类别列表(按字母顺序排序)self.class_to_idx = {c: i for i,c in enumerate(self.classes)} # 类别名到索引的映射self.images = [] # 图片路径列表(相对于根目录)self.labels = [] # 标签列表(整数)for c in self.classes:c_dir = os.path.join(root_dir, c) # 类别子目录路径for img_name in sorted(os.listdir(c_dir)): # 遍历每个图片文件名(按字母顺序排序)img_path = os.path.join(c,img_name) # 图片相对路径(相对于根目录)label = self.class_to_idx[c] # 图
使用torchvision库的models类加载预训练模型或自定义模型
- 加载预训练模型或自定义模型:torchvision.models提供了一些常用的图像分类模型,例如AlexNet、VGG、ResNet等,并且可以选择是否加载在ImageNet数据集上预训练好的权重。这些模型可以直接用于图像分类任务,也可以作为特征提取器或者微调(fine-tune)的基础。例如,要加载一个预训练好的ResNet-18模型,并冻结除最后一层外的所有参数,可以使用以下代码:
import torchvision.models as modelsmodel = models.resnet18(pretrained=True) # 加载预训练好的ResNet-18模型
for param in model.parameters(): # 遍历所有参数param.requires_grad = False # 将参数的梯度设置为False,表示不需要更新
num_features = model.fc.in_features # 获取全连接层(fc)的输入特征数
model.fc = torch.nn.Linear(num_features, 10) # 替换全连接层为一个新的线性层,输出特征数为10(假设有10个类别)
如果我们想要自定义自己的图像分类模型,我们可以通过继承torch.nn.Module类来实现一个Module对象,并实现__init__和forward两个方法。__init__方法用于定义模型中需要的各种层和参数,forward方法用于定义前向传播过程。例如,要自定义一个简单的卷积神经网络(CNN)模型,可以使用以下代码:
import torch.nn as nnclass MyCNN(nn.Module):def __init__(self):super(MyCNN, self).__init__() # 调用父类构造函数self.conv1 = nn.Conv2d(3, 6, 5) # 定义第一个卷积层,输入通道数为3(RGB),输出通道数为6,卷积核大小为5×5self.pool = nn.MaxPool2d(2, 2) # 定义最大池化层,池化核大小为2×2,步长为2self.conv2 = nn.Conv2d(6, 16, 5) # 定义第二个卷积层,输入通道数为6,输出通道数为16,卷积核大小为5×5self.fc1 = nn.Linear(16 * 5 * 5, 120) # 定义第一个全连接层,输入特征数为16×5×5(根据卷积和池化后的图像大小计算得到),输出特征数为120self.fc2 = nn.Linear(120, 84) # 定义第二个全连接层,输入特征数为120,输出特征数为84self.fc3 = nn.Linear(84, 10) # 定义第三个全连接层,输入特征数为84,
forward方法
forward方法用于定义前向传播过程,即如何根据输入的图像张量(Tensor)计算出输出的类别概率分布。我们可以使用定义好的各种层和参数,并结合一些激活函数(如ReLU)和归一化函数(如softmax)来实现forward方法。例如,要实现上面自定义的CNN模型的forward方法,可以使用以下代码:
import torch.nn.functional as Fclass MyCNN(nn.Module):def __init__(self):# 省略__init__方法的内容...def forward(self, x): # 定义前向传播过程,x是输入的图像张量x = self.pool(F.relu(self.conv1(x))) # 将x通过第一个卷积层和ReLU激活函数,然后通过最大池化层x = self.pool(F.relu(self.conv2(x))) # 将x通过第二个卷积层和ReLU激活函数,然后通过最大池化层x = x.view(-1, 16 * 5 * 5) # 将x展平为一维向量,-1表示自动推断批量大小x = F.relu(self.fc1(x)) # 将x通过第一个全连接层和ReLU激活函数x = F.relu(self.fc2(x)) # 将x通过第二个全连接层和ReLU激活函数x = self.fc3(x) # 将x通过第三个全连接层x = F.softmax(x, dim=1) # 将x通过softmax函数,沿着第一个维度(类别维度)进行归一化,得到类别概率分布return x # 返回输出的类别概率分布
进行模型训练和测试,使用matplotlib.pyplot库可视化结果
模型训练和测试是机器学习中的重要步骤,它们可以帮助我们评估模型的性能和泛化能力。matplotlib.pyplot是一个Python库,它可以用来绘制各种类型的图形,包括曲线图、散点图、直方图等。使用matplotlib.pyplot库可视化结果的一般步骤如下:
- 导入matplotlib.pyplot模块,并设置一些参数,如字体、分辨率等。
- 创建一个或多个图形对象(figure),并指定大小、标题等属性。
- 在每个图形对象中创建一个或多个子图(subplot),并指定位置、坐标轴等属性。
- 在每个子图中绘制数据,使用不同的函数和参数,如plot、scatter、bar等。
- 添加一些修饰元素,如图例(legend)、标签(label)、标题(title)等。
- 保存或显示图形。
例如:使用matplotlib.pyplot库绘制了一个线性回归模型的训练误差和测试误差曲线:
# 导入模块
import matplotlib.pyplot as plt
import numpy as np# 设置字体和分辨率
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
%config InlineBackend.figure_format = "retina"# 生成数据
x = np.linspace(0, 10, 100)
y = 3 * x + 5 + np.random.randn(100) * 2 # 真实值
w = np.random.randn() # 随机初始化权重
b = np.random.randn() # 随机初始化偏置# 定义损失函数
def loss(y_true, y_pred):return ((y_true - y_pred) ** 2).mean()# 定义梯度下降函数
def gradient_descent(x, y_true, w, b, lr):y_pred = w * x + b # 预测值dw = -2 * (x * (y_true - y_pred)).mean() # 权重梯度db = -2 * (y_true - y_pred).mean() # 偏置梯度w = w - lr * dw # 更新权重b = b - lr * db # 更新偏置return w, b# 训练模型,并记录每轮的训练误差和测试误差
epochs = 20 # 训练轮数
lr = 0.01 # 学习率
train_loss_list = [] # 训练误差列表
test_loss_list = [] # 测试误差列表for epoch in range(epochs):# 划分训练集和测试集(8:2)train_index = np.random.choice(100, size=80, replace=False)test_index = np.setdiff1d(np.arange(100), train_index)x_train, y_train = x[train_index], y[train_index]x_test, y_test = x[test_index], y[test_index]# 梯度下降更新参数,并计算训练误差和测试误差w, b = gradient_descent(x_train, y_train, w, b, lr)train_loss = loss(y_train, w * x_train + b)test_loss = loss(y_test, w * x_test + b)# 打印结果,并将误差添加到列表中print(f"Epoch {epoch+1}, Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}")train_loss_list.append(train_loss)test_loss_list.append(test_loss)# 创建一个图形对象,并设置大小为8*6英寸
plt.figure(figsize=(8,6))# 在图形对象中创建一个子图,并设置位置为1行1列的第1个
plt.subplot(1, 1, 1)# 在子图中绘制训练误差和测试误差曲线,使用不同的颜色和标签
plt.plot(np.arange(epochs), train_loss_list, "r", label="Train Loss")
plt.plot(np.arange(epochs), test_loss_list, "b", label="Test Loss")# 添加图例、坐标轴标签和标题
plt.legend()
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Linear Regression Loss Curve")# 保存或显示图形
#plt.savefig("loss_curve.png")
plt.show()
运行后,可以看到如下的图形:


参考:: PyTorch官方网站

相关文章:
【Pytorch】利用PyTorch实现图像识别
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 这是目录使用torchvision库的datasets类加载常用的数据集或自定义数据集使用torchvision库进行数据增强和变换,自定义自己的图像分类数据集并使用torchvision库加载它们使…...

在家查找下载最新《柳叶刀》The Lancet期刊文献的方法
《柳叶刀》The Lancet简介: 《柳叶刀》The Lancet是全球顶尖综合性医学期刊,每周都会发表来自世界各地顶尖科学家的研究精粹。是由托马斯威克利(Thomas Wakley)创办于1823年,由爱思唯尔(Elsevierÿ…...
当下的网络安全行业前景到底怎么样?还能否入行?
前言网络安全现在是朝阳行业,缺口是很大。不过网络安全行业就是需要技术很多的人达不到企业要求才导致人才缺口大常听到很多人不知道学习网络安全能做什么,发展前景好吗?今天我就在这里给大家介绍一下。网络安全作为目前比较火的朝阳行业&…...

SpringCloud:SpringAMQP介绍
Spring AMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。Spring AMQP官方地址 Spring AMQP提供了三个功能: 自动声明队列、交换机及其绑定关系基于注解的监听器模式,异步接收消息封…...

第十三届蓝桥杯省赛 python B组复盘
文章目录前言主要内容🦞试题 A:排列字母思路代码🦞试题 B:寻找整数思路代码🦞试题 C:纸张尺寸思路代码🦞试题 D:数位排序思路代码🦞试题 E:蜂巢思路代码&…...
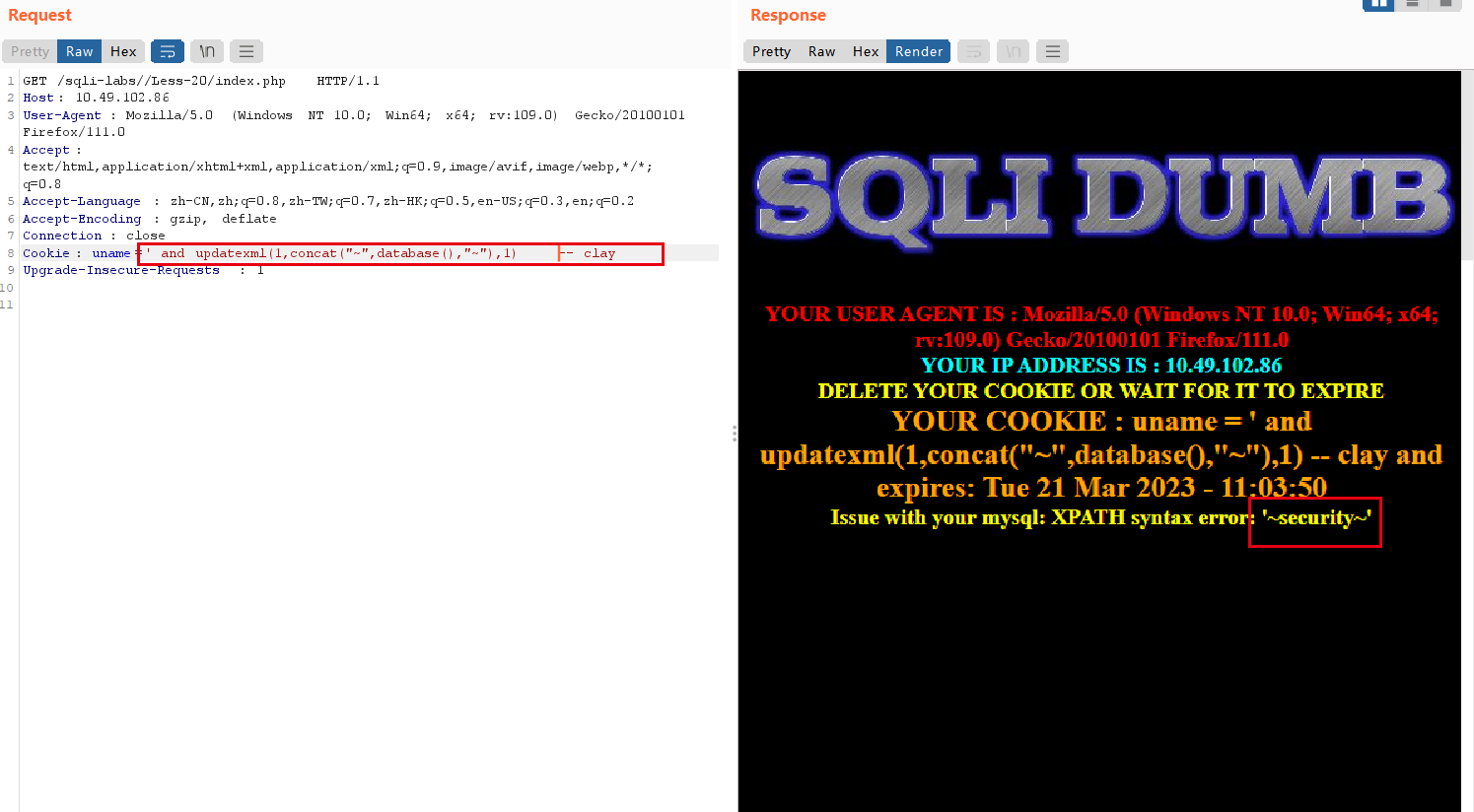
SQL注入之HTTP请求头注入
Ps: 先做实验,在有操作的基础上理解原理会更清晰更深入。 一、实验 sqli-lab 1. User-Agent注入 特点:登陆后返回用户的 User-Agent --> 服务器端可能记录用户User-Agent 输入不合法数据报错 payload: and updatexml(1,concat("~&…...

Metasploit详细教程
第一步:安装和启动Metasploit 您可以从Metasploit官方网站下载适用于您操作系统的Metasploit框架。安装Metasploit框架后,您可以使用以下命令来启动Metasploit: msfconsole该命令将启动Metasploit控制台。 第二步:查找目标设备…...

【ChatGPT】Notion AI 从注册到体验:如何免费使用
欢迎关注【youcans的GPT学习笔记】原创作品,火热更新中 【ChatGPT】Notion AI 从注册到体验1. Notion AI 介绍1.1 Notion AI 简介1.2 Notion AI 的核心能力1.3 Notion AI 与 ChatGPT 的比较2. Notion AI 国内用户注册2.1 PC 端用户注册2.2 移动端用户注册3. Notion …...
每个开发人员都需要掌握的10 个基本 SQL 命令
SQL 是一种非常常见但功能强大的工具,它可以帮助从任何数据库中提取、转换和加载数据。数据查询的本质在于SQL。随着公司和组织发现自己处理的数据量迅速增加,开发人员越来越需要有效地使用数据库来处理这些数据。所以想要暗恋数据领域,SQL是…...

Vue项目预渲染
前言 Ajax 技术的出现,让我们的 Web 应用能够在不刷新的状态下显示不同页面的内容,这就是单页应用。在一个单页应用中,往往只有一个 html 文件,然后根据访问的 url 来匹配对应的路由脚本,动态地渲染页面内容。单页应用…...

可别再用BeanUtils了(性能拉胯),试试这款转换神器
老铁们是不是经常为写一些实体转换的原始代码感到头疼,尤其是实体字段特别多的时候。有的人会说,我直接使用get/set方法。没错,get/set方法的确可以解决,而且也是性能较高的处理方法,但是大家有没有想过,要…...
Transformer 杂记
Transformer输入的是token,来自语言序列的启发。卷积神经网络(CNN)是如何进行物种分类的.它实际是直接对特征进行识别,也就是卷积神经网络最基本的作用:提取图像的特征。例如:卷积神经网络判断一只狗的时候,…...

实现异步的8种方式
前言异步执行对于开发者来说并不陌生,在实际的开发过程中,很多场景多会使用到异步,相比同步执行,异步可以大大缩短请求链路耗时时间,比如:「发送短信、邮件、异步更新等」,这些都是典型的可以通…...
Github隐藏功能显示自己的README,个人化你的Github主页
Github隐藏功能:显示自己的README 你可能还不知道,GitHub 悄悄上线了一个全新的个人页功能,显示一个自定义的 README.MD 在个人首页。要激活此功能,需要新建一个与自己 ID 同名的 Repository,新 Repo 里的README.MD将…...
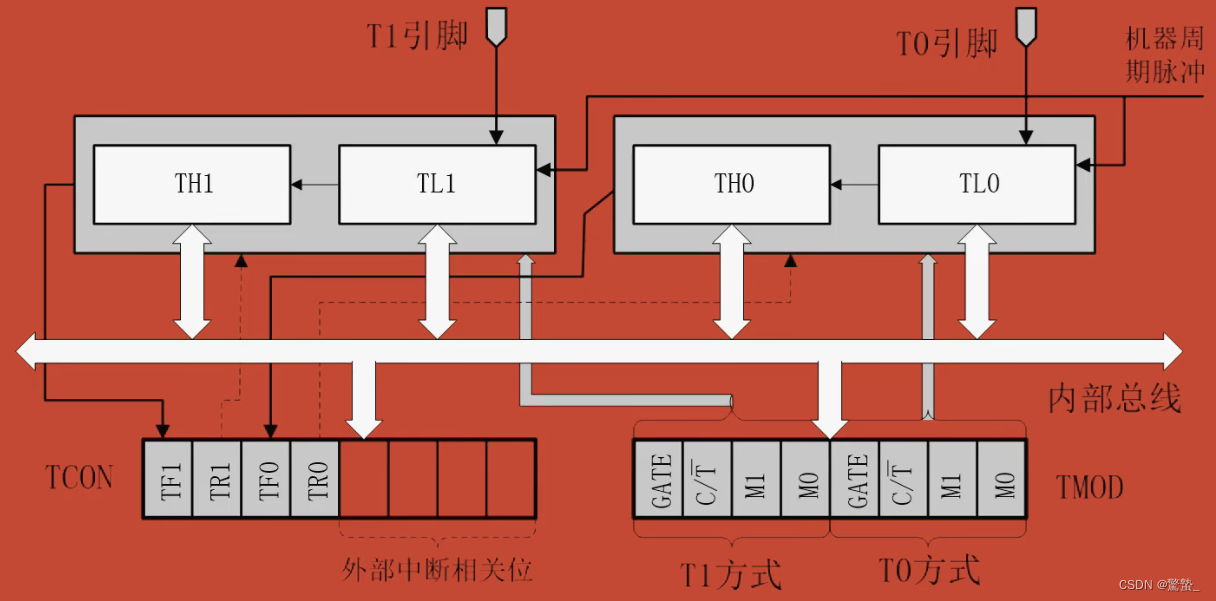
单片机 | 51单片机原理
【金善愚】 单片机应用原理篇 笔记整理 课程视频 :https://space.bilibili.com/483942191/channel/collectiondetail?sid51090 文章目录一、引脚分布介绍1.分类2.电源引脚3.时钟引脚(2根)4.控制引脚(4根)5.端口引脚(32根)二、存储器结构及空间分布介绍1.存储器的划…...
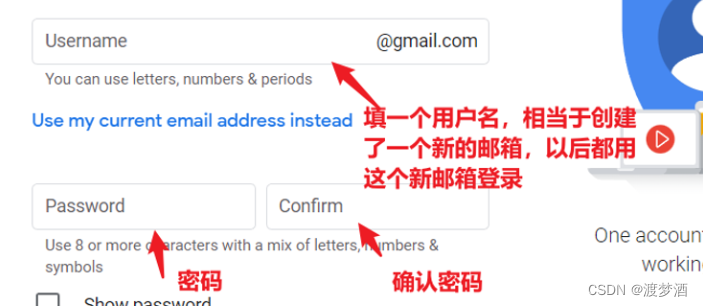
(只需五步)注册谷歌账号详细步骤,解决“此电话号码无法验证”问题
目录 第一步:打开google浏览器 第二步:设置语言为英语(美国) 第三步:点击重新启动,重启浏览器 第四步:开始注册 第五步,成功登录google账号! 如果出现这样的原因&…...
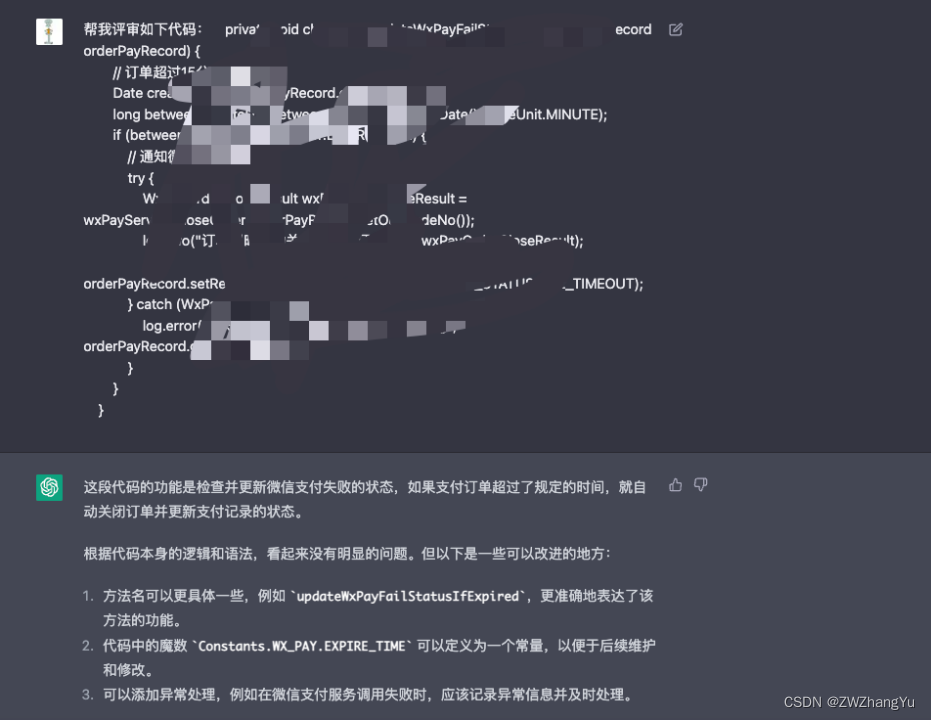
ChatGPT使用介绍、ChatGPT+编程、相关组件和插件记录
文章目录介绍认识ChatGPT是通过英汉互译来实现中文回答的吗同一个问题,为什么中英文回答不同ChatGPT的使用对话组OpenAI APIAI智能绘图DALLE 2ChatGPT for Google插件ChatGPT编程编写代码代码错误修正与功能解读代码评审与优化推荐技术方案编写和优化SQL语句在代码编…...

linux系统中复制粘贴和头文件问题解决方案
各位开发者大家好,好久不见,为了更好的服务大家,将平常所见所闻,以及遇到的问题和解决办法进行记录和总结。大家在学习过程中,有任何问题欢迎交流学习!!!。 第一:如何将w…...

Vue项目实战 —— 后台管理系统( pc端 ) —— Pro最终版本
前期回顾 开源项目 —— 原生JS实现斗地主游戏 ——代码极少、功能都有、直接粘贴即用_js斗地主_0.活在风浪里的博客-CSDN博客JS 实现 斗地主网页游戏https://blog.csdn.net/m0_57904695/article/details/128982118?spm1001.2014.3001.5501 通用版后台管理系统,如果…...

Springboot+vue开发的图书借阅管理系统项目源码下载-P0029
前言图书借阅管理系统项目是基于SpringBootVue技术开发而来,功能相对比较简单,分为两个角色即管理员和学生用户,核心业务功能就是图书的发布、借阅与归还,相比于一些复杂的系统,该项目具备简单易入手,便于二…...

python足球训练营系统的足球俱乐部管理系统 球员评估系统_m211bvkc
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能模块技术实现代码示例(球员评分计算)应用场景扩展方向获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货…...

对比直接使用厂商API,Taotoken在用量观测与账单管理上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在用量观测与账单管理上的便利性 当开发者或团队同时接入多个大模型厂商的原生API时&…...

避坑指南:在Ubuntu 20.04上配置VNC远程桌面,为什么我推荐UltraVNC Viewer而不是TigerVNC?
Ubuntu 20.04远程桌面配置:为什么UltraVNC Viewer成为技术中坚的首选? 在Linux桌面环境远程管理的世界里,VNC协议就像一位历经沧桑的老兵,依然活跃在企业运维、远程开发和混合办公的第一线。Ubuntu 20.04 LTS作为长期支持版本&…...
)
手把手教你用USB ISP下载器给Arduino Nano烧写Bootloader(含ProgISP软件详细配置)
手把手教你用USB ISP下载器为Arduino Nano烧录Bootloader 当你拿到一块全新的Arduino Nano开发板,或是遇到程序无法上传的"变砖"情况时,很可能需要重新烧写Bootloader。Bootloader是存储在微控制器中的一小段特殊程序,它负责与Ard…...

【Qt学习】基本类型、日志输出、字符串、QVariant
文章目录基本数据类型日志输出Qt Creator中看日志单独控制台看日志字符串类型示例字符串拼接字符串长度QVariant示例变量相加自定义类型前文回顾: 【Qt学习】Windows上环境配置与项目初识 【Qt学习】三个窗口类、坐标系、内存回收 基本数据类型 Qt基本数据类型定义…...

终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案
终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows…...

iOS自动化测试环境搭建:Appium+Python真机与模拟器全链路通关指南
1. 为什么iOS自动化测试环境搭建总让人卡在第一步?“AppiumPython实现iOS自动化测试~环境搭建”——这个标题里藏着太多新手看不见的暗礁。我带过三届测试团队,每年都有至少7个人卡在“连不上真机”“Xcode报错找不到WebDriverAgent”“模拟器启动后白屏…...

Arty S7 FPGA开发板:从入门到进阶的硬件加速与嵌入式开发实战
1. 项目概述:为什么是Arty S7?如果你是一名嵌入式开发者、数字电路设计的学生,或者对硬件加速、实时信号处理感兴趣,那么“FPGA开发板”这个词对你来说一定不陌生。但面对市场上琳琅满目的开发板,从几百元到上万元不等…...

LEFT JOIN 中 ON 与 WHERE 过滤的差异
在 MySQL 数据库开发中,LEFT JOIN(左外连接)是一个最常被误用的语法。许多开发者往往习惯性地将所有过滤条件一股脑地往 ON 后面塞,或者为了排版好看将条件全部扔到 WREHRE 里面。 这种模糊的逻辑在普通内连接(INNER J…...

DDD 中的代码组织:按技术层分 vs 按领域模块分,哪种才是正解?
前言 在实践领域驱动设计(DDD)时,你可能见过两种截然不同的代码组织方式:一种是传统的按技术层划分文件夹,另一种是按业务模块划分文件夹。两种写法的人都声称自己在做 DDD,那到底哪种更合理?本…...